В настоящее время компания-разработчик программного обеспечения Cloudera на базе Hadoop создает новый сертификат под названием Data Science Essentials Exam (DS-200) . Одной из целей сертификации является изучение инструментов, методов и утилит для оценки данных из командной строки. Вот почему я пишу этот пост в блоге. Unix оболочка обеспечивает огромный набор команд , которые могут быть использованы для анализа данных. Хорошее введение в команды Unix можно найти в этом руководстве .
Команды, удобные для аналитика данных: cat , find , grep , wc , cut , sort , uniq
Эти команды называются фильтрами . Данные проходят через фильтр. Более того, фильтр может немного изменить данные на пути к ним. Все фильтры считывают данные со стандартного ввода и записывают данные в стандартный вывод . Фильтр может использовать стандартный вывод другого фильтра, чтобы быть его стандартным вводом при использовании канала «|» оператор. Например, команда cat считывает файл в стандартный вывод, а команда grep использует этот вывод cat в качестве стандартного ввода для поиска, если город ‘Мюнхен’ находится в файле города. Пример набора данных доступен на github .
bz@cs ~/data $ cat city | grep Munich 3070,Munich [München],DEU,Bavaria,1194560
В приведенном выше примере вы можете увидеть структуру примера набора данных. Набор данных — это список через запятую. Первое число представляет идентификатор записи, за которой следует название города, код страны, район, а последнее число представляет население города.
Теперь давайте ответим на аналитический вопрос : какой город с наибольшим населением в наборе данных? Второй и пятый столбец можно выбрать с помощью awk . WK создает список , где население находится на первой позиции и название города находится на второй позиции. Команда сортировки может быть использована для сортировки. Таким образом, можно узнать, какой город в наборе данных имеет наибольшее население.
bz@cs ~/data/ $ awk -v OFS=" " -F"," '{print $5, $2}' city | sort -n -r | head -n 1
10500000 Mumbai (Bombay)
Также возможно создавать объединения в оболочке Unix с помощью команды join . Команда объединения предполагает, что входные данные сортируются по ключу, по которому будет происходить соединение. Вы можете найти другой набор данных на github, который содержит страны. Этот набор данных также является списком через запятую. 14-й столбец в наборе данных страны представляет идентификатор столицы, который аналогичен идентификатору в наборе данных города. Это позволяет создать список стран со своими столицами.
bz@cs ~/data/ $ cat city | head -n 2 1,Kabul,AFG,Kabol,1780000 2,Qandahar,AFG,Qandahar,237500 bz@cs ~/data/ $ cat country | head -n 2 AFG,Afghanistan,Asia,Southern and Central Asia,652090,1919,22720000,45.9,5976.00,,Afganistan/Afqanestan,Islamic Emirate,Mohammad Omar,1,AF NLD,Netherlands,Europe,Western Europe,41526,1581,15864000,78.3,371362.00,360478.00,Nederland,Constitutional Monarchy,Beatrix,5,NL bz@cs ~/data/ $ join -t "," -1 1 -2 14 -o '1.2,2.2' city country | head -n 2 Kabul,Afghanistan Amsterdam,Netherlands
Наконец, давайте глубже рассмотрим набор данных города. Вопрос для этого примера: как распределение городов в наборе данных города? Комбинация команд sort и uniq позволяет нам создавать данные для графика плотности . Эти данные могут быть переданы (>) в файл.
bz@cs ~/data/ $ cat city | cut -d , -f 3 | uniq -c | sort -r | head -n 4 363 CHN 341 IND 274 USA 250 BRA bz@cs ~/data/ $ cat city | cut -d , -f 3 | uniq -c | sort -r > count_vs_country
Gnuplot — это команда, которая позволяет нам визуализировать файл данных плотности. Мы должны сказатьgnuplot,что он должен печатать и как его печатать. Вы также можете использоватьgnuplotво времясеансовtelnetилиssh,поскольку графики могут быть напечатаны в символах ACSII. Следовательно, тип терминала должен быть установлен на «немой»
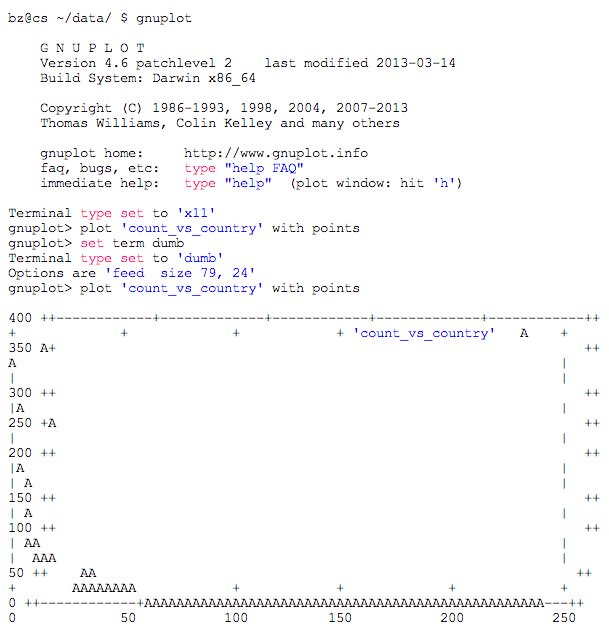
,
Участок плотности для Распределения Города, связанного со Страной
Надеюсь, вам понравился этот небольшой опыт анализа данных с помощью оболочки Unix. Это полезно для студентов, которые в настоящее время работают над учебным пособием по бета-версии Data Science Essentials (DS-200). Кроме того, я продемонстрировал, насколько мощная оболочка Unix может использоваться для базовой аналитики. Unix оболочка также может сделать основные вещи , как аналитик обычно выполняется в статистическом программном обеспечении как R .