Я хочу продемонстрировать, как вы можете получить дамп Stack Overflow и быстро импортировать его в Neo4j. После этого вы готовы начать запрашивать график для получения дополнительной информации, а затем, возможно, создать приложение поверх этого набора данных. Если вы хотите следовать, у нас есть работающий (только для чтения) сервер Neo4j с данными, доступными здесь .
Но обо всем по порядку : поздравляем Stack Overflow с тем, что он такой классный и полезный. Недавно они объявили, что на их сайте даны ответы на более чем 10 миллионов вопросов программирования (и их количество). (Они также раздают бесплатно хештег #SOreadytohelp . Подробнее об этом ниже.)
Без платформы переполнения стека многие вопросы, связанные с Neo4j, никогда не могли бы быть заданы или даны ответы. Мы по-прежнему рады, что начали уходить из групп Google для нашей общественной поддержки пользователей.
Сообщество Neo4j на Stack Overflow сильно выросло, как и количество вопросов там.

(и это график)
Импорт данных переполнения стека в Neo4j
Импорт миллионов вопросов, пользователей, ответов и комментариев по Stack Overflow в Neo4j был моей давней целью. Одно из отвлекающих факторов, которые мешали мне это сделать, — это ответить на многие из 8 200 вопросов Neo4j .
Две недели назад Дэмиен из Linkurious обзвонил меня в нашем общедоступном канале Slack . Он спросил о производительности импорта Neo4j для загрузки полного дампа данных Stack Exchange в Neo4j.
После быстрого обсуждения я указал ему на инструмент импорта CSV Neo4j , который идеально подходит для этой задачи, поскольку дамп состоит только из реляционных таблиц, завернутых в XML.
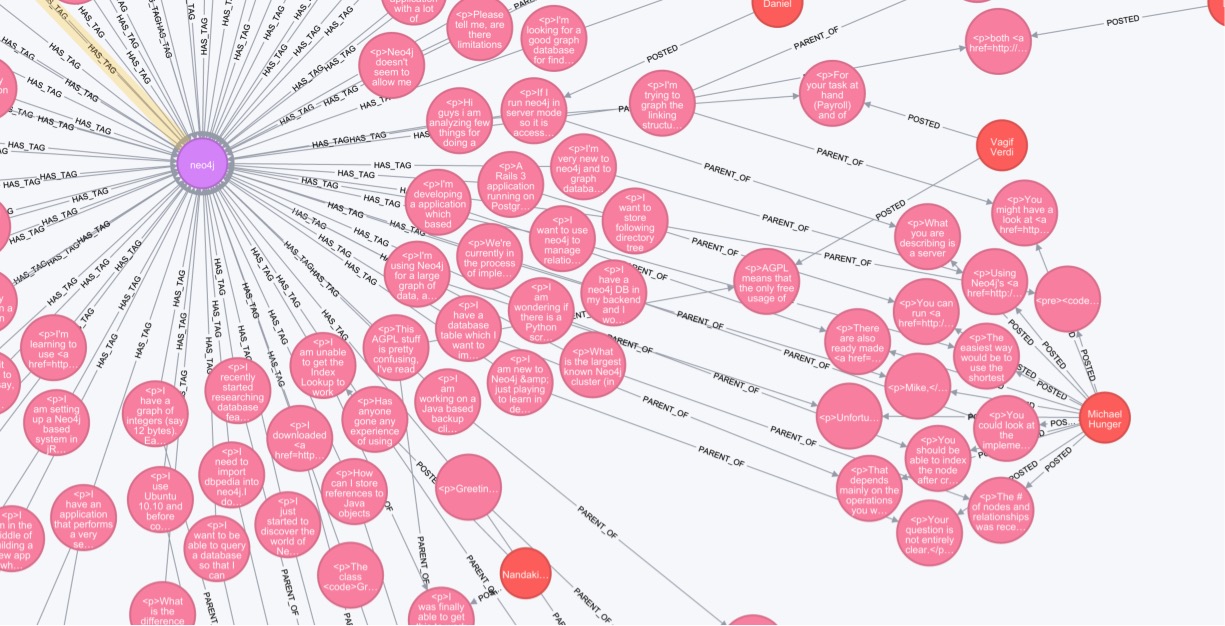
Поэтому Дэмиен написал небольшой скрипт на Python для извлечения CSV из XML, и с необходимыми заголовками инструмент neo4j-importin сделал основную работу по созданию графа из огромных таблиц. Вы можете найти скрипт и инструкции по GitHub здесь .
Импортирование небольших данных сообщества Stack Exchange занимает всего несколько секунд. Удивительно, но полный дамп Stack Overflow с пользователями, вопросами и ответами занимает 80 минут для преобразования обратно в CSV, а затем всего 3 минуты для импорта в Neo4j на обычном ноутбуке с SSD.
Вот как мы это сделали:
Скачать файлы дампов стека
Сначала мы загрузили файлы дампа из интернет-архива для сообщества Stack Overflow (всего 11 ГБ) в каталог:
- 7.3G stackoverflow.com-Posts.7z
- 576K stackoverflow.com-Tags.7z
- 154M stackoverflow.com-Users.7z
Другие данные могут быть импортированы отдельно, если мы хотим:
- 91M stackoverflow.com-Badges.7z
- 2.0G stackoverflow.com-Комментарии.7z
- 36M stackoverflow.com-PostLinks.7z
- 501M stackoverflow.com-Голосов.7z
Распакуйте файлы .7z
for i in *.7z; do 7za -y -oextracted x $i; done
Это извлекает файлы в
extracted
каталог и занимает 20 минут и использует 66 ГБ на диске.
Клон Дэмиена GitHub хранилище
Следующим шагом было клонирование репозитория Damien’s GitHub:
git clone https://github.com/mdamien/stackoverflow-neo4j
Примечание: эта команда использует Python 3 , поэтому вам нужно установить
xmltodict
sudo apt-get install python3-setuptools
easy_install3 xmltodict
Запустите преобразование XML в CSV
После этого мы запустили преобразование XML в CSV.
python3 to_csv.py extracted
Преобразование длилось 80 минут в моей системе и привело к 9,5 ГБ CSV-файлов, которые были сжаты до 3,4 ГБ.
Это структура данных, импортированная в Neo4j. Строки заголовка файлов CSV обеспечивают сопоставление.
Узлы:
posts.csv
postId:ID(Post),title,postType:INT,createdAt,score:INT,views:INT,
answers:INT,comments:INT,favorites:INT,updatedAt,body
users.csv userId:ID(User),name,reputation:INT,createdAt,accessedAt,url,location,
views:INT,upvotes:INT,downvotes:INT,age:INT,accountId:INT
tags.csv
tagId:ID(Tag),count:INT,wikiPostId:INT
Отношения:
posts_answers.csv:ANSWER -> :START_ID(Post),:END_ID(Post)
posts_rel.csv:PARENT_OF -> :START_ID(Post),:END_ID(Post)
tags_posts_rel.csv:HAS_TAG -> :START_ID(Post),:END_ID(Tag)
users_posts_rel.csv:POSTED -> :START_ID(User),:END_ID(Post)
Импорт в Neo4j
Затем мы использовали инструмент импорта Neo4j
neo/bin/neo4j-import
to ingest Posts, Users, Tags and the relationships between them.
../neo/bin/neo4j-import \
--into ../neo/data/graph.db \
--id-type string \
--nodes:Post csvs/posts.csv \
--nodes:User csvs/users.csv \
--nodes:Tag csvs/tags.csv \
--relationships:PARENT_OF csvs/posts_rel.csv \
--relationships:ANSWER csvs/posts_answers.csv \
--relationships:HAS_TAG csvs/tags_posts_rel.csv \
--relationships:POSTED csvs/users_posts_rel.csv
The actual import only takes 3 minutes, creating a graph store of 18 GB.
IMPORT DONE in 3m 48s 579ms. Imported:
31138559 nodes
77930024 relationships
260665346 properties
Neo4j Configuration
We then wanted to adapt Neo4j’s config in
conf/neo4j.properties
to increase the
dbms.pagecache.memory
option to 10G. We also edited the
conf/neo4j-wrapper.conf
to provide some more heap, like 4G or 8G.
Then we started the Neo4j server with
../neo/bin/neo4j start
Adding Indexes
We then had the option of running the next queries either directly in Neo4j’s server UI or on the command-line with
../neo/bin/neo4j-shell
which connects to the running server.
Here’s how much data we had in there:
neo4j-sh (?)$ match (n) return head(labels(n)) as label, count(*);
+-------------------+
| label | count(*) |
+-------------------+
| "Tag" | 41719 |
| "User" | 4551115 |
| "Post" | 26545725 |
+-------------------+
3 rows
Next, we created some indexes and constraints for later use:
create index on :Post(title);
create index on :Post(createdAt);
create index on :Post(score);
create index on :Post(views);
create index on :Post(favorites);
create index on :Post(answers);
create index on :Post(score);
create index on :User(name);
create index on :User(createdAt);
create index on :User(reputation);
create index on :User(age);
create index on :Tag(count);
create constraint on (t:Tag) assert t.tagId is unique;
create constraint on (u:User) assert u.userId is unique;
create constraint on (p:Post) assert p.postId is unique;
We then waited for the indexes to be finished.
schema await
Please note: Neo4j as a graph database wasn’t originally built for these global-aggregating queries. That’s why the responses are not instant.
Getting Insights with Cypher Queries
Below are just some of the insights we gleaned from the Stack Overflow data using Cypher queries:
The Top 10 Stack Overflow Users
match (u:User)
with u,size( (u)-[:POSTED]->()) as posts order by posts desc limit 10
return u.name, posts;
+---------------------------+
| u.name | posts |
+---------------------------+
| "Jon Skeet" | 32174 |
| "Gordon Linoff" | 20989 |
| "Darin Dimitrov" | 20871 |
| "BalusC" | 16579 |
| "CommonsWare" | 15493 |
| "anubhava" | 15207 |
| "Hans Passant" | 15156 |
| "Martijn Pieters" | 14167 |
| "SLaks" | 14118 |
| "Marc Gravell" | 13400 |
+---------------------------+
10 rows
7342 ms
The Top 5 tags That Jon Skeet Used in Asking Questions
It seems he never really asked questions, but only answered.
match (u:User)-[:POSTED]->()-[:HAS_TAG]->(t:Tag)
where u.name = "Jon Skeet"
return t,count(*) as posts order by posts desc limit 5;
+------------------------------------------------+
| t | posts |
+------------------------------------------------+
| Node[31096861]{tagId:"c#"} | 14 |
| Node[31096855]{tagId:".net"} | 7 |
| Node[31101268]{tagId:".net-4.0"} | 4 |
| Node[31118174]{tagId:"c#-4.0"} | 4 |
| Node[31096911]{tagId:"asp.net"} | 3 |
+------------------------------------------------+
10 rows
36 ms
The Top 5 Tags that BalusC Answered
match (u:User)-[:POSTED]->()-[:HAS_TAG]->(t:Tag)
where u.name = "BalusC"
return t.tagId,count(*) as posts order by posts desc limit 5;
+------------------------+
| t.tagId | posts |
+------------------------+
| "java" | 5 |
| "jsf" | 3 |
| "managed-bean" | 2 |
| "eclipse" | 2 |
| "cdi" | 2 |
+------------------------+
5 rows
23 ms
How am I Connected to Darin Dimitrov?
MATCH path = allShortestPaths(
(u:User {name:"Darin Dimitrov"})-[*]-(me:User {name:"Michael Hunger"}))
RETURN path;
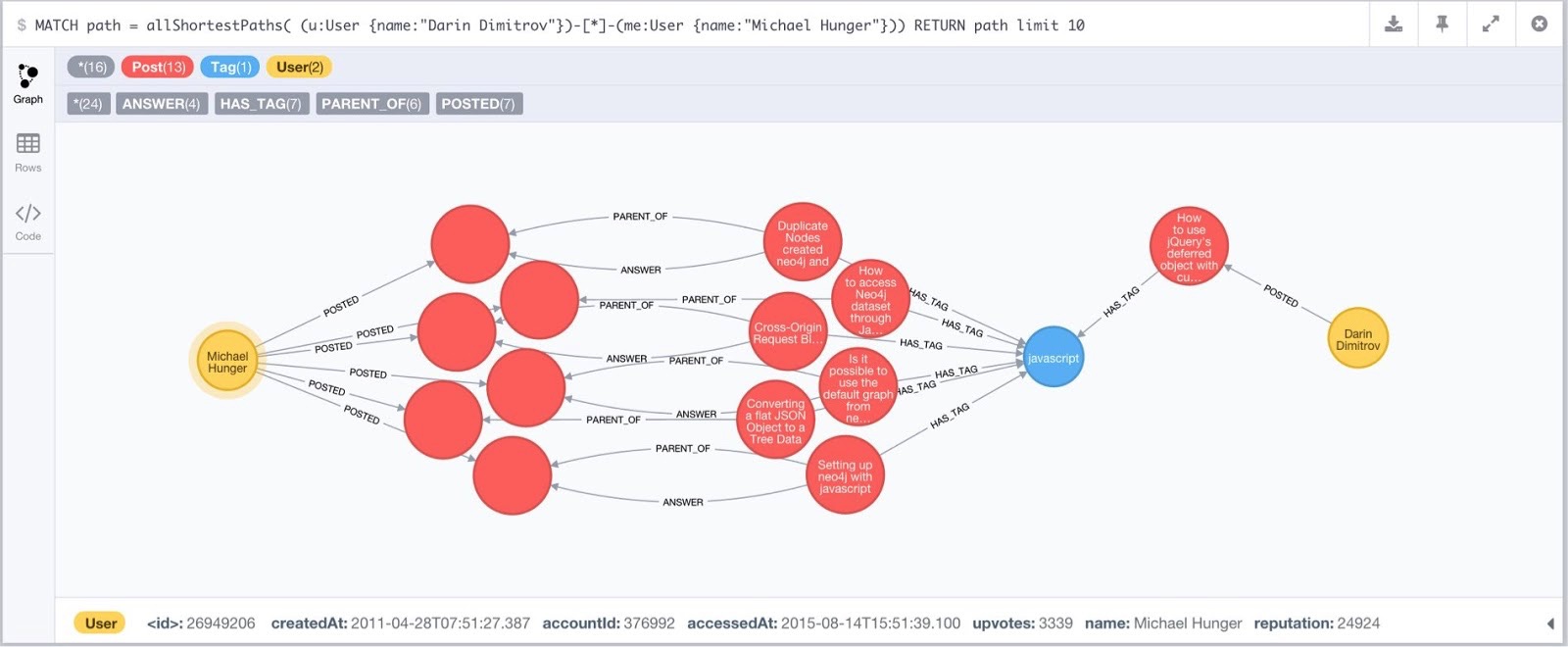
Result Visualisation in Neo4j Browser
Which Mark Answered the Most Questions about neo4j?
MATCH (u:User)-[:POSTED]->(answer)<-[:PARENT_OF]-()-[:HAS_TAG]-(:Tag {tagId:"neo4j"})
WHERE u.name like "Mark %"
RETURN u.name, u.reputation,u.location,count(distinct answer) AS answers
ORDER BY answers DESC;
+--------------------------------------------------------------------------+
| u.name | u.reputation | u.location | answers |
+--------------------------------------------------------------------------+
| "Mark Needham" | 1352 | "United Kingdom" | 36 |
| "Mark Leighton Fisher" | 4065 | "Indianapolis, IN" | 3 |
| "Mark Byers" | 377313 | "Denmark" | 2 |
| "Mark Whitfield" | 899 | <null> | 1 |
| "Mark Wojciechowicz" | 1473 | <null> | 1 |
| "Mark Hughes" | 586 | "London, UK" | 1 |
| "Mark Mandel" | 859 | "Melbourne, Australia" | 1 |
| "Mark Jackson" | 56 | "Atlanta, GA" | 1 |
+--------------------------------------------------------------------------+
8 rows
38 ms

Top 20 paths rendered as graph
The Top 5 Tags of All Time
match (t:Tag)
with t order by t.count desc limit 5
return t.tagId, t.count;
+------------------------+
| t.tagId | t.count |
+------------------------+
| "javascript" | 917772 |
| "java" | 907289 |
| "c#" | 833458 |
| "php" | 791534 |
| "android" | 710585 |
+------------------------+
5 rows
30 ms
Co-occurrence of the javascript Tag
match (t:Tag {tagId:"javascript"})<-[:HAS_TAG]-()-[:HAS_TAG]->(other:Tag)
WITH other, count(*) as freq order by freq desc limit 5
RETURN other.tagId,freq;
+----------------------+
| other.tagId | freq |
+----------------------+
| "jquery" | 318868 |
| "html" | 165725 |
| "css" | 76259 |
| "php" | 65615 |
| "ajax" | 52080 |
+----------------------+
5 rows
The Most Active Answerers for the neo4j Tag
Quick aside: Thank you to everyone who answered Neo4j questions!
match (t:Tag {tagId:"neo4j"})<-[:HAS_TAG]-()
-[:PARENT_OF]->()<-[:POSTED]-(u:User)
WITH u, count(*) as freq order by freq desc limit 10
RETURN u.name,freq;
+-------------------------------+
| u.name | freq |
+-------------------------------+
| "Michael Hunger" | 1352 |
| "Stefan Armbruster" | 760 |
| "Peter Neubauer" | 308 |
| "Wes Freeman" | 277 |
| "FrobberOfBits" | 277 |
| "cybersam" | 277 |
| "Luanne" | 235 |
| "Christophe Willemsen" | 190 |
| "Brian Underwood" | 169 |
| "jjaderberg" | 161 |
+-------------------------------+
10 rows
45 ms
Where Else Were the Top Answerers Also Active?
MATCH (neo:Tag {tagId:"neo4j"})<-[:HAS_TAG]-()
-[:PARENT_OF]->()<-[:POSTED]-(u:User)
WITH neo,u, count(*) as freq order by freq desc limit 10
MATCH (u)-[:POSTED]->()<-[:PARENT_OF]-(p)-[:HAS_TAG]->(other:Tag)
WHERE NOT (p)-[:HAS_TAG]->(neo)
WITH u,other,count(*) as freq2 order by freq2 desc
RETURN u.name,collect(distinct other.tagId)[1..5] as tags;
+----------------------------------------------------------------------------------------+
| u.name | tags |
+----------------------------------------------------------------------------------------+
| "cybersam" | ["java","javascript","node.js","arrays"] |
| "Luanne" | ["spring-data-neo4j","java","cypher","spring"] |
| "Wes Freeman" | ["go","node.js","java","php"] |
| "Peter Neubauer" | ["graph","nosql","data-structures","java"] |
| "Brian Underwood" | ["ruby-on-rails","neo4j.rb","ruby-on-rails-3","activerecord"] |
| "Michael Hunger" | ["spring-data-neo4j","nosql","cypher","graph-databases"] |
| "Christophe Willemsen" | ["php","forms","doctrine2","sonata"] |
| "Stefan Armbruster" | ["groovy","intellij-idea","tomcat","grails-plugin"] |
| "FrobberOfBits" | ["python","xsd","xml","django"] |
| "jjaderberg" | ["vim","logging","python","maven"] |
+----------------------------------------------------------------------------------------+
10 rows
84 ms
Note that this Cypher query above contains the equivalent of 14 SQL joins.
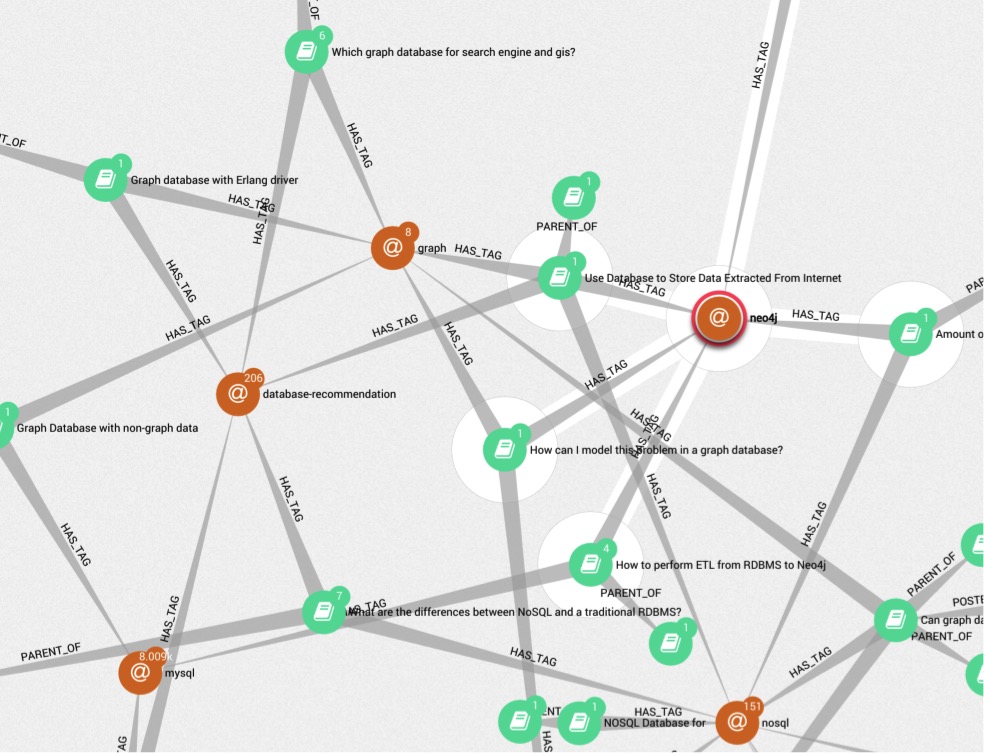
Rendered in Linkurious Visualizer
People Who Posted the Most Questions About Neo4j
MATCH (t:Tag {tagId:'neo4j'})<-[:HAS_TAG]-(:Post)<-[:POSTED]-(u:User)
RETURN u.name,count(*) as count
ORDER BY count DESC LIMIT 10;
+------------------------+
| c.name | count |
+------------------------+
| "LDB" | 39 |
| "deemeetree" | 39 |
| "alexanoid" | 38 |
| "MonkeyBonkey" | 35 |
| "Badmiral" | 35 |
| "Mik378" | 27 |
| "Kiran" | 25 |
| "red-devil" | 24 |
| "raHul" | 23 |
| "Sovos" | 23 |
+------------------------+
10 rows
42 ms
The Top Answerers for the py2neo Tag
MATCH (:Tag {tagId:'py2neo'})<-[:HAS_TAG]-()-[:PARENT_OF]->()
<-[:POSTED]-(u:User)
RETURN u.name,count(*) as count
ORDER BY count DESC LIMIT 10;
+--------------------------------+
| u.name | count |
+--------------------------------+
| "Nigel Small" | 88 |
| "Martin Preusse" | 24 |
| "Michael Hunger" | 22 |
| "Nicole White" | 9 |
| "Stefan Armbruster" | 8 |
| "FrobberOfBits" | 6 |
| "Peter Neubauer" | 5 |
| "Christophe Willemsen" | 5 |
| "cybersam" | 4 |
| "Wes Freeman" | 4 |
+--------------------------------+
10 rows
2 ms
Which Users Answered Their Own Question
This global graph query takes a bit of time as it touches 200 million paths in the database, it returns after about 60 seconds.
If you would want to execute it only on a subset of the 4.5M users you could add a filtering condition, e.g. on reputation.
MATCH (u:User) WHERE u.reputation > 20000
MATCH (u)-[:POSTED]->(question)-[:ANSWER]->(answer)<-[:POSTED]-(u)
WITH u,count(distinct question) AS questions
ORDER BY questions DESC LIMIT 5
RETURN u.name, u.reputation, questions;
+---------------------------------------------+
| u.name | u.reputation | questions |
+---------------------------------------------+
| "Stefan Kendall" | 31622 | 133 |
| "prosseek" | 31411 | 114 |
| "Cheeso" | 100779 | 107 |
| "Chase Florell" | 21207 | 99 |
| "Shimmy" | 29175 | 96 |
+---------------------------------------------+
5 rows
10 seconds
More Information
We’re happy to provide you with the graph database of the Stack Overflow dump here:
- Neo4j database dump for 2.3-SNAPSHOT or 2.2.4
- Running Neo4j Server to explore the data (read-only)
- CSV Files
If you want to learn about other ways to import or visualize Stack Overflow questions in Neo4j, please have a look at these blog posts:
- LOAD JSON from URL AS Data
- Making Master Data Management Fun with Neo4j
- Visualizing Stack Overflow
- Embrace Relationships with Neo4J, R & Java
- Please also check out the Stack Overflow developer survey. It’s a very interesting read.
Thanks again to everyone who posts and answers Neo4j questions. You’re the ones who make the Neo4j community really tick, and without you this level of analysis would only be half as much fun.
Circling back to Stack Overflow’s 10 million question milestone, thank YOU for being #SOreadytohelpwith any Stack Overflow questions related to Neo4j and Cypher.
Please let us know if you find other interesting questions and answers on this dataset. Just drop us an email to content@neo4j.com.