Урок 4. Выделите фрагменты, в которых была найдена искомая фраза
Поиск по слову или фразе имеет две цели: выяснить, в каком документе он может быть найден, но также узнать, в каком фрагменте документа был найден ответ. Есть два вспомогательных класса, которые показывают попадания документа:
- org.apache.lucene.search.TopDocs — содержит ссылки на главные документы, возвращаемые поиском. Методы TopDocs :
- totalHits — количество документов, соответствующих запросу
- ScoreDocs — массив экземпляров ScoreDoc, содержащих результаты
- getMaxScore () — возвращает лучший результат из всех матчей
- org.apache.lucene.search.ScoreDoc — представляет один результат поиска. Методы ScoreDoc :
- doc — идентификатор документа
- оценка — оценка документа
Чтобы извлечь фрагмент, в котором была найдена фраза / слово, используется класс Highlighter. Пакет выделения содержит классы для предоставления функций «ключевое слово в контексте», которые обычно используются для выделения условий поиска в тексте страниц результатов. Класс Highlighter является центральным компонентом и может использоваться для выделения наиболее интересных разделов фрагмента текста и выделения их с помощью Fragmenter.
Листинг 4.1. Получение совпадений документа с искомой фразой
public static String processResults(IndexReader reader,
IndexSearcher searcher, Analyzer analyzer, Query query,
TopScoreDocCollector collector) throws Exception {
StringBuffer answer = new StringBuffer();
SimpleHTMLFormatter htmlFormatter = new SimpleHTMLFormatter();
Highlighter highlighter = new Highlighter(htmlFormatter,
new QueryScorer(query));
highlighter.setEncoder(new SimpleHTMLEncoder());
ScoreDoc[] hits = collector.topDocs().scoreDocs;
//obtaining document hits of the search phrase
searcher.search(query, ISearchConstants.MAXIMUM_RESULTS_PER_SEARCH);
answer.append("Number of documents where it was found : ")
.append(collector.getTotalHits()).append("\n");
answer.append("\n----------------------------------------------------\n");
for (int i = 0; i < hits.length; i++) {
Document doc = reader.document(hits[i].doc);
answer.append("Document where phrase or part of it was found and its scoring : ");
answer.append(doc.get("file")).append(" (").append(hits[i].score)
.append(")").append("\n");
answer.append("\n-----------------------------------------------\n");
answer.append(searchInContent(highlighter, reader, doc, i,
ISearchConstants.FIELD_ABSTRACT_TEXT, analyzer));
answer.append(searchInContent(highlighter, reader, doc, i,
ISearchConstants.FIELD_TEXT, analyzer));
answer.append("\n------------------------------------------------\n");
}
return answer.toString();
}
Анализаторы возвращают TokenStream; TokenStream, полученный анализатором, будет использоваться для выделения фрагментов.
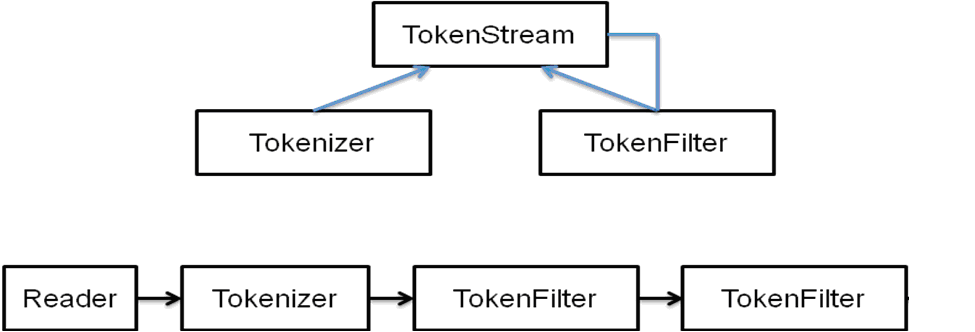
Кроме того, созданный выше объект Highlighter может использоваться для извлечения фрагмента, в котором была найдена фраза / слово:
Листинг 4.2. Выделение фрагментов (сначала анализируется аннотация, затем обычный индексированный текст)
private static String searchInContent(Highlighter highlighter,
IndexReader indexReader, Document doc, Integer docId,
String contentOption, Analyzer analyzer) throws Exception {
StringBuffer answer = new StringBuffer();
String text = doc.get(contentOption);
TokenStream tokenStream = TokenSources.getAnyTokenStream(indexReader,
docId, contentOption, analyzer);
//try to get the best matching fragment(s)
try {
TextFragment[] frag = highlighter.getBestTextFragments(tokenStream,
text, false, ISearchConstants.MAXIMUM_RESULTS_PER_SEARCH);
for (int j = 0; j < frag.length; j++) {
answer.append(SearchUtils.processText(frag[j], (contentOption
.equals(ISearchConstants.FIELD_ABSTRACT_TEXT) ? true
: false), j+1));
}
} catch (InvalidTokenOffsetsException ex) {
ex.printStackTrace();
TextFragment frag = new TextFragment(text, 0, 10);
answer.append(SearchUtils.processText(frag, (contentOption
.equals(ISearchConstants.FIELD_ABSTRACT_TEXT) ? true
: false), 1));
}
return answer.toString();
}
Личное примечание: при индексации документов старайтесь избегать документов, содержащих изображения; класс Highlighter не может выполнить извлечение фрагмента этих документов, и будет выдано исключение InvalidTokendOffsetsException.
Ресурсы
Учить
- Посетите Apache.org/tika, чтобы узнать больше.
- Посетите Apache.org/Lucene, чтобы узнать больше.