В некоторых случаях требуется индекс и, в частности, уникальное ограничение для подмножества строк таблицы базы данных. Другими словами, индекс требуется в предикате.
Многие реляционные базы данных предоставляют методику для решения проблемы без добавления дополнительных структур.
Тематическое исследование
Чтобы проиллюстрировать тему и концепции этого эссе, воспользуемся следующим случаем.
Предположим, чтобы иметь следующие требования:
- хранить транзакцию, включающую дату (год, месяц, день), тип операции и сумму;
- для каждого типа операции разрешается только операция в день;
- хранить все изменения суммы.
Первые два требования предполагают самопроизвольное создание двух связанных объектов, как показано на следующей диаграмме E / R:
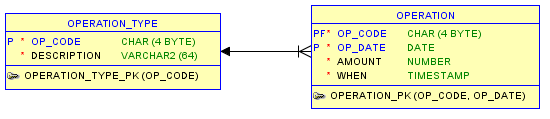
В требованиях ничего не говорится о хранении данных аудита, например о том, когда строка была вставлена, но опыт учит нас, что это достойная информация, поэтому мы добавили поле «WHEN», ожидающее такого использования ( 1 ), но оно будет воспроизводиться более важная роль.
Последнее требование усложняет ситуацию, и нет основного пути к решению: дополнительная информация может управляться либо в структуре «РАБОТА», либо во вспомогательной. В следующих параграфах мы рассмотрим альтернативы, выделяющие плюсы и минусы.
Наивное решение
Кажется, что добавление поля «WHEN» к первичному ключу решает проблему:
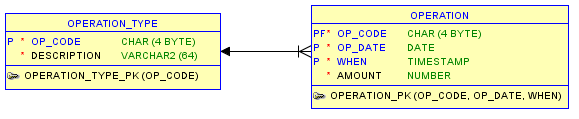
В некотором смысле это правда, но с семантической точки зрения это не является удовлетворительным, поскольку существует более или менее желательное неявное предположение: для данного типа операции и даты текущее значение суммы задается строкой с максимальным значением «WHEN». значение .
Это суппозиторий имеет по крайней мере два последствия:
- возврат к значению предыдущей вставленной суммы означает добавление новой строки с более поздним значением «WHEN»: другими словами, все остальные данные дублируются;
- поиск информации сложен.
Возможно, первый вопрос не является проблемой, поскольку, таким образом, мы сохраняем историю изменений, но получение текущего значения неестественно и требует объединения таблицы «РАБОТА» с подмножеством самого себя.
Например, представление всех операций с текущим значением задается следующим оператором SQL:
select t1.OP_CODE, t1.OP_DATE, t1.AMOUNT
from OPERATION t1 inner join
( select OP_CODE, OP_DATE, max(WHEN) from OPERATION
group by OP_CODE, OP_DATE) t2
on t1.OP_CODE = t2.OP_CODE and t1.OP_DATE = t2.OP_DATEИспользование агрегатной функции max , более того, во вложенном подзапросе, для такой простой необходимости кажется чрезмерным.
Есть ли более простые решения?
Решения с участием вспомогательных структур
Прежде чем анализировать решения, использующие единственную таблицу «РАБОТА», стоит понять, как решить проблему со вспомогательными структурами: мы можем принимать более обоснованные решения.
На следующих диаграммах E / R мы скрываем таблицу «OPERATION_TYPE», поскольку нет необходимости объяснять представление решения.
Решения с участием вспомогательных структур
Возвращаясь к предыдущему рисунку, мы можем пометить текущую сумму, ссылаясь на нее, в конкретной таблице, как на следующей диаграмме E / R:

Обратите внимание, что первичным ключом в таблице «CURRENT_OPERATION» является «OP_CODE» + «OP_DATE».
Это целесообразно позволяет управлять целостностью данных и гарантирует, что будет только текущая сумма с данным типом и датой.
Нам все еще нужно объединение, чтобы получить все текущие суммы, но оператор SQL довольно очевиден:
select t1.OP_CODE, t1.OP_DATE, t1.AMOUNT
from OPERATION t1 inner join (select OP_CODE, OP_DATE from OPERATION) t2
on t1.OP_CODE = t2.OP_CODE and t1.OP_DATE = t2.OP_DATE
Объединение необходимо, так как сумма сохраняется только в основной таблице и не реплицируется в текущей .
