 Titan — это распределенная база данных графов, способная поддерживать графы порядка 100 миллиардов ребер и поддерживать порядка 1 миллиарда транзакций в день (см. « Обучение планете с помощью Pearson» ). Программные архитектуры, использующие такие большие графовые данные, обычно имеют сотни серверов приложений, проходящих распределенный граф, представленный в кластере с несколькими машинами. Эти архитектуры не распространены в том смысле, что, возможно, только 1% приложений, написанных сегодня, требуют такого уровня мощности программного обеспечения / машины для функционирования. Остальным 99% приложений может потребоваться только один компьютер для хранения и запроса своих данных (с несколькими дополнительными узлами для обеспечения высокой доступности ). Такой бутикграфические приложения, которые обычно поддерживают порядок 100 миллионов ребер, более элегантно обслуживаются Titan 0.4.1+. В Titan 0.4.1, то в памяти кэши были выдвинуты для поддержки быстрее обходов, что делает производительность одной машины Титана сравнима с другими одиночными машинно-ориентированных баз данных графа. Более того, поскольку приложение масштабируется за пределы одной машины, простое добавление большего количества узлов в кластер Titan позволяет приложениям графического графа беспрепятственно развиваться, превращаясь в приложения Big Graph Data (см. « От одного сервера до высокодоступного кластера» ).
Titan — это распределенная база данных графов, способная поддерживать графы порядка 100 миллиардов ребер и поддерживать порядка 1 миллиарда транзакций в день (см. « Обучение планете с помощью Pearson» ). Программные архитектуры, использующие такие большие графовые данные, обычно имеют сотни серверов приложений, проходящих распределенный граф, представленный в кластере с несколькими машинами. Эти архитектуры не распространены в том смысле, что, возможно, только 1% приложений, написанных сегодня, требуют такого уровня мощности программного обеспечения / машины для функционирования. Остальным 99% приложений может потребоваться только один компьютер для хранения и запроса своих данных (с несколькими дополнительными узлами для обеспечения высокой доступности ). Такой бутикграфические приложения, которые обычно поддерживают порядок 100 миллионов ребер, более элегантно обслуживаются Titan 0.4.1+. В Titan 0.4.1, то в памяти кэши были выдвинуты для поддержки быстрее обходов, что делает производительность одной машины Титана сравнима с другими одиночными машинно-ориентированных баз данных графа. Более того, поскольку приложение масштабируется за пределы одной машины, простое добавление большего количества узлов в кластер Titan позволяет приложениям графического графа беспрепятственно развиваться, превращаясь в приложения Big Graph Data (см. « От одного сервера до высокодоступного кластера» ).
Графические представления на диске и в памяти
При представлении графа в компьютере дизайн его представлений на диске и в памяти влияет на его производительность чтения / записи. Важно, чтобы проекты сочувствовали шаблонам использования графов в приложении (см. «Письмо о базах данных нативных графов» ). Например, когда на диске лучше, чтобы совместно полученные данные графа были совмещены, иначе потребуются дорогостоящие случайные поиски на диске. Titan использует представление списка смежности на диске, где вершина и ее инцидентные ребра совмещены. Titan также позволяет сортировать падающие ребра вершины в соответствии со специфичными для приложения компараторами ребер. Эти вершинно-ориентированные индексыподдерживать детальное извлечение падающих ребер вершины с диска и (надеюсь) с той же страницы диска (см . Решение проблемы с суперузлами ).
 Как только данные графика извлекаются с диска, они помещаются в память. Titan 0.4.1+ поддерживает два уровня кэширования в памяти: теплый и горячий. Горячие кэши хранят горячие точки глобального списка смежности, а горячие кэши хранят локально пройденный подграф графа транзакции . Оба кэша сохраняют свои элементы данных (вершины и ребра) в качестве байтовых буферов . Для обходов, которые перемещаются от вершины к вершине с использованием меток ребер и свойств в качестве фильтров, создание объекта ребер можно избежать, используя вышеупомянутые порядки сортировки, ориентированные на вершины, и классический двоичный поиск., С типичными естественными графами, имеющими на несколько порядков больше ребер, чем вершин, это значительно уменьшает количество создаваемых объектов и объем используемой памяти. Кроме того, это позволяет осуществлять последовательный доступ к памяти, что увеличивает вероятность попадания в кэш ЦП (см. Случайный и последовательный доступ к памяти ).
