На прошлой неделе я продемонстрировал, как настроить автозаполнение в новом приложении Rails 3.1, используя
драгоценный камень Soulmate от
SeatGeek . Soulmate использует Redis для кэширования всех автозаполненных фраз в памяти, обеспечивая молниеносные результаты запросов. Хотя автозаполнение является очень полезной функцией и общим элементом дизайна веб-сайта, в Soulmate меня по-настоящему интересуют идеи и подробные методики использования базы данных NoSQL
Redis для реализации поиска автозаполнения.
Сегодня я собираюсь взглянуть на два хороших примера создания поискового индекса с использованием Redis: я начну с оригинального алгоритма Сальваторе Санфилиппо для автозаполнения с Redis , который использует один отсортированный набор для хранения префиксов автозаполнения. Затем я посмотрю на решение Soulmate, которое также использует Redis, но дополнительно поддерживает сопоставление нескольких слов в фразе. Я надеюсь, что эти два примера вдохновят вас рассмотреть вопрос об использовании Redis в следующий раз, когда вам потребуется реализовать любую функцию, связанную с поиском, а не только автозаполнение.
 |
| Рассмотрим решение NoSQL, такое как Redis, в следующий раз, когда вам нужно будет выполнить поиск … |
Как автозаполнение традиционно реализовано с базой данных SQL
Ruby on Rails поддерживает автозаполнение в течение многих лет; Сам DHH написал оригинальный плагин автозаполнения несколько лет назад, и сегодня есть новый, современный гем под названием rails3-jquery-autocomplete . Автозаполнение использует Javascript для отображения списка доступных параметров, которые соответствуют первым буквам, которые вводит пользователь; например, вот поле автозаполнения, которое я реализовал на прошлой неделе в примере приложения Rails 3.1:
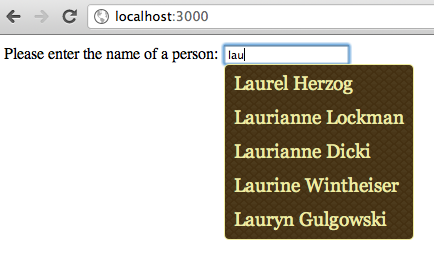
Традиционно в гемах и плагинах Rails это реализовано на сервере с помощью оператора SQL, подобного следующему:
SELECT first_name FROM people WHERE LOWER(name) LIKE "lau%"
Этот оператор SQL просит сервер базы данных просмотреть все строки в таблице «people» и найти только тех людей, чье имя начинается с заданных букв. Хотя это работает просто отлично, оно может значительно замедлиться, если у вас есть тысячи или миллионы записей, поскольку базе данных необходимо выполнить сравнение строк, чтобы найти правильные строки. Скорее всего, вам придется указать серверу базы данных создать индекс для поля first_name… и надеяться, что он поддерживает операции быстрого поиска строк с этим индексом.
Создание индекса автозаполнения с использованием отсортированного набора Redis
Сальваторе Санфилиппо (@antirez) , автор Redis, еще в сентябре 2010 года написал большую статью под названием « Автозаполнение с помощью Redis» , в которой показано, как использовать объект «Сортированный набор Redis» для реализации решения автозаполнения. Я настоятельно рекомендую вам прочитать его, чтобы получить все детали; он показывает реальное решение, реализованное с помощью Ruby, а также охватывает теорию информатики, стоящую за ее производительностью и использованием памяти.
Вместо того, чтобы полагаться на индекс сервера базы данных СУБД для поиска соответствующих терминов автозаполнения, Antirez реализует свой собственный индекс поиска с помощью Redis! Он заранее вычисляет все возможные префиксы, которые может набрать пользователь, а затем вставляет их все в объект Redis Sorted Set. Например, предположим, я хочу разрешить пользователям выбирать задачу из этого списка — мой список текущих дел на это утро:
- Вывезти мусор
- Поговорите с водителем школьного автобуса
Код Antirez сначала определит возможные префиксы или соответствующие комбинации букв, которые может ввести пользователь. В моем примере фразы задач начинаются со слов «take» и «talk», что дает нам следующие возможные префиксы:
т
та
Tak
принимать
тал
говорить
Затем Antirez добавляет эти префиксы в отсортированный набор с помощью команды Redis ZADD , например:
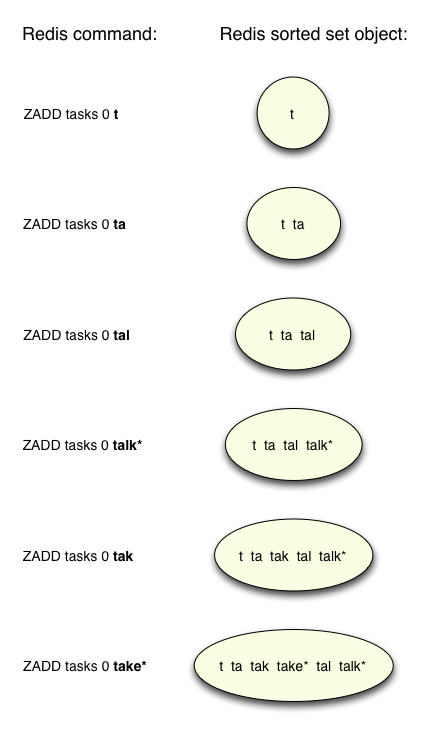
Наряду с префиксами вы, возможно, заметили, что Antirez также вставил в набор два фактических, полных слова, каждое из которых имеет символ звездочки в конце. Как мы увидим через мгновение, это позволяет коду Antirez позже находить полные слова, которые должны быть возвращены пользователю, в выпадающем списке автозаполнения.
Чтобы узнать больше о Redis Sorted Sets и всех доступных для них командах , смотрите redis.io , на котором есть прекрасно реализованная страница справочника по командам Redis . Ключевой концепцией сортированных наборов является то, что они выполняют сортировку во время вставки, то есть набор всегда сортируется, поскольку каждый элемент вставляется в нужное место в наборе.
Поиск отсортированного набора подходящих слов
Теперь предположим, что пользователь начинает вводить несколько букв в веб-форму: например, «ta». Код Antirez сможет найти подходящие слова «take» и «talk», используя следующие простые команды Redis:
redis 127.0.0.1:6379> ZRANK tasks ta (integer) 1
Команда ZRANK ищет заданный набор и возвращает индекс заданного значения. Здесь он будет возвращать 1, так как «ta» является вторым значением, а Redis использует индексы на основе 0.
redis 127.0.0.1:6379> ZRANGE tasks 1 50 1) "ta" 2) "tak" 3) "take*" 4) "tal" 5) "talk*"
ZRANGE возвращает 50 префиксов после «та», включая два полных слова «взять» и «говорить».
Код, который Antirez показывает в своем блоге, затем просматривает значения, возвращенные ZRANGE, в поисках завершающей звездочки, чтобы найти полные слова, которые соответствуют. Поскольку набор отсортирован, его код возвращает совпадающие слова в правильном порядке, отсортированном по алфавиту. Его код также делает дополнительные вызовы ZRANGE, если необходимо найти требуемое количество совпадающих полных слов.
Создание поискового индекса с использованием хэша Redis и нескольких отсортированных наборов
Алгоритм, используемый самоцветом Soulmate, похож и основан на решении Antirez. Однако SeatGeek использовал более сложный поисковый индекс, чтобы поддерживать автозаполнение для нескольких слов или фраз одновременно. Давайте посмотрим, как это работает дальше.
Во-первых, Soulmate создает объект Redis Hash и сохраняет все фразы автозаполнения путем многократного вызова команды HSET , например:

HSET очень прост: он сохраняет значение в объект Redis Hash, используя данный ключ. Это работает почти так же, как хэш Ruby, сохраняя данные в памяти. Вы заметите, что значение для каждого хеш-элемента кодируется с использованием JSON; Это удобный способ сериализации объектов Ruby в строку, а затем их сохранения в Redis. Soulmate называет хеш «soulmate-data: tasks», включая имя модели или тип данных в ключе / имени объекта Redis. Soulmate также использует общее соглашение об именовании Redis, заключающееся в использовании символа двоеточия для разделения различных слов, соединенных вместе в именах объектов Redis.
Как только все фразы сохранены в хэше Redis, Soulmate затем генерирует все возможные префиксы для всех слов, появляющихся в фразах, так же, как это делал Antirez выше, например:
Возьми: та так возьми
The: th
Автобус: бу автобус
Talk: TAL TALK
и т.д….
Затем Soulmate генерирует отдельный отсортированный набор для каждого уникального префикса, например:
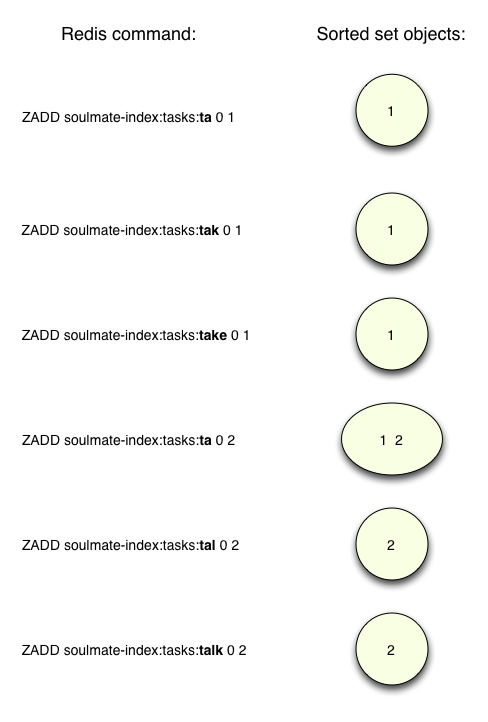
Вот что следует отметить:
- Для каждого префикса есть отдельный отсортированный набор.
- Каждый префикс содержится в самом имени набора, например, «soulmate-index: tasks: tak».
- Элементами наборов являются не префиксы, а ключи в хэше Redis, созданные выше и указывающие, какие фразы содержат каждый префикс.
- Второй параметр ZADD, ноль, здесь не используется, но может использоваться для установки порядка сортировки установленных элементов. Это называется «оценка».
Например, глядя на набор для префикса «tak», мы видим, что есть единственное значение «1», ключ в хэше выше для задачи «Убрать мусор». А для префикса «Та» есть два значения: «1» и «2», так как обе фразы содержат «Та» («Разговор» и «Возьми»). Я также пропустил много других префиксов, чтобы все было просто; Soulmate на самом деле вычисляет префиксы из всех слов в каждой фразе: «the», «bus», «driver», «trash» и т. Д. И создает дополнительные наборы для каждого из них.
Пересечение нескольких отсортированных наборов, чтобы найти соответствующие ключи хэша Redis
Создание всех этих различных отсортированных наборов позволяет Soulmate связывать несколько фраз с одним префиксом. Давайте посмотрим, как это работает: если пользователь начинает вводить «ta», то Soulmate просто нужно найти набор «soulmate-index: task: ta»:
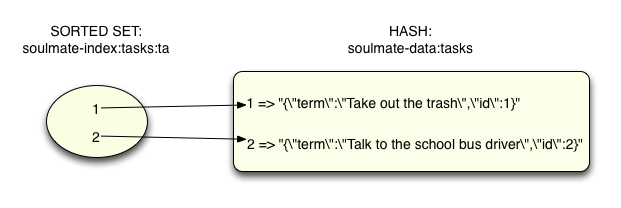
Теперь, вызвав команду ZRANGE, чтобы получить все элементы набора (0 означает начало с первого элемента, а -1 означает продолжение до конца)…
redis 127.0.0.1:6379> ZRANGE soulmate-index:tasks:ta 0 -1 1) "1" 2) "2"
… Soulmate может получить список значений ID, которые также являются ключами в хеше базы данных фраз. Наконец, Soulmate может загрузить соответствующие фразы и вернуть их, используя команду HMGET (hash множественное получение) :
redis 127.0.0.1:6379> HMGET soulmate-data:tasks 1 2
1) "{\"term\":\"Take out the trash\",\"id\":1}"
2) "{\"term\":\"Talk to the school bus driver\",\"id\":2}"
Все это происходит без единой команды SQL, и все значения данных извлекаются непосредственно из памяти, а не с диска!
Но это не все; Как я уже говорил выше, Soulmate также поддерживает возможность поиска нескольких префиксов одновременно. Например, предположим, что пользователь ввел «ta bus»… это означает, что он хочет соответствовать «Поговорите с водителем школьного автобуса», а не «Убрать мусор». Как это работает? Ну, Soulmate получит два отсортированных набора, один для «та» и один для «шины», например:
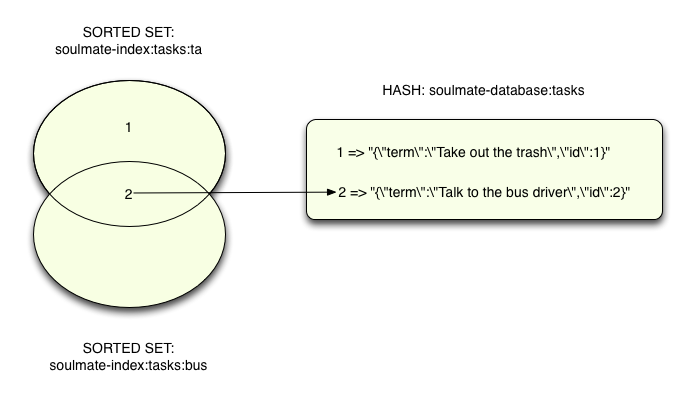
Здесь Soulmate использует команду Redis ZINTERSTORE для вычисления пересечения между двумя наборами:
redis 127.0.0.1:6379> ZINTERSTORE soulmate-cache:tasks:bus|ta 2
soulmate-index:tasks:ta soulmate-index:tasks:bus
(integer) 1
redis 127.0.0.1:6379> ZRANGE soulmate-cache:tasks:bus|ta 0 -1
1) "2"
Это создает третий набор под названием «soulmate-cache: tasks: bus | ta», содержащий только элементы, которые появляются в обоих первых двух наборах. ZINTERSTORE на самом деле поддерживает пересечение столько наборов, сколько вы хотите. Теперь Soulmate имеет значения идентификаторов фраз, которые соответствуют «ta» и «bus» — в данном случае 2, но не 1. Он использует имя «soulmate-cache: tasks: bus | ta», поскольку содержимое этого набора отражает какие фразы соответствуют «автобус» и «та».
Кэширование и устаревание значений с помощью Redis
Последнее волшебство в алгоритме Soulmate, о котором я расскажу сегодня, — это кэширование. Чтобы еще больше ускорить процесс, Soulmate сохраняет результат вызова ZINTERSTORE — третий набор, созданный с использованием общих элементов ID — для будущих поисков в случае, если один и тот же пользователь или другой пользователь снова введут одинаковые буквы. Вот как это работает:
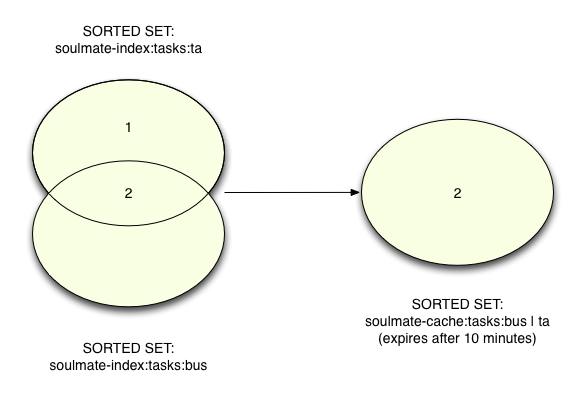
Набор пересечений был фактически сохранен выше при вызове ZINTERSTORE, и теперь, чтобы указать, что он истекает через 10 минут (600 секунд), мы будем использовать:
redis 127.0.0.1:6379> EXPIRE soulmate-cache:tasks:bus|ta 600 (integer) 1
Здесь нужно изучить две важные концепции Redis:
- Обратите внимание, как набор результатов пересечения помечается названием «soulmate-cache: tasks: ta | bus» — это распространенный шаблон Redis. Имена ключей могут быть длинными и сложными, часто могут содержать несколько значений, соединенных вместе. В этом случае два префикса, которые искал пользователь, содержат прямо в имени ключа, что позволяет Soulmate легко найти его при последующих вызовах.
- Для объектов Redis может быть установлено автоматическое истечение срока действия, что позволяет легко сохранять кэшированные значения в течение короткого времени, чтобы ускорить запросы, не позволяя им устареть, оставаясь в памяти слишком долго. Soulmate устанавливает срок действия этих наборов кеша через 10 минут.
Теперь вы можете увидеть, что весь алгоритм поиска Soulmate так же прост, как:
- Возьмите префиксы, введенные конечным пользователем
- Ищите «кэш родственной души: задачи: XX | YY | ZZ» отсортированный набор
- Если такого набора нет, найдите отсортированный набор для каждого из префиксов, используя шаблон «soulmate-index: tasks: XX», и вызовите ZINTERSTORE для их создания. Затем установите его истечь через 10 минут с помощью EXPIRE.
- Вызовите HMGET, чтобы получить соответствующие фразы автозаполнения, используя идентификаторы, найденные в отсортированном наборе.
- Верните их пользователю
Вывод
Это может показаться большим количеством хлопот и хлопот, которые нужно пройти, чтобы реализовать что-то простое, например автозаполнение — в конце концов, чтобы заставить автозаполнение работать с использованием традиционной СУБД SQL, все, что мне нужно сделать, это выполнить простой оператор SELECT, и я м сделано. Если есть много данных для поиска, возможно, мне нужно создать индекс SQL для соответствующего столбца.
Что Сальваторе Санфилиппо и команда SeatGeek сделали здесь, чтобы внедрить свой собственный индекс поиска — но зачем? Redis — это мощный инструмент со многими командами, но все они очень низкоуровневые и не настолько мощные, как настоящий оператор SQL, выполняющийся на сервере RDBMS.
Причина проста: использование базы данных NoSQL, такой как Redis, дает именно ту функциональность и поведение, которые необходимы вам для решения вашей проблемы, создания поискового индекса и ничего более. А поскольку вам не нужно платить за компиляцию, анализ и обработку оператора SQL, это будет очень и очень быстро по сравнению с использованием традиционного сервера баз данных SQL. Кроме того, поскольку команды Redis являются низкоуровневыми, вы можете свободно реализовать свой поисковый индекс любым удобным для вас способом: вы можете настроить его так, чтобы он точно соответствовал вашей модели данных и потребностям проектирования. В некотором смысле, использование Redis является более гибким решением … создайте именно то, что вам нужно для поиска ваших собственных данных, вместо использования слишком сложного инструмента, предназначенного для решения любой проблемы.