В этой главе мы узнаем о распознавании речи с использованием AI с Python.
Речь — самое основное средство общения взрослого человека. Основная цель обработки речи — обеспечить взаимодействие человека и машины.
Система обработки речи имеет в основном три задачи —
-
Во-первых , распознавание речи, которое позволяет машине поймать слова, фразы и предложения, которые мы говорим
-
Во-вторых , обработка естественного языка, чтобы позволить машине понять, что мы говорим, и
-
В-третьих , синтез речи, чтобы позволить машине говорить.
Во-первых , распознавание речи, которое позволяет машине поймать слова, фразы и предложения, которые мы говорим
Во-вторых , обработка естественного языка, чтобы позволить машине понять, что мы говорим, и
В-третьих , синтез речи, чтобы позволить машине говорить.
В этой главе основное внимание уделяется распознаванию речи , процессу понимания слов, произносимых людьми. Помните, что речевые сигналы улавливаются с помощью микрофона, а затем это должно быть понято системой.
Создание распознавателя речи
Распознавание речи или автоматическое распознавание речи (ASR) является центром внимания для проектов ИИ, таких как робототехника. Без ASR невозможно представить когнитивного робота, взаимодействующего с человеком. Однако не всегда легко создать распознаватель речи.
Трудности в разработке системы распознавания речи
Разработка высококачественной системы распознавания речи — действительно сложная проблема. Сложность технологии распознавания речи может быть в целом охарактеризована по ряду аспектов, которые обсуждаются ниже —
-
Размер словарного запаса — размер словарного запаса влияет на легкость разработки ASR. Рассмотрим следующие размеры словарного запаса для лучшего понимания.
-
Небольшой словарный запас состоит из 2-100 слов, например, как в системе голосового меню
-
Лексика среднего размера состоит, например, из нескольких сотен-тысяч слов, как в задаче поиска в базе данных.
-
Большой словарный запас состоит из нескольких тысяч слов, как в общей задаче диктовки.
-
Характеристики канала. Качество канала также является важным аспектом. Например, человеческая речь содержит широкую полосу частот с полным частотным диапазоном, тогда как телефонная речь состоит из низкой полосы пропускания с ограниченным частотным диапазоном. Обратите внимание, что в последнем сложнее.
-
Режим речи — Простота разработки ASR также зависит от режима речи, то есть, находится ли речь в режиме изолированного слова, или в режиме связанного слова, или в режиме непрерывной речи. Обратите внимание, что непрерывную речь труднее распознать.
-
Стиль речи — прочитанная речь может быть в формальном стиле или спонтанной и разговорной со случайным стилем. Последнее сложнее распознать.
-
Зависимость от говорящего — речь может быть зависимой от говорящего, адаптивной или независимой от говорящего. Труднее всего создать независимый динамик.
-
Тип шума — Шум является еще одним фактором, который следует учитывать при разработке ASR. Отношение сигнал / шум может быть в различных диапазонах, в зависимости от акустической среды, которая наблюдает меньше, чем фоновый шум —
-
Если отношение сигнал / шум превышает 30 дБ, оно считается высоким диапазоном
-
Если отношение сигнал / шум находится между 30 дБ и 10 дБ, оно считается средним SNR
-
Если отношение сигнал / шум меньше 10 дБ, оно считается низким диапазоном
-
Характеристики микрофона . Качество микрофона может быть хорошим, средним или ниже среднего. Кроме того, расстояние между ртом и микрофоном может варьироваться. Эти факторы также следует учитывать для систем распознавания.
Обратите внимание: чем больше размер словарного запаса, тем сложнее выполнить распознавание.
Например, тип фонового шума, такого как стационарный, нечеловеческий шум, фоновая речь и перекрестные помехи от других громкоговорителей, также усугубляет проблему.
Размер словарного запаса — размер словарного запаса влияет на легкость разработки ASR. Рассмотрим следующие размеры словарного запаса для лучшего понимания.
