Статья первоначально опубликована Тимоти Поттером .
SolrCloud — это набор функций в Apache Solr, которые обеспечивают гибкое масштабирование распределенных поисковых индексов с использованием шардинга и репликации. Одним из препятствий на пути внедрения SolrCloud было отсутствие инструментов для развертывания и управления кластером SolrCloud. В этой статье я представлю Solr Scale Toolkit, проект с открытым исходным кодом, спонсируемый LucidWorks ( www.lucidworks.com ), который предоставляет инструменты и руководство по развертыванию и управлению SolrCloud на облачных платформах, таких как Amazon EC2. В последнем разделе я использую инструментарий для запуска некоторых тестов производительности по сравнению с Solr 4.8.1, чтобы увидеть, насколько действительно «масштабируемым» является Solr.
мотивация
Когда вы загружаете последнюю версию Solr (4.8.1 является последней на момент написания этой статьи), на самом деле довольно легко запустить кластер SolrCloud на вашей локальной рабочей станции. Solr позволяет запустить встроенный экземпляр ZooKeeper для включения «облачного» режима с помощью простого параметра командной строки: -DzkRun. Если вы еще этого не сделали, я рекомендую следовать инструкциям, приведенным в Справочном руководстве Solr: https://cwiki.apache.org/confluence/display/solr/SolrCloud
После того, как вы поработали над «из коробки» с SolrCloud, вы быстро поняли, что вам нужны инструменты, которые помогут автоматизировать задачи развертывания и администрирования системы на нескольких серверах. Более того, после того, как вы настроили хорошо настроенный кластер, существуют текущие задачи по обслуживанию системы, которые также должны быть автоматизированы, такие как циклический перезапуск, резервное копирование вне сайта или просто попытка найти сообщение об ошибке в нескольких файлах журналов в разных сервера.
До сих пор большинству организаций приходилось интегрировать операции SolrCloud в существующую среду, используя такие инструменты, как Chef или Puppet. Хотя эти подходы по-прежнему актуальны, Solr Scale Toolkit предоставляет простое решение на основе Python, которое легко установить и использовать для управления SolrCloud. В остальных разделах этого поста я расскажу вам о некоторых ключевых функциях инструментария и призываю вас следовать им. Для начала есть небольшая настройка, необходимая для использования инструментария.
Установка и настройка
Есть три основных шага, чтобы начать использовать Solr Scale Toolkit на вашей локальной рабочей станции:
-
Настройте учетную запись Amazon Web Services (AWS) и настройте пару ключей для доступа к экземплярам из SSH
-
Установить зависимости Python
-
Клонируйте Solr Scale Toolkit из github и постройте проект, используя Maven.
Настройка учетной записи Amazon
Во-первых, вам понадобится учетная запись Amazon Web Services. Если у вас нет учетной записи Amazon AWS, ее нужно настроить перед использованием Solr Scale Toolkit, см. Http://docs.aws.amazon.com/AWSEC2/latest/UserGuide/get-set- вверх по-амазонки-ec2.html
Совет: Solr Scale Toolkit пока работает только с Linux в Amazon Web Services, но мы планируем поддерживать других облачных провайдеров в ближайшем будущем с помощью проекта Apache libcloud. https://libcloud.apache.org/
Инструментарий требует несколько задач по настройке, которые вы можете выполнить в консоли AWS. Во-первых, вам нужно настроить группу безопасности с именем solr-scale-tk. Как минимум вы должны разрешить трафик TCP к портам: 8983-8985, SSH (22) и 2181 (ZooKeeper). Конечно, вы обязаны проверить конфигурацию безопасности вашего кластера и соответствующим образом заблокировать ее. Начальные настройки просто помогут вам начать использовать инструментарий.
Вам также необходимо создать пару ключей с именем solr-scale-tk. После загрузки файла пары ключей (solr-scale-tk.pem) сохраните его в ~ / .ssh / и измените разрешения, используя:
chmod 600 ~/.ssh/solr-scale-tk.pem
Зависимости Python
Вам понадобится Python 2.7.x, работающий на вашей локальной рабочей станции. Чтобы проверить версию Python, которую вы используете, откройте оболочку командной строки и выполните: python –version. На моем Mac вывод:
[~]$ python --version Python 2.7.2
Если у вас нет Python, обратитесь к этой странице за помощью в настройке вашей конкретной операционной системы. https://www.python.org/download/ . Не беспокойтесь, если вы не знаете Python, поскольку для работы с инструментарием не требуются знания программирования.
Solr Scale Toolkit зависит от Fabric, который представляет собой инструмент на основе Python, который оптимизирует использование SSH для развертывания приложений или задач системного администрирования. Пожалуйста, обратитесь к http://fabric.readthedocs.org/en/1.8/#installation за инструкциями по установке Fabric.
После установки Fabric вам необходимо установить библиотеку Python boto для работы с Amazon Web Services. В большинстве случаев вы можете сделать это с помощью pip install boto, но, пожалуйста, обратитесь к https://github.com/boto/boto для получения дополнительной информации об установке boto. После установки вам нужно создать файл конфигурации ~ / .boto для настройки доступа к Amazon и секретных ключей.
cat ~/.boto
[Credentials]
aws_access_key_id = YOUR_ACCESS_KEY_HERE
aws_secret_access_key = YOUR_SECRET_KEY_HERE
Для получения дополнительной информации о ключах доступа Amazon см. Http://docs.aws.amazon.com/AWSSimpleQueueService/latest/SQSGettingStartedGuide/AWSCredentials.html.
Затем клонируйте проект pysolr из github и установите его, используя:
git clone https://github.com/toastdriven/pysolr.git
cd pysolr
sudo python setup.py install
Solr Scale Toolkit использует pysolr для выполнения базовых операций, таких как запросы, и фиксацию с использованием Solr HTTP API. Если у вас не установлен git, перейдите по ссылке : https://help.github.com/articles/set-up-git.
Клонируйте проект github из набора инструментов Solr Scale
Теперь, когда вы правильно настроили свою учетную запись Amazon и зависимости Python, вы можете настроить Solr Scale Toolkit.
Клонируйте проект из github: https://github.com/LucidWorks/solr-scale-tk.git.
После клонирования перейдите в каталог solr-scale-tk и выполните: fab -l
Вы должны увидеть список доступных команд Fabric, предоставляемых инструментарием.
Создайте JAR-файл Solr Scale Toolkit, используя: mvn clean package.
Если у вас не установлен Maven, см. Http://maven.apache.org/download.cgi.
Уф! Теперь вы готовы использовать Solr Scale Toolkit для развертывания и управления кластером SolrCloud.
Запуск экземпляров
Одной из наиболее важных задач при планировании использования SolrCloud является определение количества серверов, необходимых для поддержки ваших индексов. К сожалению, не существует простой формулы для определения этого, потому что здесь задействовано слишком много переменных. Однако большинство опытных пользователей SolrCloud сходятся во мнении, что единственный способ определить вычислительные ресурсы для вашего производственного кластера — это протестировать свои собственные данные и запросы. Итак, для этого блога я собираюсь продемонстрировать, как обеспечить вычислительные ресурсы для небольшого кластера, но вы должны знать, что тот же процесс работает для больших кластеров. Фактически, этот инструментарий был разработан для проведения масштабного тестирования SolrCloud. Я оставляю читателю в качестве упражнения самостоятельное планирование размера кластера.
Для этого поста давайте планируем запустить кластер SolrCloud для двух экземпляров m3.xlarge с тремя экземплярами m3.medium для размещения ансамбля ZooKeeper. Мы планируем запустить два узла Solr на каждый экземпляр, что даст нам всего 4 узла Solr в нашем кластере. Каждый узел Solr будет иметь выделенный SSD.
Следующая диаграмма изображает наш запланированный кластер.
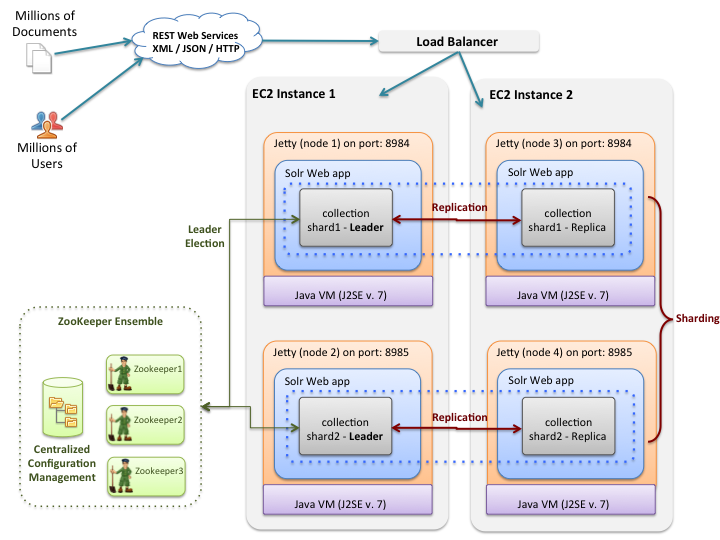
Одним из ключевых конструктивных решений, принятых на ранних этапах разработки инструментария, было использование настраиваемого AMI. В настоящее время AMI основан на RedHat Enterprise Linux 6.4. Пользовательский AMI имеет Java, Solr 4.8.1, ZooKeeper 3.4.6, а также несколько дополнительных установленных служб, таких как collectd. Идея использования пользовательского AMI заключается в том, чтобы при каждом запуске нового экземпляра не приходилось настраивать основные службы, такие как Java. Если вы не фанат RedHat, не расстраивайтесь, так как мы планируем поддерживать дополнительные версии Linux, такие как Debian, в ближайшем будущем.
При подготовке пользователя действительно нужно беспокоиться только о типе экземпляра и количестве экземпляров для запуска. Однако за кулисами возникает ряд других проблем, таких как настройка сопоставлений блочных устройств и последующее подключение всех доступных хранилищ экземпляров. Не беспокойтесь, если вы не много знаете о отображениях блочных устройств, так как инструментарий обрабатывает все детали за вас. Например, для экземпляров m3.xlarge доступны два хранилища экземпляров SSD по 40 ГБ; Инструментарий создаст файловую систему ext3 на каждом диске и смонтирует их в / vol0 и / vol1 соответственно.
Ансамбль ZooKeeper
ZooKeeper — это служба распределенной координации, которая обеспечивает централизованную настройку, управление состоянием кластера и выбор лидера для SolrCloud. На производстве вы должны запустить как минимум три сервера ZooKeeper в кластере, называемом ансамблем, для достижения высокой доступности. Для начала давайте настроим наш ансамбль ZooKeeper на три экземпляра m3.medium, используя:
fab new_zk_ensemble:zk1
Главное, что должно выделиться из этой команды, — это параметр zk1, который представляет собой идентификатор кластера, который я даю этой группе из трех экземпляров m3.medium. Инструментарий отрабатывает концепцию именованного «кластера», поэтому вам не нужно беспокоиться об именах хостов или IP-адресах; фреймворк знает, как искать хосты для конкретного кластера. За кулисами здесь используются теги Amazon для поиска экземпляров и сбора имен их хостов.
Вы можете быть удивлены, почему я не указал тип и количество экземпляров. Давайте посмотрим на документацию для команды new_zk_ensemble, используя:
fab -d new_zk_ensemble
Displaying detailed information for task 'new_zk_ensemble':
Configures, starts, and checks the health of a ZooKeeper
ensemble on one or more nodes in a cluster.
Arg Usage:
cluster (str): Cluster ID used to identify the ZooKeeper ensemble created by this command.
n (int, optional): Size of the cluster.
instance_type (str, optional):
Returns:
zkHosts: List of ZooKeeper hosts for the ensemble.
Arguments: cluster, n=3, instance_type='m3.medium'
Как видно из этой документации, значениями по умолчанию для типа экземпляра и счетчика являются m3.medium и 3 соответственно. Вы также должны помнить, что вы можете выполнить fab -d <command>, чтобы получить информацию об использовании любой команды в наборе инструментов.
За кулисами команда new_zk_ensemble выполняет следующие операции:
-
Предоставьте три экземпляра m3.medium в EC2, используя специальный AMI Solr Scale Toolkit. Инструментарий проверяет SSH-подключение к каждому экземпляру и помечает каждый экземпляр тегом cluster = zk1.
-
Настраивает ансамбль ZooKeeper с 3 узлами с клиентским портом 2181. Каждый сервер ZooKeeper настроен на использование хранилища экземпляров, смонтированного в / vol0. Инструментарий проверяет работоспособность ZooKeeper перед тем, как объявить об успехе.
Выполнение команды new_zk_ensemble эквивалентно выполнению следующих двух команд Fabric:
fab new_ec2_instances:zk1,n=3,instance_type=m3.medium
fab setup_zk_ensemble:zk1
Когда вы выполняете одну из команд Fabric инструментария, возникает ряд ключевых понятий, в том числе:
-
Многое из того, что делает инструментарий, — это изящная обработка ожиданий и проверка статуса, поэтому вы увидите несколько сообщений об ожидании и проверке различных результатов.
-
По большей части параметры имеют разумные значения по умолчанию. Конечно, такие параметры, как количество запускаемых узлов, не имеют разумного значения по умолчанию, поэтому обычно вам нужно указать параметры типа размеров.
-
Любые команды, начинающиеся с префикса «new_», подразумевают, что они предоставляют узлы в EC2, в то время как команды с префиксом «setup_» предполагают, что узлы уже подготовлены.
В целом, инструментарий разбивает задачи на 2 этапа:
-
предоставление экземпляров нашего AMI, и
-
настройка, запуск и проверка сервисов на предоставленных экземплярах
Этот двухэтапный процесс подразумевает, что, если шаг # 1 завершается успешно, но ошибка # 2 возникает в том, что узлы уже были подготовлены, и что вы не должны повторно предоставлять узлы. Давайте посмотрим на пример, чтобы убедиться, что это понятно.
Представьте, что вы получили ошибку при запуске команды new_zk_ensemble. Во-первых, вы должны принять к сведению, были ли предоставлены узлы. Вы увидите зеленое информационное сообщение об этом в консоли, например:
** 3 экземпляра EC2 были предоставлены **
Если вы видите подобное сообщение, то вы знаете, что шаг 1 был успешным, и вам нужно только позаботиться об исправлении проблемы и повторно запустить шаг 2, который в нашем примере будет запускать действие установки. Однако, как правило, безопасно просто повторно запустить команду (например, new_zk_ensemble) с тем же именем кластера, что и платформа, заметит, что узлы уже подготовлены, и просто подскажет вам, следует ли их повторно использовать. В большинстве случаев ответ — да.
Теперь, когда у нас работает ансамбль ZooKeeper, мы можем развернуть новый кластер SolrCloud.
Запустить кластер SolrCloud
Как обсуждалось выше, мы собираемся запустить новый кластер SolrCloud на двух экземплярах m3.xlarge и запустить два узла Solr на экземпляр. Каждый узел Solr должен использовать одно из хранилищ экземпляров SSD, предоставленных для экземпляров m3.xlarge.
Прежде чем запускать узлы Solr, давайте рассмотрим некоторые важные термины, используемые в Solr Scale Toolkit:
-
Экземпляр (он же машина): виртуальная машина, работающая в центре обработки данных облачного провайдера, таком как EC2
-
Узел : процесс JVM, связанный с конкретным портом в экземпляре; размещает веб-приложение Solr, работающее в Jetty
-
Коллекция : поисковый индекс, распределенный по нескольким узлам; каждая коллекция имеет имя, количество осколков и коэффициент репликации
-
Коэффициент репликации : количество копий документа в собрании, например, коэффициент репликации 3 для собрания с 100M документов означает, что всего 300M документов во всех репликах.
-
Осколок : логический фрагмент коллекции; у каждого шарда есть имя, диапазон хэша, лидер и фактор репликации. Документы назначаются одному и только одному фрагменту в коллекции с использованием стратегии маршрутизации документов.
-
Реплика : индекс Solr, в котором находится копия сегмента в коллекции; За кулисами каждая реплика реализована в виде ядра Solr. Пример: коллекция с 20 шардами и коэффициентом репликации 2 в кластере из 10 узлов приведет к 4 ядрам Solr на узел.
-
Лидер : реплика в осколке, которая принимает специальные обязанности, необходимые для поддержки распределенной индексации в Solr; каждый шард имеет одного и только одного лидера в любое время, и лидеры выбираются автоматически с помощью ZooKeeper. В общем, вам не важно, какие реплики выбраны в качестве лидера.
На следующей диаграмме показано, как каждый экземпляр в Amazon будет настроен с помощью Solr Scale Toolkit:
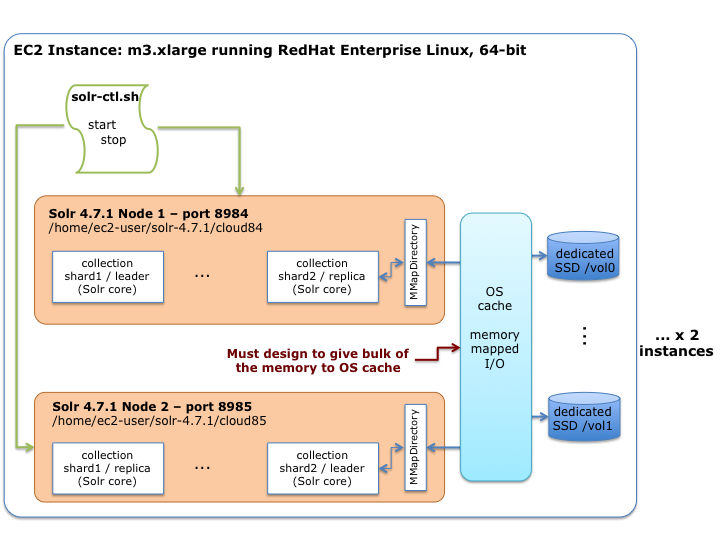
Как показано на схеме, на портах 8984 и 8985 выполняются два процесса Solr JVM. Каждый процесс имеет выделенный SSD-накопитель емкостью 40 ГБ. Индексы настроены на использование реализации MMapDirectory, которая использует отображенный в памяти ввод-вывод для загрузки структур данных индекса в кэш ОС. Каждый процесс JVM настроен с консервативной настройкой максимальной кучи, чтобы выделить как можно больше памяти для кэша ОС.
Давайте запустим новый кластер SolrCloud с именем cloud1, используя:
fab new_solrcloud:cloud1,n=2,zk=zk1,nodesPerHost=2,instance_type=m3.xlarge
Большая часть этого должна быть довольно очевидна. Zk = zk1 сообщает узлам Solr адрес ансамбля ZooKeeper; Напомним, что мы назвали ансамбль: zk1.
Если все пройдет хорошо, вы увидите сообщения, подобные следующим:
4 сервера Solr работают! Успешно запущен новый кластер SolrCloud cloud1; посетите: http: // <хост >: 8984 / solr / # /
Одним из проектных решений в наборе инструментов было использование сценария BASH для управления каждым узлом Solr в экземпляре. Другими словами, команды Fabric делегируют часть работы по управлению Solr локальному BASH-скрипту в каждом экземпляре, см. /Home/ec2-user/cloud/solr-ctl.sh.
Основная обязанность сценария solr-ctl.sh — запустить Solr с правильными параметрами JVM и системными свойствами. Вот пример команды start, используемой для запуска узла Solr в облачном режиме; не волнуйтесь, я не ожидаю, что вы будете заботиться о деталях этой команды, я просто включил ее здесь, чтобы дать вам представление о том, что делает сценарий solr-ctl.sh:
/home/ec2-user/jdk1.7.0_25/bin/java -Xss256k -server -XX:+UseG1GC -XX:MaxGCPauseMillis=5000 -XX:+HeapDumpOnOutOfMemoryError -DzkClientTimeout=5000 -verbose:gc -XX:+PrintHeapAtGC -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintTenuringDistribution -Xms3g -Xmx3g -XX:MaxPermSize=512m -XX:PermSize=256m -Djava.net.preferIPv4Stack=true -Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.local.only=false -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.authenticate=false -Djava.rmi.server.hostname=ec2-??-##-??-##.compute-1.amazonaws.com -Dcom.sun.management.jmxremote.port=1084 -Dcom.sun.management.jmxremote.rmi.port=1084 -Xloggc:/home/ec2-user/solr-4.7.1/cloud84/logs/gc.log -XX:OnOutOfMemoryError=/home/ec2-user/cloud/oom_solr.sh 84 %p -Dlog4j.debug -Dhost=ec2-??-##-??-##.compute-1.amazonaws.com -Dlog4j.configuration=file:////home/ec2-user/cloud/log4j.properties -DzkHost=ec2-??-##-??-##.compute-1.amazonaws.com:2181,...:2181/cloud1 -DSTOP.PORT=7984 -DSTOP.KEY=key -Djetty.port=8984 -Dsolr.solr.home=/home/ec2-user/solr-4.7.1/cloud84/solr -Duser.timezone=UTC -jar start.jar
Надеюсь, из этой команды должно быть ясно, что инструментарий экономит вам некоторую работу, запуская Solr, используя передовые практики, основанные на опциях, изученные сообществом Solr. Например, обратите внимание, что эта команда регистрирует скрипт-обработчик OutOfMemory, который гарантирует, что процесс будет убит, чтобы у вас не было узлов-зомби в вашем кластере.
Мы вскоре приступим к созданию коллекции и индексации некоторых документов, но сначала я бы хотел охватить дополнительную, но очень полезную функцию Solr Scale Toolkit: интеграцию с SiLK для мониторинга и агрегирования журналов.
Мета-узел
Каждый узел Solr в кластере настроен для ведения журнала в logs / solr.log. Однако было бы хорошо, если бы все предупреждения и сообщения об ошибках со всех узлов собирались в одном месте, чтобы помочь нашим системным администраторам выявлять и устранять проблемы в кластере. Кроме того, вы, вероятно, хотите внимательно следить за ключевыми показателями системы, такими как загрузка процессора, сетевой ввод-вывод и память. Инструментарий обеспечивает поддержку для этих общих требований путем интеграции с решением SiLK LucidWorks, см .: http://www.lucidworks.com/lucidworks-silk/
SiLK: Solr интегрирован с Logstash и Kibana
SiLK дает пользователям возможность выполнять специализированный поиск и анализ огромных объемов многоструктурных данных и данных временных рядов. Пользователи могут быстро преобразовывать свои выводы в визуализации и информационные панели, которые легко могут быть использованы в рамках всей организации.
Следующая диаграмма показывает, как SiLK интегрируется в Solr Scale Toolkit:
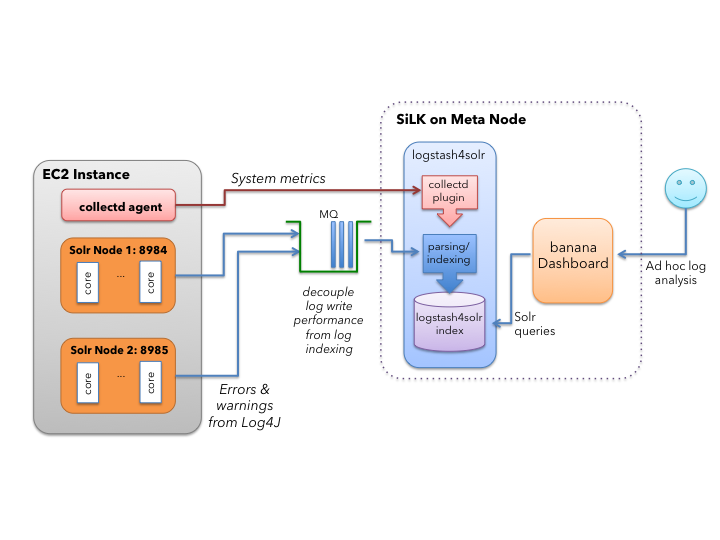
Если посмотреть на диаграмму слева направо, каждый экземпляр EC2 содержит один или несколько узлов Solr. Log4J настроен на отправку всех сообщений журнала серьезности предупреждения или выше в SiLK с помощью приложения AMQP Log4J. Кроме того, каждый экземпляр EC2 запускает клиентский агент collectd для сбора системных показателей (например, загрузки ЦП) и отправки их плагину collectd в Logstash4Solr. Сообщения журнала от наших узлов SolrCloud и метрики системы индексируются в Solr на мета-узле. Каждый документ имеет поле event_timestamp для поддержки анализа временных рядов. Вы можете создать классную панель инструментов, используя банановый интерфейс.
Чтобы запустить метаузел, сделайте следующее:
fab new_meta_node:meta1
Команда запишет URL панели банановой панели, например:
Пользовательский интерфейс Banana @ http: //ec2-##-##-###-###.compute-1.amazonaws.com: 8983 / banana
После того, как мета-узел запущен, вам нужно указать узлам SolrCloud начать отправку сообщений журнала и собранных метрик в SiLK, используя:
fab attach_to_meta_node:cloud1,meta1
Перейдите к панели бананов на мета-узле, и вы должны начать видеть собранные метрики (загрузка ЦП) для ваших узлов Solr.
Собираем все вместе
Итак, теперь у нас есть четырехузловой кластер SolrCloud, работающий в двух экземплярах EC2, высокодоступный ансамбль ZooKeeper и мета-узел, выполняющий SiLK, давайте посмотрим на все это в действии, создав новую коллекцию, проиндексировав некоторые документы и выполнив некоторые запросы.
Во-первых, давайте рассмотрим все экземпляры, которые мы запускаем, выполнив: fab mine
Это должно дать хороший отчет о том, какие экземпляры запущены в каких кластерах, например:
Finding instances tagged with username: thelabdude
*** user: thelabdude ***
{
"meta1": [
"ec2-54-84-??-??.compute-1.amazonaws.com: i-63c15040 (m3.large running for 0:44:05)"
],
"zk1": [
"ec2-54-86-??-??.compute-1.amazonaws.com: i-a535a386 (m3.medium running for 2:27:51)",
"ec2-54-86-??-??.compute-1.amazonaws.com: i-a435a387 (m3.medium running for 2:27:51)",
"ec2-54-86-??-??.compute-1.amazonaws.com: i-a635a385 (m3.medium running for 2:27:51)"
],
"cloud1": [
"ec2-54-84-??-??.compute-1.amazonaws.com: i-acdf4e8f (m3.xlarge running for 0:48:19)",
"ec2-54-85-??-??.compute-1.amazonaws.com: i-abdf4e88 (m3.xlarge running for 0:48:19)"
]
}
За кулисами экземпляры помечаются вашим локальным именем пользователя, чтобы вы могли отслеживать, какие экземпляры вы используете. Если это общая учетная запись, вы также можете сделать fab mine: all, чтобы увидеть все запущенные экземпляры для всех пользователей в учетной записи.
Теперь давайте перейдем к созданию коллекции с использованием:
fab new_collection:cloud1,example1,rf=2,shards=2
Это создаст новую коллекцию с именем example1 с 2 осколками и коэффициентом репликации 2. В этот момент вы можете индексировать свои собственные данные в коллекцию или, чтобы упростить задачу, в набор инструментов входит пример клиентского приложения SolrJ, индексирующего синтетические документы.
fab index_docs:cloud1,example1,20000
За кулисами эта команда использует файл solr-scale-tk.jar для индексации 20К синтетических документов в SolrCloud. Это приложение служит хорошим примером того, как использовать класс CloudSolrServer в SolrJ для создания клиентских приложений для SolrCloud. Утилита командной строки также служит отправной точкой для создания других клиентских инструментов на основе Java для SolrCloud, особенно когда клиентскому приложению требуется доступ к метаданным кластера в ZooKeeper. Если вам интересно, как это работает, взгляните на: https://github.com/LucidWorks/solr-scale-tk/blob/master/src/main/java/com/lucidworks/SolrCloudTools.java
Вот снимок экрана панели бананов после индексации.
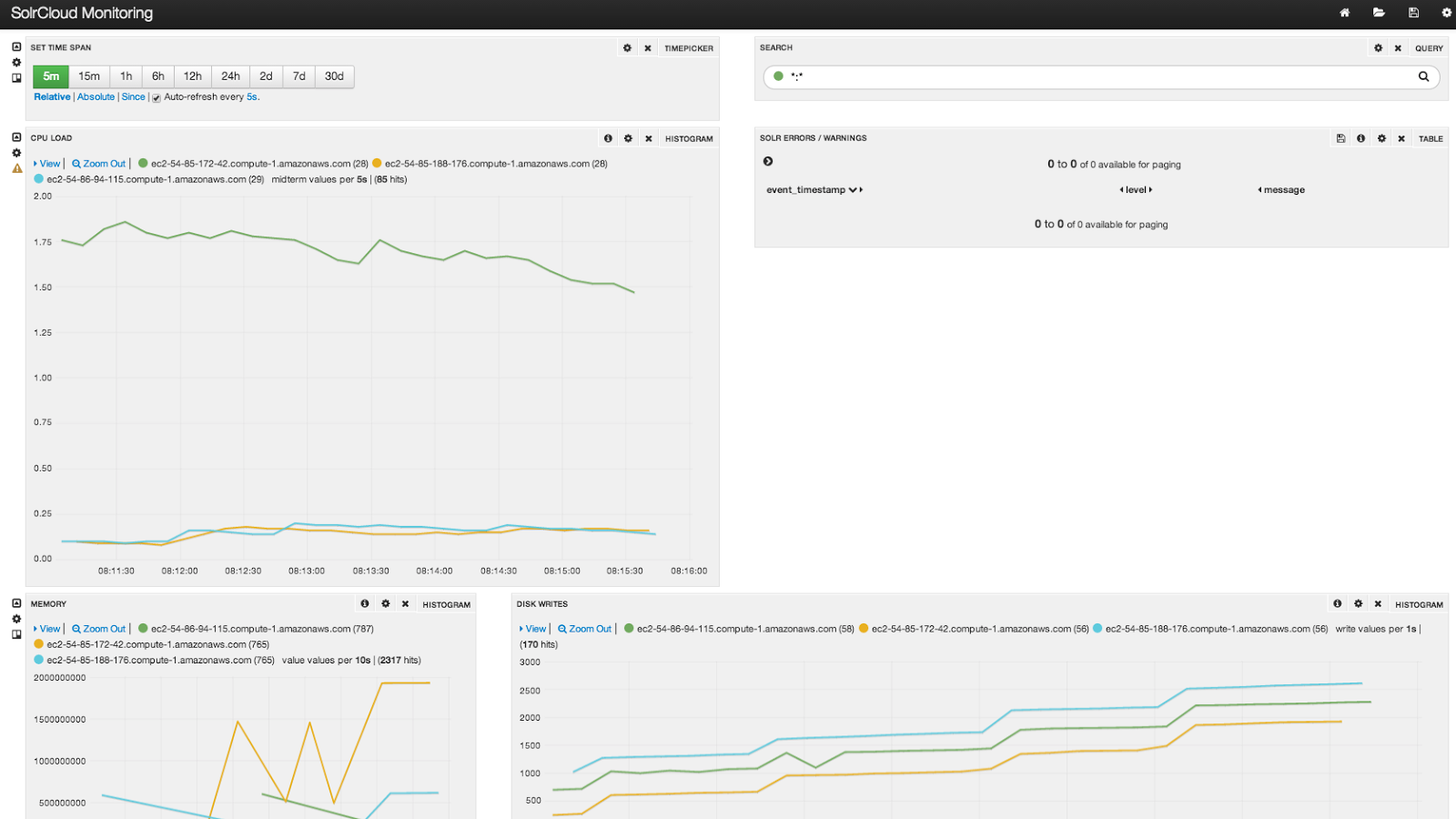
Узел с более высокой загрузкой ЦП является мета-узлом, на котором размещаются сервер collectd, SiLK и rabbitmq. Конечно, это всего лишь пример простой банановой панели инструментов; Я призываю вас пройти полный тур по SiLK, посетив: http://www.lucidworks.com/lucidworks-silk/
Другие задачи
После того, как ваш кластер запущен и работает, инструментарий также помогает вам выполнять рутинные задачи обслуживания. Давайте рассмотрим некоторые из них, чтобы вы получили представление о том, что доступно. Для получения полного списка поддерживаемых команд выполните: fab -l.
Разверните каталог конфигурации в ZooKeeper
Из коробки пример каталога конфигурации Solr (example / solr / collection1 / conf) загружается в ZooKeeper с использованием имени конфигурации «cloud». Тем не менее, довольно часто вы будете иметь свои собственные файлы конфигурации и настроек Solr. Инструментарий предоставляет команду для загрузки каталога конфигурации с рабочей станции вашего местоположения в ZooKeeper. Например, если каталог конфигурации, который я хочу загрузить, находится в / tmp / solr_conf, то я могу сделать:
fab deploy_config: cloud1, / tmp / solr_conf, foo
Третий аргумент — это имя конфигурации в ZooKeeper. Вы можете использовать это имя при создании новой коллекции, например:
fab new_collection: cloud1, использует_foo, осколки = 2, rf = 2, conf = foo
Следует также отметить шаблон с командами Fabric — все они используют идентификатор кластера в качестве первого параметра, например «cloud1».
Сборка Solr локально и патч удаленного
Прежде чем закончить, давайте рассмотрим еще одну полезную задачу по исправлению ваших серверов Solr. Представьте, что вы применили исправление для проблемы к локальной сборке Solr 4.8.1, и теперь вам нужно опубликовать исправление в своем кластере в EC2. Предположим, что локальная сборка Solr находится в / tmp / local-solr-build. Просто сделайте:
fab patch_jars: cloud1, / tmp / local-solr-build / solr
Это позволит загрузить файлы core и solrj jar с локальной рабочей станции на первый узел в кластере, а затем скопировать их на все остальные узлы, что предпочтительнее, чем попытка загрузить их на все серверы, поскольку копирование с одного сервера на другой в Amazon очень быстро. После обновления JAR выполняется повторный перезапуск, чтобы применить обновление.
Давайте уже посмотрим на некоторые масштабы!
Наконец, давайте включим инструментарий, чтобы увидеть, насколько хорошо Solr работает и масштабируется. При построении теста производительности / масштабируемости необходимо учитывать три момента. Во-первых, нам нужно клиентское приложение, которое может направлять достаточный трафик в Solr. Слишком часто я вижу пользователей, жалующихся на производительность Solr, когда на самом деле их клиентское приложение не обеспечивает достаточную нагрузку, а серверы Solr дремлет в фоновом режиме. Для этого я собираюсь использовать Amazon Elastic MapReduce, который позволяет мне наращивать столько клиентских приложений, сколько я хочу.
Во-вторых, мне нужен набор данных, который является несколько реалистичным. Для этого я использовал каркас генератора данных PigMix для создания 130M синтетических документов размером около 1 КБ, содержащих произвольно сгенерированные числовые поля, поля даты / времени, логические, строковые и английские текстовые поля; текстовые поля на английском языке следуют за распределением Zipf . Набор данных хранится в S3, поэтому я могу загрузить его по требованию из Elastic MapReduce и запустить тест производительности индексации. Генерация текста, который следует за распределением Zipf, на самом деле довольно медленна для целей бенчмаркинга, поэтому предварительное вычисление данных заблаговременно означает, что на наши тесты производительности не влияют затраты на генерацию данных.
В-третьих, мне нужно убедиться, что сетевой канал в Solr из Elastic MapReduce не ограничен. Другими словами, я не хочу, чтобы Solr ожидал ввода в сети при индексации. Для этого я решил использовать типы экземпляров r3.2xlarge с включенной расширенной сетью и в группе размещения EC2; r3.2. Большие экземпляры обеспечивают высокую пропускную способность ввода / вывода (см. http://aws.amazon.com/about-aws/whats-new/2014/04/10/r3-announcing-the-next-generation-of-amazon -ec2-memory-optimized-instances / ). Со стороны Hadoop производительность сети экземпляров m1.xlarge довольно хорошая (см .: http://flux7.com/blogs/benchmarks/benchmarking-network-performance-of-m1-and-m3-instances-using-iperf -инструмент / ). Все экземпляры развернуты в зоне доступности us-east-1b.
Что касается получения документов в Solr из Hadoop, я использую простой сценарий Pig (доступный в проекте solr-scale-toolkit), который пишет в Solr с помощью SolrStoreFunc из LucidWorks. Набор данных общедоступен на S3 от: s3: // solr-scale-tk / pig / output / syn130m. Чтобы контролировать, сколько клиентов SolrJ отправляют документы в Solr, я принудительно сокращаю, используя предложение Pig ORDER BY. В общем, при индексации из Hadoop в Solr вы хотите выполнить индексацию в редукторах, чтобы вы могли контролировать параллелизм. Может быть запущено несколько тысяч задач карты, и вы, как правило, не хотите оплачивать стоимость подключения SolrJ к ZooKeeper с каждого картографа.
Для начала я хотел получить представление о производительности первичного индексирования без репликации, поэтому я внес индекс в коллекцию 10 × 1 на 10 узлах, что заняло чуть более 31 минуты или 68 783 документа в секунду с использованием 32 редукторов и 1000 пакетов разного размера документов. Затем я увеличил число редукторов до 48 с размером пакета 1500, что привело к 73 780 документам в секунду. В целом, активность GC оставалась стабильной, и процессоры все еще имели достаточно возможностей для поддержки поиска при индексации, см. Снимок экрана из VisualVM ниже. (ПРИМЕЧАНИЕ: большое падение размера кучи, вероятно, осталось от предыдущего теста, интересные биты находятся справа от падения на этом графике).
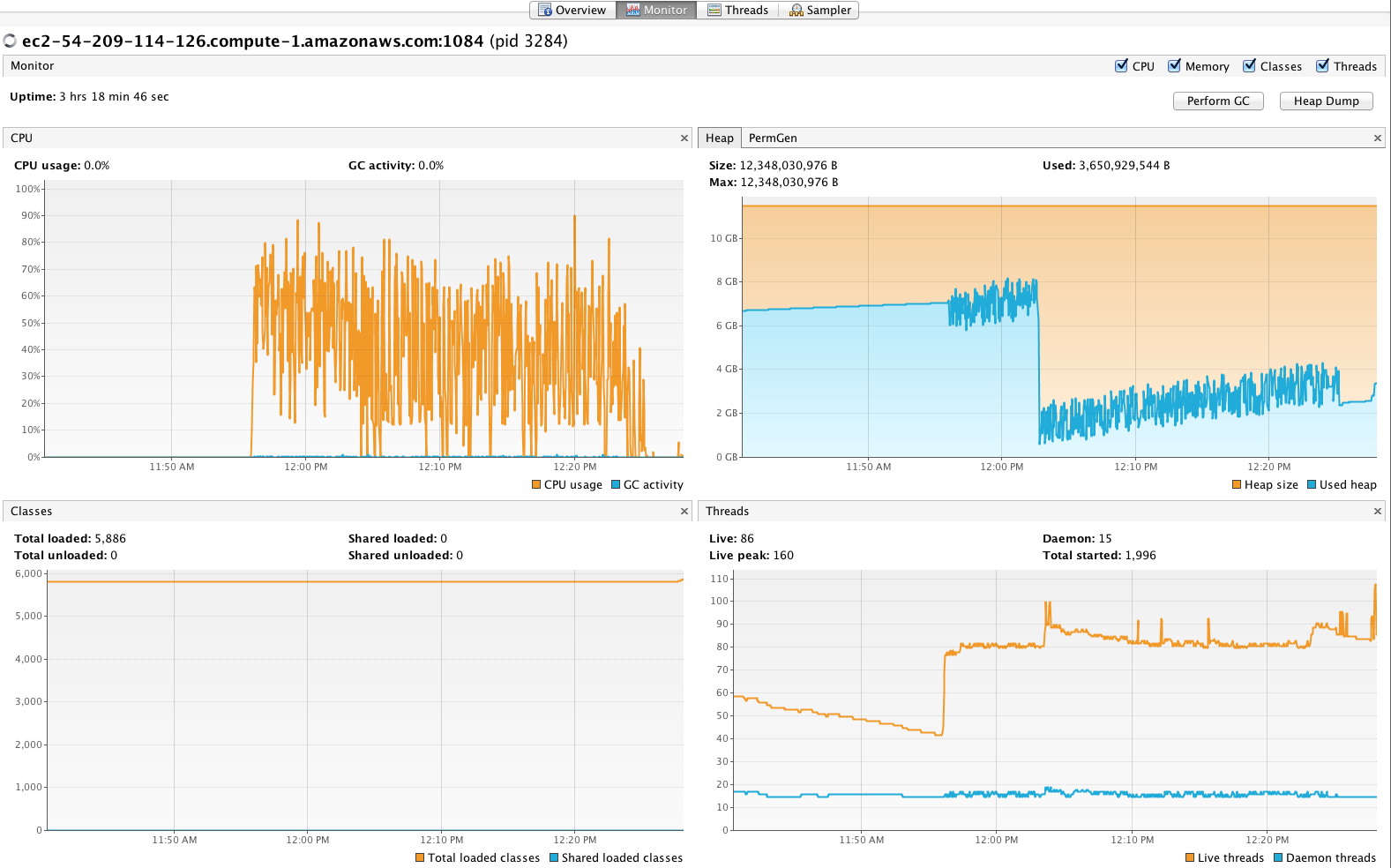 Снимок экрана из VisualVM при выполнении теста 10 × 1 с 48 редукторами.
Снимок экрана из VisualVM при выполнении теста 10 × 1 с 48 редукторами.
Затем я хотел понять влияние репликации, поэтому я выполнил те же тесты, что и раньше, с набором 10 × 2 (все еще на 10 узлах), который достигал в среднем 33 325 документов в секунду. Поскольку каждый узел теперь содержит 2 ядра Solr вместо одного, загрузка ЦП намного выше (см. График ниже). Вероятно, что 48 редукторов индексации — это слишком много для этой конфигурации, так как вы не ожидаете, что репликация вызовет такое большое замедление. Поэтому я попытался использовать только 34 редуктора и получил 34 881 документ в секунду, при этом загрузка ЦП avg / max была меньше для обработки запросов. Урок здесь не переусердствовать на стороне индексации, особенно при использовании репликации; необходимы дополнительные тесты, чтобы определить оптимальное количество индексирующих клиентов и размер пакета.
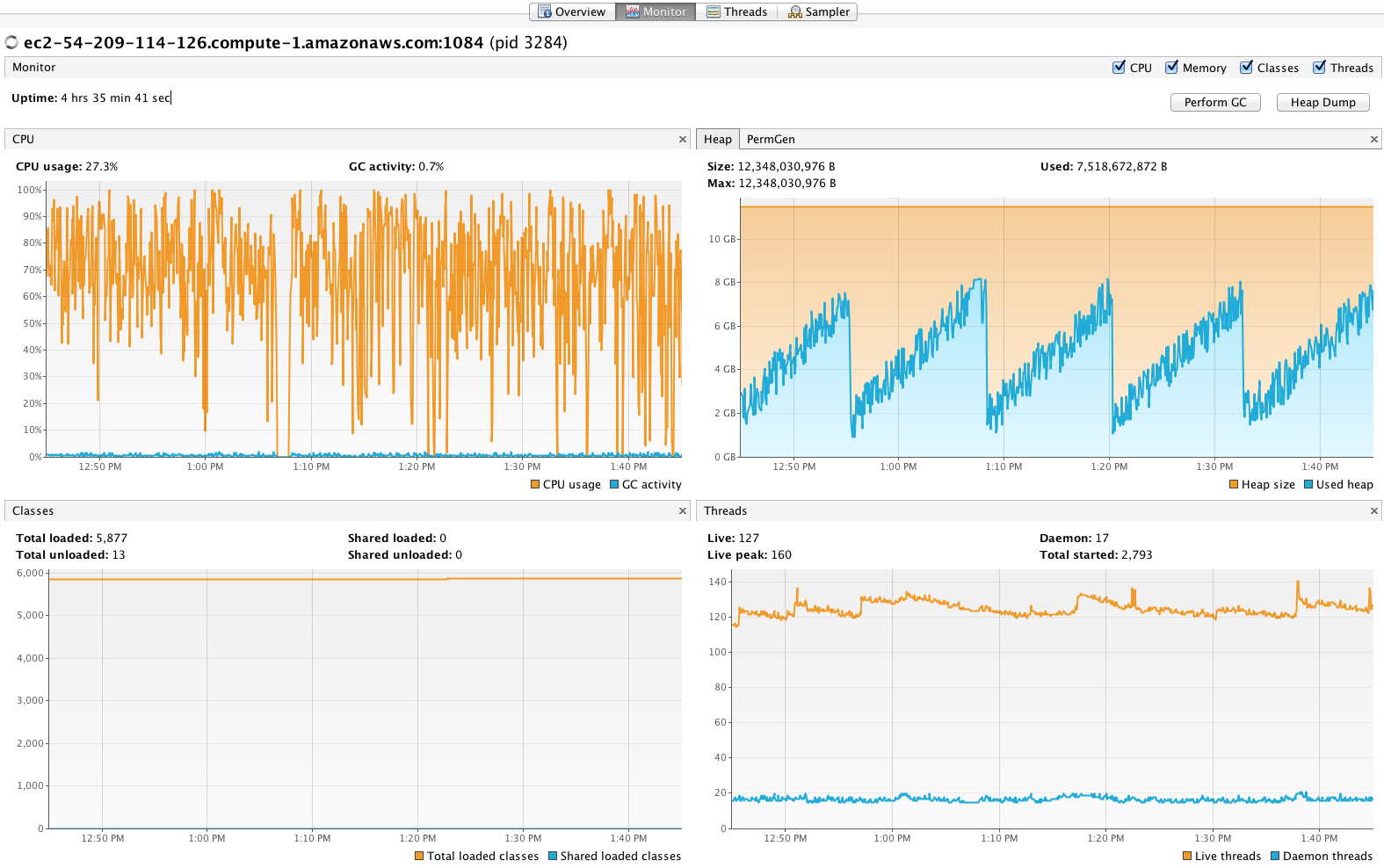
Снимок экрана при индексировании 10 × 2 с 48 редукторами; ср. и максимальная загрузка процессора слишком высока для поддержки выполнения запроса (больше не всегда лучше).
Кроме того, избыточная защита — это распространенная стратегия масштабирования Solr, поэтому я решил провести тесты для коллекции 20 × 1 и 20 × 2, что дало 101 404 и 40 536 соответственно. Очевидно, что некоторая избыточная защита помогает повысить производительность даже при использовании репликации. Похоже, у Solr было больше возможностей при выполнении тестов с 20 осколками, поэтому я увеличил количество осколков до 30 на 10 узлах, и результаты продолжали улучшаться: 121 495 для 30 × 1 и 41 152 для 30 × 2. Результаты 30 × 2 ясно показывают, что использование 60 редукторов, вероятно, было слишком много, поскольку средняя загрузка ЦП составляла 95% на протяжении всего теста, а пропускная способность лишь немного увеличилась по сравнению с тестом 20 × 2.
Наконец, добавление большего количества узлов должно привести к почти линейной масштабируемости. Для следующего цикла тестирования я бегал с 15 × 1 и 15 × 2 на 15 узлах. Для коллекции 15 × 1 я достиг 117 541 документов в секунду со стабильным процессором (в среднем около 50-60%, пик около 85%); это увеличение пропускной способности на 59% при увеличении количества узлов на 50%; лучше, чем линейный, потому что я использовал больше редукторов (60 против 48) для моего 15-узлового теста, учитывая увеличенную емкость кластера. Наконец, я выполнил тест 30 × 1 в кластере из 15 узлов и достиг 157 195 документов в секунду, что, на мой взгляд, действительно впечатляет!
В следующей таблице приведены результаты моего тестирования:
|
Размер кластера |
Num Shards |
Коэффициент репликации |
Редукторы (клиенты) |
Время (сек) |
Документы / Второй |
|
10 |
10 |
1 |
48 |
1762 |
73780 |
|
10 |
10 |
2 |
34 |
3727 |
34881 |
|
10 |
20 |
1 |
48 |
1282 |
101404 |
|
10 |
20 |
2 |
34 |
3207 |
40536 |
|
10 |
30 |
1 |
72 |
1070 |
121495 |
|
10 |
30 |
2 |
60 |
3159 |
41152 |
|
15 |
15 |
1 |
60 |
1106 |
117541 |
|
15 |
15 |
2 |
42 |
2465 |
52738 |
|
15 |
30 |
1 |
60 |
+827 |
157195 |
|
15 |
30 |
2 |
42 |
2129 |
61062 |
Есть несколько интересных выводов из этого начального этапа тестирования производительности Solr. Во-первых, эти результаты основаны на стандартном Solr 4.8.1 без «настройки» параметров конфигурации производительности индексации. Я использую предложенные настройки GC Шона Хейси (см .: http://wiki.apache.org/solr/ShawnHeisey) на Java 1.7.0 u55. Единственное изменение в конфигурации, которое я сделал, — установить в настройках autoCommit жесткую фиксацию каждые 100 000 документов и мягкую фиксацию каждые 60 секунд.
Во-вторых, шардинг явно помогает с производительностью (как и ожидалось), но репликация стоит дорого. Например, при индексировании в коллекцию 20 × 1 (2 ядра Solr на узел на 10 узлов) получается 101 404 документа в секунду, а в коллекции 10 × 2 (также имеет 2 ядра на узел) — только 34 881 документ в секунду. Это огромная разница в результатах, когда каждый узел в основном размещает одинаковое количество документов и выполняет примерно одинаковую работу. Причиной медленной репликации является то, что, хотя количество ядер одинаково, каждый руководитель должен блокироваться, пока не получит ответ при пересылке запросов на обновление репликам. Овершард помогает, потому что клиентские приложения индексации (в данном случае задачи редуктора Hadoop) отправляют обновления каждому лидеру сегмента напрямую. Используя две стратегии вместе (20 × 2), я получаю 40 536 документов в секунду.
Третий урок заключается в том, что Solr может принимать обновления слишком быстро, что может привести к снижению производительности запросов или к ухудшению (сбой сегмента). Таким образом, вам придется снизить пропускную способность индексации до устойчивого уровня, поскольку в Solr отсутствует поддержка регулирования запросов. Для меня это означало использование меньшего количества редукторов, таких как 34 вместо 48, при использовании репликации. Моя цель здесь состояла в том, чтобы избежать пиковой загрузки ЦП, превышающей 85% и в среднем только около 50-60%, оставляя много свободных циклов для выполнения запроса.
Очевидно, что ни одному эталону производительности нельзя доверять, если он не может быть повторен другими. Хорошая новость заключается в том, что любой может выполнить эти же тесты с помощью Solc Scale Toolkit с открытым исходным кодом LucidWorks и инфраструктуры Hadoop LucidWorks. Эксплуатация кластеров Elastic MapReduce и SolrCloud обойдется примерно в 17 долларов в час (10 узлов Solr х 0,70 долл. + 20 м1. Большие базовые узлы EMR * 0,48 долл. + 1 м 1 крупный мастер EMR х 0,24 долл.).
Заворачивать
Я рассмотрел многие ключевые функции инструментария, которые существуют сегодня. Есть много других функций, которые я не освещал в интересах времени (мое и ваше). Поэтому я призываю вас изучить этот инструментарий дальше.
Вы также должны иметь представление о типах индексирования рабочих нагрузок, которые может поддерживать Solr, но пробег зависит от размеров документа, сложности анализа текста, скорости сети и вычислительных ресурсов. Я планирую выполнить дополнительные тесты производительности для Solr, как только позволит время, где я сосредоточусь на тестировании производительности индексирования, а также на выполнении запросов к индексу.
Наконец, эта среда активно развивается, поэтому, пожалуйста, следите за новыми функциями, исправлениями ошибок и улучшениями в ближайшие недели. Как и в случае любого нового проекта с открытым исходным кодом, вероятно, будет несколько бородавок, неправильных предположений и ошибок проектирования. Пожалуйста, наденьте шины и оставьте отзыв, чтобы мы могли улучшить это решение для сообщества Solr. Счастливого масштабирования!
Статья первоначально опубликована Тимоти Поттером .