Как упомянуто в Приложении Современной Актуарной Теории Риска , « R (и S) — это« лингва франка »анализа данных и статистических вычислений, используемых в академических кругах, исследованиях климата, информатике, биоинформатике, фармацевтической промышленности, аналитике клиентов, анализе данных. , финансами и некоторыми страховщиками. Помимо того, что R, стабильный, быстрый, всегда актуальный и универсальный, главное преимущество R в том, что он доступен всем бесплатно. Он обладает обширными и мощными графическими возможностями и быстро развивается, являясь предпочтительным статистическим инструментом во многих научных средах. »
R основан на статистическом языке программирования S, разработанном Джо Чамберсом в лаборатории Bell в 80-х годах. Чтобы быть более конкретным, R — это реализация языка S с открытым исходным кодом, разработанная Робертом Джентлемном и Россом Ихакой. Это векторный язык, который делает его чрезвычайно интересным для актуарных вычислений. Например, рассмотрим некоторые таблицы жизни,
> TD[39:52,] > TV[39:52,]
Age Lx Age Lx
39 38 95237 38 97753
40 39 94997 39 97648
41 40 94746 40 97534
42 41 94476 41 97413
43 42 94182 42 97282
44 43 93868 43 97138
45 44 93515 44 96981
46 45 93133 45 96810
47 46 92727 46 96622
48 47 92295 47 96424
49 48 91833 48 96218
50 49 91332 49 95995
51 50 90778 50 95752
52 51 90171 51 95488
Эти (французские) таблицы жизни можно найти здесь
> TD <- read.table( + "http://perso.univ-rennes1.fr/arthur.charpentier/TD8890.csv",sep=";",header=TRUE) > TV <- read.table( + "http://perso.univ-rennes1.fr/arthur.charpentier/TV8890.csv",sep=";",header=TRUE)
Из этих векторов можно построить матрицу вероятностей смерти, ![http://latex.codecogs.com/gif.latex?\boldsymbol{P}=[\text{%20}_{k}p_x]](/wp-content/uploads/images/dzo/9875ed09cb1396ab4aca7f20558625bf.latex)
> Lx <- TD$Lx > m <- length(Lx) > p <- matrix(0,m,m); d <- p > for(i in 1:(m-1)){ + p[1:(m-i),i] <- Lx[1+(i+1):m]/Lx[i+1] + d[1:(m-i),i] <- (Lx[(1+i):(m)]-Lx[(1+i):(m)+1])/Lx[i+1]} > diag(d[(m-1):1,]) <- 0 > diag(p[(m-1):1,]) <- 0 > q <- 1-p
Можно легко вычислить, например, (текущее) ожидание жизни, определяемое как
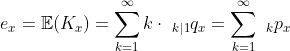
и можно рассчитать вектор ожидаемой продолжительности жизни в разных возрастах ![http://latex.codecogs.com/gif.latex?\boldsymbol{e}=[e_x]](/wp-content/uploads/images/dzo/96068a8936df39d8c2f2193f3308e63e.latex)
