В этой статье я построю модель глубокого обучения и проведу простой регрессионный анализ с использованием нейронных сетей, одного из новых алгоритмов, представленных Oracle 18c для расширенных аналитических опций. Я надеюсь, что это будет полезно в смысле осознания.
Вам также может понравиться:
Что такое глубокое обучение?
Такие темы, как наука о данных и машинное обучение, являются одними из самых важных тем сегодня. В настоящее время мы можем реализовать проблемы и методы, рассматриваемые по этим темам, которые требуют опыта и знаний для многих продуктов или программного обеспечения.
Oracle поддерживает методы и алгоритмы для решения проблем под этими заголовками с пакетом DBMS_DATA_MINING. Благодаря этой инфраструктуре Oracle позволяет пользователям разрабатывать приложения машинного обучения с использованием SQL.
С пакетом DBMS_DATA_MINING мы можем создавать такие модели, как Кастеринг, Классификация, Регрессия, Обнаружение аномалий, Извлечение признаков и Правила связывания, а затем передавать и интерпретировать наши данные. Результаты, полученные из этих моделей, могут быть использованы в качестве входных данных в наших бизнес-сценариях.
Пакет DBMS_DATA_MINING по умолчанию не установлен в базе данных Oracle. Поэтому, чтобы воспользоваться этой поддержкой, необходимо сначала установить следующий пакет. Вы можете установить Oracle Data Mining в своей базе данных, перейдя по ссылке ниже
https://docs.oracle.com/cd/E11882_01/datamine.112/e16807/install_odm.htm#DMADM117 .
Мне не нужна дополнительная установка, потому что я сделаю это приложение в автономном хранилище данных (БД), которое предлагается в качестве службы в Oracle Cloud. Я могу использовать эти алгоритмы в автономном хранилище данных. Вы можете бесплатно получить услугу «Автономное хранилище данных», которая является одной из услуг, объявленных как « Всегда бесплатные» в Oracle Open World 2019, и использовать ее в облаке в течение нескольких минут без установки. Вы можете перейти по ссылке для получения подробной информации.
Глубокое обучение является одним из самых обсуждаемых методов искусственного обучения в последние годы. Мы внимательно следим за возможностями обучения и ограничениями того, что они могут сделать, и, с одной стороны, мы хотим извлечь выгоду из наших бизнес-сценариев.
Вместе с 18c Oracle запустила инфраструктуру, которая позволяет нам строить модели нейронных сетей без необходимости переноса данных в другую среду в базе данных. Теперь давайте рассмотрим пример использования этой инфраструктуры и ее детали.
Мне нужен набор данных и проблема для его реализации. Я выбираю цены на жилье в Бостоне как проблему. Чтобы решить эту проблему, я построю регрессионную модель. Я получаю набор данных из Kaggle ( Boston Housing ).
Давайте сначала рассмотрим набор данных BOSTON_HOUSING .
| Имя столбца | Описание | Тип данных |
| CRIM | уровень преступности на душу населения по городам. | номер |
| гп | доля жилой земли зонирована под участки более 25 000 кв. футов. | номер |
| промышл | доля неторговых площадей на город. | номер |
| Чес | Фиктивная переменная реки Чарльз (= 1, если тракт ограничивает реку; 0 в противном случае). | номер |
| NOx | концентрация оксидов азота (частей на 10 миллионов). | номер |
| комната | среднее количество комнат в доме. | номер |
| возраст | доля домовладельцев, построенных до 1940 года. | номер |
| дис | средневзвешенное расстояние до пяти бостонских центров занятости. | номер |
| радиан | индекс доступности к радиальным магистралям. | номер |
| налог | ставка налога на имущество на полную стоимость за 10 000 долларов США. | номер |
| ptratio | соотношение ученик-учитель по городу. | номер |
| черный | 1000 (Bk — 0,63) ^ 2, где Bk — доля черных в городе. | номер |
| lstat | более низкий статус населения (в процентах). | номер |
| MEDV | средняя стоимость домов, занимаемых владельцами, в 1000 долларов. |
номер |
Теперь, когда мы проверили детали с нашим набором данных, давайте загрузим BOSTON_HOUSING, который мы загрузили, в нашу базу данных Oracle.
Сначала создайте таблицу Oracle, в которую мы будем загружать загруженный набор данных (train.csv).
CREATE TABLE BOSTON_HOUSING
(
ID NUMBER,
CRIM NUMBER,
ZN NUMBER,
INDUS NUMBER,
CHAS NUMBER,
NOX NUMBER,
RM NUMBER,
AGE NUMBER,
DIS NUMBER,
RAD NUMBER,
TAX NUMBER,
PTRATIO NUMBER,
BLACK NUMBER,
LSTAT NUMBER,
MEDV NUMBER
);Теперь, когда мы создали нашу таблицу, мы загрузим в таблицу набор данных, который мы скачали как CSV; у нас есть несколько способов сделать это:
- Использование Oracle External Table.
- Использование Oracle SQL Loader.
- Использование редакторов SQL-PL / SQL (Oracle SQL Developer, Toad, PL / SQL Developer и т. Д.).
Я загружу набор данных с помощью редактора, который я использую. Я использую Oracle SQL Developer в качестве редактора. С Oracle SQL Developer вы можете загружать данные следующим образом .
SELECT * FROM BOSTON_HOUSING;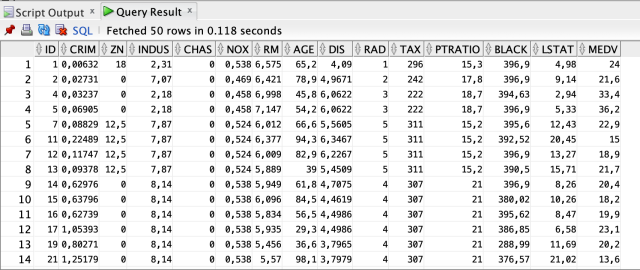
Мы завершили процесс загрузки набора данных.
Когда мы наблюдаем данные, мы видим детали в соответствии с различными характеристиками домов. Каждый ряд содержит информацию о конкретных характеристиках дома. Наши основные параметры для регрессионного анализа представлены в этой таблице. В этой таблице мы прогнозируем результат регрессионного анализа. Столбец MEDV является целевой переменной, которую мы будем использовать в этом анализе.
Чтобы построить модель глубокого обучения в базе данных, мы должны использовать алгоритм нейронной сети в пакете DBMS_DATA_MINING. Чтобы использовать этот алгоритм, нам нужно понять некоторые параметры и определить их для дальнейшего использования. Эти параметры следующие ;
| НАИМЕНОВАНИЕ НАСТРОЙКИ | НАСТРОЙКА ЗНАЧЕНИЯ | ОПИСАНИЕ |
| NNET_HIDDEN_LAYERS | Неотрицательное целое число | Определяет топологию по количеству скрытых слоев. |
| Значением по умолчанию является 1. | ||
| NNET_NODES_PER_LAYER | Список целых положительных чисел | Определяет топологию по количеству узлов на слой. Разные слои могут иметь разное количество узлов. |
| Значение должно быть неотрицательными целыми числами и разделяться запятыми. Например, 10, 20, 5. Значения параметров должны соответствовать NNET_HIDDEN_LAYERS. По умолчанию количество узлов на слой равно количеству атрибутов или 50 (если количество атрибутов> 50). | ||
| NNET_ACTIVATIONS | Список следующих строк: | Определяет функцию активации для скрытых слоев. Например, «NNET_ACTIVATIONS_BIPOLAR_SIG», «NNET_ACTIVATIONS_TANH». |
| «NNET_ACTIVATIONS_LOG_SIG» | Разные слои могут иметь разные функции активации. | |
| «NNET_ACTIVATIONS_LINEAR» | Значением по умолчанию является «NNET_ACTIVATIONS_LOG_SIG». | |
| «NNET_ACTIVATIONS_TANH» | Количество функций активации должно соответствовать NNET_HIDDEN_LAYERS и NNET_NODES_PER_LAYER. | |
| «NNET_ACTIVATIONS_ARCTAN» | Примечание: | |
| «NNET_ACTIVATIONS_BIPOLAR_SIG» | Все кавычки одинарные, а две одинарные кавычки используются для экранирования одинарных кавычек в операторах SQL. | |
| NNET_WEIGHT_LOWER_BOUND | Реальное число | Параметр задает нижнюю границу области, где веса инициализируются случайным образом. NNET_WEIGHT_LOWER_BOUND и NNET_WEIGHT_UPPER_BOUND должны быть установлены вместе. Установка одного, а не установка другого вызывает ошибку. NNET_WEIGHT_LOWER_BOUND не должен превышать NNET_WEIGHT_UPPER_BOUND. Значением по умолчанию является –sqrt (6 / (l_nodes + r_nodes)). Значение l_nodes для: |
| плотные атрибуты входного слоя (1 + количество плотных атрибутов) | ||
| разреженные атрибуты входного слоя — это число разреженных атрибутов | ||
| каждый скрытый слой (1 + количество узлов в этом скрытом слое) | ||
| Значение r_nodes — это количество узлов в слое, к которому подключается вес. | ||
| NNET_WEIGHT_UPPER_BOUND | Реальное число | Этот параметр указывает верхнюю границу области, в которой инициализируются веса. Он должен быть установлен в паре с NNET_WEIGHT_LOWER_BOUND, и его значение не должно быть меньше значения NNET_WEIGHT_LOWER_BOUND. Если не указано, значения NNET_WEIGHT_LOWER_BOUND и NNET_WEIGHT_UPPER_BOUND определяются системой. |
| Значением по умолчанию является sqrt (6 / (l_nodes + r_nodes)). Смотрите NNET_WEIGHT_LOWER_BOUND. | ||
| NNET_ITERATIONS | Положительное число | Этот параметр указывает максимальное количество итераций в алгоритме нейронной сети. |
| Значение по умолчанию 200 | ||
| NNET_TOLERANCE | TO_CHAR (0 <numeric_expr <1) | Определяет настройку допуска сходимости алгоритма нейронной сети. |
| Значением по умолчанию является 0,000001. | ||
| NNET_REGULARIZER | NNET_REGULARIZER_NONE | Настройка регуляризации для алгоритма нейронной сети. Если общее количество обучающих строк превышает 50000, по умолчанию используется NNET_REGULARIZER_HELDASIDE. Если общее количество обучающих строк меньше или равно 50000, по умолчанию используется NNET_REGULARIZER_NONE. |
| NNET_REGULARIZER_L2 | ||
| NNET_REGULARIZER_HELDASIDE | ||
| NNET_HELDASIDE_RATIO | 0 <= numeric_expr <= 1 | Определите коэффициент удержания для метода удержания в стороне. |
| Значение по умолчанию составляет 0,25. | ||
| NNET_HELDASIDE_MAX_FAIL | Значение должно быть положительным целым числом. | С NNET_REGULARIZER_HELDASIDE процесс обучения останавливается на ранней стадии, если производительность сети для данных проверки не улучшается или остается неизменной для эпох NNET_HELDASIDE_MAX_FAIL подряд. |
| Значением по умолчанию является 6. | ||
| NNET_REG_LAMBDA | TO_CHAR (numeric_expr> = 0) | Определяет параметр регуляризации L2 лямбда. Это не может быть установлено вместе с NNET_REGULARIZER_HELDASIDE. |
|
Значением по умолчанию является 1. |
Как видите, существует много параметров, которые мы можем использовать для создания модели. Мы можем использовать эти параметры с различными настройками в соответствии с топологией сети, которую мы хотим настроить.
Во-первых, мы должны сделать; создайте и сохраните операторы вставки, чтобы установить эти параметры способом, который мы хотим использовать. Нам просто нужно добавить параметры, которые мы хотим изменить, в эту таблицу. Oracle будет использовать оставшиеся параметры со значениями по умолчанию. Затем мы дадим эту таблицу в качестве параметра для чтения настроек алгоритма функции, которую мы будем использовать для создания нашей модели.
CREATE TABLE neural_network_settings (
setting_name VARCHAR2(1000),
setting_value VARCHAR2(1000)
);
BEGIN
INSERT INTO neural_network_settings (
setting_name,
setting_value
) VALUES (
dbms_data_mining.prep_auto,
dbms_data_mining.prep_auto_on
);
INSERT INTO neural_network_settings (
setting_name,
setting_value
) VALUES (
dbms_data_mining.algo_name,
dbms_data_mining.algo_neural_network
);
INSERT INTO neural_network_settings (
setting_name,
setting_value
) VALUES (
dbms_data_mining.nnet_activations,
'''NNET_ACTIVATIONS_LOG_SIG'',''NNET_ACTIVATIONS_LOG_SIG'',''NNET_ACTIVATIONS_LOG_SIG'''
);
INSERT INTO neural_network_settings (
setting_name,
setting_value
) VALUES (
dbms_data_mining.nnet_nodes_per_layer,
'512,250,100'
);
COMMIT;
END;
select * from neural_network_settings;
 Как мы видим, мы добавили параметры, которые мы не хотим использовать с настройками по умолчанию, в таблицу настроек со значениями, которые мы хотим.
Как мы видим, мы добавили параметры, которые мы не хотим использовать с настройками по умолчанию, в таблицу настроек со значениями, которые мы хотим.
Если мы объясним примерно три параметра, которые мы вставим;
- Мы выбрали алгоритм в строке номер два.
- В строке 4 мы определили, сколько слоев будет состоять из нейронной сети и сколько будет скрытых единиц. В этом примере мы создаем 3-уровневую сеть с 512 скрытыми единицами на первом уровне, 250 скрытыми единицами на втором уровне и 100 скрытыми единицами на последнем уровне.
- В третьей строке мы определили функцию активации, которую мы хотим использовать в каждом слое. В этом примере мы объявили нашего пользователя SIGMOID с каждого уровня.
Да, мы загрузили данные наших тренировок. Мы установили настройки алгоритма. Теперь пришло время создать нашу модель (обучение).
BEGIN
DBMS_DATA_MINING.CREATE_MODEL(
model_name => 'DEEP_LEARNING_MODEL',
mining_function => dbms_data_mining.REGRESSION,
data_table_name => 'BOSTON_HOUSING',
case_id_column_name => 'ID',
target_column_name => 'MEDV',
settings_table_name => 'neural_network_settings');
END;
Да, мы вызвали функцию, мы создадим нашу модель с необходимыми параметрами. Если мы посмотрим, что это за параметры.
-
Название модели: уникальное название модели, которое мы дадим нашей модели.
-
Mining function: параметр, по которому мы сообщаем тип проблемы, которую нужно решить. Поскольку мы сделали регресс в этой задаче, мы выбрали этот параметр в качестве регрессии. Мы можем выбрать CLASSIFICATION или CLUSTERING и т. Д. В зависимости от типа проблемы.
-
Data_table_name: параметр, к которому будет использоваться таблица при обучении.
-
Case_id_column_name: параметр, который дает ключ, который разделяет данные, которые мы используем в обучении. Если есть составной ключ, мы должны создать новый атрибут перед созданием модели. Так как наш столбец идентификатора уникален в нашей таблице, мы смогли предоставить этот столбец напрямую.
-
Target_column_name: где мы сообщаем, какой столбец наша модель должна использовать в качестве цели. Целевая переменная нашей модели. Другими словами, значение, которое предсказывает модель.
-
Settings_table_name: настройка таблицы, где параметры, которые мы хотим использовать нейронной сети при написании модели.
Да, мы тренируем нашу модель. Все параметрические сведения о нашей модели можно получить, введя следующий запрос на этом шаге.
select * from all_mining_model_settings where model_name='DEEP_LEARNING_MODEL';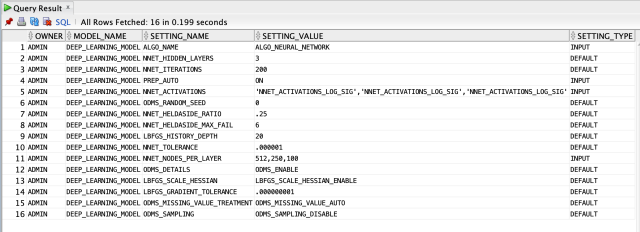 В таблице мы видим как параметры, которые мы даем извне, так и параметры модели, для которых присваивания выполняются со значениями по умолчанию.
В таблице мы видим как параметры, которые мы даем извне, так и параметры модели, для которых присваивания выполняются со значениями по умолчанию.
Теперь давайте посмотрим на таблицы с подробной информацией об этой модели глубокого обучения, которую мы создали.
Для достижения значений веса производится в каждом слое;
select * from DM$VADEEP_LEARNING_MODEL;Для общей информации о модели;
select * from DM$VGDEEP_LEARNING_MODEL;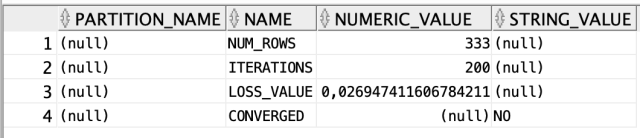 Достичь нормализации значений переменных;
Достичь нормализации значений переменных;
select * from DM$VNDEEP_LEARNING_MODEL;Теперь давайте посмотрим, как мы можем делать новые прогнозы для нашей модели. Мы можем сделать это двумя способами.
Во-первых, мы можем запустить нашу модель для всех агрегированных значений в таблице. Для этого мы будем использовать файл test.csv в файлах данных, которые мы скачали с Kaggle. Давайте создадим таблицу, куда мы будем загружать этот файл и загружать данные внутри.
CREATE TABLE BOSTON_HOUSING_TEST
(
ID NUMBER,
CRIM NUMBER,
ZN NUMBER,
INDUS NUMBER,
CHAS NUMBER,
NOX NUMBER,
RM NUMBER,
AGE NUMBER,
DIS NUMBER,
RAD NUMBER,
TAX NUMBER,
PTRATIO NUMBER,
BLACK NUMBER,
LSTAT NUMBER,
MEDV NUMBER
);
-- We can load the data with the method described above and query the table.
SELECT * FROM BOSTON_HOUSING_TEST;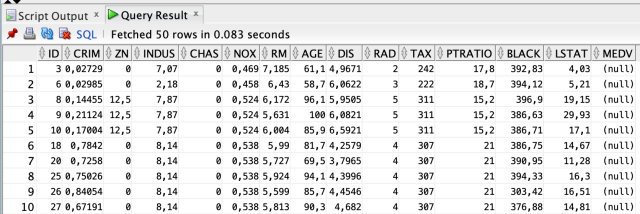 Теперь давайте введем эти данные в нашу модель и сгенерируем прогнозы.
Теперь давайте введем эти данные в нашу модель и сгенерируем прогнозы.
SELECT T.*,
PREDICTION (DEEP_LEARNING_MODEL USING *) NN_RES
FROM BOSTON_HOUSING_TEST T;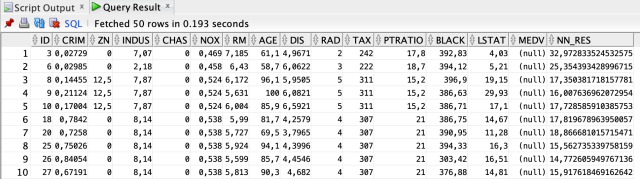 Теперь давайте посмотрим, как мы можем прогнозировать с помощью одной записи.
Теперь давайте посмотрим, как мы можем прогнозировать с помощью одной записи.
SELECT prediction(DEEP_LEARNING_MODEL USING 0.02 as crim,
12.5 as zn,
8.01 as indus,
0 as chas,
0.48 as nox,
6.25 as rm,
15.4 as age,
4.92 as dis,
4.00 as rad,
242 as tax,
15.3 as pratio,
399 as balck,
4.09 as lstat) pred
FROM dual;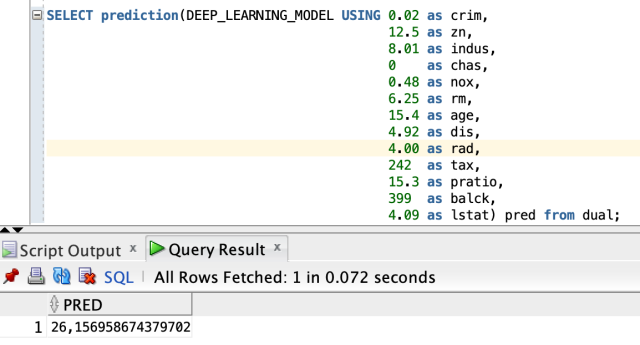 Как мы уже видели, мы смогли очень просто передать значения нашей модели и получить результат прогнозирования менее чем за секунду.
Как мы уже видели, мы смогли очень просто передать значения нашей модели и получить результат прогнозирования менее чем за секунду.
Дальнейшее чтение
Глубокое обучение и машинное обучение: часть I
Глубокое обучение с Python для начинающих
Глубокое обучение для компьютерного зрения: руководство для начинающих