Компьютерное зрение — это захватывающий и быстро растущий набор технологий для обработки данных. Он имеет широкий спектр применения от промышленного контроля качества до диагностики заболеваний. Я пробовал работать с несколькими различными технологиями, которые раньше попадали под этот зонтик, и я решил, что было бы целесообразно попытаться быстро создать прототип веб-приложения для распознавания изображений, использующего нейронную сеть .
Я использовал систему глубокого обучения под названием Caffe , созданную Центром изучения и обучения Berkeley . Есть несколько других сопоставимых систем глубокого обучения, таких как Chainer , Theano и Torch7, которые были кандидатами, но я выбрал Caffe из-за моего предыдущего опыта работы с ним. У Caffe есть набор привязок Python, которые я использовал для этого проекта. Если вам интересны дополнительные теории глубокого обучения и нейронных сетей, я рекомендую эту страницу Майкла Нильсена.
Для начала я установил все зависимости Caffe на экземпляр AWS t2.medium, работающий под управлением Ubuntu 14.04 LTS. (Инструкции по установке для 14.04 LTS можно найти здесь .) Я решил использовать CUDA только для процессора, потому что я не тренирую свою собственную нейронную сеть для этого проекта. Я получил две предварительно обученные модели из зоопарка BVLC Model , называемые GoogleNet и AlexNet . Обе эти модели прошли обучение в ImageNet , который представляет собой стандартный набор из 14 миллионов изображений.
Теперь, когда у меня установлены все необходимые компоненты , я открыл Exaptive IDE и запустил новый Xap (то, что мы любим называть веб-приложениями, созданными в Exaptive). Я начал с создания нового компонента Python для написания кода Caffe, необходимого для идентификации изображения. Я назвал новый компонент «GoogleNet» в честь модели нейронной сети, которую я хочу использовать в первую очередь.
Мой новый компонент GoogleNet в IDE, готовый для кодирования.
Затем я написал код Caffe на Python.
Сначала мы создаем экземпляр классификатора изображений кафе.
net = caffe.Classifier(
reference_model,
reference_pretrained,
mean=imagenet_mean,
channel_swap=(2, 1, 0),
raw_scale=255,
image_dims=(256, 256))Reference_model — это путь к файлу набора параметров конфигурации для сети. Кафе предоставляет модель для этого. Reference_pretrained — это еще один путь к файлу, который указывает на предварительно обученную модель GoogleNet из модельного зоопарка.
Мы берем путь к входному файлу изображения и используем методы Caffe для его загрузки.
image_file = inevents["image"]
input_image = caffe.io.load_image(image_file)Затем мы просто вызываем предикат в нашем классификаторе изображений с входным изображением в качестве аргумента.
output = net.predict([input_image])
predictions = output[0]
predicted_class_index = predictions.argmax()Затем мы получаем три верхних прогноза для нашего изображения.
ind = np.argpartition(predictions, -3)[-3:]Затем создайте хороший HTML-код для текстового компонента.
pretty_text = "<h3>GoogleNet:</h3>"
for i in range(0, len(ind[np.argsort(predictions[ind])])):
pretty_text += "#%d. %s (%2.1f%%) <br>" % (
i + 1,
name_map[ind[np.argsort(predictions[ind])][2-i]],
predictions[ind[np.argsort(predictions[ind])][2-i]] * 100)
return pretty_textОбратите внимание, что мы получаем идентификатор и используем name_map, которое соответствует идентификаторам imagenet класса изображений. Тогда pretty_text будет возвращен для пользователя.
Теперь, когда Python был написан, мне нужно было подключить пользовательский интерфейс. Чтобы получить изображение в xap, я выбрал цель удаления файла, которая является одним из часто используемых компонентов Exaptive для обработки ввода файлов.
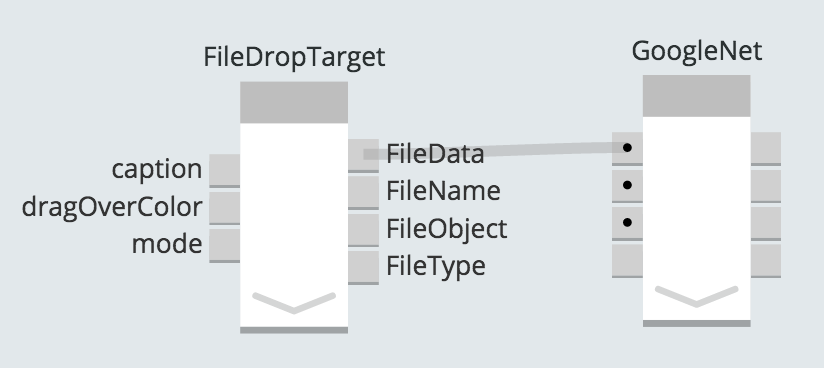
Цель перетаскивания будет использоваться для передачи изображения в компонент нейронной сети.
Цель удаления файла, готовая принять наши изображения.
На этом этапе осталось только создать текстовый дисплей для HTML, который будет создан внутри компонента нейронной сети. Для этого я выбрал компонент JavaScript с именем «Текст», который будет отображать HTML.
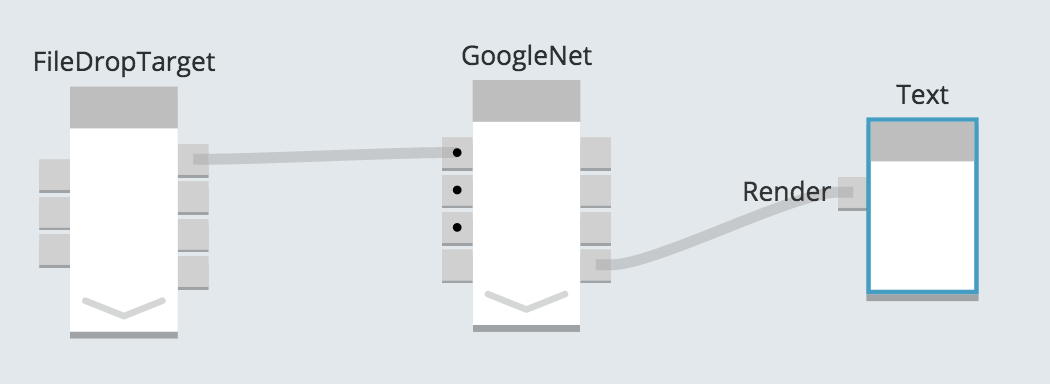
Три компонента спустя, мы готовы идентифицировать некоторые изображения.
На данный момент код был сделан. Я добавил несколько HTML и встроенных стилей, затем сохранил этот Xap и открыл его в другой вкладке. Вот страница, когда мы загружаем ее.
 Затем мы перетаскиваем изображение. Я использовал фотографию кролика и котенка. Приложение обрабатывает в течение нескольких секунд, а затем я вижу:
Затем мы перетаскиваем изображение. Я использовал фотографию кролика и котенка. Приложение обрабатывает в течение нескольких секунд, а затем я вижу:
 Оно работает! Вы можете увидеть предсказания нейронной сети (и их идентификационные номера imagenet) вместе с% уверенности, которую дает нам нейронная сеть. Итак, отсюда мы заложили основу для множества других приложений. Теперь мы можем использовать любую предварительно обученную модель нейронной сети. Например, если бы существовала модель для приложения в области наук о жизни, все, что нам нужно было бы сделать, это загрузить эту модель, и только что написанный нами компонент мог бы указывать на нее вместо модели GoogleNet и давать нам результаты из этого веб-приложения.
Оно работает! Вы можете увидеть предсказания нейронной сети (и их идентификационные номера imagenet) вместе с% уверенности, которую дает нам нейронная сеть. Итак, отсюда мы заложили основу для множества других приложений. Теперь мы можем использовать любую предварительно обученную модель нейронной сети. Например, если бы существовала модель для приложения в области наук о жизни, все, что нам нужно было бы сделать, это загрузить эту модель, и только что написанный нами компонент мог бы указывать на нее вместо модели GoogleNet и давать нам результаты из этого веб-приложения.
Чтобы проиллюстрировать это, я добавил второй компонент, который использует модель AlexNet, так что я получу результаты для одного и того же изображения из двух отдельных моделей нейронных сетей, которые были обучены на одном и том же наборе изображений.
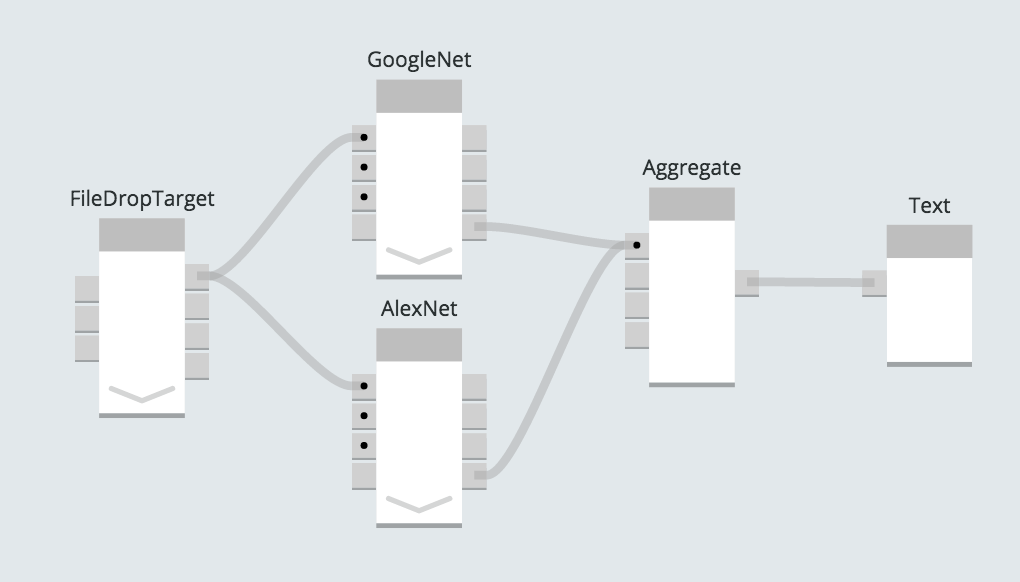
Компонент AlexNet отличается от GoogleNet только тем, какой путь к файлу модели мы используем в коде.
Запустив одно и то же изображение через обе нейронные сети, мы получим:
 В общем, процесс написания кода и подключения компонентов занял у меня чуть меньше часа. Как я писал ранее, мы можем заменить любую модель нейронной сети Caffe и использовать ее через этот базовый Xap. Отсюда, я думаю, было бы интересно создать интерфейс обучения нейронной сети в виде Xap. Было бы полезно иметь хороший внешний интерфейс для обучения нейронных сетей, от указания количества скрытых слоев до составления и настройки этих скрытых слоев и визуализации результатов тестов новых моделей. Возможно, последующее сообщение в блоге будет в порядке, как только это будет сделано.
В общем, процесс написания кода и подключения компонентов занял у меня чуть меньше часа. Как я писал ранее, мы можем заменить любую модель нейронной сети Caffe и использовать ее через этот базовый Xap. Отсюда, я думаю, было бы интересно создать интерфейс обучения нейронной сети в виде Xap. Было бы полезно иметь хороший внешний интерфейс для обучения нейронных сетей, от указания количества скрытых слоев до составления и настройки этих скрытых слоев и визуализации результатов тестов новых моделей. Возможно, последующее сообщение в блоге будет в порядке, как только это будет сделано.