Fluentd — это основанный на JSON сборщик журналов с открытым исходным кодом, изначально написанный в Treasure Data . Fluentd специально разработан для решения проблемы сбора больших данных .
Многие компании выбирают Hadoop Distributed Filesystem (HDFS) для хранения больших данных. [1] Однако до недавнего времени единственным интерфейсом API была Java. Это изменилось с новым интерфейсом WebHDFS, который позволяет пользователям взаимодействовать с HDFS через HTTP. [2]
В этом посте показано, как настроить Fluentd для получения данных по HTTP и загрузки их в HDFS через WebHDFS.
Механизм
На рисунке ниже показана архитектура высокого уровня.
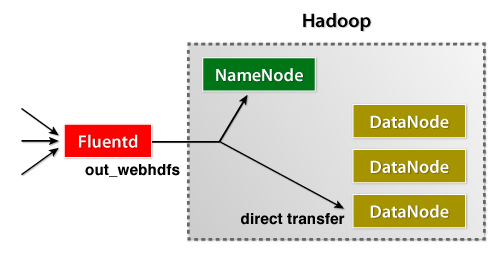
устанавливать
Для простоты в этом посте показана конфигурация с одним узлом. На этом же узле должно быть установлено следующее программное обеспечение.
- Fluentd с WebHDFS Plugin
- HDFS
Последняя версия пакета deb / rpm от Fluentd (v1.1.10 или новее) включает в себя плагин WebHDFS. Если вы хотите использовать Ruby Gems для установки плагина, gem install fluent-plugin-webhdfs сделайте свою работу.
- Пакет Debian
- RPM пакет
- Для CDH, пожалуйста, обратитесь к странице загрузки (CDH3u5 и CDH4 или позже)
Конфигурация Fluentd
Давайте настроим Fluentd. Если вы используете deb / rpm, файл конфигурации Fluentd находится по адресу /etc/td-agent/td-agent.conf. В противном случае он находится по адресу /etc/fluentd/fluentd.conf.
HTTP Input
Для ввода давайте настроим Fluentd для приема данных из HTTP. Вот как выглядит конфигурация Fluentd.
<source> type http port 8080 </source>
Вывод WebHDFS
Выходная конфигурация должна выглядеть так:
<match hdfs.access.**>
type webhdfs
host namenode.your.cluster.local
port 50070
path /log/%Y%m%d_%H/access.log.${hostname}
flush_interval 10s
</match>
Раздел соответствия определяет регулярное выражение для соответствия тегам. Если тег совпадает, то используется внутри него конфиг.
flush_internal указывает, как часто данные записываются в HDFS. Операция добавления используется для добавления входящих данных в файл, указанный path параметром.
Для значения pathможно использовать заполнители для времени и имени хоста (обратите внимание, как %Y%m%d_%H и ${hostname} как используются выше). Это предотвращает добавление данных в один файл несколькими экземплярами Fluentd, чего следует избегать при операции добавления.
Другие две опции, host и port, укажите имя узла хоста HDFS и порт соответственно.
Конфигурация HDFS
Добавить отключено по умолчанию. Пожалуйста, поместите эти конфигурации в свой hdfs-site.xml и перезапустите весь кластер.
<property> <name>dfs.webhdfs.enabled</name> <value>true</value> </property> <property> <name>dfs.support.append</name> <value>true</value> </property> <property> <name>dfs.support.broken.append</name> <value>true</value> </property>
Также, пожалуйста, убедитесь, что path указанный в выводе Fluentd WebHDFS настроен для записи пользователем hdfs.
Тест
Чтобы проверить настройки, просто отправьте JSON на Fluentd. В этом примере команда пользователей curl делает это.
$ curl -X POST -d 'json={"action":"login","user":2}' \
http://localhost:8080/hdfs.access.test
Затем, давайте перейдем к HDFS и посмотрим на сохраненные данные.
$ sudo -u hdfs hadoop fs -lsr /log/ drwxr-xr-x - 1 supergroup 0 2012-10-22 09:40 /log/20121022_14/access.log.dev
Успех!