Небольшой словарный запас состоит из 2-100 слов, например, как в системе голосового меню
Лексика среднего размера состоит, например, из нескольких сотен-тысяч слов, как в задаче поиска в базе данных.
Большой словарный запас состоит из нескольких тысяч слов, как в общей задаче диктовки.
Обратите внимание: чем больше размер словарного запаса, тем сложнее выполнить распознавание.
Характеристики канала. Качество канала также является важным аспектом. Например, человеческая речь содержит широкую полосу частот с полным частотным диапазоном, тогда как телефонная речь состоит из низкой полосы пропускания с ограниченным частотным диапазоном. Обратите внимание, что в последнем сложнее.
Режим речи — Простота разработки ASR также зависит от режима речи, то есть, находится ли речь в режиме изолированного слова, или в режиме связанного слова, или в режиме непрерывной речи. Обратите внимание, что непрерывную речь труднее распознать.
Стиль речи — прочитанная речь может быть в формальном стиле или спонтанной и разговорной со случайным стилем. Последнее сложнее распознать.
Зависимость от говорящего — речь может быть зависимой от говорящего, адаптивной или независимой от говорящего. Труднее всего создать независимый динамик.
Тип шума — Шум является еще одним фактором, который следует учитывать при разработке ASR. Отношение сигнал / шум может быть в различных диапазонах, в зависимости от акустической среды, которая наблюдает меньше, чем фоновый шум —
Если отношение сигнал / шум превышает 30 дБ, оно считается высоким диапазоном
Если отношение сигнал / шум находится между 30 дБ и 10 дБ, оно считается средним SNR
Если отношение сигнал / шум меньше 10 дБ, оно считается низким диапазоном
Например, тип фонового шума, такого как стационарный, нечеловеческий шум, фоновая речь и перекрестные помехи от других громкоговорителей, также усугубляет проблему.
Характеристики микрофона . Качество микрофона может быть хорошим, средним или ниже среднего. Кроме того, расстояние между ртом и микрофоном может варьироваться. Эти факторы также следует учитывать для систем распознавания.
Несмотря на эти трудности, исследователи много работали над различными аспектами речи, такими как понимание речевого сигнала, говорящего и определение акцентов.
Вы должны будете выполнить шаги, описанные ниже, чтобы создать распознаватель речи —
Визуализация аудиосигналов — чтение из файла и работа с ним
Это первый шаг в построении системы распознавания речи, поскольку он дает понимание того, как структурирован звуковой сигнал. Вот некоторые общие шаги, которые можно выполнить для работы со звуковыми сигналами:
запись
Если вам необходимо прочитать аудиосигнал из файла, то сначала запишите его с помощью микрофона.
отбор проб
При записи с микрофона сигналы сохраняются в оцифрованном виде. Но чтобы работать над этим, машина нуждается в них в дискретной числовой форме. Следовательно, мы должны выполнить выборку на определенной частоте и преобразовать сигнал в дискретную числовую форму. Выбор высокой частоты для выборки подразумевает, что когда люди слушают сигнал, они чувствуют его как непрерывный звуковой сигнал.
пример
В следующем примере показан пошаговый подход к анализу аудиосигнала с использованием Python, который хранится в файле. Частота этого аудиосигнала составляет 44 100 Гц.
