Мы блог о Java и SQL на некоторое время теперь, на блоге jOOQ . За прошедшие годы, исследуя интересные темы блогов, мы обнаружили в блогосфере множество драгоценных камней SQL, которые вдохновили нас на нашу работу и нашу страсть к SQL.
Сегодня мы представляем вам список из 10 статей, которые, по нашему мнению, вы обязательно должны прочитать. В конце списка вы согласитесь, что либо:
- SQL потрясающий
- SQL сумасшедший
… или, возможно, оба. Здесь идет, в произвольном порядке:
1. Джо Селко: «Разделенные мы стоим: SQL реляционного разделения»
Реляционное деление является очень мощным понятием в реляционной алгебре . Он отвечает на такие вопросы, как:
Дайте мне всех студентов, которые прошли данный набор курсов
К сожалению, деление не имеет прямого эквивалента в SQL. Хотелось бы, чтобы был такой пункт, как
TABLE_A
DIVIDE BY TABLE_B
ON [ some predicate ]
Тем не менее, вы можете выразить разделение в SQL различными способами.
Прочитайте статью Джо: « Разделенные мы стоим: SQL реляционного разделения »
2. Алекс Боленок: «С Новым годом!»
Алек Боленок (он же Quassnoi ) ведет блог о различных интересных вещах, связанных с SQL, но один из его главных вкладов каждый год — его серия «с новым годом». Алек рисует «красиво» (красота в глазах смотрящего) и, конечно же, впечатляющие картинки в вашей консоли SQL. Например:
Прочитайте Alek’s, « Рождественская елка в SQL »
3. Маркус Винанд: «Кластеризация данных: вторая сила индексации»
Маркус Винанд является автором популярной книги « Объяснение производительности SQL» , части которой вы также можете прочитать в его блоге « Используйте индекс Люка ». Как в книге, так и на этой странице есть невероятное количество очень полезных знаний, но один из наиболее показательных и полезных приемов SQL — это знание о «покрытии индексов», «кластеризации индексов» или «сканировании только индекса»
Прочитайте статью Маркуса: « Кластеризация данных: вторая сила индексации »
4. Дмитрий Фонтейн: «Понимание оконных функций»
Был SQL перед оконными функциями и SQL после оконных функций
Оконные функции являются одними из самых мощных и недостаточно используемых функций SQL. Они доступны во всех коммерческих базах данных, в PostgreSQL, а вскоре и в Firebird 3.0. Мы сами несколько раз писали об оконных функциях , но одно из лучших резюме и объяснений того, что они на самом деле и как они работают, было написано Дмитрием Фонтейном.
Прочтите у Дмитрия: « Понимание оконных функций »
Немного рекламы для нашего собственного письма. Мы собрали 10 самых распространенных ошибок, которые делают Java-разработчики при написании SQL. Эти ошибки на самом деле даже не являются специфическими для разработчиков Java, они могут случиться с любым разработчиком. Эта статья вызвала большую популярность в нашем блоге, в этом должна быть какая-то великая правда.
Прочитайте статью Лукаса: « 10 распространенных ошибок, которые делают Java-разработчики при написании SQL »
6. Андраш Габор «Методы разбиения на страницы в SQL»
До недавнего времени смещение нумерации страниц было довольно сложно реализовать в коммерческих базах данных, таких как Oracle, SQL Server, DB2, Sybase, в которых не было эквивалента условию MySQL / PostgreSQL LIMIT .. OFFSET. Однако нумерацию страниц можно эмулировать, и для этого существует множество методов. Выбор правильной техники имеет важное значение для производительности. Если вы используете Oracle 11g или менее, вы должны отфильтровать ROWNUM:
Прочитайте « Методы разбиения на страницы в SQL » Андраса
Кстати, вам, вероятно, следует подумать о том, чтобы вообще не использовать OFFSET. Подробнее о движении NO OFFSET читайте…
7. Маркус Винданд: «Нам нужна инструментальная поддержка для нумерации клавиш»
Если вы думаете о OFFSETнумерации страниц, то это довольно глупая вещь с технической точки зрения и бесполезная с точки зрения бизнеса. Вот почему
С технической точки зрения …
… Вам необходимо применить фильтрацию, группировку и упорядочение для огромного количества данных, пропуская и отбрасывая все данные, которые появляются до смещения, пока не дойдете до первой интересующей строки. Это большая трата ресурсов, учитывая, что …
С точки зрения бизнеса …
… возможно, страницы 1-3 интересны, но абсолютно бессмысленно предлагать пользователям перейти на страницу 1337. После определенного смещения значение смещения с точки зрения бизнеса исчезло. Вы также можете отображать случайные, неупорядоченные образцы данных. Пользователь не заметит. Вероятно, когда вы достигнете более высокой страницы в результатах поиска Google, это именно то, что происходит. Случайная вещь.
Или на Reddit. Там вы можете найти случайные вещи уже на первой странице — например, этот популярный показ Стабилизированной головы на зеленой виноградной змее .
Намного лучше, чем офсетная нумерация страниц, это нумерация клавиш (о которой мы также писали ).
Прочитайте статью Маркуса « Нам нужна инструментальная поддержка для нумерации клавиш »

8. Джош Беркус «Пометь все»
Реализация тегов в реляционной базе данных может быть чудовищной с точки зрения производительности. Должны ли вы нормализовать (один ко многим)? Стоит ли сильно нормализоваться (многие ко многим)? Следует ли использовать вложенные коллекции / массивы / или даже структуры данных JSON?
Джош написал очень интересную статью о производительности тяжелых тегов в PostgreSQL, показывая, что нормализация не всегда лучший выбор.
Прочитайте « Пометь все » Джоша
9. Алек Боленок «10 вещей в SQL Server (которые не работают должным образом)»
Это снова работа Алекса (Кассной). Очень интересный набор вещей, которые происходят внутри SQL Server, чего вы не ожидали, когда привыкли использовать другие базы данных. Независимо от того, используете вы SQL Server или нет, это необходимо прочитать, чтобы повысить осведомленность о тонких небольших различиях между реализациями SQL.
Прочитайте статью Алекса « 10 вещей в SQL Server (которые не работают должным образом) »
10. Аарон Бертран: «Лучшие подходы для подведения итогов»
Промежуточные итоги являются очень типичным примером использования отчетов на основе SQL. Промежуточный итог — это то, что каждый менеджер проектов, использующий Excel, интуитивно знает, как это сделать. Просто перетащите эту сладкую сладкую формулу в таблицу и сделайте следующее:
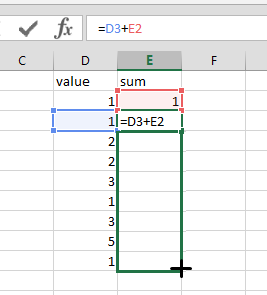
Как сделать то же самое в SQL? Есть снова множество способов. Аарон Бертран суммировал различные решения для SQL Server 2012.
Прочитайте Аарона « Лучшие подходы для подведения итогов »
Много других статей
Конечно, есть много других очень хороших статей, дающих глубокое понимание полезных трюков SQL. Если вы обнаружите, что столкнулись со статьей, которая будет приятно дополнять этот список, пожалуйста, оставьте ссылку и описание в разделе комментариев. Будущие читатели оценят дополнительное понимание.