Как мы знаем, хранимая процедура предназначена для обработки вычислений с использованием сложной бизнес-логики.
В прошлом структура данных и бизнес-логика были настолько просты, что одного оператора SQL было достаточно для достижения вычислительной цели пользователя. В условиях быстрого роста информационной индустрии пользователи часто обнаруживают, что им необходимо достигать все более сложных вычислительных целей, чтобы превзойти своих конкурентов. Для решения таких вычислений одного SQL недостаточно. Программисты баз данных предъявляют дополнительные требования к суждениям и операторам цикла, ветвлениям на нескольких уровнях или более точным операциям с данными, а также к разложению неясной цели на несколько четких и действенных шагов, связанных со сложной логикой. Именно для всех этих требований была введена хранимая процедура.
До настоящего времени хранимая процедура стала предпочтительным инструментом для сложных вычислений данных, играя важную роль. Однако хранимые процедуры по-прежнему вызывают различные неудобства. Например, многие их функции неудобны — их трудно отлаживать или переносить; и есть некоторые базы данных с довольно слабыми хранимыми процедурами. Эти проблемы иногда серьезно влияют на эффективность работы разработчиков баз данных.
Неудобные функции хранимой процедуры включают в себя неполное пошаговое вычисление, слабую поддержку вычислений с набором данных, для набора данных не может быть установлен порядковый номер и нет механизма ссылки на объект. Давайте проверим это на простом примере — найдите «лучшие n самых продаваемых продуктов в любом штате», проанализировав таблицу региональных продаж. В этом сценарии эти неудобства делают довольно сложным написание хранимой процедуры.
01 create or replace package salesPkg
02 as
03 type salesCur is ref cursor;
04 end;
05 CREATE OR REPLACE PROCEDURE topPro(io_cursor OUT salesPkg.salesCur)
06 is
07 varSql varchar2(2000);
08 tb_count integer;
09 BEGIN
10 select count(*) into tb_count from dba_tables where table_name='TOPPROTMP';
11 if tb_count=0 then
12 strCreate:='CREATE GLOBAL TEMPORARY TABLE TOPPROTMP (
stateTmp NUMBER not null,
productTmp varchar2(10) not null,
amountTmp NUMBER not null
)
ON COMMIT PRESERVE ROWS';
13 execute immediate strCreate;
14 end if;
15 execute immediate 'truncate table TOPPROTMP';
16 insert into TOPPROTMP(stateTmp,productTmp,amountTmp)
select state,product,amount from stateSales a
where not(
(a.state,a.product) in (
select state,product from stateSales group by state,product having count(*) > 1
)
and rowid not in (
select min(rowid) from stateSales group by state,product having count(*)>1
)
)
order by state,product;
17 OPEN io_cursor for
18 SELECT productTmp FROM (
SELECT stateTmp,productTmp,amountTmp,rankorder
FROM (SELECT stateTmp,productTmp,amountTmp,RANK() OVER(PARTITION BY stateTmp ORDER BY amountTmp DESC) rankorder
FROM TOPPROTMP
)
WHERE rankorder<=10 order by stateTmp
)
GROUP BY productTmp
HAVING COUNT(*)=(SELECT COUNT(DISTINCT stateTmp ) FROM TOPPROTMP);
END;
В котором код в строке 16 состоит в том, чтобы отфильтровать дубликаты и записать отфильтрованные данные во «временную таблицу». Поскольку трудно получить отдельные данные напрямую, попробуйте этот совет: найдите дублирующие данные, а затем используйте «не «чтобы изменить условие, а остальные — это отдельные данные. Эту функцию можно реализовать, внедрив два подзапроса.
В качестве другого примера, строка 18 — найти продукты, входящие в топ-10 в любом штате. Во-первых, используйте оконную функцию, чтобы получить ранжирование продуктов каждого штата; Во-вторых, отфильтруйте 10 лучших продуктов в каждом штате; Наконец, получить продукты, входящие в топ-10 в любом государстве. SQL не предоставляет никаких функций для поиска множеств пересечений. Итак, для устранения этого слабого места приведем еще один совет: группируйте по продуктам, чтобы проверить, равно ли количество одинаковых продуктов количеству штатов; если они равны, это означает, что продукт входит в топ-10 в каждом штате.
Помимо неудобных функций, довольно слабая поддержка функции отладки является еще одним неудобством хранимых процедур.
Хотя на рынке есть Oracle, DB2 и другие базы данных, предлагающие функции отладки для соответствующих хранимых процедур, их функции отладки неполны. При запуске хранимой процедуры, независимо от того, является ли оператор SQL длинным или коротким, независимо от того, сколько вложенных циклов или вычислительных шагов он содержит, программисты могут просматривать только результат одного оператора, а промежуточная процедура для них полностью прозрачна. Скорее всего, это побуждает к пошаговой отладке и ставит под угрозу преимущества запуска курсора или следующего шага. Программистам на самом деле разрешено только просматривать курсор и простые переменные. Такие переменные полезны, но ни в коем случае не имеют такого же значения, как промежуточная процедура SQL. Другая проблема заключается в том, что для запуска средств отладки требуется множество рабочих нагрузок по настройке и подготовке.Новички вряд ли справятся с этим без гидов.
Третье неудобство заключается в том, что хранимую процедуру сложно перенести. Вообще говоря, SQL можно перенести с помощью нескольких простых модификаций. Несмотря на небольшое различие в деталях синтаксиса, SQL от разных поставщиков являются надмножествами стандарта ANSI. Однако хранимая процедура — это совсем другое. Миграция хранимой процедуры намного сложнее, чем перезапись, потому что соответствующие стандарты разных поставщиков сильно различаются. В этой ситуации у пользователей нет другого выбора, кроме как строго придерживаться одного поставщика баз данных. Пользователям не останется места, чтобы снизить цену, если поставщики баз данных переоценят их при обновлении своих серверов, хранилищ и пользовательских лицензионных соглашений.
SQL является важной функцией любой базы данных, а хранимая процедура — нет. Некоторые базы данных предлагают только относительно плохие хранимые процедуры, а другие вообще не предоставляют их. Взять, к примеру, хранимые процедуры MySQL. Его функции и производительность хуже, чем у MS SQL, Oracle и некоторых других баз данных, и MySQL может вызвать много исключений при интенсивном параллелизме. MSSQL Compact, SQLITE, Hive, Access и другие базы данных не поддерживают хранимые процедуры.
Очевидно, что неудобства хранимых процедур поставили под угрозу вычислительную производительность баз данных и доставили много проблем программистам — значительные трудности в разработке, неэффективная разработка и неудобное обслуживание. Кроме того, эти неудобства также влияют на результат внедрения бизнес-логики, достижения сложных вычислительных целей и принятия разумных бизнес-решений. Тогда как вы расширяете возможности хранимой процедуры?
esProc — это скрипт для работы с базами данных, специально созданный для решения сложных вычислительных задач. С вычислительной производительностью, одинаково хорошей и даже лучшей, чем у хранимых процедур, esProc дополнительно обеспечивает удобный интуитивно понятный стиль сетки, пошаговые вычисления, профессиональные функции отладки, гибкий синтаксис, полную вычислительную систему и плавную поддержку интерактивных вычислений между различные базы данных.
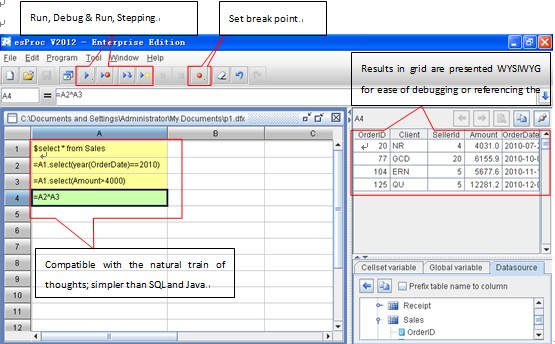
esProc — это скрипт-инструмент со стилем сетки. С esProc вычислительная логика может быть удобно размещена в двумерном пространстве. Таким образом, бизнес-алгоритм легче интерпретируется на компьютерном языке. esProc поддерживает пошаговые вычисления. Конкретно, esProc позволяет пользователям разбивать сложную цель на несколько простых шагов в своей сетке и, в конечном счете, достигать сложной цели, выполняя эти простые задачи. Разработанный с «пошаговыми» идеями, в esProc введена действительно практичная функция отладки, включающая различные функции, такие как точка останова, пошаговое выполнение, выполнение до курсора, начало и конец. В отличие от поддельного сценария отладки, такого как SQL / SP, esProc может напрямую и просто отлаживать основные этапы, без необходимости создавать конкретную промежуточную таблицу.Точка останова может быть установлена в любой позиции без изменения кода.
esProc поддерживает истинный тип данных набора. Членом набора могут быть данные любых простых типов данных, записей и / или других наборов. esProc поддерживает упорядоченный набор, что означает, что пользователи могут получить доступ к элементу набора и выполнить вычисления, связанные с порядковым номером, например, ранжирование, сортировка, сравнение по годам и сравнение относительных соотношений ссылок. Набор-набор может использоваться для представления равной группировки, выравнивания и перечисления. Кроме того, пользователи могут работать с отдельными записями так же, как они использовали для работы с объектом. esProc может проще представлять сложные вычисления с помощью гибкого синтаксиса, например, вычисление относительных позиций в многоуровневых группировках, а также группирование и суммирование по заданному набору.
esProc может расширить возможности хранимых процедур и, в конечном итоге, расширить вычислительные возможности базы данных, уменьшить сложность разработки для программистов, повысить эффективность разработки и облегчить сопровождение и миграцию кода. esProc может легко реализовывать сложные алгоритмы данных и бизнес-логику.
Наконец, для рассмотренного выше случая, чтобы обсудить неудобства хранимых процедур, давайте посмотрим на решение esProc, показанное ниже:
