Большие графические данные на платформе больших данных Hortonworks
Сентябрь 29, 2018
Это архивный репост поста в блоге, который первоначально был опубликован в блоге Hortonworks .
Hortonworks Data Platform (HDP) удобно объединяет множество инструментов Big Data в Hadoop экосистеме. Таким образом, он предоставляет кластерно-ориентированные сервисы хранения , обработки , мониторинга и интеграции данных . HDP упрощает развертывание и управление производственной системой на основе Hadoop.
В Hadoop данные представлены в виде пар ключ / значение . В HBase данные представлены в виде набора широких строк . Эти атомарные структуры упрощают глобальную обработку данных (через MapReduce ) и чтение / запись для конкретных строк (через HBase). Однако написание запросов нетривиально, если данные имеют сложную, взаимосвязанную структуру, которую необходимо проанализировать (см. Соединения Hadoop и Соединения HBase ). Без соответствующего уровня абстракции обработка высокоструктурированных данных является трудоемкой. Действительно, выбирая правильное представление данных и связанные инструменты открывают иначе невообразимые возможности. Одним из таких представлений данных, которые естественным образом фиксируют сложные отношения, является график (или сеть). В этой статье представлен пакет технологий Aurelius Big Graph Data совместно с платформой данных Hortonworks. Для реального заземления в этом контексте описан клон GitHub, чтобы помочь читателю понять, как использовать эти технологии для построения масштабируемых, распределенных систем на основе графов .
Интеграция графического кластера Aurelius и платформы данных Hortonworks
Аврелий График кластер может быть использован совместно с Hortonworks платформой данных , чтобы предоставить пользователям распределенного хранение графа и систему обработки с преимуществами управления и интеграции , предоставляемых HDP. Графические технологии Aurelius включают Titan , масштабируемую базу данных графов, оптимизированную для предоставления результатов в реальном времени тысячам одновременно работающих пользователей, и Faunus , механизм аналитики распределенных графов, оптимизированный для пакетной обработки графов, представленных в многопользовательском кластере.
В онлайн социальной системеНапример, обычно существует пользовательская база, которая создает вещи и различные отношения между этими вещами (например, лайки, авторы, ссылки, поток). Более того, они создают отношения между собой (например, друг, член группы). Для захвата и обработки этой структуры полезна графовая база данных. Когда граф большой и находится под большой транзакционной нагрузкой, то база данных распределенного графа, такая как Titan / HBase, может использоваться для предоставления услуг в реальном времени, таких как поиск, рекомендации, ранжирование, оценки и т. Д. Затем, периодический автономный глобальный граф статистика может быть использована. Примеры включают в себя выявление наиболее подключенных пользователей или отслеживание относительной важности конкретных тенденций. Faunus / Hadoop выполняет это требование. Графовые запросы / обходы в Титане и Фаунусе просты,однострочные команды, которые оптимизированы как семантически, так и вычислительно для обработки графа. Они выражены с использованием Язык обхода графа Гремлина . Роли, которые Титан, Фаунус и Гремлин играют в HDP, показаны ниже.
Графическое представление GitHub
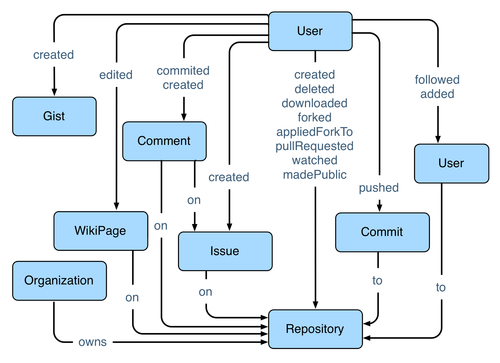
GitHub — это онлайновый сервис с исходным кодом, в котором более 2 миллионов человек работают над более чем 4 миллионами проектов Тем не менее, GitHub предоставляет больше, чем просто контроль версий . За последние 4 года GitHub стал массовым онлайн-сообществом для сотрудничества в области программного обеспечения. Некоторые из крупнейших программных проектов в мире используют GitHub (например, ядро Linux ).