Почему бы не сохранить также «AMOUNT» в таблице «CURRENT_OPERATION»?
Для этого нам необходимо гарантировать согласованность данных, и это вносит неприятные сложности.
Вспомогательная таблица истории
Возможный ответ на предыдущий вопрос изображен на следующей диаграмме E / R:

В таблице «OPERATION» хранятся текущие операции и таблица истории всех операций: другими словами, таблица «OPERATION» является подходящим подмножеством таблицы «OPERATION_HISTORY». Теперь оператор SQL не может быть проще:
select OP_CODE, OP_DATE, AMOUNT from OPERATIONОбратите внимание, что поле «WHEN» было перемещено в таблице истории: это делает таблицу «OPERATION» максимально чистой.
Это решение, к сожалению, создает две трудности:
- Согласованность : как мы можем гарантировать, что сумма в одинаковых строках одинакова?
- Целостность : как мы можем гарантировать, что в «OPERATION» не существует строк, которых нет в «OPERATION_HISTORY»?
Эти проблемы могут быть решены с помощью триггеров базы данных в средах, которые их разрешают, но таким образом мы вводим больше сложности, чем уменьшаем ее.
Добавление поля «WHEN» в таблицу «OPERATION» не поможет:

Связь между двумя таблицами была удалена, так как два набора строк должны быть непересекающимися: это делает последовательность очевидной, но нам все еще нужны триггеры базы данных, чтобы проверить, что пересечение является пустым ( 2 ).
наблюдения
Использование вспомогательных таблиц уменьшает сложность запросов, передавая их в операторах управления (вставка, обновление и удаление): этот сдвиг приветствуется, поскольку обычно чтение происходит во много раз чаще, чем запись .
Техника таблицы «OPERATION_HISTORY» кажется более естественной, но она скрывает подводные камни.
Техника «CURRENT_OPERATION» эффективна с точки зрения отношений.
Пересмотренное Наивное Решение
Поскольку использование вспомогательных таблиц может вызвать новые проблемы, инстинктивно пытаться обходиться без них.
Мы исследовали другие возможности, чтобы упростить оператор SQL, но, возвращаясь к некорректному запросу, проблема заключалась в определении текущей суммы: почему бы не сделать это явным, добавив логический флаг в таблицу «РАБОТА»?
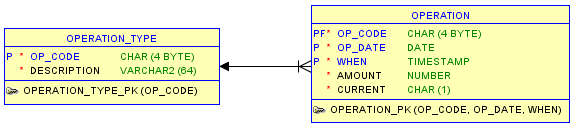
Таким образом, сложность переместилась в операторы управления (вставка, обновление, удаление), которые должны соответствующим образом обрабатывать поле «CURRENT».
Но теперь сложный запрос может быть уменьшен до:
select OP_CODE, OP_DATE, AMOUNT from OPERATION where CURRENT = 'Y'Поскольку управление сложностью вставки более желательно, чем сложность запросов, это решение завершит этот анализ, за исключением того, что мы также должны обеспечить согласованность данных .
К сожалению, с введением флага «CURRENT», как мы можем гарантировать, что существует не более одной текущей суммы для данного типа операции и даты?
Прежде чем пытаться ответить на предыдущий вопрос и исследовать некоторые альтернативы, мы представляем реальное усовершенствование моделирования.
Первичные ключи и уникальные ограничения
На последней диаграмме E / R первичный ключ таблицы «OPERATION» состоит из трех полей: «OP_CODE», «OP_DATE» и «WHEN».
Составные первичные ключи имеют как минимум два недостатка:
- ими очень неудобно манипулировать, особенно при соединении с другими таблицами;
- они часто передают деловую информацию и / или правила, которые могут меняться со временем.
Простой и эффективный обходной путь заключается в создании суррогатного ключа, числового идентификатора, не связанного с каким-либо бизнес-значением, для использования в качестве первичного и, в частности, реляционного ключа.
Такие числовые идентификаторы — очень часто используемые сегодня — обычно используют некоторые специальные функции, предоставляемые базой данных, для генерации ( 4 ) добавочных и уникальных значений для каждого нового запроса.
Добавление такого независимого числового идентификатора не устраняет необходимость обрабатывать уникальность бизнес-ключа (естественный ключ данных). Все реляционные базы данных позволяют создавать уникальные ограничения на множество полей, поэтому проблема легко решается.
Мы получаем гибкость с таким улучшением:
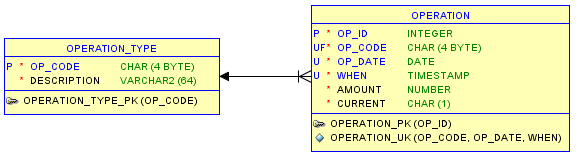
Кстати, есть еще одна возможность для определения уникального ограничения, менее очевидная, но, возможно, технически лучше, а именно: «OP_CODE» + «OP_DATE» + «OP_ID»
Мы не углубляем плюсы и минусы этого варианта как не относящиеся к настоящему тезису.
Решение со специальным индексом
Со ссылкой на модель на предыдущем рисунке стоит последняя проблема: согласованность данных.
Нам нужно найти способ гарантировать, что в таблице присутствует только строка с «CURRENT» = «Y» для каждого типа операции и даты.
Если только уникальные индексы могут быть применены к подмножеству данных таблицы …
Но ждать! Возможно, некоторые среды баз данных могут обеспечить требуемую функциональность. И ответ — да! Их называют частичными индексами, отфильтрованными индексами, условными индексами или другими прилагательными.
Нет никакого соглашения относительно названия и синтаксиса, но потребность была удовлетворена и реализована.
Если такой специальный индекс предоставлен, то уникальное ограничение должно быть определено только для полей «OP_CODE» и «OP_DATE», фильтрующих только для «CURRENT» = «Y»; поле «КОГДА» в действительности становится излишним со структурной точки зрения, и мы оставляем его как остаток от первоначальной цели аудита:
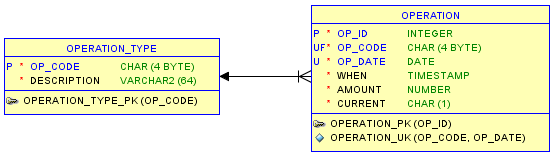
When applicable, this is clearly a very clean and effective strategy from a modeling point of view (5): readability, minimal structure, self-evidence, simple queries.
Microsoft SQL Server, PostgreSQL, SQLite RDBMS
Recent versions of the Microsoft SQL Server RDBMS, the PostgreSQL RDBMS, the SQLite RDBMS supply the possibility to create filtered indexes by adding the clause where.
Actually PostgreSQL and SQLite call it partial indexes instead of filtered indexes.
The syntax to define an index on a table subset is crystal clear as we can appreciate by means of the following SQL statement:
create unique index OPERATION_UK on OPERATION (OP_CODE, OP_DATE) where CURRENT = 'Y'Oracle RDBMS
The Oracle RDBMS does not support the where clause to create filtered indexes, but it provides a flexible though complex syntax to create functional indexes able to get the same result.
This is the SQL statement to build the sought index:
create unique index OPERATION_UK on OPERATION (
(case when CURRENT = 'Y' then OP_CODE else NULL end),
(case when CURRENT = 'Y' then TRUNC(OP_DATE, 'DD') else NULL end) )The use of the TRUNC function is a technical expedient that allows to treating the Oracle Date type as a Date and not as a DateTime.
Other RDBMS
No other RDBMS — with the possible exception of IBM DB2 — seem to provide filtered index, at least in a so direct way as shown in the previous two paragraphs.
In particular:
- MySQL calls partial the indexes with functions applied to part of a column (such as substrings); in other words it does not supply indexes for table row subsets;
- IBM DB2 supplies a fairly complex syntax for creating indexes, but they do not look like supporting predicate to filter rows;
- SAP Sybase ASE (Adaptive Server Enterprise) — even though shares the same origin with Microsoft SQL Server — supports partial indexes but requires partitioned (6) tables.
Perhaps an in-depth analysis of the SQL dialect of specific database systems may highlight other opportunities, but for our case study this is not necessary as a smart alternative exists and it works with near all the RDBMS.
The Last but not the Least resource: The Tricky NULL Value
We recall a couple of facts:
- near all relational databases allow to assign the null value to column fields;
- near all relational databases require the ‘IS NULL’ predicate to check if the value of a column field is null, in other words the use of ‘=’ operator with nulls does not work.
Why? (7)
Well, the answer is at first sight surprising: the SQL standard states that unknown is the result of the expression
| NULL = NULL |
We cannot compare a field value with a NULL value because unknown is the result of the expression
| FieldName = NULL |
This behavior derives by the three value logic (3VL) implemented in SQL (8). The 3VL is based on the three values TRUE, FALSE and UNKNOWN:
- all expressions involving only the values TRUE and FALSE are resolved in the classical boolean way;
- all expressions including at least one UNKNOWN value are resolved as UNKNOWN.
Obviously in SQL the UNKNOWN role is taken by the NULL value.
In this scenario NULL values shall be handled accordingly in the relational database indexes, and in particular with the unique constraints!
Near all relation databases allow to index columns that accept NULL values: check specific RDBMS documentation for details and possible exceptions.
Armed with this knowledge, it is not difficult to figure out how to adapt our model in order to exploit the new logic: it is sufficient to simply force the «CURRENT» field to accept the values ‘Y’ and NULL instead of ‘Y’ and ‘N’:
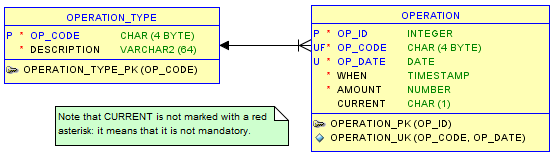
Now the following unique constraint magically works!
create unique index OPERATION_UK on OPERATION (OP_CODE, OP_DATE, CURRENT)For a given «OP_CODE» and «OP_DATE» we can have only a row with «CURRENT» = ‘Y’ and any number of rows with the «CURRENT» value null as they are all different pursuant of the fact that
| «OP_CODE» + «OP_DATE» + NULL | cannot ever be equal to | «OP_CODE» + «OP_DATE» + NULL |
due to the NULL presence in the expression!
Conclusion
The main purpose of this article is to highlight the flexibility of the relational database paradigm and the data integrity problems that also a simple case study may raise. We showed various techniques to approach the difficulties trying to evaluate pros and contras steadily seeking simplicity.
In summary we have compared two different kind of database extensions: the first based on auxiliary tables and the second based on auxiliary indexes (unique constraints to be more precise).
The strong point of using auxiliary tables is that it works with any relational database, while the strong point of using indexes is the neatness.
We focused our efforts on filtered indexes as they are a powerful resource when available, but eventually we introduced an expedient worthy of being understood as it is based on 3VL that is at the core of the relational database theory.
The last techniques unfortunately may not suitable or convenient: the interest for filtered (or partial) indexes is due to the fact they provide extra adaptability.
For
| CURRENT = ‘Y’ | ==> | REMOVED = ‘N’ or REMOVED is NULL |
| CURRENT = ‘N’ or CURRENT is NULL | ==> | REMOVED = ‘Y’ |
The use of this virtual deletion of a record does not allow the application of the unique constraints with NULL values unless to codifying REMOVED is NULL as logically equivalent to REMOVED = ‘Y’, but it is strongly counterintuitive.
Notes
| 1 | In the real world some other fields will be required (such as the user that performed the operation), but they are not necessary in this abstract and simplified context. |
| 2 | The intersection involves not the all columns, but only the key fields «OP_CODE», «OP_DATE» and «WHEN». |
| 3 | The exact where condition depends on the SQL dialect as some databases does not handle directly boolean values and they require to treat boolean values with integers (1 and 0) or characters (‘Y’ and ‘N’, or ‘T’ and ‘F’, or ‘1’ and ‘0’). |
| 4 | Some databases supply auto-incremental numeric types, others the concept of sequence: a sequence is an auto-incremental resource more general than auto-incremental types. |
| 5 | Well, somebody may object that separating current values from other values putting them in different tables (see solution with history table) is good for performance and maintainability. Perhaps this may be true, but if we have such troublesome then we may define partitioned tables (when supported) on «CURRENT» flag! |
| 6 | Table partitions address important issues in supporting large collections of rows by decomposing them in smaller and more manageable blocks. The RDBMSs that support partitions often allow to create specific indexes for each partition. |
| 7 | The programming languages take generally a different position: in Java for example the expression variable == null is a standard Boolean expression that it is true when variable is null and false otherwise. Be aware that languages related to database — such as the PL/SQL, the Transact SQL — follow the database paradigm. |
| 8 | 3VL has advantages, but also drawbacks, for example, writing SQL where conditions is complex and insidious when columns with null values are involved. |