Kafka и ELK Stack — обычно эти два компонента являются частью одного архитектурного решения, а Kafka выступает в качестве буфера перед Logstash для обеспечения устойчивости. В этой статье рассматривается другая комбинация — использование стека ELK для сбора и анализа журналов Kafka.
Больше по теме:
- 9 инструментов с открытым исходным кодом DevOps, которые мы любим
- Анализ журнала MySQL с помощью стека ELK
- Интеграция Google Pub / Sub со стеком ELK
Как объяснялось в предыдущем посте , Кафка играет ключевую роль в нашей архитектуре. Таким образом, мы создали систему мониторинга, обеспечивающую передачу данных по конвейерам, как и ожидалось. Ключевые показатели производительности, такие как задержка и задержка, тщательно отслеживаются с использованием различных процессов и инструментов.
Другим элементом этой системы мониторинга являются журналы Kafka.
Kafka сгенерировал несколько типов файлов журналов, но мы обнаружили, что журналы сервера особенно полезны. Мы собираем эти журналы, используя Filebeat, добавляем поля метаданных и применяем конфигурации синтаксического анализа для анализа уровня журнала и класса Java.
В этой статье я предоставлю инструкции, необходимые для подключения ваших серверов Kafka к стеку ELK или Logz.io, чтобы вы могли настроить собственную систему регистрации для Kafka. Первые несколько шагов объясняют, как установить Kafka и протестировать его, чтобы сгенерировать некоторые примеры журналов сервера, но если у вас уже запущен и работает Kafka, просто перейдите к следующим шагам, которые включают установку стека ELK и настройку конвейера.
Установка Кафки
Java требуется для запуска и Kafka, и стека ELK, поэтому давайте начнем с установки Java:
sudo apt-get update
sudo apt-get install default-jreДалее, Apache Kafka использует ZooKeeper для хранения информации о конфигурации и синхронизации, поэтому нам нужно установить ZooKeeper перед настройкой Kafka:
sudo apt-get install zookeeperdПо умолчанию ZooKeeper прослушивает порт 2181. Вы можете проверить, выполнив следующую команду:
netstat -nlpt | grep ':2181'Далее давайте загрузим и распакуем Кафку:
wget http://apache.mivzakim.net/kafka/2.1.0/kafka_2.11-2.1.0.tgz
tar -xvzf kafka_2.12-2.1.0.tgz
sudo cp -r kafka_2.11-2.1.0 /opt/kafkaТеперь мы готовы запустить Kafka, что мы и сделаем с помощью этого скрипта:
sudo /opt/kafka/bin/kafka-server-start.sh
/opt/kafka/config/server.propertiesВы должны увидеть длинный список сообщений INFO, в конце которого появится сообщение об успешном запуске Kafka:
[2018-12-30 08:57:45,714] INFO Kafka version : 2.1.0 (org.apache.kafka.common.utils.AppInfoParser)
[2018-12-30 08:57:45,714] INFO Kafka commitId : 809be928f1ae004e (org.apache.kafka.common.utils.AppInfoParser)
[2018-12-30 08:57:45,716] INFO [KafkaServer id=0] started (kafka.server.KafkaServer)Поздравляю, у вас есть Кафка, которая работает и слушает порт 9092.
Тестирование вашего сервера Kafka
Давайте возьмем Кафку для простого пробного запуска.
Сначала создайте свою первую тему с одним разделом и одной репликой (у нас только один сервер Kafka) с помощью следующей команды:
/opt/kafka/bin/kafka-topics.sh --create --zookeeper localhost:2181
--replication-factor 1 --partitions 1 --topic danielTestВы должны увидеть следующий вывод:
Created topic "danielTest"Используя производителя консоли, мы теперь опубликуем несколько примеров сообщений в нашей недавно созданной теме Kafka:
/opt/kafka/bin/kafka-console-producer.sh --broker-list
localhost:9092 --topic danielTestВ командной строке введите несколько сообщений по теме:
>This is just a test
>Typing a message
>OKТеперь на отдельной вкладке мы запустим потребительскую команду Kafka для чтения данных из Kafka и отображения сообщений, которые мы отправили в тему на стандартный вывод.
/opt/kafka/bin/kafka-console-consumer.sh --bootstrap-server
localhost:9092 --topic danielTest --from-beginningВы должны увидеть те же сообщения, которые вы отправили в отображаемую тему:
This is just a test
Typing a message
OKУстановка стека ELK
Теперь, когда мы убедились, что механизм публикации / подписки работает, давайте установим компоненты для его регистрации — Elasticsearch, Kibana и Filebeat.