GitHub быстро растет — каждый час происходит от 10 000 до 30 000 событий (например, пользователь вносит код в репозиторий). Платформа данных Hortonworks подходит для хранения, анализа и мониторинга состояния GitHub. Однако ему не хватает специальных инструментов для обработки этих данных с точки зрения отношений. Представление GitHub в виде графа является естественным, поскольку GitHub связывает людей, исходный код, материалы, проекты и организации различными способами. Мышление исключительно в терминах пар ключ / значение и широких строк запутывает базовую реляционную структуру, которая может быть использована для более сложных алгоритмов анализа в реальном времени и пакетной обработки.
GitHub предоставляет 18 типов событий , которые варьируются от новых коммитов и разветвленных событий до открытия новых заявок, комментариев и добавления участников в проект. Действие агрегируется в почасовых архивах, [каждый из которых] содержит поток
событий GitHub в кодировке JSON . (через githubarchive.org )
Вышеупомянутые события могут быть представлены в соответствии с популярной моделью данных графа свойств . Схема графа, описывающая типы «вещей» и отношения между ними, представлена ниже. Анализ необработанных данных в соответствии с этой схемой дает экземпляр графа.
Развертывание основанного на графике GitHub
Чтобы интегрировать Aurelius Graph Cluster с HDP, Whirr используется для запуска машинного кластера 4 m1.xlarge на Amazon EC2 . Подробные инструкции для этого процесса приведены в блоге Aurelius , за исключением того, что для HDP должен использоваться измененный файл свойств Whirr. Полное решение HDP Whirr в настоящее время находится в разработке. Чтобы добавить технологии Aurelius в существующий кластер HDP, просто загрузите Titan и Faunus , которые взаимодействуют с установленными компонентами, такими как Hadoop и HBase, без дальнейшей настройки.
5830 почасовых архивных файлов GitHub в период с середины марта 2012 года до середины ноября 2012 года содержат 31 миллион событий GitHub. Архивные файлы анализируются для создания графика. Например, когда анализируется push-событие GitHub, генерируются вершины с типами user, commit и repository. Ребро с выдвинутой меткой связывает пользователя с коммитом, а ребро с меткой для связывания коммита с репозиторием. У вершины пользователя есть такие свойства, как имя пользователя и адрес электронной почты, у вершины фиксации есть такие свойства, как уникальная сумма sha идентификатор для коммита и его метка времени, а вершина репозитория имеет такие свойства, как URL-адрес и используемый язык программирования. Таким образом, 31 миллион событий дают 27 миллионов вершин и 79 миллионов ребер (сравнительно небольшой график, хотя и растущий). Полные инструкции по синтаксическому анализу данных содержатся в документации по githubarchive-parser . После того, как параметры конфигурации рассмотрены, запустить автоматический параллельный анализатор очень просто.
Сгенерированные данные вершин и ребер импортируются в кластер Titan / HBase с помощью оболочки BatchGraph API-интерфейса графа Blueprints (простой однопоточный инструмент вставки).
Titan — это распределенная графовая база данных, которая использует существующие системы хранения для своей устойчивости. В настоящее время Titan обеспечивает готовую поддержку Apache HBase и Cassandra (см. Документацию ). Хранение и обработка графиков в кластерной среде стали возможными благодаря многочисленным методам, позволяющим как эффективно представлять граф в системе данных в стиле BigTable , так и эффективно обрабатывать этот граф, используя обходные списки и индексы, ориентированные на вершины . Более того, для разработчика Titan предоставляет встроенную поддержку языка обхода графа Гремина . В этом разделе будут продемонстрированы различные обходы Gremlin по проанализированным данным GitHub.
Следующий фрагмент Gremlin определяет, какие репозитории ( окрам ) совершил больше всего. Запрос первым находит вершину с именем okram , а затем принимает исходящую сдвинута -ребру его фиксации. Для каждого из этих фиксаций, уходящий в -ребра проходятся в хранилище, выделяющих была отодвинута. Затем извлекается имя хранилища, и эти имена группируются и подсчитываются. Карта количества побочных эффектов выводится, сортируется в порядке убывания и отображается. Графический пример, демонстрирующий ходьба гремлинов, приведен ниже.