> life.exp = function(x){sum(p[1:nrow(p),x])} > e = Vectorize(life.exp)(1:m)
Фактически, любой вид актуарной величины может быть получен из этих матриц. Ожидаемая текущая стоимость (или актуарная стоимость) временного пожизненного аннуитета составляет, например,
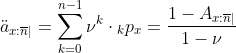
Код для вычисления этих функций находится здесь
> for(j in 1:(m-1)){ adots[,j]<-cumsum(1/(1+i)^(0:(m-1))*c(1,p[1:(m-1),j])) }
или рассмотрите ожидаемую текущую стоимость термина страхования
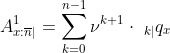
со следующим кодом
> for(j in 1:(m-1)){ A[,j]<-cumsum(1/(1+i)^(1:m)*d[,j]) }
Еще некоторые подробности можно найти в первой части заметок об ускоренных курсах прошлого лета в Мейелисальпе. С вектором — или матрицами — чрезвычайно удобно работать, когда имеешь дело с непредвиденными обстоятельствами жизни. Также возможно моделировать предполагаемую смертность. Здесь смертность является не только функцией возраста 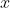 , но и времени
, но и времени 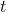 ,
,
> t(DTF)[1:10,1:10] 1899 1900 1901 1902 1903 1904 1905 1906 1907 1908 0 64039 61635 56421 53321 52573 54947 50720 53734 47255 46997 1 12119 11293 10293 10616 10251 10514 9340 10262 10104 9517 2 6983 6091 5853 5734 5673 5494 5028 5232 4477 4094 3 4329 3953 3748 3654 3382 3283 3294 3262 2912 2721 4 3220 3063 2936 2710 2500 2360 2381 2505 2213 2078 5 2284 2149 2172 2020 1932 1770 1788 1782 1789 1751 6 1834 1836 1761 1651 1664 1433 1448 1517 1428 1328 7 1475 1534 1493 1420 1353 1228 1259 1250 1204 1108 8 1353 1358 1255 1229 1251 1169 1132 1134 1083 961 9 1175 1225 1154 1008 1089 981 1027 1025 957 885
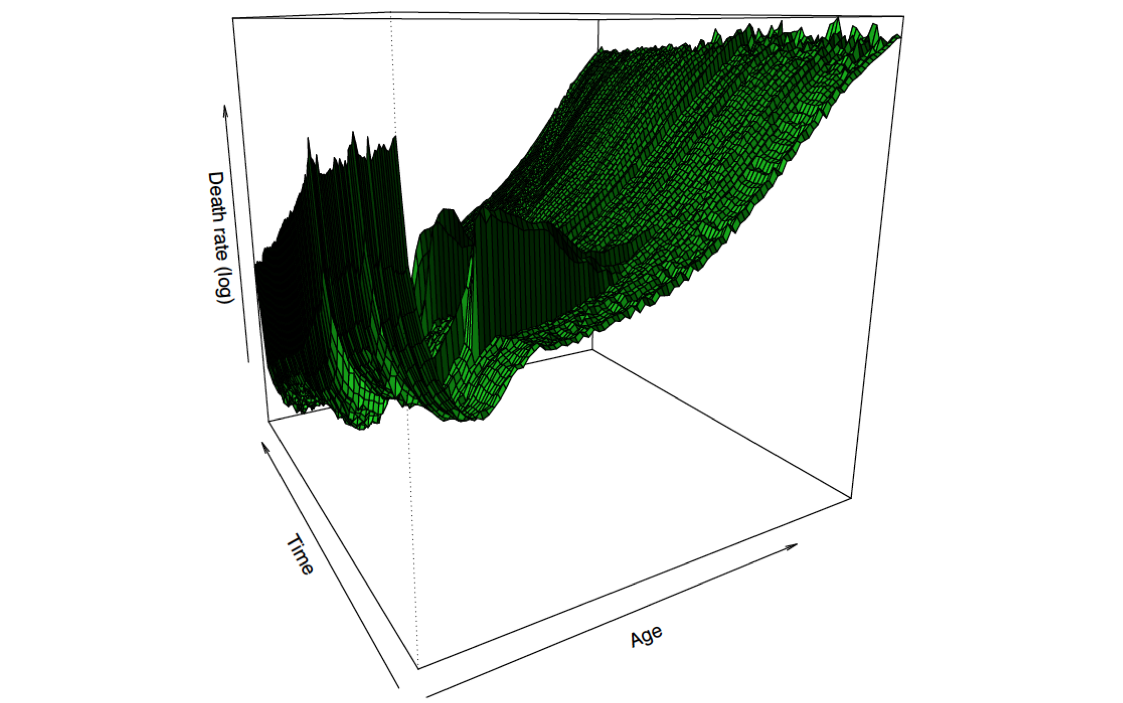
Таким образом, теперь у нас есть матрица силы смертности ![http://latex.codecogs.com/gif.latex?\boldsymbol{\mu}=[\mu_{x,t}]](/wp-content/uploads/images/dzo/2fccb77494f5de9451236403643e28e8.latex)
Также можно использовать пакеты R для оценки модели смертности Ли-Картера,
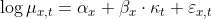
> library(demography) > MUH =matrix(DEATH$Male/EXPOSURE$Male,nL,nC) > POPH=matrix(EXPOSURE$Male,nL,nC) > BASEH <- demogdata(data=MUH, pop=POPH, ages=AGE, years=YEAR, type="mortality", + label="France", name="Hommes", lambda=1) > RES=residuals(LCH,"pearson")
Можно легко изучить остатки, например, в зависимости от возраста,
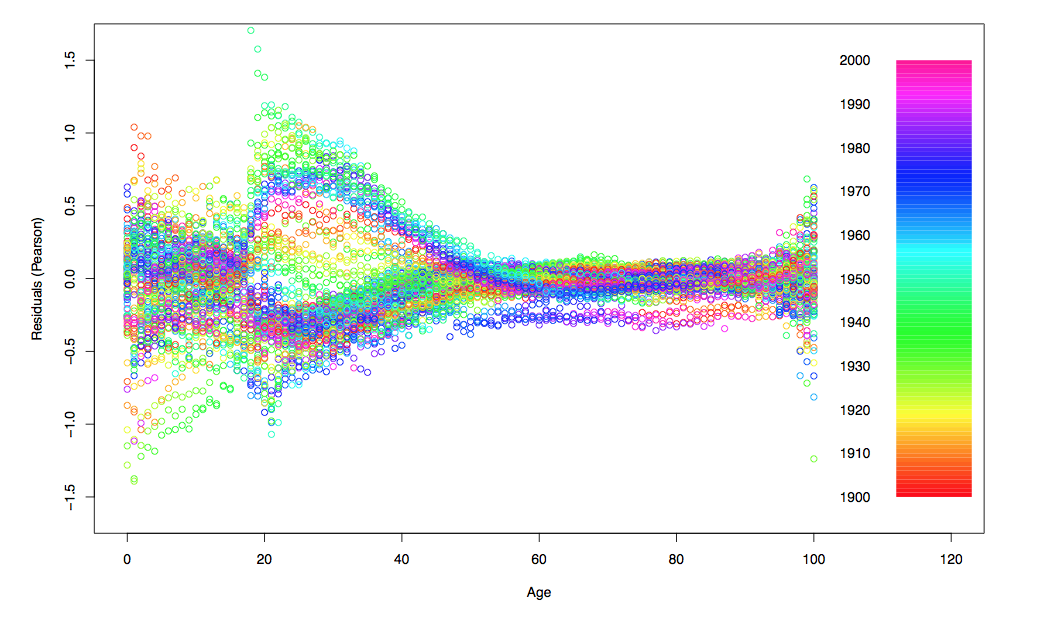
