Это часть 2 (из 2) моей серии по программированию VoltDB — Easy, Flexible и Ultra-fast. В блоге, часть 1 , показано, как создать приложение VoltDB с помощью специальных запросов и выполнения тысяч транзакций в секунду. Также показано, как преобразование этой логики в хранимые процедуры VoltDB позволяет распараллеливать выполнение запросов и достигать 100 000+ транзакций в секунду на одном узле. В этом посте я расскажу о масштабировании свыше 100 000 транзакций в секунду путем создания кластерной базы данных VoltDB.
Прежде всего, вам нужно запустить VoltD B как кластеризованную базу данных по двум причинам : масштаб и высокая доступность. Я буду говорить о каждой из этих тем в оставшейся части этого поста.
Шкала
Масштабирование приложения может осуществляться в двух измерениях: расширение емкости хранения данных (размер базы данных) и масштабирование пропускной способности транзакции. Масштабирование пропускной способности транзакций является темой этого блога. Чтобы масштабировать пропускную способность транзакции сверх возможностей отдельного узла, вам необходимо создать кластер VoltDB.
Чтобы создать кластер VoltDB, вам нужно будет создать файл развертывания. Файл развертывания довольно прост: он определяет, сколько узлов в кластере, сколько разделов будет у каждого узла и коэффициент высокой доступности (kfactor, обсуждается в следующем разделе). Вот пример файла развертывания, который определяет кластер из 3 узлов с 6 разделами на узел, без указания высокой доступности:
<?xml version="1.0"?>
<deployment>
<cluster hostcount="3"
sitesperhost="6"
kfactor="0"
/>
</deployment>
Этот файл развертывания передается в командную строку voltdb при запуске первого узла кластера:
$ voltdb create \
leader voltsvr1 \
catalog mycatalog.jar \
deployment deployment.xml
Чтобы запустить кластер, вы должны:
- Скопируйте каталог приложения на ведущий узел.
- Скопируйте файл развертывания на все узлы кластера.
- Войдите и запустите серверный процесс, используя предыдущую команду на каждом узле.
Файл развертывания должен быть одинаковым на всех узлах (проверено с использованием контрольных сумм) для запуска кластера. [Обратите внимание, что в простейшем случае — при работе на одном узле без включенных специальных параметров — вы можете пропустить именование файла развертывания и узла-лидера и указать только каталог при запуске базы данных.]
В VoltDB Enterprise Edition этот процесс значительно упрощается, поскольку эти этапы настройки автоматизируются с помощью VoltDB Enterprise Manager. VoltDB Enterprise Manager имеет простой в использовании графический веб-интерфейс для управления кластерами VoltDB.
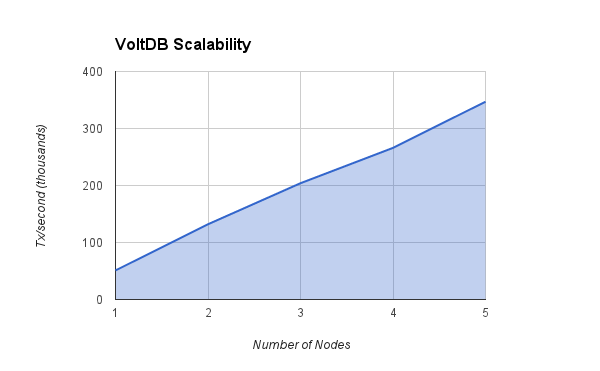
VoltDB линейно масштабируется. Добавление дополнительных узлов даст примерно 90% дополнительной транзакционной емкости. Другими словами, если ваше приложение выполняет 100 000 транзакций в секунду на одном узле, когда вы добавляете узел в кластер VoltDB, вы обычно можете добавить дополнительные 90 000 транзакций в секунду. Вот пропускная способность примера приложения VoltDB Key / Value, запущенного на 1 узле, и кластеров от 2 до 5 узлов. В этом тесте каждый узел представляет собой Amazon EC2 cc1.4xlarge, и его конфигурация описана в типах экземпляров Amazon EC2.
Высокая доступность
Вторая причина определения кластерной базы данных VoltDB — высокая доступность. Обеспечение высокой доступности базы данных позволяет вашему приложению продолжать работу, даже когда некоторые узлы в вашем кластере становятся недоступными. VoltDB реализует настраиваемую пользователем функцию, называемую K-safety, которая обеспечивает синхронную репликацию разделов с несколькими основными устройствами в вашем кластере VoltDB. Указывая значение k-safe больше нуля, вы указываете VoltDB создать и поддерживать столько дополнительных копий каждого раздела. Эти копии разделов будут аккуратно распределены между узлами в кластере, так что вы можете потерять не менее k узлов и при этом сохранить полный набор данных. Другими словами, если указать значение k-safety 2, это означает, что VoltDB будет поддерживать 3 копии каждого раздела в кластере,оригинальный раздел и 2 дополнительных экземпляра. Это также означает, что ваш кластер может продолжать работать и возвращать правильные (и полные) данные, если два узла выпадают из кластера.
<?xml version="1.0"?>
<deployment>
<cluster hostcount="6"
sitesperhost="6"
kfactor="2"
/>
</deployment>
K-safety можно настроить в файле развертывания при определении кластера. Атрибут kfactor позволяет указать количество поддерживаемых копий разделов. В приведенном выше примере определяется кластер из 6 узлов с коэффициентом k-безопасности 2. В этой конфигурации у вашего кластера будет всего 24 раздела (по 4 на каждый узел в кластере). Тем не менее, будет только 8 уникальных разделов с 2 дополнительными репликами каждого раздела (всего 24). Когда два узла удаляются из сбоя, остальные 4 узла в кластере гарантированно имеют полный набор из 8 уникальных разделов и, следовательно, могут все еще возвращать полностью согласованные результаты.
Обратите внимание, что указание k-safety означает, что ваша база данных будет выполнять дополнительную работу для репликации данных по всем разделам. Это означает, что может быть некоторое сокращение числа транзакций в секунду, которое может поддерживать ваш кластер, в зависимости от сочетания рабочей нагрузки чтения / записи вашего приложения (запись потребует дополнительной обработки репликации, чтение не будет — тяжелые рабочие нагрузки будут фактически быстрее, когда k -безопасная репликация включена). Вот повторный прогон Voter с K-safety, заданным на 1, что означает, что в кластере есть 1 копия каждого раздела. 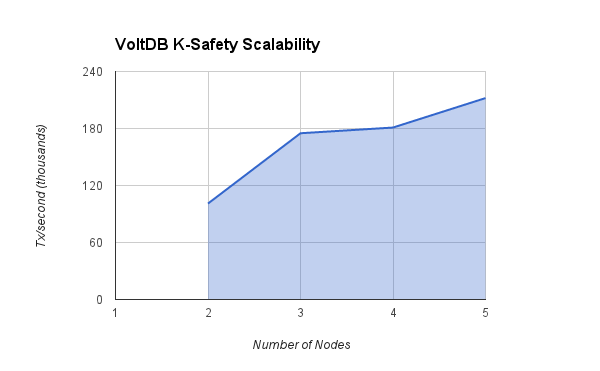
Документация VoltDB содержит подробное описание K-safety, которое вы можете прочитать здесь .
Вывод
Очень легко начать работу с VoltDB и начать видеть значительные транзакции в секунду. Просто определите свою схему, запустите VoltDB и начните выдавать специальные запросы. С помощью этой стратегии вы сможете выполнять тысячи транзакций в секунду без особых усилий. Чтобы достичь поистине сногсшибательных транзакций веб-масштаба, от 10 до тысяч транзакций в секунду, вам нужно будет поместить ваш SQL в хранимые процедуры VoltDB и выполнить их в кластере VoltDB. Благодаря линейной масштабируемости VoltDB может достигать миллионов транзакций в секунду на относительно небольшом кластере. Обратите внимание, что никакого специального оборудования не требуется — числа, приведенные в этом блоге, были сгенерированы с использованием ранней бета-версии VoltDB v3.0, работающей на экземплярах виртуальных машин в облаке Amazon.