Начните с загрузки и установки открытого ключа подписи Elastic:
wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo
apt-key add -Добавьте определение хранилища:
echo "deb https://artifacts.elastic.co/packages/6.x/apt stable main" |
sudo tee -a /etc/apt/sources.list.d/elastic-6.x.listОбновите систему и установите Elasticsearch:
sudo apt-get update && sudo apt-get install elasticsearchЗапустите Elasticsearch, используя:
sudo service elasticsearch startВы можете убедиться, что Elasticsearch запущен, используя следующий cURL:
curl "http://localhost:9200"Вы должны увидеть вывод, похожий на этот:
{
"name" : "6YVkfM0",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "8d8-GCYiQoOQMJdDrzugdg",
"version" : {
"number" : "6.5.4",
"build_flavor" : "default",
"build_type" : "deb",
"build_hash" : "d2ef93d",
"build_date" : "2018-12-17T21:17:40.758843Z",
"build_snapshot" : false,
"lucene_version" : "7.5.0",
"minimum_wire_compatibility_version" : "5.6.0",
"minimum_index_compatibility_version" : "5.0.0"
},
"tagline" : "You Know, for Search"
}Далее мы собираемся установить Kibana с:
sudo apt-get install kibanaОткройте файл конфигурации Kibana по адресу: /etc/kibana/kibana.yml и убедитесь, что у вас определена следующая конфигурация:
server.port: 5601
elasticsearch.url: "http://localhost:9200"И начните Kibana с:
sudo service kibana startЧтобы установить Filebeat, используйте:
sudo apt install filebeatКонфигурирование конвейера
Я опишу два способа доставки журналов Kafka в стек ELK — один, если вы используете Logz.io, другой для отправки их в ваше собственное развертывание ELK.
Доставка в Logz.io
Для отправки данных в Logz.io требуются некоторые настройки в файле конфигурации Filebeat. Поскольку наши слушатели обрабатывают синтаксический анализ, в этом случае нет необходимости использовать Logstash.
Во-первых, вам нужно скачать сертификат SSL для использования шифрования:
wget https://raw.githubusercontent.com/logzio/public-certificates/master/
COMODORSADomainValidationSecureServerCA.crt
sudo mkdir -p /etc/pki/tls/certs
sudo cp COMODORSADomainValidationSecureServerCA.crt
/etc/pki/tls/certs/Файл конфигурации должен выглядеть следующим образом:
filebeat.inputs:
- type: log
paths:
- /opt/kafka/logs/server.log
fields:
logzio_codec: plain
token: <yourAccountToken>
type: kafka_server
env: dev
fields_under_root: true
encoding: utf-8
ignore_older: 3h
multiline:
pattern: '\[[0-9]{4}-[0-9]{2}-[0-9]{2} [0-9]{2}:[0-9]{2}:[0-9]{2},[0-9]{3}\] ([A-a]lert|ALERT|[T|t]race|TRACE|[D|d]ebug|DEBUG|[N|n]otice|NOTICE|[I|i]nfo|INFO|[W|w]arn?(?:ing)?|WARN?(?:ING)?|[E|e]rr?(?:or)?|ERR?(?:OR)?|[C|c]rit?(?:ical)?|CRIT?(?:ICAL)?|[F|f]atal|FATAL|[S|s]evere|SEVERE|EMERG(?:ENCY)?|[Ee]merg(?:ency)?)'
negate: true
match: after
registry_file: /var/lib/filebeat/registry
output:
logstash:
hosts: ["listener.logz.io:5015"]
ssl:
certificate_authorities: ['/etc/pki/tls/certs/COMODORSADomainValidationSecureServerCA.crt']
processors:
- add_host_metadata: ~
- add_cloud_metadata: ~Несколько замечаний о конфигурации:
- Ваш токен учетной записи Logz.io можно получить на странице «Общие настройки» в Logz.io (щелкните зубчатое колесо в правом верхнем углу).
- Обязательно используйте kafka_server в качестве типа журнала для автоматического разбора.
- Я рекомендую проверить YAML перед запуском Filebeat. Вы можете использовать этот онлайн-инструмент . Или вы можете использовать мастер Filebeat для автоматической генерации файла YAML (доступно в разделе Filebeat, в разделе Доставка журналов в пользовательском интерфейсе).