Импортируйте необходимые пакеты, как показано здесь —
import numpy as np import matplotlib.pyplot as plt from scipy.io import wavfile
Теперь прочитайте сохраненный аудиофайл. Он вернет два значения: частоту дискретизации и аудиосигнал. Укажите путь к аудиофайлу, где он хранится, как показано здесь —
frequency_sampling, audio_signal = wavfile.read("/Users/admin/audio_file.wav")
Отобразите такие параметры, как частота дискретизации аудиосигнала, тип данных сигнала и его длительность, используя показанные команды —
print('\nSignal shape:', audio_signal.shape) print('Signal Datatype:', audio_signal.dtype) print('Signal duration:', round(audio_signal.shape[0] / float(frequency_sampling), 2), 'seconds')
Этот шаг включает в себя нормализацию сигнала, как показано ниже —
audio_signal = audio_signal / np.power(2, 15)
На этом шаге мы извлекаем первые 100 значений из этого сигнала для визуализации. Используйте следующие команды для этой цели —
audio_signal = audio_signal [:100] time_axis = 1000 * np.arange(0, len(signal), 1) / float(frequency_sampling)
Теперь визуализируйте сигнал, используя команды, приведенные ниже —
plt.plot(time_axis, signal, color='blue') plt.xlabel('Time (milliseconds)') plt.ylabel('Amplitude') plt.title('Input audio signal') plt.show()
Вы сможете увидеть выходной график и данные, извлеченные для вышеуказанного аудиосигнала, как показано на рисунке здесь
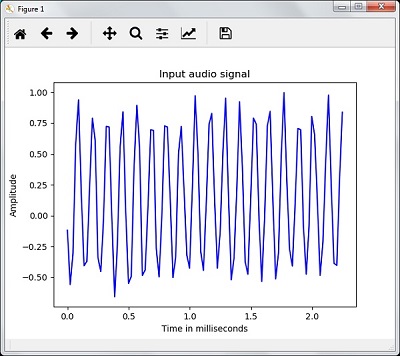
Signal shape: (132300,) Signal Datatype: int16 Signal duration: 3.0 seconds
Характеризация звукового сигнала: преобразование в частотную область
Характеристика аудиосигнала включает в себя преобразование сигнала временной области в частотную область и понимание его частотных составляющих посредством. Это важный шаг, потому что он дает много информации о сигнале. Вы можете использовать математический инструмент, такой как преобразование Фурье, чтобы выполнить это преобразование.
пример
В следующем примере шаг за шагом показано, как охарактеризовать сигнал с помощью Python, который хранится в файле. Обратите внимание, что здесь мы используем математический инструмент преобразования Фурье для преобразования его в частотную область.
Импортируйте необходимые пакеты, как показано здесь —
import numpy as np import matplotlib.pyplot as plt from scipy.io import wavfile
Теперь прочитайте сохраненный аудиофайл. Он вернет два значения: частоту дискретизации и звуковой сигнал. Укажите путь к аудиофайлу, в котором он хранится, как показано здесь в команде —
frequency_sampling, audio_signal = wavfile.read("/Users/admin/sample.wav")
На этом шаге мы отобразим такие параметры, как частота дискретизации аудиосигнала, тип данных сигнала и его длительность, используя команды, приведенные ниже —
print('\nSignal shape:', audio_signal.shape) print('Signal Datatype:', audio_signal.dtype) print('Signal duration:', round(audio_signal.shape[0] / float(frequency_sampling), 2), 'seconds')
На этом этапе нам нужно нормализовать сигнал, как показано в следующей команде —
audio_signal = audio_signal / np.power(2, 15)
Этот шаг включает в себя извлечение длины и половины длины сигнала. Используйте следующие команды для этой цели —
length_signal = len(audio_signal) half_length = np.ceil((length_signal + 1) / 2.0).astype(np.int)
Теперь нам нужно применить математические инструменты для преобразования в частотную область. Здесь мы используем преобразование Фурье.
signal_frequency = np.fft.fft(audio_signal)
Теперь сделайте нормализацию сигнала в частотной области и возведите в квадрат —
signal_frequency = abs(signal_frequency[0:half_length]) / length_signal signal_frequency **= 2
Далее извлекаем длину и половину длины преобразованного по частоте сигнала —
len_fts = len(signal_frequency)
Обратите внимание, что преобразованный Фурье сигнал должен быть скорректирован для четного и нечетного случая.