или функция года,
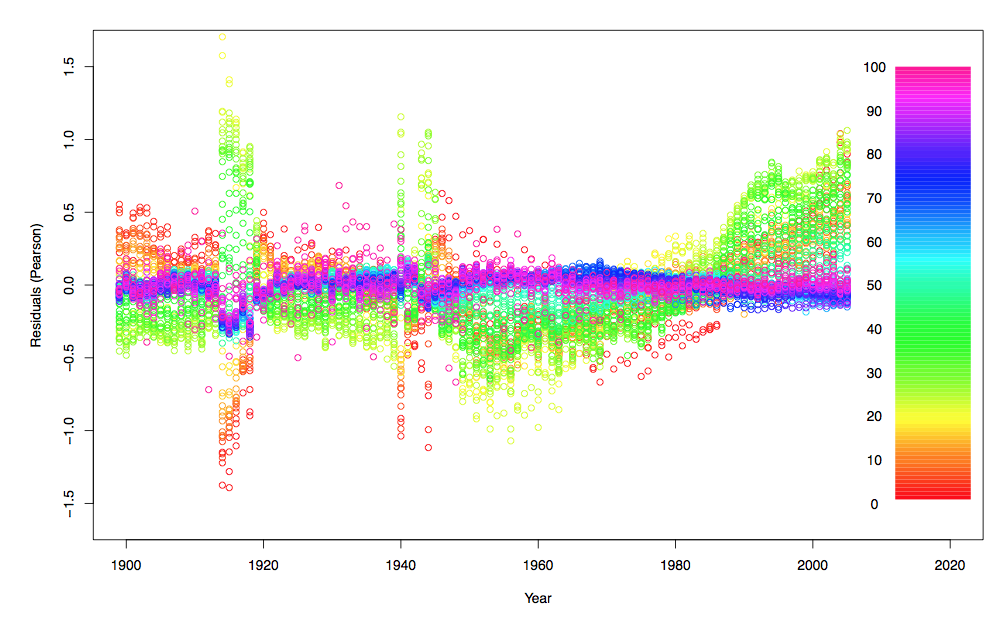
Еще некоторые подробности можно найти во второй части заметок об ускоренных курсах прошлого лета в Мейелисальпе.
R также интересен огромным количеством библиотек, которые можно использовать для прогнозного моделирования. Можно легко использовать функции сглаживания в регрессии или деревья регрессии,
> TREE = tree((nbr>0)~ageconducteur,data=sinistres,split="gini",mincut = 1) > age = data.frame(ageconducteur=18:90) > y1 = predict(TREE,age) > reg = glm((nbr>0)~bs(ageconducteur),data=sinistres,family="binomial") > y = predict(reg,age,type="response")
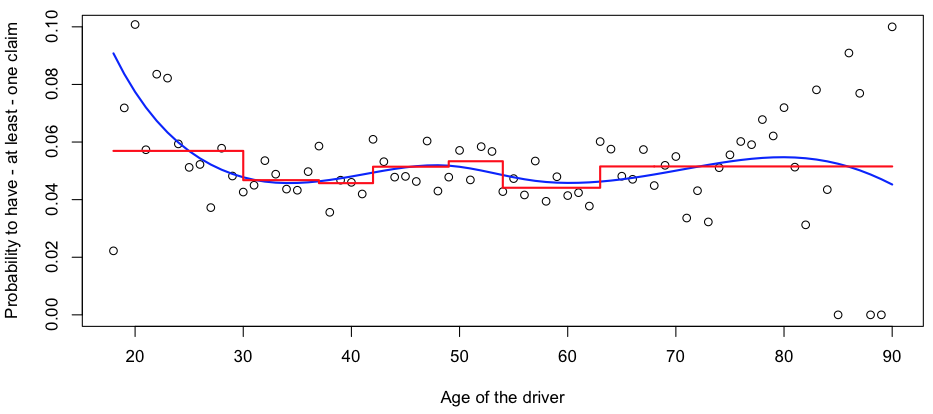
Некоторые практики могут быть напуганы, потому что легенда утверждает, что R не так хорош, как SAS, для обработки больших баз данных. На самом деле, для импорта наборов данных можно использовать множество функций. Наиболее удобный, вероятно,
> baseCOUT = read.table("http://freakonometrics.free.fr/baseCOUT.csv", + sep=";",header=TRUE,encoding="latin1") > tail(baseCOUT,4) numeropol debut_pol fin_pol freq_paiement langue type_prof alimentation type_territoire 6512 87291 2002-10-16 2003-01-22 mensuel A Professeur Vegetarien Urbain 6513 87301 2002-10-01 2003-09-30 mensuel A Technicien Vegetarien Urbain 6514 87417 2002-10-24 2003-10-21 mensuel F Technicien Vegetalien Semi-urbain 6515 88128 2003-01-17 2004-01-16 mensuel F Avocat Vegetarien Semi-urbain utilisation presence_alarme marque_voiture sexe exposition age duree_permis age_vehicule i coutsin 6512 Travail-occasionnel oui FORD M 0.2684932 47 29 28 1 1274.5901 6513 Loisir oui HONDA M 0.9972603 44 24 25 1 278.0745 6514 Travail-occasionnel non VOLKSWAGEN F 0.9917808 23 3 11 1 403.1242 6515 Loisir non FIAT F 0.9972603 23 4 11 1 230.9565
Но если набор данных слишком велик, можно также указать, какие переменные могут быть интересны, используя
> mycols = rep("NULL", 18) > mycols[c(1,4,5,12,13,14,18)] <- NA > baseCOUTsubC = read.table("http://freakonometrics.free.fr/baseCOUT.csv", + colClasses = mycols,sep=";",header=TRUE,encoding="latin1") > head(baseCOUTsubC,4) numeropol freq_paiement langue sexe exposition age coutsin 1 6 annuel A M 0.9945205 42 279.5839 2 27 mensuel F M 0.2438356 51 814.1677 3 27 mensuel F M 1.0000000 53 136.8634 4 76 mensuel F F 1.0000000 42 608.7267
Также возможно (до запуска кода для всего набора данных) импортировать только первые строки набора данных.