The above query can be taken 2-steps further to determine Marko’s collaborators. If two people have pushed commits to the same repository, then they are collaborators. Given that the number of people committing to a repository could be many and typically, a collaborator has pushed numerous commits, a max of 2500 such collaborator paths are searched. One of the most important aspects of graph traversing is understanding thecombinatorial path explosions that can occur when traversing multiple hops through a graph (see Loopy Lattices).
Complex traversals are easy to formulate with the data in this representation. For example, Titan can be used to generate followship recommendations. There are numerous ways to express a recommendation (with varying semantics). A simple one is: “Recommend me people to follow based on people who watch the same repositories as me. The more repositories I watch in common with someone, the higher they should be ranked.” The traversal below starts at Marko, then traverses to all the repositories that Marko watches. Then to who else (not Marko) looks at those repositories and finally counts those people and returns the top 5 names of the sorted result set. In fact, Marko andStephen (spmallette) are long time collaborators and thus, have similar tastes in software.
Несколько самоописываемых прохождений представлены выше, которые имеют корни в окраме . Наконец, обратите внимание, что Titan оптимизирован для локальных / эгоцентрических обходов. То есть из конкретной исходной вершины (или небольшого набора вершин) используйте некоторое описание пути, чтобы получить вычисление на основе пройденных явных путей. Для проведения глобального анализа графа (где исходным набором вершин является весь граф), используется среда пакетной обработки, такая как Faunus.
Faunus: механизм аналитики графиков
Every Titan traversal begins at a small set of vertices (or edges). Titan is not designed for global analyses which involve processing the entire graph structure. The Hadoop component of Hortonworks Data Platform provides a reliable backend for global queries via Faunus. Gremlin traversals in Faunus are compiled down to MapReduce jobs, where the first job’s InputFormatis Titan/HBase. In order to not interfere with the production Titan/HBase instance, a snapshot of the live graph is typically generated and stored in Hadoop’s distributed file system HDFS as aSequenceFile available for repeated analysis. The most general SequenceFile (with all vertices, edges, and properties) is created below (i.e. a full graph dump).
Given the generated SequenceFile, the vertices and edges are counted by type and label, which is by definition a global operation.
01
gremlin> g.V.type.groupCount
02
==>Gist 780626
03
==>Issue 1298935
04
==>Organization 36281
05
==>Comment 2823507
06
==>Commit 20338926
07
==>Repository 2075934
08
==>User 983384
09
==>WikiPage 252915
10
gremlin> g.E.label.groupCount
11
==>deleted 170139
12
==>on 7014052
13
==>owns 180092
14
==>pullRequested 930796
15
==>pushed 27538088
16
==>to 27719774
17
==>added 181609
18
==>created 10063346
19
==>downloaded 122157
20
==>edited 276609
21
==>forked 1015435
22
==>of 536816
23
==>appliedForkTo 1791
24
==>followed 753451
25
==>madePublic 26602
26
==>watched 2784640
Since GitHub is collaborative in a way similar to Wikipedia, there are a few users who contribute a lot, and many users who contribute little or none at all. To determine the distribution of contributions, Faunus can be used to compute the out degree distribution of pushed-edges, which correspond to users pushing commits to repositories. This is equivalent to Gremlin visiting each user vertex, counting all of the outgoing pushed-edges, and returning the distribution of counts.
When the degree distribution is plotted using log-scaled axes, the results are similar to the Wikipedia contribution distribution, as expected. This is a common theme in most natural graphs — real-world graphs are not random structures and are composed of few “hubs” and numerous “satellites.”
More sophisticated queries can be performed by first extracting a slice of the original graph that only contains relevant information, so that computational resources are not wasted loading needless aspects of the graph. These slices can be saved to HDFS for subsequent traversals. For example, to calculate the most central co-watched project on GitHub, the primary graph is stripped down to only watched-edges between users and repositories. The final traversal below, walks the “co-watched” graph 2 times and counts the number of paths that have gone through each repository. The repositories are sorted by their path counts in order to express which repositories are most central/important/respected according to the watches subgraph.
This post discussed the use of Hortonworks Data Platform in concert with the Aurelius Graph Cluster to store and process the graph data generated by the online social coding system GitHub. The example data set used throughout was provided by GitHub Archive, an ongoing record of events in GitHub. While the dataset currently afforded by GitHub Archive is relatively small, it continues to grow each day. The Aurelius Graph Cluster has been demonstrated in practice to support graphs with hundreds of billions of edges. As more organizations realize the graph structure within their Big Data, the Aurelius Graph Cluster is there to provide both real-time and batch graph analytics.
Acknowledgments
The authors wish to thank Steve Loughran for his help with Whirr and HDP. Moreover, Russell Jurney requested this post and, in a steadfast manner, ensured it was delivered.
Alder, B. T., de Alfaro, L., Pye, I., Raman V., “Measuring Author Contributions to the Wikipedia,” WikiSym ’08 Proceedings of the 4th International Symposium on Wikis, Article No. 15, September 2008.

 В Hadoop данные представлены в виде пар ключ / значение . В HBase данные представлены в виде набора широких строк . Эти атомарные структуры упрощают глобальную обработку данных (через MapReduce ) и чтение / запись для конкретных строк (через HBase). Однако написание запросов нетривиально, если данные имеют сложную, взаимосвязанную структуру, которую необходимо проанализировать (см. Соединения Hadoop и Соединения HBase ). Без соответствующего уровня абстракции обработка высокоструктурированных данных является трудоемкой. Действительно, выбирая правильное представление данных и связанные инструменты открывают иначе невообразимые возможности. Одним из таких представлений данных, которые естественным образом фиксируют сложные отношения, является график (или сеть). В этой статье представлен пакет технологий Aurelius Big Graph Data совместно с платформой данных Hortonworks. Для реального заземления в этом контексте описан клон GitHub, чтобы помочь читателю понять, как использовать эти технологии для построения масштабируемых, распределенных систем на основе графов .
В Hadoop данные представлены в виде пар ключ / значение . В HBase данные представлены в виде набора широких строк . Эти атомарные структуры упрощают глобальную обработку данных (через MapReduce ) и чтение / запись для конкретных строк (через HBase). Однако написание запросов нетривиально, если данные имеют сложную, взаимосвязанную структуру, которую необходимо проанализировать (см. Соединения Hadoop и Соединения HBase ). Без соответствующего уровня абстракции обработка высокоструктурированных данных является трудоемкой. Действительно, выбирая правильное представление данных и связанные инструменты открывают иначе невообразимые возможности. Одним из таких представлений данных, которые естественным образом фиксируют сложные отношения, является график (или сеть). В этой статье представлен пакет технологий Aurelius Big Graph Data совместно с платформой данных Hortonworks. Для реального заземления в этом контексте описан клон GitHub, чтобы помочь читателю понять, как использовать эти технологии для построения масштабируемых, распределенных систем на основе графов . Аврелий График кластер может быть использован совместно с Hortonworks платформой данных , чтобы предоставить пользователям распределенного хранение графа и систему обработки с преимуществами управления и интеграции , предоставляемых HDP. Графические технологии Aurelius включают Titan , масштабируемую базу данных графов, оптимизированную для предоставления результатов в реальном времени тысячам одновременно работающих пользователей, и Faunus , механизм аналитики распределенных графов, оптимизированный для пакетной обработки графов, представленных в многопользовательском кластере.