if length_signal % 2: signal_frequency[1:len_fts] *= 2 else: signal_frequency[1:len_fts-1] *= 2
Теперь извлеките мощность в децибелах (дБ) —
signal_power = 10 * np.log10(signal_frequency)
Отрегулируйте частоту в кГц для оси X —
x_axis = np.arange(0, len_half, 1) * (frequency_sampling / length_signal) / 1000.0
Теперь визуализируйте характеристику сигнала следующим образом:
plt.figure() plt.plot(x_axis, signal_power, color='black') plt.xlabel('Frequency (kHz)') plt.ylabel('Signal power (dB)') plt.show()
Вы можете наблюдать выходной график вышеуказанного кода, как показано на рисунке ниже —
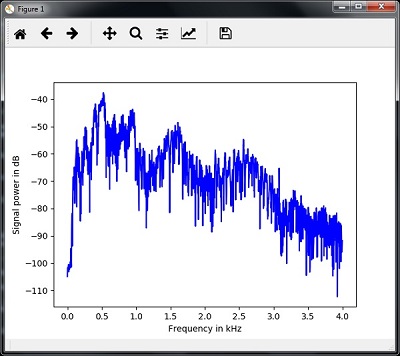
Генерация монотонного звукового сигнала
Два шага, которые вы видели до сих пор, важны для изучения сигналов. Теперь этот шаг будет полезен, если вы хотите сгенерировать аудиосигнал с некоторыми предопределенными параметрами. Обратите внимание, что этот шаг сохранит аудиосигнал в выходной файл.
пример
В следующем примере мы собираемся сгенерировать монотонный сигнал, используя Python, который будет храниться в файле. Для этого вам нужно будет предпринять следующие шаги —
Импортируйте необходимые пакеты, как показано на рисунке —
import numpy as np import matplotlib.pyplot as plt from scipy.io.wavfile import write
Укажите файл, в котором должен быть сохранен выходной файл
output_file = 'audio_signal_generated.wav'
Теперь укажите параметры по вашему выбору, как показано на рисунке —
duration = 4 # in seconds frequency_sampling = 44100 # in Hz frequency_tone = 784 min_val = -4 * np.pi max_val = 4 * np.pi
На этом этапе мы можем генерировать звуковой сигнал, как показано на рисунке —
t = np.linspace(min_val, max_val, duration * frequency_sampling) audio_signal = np.sin(2 * np.pi * tone_freq * t)
Теперь сохраните аудиофайл в выходной файл —
write(output_file, frequency_sampling, signal_scaled)
Извлеките первые 100 значений для нашего графика, как показано на рисунке —
audio_signal = audio_signal[:100] time_axis = 1000 * np.arange(0, len(signal), 1) / float(sampling_freq)
Теперь визуализируйте сгенерированный аудиосигнал следующим образом:
plt.plot(time_axis, signal, color='blue') plt.xlabel('Time in milliseconds') plt.ylabel('Amplitude') plt.title('Generated audio signal') plt.show()
Вы можете наблюдать за сюжетом, как показано на рисунке ниже —
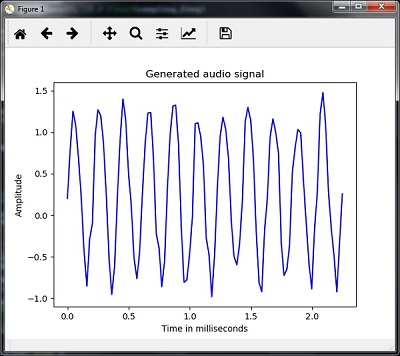
Извлечение функций из речи
Это самый важный шаг в создании распознавателя речи, потому что после преобразования речевого сигнала в частотную область мы должны преобразовать его в используемую форму вектора признаков. Для этой цели мы можем использовать различные методы извлечения признаков, такие как MFCC, PLP, PLP-RASTA и т. Д.
пример
В следующем примере мы собираемся постепенно извлечь элементы из сигнала, используя Python, используя технику MFCC.
