Эта статья представляет собой второе Подтверждение концепции из серии, описанной в предыдущей статье 4 Практические подходы для улучшения реализации уровня доступа к данным, и представляет, как реализовать Hazelcast через MyBatis, как добиться оптимальной конфигурации для него, и личное мнение о Автор о выбранном подходе для уровня доступа к данным.
Согласно сайту, Hazelcast является ведущей сеткой данных с открытым исходным кодом в памяти. Эта характеристика Hazelcast относится к тому, что платформа Apache License предлагает масштабируемую платформу для распространения данных. Кроме того, Hazelcast отличается простотой использования, легким набором функций и механизмами резервного копирования и переключения при сбое.
В рамках этой статьи будут рассмотрены следующие аспекты:
1. Какую выгоду получит приложение от кэширования с помощью Hazelcast? Функции Hazelcast будут подробно описаны в этом разделе.
2 . Практическая реализация проекта HazelcastPOC — в этом разделе ключевые концепции Hazelcast будут изучены в ходе практической реализации.
3. Summary — How has the application performance been improved after this implementation?
Code of all the projects that will be implemented can be found at https://github.com/ammbra/CacherPoc or if you are interested only in the current implementation, you can access it here : https://github.com/ammbra/CacherPoc/tree/master/HazelcastPoc
How will an application benefit from caching using Hazelcast?
Applications servers and web servers can be configured to scale out in order to handle large amount of data by adding a load balancer. But web applications need to be aware of the status of a given user session because it holds informations related to the user identity and the authentication state.
A session lives on the machine where it was first created and all user traffic from that user is forced to go through that specific machine. This situation binds a user to a machine and sometimes machines crash or are restarted for maintenance. In order to avoid binding a user to a machine, a lot of nowadays web applications have a “keep me logged in” option; this option signals that the user session should be persisted no matter the backend conditions.
But instead implementing complex mechanisms in order to «walk» data accross machines, choose Hazelcast cache implementation. Hazelcast is able to handle this type of case with in-memory performance and achieve scalability no matter how many new nodes are added to the application.
According to its website, Hazelcast is a In‐MemoryDataGrid(IMDG) that supports clusteringand is a highlyscalabledatadistribution solutionforJava due to its distributed data structures for Java. This means that an application would benefit of :
- Scalability
- Posibility to sharedataacrosscluster (cluster information and membershio events)
- Data Partitioning (Hazelcast has a distributed/partitioned implementation of map, queue, set, list, lock and executor service)
- Load Balancing
- Transactionability (through its JCA support)
- Sending/receiving messages ( topic support for publish/subscribe messaging)
- In parallel process on two or more JVM
- Dynamic clustering,backup and fail‐over mechanisms
- Easy deployment, Hazelcast having a small library of 2.6MB that can be embedded in every copy of an web application server.
Hands-on implementation of the HazelcastPOC project
Our implementation of HazelcastPoc will look as described in the diagram below:
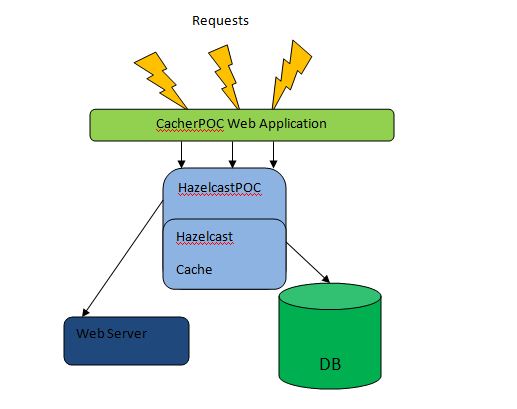
In order to test Hazelcast performance the following project setup could be performed:
Step 1. Create a new Maven EJB Project from your IDE (this kind of project is platform provided by NetBeans but for those that use eclipse, here is an usefull tutorial). In the article this project is named HazelcastPOC.