> baseCOUTsubCR = read.table("http://freakonometrics.free.fr/baseCOUT.csv", + colClasses = mycols,sep=";",header=TRUE,encoding="latin1",nrows=100) > tail(baseCOUTsubCR,4) numeropol freq_paiement langue sexe exposition age coutsin 97 1193 mensuel F F 0.9972603 55 265.0621 98 1204 mensuel F F 0.9972603 38 9547.7267 99 1231 mensuel F M 1.0000000 40 442.7267 100 1245 annuel F F 0.6767123 48 179.1925
Также возможно импортировать заархивированный файл. Сам файл имеет меньший размер, и его обычно можно импортировать быстрее.
> import.zip = function(file){ + temp = tempfile() + download.file(file,temp); + read.table(unz(temp, "baseFREQ.csv"),sep=";",header=TRUE,encoding="latin1")} > system.time(import.zip("http://freakonometrics.free.fr/baseFREQ.csv.zip")) trying URL 'http://freakonometrics.free.fr/baseFREQ.csv.zip' Content type 'application/zip' length 692655 bytes (676 Kb) opened URL ================================================== downloaded 676 Kb user system elapsed 0.762 0.029 4.578 > system.time(read.table("http://freakonometrics.free.fr/baseFREQ.csv", + sep=";",header=TRUE,encoding="latin1")) user system elapsed 0.591 0.072 9.277
Наконец, обратите внимание, что можно импортировать любой набор данных, а не только текстовый файл. Даже папка Microsoft Excel. На компьютере с Windows можно использовать SQL-запросы
> sheet = "c:\\Documents and Settings\\user\\excelsheet.xls" > connection = odbcConnectExcel(sheet) > spreadsheet = sqlTables(connection) > query = paste("SELECT * FROM",spreadsheet$TABLE_NAME[1],sep=" ") > result = sqlQuery(connection,query)
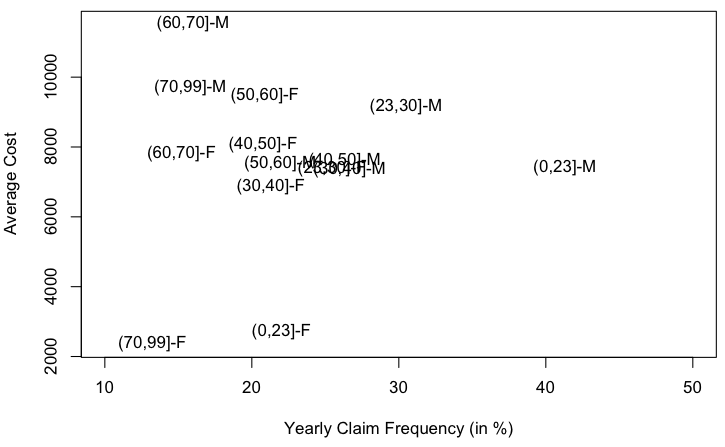
Затем после импорта набора данных можно использовать несколько функций:
> cost = aggregate(coutsin~ AgeSex,mean, data=baseCOUT) > frequency = merge(aggregate(nbsin~ AgeSex,sum, data=baseFREQ), + aggregate(exposition~ AgeSex,sum, data=baseFREQ)) > frequency$freq = frequency$nbsin/frequency$exposition > base.freq.cost = merge(frequency, cost)
Наконец, R интересен своим графическим интерфейсом. « Если вы можете изобразить это в своей голове, велика вероятность, что вы сможете заставить его работать в R. R позволяет легко читать данные, генерировать линии и точки и размещать их там, где вы хотите. Это очень гибкий и супер быстрый. Когда у вас есть только два или три часа до крайнего срока, R может быть великолепным », — сказала Аманда Кокс, графический редактор New York Times. « R особенно ценен в крайних сроках, когда данные скудны, а время драгоценно ».
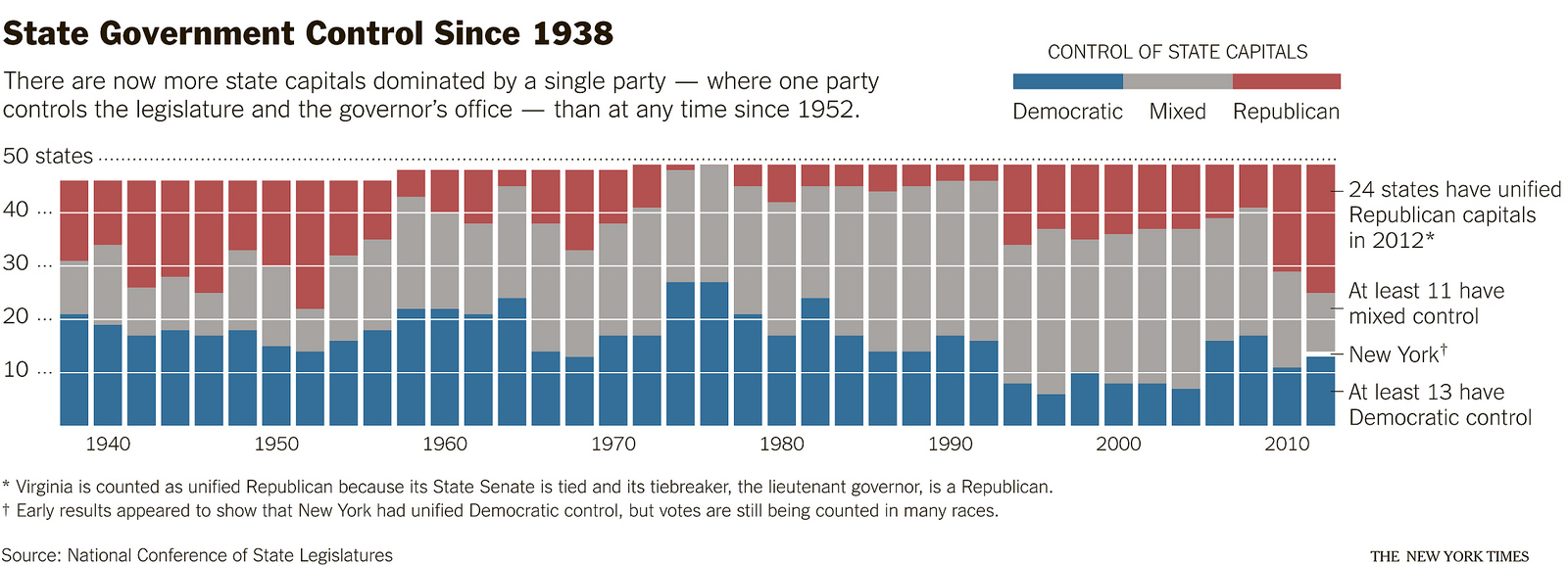
Несколько дел были рассмотрены в блоге http: //chartsnthings.tumblr.com/… . Во-первых, мы начнем с простого графика, здесь контроль правительства штата в США.
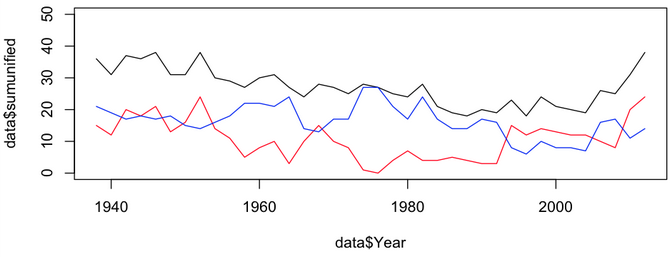
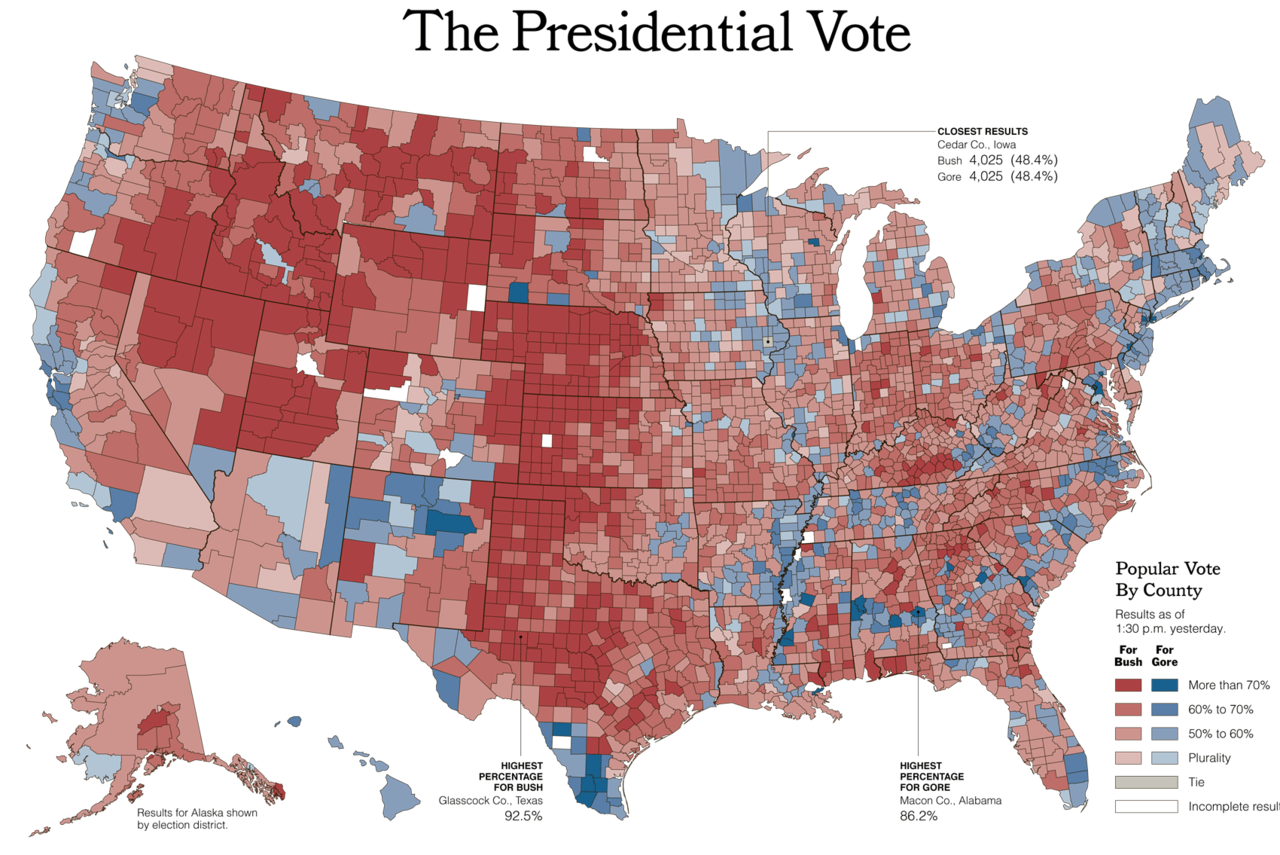
Затем попробуйте найти хорошее визуальное представление, например,

И, наконец, вы можете просто распечатать его в своей любимой газете,
И вы можете получить любой вид графиков,
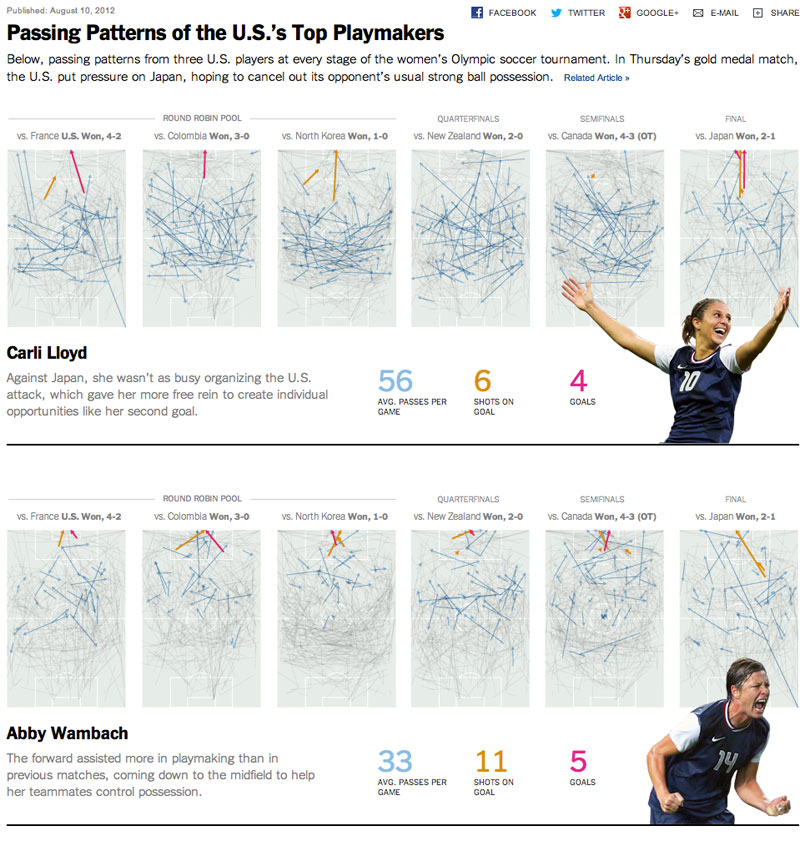
И не только о политике,
 Графики важны. « Речь идет не только о создании графики для публикации. Речь идет об игре и создании набора графики, которая поможет вам изучить ваши данные. Этот вид графического анализа — действительно полезный способ помочь вам понять, с чем вы имеете дело, потому что, если вы не видите его, вы не можете его понять. Но когда вы начнете разбираться в этом, вы действительно сможете увидеть, что у вас есть », — сказал Питер Олдхоус, руководитель бюро в Сан-Франциско журнала New Scientist. Даже для актуариев. «Коммерческий страховой процесс был строгим, но также довольно субъективным и основанным на интуиции. R позволяет нам передавать наши аналитические результаты привлекательными и инновационными способами нетехнической аудитории через быстрые жизненные циклы разработки. R помогает нам показать нашим клиентам, как они могут улучшить свои процессы и эффективность, позволяя нашим консультантам эффективно проводить анализ », — объяснил Джон Лакер, команда опытных аналитиков из Deloitte Consulting Principal, на http://blog.revolutionanalytics.com. / r-is-hot / . См. Также мнение Эндрю Гельмана на графиках http://www.stat.columbia.edu/…
Графики важны. « Речь идет не только о создании графики для публикации. Речь идет об игре и создании набора графики, которая поможет вам изучить ваши данные. Этот вид графического анализа — действительно полезный способ помочь вам понять, с чем вы имеете дело, потому что, если вы не видите его, вы не можете его понять. Но когда вы начнете разбираться в этом, вы действительно сможете увидеть, что у вас есть », — сказал Питер Олдхоус, руководитель бюро в Сан-Франциско журнала New Scientist. Даже для актуариев. «Коммерческий страховой процесс был строгим, но также довольно субъективным и основанным на интуиции. R позволяет нам передавать наши аналитические результаты привлекательными и инновационными способами нетехнической аудитории через быстрые жизненные циклы разработки. R помогает нам показать нашим клиентам, как они могут улучшить свои процессы и эффективность, позволяя нашим консультантам эффективно проводить анализ », — объяснил Джон Лакер, команда опытных аналитиков из Deloitte Consulting Principal, на http://blog.revolutionanalytics.com. / r-is-hot / . См. Также мнение Эндрю Гельмана на графиках http://www.stat.columbia.edu/…
Так что да, актуариям может быть интересно использовать R для актуарной связи, как упоминалось в http: //www.londonr.org/…
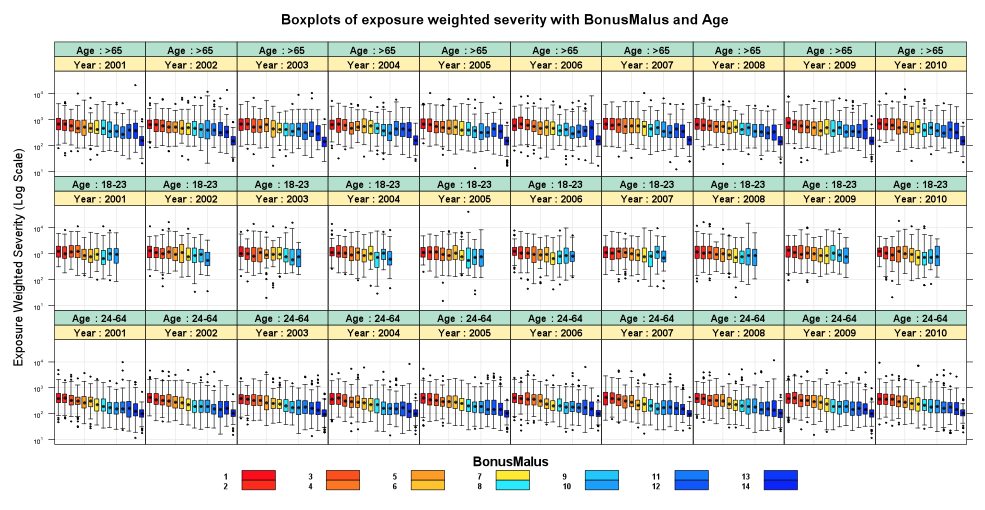
Actuarial Toolkit (см. Http: //www.actuaries.org.uk/… ) подчеркивает интерес R: « Сила языка R заключается в его функциях для статистического моделирования, анализа данных и графики; его способность читать и записывать данные из различных источников данных; а также возможность встраивать R в Excel или другие языки, такие как VBA. Благодаря тому, что SAS хорош для манипулирования данными, R — для моделирования и графического вывода ».
С 2011 года Asia Capital Reinsurance Group (ACR) использует R для решения проблем с большими данными (см . Http://www.reuters.com/… ). И Lloyd’s использует графики движения, созданные с помощью R, чтобы предоставить анализ инвесторам (как обсуждалось на http://blog.revolutionanalytics.com/… )

Много информации можно найти на http: //jeffreybreen.wordpress.com/…
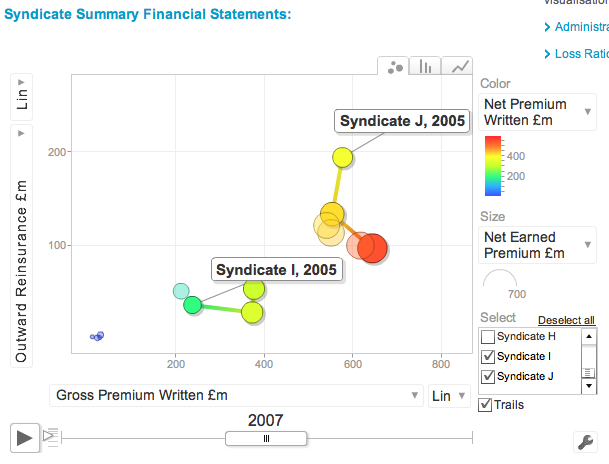
Маркус Гесманн упомянул в своем блоге много интересных графиков, используемых для актуарной отчетности, http: //lamages.blogspot.ca/…
Кроме того, R свободен. Это можно сравнить с SAS, 6000 долл. За ПК или 28 000 долл. За процессор на сервере (как указано на сайте http://en.wikipedia.org/… )
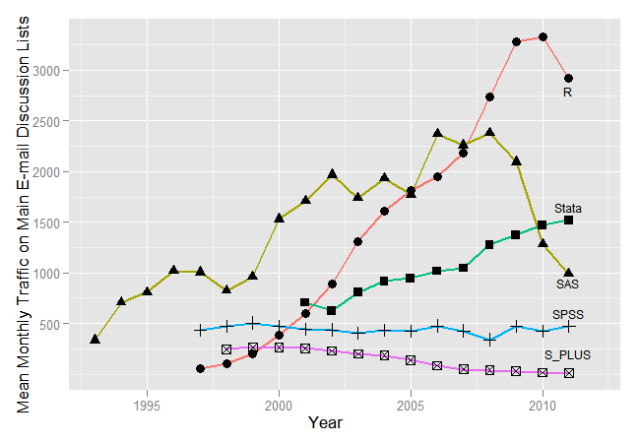
Он также становится все более и более популярным, как язык программирования. Как упоминалось в этом месяце по популярности прозрачного языка (см. Http: //lang-index.sourceforge.net/ ), R занимает 12 место. Далеко после C или Java, но до Matlab (22) или SAS (27). На StackOverFlow (см. Http: //stackoverflow.com/ ) также далеко C ++ (399 232 вхождения) или Java (348 418), но с 21 818 вхождениями он появляется до Matlab (14 580) и SAS (899). Как уже упоминалось на http: //r4stats.com/articles/popularity/, R становится все более и более популярным, на трафике обсуждения listserv.
Это, безусловно, самое популярное программное обеспечение для анализа данных, как отмечалось в опросе Rexer Analytics, в 2009 году.
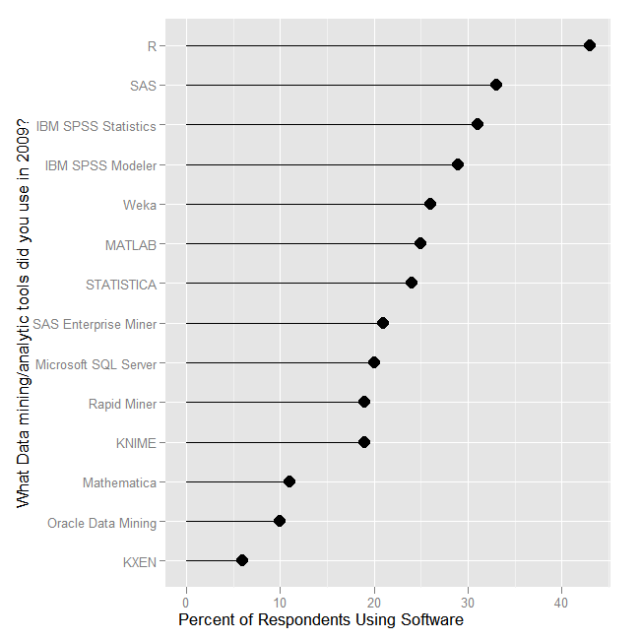
Как насчет актуариев? В опросе (см. Http: //palisade.com/… ) R не был чрезвычайно популярен.
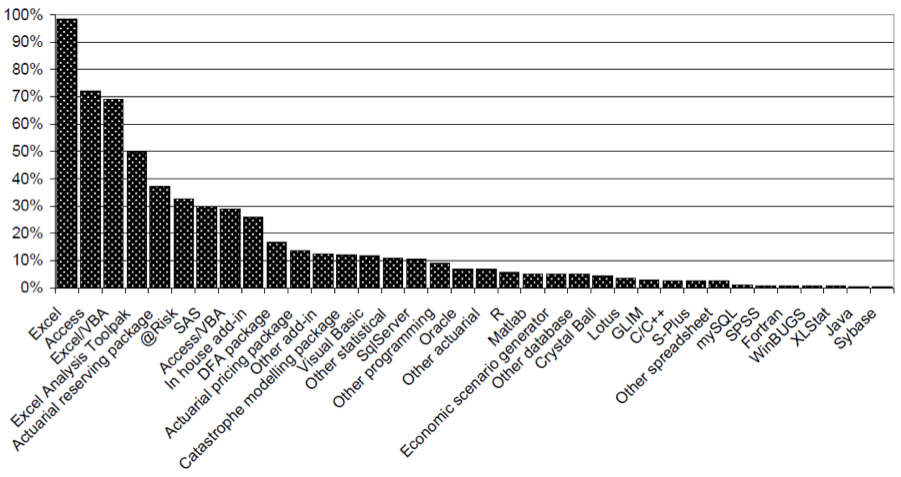
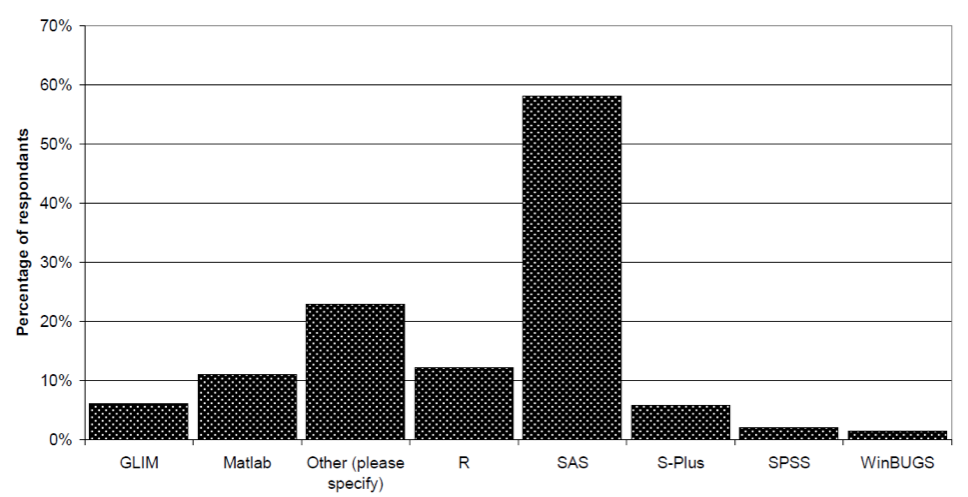
Если рассматривать только статистическое программное обеспечение, то SAS все еще далеко впереди, среди актуариев Великобритании и CAS.
Но, как отметил Майк Кинг, аналитик по количественным анализам, Bank of America, « я не могу представить себе ни одного языка программирования, в котором есть такое невероятное сообщество пользователей. Если у вас есть вопрос, вы можете быстро ответить на него лидерам в этой области. Это означает очень небольшое время простоя ». Об этом также упоминал Гленн Мейерс в «Актуарном обзоре» «Самая мощная причина использования R — это сообщество » (на http: //nytimes.com/… ). Например, http: //r-bloggers.com/ имеет вклад более 425 пользователей R.
По словам Бо Каугилла из Google « Лучшее в R — это то, что он был разработан статистиками. Хуже всего то, что R был разработан статистиками. »