Сохраните файл и запустите Filebeat с:
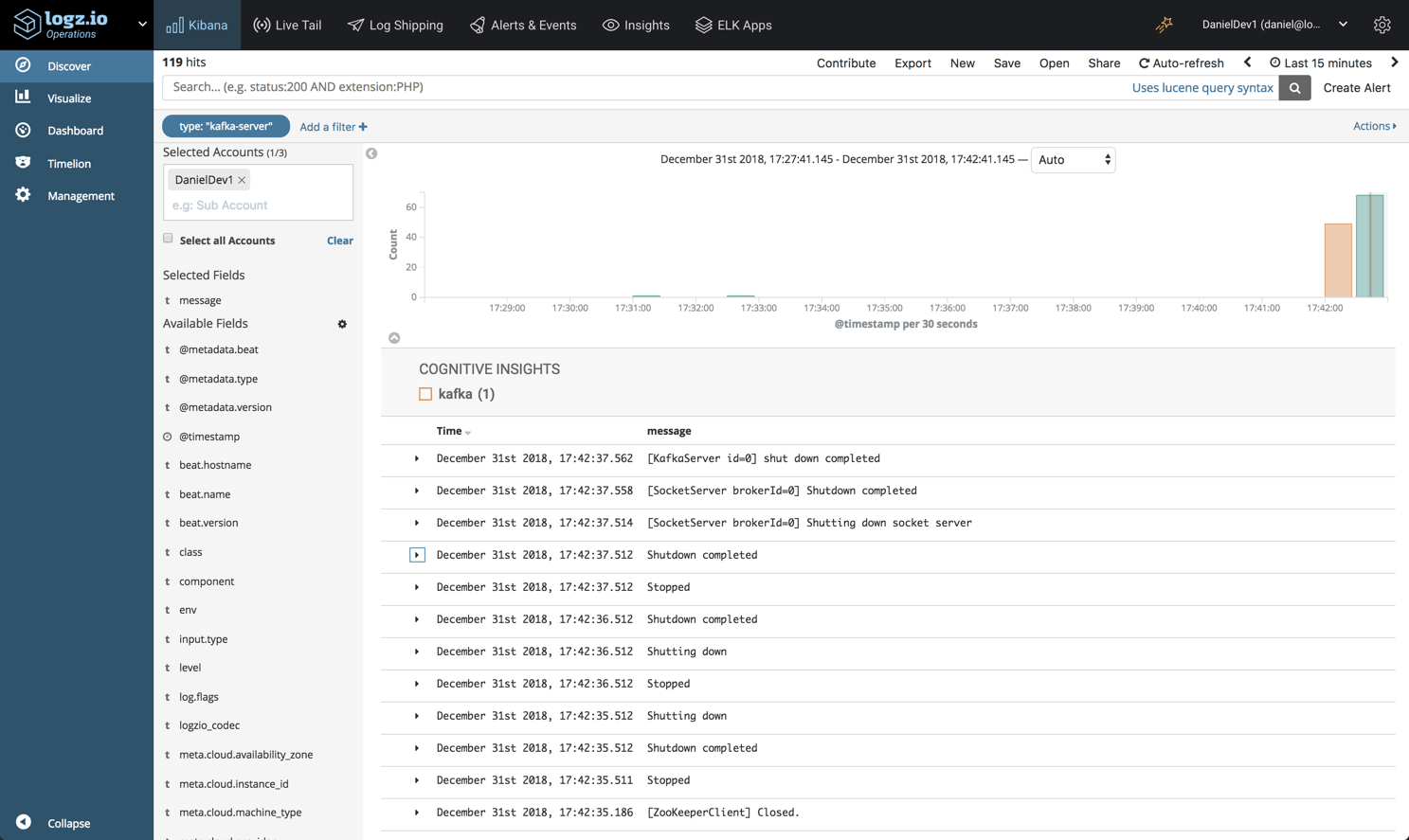
sudo service filebeat startВы должны начать видеть журналы вашего сервера Kafka, появляющиеся в Logz.io через минуту или две:
Доставка в ELK
Для отправки журналов сервера Kafka в ваш собственный ELK вы можете использовать модуль Kafka Filebeat. Модуль собирает данные, анализирует их и определяет шаблон индекса Elasticsearch в Kibana.
Чтобы использовать модуль, сначала определите путь к файлам журнала:
sudo vim /etc/filebeat/modules.d/kafka.yml.disabled
- module: kafka
log:
enabled: true
#var.kafka_home:
var.paths:
- "/opt/kafka/logs/server.log"
Включите модуль и настройте среду с помощью:
sudo filebeat modules enable kafka
sudo filebeat setup -eИ последнее, но не менее важное: перезапустите Filebeat с помощью:
sudo service filebeat restartЧерез минуту или две, открыв Kibana, вы обнаружите, что индекс «filebeat- *» определен, а журналы сервера Kafka отображаются на странице Discover:

Анализ данных
Итак — что мы ищем? Что можно сделать с журналами сервера Kafka?
Анализ, примененный к журналам, анализирует некоторые важные поля, в частности, уровень журнала и класс Kafka и компонент журнала, генерирующий журнал. Мы можем использовать эти поля для мониторинга и устранения неполадок Кафки различными способами.
Например, мы могли бы создать простую визуализацию для отображения количества серверов Kafka, на которых мы работаем:

Или мы можем создать визуализацию, дающую нам разбивку различных журналов по уровням:

Аналогично, мы могли бы создать визуализацию, показывающую разбивку более многословных компонентов Kafka:

В конце концов, вы поместите эти и другие визуализации в одну панель мониторинга ваших экземпляров Kafka:

Сноски
Как и любой другой компонент в вашем стеке, Kafka должен регистрироваться и контролироваться. В Logz.io мы используем многоуровневую систему мониторинга, которая включает метрики и журналы, чтобы убедиться, что наши конвейеры данных функционируют должным образом.
Как уже упоминалось, журналы сервера Kafka — это только один тип журналов, которые генерирует Kafka, поэтому вы можете изучить возможность отправки других типов в ELK для анализа. В любом случае, ELK — это мощный инструмент анализа, который поможет вам в трудные времена.
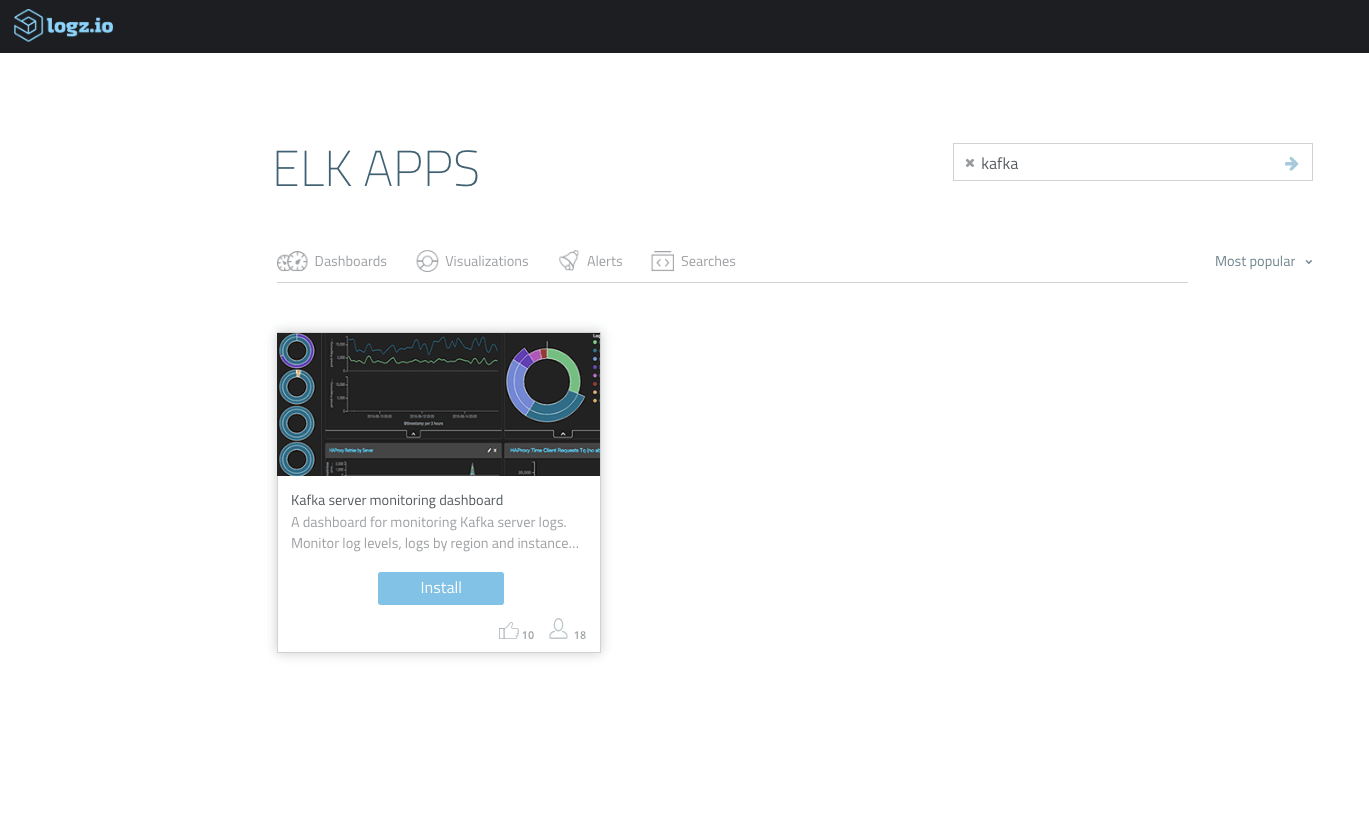
Приведенная выше панель управления доступна для использования в приложениях ELK — библиотеке панелей и визуализаций Logz.io. Чтобы развернуть его, просто откройте ELK Apps и выполните поиск «Kafka».