Создание точных моделей машинного обучения, способных идентифицировать и локализовать несколько объектов на одном изображении, остается основной проблемой в компьютерном зрении. Но с недавними достижениями в области глубокого обучения, приложения для обнаружения объектов стали легче разрабатывать, чем когда-либо прежде. API обнаружения объектов TensorFlow — это платформа с открытым исходным кодом, созданная поверх TensorFlow, которая позволяет легко создавать, обучать и развертывать модели обнаружения объектов.
Вы можете просмотреть эту видео-лекцию по обнаружению объектов в реальном времени, где наш эксперт по углубленному обучению обсуждает, как обнаружить объект в режиме реального времени с помощью TensorFlow.
Что такое обнаружение объектов?
Обнаружение объектов — это процесс обнаружения реальных объектов, таких как автомобили, велосипеды, телевизоры, цветы и люди, в неподвижных изображениях или видеороликах. Это позволяет распознавать, локализовать и обнаруживать несколько объектов в изображении, что дает нам гораздо лучшее понимание изображения в целом. Он обычно используется в таких приложениях, как поиск изображений, безопасность, наблюдение и расширенные системы помощи водителю (ADAS).
Обнаружение объекта может быть сделано несколькими способами:
- Обнаружение объектов на основе объектов
- Обнаружение объекта Виола Джонс
- Классификация SVM с функциями HOG
- Глубокое обнаружение объекта обучения
В этом уроке по обнаружению объектов мы сосредоточимся на детальном изучении объектов, так как TensorFlow использует глубокое обучение для вычислений.

Приложения обнаружения объектов
Распознавание лица

Группа исследователей из Facebook разработала систему глубокого обучения лицу под названием «DeepFace», которая очень эффективно идентифицирует человеческие лица в цифровом изображении. Google использует свою собственную систему распознавания лиц в Google Фото, которая автоматически разделяет все фотографии на основе человека на изображении. В распознавании лиц участвуют различные компоненты, такие как глаза, нос, рот и брови.
Подсчет людей

Обнаружение объектов также может быть использовано для подсчета людей. Он используется для анализа производительности магазина или статистики толпы во время фестивалей. Это, как правило, сложнее, так как люди быстро выходят за рамки.
Это очень важное приложение, так как во время скопления людей эта функция может использоваться для нескольких целей.
Промышленная проверка качества
Обнаружение объектов также используется в производственных процессах для идентификации продуктов. Поиск конкретного объекта с помощью визуального осмотра является основной задачей, которая задействована во многих производственных процессах, таких как сортировка, управление запасами, обработка, управление качеством, упаковка и т. Д.
Управление запасами может быть очень сложным, поскольку элементы трудно отслеживать в режиме реального времени. Автоматический подсчет и локализация объектов позволяет повысить точность инвентаризации.
Самостоятельные автомобили
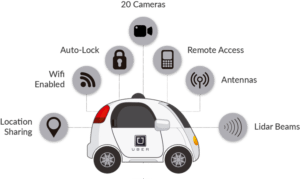
Самостоятельные автомобили — это будущее; в этом нет никаких сомнений. Но работать за ним очень сложно, так как он сочетает в себе различные методы для восприятия окружающей обстановки, включая радар, лазерное излучение, GPS, одометрию и компьютерное зрение.
Усовершенствованные системы управления интерпретируют сенсорную информацию для определения подходящих путей навигации, а также препятствий, и как только датчик изображения обнаруживает любые признаки живого существа на своем пути, он автоматически останавливается. Это происходит с очень высокой скоростью и является большим шагом на пути к автомобилям без водителя.
Безопасность

Обнаружение объектов играет очень важную роль в безопасности. Будь то идентификация лица Apple или сканирование сетчатки, используемое во всех научно-фантастических фильмах.
Он также используется правительством для доступа к каналам безопасности и сопоставления их с существующей базой данных, чтобы найти преступников или обнаружить автомобиль грабителей.
Приложения безграничны.
Рабочий процесс обнаружения объектов
Каждый алгоритм обнаружения объектов имеет свой способ работы, но все они работают по одному и тому же принципу.
Извлечение функций: они извлекают элементы из имеющихся изображений и используют эти функции для определения класса изображения. Будь то через MatLab, Open CV, Альт-Джонс или глубокое обучение.
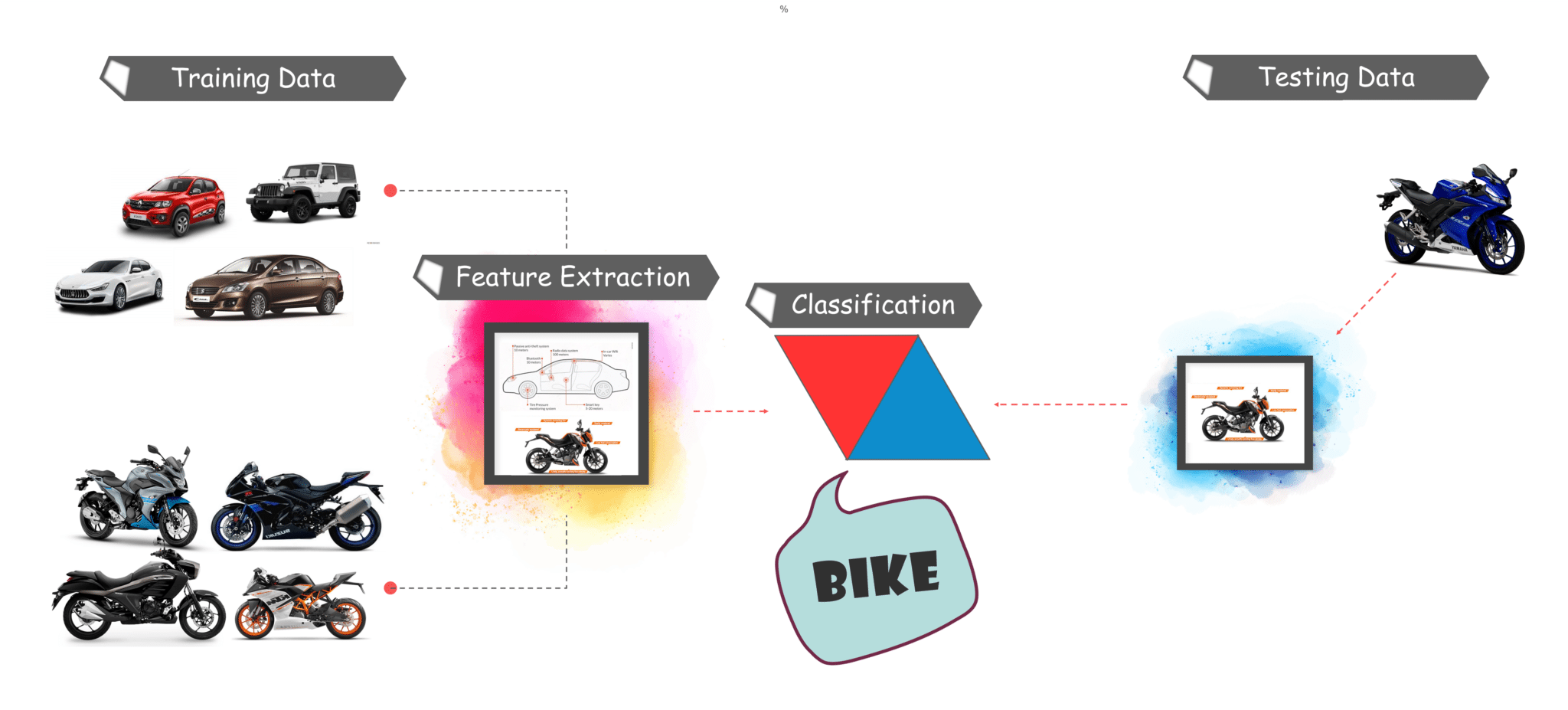
чтобы вы поняли основной рабочий процесс обнаружения объектов, давайте перейдем к учебнику и разберемся, что такое Tensorflow и каковы его компоненты.
Что такое TensorFlow?
Tensorflow — это система машинного обучения с открытым исходным кодом Google для программирования потоков данных по ряду задач. Узлы в графе представляют математические операции, в то время как ребра графа представляют собой многомерные массивы данных (тензоры), передаваемые между ними.
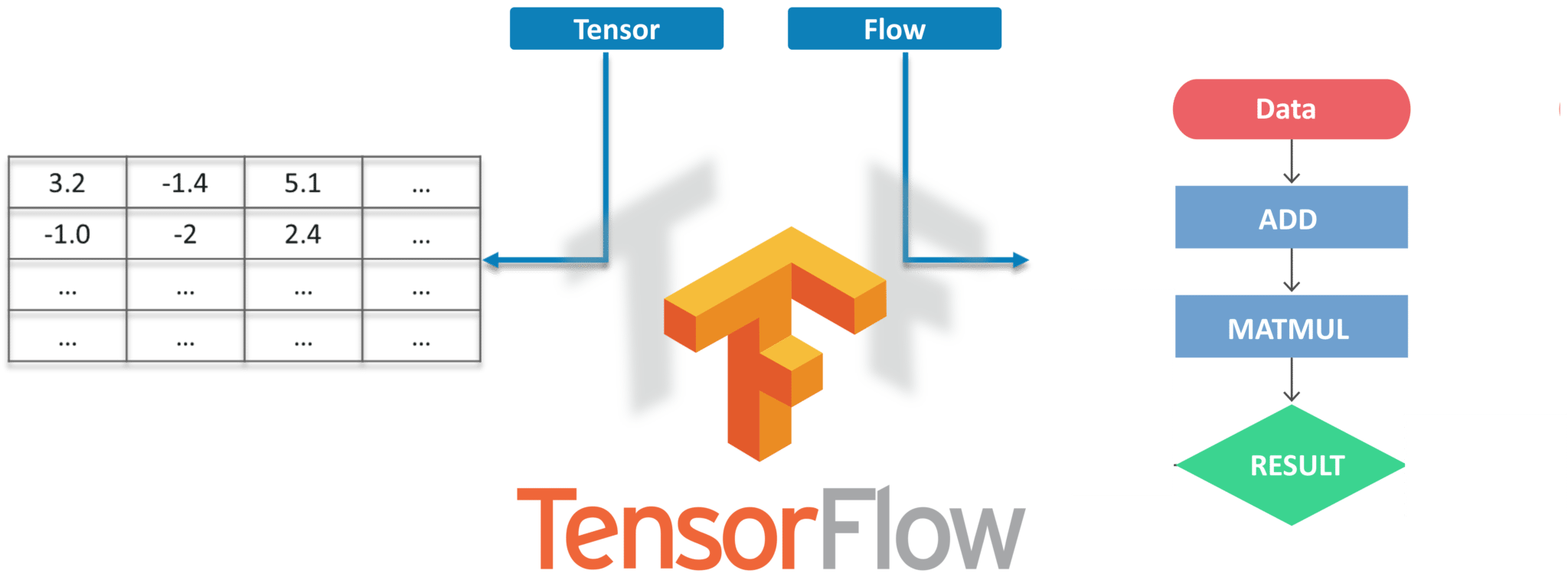
Тензоры — это просто многомерные массивы, расширение двумерных таблиц данных с более высоким измерением. Есть много особенностей Tensorflow, которые делают его подходящим для глубокого обучения. Итак, без лишних слов, давайте посмотрим, как мы можем реализовать обнаружение объектов с помощью Tensorflow.
Учебник по обнаружению объектов
Предпосылки
Прежде чем приступить к демонстрации, давайте посмотрим на предварительные условия:
- питон
- TensorFlow
- TensorBoard
- Protobuf v3.4 или выше
Настройка среды
Чтобы загрузить TensorFlow и TensorFlow GPU, вы можете использовать команды pip или conda:
# For CPU
pip install tensorflow
# For GPU
pip install tensorflow-gpuДля всех остальных библиотек мы можем использовать pip или conda для их установки. Код предоставлен ниже:
pip install --user Cython
pip install --user contextlib2
pip install --user pillow
pip install --user lxml
pip install --user jupyter
pip install --user matplotlibДалее, у нас есть Protobuf: Protocol Buffers (Protobuf) — это не зависящий от языка, не зависящий от платформы, расширяемый механизм Google для сериализации структурированных данных. Думайте об этом как о XML, но меньше, быстрее и проще. Вам нужно скачать Protobuf версии 3.4 или выше для этой демонстрации и распаковать ее.
Теперь вам нужно клонировать или скачать TensorFlow’s Model с GitHub . После загрузки и извлечения переименуйте «моделей-мастеров» в «модели».
Для простоты мы будем хранить «models» и «protobuf» в одной папке с именем «Tensorflow».
Далее нам нужно зайти в папку Tensorflow, а затем в папку исследования и запустить оттуда protobuf с помощью этой команды:
"path_of_protobuf's bin"./bin/protoc object_detection/protos/Чтобы проверить, сработало ли это или нет, вы можете перейти в папку protos в пределах models> object_detection> protos и там, вы можете увидеть, что для каждого proto-файла создан один файл python.
Основной код

После настройки среды вам нужно перейти в каталог «object_detection» и создать новый файл Python. Вы можете использовать Spyder или Jupyter, чтобы написать свой код.
Прежде всего, нам нужно импортировать все библиотеки.
import numpy as np
import os
import six.moves.urllib as urllib
import sys
import tarfile
import tensorflow as tf
import zipfile
from collections import defaultdict
from io import StringIO
from matplotlib import pyplot as plt
from PIL import Image
sys.path.append("..")
from object_detection.utils import ops as utils_ops
from utils import label_map_util
from utils import visualization_utils as vis_utilДалее мы загрузим модель, которая обучается на наборе данных COCO . COCO расшифровывается как Common Objects in Context, и этот набор данных содержит около 330 тыс. Изображений. Выбор модели важен, потому что вам нужно найти компромисс между скоростью и точностью. В зависимости от ваших требований и системной памяти должна быть выбрана правильная модель.
« Models> research> object_detection> g3doc> Detection_model_zoo » содержит все модели с разной скоростью и точностью (mAP).
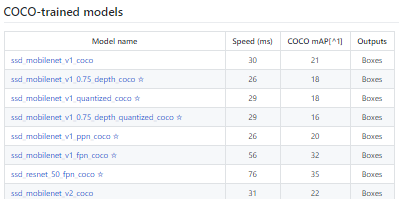
Далее мы предоставляем требуемую модель и замороженный граф вывода, сгенерированный Tensorflow.
MODEL_NAME = 'ssd_mobilenet_v1_coco_2017_11_17'
MODEL_FILE = MODEL_NAME + '.tar.gz'
DOWNLOAD_BASE = 'http://download.tensorflow.org/models/object_detection/'
PATH_TO_CKPT = MODEL_NAME + '/frozen_inference_graph.pb'
PATH_TO_LABELS = os.path.join('data', 'mscoco_label_map.pbtxt')
NUM_CLASSES = 90Этот код загрузит эту модель из Интернета и извлечет замороженный граф вывода этой модели.
opener = urllib.request.URLopener()
opener.retrieve(DOWNLOAD_BASE + MODEL_FILE, MODEL_FILE)
tar_file = tarfile.open(MODEL_FILE)
for file in tar_file.getmembers():
file_name = os.path.basename(file.name)
if 'frozen_inference_graph.pb' in file_name:
tar_file.extract(file, os.getcwd())
detection_graph = tf.Graph()
with detection_graph.as_default():
od_graph_def = tf.GraphDef()
with tf.gfile.GFile(PATH_TO_CKPT, 'rb') as fid:
serialized_graph = fid.read()
od_graph_def.ParseFromString(serialized_graph)
tf.import_graph_def(od_graph_def, name='')Далее мы собираемся загрузить все метки
label_map = label_map_util.load_labelmap(PATH_TO_LABELS)
categories = label_map_util.convert_label_map_to_categories(label_map, max_num_classes=NUM_CLASSES, use_display_name=True)
category_index = label_map_util.create_category_index(categories)
Теперь мы преобразуем данные изображений в массив numPy для обработки.
def load_image_into_numpy_array(image):
(im_width, im_height) = image.size
return np.array(image.getdata()).reshape(
(im_height, im_width, 3)).astype(np.uint8)Путь к изображениям для целей тестирования определяется здесь. У нас есть соглашение об именах «image [i]» для i в (от 1 до n + 1), где n — количество предоставленных изображений.
PATH_TO_TEST_IMAGES_DIR = 'test_images'
TEST_IMAGE_PATHS = [ os.path.join(PATH_TO_TEST_IMAGES_DIR, 'image{}.jpg'.format(i)) for i in range(1, 8) ]Этот код выполняет вывод для одного изображения, где он обнаруживает объекты, создает блоки и предоставляет класс и оценку класса этого конкретного объекта.
def run_inference_for_single_image(image, graph):
with graph.as_default():
with tf.Session() as sess:
# Get handles to input and output tensors
ops = tf.get_default_graph().get_operations()
all_tensor_names = {output.name for op in ops for output in op.outputs}
tensor_dict = {}
for key in [
'num_detections', 'detection_boxes', 'detection_scores',
'detection_classes', 'detection_masks'
]:
tensor_name = key + ':0'
if tensor_name in all_tensor_names:
tensor_dict[key] = tf.get_default_graph().get_tensor_by_name(
tensor_name)
if 'detection_masks' in tensor_dict:
# The following processing is only for single image
detection_boxes = tf.squeeze(tensor_dict['detection_boxes'], [0])
detection_masks = tf.squeeze(tensor_dict['detection_masks'], [0])
# Reframe is required to translate mask from box coordinates to image coordinates and fit the image size.
real_num_detection = tf.cast(tensor_dict['num_detections'][0], tf.int32)
detection_boxes = tf.slice(detection_boxes, [0, 0], [real_num_detection, -1])
detection_masks = tf.slice(detection_masks, [0, 0, 0], [real_num_detection, -1, -1])
detection_masks_reframed = utils_ops.reframe_box_masks_to_image_masks(
detection_masks, detection_boxes, image.shape[0], image.shape[1])
detection_masks_reframed = tf.cast(
tf.greater(detection_masks_reframed, 0.5), tf.uint8)
# Follow the convention by adding back the batch dimension
tensor_dict['detection_masks'] = tf.expand_dims(
detection_masks_reframed, 0)
image_tensor = tf.get_default_graph().get_tensor_by_name('image_tensor:0')
# Run inference
output_dict = sess.run(tensor_dict,
feed_dict={image_tensor: np.expand_dims(image, 0)})
# all outputs are float32 numpy arrays, so convert types as appropriate
output_dict['num_detections'] = int(output_dict['num_detections'][0])
output_dict['detection_classes'] = output_dict[
'detection_classes'][0].astype(np.uint8)
output_dict['detection_boxes'] = output_dict['detection_boxes'][0]
output_dict['detection_scores'] = output_dict['detection_scores'][0]
if 'detection_masks' in output_dict:
output_dict['detection_masks'] = output_dict['detection_masks'][0]
return output_dictНаш последний цикл, который будет вызывать все функции, определенные выше, будет запускать вывод по всем входным изображениям по одному, что обеспечит нам вывод изображений, в которых объекты обнаружены с метками, и процент / оценка этого объекта, являющегося аналогично тренировочным данным.
for image_path in TEST_IMAGE_PATHS:
image = Image.open(image_path)
# the array based representation of the image will be used later in order to prepare the
# result image with boxes and labels on it.
image_np = load_image_into_numpy_array(image)
# Expand dimensions since the model expects images to have shape: [1, None, None, 3]
image_np_expanded = np.expand_dims(image_np, axis=0)
# Actual detection.
output_dict = run_inference_for_single_image(image_np, detection_graph)
# Visualization of the results of a detection.
vis_util.visualize_boxes_and_labels_on_image_array(
image_np,
output_dict['detection_boxes'],
output_dict['detection_classes'],
output_dict['detection_scores'],
category_index,
instance_masks=output_dict.get('detection_masks'),
use_normalized_coordinates=True,
line_thickness=8)
plt.figure(figsize=IMAGE_SIZE)
plt.imshow(image_np)
Теперь давайте посмотрим, как мы можем обнаруживать объекты в прямом эфире видео.
Обнаружение живых объектов с использованием Tensorflow
Для этой демонстрации мы будем использовать тот же код, но немного подправим. Мы собираемся использовать OpenCV и модуль камеры, чтобы использовать прямую трансляцию веб-камеры для обнаружения объектов.
Добавьте библиотеку OpenCV и камеру, используемую для захвата изображений. Просто добавьте следующие строки в раздел библиотеки импорта.
import cv2
cap = cv2.VideoCapture(0)Нам не нужно загружать изображения из каталога и конвертировать его в массив numPy, так как OpenCV позаботится об этом за нас.
Заменить это:
for image_path in TEST_IMAGE_PATHS:
image = Image.open(image_path)
# the array based representation of the image will be used later in order to prepare the
# result image with boxes and labels on it.
image_np = load_image_into_numpy_array(image)С этим:
while True:
ret, image_np = cap.read()Мы не будем использовать matplotlib для окончательного показа изображения. Вместо этого мы будем использовать OpenCV и для этого. Для этого…
Удали это:
cv2.imshow('object detection', cv2.resize(image_np, (800,600)))
if cv2.waitKey(25) & 0xFF == ord('q'):
cv2.destroyAllWindows()
breakЭтот код будет использовать OpenCV, который, в свою очередь, будет использовать объект камеры, инициализированный ранее, чтобы открыть новое окно с именем « Object_Detection » размером «800 × 600». Камера будет показывать изображения в течение 25 миллисекунд, в противном случае она закроет окно.
Окончательный код со всеми изменениями:
import numpy as np
import os
import six.moves.urllib as urllib
import sys
import tarfile
import tensorflow as tf
import zipfile
from collections import defaultdict
from io import StringIO
from matplotlib import pyplot as plt
from PIL import Image
import cv2
cap = cv2.VideoCapture(0)
sys.path.append("..")
from utils import label_map_util
from utils import visualization_utils as vis_util
MODEL_NAME = 'ssd_mobilenet_v1_coco_11_06_2017'
MODEL_FILE = MODEL_NAME + '.tar.gz'
DOWNLOAD_BASE = 'http://download.tensorflow.org/models/object_detection/'
# Path to frozen detection graph. This is the actual model that is used for the object detection.
PATH_TO_CKPT = MODEL_NAME + '/frozen_inference_graph.pb'
# List of the strings that is used to add correct label for each box.
PATH_TO_LABELS = os.path.join('data', 'mscoco_label_map.pbtxt')
NUM_CLASSES = 90
opener = urllib.request.URLopener()
opener.retrieve(DOWNLOAD_BASE + MODEL_FILE, MODEL_FILE)
tar_file = tarfile.open(MODEL_FILE)
for file in tar_file.getmembers():
file_name = os.path.basename(file.name)
if 'frozen_inference_graph.pb' in file_name:
tar_file.extract(file, os.getcwd())
detection_graph = tf.Graph()
with detection_graph.as_default():
od_graph_def = tf.GraphDef()
with tf.gfile.GFile(PATH_TO_CKPT, 'rb') as fid:
serialized_graph = fid.read()
od_graph_def.ParseFromString(serialized_graph)
tf.import_graph_def(od_graph_def, name='')
label_map = label_map_util.load_labelmap(PATH_TO_LABELS)
categories = label_map_util.convert_label_map_to_categories(label_map, max_num_classes=NUM_CLASSES, use_display_name=True)
category_index = label_map_util.create_category_index(categories)
with detection_graph.as_default():
with tf.Session(graph=detection_graph) as sess:
while True:
ret, image_np = cap.read()
# Expand dimensions since the model expects images to have shape: [1, None, None, 3]
image_np_expanded = np.expand_dims(image_np, axis=0)
image_tensor = detection_graph.get_tensor_by_name('image_tensor:0')
# Each box represents a part of the image where a particular object was detected.
boxes = detection_graph.get_tensor_by_name('detection_boxes:0')
# Each score represent how level of confidence for each of the objects.
# Score is shown on the result image, together with the class label.
scores = detection_graph.get_tensor_by_name('detection_scores:0')
classes = detection_graph.get_tensor_by_name('detection_classes:0')
num_detections = detection_graph.get_tensor_by_name('num_detections:0')
# Actual detection.
(boxes, scores, classes, num_detections) = sess.run(
[boxes, scores, classes, num_detections],
feed_dict={image_tensor: image_np_expanded})
# Visualization of the results of a detection.
vis_util.visualize_boxes_and_labels_on_image_array(
image_np,
np.squeeze(boxes),
np.squeeze(classes).astype(np.int32),
np.squeeze(scores),
category_index,
use_normalized_coordinates=True,
line_thickness=8)
cv2.imshow('object detection', cv2.resize(image_np, (800,600)))
if cv2.waitKey(25) 0xFF == ord('q'):
cv2.destroyAllWindows()
breakЯ надеюсь, что вам всем понравилась эта статья, и теперь вы понимаете всю мощь Tensorflow и то, как легко обнаруживать объекты на изображениях и в прямом эфире. Итак, если вы прочитали это, вы больше не новичок в обнаружении объектов и TensorFlow. Попробуйте эти примеры и дайте мне знать, если у вас возникнут какие-либо проблемы при развертывании кода.