Step 2. Edit your project’s pom.xml by adding required jars :
<dependency>
<groupId>org.mybatis.caches</groupId>
<artifactId>mybatis-hazelcast</artifactId>
<version>1.1.0</version>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
<dependency>
<groupId>com.hazelcast</groupId>
<artifactId>hazelcast</artifactId>
<version>3.3.3</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.5</version>
</dependency>
Step 3. Add your database connection driver, in this case apache derby:
<dependency>
<groupId>org.apache.derby</groupId>
<artifactId>derbyclient</artifactId>
<version>10.11.1.1</version>
</dependency>
Step 4. Run mvn clean and mvn install commands on your project.
Now you should have your project in place, so let’s go ahead with our implementation of MyBatis :
Step 1. Configure under resources/com/tutorial/hazelcastpoc/xml folder the Configuration.xml file with :
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<environments default="development">
<environment id="development">
<transactionManager type="JDBC"/>
<dataSource type="UNPOOLED">
<property name="driver" value="org.apache.derby.jdbc.ClientDriver"/>
<property name="url" value="dburl"/>
<property name="username" value="cruddy"/>
<property name="password" value="cruddy"/>
</dataSource>
</environment>
</environments>
<mappers>
<!--<mapper resource="com/tutorial/hazelcastpoc/xml/EmployeeMapper.xml" /> -->
</mappers>
</configuration>
Step 2. Create in java your own SQLSessionFactory implementation. For example, create com.tutorial.Hazelcastpoc.config. SQLSessionFactory as below :
public class SQLSessionFactory {
private static final SqlSessionFactory FACTORY;
static {
try {
Reader reader = Resources.getResourceAsReader("com/tutorial/hazelcastpoc/xml/Configuration.xml");
FACTORY = new SqlSessionFactoryBuilder().build(reader);
} catch (Exception e){
throw new RuntimeException("Fatal Error. Cause: " + e, e);
}
}
public static SqlSessionFactory getSqlSessionFactory() {
return FACTORY;
}
}
Step 3. Create your necessary bean classes, the ones that will map to your sql results, like Employee:
public class Employee implements Serializable {
private static final long serialVersionUID = 1L;
private Integer id;
private String firstName;
private String lastName;
private String adress;
private Date hiringDate;
private String sex;
private String phone;
private int positionId;
private int deptId;
public Employee() {
}
public Employee(Integer id) {
this.id = id;
}
@Override
public String toString() {
return "com.tutorial.hazelcastpoc.bean.Employee[ id=" + id + " ]";
}
}
Step 4. Create the IEmployeeDAO interface that will expose the EJB implementation when injected:
public interface IEmployeeDAO {
public List<Employee> getEmployees();
}
Step 5. Implement the above inteface:
@Stateless(name = "hazelcastDAO")
@TransactionManagement(TransactionManagementType.CONTAINER)
public class EmployeeDAO implements IEmployeeDAO {
private static Logger logger = Logger.getLogger(EmployeeDAO.class);
private SqlSessionFactory sqlSessionFactory;
@PostConstruct
public void init() {
sqlSessionFactory = SQLSessionFactory.getSqlSessionFactory();
}
@Override
public List<Employee> getEmployees() {
logger.info("Getting employees with Hazelcast.....");
SqlSession sqlSession = sqlSessionFactory.openSession();
List<Employee> results = sqlSession.selectList("retrieveEmployees");
sqlSession.close();
return results;
}
}
Step 6. Create the EmployeeMapper.xml that contains the query named «retrieveEmployees» :
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd" >
<mapper namespace="com.tutorial.hazelcastpoc.mapper.EmployeeMapper" >
<resultMap id="results" type="com.tutorial.hazelcastpoc.bean.Employee" >
<id column="id" property="id" javaType="integer" jdbcType="BIGINT" />
<result column="first_name" property="firstName" javaType="string" jdbcType="VARCHAR"/>
<result column="last_name" property="lastName" javaType="string" jdbcType="VARCHAR"/>
<result column="hiring_date" property="hiringDate" javaType="date" jdbcType="DATE" />
<result column="sex" property="sex" javaType="string" jdbcType="VARCHAR" />
<result column="dept_id" property="deptId" javaType="integer" jdbcType="BIGINT" />
</resultMap>
<select id="retrieveEmployees" resultMap="results" >
select id, first_name, last_name, hiring_date, sex, dept_id
from employee
</select>
</mapper>
If you remember our CacherPOC setup from the previously article, then you can test your implementation if you add HazelcastPOC project as dependency and inject the IEmployeeDAO inside the HazelcastServlet. Your CacherPOC pom.xml file should contain a dependency to HazelcastPOC project:
<dependency>
<groupId>${project.groupId}</groupId>
<artifactId>HazelcastPoc</artifactId>
<version>${project.version}</version>
</dependency>
and your servlet should look like:
@WebServlet("/HazelcastServlet")
public class HazelcastServlet extends HttpServlet {
private static Logger logger = Logger.getLogger(HazelcastServlet.class);
@EJB(beanName ="hazelcastDAO")
IEmployeeDAO employeeDAO;
private static final String LIST_USER = "/listEmployee.jsp";
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
String forward= LIST_USER;
List<Employee> results = new ArrayList<Employee>();
for (int i = 0; i < 10; i++) {
for (Employee emp : employeeDAO.getEmployees()) {
logger.debug(emp);
results.add(emp);
}
try {
Thread.sleep(3000);
} catch (Exception e) {
logger.error(e, e);
}
}
req.setAttribute("employees", results);
RequestDispatcher view = req.getRequestDispatcher(forward);
view.forward(req, resp);
}
}
Run your CacherPoc implementation to check if your Data Access Layer with MyBatis is working or download the code provided athttps://github.com/ammbra/CacherPoc
But if a great amount of employees is stored in database, or perhaps the retrieval of a number of 10xemployeesNo represents a lot of workload for the database. Also, can be noticed that the query from the EmployeeMapper.xml retrieves data that almost never changes (id, first_name, last_name, hiring_date, sex cannot change; the only value that might change in time is dept_id); so a caching mechanism can be used.
Below is described how caching can be achieved using Hazelcast:
Caching Step 1. Here should have been a configuration file, but Hazelcast does not need such a dependency. One care less for developers.
Caching Step 2. Update your EmployeeMapper.xml to use the previous implemented caching strategy:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd" >
<mapper namespace="com.tutorial.hazelcastpoc.dao.EmployeeDao" >
<cache type="org.mybatis.caches.hazelcast.LoggingHazelcastCache"/>
<resultMap id="results" type="com.tutorial.hazelcastpoc.bean.Employee" >
<id column="id" property="id" javaType="integer" jdbcType="BIGINT" />
<result column="first_name" property="firstName" javaType="string" jdbcType="VARCHAR"/>
<result column="last_name" property="lastName" javaType="string" jdbcType="VARCHAR"/>
<result column="adress" property="adress" javaType="string" jdbcType="VARCHAR" />
<result column="hiring_date" property="hiringDate" javaType="date" jdbcType="DATE" />
<result column="sex" property="sex" javaType="string" jdbcType="VARCHAR" />
<result column="dept_id" property="deptId" javaType="integer" jdbcType="BIGINT" />
</resultMap>
<select id="retrieveEmployees" resultMap="results" useCache="true">
select id, first_name, last_name, hiring_date, sex, dept_id
from employee
</select>
</mapper>
By adding the line <cache type=»org.mybatis.caches.hazelcast.LoggingHazelcastCache «/> and specifying on the query useCache=»true» you are activating Hazelcast cache with logging capabilities for the DataAccessLayer implementation.