Аврелий График кластер может быть использован совместно с Hortonworks платформой данных , чтобы предоставить пользователям распределенного хранение графа и систему обработки с преимуществами управления и интеграции , предоставляемых HDP. Графические технологии Aurelius включают Titan , масштабируемую базу данных графов, оптимизированную для предоставления результатов в реальном времени тысячам одновременно работающих пользователей, и Faunus , механизм аналитики распределенных графов, оптимизированный для пакетной обработки графов, представленных в многопользовательском кластере.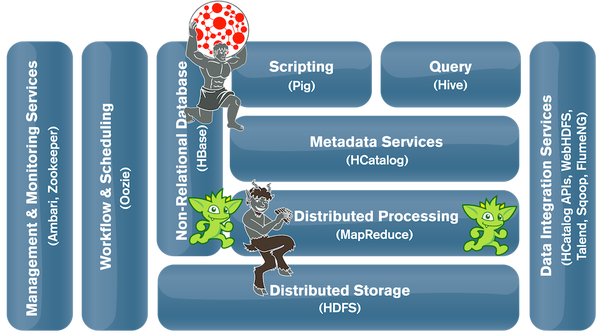
 GitHub — это онлайновый сервис с исходным кодом, в котором более 2 миллионов человек работают над более чем 4 миллионами проектов Тем не менее, GitHub предоставляет больше, чем просто контроль версий . За последние 4 года GitHub стал массовым онлайн-сообществом для сотрудничества в области программного обеспечения. Некоторые из крупнейших программных проектов в мире используют GitHub (например, ядро Linux ).
GitHub — это онлайновый сервис с исходным кодом, в котором более 2 миллионов человек работают над более чем 4 миллионами проектов Тем не менее, GitHub предоставляет больше, чем просто контроль версий . За последние 4 года GitHub стал массовым онлайн-сообществом для сотрудничества в области программного обеспечения. Некоторые из крупнейших программных проектов в мире используют GitHub (например, ядро Linux ).
 Чтобы интегрировать Aurelius Graph Cluster с HDP, Whirr используется для запуска машинного кластера 4 m1.xlarge на Amazon EC2 . Подробные инструкции для этого процесса приведены в блоге Aurelius , за исключением того, что для HDP должен использоваться измененный файл свойств Whirr. Полное решение HDP Whirr в настоящее время находится в разработке. Чтобы добавить технологии Aurelius в существующий кластер HDP, просто загрузите Titan и Faunus , которые взаимодействуют с установленными компонентами, такими как Hadoop и HBase, без дальнейшей настройки.
Чтобы интегрировать Aurelius Graph Cluster с HDP, Whirr используется для запуска машинного кластера 4 m1.xlarge на Amazon EC2 . Подробные инструкции для этого процесса приведены в блоге Aurelius , за исключением того, что для HDP должен использоваться измененный файл свойств Whirr. Полное решение HDP Whirr в настоящее время находится в разработке. Чтобы добавить технологии Aurelius в существующий кластер HDP, просто загрузите Titan и Faunus , которые взаимодействуют с установленными компонентами, такими как Hadoop и HBase, без дальнейшей настройки. Titan — это распределенная графовая база данных, которая использует существующие системы хранения для своей устойчивости. В настоящее время Titan обеспечивает готовую поддержку Apache HBase и Cassandra (см. Документацию ). Хранение и обработка графиков в кластерной среде стали возможными благодаря многочисленным методам, позволяющим как эффективно представлять граф в системе данных в стиле BigTable , так и эффективно обрабатывать этот граф, используя обходные списки и индексы, ориентированные на вершины . Более того, для разработчика Titan предоставляет встроенную поддержку языка обхода графа Гремина . В этом разделе будут продемонстрированы различные обходы Gremlin по проанализированным данным GitHub.
Titan — это распределенная графовая база данных, которая использует существующие системы хранения для своей устойчивости. В настоящее время Titan обеспечивает готовую поддержку Apache HBase и Cassandra (см. Документацию ). Хранение и обработка графиков в кластерной среде стали возможными благодаря многочисленным методам, позволяющим как эффективно представлять граф в системе данных в стиле BigTable , так и эффективно обрабатывать этот граф, используя обходные списки и индексы, ориентированные на вершины . Более того, для разработчика Titan предоставляет встроенную поддержку языка обхода графа Гремина . В этом разделе будут продемонстрированы различные обходы Gremlin по проанализированным данным GitHub.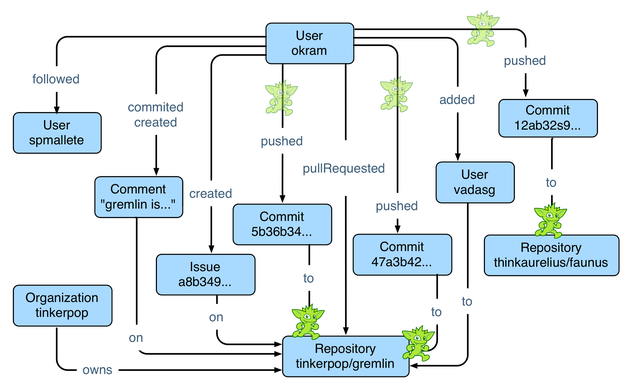
 Every Titan traversal begins at a small set of vertices (or edges). Titan is not designed for global analyses which involve processing the entire graph structure. The Hadoop component of Hortonworks Data Platform provides a reliable backend for global queries via Faunus. Gremlin traversals in Faunus are compiled down to MapReduce jobs, where the first job’s
Every Titan traversal begins at a small set of vertices (or edges). Titan is not designed for global analyses which involve processing the entire graph structure. The Hadoop component of Hortonworks Data Platform provides a reliable backend for global queries via Faunus. Gremlin traversals in Faunus are compiled down to MapReduce jobs, where the first job’s 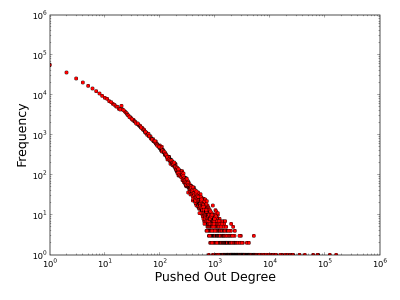
 More sophisticated queries can be performed by first extracting a slice of the original graph that only contains relevant information, so that computational resources are not wasted loading needless aspects of the graph. These slices can be saved to HDFS for subsequent traversals. For example, to calculate the most central co-watched project on GitHub, the primary graph is stripped down to only watched-edges between users and repositories. The final traversal below, walks the “co-watched” graph 2 times and counts the number of paths that have gone through each repository. The repositories are sorted by their path counts in order to express which repositories are most central/important/respected according to the watches subgraph.
More sophisticated queries can be performed by first extracting a slice of the original graph that only contains relevant information, so that computational resources are not wasted loading needless aspects of the graph. These slices can be saved to HDFS for subsequent traversals. For example, to calculate the most central co-watched project on GitHub, the primary graph is stripped down to only watched-edges between users and repositories. The final traversal below, walks the “co-watched” graph 2 times and counts the number of paths that have gone through each repository. The repositories are sorted by their path counts in order to express which repositories are most central/important/respected according to the watches subgraph. This post discussed the use of Hortonworks Data Platform in concert with the Aurelius Graph Cluster to store and process the graph data generated by the online social coding system GitHub. The example data set used throughout was provided by GitHub Archive, an ongoing record of events in GitHub. While the dataset currently afforded by GitHub Archive is relatively small, it continues to grow each day. The Aurelius Graph Cluster has been demonstrated in practice to support graphs with hundreds of billions of edges. As more organizations realize the graph structure within their Big Data, the Aurelius Graph Cluster is there to provide both real-time and batch graph analytics.
This post discussed the use of Hortonworks Data Platform in concert with the Aurelius Graph Cluster to store and process the graph data generated by the online social coding system GitHub. The example data set used throughout was provided by GitHub Archive, an ongoing record of events in GitHub. While the dataset currently afforded by GitHub Archive is relatively small, it continues to grow each day. The Aurelius Graph Cluster has been demonstrated in practice to support graphs with hundreds of billions of edges. As more organizations realize the graph structure within their Big Data, the Aurelius Graph Cluster is there to provide both real-time and batch graph analytics.