Многие люди очень рады большим данным. Они любят играть, исследовать, работать и изучать эту границу. Скорее всего, эти люди либо работают, либо хотели бы поиграть с большим объемом данных (сотни гигабайт или даже терабайт). Но вот в чем дело, найти набор данных объемом в несколько гигабайт непросто. Обычно такие наборы данных необходимы для экспериментов с новой средой обработки данных, такой как Apache Spark, или инструментами потоковой передачи данных, такими как Apache Kafka. В этом посте я опишу и предоставлю ссылку на простой и мощный набор данных переполнения стека объемом в несколько гигабайт.
1. Наборы данных для машинного обучения
Существует множество источников проблем машинного обучения. Kaggle — лучший источник для этих проблем, и они предлагают множество наборов данных, представленных с примерами кода. Большинство этих наборов данных чистые и готовы к использованию в ваших экспериментах по машинному обучению.
В реальной жизни ученого, занимающегося данными, скорее всего, у вас нет роскоши чистых данных, а размер входных данных создает дополнительную большую проблему. Университетские курсы, а также онлайн-курсы предлагают ограниченную точку зрения на науку о данных и машинное обучение, поскольку они учат студентов применять статистические и машинные методы обучения к небольшому количеству чистых данных. На самом деле, специалист по данным тратит большую часть своего времени на получение данных и их очистку. По словам Хэла Вариана (главного экономиста Google), «самая сексуальная работа 21-го века» принадлежит статистикам (и, я полагаю, ученым данных). Однако большую часть времени они выполняют работу по «очистке».
Чтобы поэкспериментировать с новыми инструментами обработки данных или потоковой передачи данных, вам нужны большие (больше, чем ваш компьютер может хранить в памяти) и неочищенные наборы данных.
Большие и нечистые наборы данных позволят вам получить реальную обработку данных или приобрести аналитические навыки. Оказывается, это не так легко найти.
2. Наборы данных для обработки
Kdnuggets и Quora имеют довольно хорошие списки открытых репозиториев:
- http://www.kdnuggets.com/datasets/index.html
- https://www.quora.com/What-kinds-of-large-datasets-open-to-the-public-do-you-analyze-the-mostly
Большинство этих наборов данных из этих списков очень малы по размеру, и по большей части вам нужны специальные знания из конкретной бизнес-области набора данных, такой как физика или здравоохранение. Однако для обучения и экспериментов было бы неплохо иметь набор данных из хорошо известного бизнес-домена, с которым знакомы все люди.
Данные социальных сетей являются лучшими, потому что люди понимают эти наборы данных, и у них есть интуиция о данных, которые важны в аналитическом процессе. Вы можете использовать API социальной сети для извлечения ваших наборов данных. К сожалению, ваш набор данных не лучший для обмена вашими аналитическими результатами с другими людьми. Было бы здорово найти общий набор данных социальной сети с открытой лицензией. И я нашел один!
3. Переполнение стека в открытом наборе данных
Набор данных переполнения стека — единственный открытый социальный набор данных, который мне удалось найти. Stackoverflow.com — это вопрос и ответы на веб-сайте о программировании. Этот веб-сайт особенно полезен, когда вам нужно написать код на языке, с которым вы не знакомы. Этот хорошо известный подход называется разработкой, управляемой переполнением стека, или SDD. Я считаю, что все люди из высокотехнологичной индустрии знакомы с Stack Overflow, и многие из них имеют учетную запись на этом веб-сайте.
Компания Stack Exchange (владелец stackoverflow.com) публикует набор данных stackexchange по открытой творческой общей лицензии. Вы можете найти самый свежий набор данных на этой странице:
https://archive.org/details/stackexchange
Набор данных содержит все данные об обмене стеками, включая переполнение стека, а общий размер архива составляет 27 гигабайт . Размер несжатых данных составляет более 1 терабайта.
4. Как скачать и извлечь набор данных?
Однако этот набор данных получить нелегко. Для начала вам необходимо загрузить архив всего набора данных. Обратите внимание, что скорость загрузки очень низкая. Они рекомендуют использовать битторрент-клиент для загрузки архива, но часто у него возникают некоторые проблемы. Без битторента я сделал 3 попытки и потратил 2 дня на скачивание этого архива. Далее необходимо распаковать большой архив . Наконец, вам нужно распаковать подмножество данных, которые вам нужны (например, stackoverflow-Posts или travel.stackexchange) с помощью компрессора 7z . Если у вас нет компрессора 7z, вам нужно найти и установить его на свой компьютер.
После загрузки архива с https://archive.org/details/stackexchange извлеките все связанные со Stack Overflow архивы и распакуйте каждый из них (все архивы, которые начинаются со stackoverflow.com):
- Posts.7z-stackoverflow.com
- PostsHistory.7z-stackoverflow.com
- Comments.7z-stackoverflow.com
- Badges.7z-stackoverflow.com
- PostLinks.7z-stackoverflow.com
- Tags.7z-stackoverflow.com
- Users.7z-stackoverflow.com
- Votes.7z-stackoverflow.com
В результате вы увидите набор XML-файлов с одинаковыми именами.
5. Как использовать набор данных?
Давайте поэкспериментируем с набором данных. Самый интересный файл это Posts.xml. Этот файл содержит 34 ГБ несжатых данных, приблизительно 70% — это основной текст, который представляет собой текст вопросов с веб-сайта. Этот объем данных, скорее всего, не умещается в вашей памяти. Мы можем использовать технологию обработки данных на диске или машинного обучения. Это хороший шанс использовать Apache Spark и MLLib или ваше собственное решение.
Давайте посмотрим, как этот вопрос переполнения стека будет выглядеть в файле.
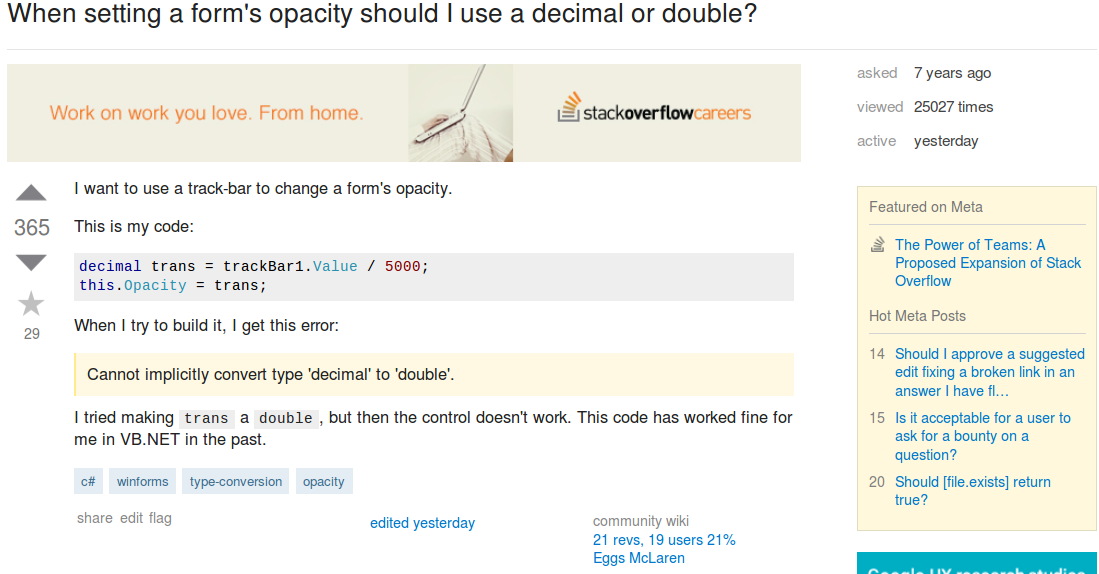
В файле этот пост представлен одной строкой. Обратите внимание: поскольку текст является HTML, открывающий и закрывающий теги p (<p> и </ p>) записываются как & lt; p & gt; и & lt; / p & gt; соответственно.
<row>
Id=“4”
PostTypeId=“1”
AcceptedAnswerId=“7”
CreationDate=“2008-07-31T21:42:52.667”
Score=“322”
ViewCount=“21888”
Body=“<p>I want to use a track-bar to change a form’s opacity.</p> <p>This is my code:</p> <pre><code>decimal trans = trackBar1.Value / 5000; this.Opacity = trans; </code></pre> <p>When I try to build it, I get this error:</p> <blockquote> <p>Cannot implicitly convert type ‘decimal’ to ‘double’.</p> </blockquote> <p>I tried making <code>trans</code> a <code>double</code>, but then the control doesn’t work. This code has worked fine for me in VB.NET in the past. </p> ”
OwnerUserId=“8”
LastEditorUserId=“451518”
LastEditorDisplayName=“Rich B”
LastEditDate=“2014-07-28T10:02:50.557”
LastActivityDate=“2014-12-20T17:18:47.807”
Title=“When setting a form’s opacity should I use a decimal or double?”