Clean, build and redeploy both HazelcastPOC and CacherPoc projects; now retrieve your employees for two times in order to allow the in-memory cache to store the values. When you run your query for the first time, your application will execute the query on the database and retrieve the results. Second time you access the employee list, your application will access the in-memory storage.
Summary — How has the application performance been improved after this implementation?
An application’s performances depend on a multitude of factors:
- how many times a cached piece of data can and is reduced by the application
- the proportion of the response time that is alleviated by caching
Amdhal’s law can be used to estimate the system’s speed up :
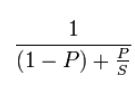 where P is proportion speed up and S is speed up.
where P is proportion speed up and S is speed up.
Let’s take our implementation as example and calculate the speed up.
When the application ran the query without caching,a JDBC transaction is performed and in your log shoudl be something similar to:
INFO: 2014-12-02 18:01:30,020 [EmployeeDAO] INFO com.tutorial.hazelcastpoc.dao.EmployeeDAO:38 - Getting employees..... INFO: 2014-12-02 18:01:39,148 [JdbcTransaction] DEBUG org.apache.ibatis.transaction.jdbc.JdbcTransaction:98 - Setting autocommit to false on JDBC Connection [org.apache.derby.client.net.NetConnection40@1c374fd] INFO: 2014-12-02 18:01:39,159 [retrieveEmployees] DEBUG com.tutorial.hazelcastpoc.mapper.EmployeeMapper.retrieveEmployees:139 - ==> Preparing: select id, first_name, last_name, hiring_date, sex, dept_id from employee INFO: 2014-12-02 18:01:39,220 [retrieveEmployees] DEBUG com.tutorial.hazelcastpoc.mapper.EmployeeMapper.retrieveEmployees:139 - ==> Parameters: INFO: 2014-12-02 18:01:39,316 [retrieveEmployees] DEBUG com.tutorial.hazelcastpoc.mapper.EmployeeMapper.retrieveEmployees:139 - <== Total: 13
while running the queries with Hazelcast caching the JDBC transaction is performed only once (to initialize the cache) and after that the log will look like :
INFO: Loading 'hazelcast-default.xml' from classpath.
INFO: [LOCAL] [dev] [3.3.3] Prefer IPv4 stack is true.
INFO: [LOCAL] [dev] [3.3.3] Picked Address[192.168.0.11]:5701, using socket ServerSocket[addr=/0:0:0:0:0:0:0:0,localport=5701], bind any local is true
INFO: [192.168.0.11]:5701 [dev] [3.3.3] Starting with 8 generic operation threads and 8 partition operation threads.
INFO: [192.168.0.11]:5701 [dev] [3.3.3] Hazelcast 3.3.3 (20141112 - eadb69c) starting at Address[192.168.0.11]:5701
INFO: [192.168.0.11]:5701 [dev] [3.3.3] Copyright (C) 2008-2014 Hazelcast.com
INFO: [192.168.0.11]:5701 [dev] [3.3.3] Creating MulticastJoiner
INFO: [192.168.0.11]:5701 [dev] [3.3.3] Address[192.168.0.11]:5701 is STARTING
INFO: [192.168.0.11]:5701 [dev] [3.3.3]
Members [1] {
Member [192.168.0.11]:5701 this
}
INFO: [192.168.0.11]:5701 [dev] [3.3.3] Address[192.168.0.11]:5701 is STARTED
INFO: 2014-12-02 21:08:49,977 [LogFactory] DEBUG org.apache.ibatis.logging.LogFactory:128 - Logging initialized using 'class org.apache.ibatis.logging.slf4j.Slf4jImpl' adapter.
INFO: 2014-12-02 21:08:50,459 [EmployeeDAO] INFO com.tutorial.hazelcastpoc.dao.EmployeeDAO:37 - Getting employees.....
INFO: [192.168.0.11]:5701 [dev] [3.3.3] Initializing cluster partition table first arrangement...