Как только данные графика извлекаются с диска, они помещаются в память. Titan 0.4.1+ поддерживает два уровня кэширования в памяти: теплый и горячий. Горячие кэши хранят горячие точки глобального списка смежности, а горячие кэши хранят локально пройденный подграф графа транзакции . Оба кэша сохраняют свои элементы данных (вершины и ребра) в качестве байтовых буферов . Для обходов, которые перемещаются от вершины к вершине с использованием меток ребер и свойств в качестве фильтров, создание объекта ребер можно избежать, используя вышеупомянутые порядки сортировки, ориентированные на вершины, и классический двоичный поиск., С типичными естественными графами, имеющими на несколько порядков больше ребер, чем вершин, это значительно уменьшает количество создаваемых объектов и объем используемой памяти. Кроме того, это позволяет осуществлять последовательный доступ к памяти, что увеличивает вероятность попадания в кэш ЦП (см. Случайный и последовательный доступ к памяти ).
{kind=link}
В итоге, обновления в Titan 0.4.1+ затрагивают несколько уровней иерархии памяти, в которых каждый диск, глобальный кэш и локальные транзакции имеют соответствующие структуры данных, соответствующие их конечной роли в обработке графа. Преимущества этих конструкций демонстрируются в следующих разделах.
Обходы Titan Graph на бутиковом графике
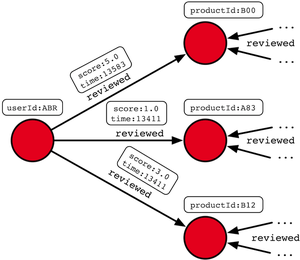 Чтобы протестировать представления Titan на диске и в памяти в масштабе бутика, была сгенерирована графическая версия данных веб-рейтинга Amazon . Преимущество этого набора данных в два раза: 1.) это хороший размер (37 миллионов ребер) для демонстрации одного варианта использования машины и 2.) он поддерживает свойства ребер, которые демонстрируют преимущество вершинно-ориентированных индексов Titan в графе обработка. Схема для графа представлена слева, где есть два типа вершин: пользователи и продукты. График является двудольным в том смысле, что пользователи ссылаются на продукты по рассмотренным краям. В рассмотренной -ребре подесть два свойства: счет (с плавающей точкой между 1-5) и время(долгое время в Unix ).
Чтобы протестировать представления Titan на диске и в памяти в масштабе бутика, была сгенерирована графическая версия данных веб-рейтинга Amazon . Преимущество этого набора данных в два раза: 1.) это хороший размер (37 миллионов ребер) для демонстрации одного варианта использования машины и 2.) он поддерживает свойства ребер, которые демонстрируют преимущество вершинно-ориентированных индексов Titan в графе обработка. Схема для графа представлена слева, где есть два типа вершин: пользователи и продукты. График является двудольным в том смысле, что пользователи ссылаются на продукты по рассмотренным краям. В рассмотренной -ребре подесть два свойства: счет (с плавающей точкой между 1-5) и время(долгое время в Unix ).
 Соответствующий тест был выполнен на двух типах экземпляров Amazon EC2:
Соответствующий тест был выполнен на двух типах экземпляров Amazon EC2: m2.xlarge( жесткий диск — жесткий диск ) и c3.xlarge( твердотельный диск — SSD ). Для того, чтобы продемонстрировать Titan 0.4.1 в относительные преимущества производительности, Titan 0.4.0 и популярный 3 — й база данные партии графа были испытаны также. Один и тот же код был запущен во всех системах с использованием API-интерфейса TinkerPop ‘s Blueprints . Были настроены параметры кучи JVM, -Xms3G -Xmx3Gи были использованы параметры по умолчанию для всех систем, за исключением теплого кэша, явно включенного для Titan 0.4.1:
cache.db-cache=true cache.db-cache-size=0.5 cache.db-cache-time=0
Тест был выполнен, как перечислено ниже. Обратите внимание, что для холодного времени кэширования было выполнено время выполнения первого запроса. Для теплого времени кэширования транзакция откатывается и запрос выполняется снова. Для горячего кэширования запрос не откатывается и запрос выполняется повторно. Фактические обходы Gremlin представлены в блоке кода ниже минус a, .count()который использовался для обеспечения того, чтобы все базы данных возвращали одинаковый набор результатов. Наконец, обратите внимание, что Titan / Cassandra использовался для этого эксперимента, хотя последние разработки кэша доступны для любой из базовых систем хранения Titan.

- 300 необработанных пользовательских идентификаторов были собраны из необработанных данных веб-обзора Amazon.
- 100 пользователей были опрошены с помощью «предпочтения пользователя».
- 100 пользователей были опрошены с помощью «сходства пользователей».
- 100 пользователей были опрошены с помощью «рекомендации продукта».
// what products has the user liked in the last year?
// user preference
user.outE('reviewed').has('score',5f).has('time',T.gte,ONE_YEAR_AGO).inV
// what users have liked the same products that the user liked within the last year?
// user similarity
user.outE('reviewed').has('score',5f).has('time',T.gte,ONE_YEAR_AGO).inV
.inE('reviewed').has('score',5f).has('time',T.gte,ONE_YEAR_AGO).outV()
.except([user])
// what products are liked by the users that like the same products as the user within the last year?
// product recommendation
user.outE('reviewed').has('score',5f).has('time',T.gte,ONE_YEAR_AGO).inV.aggregate(x)
.inE('reviewed').has('score',5f).has('time',T.gte,ONE_YEAR_AGO).outV
.except([user])[0.<1000]
.outE('reviewed').has('score',5f).has('time',T.gte,ONE_YEAR_AGO).inV
.except(x).groupCount(m)
Результаты тестирования доступны для ознакомительного просмотра по следующим URL-адресам (стало возможным благодаря HighCharts JS ).
Графики имеют больше точек данных на левом конце оси X. Чтобы изучить результаты этих меньших наборов результатов, графики можно увеличить, перетащив квадрат над этой областью диаграммы. Каждая линия графика может быть активирована (или деактивирована), нажав на название соответствующей линии в легенде графика.
Важно подчеркнуть, что результаты любого теста следует понимать в контексте, в котором они были выполнены. Этот тест демонстрирует относительную производительность
- на наборе данных графа бутика (то есть относительно небольшого графа),
- используя настройки по умолчанию для графовых баз данных,
- против двух разных носителей длительного хранения (HDD и SSD),
- в рамках ограничений ресурса одного компьютера (
m2.xlargeиc3.xlarge),- выполнение 3 конкретных запросов на чтение,
- и только с одним пользователем / потоком, запрашивающим базу данных в любой момент времени.
Холодные кэши демонстрируют производительность на диске
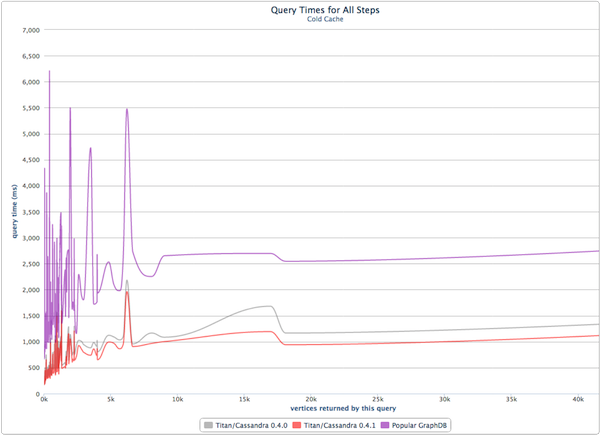
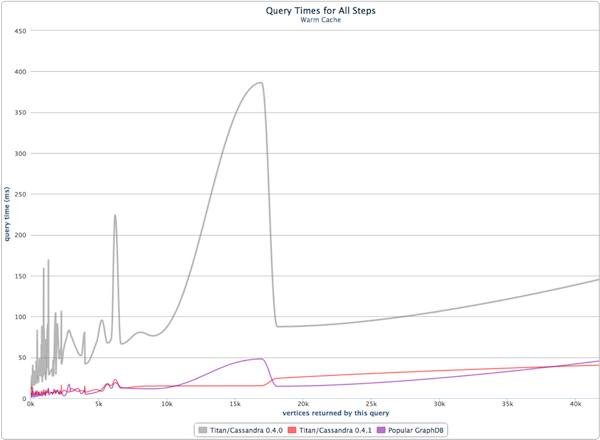
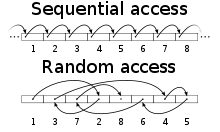 На приведенной выше диаграмме показано количество вершин, возвращаемых обходом по оси x, в зависимости от времени, которое потребовалось для обхода в миллисекундах по оси y. Числа производительности холодного кэша Titan во многом связаны с его секвенизацией графа путем совмещения краев с их вершинами на диске (см. « Масштабируемые графические вычисления»: граф Der Gekrümmte ). Кроме того, с вершинно-ориентированными индексами ребра не только совмещены с их вершинами, но и отсортированы так, что «оценка, равная 5», быстро выбирается с использованием индекса смещения. Если ребра не совмещены с их вершинами, то график не выстраивается последовательно. Это может привести к плохому времени выборки при поиске случайного дискатребуются (см. фиолетовую линию). Эффект произвольного доступа к диску становится более очевидным на графике жесткого диска (в отличие от графика твердотельного диска выше). Обратите внимание, что в любой многопользовательской системе трудно добиться чистой секвенизации, которая допускает случайную запись. По этой причине различные процессы сжатия происходят для борьбы с дефрагментацией данных на диске.
На приведенной выше диаграмме показано количество вершин, возвращаемых обходом по оси x, в зависимости от времени, которое потребовалось для обхода в миллисекундах по оси y. Числа производительности холодного кэша Titan во многом связаны с его секвенизацией графа путем совмещения краев с их вершинами на диске (см. « Масштабируемые графические вычисления»: граф Der Gekrümmte ). Кроме того, с вершинно-ориентированными индексами ребра не только совмещены с их вершинами, но и отсортированы так, что «оценка, равная 5», быстро выбирается с использованием индекса смещения. Если ребра не совмещены с их вершинами, то график не выстраивается последовательно. Это может привести к плохому времени выборки при поиске случайного дискатребуются (см. фиолетовую линию). Эффект произвольного доступа к диску становится более очевидным на графике жесткого диска (в отличие от графика твердотельного диска выше). Обратите внимание, что в любой многопользовательской системе трудно добиться чистой секвенизации, которая допускает случайную запись. По этой причине различные процессы сжатия происходят для борьбы с дефрагментацией данных на диске.
Благодаря методам сжатия графов, основанным на совместном расположении данных и логической смежности, занимаемая Титаном площадь диска остается относительно низкой.
- Титан / Кассандра — 2,9 гигабайта
- Популярная графическая база данных — 15,0 гигабайт
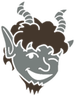 Секвенизация и сжатый формат данных полезны при выполнении распределенных запросов OLAP с Faunus . Строки данных (т. Е. Вершина и ее падающие ребра) могут последовательно извлекаться с диска, что позволяет более эффективно выполнять глобальные параллельные сканирования графа (см. Faunus Предоставляет аналитику данных большого графа ). Кроме того, быстрее перемещать 2,9 гигабайта данных, чем 15,0 гигабайта.
Секвенизация и сжатый формат данных полезны при выполнении распределенных запросов OLAP с Faunus . Строки данных (т. Е. Вершина и ее падающие ребра) могут последовательно извлекаться с диска, что позволяет более эффективно выполнять глобальные параллельные сканирования графа (см. Faunus Предоставляет аналитику данных большого графа ). Кроме того, быстрее перемещать 2,9 гигабайта данных, чем 15,0 гигабайта.
Теплые кэши демонстрируют производительность кэша вне кучи
После извлечения данных с диска они помещаются в память. Titan всегда хорошо справлялся с извлечением графических данных с базового носителя данных (как было показано в предыдущем разделе с HDD и SSD ). С точки зрения производительности в памяти, Titan 0.4.1 теперь может похвастаться системой «горячего кэша». Преимущество этого дополнения проявляется на графике выше при сравнении Titan 0.4.0 и Titan 0.4.1. В Titan 0.4.1 области графика с широким доступом хранятся в глобальном кэше, состоящем в основном из байтовых буферов. Если данные не находятся в кеше (потеря кеша), то механизмы кэширования Cassandra используются (обычно это кеш ключа и кеш страниц на основе ОС ).). Важно подчеркнуть, что отсутствие теплого кэша в Titan 0.4.1 дает время выполнения, эквивалентное тем, которые наблюдаются в Titan 0.4.0 (которые для представленных сложных обходов остаются менее секунды — см. Серую линию). Эти промежутки времени до секунды возможны из-за представления Titan на диске. Последовательность графиков позволяет эффективно использовать кеш страниц ОС, где «переход на диск» обычно не приводит к случайным поискам.
Горячие кэши демонстрируют производительность транзакций в куче
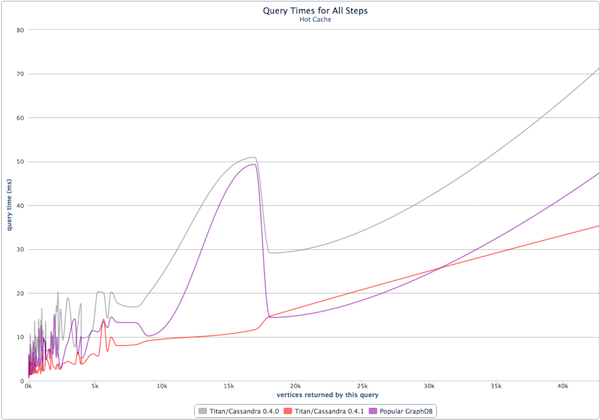
Чтобы ответить на запрос, примитивы обхода сначала проверяют данные в горячем кэше текущей транзакции , затем в глобальном горячем кэше, а затем на определенной странице диска (которая, опять же, может быть в памяти из-за кэша страниц операционной системы). Где бы в конечном итоге ни находились данные, они вычисляются в оперативном кеше локальной транзакции. Для обходов, которые перемещаются от вершины к вершине путем фильтрации путей с использованием свойств и меток ребер , Titan не нужно десериализовать ребра в объекты. Вместо этого он работает непосредственно с байтовыми буферами, хранящимися в теплом кэше. Это значительно уменьшает количество создаваемых объектов ( |V| << |E|), количество времени, затрачиваемого на сбор мусора кучей молодого поколенияи хорошо настраивает Titan для быстрых, рекурсивных графовых алгоритмов (которые будут рассмотрены в будущем сообщении в блоге).
Вывод
 Аврелий постоянно рекламировали Титана как Big Data Graph решение для OLTP приложений графов , которые используют графики и транзакционные нагрузки настолько велики , что они требуют больше ресурсов , чем одна машина может обеспечить. Однако для организаций, желающих использовать графическую базу данных, сотни миллиардов ребер обычно не являются их отправной точкой. Titan 0.4.1+ лучше поддерживает бутик-магазины, начиная с графиков и желая в конечном итоге приобрести массивный, универсальный график своего домена. Более того, все эти функциональные возможности обработки графиков предоставляются в рамках коммерческого соглашения Apache2.лицензия свободного программного обеспечения. С помощью Titan 0.4.1+ графические приложения могут свободно перемещаться с одного компьютера на один высокодоступный узел (например, кластер из 3 компьютеров с коэффициентом репликации 3) в полностью распределенный граф, представленный на произвольном количестве машин.
Аврелий постоянно рекламировали Титана как Big Data Graph решение для OLTP приложений графов , которые используют графики и транзакционные нагрузки настолько велики , что они требуют больше ресурсов , чем одна машина может обеспечить. Однако для организаций, желающих использовать графическую базу данных, сотни миллиардов ребер обычно не являются их отправной точкой. Titan 0.4.1+ лучше поддерживает бутик-магазины, начиная с графиков и желая в конечном итоге приобрести массивный, универсальный график своего домена. Более того, все эти функциональные возможности обработки графиков предоставляются в рамках коммерческого соглашения Apache2.лицензия свободного программного обеспечения. С помощью Titan 0.4.1+ графические приложения могут свободно перемещаться с одного компьютера на один высокодоступный узел (например, кластер из 3 компьютеров с коэффициентом репликации 3) в полностью распределенный граф, представленный на произвольном количестве машин.
Подтверждения
Этот пост был начат доктором Родригесом после того, как он написал электронное письмо команде Aurelius, в котором говорилось, что кэш в памяти Titan должен быть оптимизирован для сценариев использования графиков бутиков. Павел Яскевич принял вызов и смог увеличить скорость прохождения с помощью программного профилирования горячей точки. После этого д-р Bröcheler дал дальнейшую оптимизацию, умело используя последовательные представления в памяти байтового буфера графических данных. Д-р Джулиан Макаули предоставил Аврелию предварительно обработанную версию данных веб-обзора Amazon под лицензией BSD и Дэниэла Куппица Использовать этот набор данных для тщательной постановки и выполнения представленного теста.
Авторы


