Учитывая то, что, как мне кажется, наметился сдвиг в сторону клиентского MVC, работающего с целыми документами JSON вверх и вниз по сети, мне интересно, есть ли также необходимость в технологии, позволяющей прозрачно создавать / поддерживать реляционные наборы записей для соответствующих операций записи документов. Реляционные записи желательны, поскольку они поддерживают простые средства отчетности, использующие SQL . Инструменты, такие как Crystal или Jasper Reports.
Меня не так интересуют улучшения SQL, которые допускают фрагменты JSON в запросах . Я также не заинтересован в решениях для пользовательских поисковых систем, таких какasticsearch, которые позволяют выполнять сложные запросы индекса. Я ищу что-то, что выполняет вторичную запись в обычную реляционную схему (определенную или автоматически сгенерированную) таким образом, чтобы отчеты Crystal или Jasper (или эквивалентные) могли легко использовать записи для создания отчетов. Результирующая схема (кроме стоимости вторичной записи) будет оптимизирована для запросов.
Мартин Фаулер, как всегда, устанавливает основу для того, что я хочу, с помощью записи bliki ReportingDatabase
Работающий пример
Вот фрагмент JSON, похожий на первый на: http://en.wikipedia.org/wiki/ JSON
{
"id" : 101,
"firstName": "John",
"lastName" : "Smith",
"age" : 25,
"address" :
{
"streetAddress": "21 2nd Street",
"city" : "New York",
"state" : "NY",
"postalCode" : "10021"
},
"phoneNumber":
[
{
"type" : "home",
"number": "212 555-1234"
},
{
"type" : "fax",
"number": "646 555-4567"
}
]
}
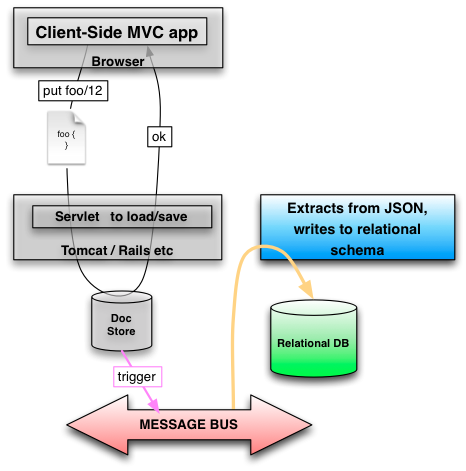
Если бы этот ресурс был перезаписан в базе данных NoSQL, то это был бы один ввод / вывод. Триггер может выбрать эту запись и, по крайней мере, в Postgres, может обрабатывать экономические обновления, а также удаление / запись в зависимости от обстоятельств в реляционную схему. В этом случае это будет четыре записи (возможно, в отдельную базу данных / сервер в хранилище документов):
Человек
| мне бы | имя | фамилия | возраст |
| 101 | Джон | кузнец | 25 |
PersonAddress
| мне бы | адрес улицы | город | штат | Почтовый Код |
| 101 | 21 2-я улица | Нью-Йорк | Нью-Йорк | 10021 |
PersonPhoneNumber
| мне бы | IX | тип | число |
| 101 | 0 | дом | 212 555-1234 |
| 101 | 1 | факс | 646 555-4567 |
Извлечение реляционных полей из JSON декларативно.
В идеале должен существовать декларативный язык, похожий на XPATH , который позволил бы нам кратко объявить разделы документа JSON, которые мы хотели бы разбить на строки в реляционной схеме. Уже существует два альтернативных варианта — JAQL или JsonPath , но мы бы хотели использовать их таким образом, чтобы пакетные документы обрабатывались в связные операторы SQL :
{
"tables":
[
{
"name" : "Person",
"key": "id"
"fields": "firstName, lastName, age"
},
{
"name" : "PersonAddress",
"key": "id"
"fields": "address.streetAddress, address.city, address.state, address.postalCode"
},
{
"name" : "PersonPhoneNumber",
"key": "id, phoneNumber.@index as ix"
"fields": "phoneNumber[ix].type, phoneNumber[ix].number"
}
]
}
Вопрос о том, может ли DDL автоматически извлекаться для выдачи правильных операторов CREATE TABLE, является дискуссионным. Также не ясно, будет ли JSON успешной нотацией для извлечения реляционных данных из документов JSON .
PUT против POST
Веб-приложения классически создаются из приложений GET и POST . Ниже приведена временная шкала веб-технологий в двух записях блога — 1993, 2000, 2006 и последующих 2012 годах , и, наконец, одна из них, превозносящих достоинства документа, является единственным источником правды . Во втором и третьем я говорю о потенциале PUT как механизма обратной записи документов, над которыми «работали» на странице. Что касается сегодняшней записи в блоге, PUT всего документа вплоть до базы данных является мощным, поскольку он облегчает запуск старого и нового документа за одну операцию. Вы можете быть доставлены в POST из-за большого размера документа и необходимости выполнять дополнительную обработку на уровне постоянства, чтобы иметь смысл в хранилище документов, но последующее преобразование в реляционную форму все еще будет возможно.
Разумеется, PUT или POST , документы или фрагменты JSON по- прежнему требуют повторной проверки на стороне сервера, а также проверки подлинности / аудита / контроля доступа.
Важно отметить, что многие уважаемые коллеги ThoughtWorks советуют PUT и POST делать отдельные обновления для внутреннего документа.
Взрыв из прошлого: Oracle Intermedia.
Одиннадцать лет назад в Oracle была технология Intermedia, которая (помимо прочего) записывала бы XML в сгусток и записывала дополнительные записи в связанные таблицы, чтобы обеспечить прямую индексацию атрибутов / элементов XML . Они больше не говорят об этом больше. Я не могу вспомнить, было ли это сделано в реальном времени или нет, но мне кажется, что это было в том же пространстве, что и я.
Службы аналитики SQL Server компании MicroSoft
Как и в Oracle InterMedia, у Microsoft есть технология SQL Server Analysis Services . В отличие от Intermedia, он наиболее актуален.
Среди многих других вещей OLAP , он разбивает сгустки XML на выдающиеся кубы с возможностью поиска. Используя эту часть MAS (?), Можно легко создавать кубы для различных наборов данных, что позволяет легко создавать отчеты в автономном режиме. В конце концов, это не совсем то, что я ищу.
Следить за
Ник Ферриер, например, жаждет написать что-то более техническое для реляционной идеи NoSql. Я свяжусь с ним, когда он закончит.