INFO: 2014-12-02 21:08:50,619 [EmployeeDao] DEBUG com.tutorial.hazelcastpoc.dao.EmployeeDao:62 - Cache Hit Ratio [com.tutorial.hazelcastpoc.dao.EmployeeDao]: 0.0
INFO: 2014-12-02 21:08:50,647 [JdbcTransaction] DEBUG org.apache.ibatis.transaction.jdbc.JdbcTransaction:132 - Opening JDBC Connection
INFO: 2014-12-02 21:08:52,649 [JdbcTransaction] DEBUG org.apache.ibatis.transaction.jdbc.JdbcTransaction:98 - Setting autocommit to false on JDBC Connection [org.apache.derby.client.net.NetConnection40@11b8570]
INFO: 2014-12-02 21:08:52,660 [retrieveEmployees] DEBUG com.tutorial.hazelcastpoc.dao.EmployeeDao.retrieveEmployees:139 - ==> Preparing: select id, first_name, last_name, hiring_date, sex, dept_id from employee
INFO: 2014-12-02 21:08:53,263 [retrieveEmployees] DEBUG com.tutorial.hazelcastpoc.dao.EmployeeDao.retrieveEmployees:139 - ==> Parameters:
INFO: 2014-12-02 21:08:53,361 [retrieveEmployees] DEBUG com.tutorial.hazelcastpoc.dao.EmployeeDao.retrieveEmployees:139 - <== Total: 13
INFO: 2014-12-02 21:08:53,610 [JdbcTransaction] DEBUG org.apache.ibatis.transaction.jdbc.JdbcTransaction:120 - Resetting autocommit to true on JDBC Connection [org.apache.derby.client.net.NetConnection40@11b8570]
INFO: 2014-12-02 21:08:53,612 [JdbcTransaction] DEBUG org.apache.ibatis.transaction.jdbc.JdbcTransaction:88 - Closing JDBC Connection [org.apache.derby.client.net.NetConnection40@11b8570]
INFO: 2014-12-02 21:08:53,614 [HazelcastCacheServlet] DEBUG com.tutorial.cacherpoc.HazelcastCacheServlet:41 - com.tutorial.crudwithjsp.model.Employee[ id=1 ]
--
INFO: 2014-12-02 21:08:53,612 [JdbcTransaction] DEBUG org.apache.ibatis.transaction.jdbc.JdbcTransaction:88 - Closing JDBC Connection [org.apache.derby.client.net.NetConnection40@11b8570]
INFO: 2014-12-02 21:08:53,614 [HazelcastCacheServlet] DEBUG com.tutorial.cacherpoc.HazelcastCacheServlet:41 - com.tutorial.crudwithjsp.model.Employee[ id=1 ]
INFO: 2014-12-02 21:08:56,620 [EmployeeDAO] INFO com.tutorial.hazelcastpoc.dao.EmployeeDAO:37 - Getting employees.....
INFO: 2014-12-02 21:08:56,641 [EmployeeDao] DEBUG com.tutorial.hazelcastpoc.dao.EmployeeDao:62 - Cache Hit Ratio [com.tutorial.hazelcastpoc.dao.EmployeeDao]: 0.5
Let’s look at the time that each of our 10 times requests has scored:
- the first not cached 10 times requests took about 57seconds and 51 milliseconds ,
- while the cached requests scored a time of 28seconds and 48 miliseconds.
In order to apply Amdhal’s law for the system the following input is needed:
- Un-cached page time: 60 seconds
- Database time (S): 58 seconds
- Cache retrieval time: 29 seconds
- Proportion: 96.6% (58/60) (P)
The expected system speedup is thus:
1 / (( 1 – 0.966) + 0.966 / (58/29)) = 1 / (0.034 + 0.966 /2) = 1.96 times system speedup
This result can be improved of course, but the purpose of this article was to proove that caching using Hazelcast over MyBatis offers a significant improvement to what used to be available before its implementation.
Learn more from: