Это первое сообщение в блоге, в котором рассматриваются некоторые шаблоны организации данных в MapReduce. Мы рассмотрим, как объединить вывод для нескольких файлов в одной задаче, как объединить данные в несколько файлов, а также как объединить данные. Это все общие шаблоны, которые полезно иметь в вашем наборе инструментов MapReduce.
Мы начнем с рассмотрения вывода данных на вашей карте или сокращения задач. По умолчанию при использовании OutputFormat, производного от FileOutputFormat (например, TextOutputFormat), все выходные данные для задачи сокращения (или задачи карты в задании, состоящем только из карты) записываются в один файл в HDFS.
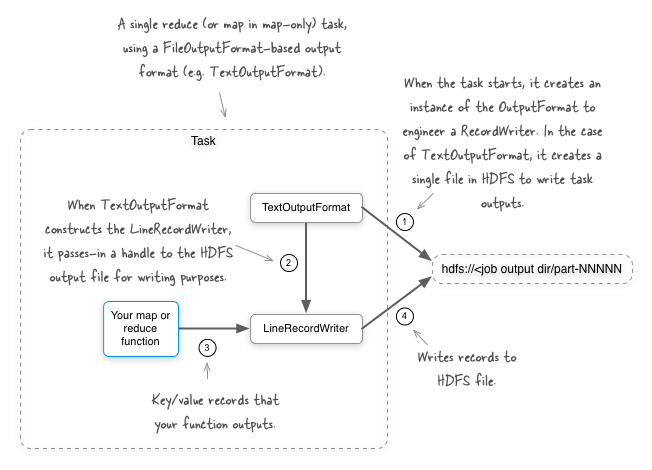
Представьте себе ситуацию, когда у вас есть журналы активности пользователей, передаваемые в HDFS, и вы хотите написать задание MapReduce, чтобы лучше организовать входящие данные. Например, крупная организация с несколькими продуктами может захотеть объединить журналы, основанные на продукте. Для этого вам понадобится возможность записи в несколько выходных файлов в одной задаче. Давайте посмотрим, как мы можем это сделать.
MultipleOutputFormat
Есть несколько способов достичь своей цели, и первый вариант, который мы рассмотрим, это MultipleOutputFormat класс в Hadoop. Это абстрактный класс, который позволяет вам делать следующее:
- Определите выходной путь для каждой записи ключа / значения, выдаваемой задачей.
- Включите входные пути в выходной каталог для заданий только для карт.
- Переопределите ключ и значение, которые используются для записи в базовый
RecordWriter. Это полезно в ситуациях, когда вы хотите удалить данные из выходных данных, поскольку они дублируют данные в имени файла. - Для каждого выходного пути определите,
RecordWriterчто следует использовать для записи выходных данных.
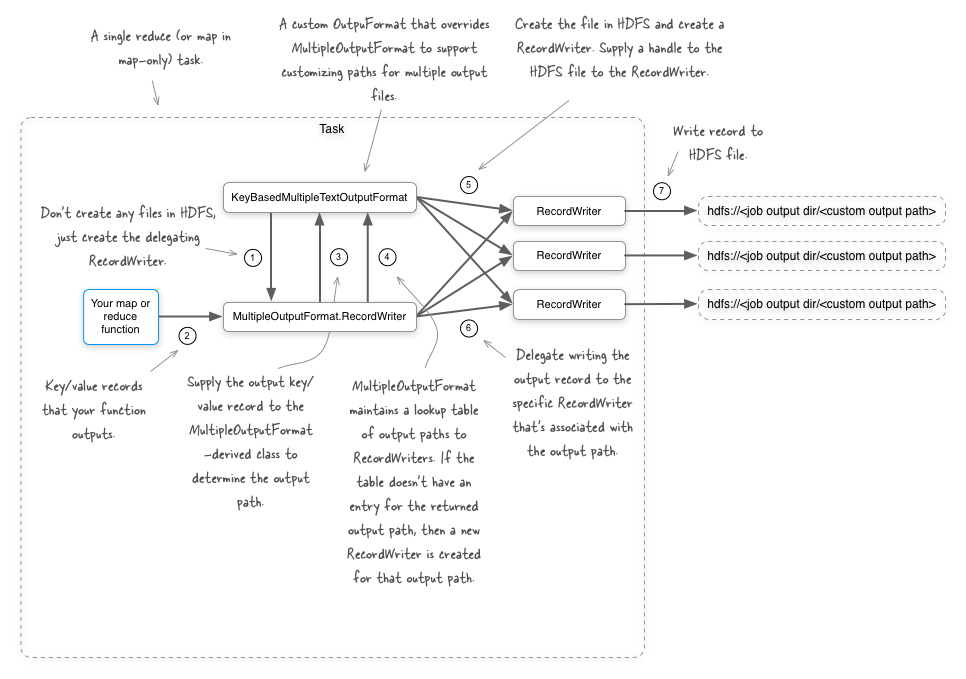
Достаточно хорошо со словами — давайте посмотрим на некоторые данные и код. Прежде всего, это простые данные, которые мы будем использовать в нашем примере — представьте, что вы работаете на фруктовом рынке с местоположениями в нескольких городах, и у вас есть поток транзакций покупки, который содержит местоположение магазина вместе с фруктами, которые были куплены.
cupertino apple
sunnyvale banana
cupertino pear
Чтобы упаковать свои данные для последующего анализа, вы хотите объединить каждую запись в файлы для конкретного города. Для простых данных, указанных выше, вы не хотите фильтровать, проецировать или преобразовывать свои данные, просто разбейте их на части, так что простое задание, состоящее только из карт идентификации, выполнит эту работу. Чтобы форсировать несколько картографов, мы запишем данные в два отдельных файла.
$ TAB="$(printf '\t')"
$ hdfs -put - file1.txt << EOF
cupertino${TAB}apple
sunnyvale${TAB}banana
EOF
$ hdfs -put - file2.txt << EOF
cupertino${TAB}pear
EOF
Вот код, который позволит вам создавать выходные файлы для конкретного города.
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.*;
import org.apache.hadoop.mapred.lib.IdentityMapper;
import org.apache.hadoop.mapred.lib.MultipleTextOutputFormat;
import org.apache.hadoop.util.Progressable;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import java.io.IOException;
import java.util.Arrays;
/**
* An example of how to use {@link org.apache.hadoop.mapred.lib.MultipleOutputFormat}.
*/
public class MOFExample extends Configured implements Tool {
/**
* Create output files based on the output record's key name.
*/
static class KeyBasedMultipleTextOutputFormat
extends MultipleTextOutputFormat<Text, Text> {
@Override
protected String generateFileNameForKeyValue(Text key, Text value, String name) {
return key.toString() + "/" + name;
}
}
/**
* The main job driver.
*/
public int run(final String[] args) throws Exception {
String csvInputs = StringUtils.join(Arrays.copyOfRange(args, 0, args.length - 1), ",");
Path outputDir = new Path(args[args.length - 1]);
JobConf jobConf = new JobConf(super.getConf());
jobConf.setJarByClass(MOFExample.class);
jobConf.setNumReduceTasks(0);
jobConf.setMapperClass(IdentityMapper.class);
jobConf.setInputFormat(KeyValueTextInputFormat.class);
jobConf.setOutputFormat(KeyBasedMultipleTextOutputFormat.class);
FileInputFormat.setInputPaths(jobConf, csvInputs);
FileOutputFormat.setOutputPath(jobConf, outputDir);
return JobClient.runJob(jobConf).isSuccessful() ? 0 : 1;
}
/**
* Main entry point for the utility.
*
* @param args arguments
* @throws Exception when something goes wrong
*/
public static void main(final String[] args) throws Exception {
int res = ToolRunner.run(new Configuration(), new MOFExample(), args);
System.exit(res);
}
}
Запустите этот код, и вы увидите следующие файлы в HDFS, где /output находится каталог вывода задания:
$ hadoop fs -lsr /output
/output/cupertino/part-00000
/output/cupertino/part-00001
/output/sunnyvale/part-00000
Если вы посмотрите на выходные файлы, вы увидите, что файлы содержат правильные сегменты.
$ hadoop fs -lsr /output/cupertino/*
cupertino apple
cupertino pear
$ hadoop fs -lsr /output/sunnyvale/*
sunnyvale banana
Круто, у вас есть данные, сгруппированные по магазинам. Теперь, когда у нас все работает, давайте посмотрим, что мы сделали, чтобы туда добраться. Мы должны были сделать две вещи, чтобы заставить это работать:
Расширить MultipleTextOutputFormat
Вот где произошло волшебство — давайте снова посмотрим на этот класс.
static class KeyBasedMultipleTextOutputFormat extends MultipleTextOutputFormat<Text, Text> {
@Override
protected String generateFileNameForKeyValue(Text key, Text value, String name) {
return key.toString() + "/" + name;
}
}
Вы работаете с текстом, поэтому вы расширили MultipleTextOutputFormatкласс, который в свою очередь расширяется MultipleOutputFormat. MultipleTextOutputFormat это простой класс, который инструктирует MultipleOutputFormat использовать его TextOutputFormat в качестве основного выходного формата для записи записей. Если бы вы использовали MultipleOutputFormat как есть, он ведет себя так, как если бы вы использовали обычный TextOutputFormat, то есть он будет записывать только в один выходной файл. Чтобы записать данные в несколько файлов, вы должны были расширить их, как в примере выше.
generateFileNameForKeyValue Метод позволяет вернуть выходной путь для ввода записи. Третий аргумент name— это исходное FileOutputFormatимя файла, созданное в форме «part-NNNNN», где «NNNNN» — это индекс задачи, чтобы обеспечить уникальность. Чтобы избежать конфликтов файлов, рекомендуется убедиться, что сгенерированные выходные пути являются уникальными, и использование исходного выходного файла, безусловно, является хорошим способом сделать это. В нашем примере мы используем ключ в качестве имени каталога, а затем записываем исходное FileOutputFormat имя файла в этом каталоге.
Укажите формат вывода
Следующий шаг был прост — укажите, что этот формат вывода должен использоваться для вашей работы:
jobConf.setOutputFormat(KeyBasedMultipleTextOutputFormat.class);
Ранее мы также упоминали, что вы можете использовать входной путь как часть выходного пути, который мы рассмотрим далее.
Использование входного имени файла как части выходного имени файла в заданиях только для карты
Что если мы хотим сохранить имя входного файла как часть имени выходного файла? Это работает только для заданий только на карте и может быть выполнено путем переопределения getInputFileBasedOutputFileName метода. Давайте посмотрим на следующий код, чтобы понять, как этот метод вписывается в общую последовательность действий, которые MultipleOutputFormat выполняет класс:
public void write(K key, V value) throws IOException {
// get the file name based on the key
String keyBasedPath = generateFileNameForKeyValue(key, value, myName);
// get the file name based on the input file name
String finalPath = getInputFileBasedOutputFileName(myJob, keyBasedPath);
// get the actual key
K actualKey = generateActualKey(key, value);
V actualValue = generateActualValue(key, value);
RecordWriter<K, V> rw = this.recordWriters.get(finalPath);
if (rw == null) {
// if we don't have the record writer yet for the final path, create
// one
// and add it to the cache
rw = getBaseRecordWriter(myFS, myJob, finalPath, myProgressable);
this.recordWriters.put(finalPath, rw);
}
rw.write(actualKey, actualValue);
};
getInputFileBasedOutputFileName Метод вызывается с выходом generateFileNameForKeyValue, который содержит наш уже настроенный файл вывода. KeyBasedMultipleTextOutputFormat Теперь наш новый можно обновить, чтобы переопределить getInputFileBasedOutputFileName и добавить исходное имя файла к имени файла:
static class KeyBasedMultipleTextOutputFormat extends MultipleTextOutputFormat {
@Override
protected String generateFileNameForKeyValue(Object key, Object value, String name) {
return key.toString() + "/" + name;
}
@Override
protected String getInputFileBasedOutputFileName(JobConf job, String name) {
String infilename = new Path(job.get("map.input.file")).getName();
return name + "-" + infilename;
}
Если вы работаете с измененным классом OutputFormat, вы увидите следующие файлы в HDFS, подтверждая, что входные имена файлов теперь объединяются до конца каждого выходного файла.
$ hadoop fs -lsr /output
/output/cupertino/part-00000-file1.txt
/output/cupertino/part-00001-file2.txt
/output/sunnyvale/part-00000-file1.txt
Реализация getInputFileBasedOutputFileName in MultipleOutputFormat не делает ничего интересного по умолчанию, но если вы установите значение mapred.outputformat.numOfTrailingLegsнастраиваемого в целое число больше 0, то getInputFileBasedOutputFileName часть пути ввода будет использоваться в качестве пути вывода.
Давайте посмотрим, что происходит, когда мы устанавливаем значение 1:
jobConf.setInt("mapred.outputformat.numOfTrailingLegs", 1);
Выходные файлы в HDFS теперь точно отражают входные файлы, используемые для работы:
$ hadoop fs -lsr /output
/output/file1.txt
/output/file2.txt
Если мы установим mapred.outputformat.numOfTrailingLegs значение 2, и наши входные файлы существуют в /inputsкаталоге, то наш выходной каталог будет выглядеть так:
$ hadoop fs -lsr /output
/output/input/file1.txt
/output/input/file2.txt
В основном, если вы продолжите увеличивать mapred.outputformat.numOfTrailingLegs, то MultipleOutputFormat продолжите идти вверх по родительским каталогам входного файла и использовать их в выходном пути.
Изменение выходного ключа и значения
Вполне возможно, что фактический ключ и значение, которое вы хотите выдать, отличаются от тех, которые использовались для определения выходного файла. В нашем примере мы взяли выходной ключ и записали в каталог, используя имя ключа. Если вы сделаете это, сохранение ключа в выходном файле может оказаться излишним. Как бы мы изменили выходную запись, чтобы ключ не записывался? MultipleOutputFormat спиной к generateActualKey методу
class KeyBasedMultipleTextOutputFormat extends MultipleTextOutputFormat<Text, Text> {
@Override
protected String generateFileNameForKeyValue(Text key, Text value, String name) {
return key.toString() + "/" + name;
}
@Override
protected Text generateActualKey(Text key, Text value) {
return null;
}
}
Возвращаемое значение из этого метода заменяет ключ, который передается в базовый RecordWriter, поэтому, если вы вернетесь, null как в примере выше, ключ не будет записан в файл.
$ hadoop fs -lsr /output/cupertino/*
apple
pear
$ hadoop fs -lsr /output/sunnyvale/*
banana
Вы можете получить тот же результат для выходного значения, переопределив generateActualValue метод.
Изменение RecordWriter
In our final step we’ll look at how you can leverage multiple RecordWriter classes for different output files. This is accomplished by overriding the getRecordWriter method. In the example below we’re leveraging the same TextOutputFormat for all the files, but it gives you a sense of what can be accomplished.
static class KeyBasedMultipleTextOutputFormat extends MultipleTextOutputFormat<Text, Text> {
@Override
protected String generateFileNameForKeyValue(Text key, Text value, String name) {
return key.toString() + "/" + name;
}
@Override
public RecordWriter<Text, Text> getRecordWriter(FileSystem fs, JobConf job, String name, Progressable prog) throws IOException {
if (name.startsWith("apple")) {
return new TextOutputFormat<Text, Text>().getRecordWriter(fs, job, name, prog);
} else if (name.startsWith("banana")) {
return new TextOutputFormat<Text, Text>().getRecordWriter(fs, job, name, prog);
}
return super.getRecordWriter(fs, job, name, prog);
}
}
Conclusion
When using MultipleOutputFormat, give some thought to the number of distinct files that each reducer will create. It would be prudent to plan your bucketing so that you have a relatively small number of files.
In this post we extended MultipleTextOutputFormat, which is a simple extension ofMultipleOutputFormat that supports text outputs. MultipleSequenceFileOutputFormat also exists to support SequenceFiles in a similar fashion.
So what are the shortcomings with the MultipleOutputFormat class?
- If you have a job that uses both map and reduce phases, then
MultipleOutputFormatcan’t be used in the map-side to write outputs. Of course,MultipleOutputFormatworks fine in map-only jobs. - All
RecordWriterclasses must support exactly the same output record types. For example, you wouldn’t be able to support a RecordWriter that emitted<IntWritable, Text>for one output file, and have another RecordWriter that emitted<Text, Text>. MultipleOutputFormatexists in themapredpackage, so it won’t work with a job that requires use of themapreducepackage.
All is not lost if you bump into either one of these issues, as you’ll discover in the next blog post.