Вступление
HBase является одной из самых популярных баз данных NoSQL, она доступна во всех основных дистрибутивах Hadoop, а также является частью AWS Elastic MapReduce в качестве дополнительного приложения. Из коробки у него есть собственные операции с моделью данных, такие как Get, Put, Scan и Delete, и он не предлагает SQL-подобные возможности, в отличие, например, от языка запросов Cassandra, CQL.
Apache Phoenix — это слой SQL поверх HBase для поддержки наиболее распространенных SQL-подобных операций, таких как CREATE TABLE, SELECT, UPSERT, DELETE и т. Д. Первоначально он был разработан инженерами Salesforce.com для внутреннего использования и был открыт с открытым исходным кодом. В 2013 году он стал проектом инкубатора Apache.
Архитектура
Мы рассмотрели HBase более подробно в этой статье. Краткий обзор: архитектура HBase основана на трех ключевых компонентах: главный сервер HBase, серверы региона HBase и Zookeeper.
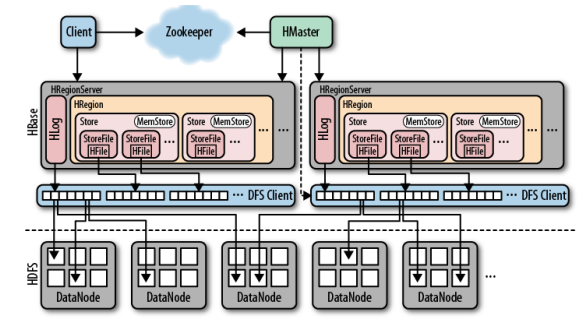
Клиент должен найти RegionServers для работы с данными, хранящимися в HBase. По сути, регионы являются основными элементами для распределения таблиц по кластеру. Чтобы найти серверы регионов, клиенту сначала нужно будет поговорить с Zookeeper.
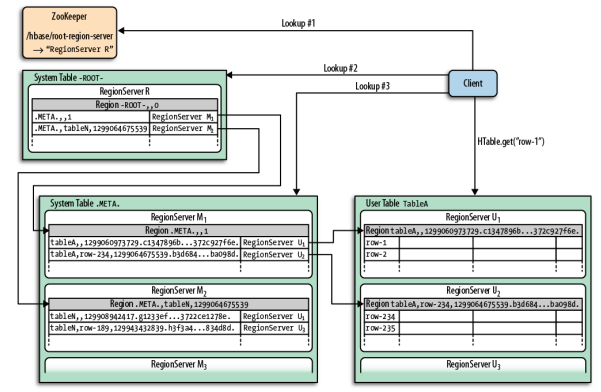
Ключевыми элементами в модели данных HBase являются таблицы, семейства столбцов, столбцы и ключи строк. Таблицы состоят из столбцов и строк. Отдельные элементы на пересечении столбцов и строк (ячейки в термине HBase) являются версиями, основанными на отметке времени. Строки идентифицируются отсортированными ключами строк — эти ключи строк можно рассматривать как первичные ключи, и через них можно получить доступ ко всем данным в таблице.
Столбцы сгруппированы в семейства столбцов; во время создания таблицы необязательно указывать все столбцы, только семейства столбцов. Столбцы имеют префикс, полученный из семейства столбцов, и его собственный спецификатор, имя столбца выглядит следующим образом: ‘contents: html’.
Как мы уже видели, классическая модель данных HBase не разработана с учетом SQL. Под капотом находится многогранная карта. Вот где Феникс приходит на помощь; он предлагает скин SQL на HBase. Phoenix реализован как драйвер JDBC. С точки зрения архитектуры клиент Java, использующий JDBC, может быть настроен для работы с драйвером Phoenix и может подключаться к HBase с помощью SQL-подобных операторов. Мы покажем, как использовать клиент SQuirreL , популярный графический клиент SQL на основе Java, вместе с Phoenix.
Начало работы с Фениксом
Вы можете скачать Phoenix с сайта загрузки Apache . Различные версии Phoenix совместимы с различными версиями HBase, поэтому, пожалуйста, прочитайте документацию Phoenix, чтобы убедиться, что вы правильно настроили систему. В наших тестах мы использовали Phoenix 3.0.0 с HBase 0.94, дистрибутив Hadoop был Cloudera CDH4.4 с Hadoop v1. Пакет Phoenix содержит драйверы Hadoop версии 1 и 2 для клиентов, поэтому нам пришлось использовать соответствующий Hadoop- 1 файлов, подробности смотрите позже, когда говорите о клиенте SQuirreL.
После того, как вы разархивировали загруженный пакет Phoenix, вам необходимо скопировать соответствующие файлы jar Phoenix на серверы региона HBase, чтобы гарантировать, что клиент Phoenix может обмениваться данными с ними, в противном случае вы можете получить сообщение об ошибке, в котором говорится, что файлы jar клиента и сервера не совместимо
$ cd ~/phoenix/phoenix-3.0.0-incubating/common $ cp phoenix-3.0.0-incubating-client-minimal.jar /usr/lib/hbase/lib $ cp phoenix-core-3.0.0-incubating.jar /usr/lib/hbase/lib
После того, как вы скопировали файлы JAR на серверы региона, нам пришлось их перезапустить.
Phoenix предоставляет инструмент командной строки под названием sqlline — это утилита, написанная на Python. Его функциональность аналогична инструментам командной строки Oracle SQLPlus или MySQL; не слишком сложный, но делает работу для простых случаев использования.
Прежде чем вы начнете использовать sqlline, вы можете создать образец таблицы базы данных, заполнить ее и выполнить несколько простых запросов следующим образом:
$ cd ~/phoenix/phoenix-3.0.0.0-incubating/bin $ ./psql.py localhost ../examples/web_stat.sql ../examples/web_stat.csv ../examples/web_stat_queries.sql
Это запустит оператор CREATE TABLE:
CREATE TABLE IF NOT EXISTS WEB_STAT (
HOST CHAR(2) NOT NULL,
DOMAIN VARCHAR NOT NULL,
FEATURE VARCHAR NOT NULL,
DATE DATE NOT NULL,
USAGE.CORE BIGINT,
USAGE.DB BIGINT,
STATS.ACTIVE_VISITOR INTEGER
CONSTRAINT PK PRIMARY KEY (HOST, DOMAIN, FEATURE, DATE)
);
Затем загрузите данные, хранящиеся в CSV-файле web_stat:
NA,Salesforce.com,Login,2013-01-01 01:01:01,35,42,10 EU,Salesforce.com,Reports,2013-01-02 12:02:01,25,11,2 EU,Salesforce.com,Reports,2013-01-02 14:32:01,125,131,42 NA,Apple.com,Login,2013-01-01 01:01:01,35,22,40 NA,Salesforce.com,Dashboard,2013-01-03 11:01:01,88,66,44 ...
И запустите несколько примеров запросов к таблице, например:
-- Average CPU and DB usage by Domain SELECT DOMAIN, AVG(CORE) Average_CPU_Usage, AVG(DB) Average_DB_Usage FROM WEB_STAT GROUP BY DOMAIN ORDER BY DOMAIN DESC;
Теперь вы можете подключиться к HBase, используя sqlline:
$ ./sqlline.py localhost [cloudera@localhost bin]$ ./sqlline.py localhost .. Connecting to jdbc:phoenix:localhost Driver: org.apache.phoenix.jdbc.PhoenixDriver (version 3.0) Autocommit status: true Transaction isolation: TRANSACTION_READ_COMMITTED .. Done sqlline version 1.1.2 0: jdbc:phoenix:localhost> select count(*) from web_stat; +------------+ | COUNT(1) | +------------+ | 39 | +------------+ 1 row selected (0.112 seconds) 0: jdbc:phoenix:localhost> select host, sum(active_visitor) from web_stat group by host; +------+---------------------------+ | HOST | SUM(STATS.ACTIVE_VISITOR) | +------+---------------------------+ | EU | 698 | | NA | 1639 | +------+---------------------------+ 2 rows selected (0.294 seconds) 0: jdbc:phoenix:localhost>
Использование SQuirreL с Фениксом
Если вы предпочитаете использовать графический клиент SQL с Phoenix, вы можете скачать, например, SQuirreL здесь. После этого первым делом скопируйте соответствующий файл jar драйвера Phoenix в каталог lib SQuirreL:
$ cd ~/phoenix $ cp phoenix-3.0.0-incubating/hadoop-1/phoenix-3.0.0.-incubatibg-client.jar ~/squirrel/lib
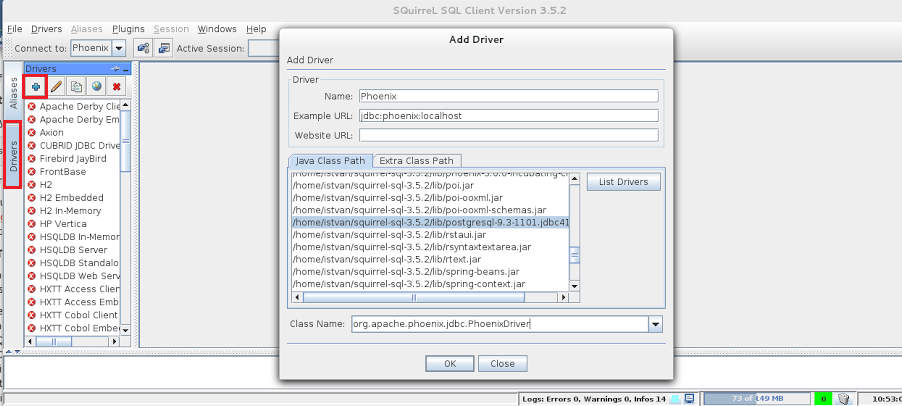
Теперь вы готовы настроить драйвер JDBC в клиенте SQuirreL, как показано на рисунке ниже:
Затем вы можете подключиться к Phoenix, используя соответствующую строку подключения (jdbc: phoenix: localhost в нашем тестовом сценарии):
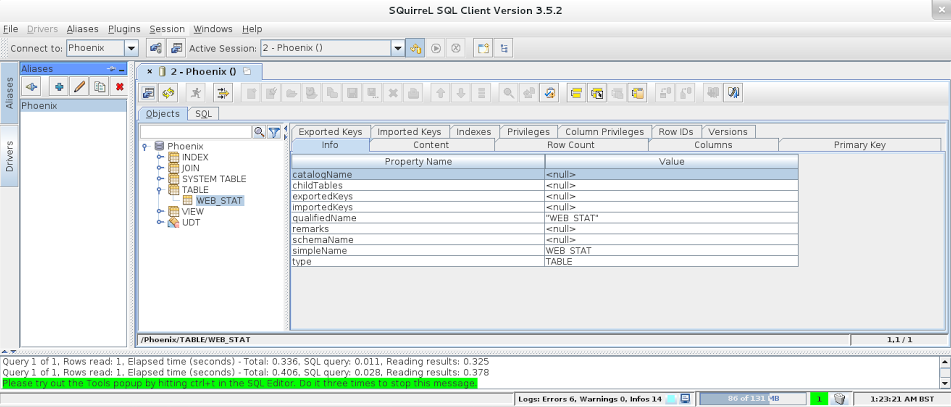
После подключения вы можете начать выполнение ваших запросов SQL: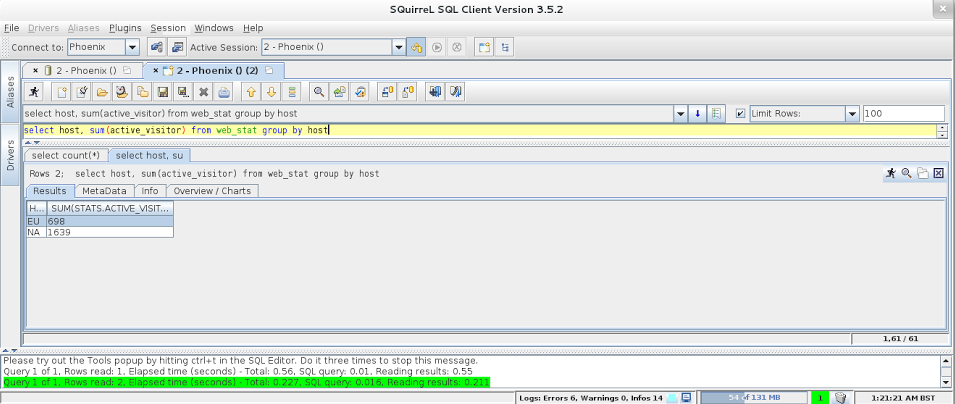
Phoenix на веб-сервисах Amazon — AWS Elastic MapReduce с Phoenix
Вы также можете использовать Phoenix с AWS Elastic MapReduce. При создании кластера необходимо указать версию Apach Hadoop, затем настроить HBase как дополнительное приложение и определить действие начальной загрузки для загрузки Phoenix в кластер AWS EMR. Смотрите детали ниже на картинках:
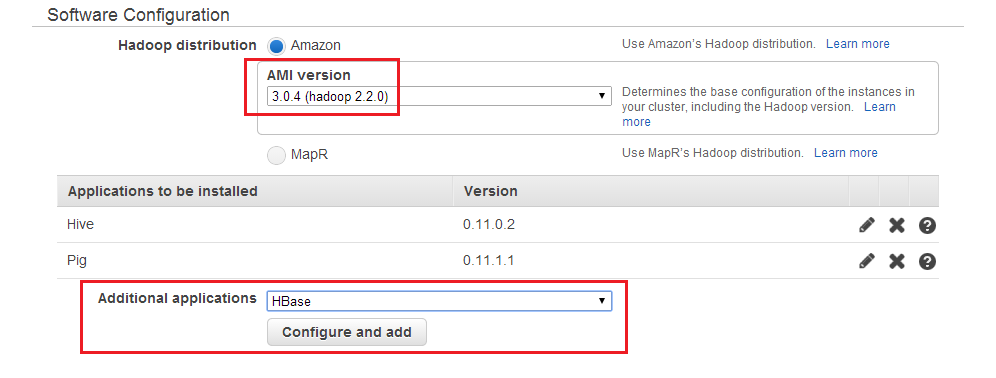
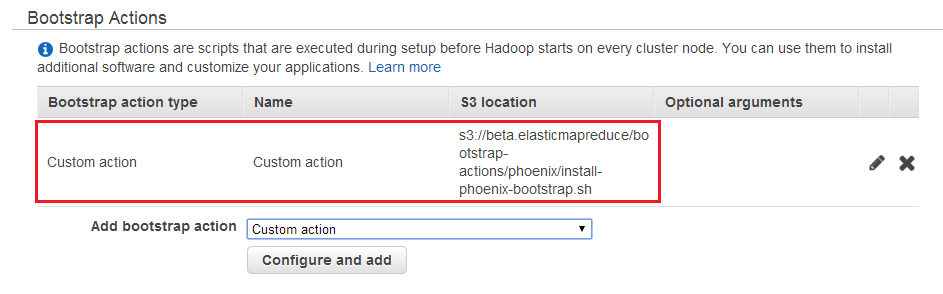
После запуска кластера вы можете войти на главный узел, используя ssh, и проверить свою конфигурацию Phoenix.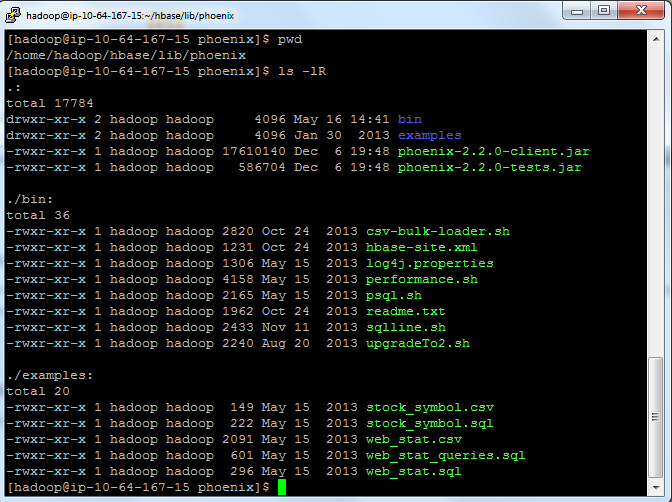
Вывод
SQL является одним из самых популярных языков, используемых исследователями данных, и, вероятно, так и останется. С появлением баз данных Big Data и NoSQL объем, разнообразие и скорость данных значительно возросли, но потребность в традиционных, хорошо известных языках для их обработки не сильно изменилась. Решения SQL на Hadoop набирают обороты. Apache Phoenix — интересный проигрыватель с открытым исходным кодом, предлагающий слой SQL поверх HBase.