Импортируйте необходимые пакеты, как показано здесь —
import numpy as np import matplotlib.pyplot as plt from scipy.io import wavfile from python_speech_features import mfcc, logfbank
Теперь прочитайте сохраненный аудиофайл. Он вернет два значения — частоту дискретизации и аудиосигнал. Укажите путь к аудиофайлу, в котором он хранится.
frequency_sampling, audio_signal = wavfile.read("/Users/admin/audio_file.wav")
Обратите внимание, что здесь мы берем первые 15000 образцов для анализа.
audio_signal = audio_signal[:15000]
Используйте методы MFCC и выполните следующую команду, чтобы извлечь функции MFCC:
features_mfcc = mfcc(audio_signal, frequency_sampling)
Теперь напечатайте параметры MFCC, как показано на рисунке —
print('\nMFCC:\nNumber of windows =', features_mfcc.shape[0]) print('Length of each feature =', features_mfcc.shape[1])
Теперь постройте и визуализируйте функции MFCC, используя команды, приведенные ниже —
features_mfcc = features_mfcc.T plt.matshow(features_mfcc) plt.title('MFCC')
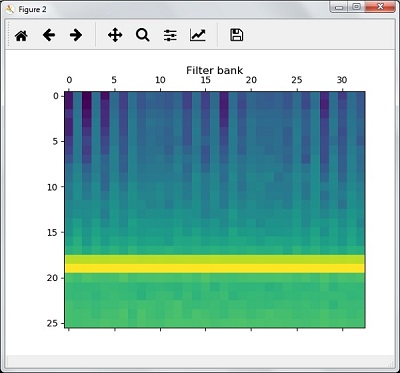
На этом этапе мы работаем с функциями банка фильтров, как показано на рисунке —
Извлечь особенности банка фильтров —
filterbank_features = logfbank(audio_signal, frequency_sampling)
Теперь напечатайте параметры набора фильтров.
print('\nFilter bank:\nNumber of windows =', filterbank_features.shape[0]) print('Length of each feature =', filterbank_features.shape[1])
Теперь постройте и визуализируйте функции набора фильтров.
filterbank_features = filterbank_features.T plt.matshow(filterbank_features) plt.title('Filter bank') plt.show()
В результате выполнения описанных выше шагов вы можете наблюдать следующие результаты: Рисунок 1 для MFCC и Рисунок 2 для Банка фильтров
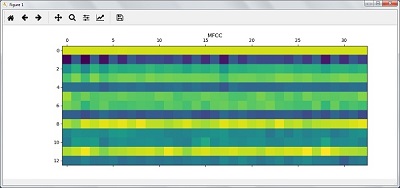
Распознавание произнесенных слов
Распознавание речи означает, что когда люди говорят, машина это понимает. Здесь мы используем Google Speech API в Python, чтобы это произошло. Для этого нам нужно установить следующие пакеты:
-
Pyaudio — его можно установить с помощью команды pip install Pyaudio .
-
SpeechRecognition — этот пакет можно установить с помощью pip install SpeechRecognition.
-
Google-Speech-API — его можно установить с помощью команды pip install google-api-python-client .
Pyaudio — его можно установить с помощью команды pip install Pyaudio .
SpeechRecognition — этот пакет можно установить с помощью pip install SpeechRecognition.
Google-Speech-API — его можно установить с помощью команды pip install google-api-python-client .
пример
Обратите внимание на следующий пример, чтобы понять о распознавании произнесенных слов —
Импортируйте необходимые пакеты, как показано на рисунке —
import speech_recognition as sr
Создайте объект, как показано ниже —
recording = sr.Recognizer()
Теперь модуль Microphone () примет голос в качестве входа —
with sr.Microphone() as source: recording.adjust_for_ambient_noise(source) print("Please Say something:") audio = recording.listen(source)
Теперь Google API распознает голос и выдает результат.
try:
print("You said: \n" + recording.recognize_google(audio))
except Exception as e:
print(e)
Вы можете увидеть следующий вывод —
Please Say Something: You said:
Например, если вы сказали tutorialspoint.com , то система распознает его правильно следующим образом: