D Программирование — Обзор
Язык программирования D — это объектно-ориентированный язык системного мультипарадигмального программирования, разработанный Вальтером Брайтом из Digital Mars. Его разработка началась в 1999 году и была впервые выпущена в 2001 году. Основная версия D (1.0) была выпущена в 2007 году. В настоящее время у нас есть версия D. для D2
D — это язык с синтаксисом в стиле C и использует статическую типизацию. Есть много возможностей C и C ++ в D, но также есть некоторые возможности этого языка, не включенные в D. Некоторые из заметных дополнений к D включают:
- Модульное тестирование
- Истинные модули
- Вывоз мусора
- Массивы первого класса
- Свободно и открыто
- Ассоциативные массивы
- Динамические массивы
- Внутренние классы
- Затворы
- Анонимные функции
- Ленивая оценка
- Затворы
Несколько Парадигм
D — это язык программирования с несколькими парадигмами. Несколько парадигм включает в себя,
- Императив
- Объектно-ориентированный
- Метапрограммирование
- функциональная
- параллельный
пример
import std.stdio; void main(string[] args) { writeln("Hello World!"); }
Учимся Д
Самое важное, что нужно сделать при изучении языка D, это сосредоточиться на концепциях, а не потеряться в технических деталях языка.
Цель изучения языка программирования — стать лучшим программистом; то есть, чтобы стать более эффективным в разработке и внедрении новых систем и в поддержании старых.
Область применения D
У D-программирования есть некоторые интересные особенности, и официальный сайт D-программ утверждает, что D удобен, мощен и эффективен. D-программирование добавляет в базовый язык множество функций, которые язык C предоставил в виде стандартных библиотек, таких как массив с изменяемыми размерами и строковые функции. D делает отличный второй язык для средних и продвинутых программистов. D лучше обрабатывает память и управляет указателями, что часто вызывает проблемы в C ++.
D программирование предназначено в основном для новых программ, которые конвертируют существующие программы. Он обеспечивает встроенное тестирование и верификацию, идеально подходящие для большого нового проекта, который будет написан миллионами строк кода большими командами.
D Программирование — Окружающая среда
Настройка локальной среды для D
Если вы все еще хотите настроить свою среду для языка программирования D, вам потребуются следующие два программного обеспечения, доступные на вашем компьютере: (а) текстовый редактор, (б) компилятор D.
Текстовый редактор для программирования D
Это будет использоваться для ввода вашей программы. Примерами немногих редакторов являются Блокнот Windows, команда редактирования ОС, Brief, Epsilon, EMACS и vim или vi.
Имя и версия текстового редактора могут различаться в разных операционных системах. Например, Блокнот будет использоваться в Windows, а vim или vi могут использоваться в Windows, а также в Linux или UNIX.
Файлы, которые вы создаете в редакторе, называются исходными файлами и содержат исходный код программы. Исходные файлы для программ D названы с расширением » .d «.
Перед началом программирования убедитесь, что у вас есть один текстовый редактор, и у вас достаточно опыта, чтобы написать компьютерную программу, сохранить ее в файле, собрать и, наконец, выполнить.
Компилятор D
Большинство современных реализаций D компилируются непосредственно в машинный код для эффективного выполнения.
У нас есть несколько доступных D-компиляторов, и это включает следующее.
-
DMD — Компилятор Digital Mars D является официальным компилятором D от Walter Bright.
-
GDC — внешний интерфейс для GCC, созданный с использованием открытого исходного кода компилятора DMD.
-
LDC — Компилятор, основанный на внешнем интерфейсе DMD, который использует LLVM в качестве своего внутреннего конца для компилятора.
DMD — Компилятор Digital Mars D является официальным компилятором D от Walter Bright.
GDC — внешний интерфейс для GCC, созданный с использованием открытого исходного кода компилятора DMD.
LDC — Компилятор, основанный на внешнем интерфейсе DMD, который использует LLVM в качестве своего внутреннего конца для компилятора.
Вышеупомянутые различные компиляторы могут быть загружены из загрузок D
Мы будем использовать версию D 2, и мы рекомендуем не загружать D1.
Давайте запустим программу helloWorld.d следующим образом. Мы будем использовать это как первую программу, которую мы запускаем на выбранной вами платформе.
import std.stdio; void main(string[] args) { writeln("Hello World!"); }
Мы можем увидеть следующий вывод.
$ hello world
Установка D на Windows
Загрузите установщик Windows.
Запустите загруженный исполняемый файл, чтобы установить D, что можно сделать, следуя инструкциям на экране.
Теперь мы можем создать и запустить рекламный файл, скажем, helloWorld.d, перейдя в папку, содержащую файл, используя cd, а затем выполнив следующие шаги:
C:\DProgramming> DMD helloWorld.d C:\DProgramming> helloWorld
Мы можем увидеть следующий вывод.
hello world
C: \ DProgramming — это папка, которую я использую для сохранения сэмплов. Вы можете изменить его в папку, в которой вы сохранили D программ.
Установка D на Ubuntu / Debian
Загрузите установщик Debian.
Запустите загруженный исполняемый файл, чтобы установить D, что можно сделать, следуя инструкциям на экране.
Теперь мы можем создать и запустить рекламный файл, скажем, helloWorld.d, перейдя в папку, содержащую файл, используя cd, а затем выполнив следующие шаги:
$ dmd helloWorld.d $ ./helloWorld
Мы можем увидеть следующий вывод.
$ hello world
Установка D на Mac OS X
Загрузите установщик Mac.
Запустите загруженный исполняемый файл, чтобы установить D, что можно сделать, следуя инструкциям на экране.
Теперь мы можем создать и запустить рекламный файл, скажем, helloWorld.d, перейдя в папку, содержащую файл, используя cd, а затем выполнив следующие шаги:
$ dmd helloWorld.d $ ./helloWorld
Мы можем увидеть следующий вывод.
$ hello world
Установка D на Fedora
Загрузите установщик fedora.
Запустите загруженный исполняемый файл, чтобы установить D, что можно сделать, следуя инструкциям на экране.
Теперь мы можем создать и запустить рекламный файл, скажем, helloWorld.d, перейдя в папку, содержащую файл, используя cd, а затем выполнив следующие шаги:
$ dmd helloWorld.d $ ./helloWorld
Мы можем увидеть следующий вывод.
$ hello world
Установка D на OpenSUSE
Загрузите установщик OpenSUSE.
Запустите загруженный исполняемый файл, чтобы установить D, что можно сделать, следуя инструкциям на экране.
Теперь мы можем создать и запустить рекламный файл, скажем, helloWorld.d, перейдя в папку, содержащую файл, используя cd, а затем выполнив следующие шаги:
$ dmd helloWorld.d $ ./helloWorld
Мы можем увидеть следующий вывод.
$ hello world
D IDE
У нас есть поддержка IDE для D в виде плагинов в большинстве случаев. Это включает,
-
Плагин Visual D — это плагин для Visual Studio 2005-13
-
DDT — это плагин Eclipse, который обеспечивает завершение кода, отладку с помощью GDB.
-
Завершение кода Mono-D , рефакторинг с поддержкой dmd / ldc / gdc. Он был частью GSoC 2012.
-
Code Blocks — это многоплатформенная IDE, которая поддерживает создание, выделение и отладку D-проекта.
Плагин Visual D — это плагин для Visual Studio 2005-13
DDT — это плагин Eclipse, который обеспечивает завершение кода, отладку с помощью GDB.
Завершение кода Mono-D , рефакторинг с поддержкой dmd / ldc / gdc. Он был частью GSoC 2012.
Code Blocks — это многоплатформенная IDE, которая поддерживает создание, выделение и отладку D-проекта.
D Программирование — основной синтаксис
Программа D довольно проста в изучении и позволяет начать создавать нашу первую программу D!
Первая программа D
Давайте напишем простую D-программу. Все файлы D будут иметь расширение .d. Поэтому поместите следующий исходный код в файл test.d.
import std.stdio; /* My first program in D */ void main(string[] args) { writeln("test!"); }
Предполагая, что среда D настроена правильно, давайте запустим программирование, используя —
$ dmd test.d $ ./test
Мы можем увидеть следующий вывод.
test
Давайте теперь посмотрим на основную структуру D-программы, чтобы вам было легко понять основные строительные блоки языка D-программирования.
Импорт в D
Библиотеки, которые являются коллекциями многократно используемых частей программы, могут быть сделаны доступными для нашего проекта с помощью импорта. Здесь мы импортируем стандартную библиотеку io, которая обеспечивает основные операции ввода-вывода. Writeln, который используется в вышеуказанной программе, является функцией стандартной библиотеки D. Используется для печати строки текста. Содержимое библиотеки в D сгруппировано в модули, которые основаны на типах задач, которые они намерены выполнять. Единственный модуль, который использует эта программа, это std.stdio, который обрабатывает ввод и вывод данных.
Основная функция
Основная функция — запуск программы, и она определяет порядок выполнения и порядок выполнения других разделов программы.
Жетоны в D
Программа AD состоит из различных токенов, и токен — это либо ключевое слово, идентификатор, константа, строковый литерал, либо символ. Например, следующий оператор D состоит из четырех токенов —
writeln("test!");
Отдельные токены —
writeln ( "test!" ) ;
Комментарии
Комментарии подобны вспомогательному тексту в вашей D-программе и игнорируются компилятором. Многострочный комментарий начинается с / * и заканчивается символами * /, как показано ниже —
/* My first program in D */
Отдельный комментарий пишется с использованием // в начале комментария.
// my first program in D
Идентификаторы
Идентификатор AD — это имя, используемое для идентификации переменной, функции или любого другого определенного пользователем элемента. Идентификатор начинается с буквы от A до Z или от a до z или подчеркивания _, за которым следуют ноль или более букв, подчеркиваний и цифр (от 0 до 9).
D не допускает использование знаков препинания, таких как @, $ и% в идентификаторах. D — чувствительный к регистру язык программирования. Таким образом, рабочая сила и рабочая сила — это два разных идентификатора в D. Вот несколько примеров допустимых идентификаторов:
mohd zara abc move_name a_123 myname50 _temp j a23b9 retVal
Ключевые слова
В следующем списке показано несколько зарезервированных слов в D. Эти зарезервированные слова нельзя использовать в качестве имен констант, переменных или любых других идентификаторов.
| Аннотация | псевдоним | выравнивать | как м |
| утверждать | авто | тело | BOOL |
| байт | дело | бросать | ловить |
| голец | учебный класс | Const | Продолжить |
| dchar | отлаживать | дефолт | делегат |
| осуждается | делать | двойной | еще |
| перечисление | экспорт | внешний | ложный |
| окончательный | в конце концов | поплавок | за |
| для каждого | функция | идти к | если |
| Импортировать | в | INOUT | ИНТ |
| интерфейс | инвариантный | является | долго |
| макрос | Mixin | модуль | новый |
| ноль | из | переопределение | пакет |
| прагма | частный | защищенный | общественности |
| реальный | ссылка | вернуть | объем |
| короткая | статический | структура | супер |
| переключатель | синхронизированный | шаблон | этот |
| бросать | правда | пытаться | TypeId |
| тип | UBYTE | UINT | ULONG |
| союз | модульный тест | USHORT | версия |
| недействительным | WCHAR | в то время как | с |
Пробел в D
Строка, содержащая только пробел, возможно, с комментарием, называется пустой строкой, и D-компилятор полностью игнорирует ее.
Пробел — это термин, используемый в D для описания пробелов, вкладок, символов новой строки и комментариев. Пробелы отделяют одну часть оператора от другой и позволяют интерпретатору определить, где заканчивается один элемент в выражении, например int, и начинается следующий элемент. Поэтому в следующем утверждении —
local age
Должен быть хотя бы один пробельный символ (обычно пробел) между местным и возрастом, чтобы переводчик мог их различить. С другой стороны, в следующем утверждении
int fruit = apples + oranges //get the total fruits
Никаких пробельных символов не требуется между фруктами и = или между = и яблоками, хотя вы можете включить некоторые из них, если хотите, чтобы они были удобочитаемыми.
D Программирование — Переменные
Переменная — это не что иное, как имя, данное области памяти, которой могут манипулировать наши программы. Каждая переменная в D имеет определенный тип, который определяет размер и расположение памяти переменной; диапазон значений, которые могут быть сохранены в этой памяти; и набор операций, которые могут быть применены к переменной.
Имя переменной может состоять из букв, цифр и символа подчеркивания. Он должен начинаться либо с буквы, либо с подчеркивания. Прописные и строчные буквы различны, потому что D чувствителен к регистру. Основываясь на базовых типах, описанных в предыдущей главе, будут следующие базовые типы переменных:
| Sr.No. | Тип и описание |
|---|---|
| 1 |
голец Обычно один октет (один байт). Это целочисленный тип. |
| 2 |
ИНТ Наиболее натуральный размер целого числа для машины. |
| 3 |
поплавок Значение с плавающей запятой одинарной точности. |
| 4 |
двойной Значение с плавающей запятой двойной точности. |
| 5 |
недействительным Представляет отсутствие типа. |
голец
Обычно один октет (один байт). Это целочисленный тип.
ИНТ
Наиболее натуральный размер целого числа для машины.
поплавок
Значение с плавающей запятой одинарной точности.
двойной
Значение с плавающей запятой двойной точности.
недействительным
Представляет отсутствие типа.
Язык программирования D также позволяет определять различные другие типы переменных, такие как перечисление, указатель, массив, структура, объединение и т. Д., Которые мы рассмотрим в следующих главах. Для этой главы давайте изучим только основные типы переменных.
Определение переменной в D
Определение переменной сообщает компилятору, где и сколько места нужно создать для переменной. Определение переменной определяет тип данных и содержит список из одной или нескольких переменных этого типа следующим образом:
type variable_list;
Здесь тип должен быть допустимым типом данных D, включая char, wchar, int, float, double, bool или любой определенный пользователем объект и т. Д., А variable_list может состоять из одного или нескольких имен идентификаторов, разделенных запятыми. Некоторые действительные объявления показаны здесь —
int i, j, k; char c, ch; float f, salary; double d;
Линия int i, j, k; оба объявляют и определяют переменные i, j и k; который инструктирует компилятор создавать переменные с именами i, j и k типа int.
Переменные могут быть инициализированы (им присвоено начальное значение) в их объявлении. Инициализатор состоит из знака равенства, за которым следует постоянное выражение:
type variable_name = value;
Примеры
extern int d = 3, f = 5; // declaration of d and f. int d = 3, f = 5; // definition and initializing d and f. byte z = 22; // definition and initializes z. char x = 'x'; // the variable x has the value 'x'.
Когда переменная объявляется в D, для нее всегда устанавливается «инициализатор по умолчанию», к которому можно обращаться вручную как T.init, где T — тип (например, int.init ). Инициализатором по умолчанию для целочисленных типов является 0, для логических значений false и для чисел с плавающей точкой NaN.
Объявление переменной в D
Объявление переменной дает гарантию компилятору, что существует одна переменная с заданным типом и именем, так что компилятор приступает к дальнейшей компиляции, не требуя полной информации о переменной. Объявление переменной имеет смысл только во время компиляции, компилятору требуется фактическое объявление переменной во время компоновки программы.
пример
Попробуйте следующий пример, где переменные были объявлены в начале программы, но определены и инициализированы внутри основной функции —
import std.stdio; int a = 10, b = 10; int c; float f; int main () { writeln("Value of a is : ", a); /* variable re definition: */ int a, b; int c; float f; /* Initialization */ a = 30; b = 40; writeln("Value of a is : ", a); c = a + b; writeln("Value of c is : ", c); f = 70.0/3.0; writeln("Value of f is : ", f); return 0; }
Когда приведенный выше код компилируется и выполняется, он дает следующий результат —
Value of a is : 10 Value of a is : 30 Value of c is : 70 Value of f is : 23.3333
Lvalues и Rvalues в D
Есть два вида выражений в D —
-
lvalue — выражение, являющееся lvalue, может отображаться как слева или справа от присваивания.
-
rvalue — выражение, являющееся rvalue, может появляться справа, но не слева от присваивания.
lvalue — выражение, являющееся lvalue, может отображаться как слева или справа от присваивания.
rvalue — выражение, являющееся rvalue, может появляться справа, но не слева от присваивания.
Переменные являются lvalues и могут отображаться в левой части назначения. Числовые литералы являются r-значениями и поэтому не могут быть назначены и не могут отображаться слева. Следующее утверждение действительно:
int g = 20;
Но следующее не является допустимым утверждением и приведет к ошибке времени компиляции:
10 = 20;
D Программирование — Типы данных
В языке программирования D типы данных относятся к обширной системе, используемой для объявления переменных или функций различных типов. Тип переменной определяет, сколько места она занимает в хранилище и как интерпретируется сохраненный битовый массив.
Типы в D можно классифицировать следующим образом:
| Sr.No. | Типы и описание |
|---|---|
| 1 |
Основные типы Они являются арифметическими типами и состоят из трех типов: (а) целое число, (б) с плавающей точкой и (в) символ. |
| 2 |
Перечисляемые типы Это снова арифметические типы. Они используются для определения переменных, которым могут быть назначены только определенные дискретные целочисленные значения по всей программе. |
| 3 |
Тип пустоты Спецификатор типа void указывает, что значение недоступно. |
| 4 |
Производные типы Они включают (a) типы указателей, (b) типы массивов, (c) типы структур, (d) типы объединений и (e) типы функций. |
Основные типы
Они являются арифметическими типами и состоят из трех типов: (а) целое число, (б) с плавающей точкой и (в) символ.
Перечисляемые типы
Это снова арифметические типы. Они используются для определения переменных, которым могут быть назначены только определенные дискретные целочисленные значения по всей программе.
Тип пустоты
Спецификатор типа void указывает, что значение недоступно.
Производные типы
Они включают (a) типы указателей, (b) типы массивов, (c) типы структур, (d) типы объединений и (e) типы функций.
Типы массивов и типы структур совместно называются агрегатными типами. Тип функции указывает тип возвращаемого значения функции. Мы увидим основные типы в следующем разделе, тогда как другие типы будут рассмотрены в следующих главах.
Целочисленные типы
В следующей таблице приведены списки стандартных целочисленных типов с их размерами хранения и диапазонами значений.
| Тип | Размер хранилища | Диапазон значений |
|---|---|---|
| BOOL | 1 байт | ложь или правда |
| байт | 1 байт | От -128 до 127 |
| UBYTE | 1 байт | От 0 до 255 |
| ИНТ | 4 байта | От -2 147 483 648 до 2 147 483 647 |
| UINT | 4 байта | От 0 до 4 294 967 295 |
| короткая | 2 байта | От -32 768 до 32 767 |
| USHORT | 2 байта | От 0 до 65 535 |
| долго | 8 байт | От -9223372036854775808 до 9223372036854775807 |
| ULONG | 8 байт | От 0 до 18446744073709551615 |
Чтобы получить точный размер типа или переменной, вы можете использовать оператор sizeof . Тип выражения . (Sizeof) возвращает размер хранилища объекта или типа в байтах. Следующий пример получает размер типа int на любой машине —
import std.stdio; int main() { writeln("Length in bytes: ", ulong.sizeof); return 0; }
Когда вы компилируете и запускаете вышеуказанную программу, она дает следующий результат —
Length in bytes: 8
Типы с плавающей точкой
В следующей таблице упоминаются стандартные типы с плавающей точкой с размерами хранения, диапазонами значений и их назначением.
| Тип | Размер хранилища | Диапазон значений | Цель |
|---|---|---|---|
| поплавок | 4 байта | 1.17549e-38 до 3.40282e + 38 | 6 десятичных знаков |
| двойной | 8 байт | 2,22507e-308 до 1,77969e + 308 | 15 десятичных знаков |
| реальный | 10 байт | 3.3621e-4932 до 1.18973e + 4932 | либо самый большой тип с плавающей запятой, поддерживаемый аппаратным обеспечением, либо double; смотря что больше |
| ifloat | 4 байта | 1.17549e-38i до 3.40282e + 38i | мнимое значение типа float |
| idouble | 8 байт | От 2,22507e-308i до 1,77969e + 308i | мнимый тип значения double |
| я реальный | 10 байт | 3.3621e-4932 до 1.18973e + 4932 | мнимый тип значения реального |
| cfloat | 8 байт | 1.17549e-38 + 1.17549e-38i до 3.40282e + 38 + 3.40282e + 38i | тип комплексного числа из двух поплавков |
| cdouble | 16 байт | 2.22507e-308 + 2.22507e-308i до 1.79769e + 308 + 1.79769e + 308i | тип комплексного числа из двух двойных |
| Creal | 20 байт | 3.3621e-4932 + 3.3621e-4932i до 1.18973e + 4932 + 1.18973e + 4932i | тип комплексного числа из двух вещественных чисел |
В следующем примере печатается место для хранения, занятое типом с плавающей запятой, и его значениями диапазона.
import std.stdio; int main() { writeln("Length in bytes: ", float.sizeof); return 0; }
Когда вы компилируете и запускаете вышеупомянутую программу, она дает следующий результат в Linux:
Length in bytes: 4
Типы персонажей
В следующей таблице перечислены стандартные типы символов с размерами хранилища и его назначением.
| Тип | Размер хранилища | Цель |
|---|---|---|
| голец | 1 байт | Кодовый блок UTF-8 |
| WCHAR | 2 байта | Кодовый блок UTF-16 |
| dchar | 4 байта | Кодовая единица UTF-32 и кодовая точка Unicode |
В следующем примере печатается область памяти, занимаемая типом char.
import std.stdio; int main() { writeln("Length in bytes: ", char.sizeof); return 0; }
Когда вы компилируете и запускаете вышеуказанную программу, она дает следующий результат —
Length in bytes: 1
Тип пустоты
Тип void указывает, что значение недоступно. Он используется в двух видах ситуаций —
| Sr.No. | Типы и описание |
|---|---|
| 1 |
Функция возвращается как void В D есть различные функции, которые не возвращают значение, или вы можете сказать, что они возвращают void. Функция без возвращаемого значения имеет тип возврата как void. Например, void exit (int status); |
| 2 |
Аргументы функции как void В D есть различные функции, которые не принимают никаких параметров. Функция без параметра может быть принята как пустая. Например, int rand (void); |
Функция возвращается как void
В D есть различные функции, которые не возвращают значение, или вы можете сказать, что они возвращают void. Функция без возвращаемого значения имеет тип возврата как void. Например, void exit (int status);
Аргументы функции как void
В D есть различные функции, которые не принимают никаких параметров. Функция без параметра может быть принята как пустая. Например, int rand (void);
В настоящее время тип пустоты может быть вам не понят, поэтому давайте продолжим, и мы рассмотрим эти концепции в следующих главах.
D Программирование — Перечисления
Перечисление используется для определения именованных значений констант. Перечислимый тип объявляется с использованием ключевого слова enum .
Синтаксис перечисления
Простейшая форма определения перечисления следующая —
enum enum_name {
enumeration list
}
Куда,
-
Enum_name указывает имя типа перечисления.
-
Список перечисления представляет собой список идентификаторов через запятую.
Enum_name указывает имя типа перечисления.
Список перечисления представляет собой список идентификаторов через запятую.
Каждый из символов в списке перечисления обозначает целочисленное значение, на один больше, чем символ, который предшествует ему. По умолчанию значение первого символа перечисления равно 0. Например, —
enum Days { sun, mon, tue, wed, thu, fri, sat };
пример
В следующем примере демонстрируется использование переменной enum —
import std.stdio; enum Days { sun, mon, tue, wed, thu, fri, sat }; int main(string[] args) { Days day; day = Days.mon; writefln("Current Day: %d", day); writefln("Friday : %d", Days.fri); return 0; }
Когда приведенный выше код компилируется и выполняется, он дает следующий результат —
Current Day: 1 Friday : 5
В приведенной выше программе мы видим, как можно использовать перечисление. Изначально мы создаем переменную с именем day для нашего пользовательского перечисления Days. Затем мы устанавливаем его в mon, используя оператор точки. Нам нужно использовать метод writefln, чтобы напечатать значение mon, которое было сохранено. Вам также необходимо указать тип. Он имеет тип integer, поэтому мы используем% d для печати.
Именованные свойства Enums
Приведенный выше пример использует имя Days для перечисления и называется named enums. Эти именованные перечисления имеют следующие свойства —
-
Init — инициализирует первое значение в перечислении.
-
min — возвращает наименьшее значение перечисления.
-
max — возвращает наибольшее значение перечисления.
-
sizeof — возвращает размер хранилища для перечисления.
Init — инициализирует первое значение в перечислении.
min — возвращает наименьшее значение перечисления.
max — возвращает наибольшее значение перечисления.
sizeof — возвращает размер хранилища для перечисления.
Давайте изменим предыдущий пример, чтобы использовать свойства.
import std.stdio; // Initialized sun with value 1 enum Days { sun = 1, mon, tue, wed, thu, fri, sat }; int main(string[] args) { writefln("Min : %d", Days.min); writefln("Max : %d", Days.max); writefln("Size of: %d", Days.sizeof); return 0; }
Когда приведенный выше код компилируется и выполняется, он дает следующий результат —
Min : 1 Max : 7 Size of: 4
Аноним Enum
Перечисление без имени называется анонимным перечислением. Пример анонимного перечисления приведен ниже.
import std.stdio; // Initialized sun with value 1 enum { sun , mon, tue, wed, thu, fri, sat }; int main(string[] args) { writefln("Sunday : %d", sun); writefln("Monday : %d", mon); return 0; }
Когда приведенный выше код компилируется и выполняется, он дает следующий результат —
Sunday : 0 Monday : 1
Анонимные перечисления работают почти так же, как именованные перечисления, но у них нет свойств max, min и sizeof.
Перечисление с синтаксисом базового типа
Синтаксис перечисления с базовым типом показан ниже.
enum :baseType {
enumeration list
}
Некоторые из базовых типов включают long, int и string. Пример использования long показан ниже.
import std.stdio; enum : string { A = "hello", B = "world", } int main(string[] args) { writefln("A : %s", A); writefln("B : %s", B); return 0; }
Когда приведенный выше код компилируется и выполняется, он дает следующий результат —
A : hello B : world
Больше возможностей
Перечисление в D обеспечивает такие функции, как инициализация нескольких значений в перечислении с несколькими типами. Пример показан ниже.
import std.stdio; enum { A = 1.2f, // A is 1.2f of type float B, // B is 2.2f of type float int C = 3, // C is 3 of type int D // D is 4 of type int } int main(string[] args) { writefln("A : %f", A); writefln("B : %f", B); writefln("C : %d", C); writefln("D : %d", D); return 0; }
Когда приведенный выше код компилируется и выполняется, он дает следующий результат —
A : 1.200000 B : 2.200000 C : 3 D : 4
D Программирование — Литералы
Постоянные значения, которые вводятся в программу как часть исходного кода, называются литералами .
Литералы могут иметь любой из основных типов данных и могут быть разделены на целочисленные цифры, числа с плавающей точкой, символы, строки и логические значения.
Опять же, литералы обрабатываются как обычные переменные, за исключением того, что их значения не могут быть изменены после их определения.
Целочисленные литералы
Целочисленный литерал может быть следующих типов:
-
Десятичное число использует нормальное представление чисел с первой цифрой, которая не может быть 0, поскольку эта цифра зарезервирована для указания восьмеричной системы. Это не включает 0 само по себе: 0 — ноль.
-
Octal использует 0 в качестве префикса для нумерации.
-
Двоичный код использует 0b или 0B в качестве префикса.
-
Шестнадцатеричный использует 0x или 0X в качестве префикса.
Десятичное число использует нормальное представление чисел с первой цифрой, которая не может быть 0, поскольку эта цифра зарезервирована для указания восьмеричной системы. Это не включает 0 само по себе: 0 — ноль.
Octal использует 0 в качестве префикса для нумерации.
Двоичный код использует 0b или 0B в качестве префикса.
Шестнадцатеричный использует 0x или 0X в качестве префикса.
Целочисленный литерал также может иметь суффикс, который представляет собой комбинацию U и L для беззнакового и длинного соответственно. Суффикс может быть в верхнем или нижнем регистре и может быть в любом порядке.
Если вы не используете суффикс, компилятор сам выбирает между int, uint, long и ulong в зависимости от величины значения.
Вот несколько примеров целочисленных литералов —
212 // Legal 215u // Legal 0xFeeL // Legal 078 // Illegal: 8 is not an octal digit 032UU // Illegal: cannot repeat a suffix
Ниже приведены другие примеры различных типов целочисленных литералов —
85 // decimal 0213 // octal 0x4b // hexadecimal 30 // int 30u // unsigned int 30l // long 30ul // unsigned long 0b001 // binary
Литералы с плавающей точкой
Литералы с плавающей запятой могут быть указаны в десятичной системе как в 1.568 или в шестнадцатеричной системе как в 0x91.bc.
В десятичной системе показатель степени может быть представлен путем добавления символа e или E и числа после этого. Например, 2.3e4 означает «2,3 умножить на 10 в степени 4». Символ «+» может быть указан перед значением показателя степени, но это не имеет никакого эффекта. Например, 2.3e4 и 2.3e + 4 одинаковы.
Символ «-», добавляемый до значения показателя степени, меняет значение на «делится на 10 в степени». Например, 2.3e-2 означает «2.3, деленное на 10 в степени 2».
В шестнадцатеричной системе значение начинается с 0x или 0X. Показатель степени определяется как p или P вместо e или E. Показатель степени означает не «10 в степень», а «2 в степень». Например, P4 в 0xabc.defP4 означает «abc.de умножить на 2 до степени 4».
Вот несколько примеров литералов с плавающей точкой —
3.14159 // Legal 314159E-5L // Legal 510E // Illegal: incomplete exponent 210f // Illegal: no decimal or exponent .e55 // Illegal: missing integer or fraction 0xabc.defP4 // Legal Hexa decimal with exponent 0xabc.defe4 // Legal Hexa decimal without exponent.
По умолчанию тип литерала с плавающей запятой — двойной. F и F означают float, а спецификатор L означает вещественное.
Логические литералы
Есть два логических литерала, и они являются частью стандартных ключевых слов D —
-
Значение true, представляющее истину.
-
Значение false, представляющее ложь.
Значение true, представляющее истину.
Значение false, представляющее ложь.
Не следует считать значение true равным 1, а значение false равным 0.
Символьные литералы
Символьные литералы заключены в одинарные кавычки.
Символьный литерал может быть простым символом (например, «x»), escape-последовательностью (например, «\ t»), символом ASCII (например, «\ x21»), символом Unicode (например, «\ u011e») или как именованный символ (например, ‘\ ©’, ‘\ ♥’, ‘\ €’).
Существуют определенные символы в D, когда им предшествует обратная косая черта, они будут иметь особое значение, и они используются для представления, например, новой строки (\ n) или табуляции (\ t). Здесь у вас есть список некоторых из таких кодов escape-последовательностей —
| Последовательность побега | Имея в виду |
|---|---|
| \\ | \ персонаж |
| \» | ‘ персонаж |
| \» | » персонаж |
| \? | ? персонаж |
| \ а | Оповещение или звонок |
| \ б | возврат на одну позицию |
| \ е | Форма подачи |
| \ п | Новая линия |
| \р | Возврат каретки |
| \ т | Горизонтальная вкладка |
| \ v | Вертикальная вкладка |
В следующем примере показано несколько символов escape-последовательности —
import std.stdio; int main(string[] args) { writefln("Hello\tWorld%c\n",'\x21'); writefln("Have a good day%c",'\x21'); return 0; }
Когда приведенный выше код компилируется и выполняется, он дает следующий результат —
Hello World! Have a good day!
Строковые литералы
Строковые литералы заключены в двойные кавычки. Строка содержит символы, похожие на символьные литералы: простые символы, escape-последовательности и универсальные символы.
Вы можете разбить длинную строку на несколько строк, используя строковые литералы, и разделить их, используя пробелы.
Вот несколько примеров строковых литералов —
import std.stdio; int main(string[] args) { writeln(q"MY_DELIMITER Hello World Have a good day MY_DELIMITER"); writefln("Have a good day%c",'\x21'); auto str = q{int value = 20; ++value;}; writeln(str); }
В приведенном выше примере вы можете найти использование q «MY_DELIMITER MY_DELIMITER» для представления многострочных символов. Также вы можете увидеть q {} для представления самого оператора языка D.
D Программирование — Операторы
Оператор — это символ, который указывает компилятору выполнять определенные математические или логические манипуляции. Язык D богат встроенными операторами и предоставляет следующие типы операторов:
- Арифметические Операторы
- Операторы отношений
- Логические Операторы
- Битовые операторы
- Операторы присваивания
- Разные Операторы
В этой главе один за другим рассматриваются арифметические, реляционные, логические, побитовые, присваивания и другие операторы.
Арифметические Операторы
В следующей таблице показаны все арифметические операторы, поддерживаемые языком D. Предположим, что переменная A содержит 10, а переменная B содержит 20, тогда —
| оператор | Описание | пример |
|---|---|---|
| + | Это добавляет два операнда. | А + Б дает 30 |
| — | Вычитает второй операнд из первого. | A — B дает -10 |
| * | Умножает оба операнда. | A * B дает 200 |
| / | Он делит числитель на денумератор. | Б / А дает 2 |
| % | Возвращает остаток от целочисленного деления. | B% A дает 0 |
| ++ | Оператор приращения увеличивает целочисленное значение на единицу. | А ++ дает 11 |
| — | Оператор декрементов уменьшает целочисленное значение на единицу. | A— дает 9 |
Операторы отношений
В следующей таблице показаны все реляционные операторы, поддерживаемые языком D. Предположим, что переменная A содержит 10, а переменная B содержит 20, тогда —
| оператор | Описание | пример |
|---|---|---|
| == | Проверяет, равны ли значения двух операндов или нет, если да, тогда условие становится истинным. | (A == B) не соответствует действительности. |
| знак равно | Проверяет, равны ли значения двух операндов или нет, если значения не равны, тогда условие становится истинным. | (A! = B) верно. |
| > | Проверяет, больше ли значение левого операнда, чем значение правого операнда, если да, тогда условие становится истинным. | (A> B) не соответствует действительности. |
| < | Проверяет, меньше ли значение левого операнда, чем значение правого операнда, если да, тогда условие становится истинным. | (A <B) верно. |
| > = | Проверяет, больше ли значение левого операнда или равно значению правого операнда, если да, тогда условие становится истинным. | (A> = B) не соответствует действительности. |
| <= | Проверяет, меньше ли значение левого операнда или равно значению правого операнда, если да, тогда условие становится истинным. | (A <= B) верно. |
Логические Операторы
В следующей таблице показаны все логические операторы, поддерживаемые языком D. Предположим, что переменная A содержит 1, а переменная B содержит 0, тогда —
| оператор | Описание | пример |
|---|---|---|
| && | Это называется логическим оператором И. Если оба операнда отличны от нуля, условие становится истинным. | (A && B) неверно. |
| || | Это называется логическим оператором ИЛИ. Если любой из двух операндов отличен от нуля, условие становится истинным. | (A || B) верно. |
| ! | Это называется логическим оператором НЕ. Используйте для изменения логического состояния своего операнда. Если условие истинно, то оператор Логический НЕ будет делать ложь. | ! (A && B) верно. |
Битовые операторы
Битовые операторы работают с битами и выполняют побитовые операции. Таблицы истинности для &, | и ^ следующие:
| п | Q | P & Q | р | Q | р ^ д |
|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 |
| 0 | 1 | 0 | 1 | 1 |
| 1 | 1 | 1 | 1 | 0 |
| 1 | 0 | 0 | 1 | 1 |
Предположим, если А = 60; и B = 13. В двоичном формате они будут выглядеть следующим образом —
A = 0011 1100
B = 0000 1101
——————
A & B = 0000 1100
A | B = 0011 1101
A ^ B = 0011 0001
~ A = 1100 0011
Побитовые операторы, поддерживаемые языком D, перечислены в следующей таблице. Предположим, что переменная A содержит 60, а переменная B содержит 13, тогда —
| оператор | Описание | пример |
|---|---|---|
| & | Двоичный оператор AND немного копирует результат, если он существует в обоих операндах. | (A & B) даст 12, значит 0000 1100. |
| | | Оператор двоичного ИЛИ копирует немного, если он существует в любом из операндов. | (A | B) дает 61. Значит, 0011 1101. |
| ^ | Двоичный оператор XOR копирует бит, если он установлен в одном операнде, но не в обоих. | (A ^ B) дает 49. Значит 0011 0001 |
| ~ | Оператор дополнения двоичных единиц является унарным и имеет эффект «переворачивания» битов. | (~ A) дает -61. Означает 1100 0011 в 2-х дополнениях. |
| << | Двоичный оператор левого сдвига. Значение левого операнда перемещается влево на количество битов, указанное правым операндом. | А << 2 дают 240. Значит 1111 0000 |
| >> | Оператор двоичного правого сдвига. Значение левого операнда перемещается вправо на количество битов, указанное правым операндом. | A >> 2 дают 15. Значит 0000 1111. |
Операторы присваивания
Следующие операторы присваивания поддерживаются языком D —
| оператор | Описание | пример |
|---|---|---|
| знак равно | Это простой оператор присваивания. Он присваивает значения из правого операнда левому операнду | C = A + B присваивает значение A + B в C |
| + = | Это оператор добавления и присваивания. Добавляет правый операнд к левому операнду и присваивает результат левому операнду | C + = A эквивалентно C = C + A |
| знак равно | Это оператор вычитания И присваивания. Вычитает правый операнд из левого операнда и присваивает результат левому операнду. | C — = A эквивалентно C = C — A |
| знак равно | Это оператор умножения И присваивания. Он умножает правый операнд на левый операнд и присваивает результат левому операнду. | C * = A эквивалентно C = C * A |
| знак равно | Это оператор разделения И присваивания. Он делит левый операнд на правый операнд и присваивает результат левому операнду. | C / = A эквивалентно C = C / A |
| знак равно | Это модуль И оператор присваивания. Он принимает модуль с использованием двух операндов и присваивает результат левому операнду. | C% = A эквивалентно C = C% A |
| << = | Это левый сдвиг и оператор присваивания. | C << = 2 совпадает с C = C << 2 |
| >> = | Это правый сдвиг И оператор присваивания. | C >> = 2 — это то же самое, что C = C >> 2 |
| знак равно | Это побитовое И оператор присваивания. | C & = 2 совпадает с C = C & 2 |
| ^ = | Это битовое исключающее ИЛИ и оператор присваивания. | C ^ = 2 совпадает с C = C ^ 2 |
| | = | Это побитовое ИЛИ и оператор присваивания | C | = 2 — это то же самое, что C = C | 2 |
Смешанные операторы — Sizeof и Ternary
Есть несколько других важных операторов, включая sizeof и ? : поддерживается D Language.
| оператор | Описание | пример |
|---|---|---|
| размер() | Возвращает размер переменной. | sizeof (a), где a является целым числом, возвращает 4. |
| & | Возвращает адрес переменной. | & А; дает фактический адрес переменной. |
| * | Указатель на переменную. | * А; дает указатель на переменную. |
| ? : | Условное выражение | Если условие истинно, то значение X: в противном случае значение Y. |
Приоритет операторов в D
Приоритет оператора определяет группировку терминов в выражении. Это влияет на то, как оценивается выражение. Некоторые операторы имеют приоритет над другими.
Например, оператор умножения имеет более высокий приоритет, чем оператор сложения.
Давайте рассмотрим выражение
х = 7 + 3 * 2.
Здесь х назначено 13, а не 20. Простая причина в том, что оператор * имеет более высокий приоритет, чем +, поэтому сначала вычисляется 3 * 2, а затем результат добавляется в 7.
Здесь операторы с самым высоким приоритетом отображаются вверху таблицы, а операторы с самым низким — внизу. Внутри выражения операторы с более высоким приоритетом вычисляются первыми.
| категория | оператор | Ассоциативность |
|---|---|---|
| постфикс | () [] ->. ++ — — | Слева направо |
| Одинарный | + -! ~ ++ — — (тип) * & sizeof | Справа налево |
| Multiplicative | * /% | Слева направо |
| присадка | + — | Слева направо |
| сдвиг | << >> | Слева направо |
| реляционный | <<=>> = | Слева направо |
| равенство | ==! = | Слева направо |
| Побитовое И | & | Слева направо |
| Побитовый XOR | ^ | Слева направо |
| Побитовое ИЛИ | | | Слева направо |
| Логическое И | && | Слева направо |
| Логическое ИЛИ | || | Слева направо |
| условный | ?: | Справа налево |
| присваивание | = + = — = * = / =% = >> = << = & = ^ = | = | Справа налево |
| запятая | , | Слева направо |
D Программирование — Циклы
Может возникнуть ситуация, когда вам нужно выполнить блок кода несколько раз. В общем случае операторы выполняются последовательно: первый оператор в функции выполняется первым, затем второй и так далее.
Языки программирования предоставляют различные структуры управления, которые позволяют более сложные пути выполнения.
Оператор цикла выполняет оператор или группу операторов несколько раз. Следующая общая форма оператора цикла в основном используется в языках программирования —
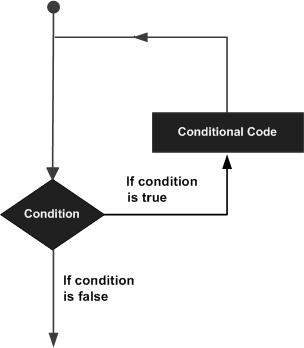
Язык программирования D предоставляет следующие типы циклов для обработки требований циклов. Нажмите на следующие ссылки, чтобы проверить их детали.
| Sr.No. | Тип и описание петли |
|---|---|
| 1 | в то время как цикл
Он повторяет оператор или группу операторов, пока данное условие выполняется. Он проверяет условие перед выполнением тела цикла. |
| 2 | для цикла
Он выполняет последовательность операторов несколько раз и сокращает код, который управляет переменной цикла. |
| 3 | делать … пока цикл
Как оператор while, за исключением того, что он проверяет условие в конце тела цикла. |
| 4 | вложенные циклы
Вы можете использовать один или несколько циклов внутри любого другого цикла while, for или do.. while. |
Он повторяет оператор или группу операторов, пока данное условие выполняется. Он проверяет условие перед выполнением тела цикла.
Он выполняет последовательность операторов несколько раз и сокращает код, который управляет переменной цикла.
Как оператор while, за исключением того, что он проверяет условие в конце тела цикла.
Вы можете использовать один или несколько циклов внутри любого другого цикла while, for или do.. while.
Заявления о контроле цикла
Операторы управления циклом изменяют выполнение от его нормальной последовательности. Когда выполнение покидает область действия, все автоматические объекты, созданные в этой области, уничтожаются.
D поддерживает следующие операторы управления —
| Sr.No. | Контрольное заявление и описание |
|---|---|
| 1 | заявление о нарушении
Завершает оператор цикла или переключателя и передает выполнение в оператор, следующий сразу за циклом или переключателем. |
| 2 | продолжить заявление
Заставляет петлю пропускать оставшуюся часть своего тела и немедленно проверять свое состояние перед повторением. |
Завершает оператор цикла или переключателя и передает выполнение в оператор, следующий сразу за циклом или переключателем.
Заставляет петлю пропускать оставшуюся часть своего тела и немедленно проверять свое состояние перед повторением.
Бесконечный цикл
Цикл становится бесконечным, если условие никогда не становится ложным. Цикл for традиционно используется для этой цели. Поскольку ни одно из трех выражений, образующих цикл for, не требуется, вы можете создать бесконечный цикл, оставив условное выражение пустым.
import std.stdio; int main () { for( ; ; ) { writefln("This loop will run forever."); } return 0; }
Когда условное выражение отсутствует, оно считается истинным. У вас может быть выражение инициализации и приращения, но программисты D чаще используют конструкцию for (;;) для обозначения бесконечного цикла.
ПРИМЕЧАНИЕ. — Вы можете завершить бесконечный цикл, нажав клавиши Ctrl + C.
D Программирование — Решения
Структуры принятия решений содержат условие для оценки вместе с двумя наборами операторов, которые должны быть выполнены. Один набор операторов выполняется, если условие истинно, и другой набор операторов выполняется, если условие ложно.
Ниже приводится общая форма типичной структуры принятия решений, встречающейся в большинстве языков программирования.
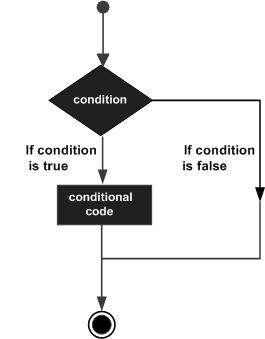
Язык программирования D принимает любые ненулевые и ненулевые значения как истинные , и если это или ноль или нуль , то это предполагается как ложное значение.
Язык программирования D предоставляет следующие типы решений для принятия решений.
| Sr.No. | Заявление и описание |
|---|---|
| 1 | если заявление
Оператор if состоит из логического выражения, за которым следует одно или несколько операторов. |
| 2 | если … еще заявление
За оператором if может следовать необязательный оператор else , который выполняется, когда логическое выражение имеет значение false. |
| 3 | вложенные операторы if
Вы можете использовать один оператор if или else if внутри другого оператора if или else if . |
| 4 | заявление о переключении
Оператор switch позволяет проверять переменную на соответствие списку значений. |
| 5 | вложенные операторы switch
Вы можете использовать один оператор switch внутри другого оператора (ов) switch . |
Оператор if состоит из логического выражения, за которым следует одно или несколько операторов.
За оператором if может следовать необязательный оператор else , который выполняется, когда логическое выражение имеет значение false.
Вы можете использовать один оператор if или else if внутри другого оператора if или else if .
Оператор switch позволяет проверять переменную на соответствие списку значений.
Вы можете использовать один оператор switch внутри другого оператора (ов) switch .
? : Оператор в D
Мы накрыли условного оператора? : в предыдущей главе, которая может быть использована для замены операторов if … else . Имеет следующую общую форму
Exp1 ? Exp2 : Exp3;
Где Exp1, Exp2 и Exp3 являются выражениями. Обратите внимание на использование и размещение толстой кишки.
Значение? Выражение определяется следующим образом:
-
Exp1 оценивается. Если это правда, то Exp2 оценивается и становится значением целого? выражение.
-
Если Exp1 имеет значение false, то Exp3 оценивается, и его значение становится значением выражения.
Exp1 оценивается. Если это правда, то Exp2 оценивается и становится значением целого? выражение.
Если Exp1 имеет значение false, то Exp3 оценивается, и его значение становится значением выражения.
D Программирование — Функции
В этой главе описываются функции, используемые в D-программировании.
Определение функции в D
Базовое определение функции состоит из заголовка функции и тела функции.
Синтаксис
return_type function_name( parameter list ) {
body of the function
}
Вот все части функции —
-
Тип возврата — функция может возвращать значение. Return_type — это тип данных значения, которое возвращает функция. Некоторые функции выполняют нужные операции без возврата значения. В этом случае return_type является ключевым словом void .
-
Имя функции — это фактическое имя функции. Имя функции и список параметров вместе составляют сигнатуру функции.
-
Параметры — параметр похож на заполнитель. Когда вызывается функция, вы передаете значение параметру. Это значение называется фактическим параметром или аргументом. Список параметров относится к типу, порядку и количеству параметров функции. Параметры являются необязательными; то есть функция может не содержать параметров.
-
Тело функции — Тело функции содержит набор операторов, которые определяют, что делает функция.
Тип возврата — функция может возвращать значение. Return_type — это тип данных значения, которое возвращает функция. Некоторые функции выполняют нужные операции без возврата значения. В этом случае return_type является ключевым словом void .
Имя функции — это фактическое имя функции. Имя функции и список параметров вместе составляют сигнатуру функции.
Параметры — параметр похож на заполнитель. Когда вызывается функция, вы передаете значение параметру. Это значение называется фактическим параметром или аргументом. Список параметров относится к типу, порядку и количеству параметров функции. Параметры являются необязательными; то есть функция может не содержать параметров.
Тело функции — Тело функции содержит набор операторов, которые определяют, что делает функция.
Вызов функции
Вы можете вызвать функцию следующим образом —
function_name(parameter_values)
Типы функций в D
D программирования поддерживает широкий спектр функций, и они перечислены ниже.
- Чистые функции
- Nothrow Функции
- Ссылочные функции
- Авто Функции
- Вариадические функции
- Функции Inout
- Функции недвижимости
Различные функции описаны ниже.
Чистые функции
Чистые функции — это функции, которые не могут получить доступ к глобальному или статическому изменяемому состоянию, сохраняя их аргументы. Это может позволить оптимизацию, основанную на том факте, что чистая функция гарантированно не изменяет ничего, что не передается ей, и в случаях, когда компилятор может гарантировать, что чистая функция не может изменить свои аргументы, он может включить полную функциональную чистоту, что является гарантией того, что функция всегда будет возвращать один и тот же результат для одних и тех же аргументов).
import std.stdio; int x = 10; immutable int y = 30; const int* p; pure int purefunc(int i,const char* q,immutable int* s) { //writeln("Simple print"); //cannot call impure function 'writeln' debug writeln("in foo()"); // ok, impure code allowed in debug statement // x = i; // error, modifying global state // i = x; // error, reading mutable global state // i = *p; // error, reading const global state i = y; // ok, reading immutable global state auto myvar = new int; // Can use the new expression: return i; } void main() { writeln("Value returned from pure function : ",purefunc(x,null,null)); }
Когда приведенный выше код компилируется и выполняется, он дает следующий результат —
Value returned from pure function : 30
Nothrow Функции
Другие функции не выдают никаких исключений, полученных из класса Exception. Другие функции ковариантны с метательными.
Nothrow гарантирует, что функция не создает никаких исключений.
import std.stdio; int add(int a, int b) nothrow { //writeln("adding"); This will fail because writeln may throw int result; try { writeln("adding"); // compiles result = a + b; } catch (Exception error) { // catches all exceptions } return result; } void main() { writeln("Added value is ", add(10,20)); }
Когда приведенный выше код компилируется и выполняется, он дает следующий результат —
adding Added value is 30
Ссылочные функции
Функции Ref позволяют функциям возвращаться по ссылке. Это аналогично параметрам функции ref.
import std.stdio; ref int greater(ref int first, ref int second) { return (first > second) ? first : second; } void main() { int a = 1; int b = 2; greater(a, b) += 10; writefln("a: %s, b: %s", a, b); }
Когда приведенный выше код компилируется и выполняется, он дает следующий результат —
a: 1, b: 12
Авто Функции
Авто функции могут возвращать значения любого типа. Нет ограничений по типу, который будет возвращен. Простой пример функции автоматического типа приведен ниже.
import std.stdio; auto add(int first, double second) { double result = first + second; return result; } void main() { int a = 1; double b = 2.5; writeln("add(a,b) = ", add(a, b)); }
Когда приведенный выше код компилируется и выполняется, он дает следующий результат —
add(a,b) = 3.5
Вариадические функции
Функции Variadiac — это те функции, в которых количество параметров для функции определяется во время выполнения. В C есть ограничение наличия хотя бы одного параметра. Но в D-программировании такого ограничения нет. Простой пример показан ниже.
import std.stdio; import core.vararg; void printargs(int x, ...) { for (int i = 0; i < _arguments.length; i++) { write(_arguments[i]); if (_arguments[i] == typeid(int)) { int j = va_arg!(int)(_argptr); writefln("\t%d", j); } else if (_arguments[i] == typeid(long)) { long j = va_arg!(long)(_argptr); writefln("\t%d", j); } else if (_arguments[i] == typeid(double)) { double d = va_arg!(double)(_argptr); writefln("\t%g", d); } } } void main() { printargs(1, 2, 3L, 4.5); }
Когда приведенный выше код компилируется и выполняется, он дает следующий результат —
int 2 long 3 double 4.5
Функции Inout
Inout может использоваться как для параметров, так и для возвращаемых типов функций. Это как шаблон для непостоянных, постоянных и неизменных. Атрибут mutable выводится из параметра. Значит, inout переводит выведенный атрибут изменчивости в тип возвращаемого значения. Простой пример, показывающий, как меняется изменчивость, показан ниже.
import std.stdio; inout(char)[] qoutedWord(inout(char)[] phrase) { return '"' ~ phrase ~ '"'; } void main() { char[] a = "test a".dup; a = qoutedWord(a); writeln(typeof(qoutedWord(a)).stringof," ", a); const(char)[] b = "test b"; b = qoutedWord(b); writeln(typeof(qoutedWord(b)).stringof," ", b); immutable(char)[] c = "test c"; c = qoutedWord(c); writeln(typeof(qoutedWord(c)).stringof," ", c); }
Когда приведенный выше код компилируется и выполняется, он дает следующий результат —
char[] "test a" const(char)[] "test b" string "test c"
Функции недвижимости
Свойства позволяют использовать функции-члены, такие как переменные-члены. Он использует ключевое слово @property. Свойства связаны со связанной функцией, которая возвращает значения в соответствии с требованием. Простой пример для свойства показан ниже.
import std.stdio; struct Rectangle { double width; double height; double area() const @property { return width*height; } void area(double newArea) @property { auto multiplier = newArea / area; width *= multiplier; writeln("Value set!"); } } void main() { auto rectangle = Rectangle(20,10); writeln("The area is ", rectangle.area); rectangle.area(300); writeln("Modified width is ", rectangle.width); }
Когда приведенный выше код компилируется и выполняется, он дает следующий результат —
The area is 200 Value set! Modified width is 30
D Программирование — Персонажи
Символы являются строительными блоками строк. Любой символ системы письма называется символом: буквы алфавита, цифры, знаки пунктуации, символ пробела и т. Д. Смущает то, что строительные блоки самих символов также называются символами.
Целочисленное значение строчной буквы a равно 97, а целочисленное значение цифры 1 равно 49. Эти значения были назначены просто соглашениями, когда была разработана таблица ASCII.
В следующей таблице упоминаются стандартные типы символов с указанием их размеров и назначения.
Символы представлены типом char, который может содержать только 256 различных значений. Если вы знакомы с типом char из других языков, вы, возможно, уже знаете, что он недостаточно велик для поддержки символов многих систем письма.
| Тип | Размер хранилища | Цель |
|---|---|---|
| голец | 1 байт | Кодовый блок UTF-8 |
| WCHAR | 2 байта | Кодовый блок UTF-16 |
| dchar | 4 байта | Кодовая единица UTF-32 и кодовая точка Unicode |
Некоторые полезные символьные функции перечислены ниже —
-
isLower — определяет, является ли символ нижнего регистра?
-
isUpper — Определяет, является ли символ в верхнем регистре?
-
isAlpha — Определяет, является ли буквенно-цифровой символ Unicode (как правило, буква или цифра)?
-
isWhite — определяет, является ли символ пробела?
-
toLower — производит нижний регистр данного символа.
-
toUpper — производит верхний регистр данного символа.
isLower — определяет, является ли символ нижнего регистра?
isUpper — Определяет, является ли символ в верхнем регистре?
isAlpha — Определяет, является ли буквенно-цифровой символ Unicode (как правило, буква или цифра)?
isWhite — определяет, является ли символ пробела?
toLower — производит нижний регистр данного символа.
toUpper — производит верхний регистр данного символа.
import std.stdio; import std.uni; void main() { writeln("Is ğ lowercase? ", isLower('ğ')); writeln("Is Ş lowercase? ", isLower('Ş')); writeln("Is İ uppercase? ", isUpper('İ')); writeln("Is ç uppercase? ", isUpper('ç')); writeln("Is z alphanumeric? ", isAlpha('z')); writeln("Is new-line whitespace? ", isWhite('\n')); writeln("Is underline whitespace? ", isWhite('_')); writeln("The lowercase of Ğ: ", toLower('Ğ')); writeln("The lowercase of İ: ", toLower('İ')); writeln("The uppercase of ş: ", toUpper('ş')); writeln("The uppercase of ı: ", toUpper('ı')); }
Когда приведенный выше код компилируется и выполняется, он дает следующий результат —
Is ğ lowercase? true Is Ş lowercase? false Is İ uppercase? true Is ç uppercase? false Is z alphanumeric? true Is new-line whitespace? true Is underline whitespace? false The lowercase of Ğ: ğ The lowercase of İ: i The uppercase of ş: Ş The uppercase of ı: I
Чтение символов в D
Мы можем читать символы, используя readf, как показано ниже.
readf(" %s", &letter);
Поскольку D-программирование поддерживает Unicode, для чтения символов Unicode нам нужно читать дважды и писать дважды, чтобы получить ожидаемый результат. Это не работает на онлайн-компиляторе. Пример показан ниже.
import std.stdio; void main() { char firstCode; char secondCode; write("Please enter a letter: "); readf(" %s", &firstCode); readf(" %s", &secondCode); writeln("The letter that has been read: ", firstCode, secondCode); }
Когда приведенный выше код компилируется и выполняется, он дает следующий результат —
Please enter a letter: ğ The letter that has been read: ğ
D Программирование — Строки
D обеспечивает следующие два типа строковых представлений —
- Массив символов
- Основная языковая строка
Массив символов
Мы можем представить массив символов в одной из двух форм, как показано ниже. Первая форма предоставляет размер напрямую, а вторая использует метод dup, который создает доступную для записи копию строки «Доброе утро».
char[9] greeting1 = "Hello all"; char[] greeting2 = "Good morning".dup;
пример
Вот простой пример, использующий вышеупомянутые простые формы массива символов.
import std.stdio; void main(string[] args) { char[9] greeting1 = "Hello all"; writefln("%s",greeting1); char[] greeting2 = "Good morning".dup; writefln("%s",greeting2); }
Когда приведенный выше код компилируется и выполняется, он выдает результат, который выглядит следующим образом:
Hello all Good morning
Базовая языковая строка
Строки встроены в основной язык D. Эти строки совместимы с массивом символов, показанным выше. В следующем примере показано простое строковое представление.
string greeting1 = "Hello all";
пример
import std.stdio; void main(string[] args) { string greeting1 = "Hello all"; writefln("%s",greeting1); char[] greeting2 = "Good morning".dup; writefln("%s",greeting2); string greeting3 = greeting1; writefln("%s",greeting3); }
Когда приведенный выше код компилируется и выполняется, он выдает результат, который выглядит следующим образом:
Hello all Good morning Hello all
Конкатенация строк
Конкатенация строк в D-программировании использует символ тильды (~).
пример
import std.stdio; void main(string[] args) { string greeting1 = "Good"; char[] greeting2 = "morning".dup; char[] greeting3 = greeting1~" "~greeting2; writefln("%s",greeting3); string greeting4 = "morning"; string greeting5 = greeting1~" "~greeting4; writefln("%s",greeting5); }
Когда приведенный выше код компилируется и выполняется, он выдает результат, который выглядит следующим образом:
Good morning Good morning
Длина строки
Длина строки в байтах может быть получена с помощью функции длины.
пример
import std.stdio; void main(string[] args) { string greeting1 = "Good"; writefln("Length of string greeting1 is %d",greeting1.length); char[] greeting2 = "morning".dup; writefln("Length of string greeting2 is %d",greeting2.length); }
Когда приведенный выше код компилируется и выполняется, он дает следующий результат —
Length of string greeting1 is 4 Length of string greeting2 is 7
Сравнение строк
Сравнение строк довольно просто в D-программировании. Вы можете использовать операторы ==, <и> для сравнения строк.
пример
import std.stdio; void main() { string s1 = "Hello"; string s2 = "World"; string s3 = "World"; if (s2 == s3) { writeln("s2: ",s2," and S3: ",s3, " are the same!"); } if (s1 < s2) { writeln("'", s1, "' comes before '", s2, "'."); } else { writeln("'", s2, "' comes before '", s1, "'."); } }
Когда приведенный выше код компилируется и выполняется, он выдает результат, который выглядит следующим образом:
s2: World and S3: World are the same! 'Hello' comes before 'World'.
Замена строк
Мы можем заменить строки, используя строку [].
пример
import std.stdio; import std.string; void main() { char[] s1 = "hello world ".dup; char[] s2 = "sample".dup; s1[6..12] = s2[0..6]; writeln(s1); }
Когда приведенный выше код компилируется и выполняется, он выдает результат, который выглядит следующим образом:
hello sample
Методы индекса
Методы индекса для определения местоположения подстроки в строке, включая indexOf и lastIndexOf, объясняются в следующем примере.
пример
import std.stdio; import std.string; void main() { char[] s1 = "hello World ".dup; writeln("indexOf of llo in hello is ",std.string.indexOf(s1,"llo")); writeln(s1); writeln("lastIndexOf of O in hello is " ,std.string.lastIndexOf(s1,"O",CaseSensitive.no)); }
Когда приведенный выше код компилируется и выполняется, он дает следующий результат —
indexOf.of llo in hello is 2 hello World lastIndexOf of O in hello is 7
Обработка дел
Методы, используемые для изменения случаев, показаны в следующем примере.
пример
import std.stdio; import std.string; void main() { char[] s1 = "hello World ".dup; writeln("Capitalized string of s1 is ",capitalize(s1)); writeln("Uppercase string of s1 is ",toUpper(s1)); writeln("Lowercase string of s1 is ",toLower(s1)); }
Когда приведенный выше код компилируется и выполняется, он дает следующий результат —
Capitalized string of s1 is Hello world Uppercase string of s1 is HELLO WORLD Lowercase string of s1 is hello world
Ограничение персонажей
Символы ограничения в строках показаны в следующем примере.
пример
import std.stdio; import std.string; void main() { string s = "H123Hello1"; string result = munch(s, "0123456789H"); writeln("Restrict trailing characters:",result); result = squeeze(s, "0123456789H"); writeln("Restrict leading characters:",result); s = " Hello World "; writeln("Stripping leading and trailing whitespace:",strip(s)); }
Когда приведенный выше код компилируется и выполняется, он дает следующий результат —
Restrict trailing characters:H123H Restrict leading characters:ello1 Stripping leading and trailing whitespace:Hello World
D Программирование — Массивы
Язык программирования D предоставляет структуру данных, названную массивами , в которой хранится последовательная коллекция фиксированного размера элементов одного типа. Массив используется для хранения коллекции данных. Часто более полезно думать о массиве как о коллекции переменных одного типа.
Вместо того, чтобы объявлять отдельные переменные, такие как number0, number1, … и number99, вы объявляете одну переменную массива, такую как числа, и используете числа [0], числа [1] и …, числа [99] для представления отдельные переменные. Определенный элемент в массиве доступен по индексу.
Все массивы состоят из смежных областей памяти. Самый низкий адрес соответствует первому элементу, а самый высокий адрес — последнему.
Объявление массивов
Чтобы объявить массив на языке программирования D, программист задает тип элементов и количество элементов, требуемых для массива, следующим образом:
type arrayName [ arraySize ];
Это называется одномерным массивом. ArraySize должен быть целочисленной константой, большей нуля, а тип может быть любым допустимым типом данных языка программирования D. Например, чтобы объявить массив из 10 элементов с именем balance типа double, используйте этот оператор —
double balance[10];
Инициализация массивов
Вы можете инициализировать элементы массива языка программирования D по одному или использовать один оператор следующим образом
double balance[5] = [1000.0, 2.0, 3.4, 17.0, 50.0];
Количество значений в квадратных скобках [] справа не может быть больше, чем количество элементов, которые вы объявляете для массива в квадратных скобках []. В следующем примере назначается один элемент массива —
Если вы опустите размер массива, будет создан массив, достаточно большой, чтобы вместить инициализацию. Поэтому, если вы напишите
double balance[] = [1000.0, 2.0, 3.4, 17.0, 50.0];
тогда вы создадите точно такой же массив, как и в предыдущем примере.
balance[4] = 50.0;
Приведенный выше оператор присваивает элементу номер 5 в массиве значение 50,0. Массив с 4-м индексом будет 5-м, т. Е. Последним элементом, поскольку все массивы имеют 0 в качестве индекса их первого элемента, который также называется базовым индексом. Следующее графическое изображение показывает тот же массив, который мы обсуждали выше —

Доступ к элементам массива
Доступ к элементу осуществляется путем индексации имени массива. Это делается путем помещения индекса элемента в квадратные скобки после имени массива. Например —
double salary = balance[9];
Вышеприведенный оператор берет 10- й элемент из массива и присваивает значение переменной salary . В следующем примере реализуются объявления, присваивание и доступ к массивам:
import std.stdio; void main() { int n[ 10 ]; // n is an array of 10 integers // initialize elements of array n to 0 for ( int i = 0; i < 10; i++ ) { n[ i ] = i + 100; // set element at location i to i + 100 } writeln("Element \t Value"); // output each array element's value for ( int j = 0; j < 10; j++ ) { writeln(j," \t ",n[j]); } }
Когда приведенный выше код компилируется и выполняется, он дает следующий результат —
Element Value 0 100 1 101 2 102 3 103 4 104 5 105 6 106 7 107 8 108 9 109
Статические массивы и динамические массивы
Если длина массива указана при написании программы, этот массив является статическим массивом. Когда длина может измениться во время выполнения программы, этот массив является динамическим массивом.
Определение динамических массивов проще, чем определение массивов фиксированной длины, потому что пропуск длины делает динамический массив —
int[] dynamicArray;
Свойства массива
Вот свойства массивов —
| Sr.No. | Описание недвижимости |
|---|---|
| 1 |
.в этом Статический массив возвращает литерал массива, где каждый элемент литерала является свойством .init типа элемента массива. |
| 2 |
.размер Статический массив возвращает длину массива, умноженную на количество байтов на элемент массива, в то время как динамические массивы возвращают размер ссылки на динамический массив, который равен 8 в 32-разрядных сборках и 16 в 64-разрядных сборках. |
| 3 |
.length Статический массив возвращает количество элементов в массиве, в то время как динамические массивы используются для получения / установки количества элементов в массиве. Длина имеет тип size_t. |
| 4 |
.ptr Возвращает указатель на первый элемент массива. |
| 5 |
.dup Создайте динамический массив того же размера и скопируйте в него содержимое массива. |
| 6 |
.idup Создайте динамический массив того же размера и скопируйте в него содержимое массива. Копия печатается как неизменяемая. |
| 7 |
.задний ход Меняет местами порядок элементов в массиве. Возвращает массив. |
| 8 |
.Сортировать Сортирует по порядку элементов в массиве. Возвращает массив. |
.в этом
Статический массив возвращает литерал массива, где каждый элемент литерала является свойством .init типа элемента массива.
.размер
Статический массив возвращает длину массива, умноженную на количество байтов на элемент массива, в то время как динамические массивы возвращают размер ссылки на динамический массив, который равен 8 в 32-разрядных сборках и 16 в 64-разрядных сборках.
.length
Статический массив возвращает количество элементов в массиве, в то время как динамические массивы используются для получения / установки количества элементов в массиве. Длина имеет тип size_t.
.ptr
Возвращает указатель на первый элемент массива.
.dup
Создайте динамический массив того же размера и скопируйте в него содержимое массива.
.idup
Создайте динамический массив того же размера и скопируйте в него содержимое массива. Копия печатается как неизменяемая.
.задний ход
Меняет местами порядок элементов в массиве. Возвращает массив.
.Сортировать
Сортирует по порядку элементов в массиве. Возвращает массив.
пример
Следующий пример объясняет различные свойства массива —
import std.stdio; void main() { int n[ 5 ]; // n is an array of 5 integers // initialize elements of array n to 0 for ( int i = 0; i < 5; i++ ) { n[ i ] = i + 100; // set element at location i to i + 100 } writeln("Initialized value:",n.init); writeln("Length: ",n.length); writeln("Size of: ",n.sizeof); writeln("Pointer:",n.ptr); writeln("Duplicate Array: ",n.dup); writeln("iDuplicate Array: ",n.idup); n = n.reverse.dup; writeln("Reversed Array: ",n); writeln("Sorted Array: ",n.sort); }
Когда приведенный выше код компилируется и выполняется, он дает следующий результат —
Initialized value:[0, 0, 0, 0, 0] Length: 5 Size of: 20 Pointer:7FFF5A373920 Duplicate Array: [100, 101, 102, 103, 104] iDuplicate Array: [100, 101, 102, 103, 104] Reversed Array: [104, 103, 102, 101, 100] Sorted Array: [100, 101, 102, 103, 104]
Многомерные массивы в D
D программирование допускает многомерные массивы. Вот общая форма объявления многомерного массива —
type name[size1][size2]...[sizeN];
пример
Следующая декларация создает трехмерное 5. 10 4-х целочисленный массив —
int threedim[5][10][4];
Двумерные массивы в D
Простейшей формой многомерного массива является двумерный массив. Двумерный массив — это, по сути, список одномерных массивов. Чтобы объявить двумерный целочисленный массив размером [x, y], вы должны написать синтаксис следующим образом:
type arrayName [ x ][ y ];
Где тип может быть любым допустимым типом данных программирования D, а arrayName будет действительным идентификатором программирования D.
Где тип может быть любым допустимым типом данных программирования D, а arrayName является допустимым идентификатором программирования D.
Двумерный массив можно представить как таблицу, которая имеет x количество строк и y количество столбцов. Двумерный массив, содержащий три строки и четыре столбца, может быть показан ниже:
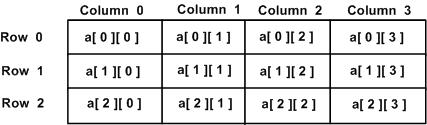
Таким образом, каждый элемент в массиве a идентифицируется элементом как a [i] [j] , где a — это имя массива, а i и j — индексы, которые однозначно идентифицируют каждый элемент в a.
Инициализация двухмерных массивов
Многомерные массивы можно инициализировать, указав значения в скобках для каждой строки. Следующий массив имеет 3 строки, а каждая строка имеет 4 столбца.
int a[3][4] = [ [0, 1, 2, 3] , /* initializers for row indexed by 0 */ [4, 5, 6, 7] , /* initializers for row indexed by 1 */ [8, 9, 10, 11] /* initializers for row indexed by 2 */ ];
Вложенные скобки, которые указывают на предполагаемый ряд, являются необязательными. Следующая инициализация эквивалентна предыдущему примеру —
int a[3][4] = [0,1,2,3,4,5,6,7,8,9,10,11];
Доступ к двумерным элементам массива
Доступ к элементу в двумерном массиве осуществляется с использованием индексов, то есть индекса строки и индекса столбца массива. Например
int val = a[2][3];
Вышеупомянутое утверждение берет 4-й элемент из 3-й строки массива. Вы можете проверить это в приведенной выше диграмме.
import std.stdio; void main () { // an array with 5 rows and 2 columns. int a[5][2] = [ [0,0], [1,2], [2,4], [3,6],[4,8]]; // output each array element's value for ( int i = 0; i < 5; i++ ) for ( int j = 0; j < 2; j++ ) { writeln( "a[" , i , "][" , j , "]: ",a[i][j]); } }
Когда приведенный выше код компилируется и выполняется, он дает следующий результат —
a[0][0]: 0 a[0][1]: 0 a[1][0]: 1 a[1][1]: 2 a[2][0]: 2 a[2][1]: 4 a[3][0]: 3 a[3][1]: 6 a[4][0]: 4 a[4][1]: 8
Распространенные операции над массивами в D
Вот различные операции, выполняемые над массивами —
Нарезка массива
Мы часто используем часть массива, и нарезка массива часто весьма полезна. Простой пример нарезки массива показан ниже.
import std.stdio; void main () { // an array with 5 elements. double a[5] = [1000.0, 2.0, 3.4, 17.0, 50.0]; double[] b; b = a[1..3]; writeln(b); }
Когда приведенный выше код компилируется и выполняется, он дает следующий результат —
[2, 3.4]
Копирование массива
Мы также используем копирование массива. Простой пример копирования массива показан ниже.
import std.stdio; void main () { // an array with 5 elements. double a[5] = [1000.0, 2.0, 3.4, 17.0, 50.0]; double b[5]; writeln("Array a:",a); writeln("Array b:",b); b[] = a; // the 5 elements of a[5] are copied into b[5] writeln("Array b:",b); b[] = a[]; // the 5 elements of a[3] are copied into b[5] writeln("Array b:",b); b[1..2] = a[0..1]; // same as b[1] = a[0] writeln("Array b:",b); b[0..2] = a[1..3]; // same as b[0] = a[1], b[1] = a[2] writeln("Array b:",b); }
Когда приведенный выше код компилируется и выполняется, он дает следующий результат —
Array a:[1000, 2, 3.4, 17, 50] Array b:[nan, nan, nan, nan, nan] Array b:[1000, 2, 3.4, 17, 50] Array b:[1000, 2, 3.4, 17, 50] Array b:[1000, 1000, 3.4, 17, 50] Array b:[2, 3.4, 3.4, 17, 50]
Настройка массива
Простой пример установки значения в массиве показан ниже.
import std.stdio; void main () { // an array with 5 elements. double a[5]; a[] = 5; writeln("Array a:",a); }
Когда приведенный выше код компилируется и выполняется, он дает следующий результат —
Array a:[5, 5, 5, 5, 5]
Конкатенация массивов
Простой пример объединения двух массивов показан ниже.
import std.stdio; void main () { // an array with 5 elements. double a[5] = 5; double b[5] = 10; double [] c; c = a~b; writeln("Array c: ",c); }
Когда приведенный выше код компилируется и выполняется, он дает следующий результат —
Array c: [5, 5, 5, 5, 5, 10, 10, 10, 10, 10]
D Программирование — Ассоциативные массивы
Ассоциативные массивы имеют индекс, который не обязательно является целым числом и может быть малонаселенным. Индекс для ассоциативного массива называется Key , а его тип называется KeyType .
Ассоциативные массивы объявляются путем помещения KeyType в [] объявления массива. Простой пример для ассоциативного массива показан ниже.
import std.stdio; void main () { int[string] e; // associative array b of ints that are e["test"] = 3; writeln(e["test"]); string[string] f; f["test"] = "Tuts"; writeln(f["test"]); writeln(f); f.remove("test"); writeln(f); }
Когда приведенный выше код компилируется и выполняется, он дает следующий результат —
3 Tuts ["test":"Tuts"] []
Инициализация ассоциативного массива
Простая инициализация ассоциативного массива показана ниже.
import std.stdio; void main () { int[string] days = [ "Monday" : 0, "Tuesday" : 1, "Wednesday" : 2, "Thursday" : 3, "Friday" : 4, "Saturday" : 5, "Sunday" : 6 ]; writeln(days["Tuesday"]); }
Когда приведенный выше код компилируется и выполняется, он дает следующий результат —
1
Свойства ассоциативного массива
Вот свойства ассоциативного массива —
| Sr.No. | Описание недвижимости |
|---|---|
| 1 |
.размер Возвращает размер ссылки на ассоциативный массив; это 4 в 32-битных сборках и 8 в 64-битных сборках. |
| 2 |
.length Возвращает количество значений в ассоциативном массиве. В отличие от динамических массивов, он доступен только для чтения. |
| 3 |
.dup Создайте новый ассоциативный массив того же размера и скопируйте в него содержимое ассоциативного массива. |
| 4 |
.keys Возвращает динамический массив, элементами которого являются ключи в ассоциативном массиве. |
| 5 |
.ценности Возвращает динамический массив, элементами которого являются значения в ассоциативном массиве. |
| 6 |
.rehash Реорганизует ассоциативный массив на месте, чтобы поиск был более эффективным. Перефразирование эффективно, когда, например, программа закончила загрузку таблицы символов и теперь нуждается в быстром поиске в ней. Возвращает ссылку на реорганизованный массив. |
| 7 |
.byKey () Возвращает делегат, пригодный для использования в качестве Aggregate для ForeachStatement, который будет перебирать ключи ассоциативного массива. |
| 8 |
.byValue () Возвращает делегат, пригодный для использования в качестве Aggregate для ForeachStatement, который будет перебирать значения ассоциативного массива. |
| 9 |
.get (Key key, lazy Value defVal) Смотрит вверх ключ; если он существует, возвращает соответствующее значение, иначе оценивает и возвращает defVal. |
| 10 |
.remove (ключевой ключ) Удаляет объект для ключа. |
.размер
Возвращает размер ссылки на ассоциативный массив; это 4 в 32-битных сборках и 8 в 64-битных сборках.
.length
Возвращает количество значений в ассоциативном массиве. В отличие от динамических массивов, он доступен только для чтения.
.dup
Создайте новый ассоциативный массив того же размера и скопируйте в него содержимое ассоциативного массива.
.keys
Возвращает динамический массив, элементами которого являются ключи в ассоциативном массиве.
.ценности
Возвращает динамический массив, элементами которого являются значения в ассоциативном массиве.
.rehash
Реорганизует ассоциативный массив на месте, чтобы поиск был более эффективным. Перефразирование эффективно, когда, например, программа закончила загрузку таблицы символов и теперь нуждается в быстром поиске в ней. Возвращает ссылку на реорганизованный массив.
.byKey ()
Возвращает делегат, пригодный для использования в качестве Aggregate для ForeachStatement, который будет перебирать ключи ассоциативного массива.
.byValue ()
Возвращает делегат, пригодный для использования в качестве Aggregate для ForeachStatement, который будет перебирать значения ассоциативного массива.
.get (Key key, lazy Value defVal)
Смотрит вверх ключ; если он существует, возвращает соответствующее значение, иначе оценивает и возвращает defVal.
.remove (ключевой ключ)
Удаляет объект для ключа.
пример
Пример использования вышеуказанных свойств показан ниже.
import std.stdio; void main () { int[string] array1; array1["test"] = 3; array1["test2"] = 20; writeln("sizeof: ",array1.sizeof); writeln("length: ",array1.length); writeln("dup: ",array1.dup); array1.rehash; writeln("rehashed: ",array1); writeln("keys: ",array1.keys); writeln("values: ",array1.values); foreach (key; array1.byKey) { writeln("by key: ",key); } foreach (value; array1.byValue) { writeln("by value ",value); } writeln("get value for key test: ",array1.get("test",10)); writeln("get value for key test3: ",array1.get("test3",10)); array1.remove("test"); writeln(array1); }
Когда приведенный выше код компилируется и выполняется, он дает следующий результат —
sizeof: 8 length: 2 dup: ["test":3, "test2":20] rehashed: ["test":3, "test2":20] keys: ["test", "test2"] values: [3, 20] by key: test by key: test2 by value 3 by value 20 get value for key test: 3 get value for key test3: 10 ["test2":20]
D Программирование — Указатели
Указатели на программирование D легко и весело выучить. Некоторые задачи D-программирования выполняются с помощью указателей, а другие задачи D-программирования, такие как динамическое распределение памяти, не могут быть выполнены без них. Простой указатель показан ниже.
Вместо прямого указания на переменную указатель указывает на адрес переменной. Как вы знаете, каждая переменная является ячейкой памяти, и каждая ячейка памяти имеет свой адрес, к которому можно обратиться, используя оператор амперсанда (&), который обозначает адрес в памяти. Рассмотрим следующее, которое печатает адрес определенных переменных:
import std.stdio; void main () { int var1; writeln("Address of var1 variable: ",&var1); char var2[10]; writeln("Address of var2 variable: ",&var2); }
Когда приведенный выше код компилируется и выполняется, он дает следующий результат —
Address of var1 variable: 7FFF52691928 Address of var2 variable: 7FFF52691930
Что такое указатели?
Указатель — это переменная, значением которой является адрес другой переменной. Как и любая переменная или константа, вы должны объявить указатель, прежде чем вы сможете работать с ним. Общая форма объявления переменной указателя —
type *var-name;
Здесь тип — это базовый тип указателя; это должен быть допустимый тип программирования, а var-name — это имя переменной-указателя. Звездочка, которую вы использовали для объявления указателя, та же, что и для умножения. Тем не мение; в этом утверждении звездочка используется для обозначения переменной в качестве указателя. Следующее является действительным объявлением указателя —
int *ip; // pointer to an integer double *dp; // pointer to a double float *fp; // pointer to a float char *ch // pointer to character
Фактический тип данных значения всех указателей, будь то целое число, число с плавающей запятой, символ или другое, является одним и тем же, длинное шестнадцатеричное число, представляющее адрес памяти. Единственное различие между указателями разных типов данных — это тип данных переменной или константы, на которую указывает указатель.
Использование указателей в D-программировании
Есть несколько важных операций, когда мы очень часто используем указатели.
-
мы определяем переменные указателя
-
назначить адрес переменной указателю
-
наконец, получить доступ к значению по адресу, доступному в переменной указателя.
мы определяем переменные указателя
назначить адрес переменной указателю
наконец, получить доступ к значению по адресу, доступному в переменной указателя.
Это делается с помощью унарного оператора *, который возвращает значение переменной, расположенной по адресу, указанному ее операндом. В следующем примере используются эти операции —
import std.stdio; void main () { int var = 20; // actual variable declaration. int *ip; // pointer variable ip = &var; // store address of var in pointer variable writeln("Value of var variable: ",var); writeln("Address stored in ip variable: ",ip); writeln("Value of *ip variable: ",*ip); }
Когда приведенный выше код компилируется и выполняется, он дает следующий результат —
Value of var variable: 20 Address stored in ip variable: 7FFF5FB7E930 Value of *ip variable: 20
Нулевые указатели
Рекомендуется всегда присваивать указатель NULL переменной-указателю, если у вас нет точного адреса для назначения. Это делается во время объявления переменной. Указатель, которому присваивается значение NULL, называется указателем NULL .
Пустой указатель — это константа со значением ноль, определенная в нескольких стандартных библиотеках, включая iostream. Рассмотрим следующую программу —
import std.stdio; void main () { int *ptr = null; writeln("The value of ptr is " , ptr) ; }
Когда приведенный выше код компилируется и выполняется, он дает следующий результат —
The value of ptr is null
В большинстве операционных систем программам не разрешен доступ к памяти по адресу 0, поскольку эта память зарезервирована операционной системой. Тем не мение; адрес памяти 0 имеет особое значение; он сигнализирует о том, что указатель не предназначен для указания на доступную ячейку памяти.
По соглашению, если указатель содержит нулевое (нулевое) значение, предполагается, что он ничего не указывает. Чтобы проверить нулевой указатель, вы можете использовать оператор if следующим образом:
if(ptr) // succeeds if p is not null if(!ptr) // succeeds if p is null
Таким образом, если все неиспользуемые указатели имеют нулевое значение и вы избегаете использования нулевого указателя, вы можете избежать случайного неправильного использования неинициализированного указателя. Часто неинициализированные переменные содержат некоторые ненужные значения, и становится трудно отлаживать программу.
Указатель Арифметика
Существует четыре арифметических оператора, которые можно использовать в указателях: ++, -, + и —
Чтобы понять арифметику указателей, рассмотрим целочисленный указатель с именем ptr , который указывает на адрес 1000. Предполагая 32-разрядные целые числа, выполним следующую арифметическую операцию с указателем:
ptr++
тогда ptr будет указывать на местоположение 1004, потому что каждый раз, когда ptr увеличивается, он указывает на следующее целое число. Эта операция переместит указатель на следующую ячейку памяти, не влияя на фактическое значение в ячейке памяти.
Если ptr указывает на символ, адрес которого равен 1000, то вышеуказанная операция указывает на местоположение 1001, потому что следующий символ будет доступен на 1001.
Увеличение указателя
Мы предпочитаем использовать указатель в нашей программе вместо массива, потому что указатель переменной можно увеличивать, в отличие от имени массива, которое нельзя увеличивать, потому что это постоянный указатель. Следующая программа увеличивает указатель переменной для доступа к каждому последующему элементу массива:
import std.stdio; const int MAX = 3; void main () { int var[MAX] = [10, 100, 200]; int *ptr = &var[0]; for (int i = 0; i < MAX; i++, ptr++) { writeln("Address of var[" , i , "] = ",ptr); writeln("Value of var[" , i , "] = ",*ptr); } }
Когда приведенный выше код компилируется и выполняется, он дает следующий результат —
Address of var[0] = 18FDBC Value of var[0] = 10 Address of var[1] = 18FDC0 Value of var[1] = 100 Address of var[2] = 18FDC4 Value of var[2] = 200
Указатели против массива
Указатели и массивы тесно связаны. Однако указатели и массивы не являются полностью взаимозаменяемыми. Например, рассмотрим следующую программу —
import std.stdio; const int MAX = 3; void main () { int var[MAX] = [10, 100, 200]; int *ptr = &var[0]; var.ptr[2] = 290; ptr[0] = 220; for (int i = 0; i < MAX; i++, ptr++) { writeln("Address of var[" , i , "] = ",ptr); writeln("Value of var[" , i , "] = ",*ptr); } }
В приведенной выше программе вы можете увидеть var.ptr [2] для установки второго элемента и ptr [0], который используется для установки нулевого элемента. Оператор инкремента может использоваться с ptr, но не с var.
Когда приведенный выше код компилируется и выполняется, он дает следующий результат —
Address of var[0] = 18FDBC Value of var[0] = 220 Address of var[1] = 18FDC0 Value of var[1] = 100 Address of var[2] = 18FDC4 Value of var[2] = 290
Указатель на указатель
Указатель на указатель — это форма множественного косвенного обращения или цепочка указателей. Обычно указатель содержит адрес переменной. Когда мы определяем указатель на указатель, первый указатель содержит адрес второго указателя, который указывает на местоположение, которое содержит фактическое значение, как показано ниже.

Переменная, которая является указателем на указатель, должна быть объявлена как таковая. Это делается путем размещения дополнительной звездочки перед ее именем. Например, следующий синтаксис для объявления указателя на указатель типа int —
int **var;
Когда на целевое значение косвенно указывает указатель на указатель, то для доступа к этому значению требуется дважды применить оператор звездочки, как показано ниже в примере:
import std.stdio; const int MAX = 3; void main () { int var = 3000; writeln("Value of var :" , var); int *ptr = &var; writeln("Value available at *ptr :" ,*ptr); int **pptr = &ptr; writeln("Value available at **pptr :",**pptr); }
Когда приведенный выше код компилируется и выполняется, он дает следующий результат —
Value of var :3000 Value available at *ptr :3000 Value available at **pptr :3000
Передача указателя на функции
D позволяет передавать указатель на функцию. Для этого он просто объявляет параметр функции как тип указателя.
Следующий простой пример передает указатель на функцию.
import std.stdio; void main () { // an int array with 5 elements. int balance[5] = [1000, 2, 3, 17, 50]; double avg; avg = getAverage( &balance[0], 5 ) ; writeln("Average is :" , avg); } double getAverage(int *arr, int size) { int i; double avg, sum = 0; for (i = 0; i < size; ++i) { sum += arr[i]; } avg = sum/size; return avg; }
Когда приведенный выше код компилируется и выполняется, он дает следующий результат —
Average is :214.4
Возврат указателя из функций
Рассмотрим следующую функцию, которая возвращает 10 чисел, используя указатель, означает адрес первого элемента массива.
import std.stdio; void main () { int *p = getNumber(); for ( int i = 0; i < 10; i++ ) { writeln("*(p + " , i , ") : ",*(p + i)); } } int * getNumber( ) { static int r [10]; for (int i = 0; i < 10; ++i) { r[i] = i; } return &r[0]; }
Когда приведенный выше код компилируется и выполняется, он дает следующий результат —
*(p + 0) : 0 *(p + 1) : 1 *(p + 2) : 2 *(p + 3) : 3 *(p + 4) : 4 *(p + 5) : 5 *(p + 6) : 6 *(p + 7) : 7 *(p + 8) : 8 *(p + 9) : 9
Указатель на массив
Имя массива — это постоянный указатель на первый элемент массива. Поэтому в декларации —
double balance[50];
balance — это указатель на & balance [0], который является адресом первого элемента массива balance. Таким образом, следующий фрагмент программы назначает p адрес первого элемента баланса —
double *p; double balance[10]; p = balance;
Допустимо использовать имена массивов в качестве указателей на константы, и наоборот. Следовательно, * (баланс + 4) является законным способом доступа к данным на балансе [4].
Как только вы сохраните адрес первого элемента в p, вы можете получить доступ к элементам массива, используя * p, * (p + 1), * (p + 2) и так далее. В следующем примере показаны все концепции, рассмотренные выше.
import std.stdio; void main () { // an array with 5 elements. double balance[5] = [1000.0, 2.0, 3.4, 17.0, 50.0]; double *p; p = &balance[0]; // output each array element's value writeln("Array values using pointer " ); for ( int i = 0; i < 5; i++ ) { writeln( "*(p + ", i, ") : ", *(p + i)); } }
Когда приведенный выше код компилируется и выполняется, он дает следующий результат —
Array values using pointer *(p + 0) : 1000 *(p + 1) : 2 *(p + 2) : 3.4 *(p + 3) : 17 *(p + 4) : 50
D Программирование — Кортежи
Кортежи используются для объединения нескольких значений в один объект. Кортежи содержат последовательность элементов. Элементы могут быть типами, выражениями или псевдонимами. Число и элементы кортежа фиксируются во время компиляции и не могут быть изменены во время выполнения.
Кортежи имеют характеристики как структур, так и массивов. Элементы кортежа могут быть разных типов, например структуры. Доступ к элементам осуществляется через индексирование, как в массивах. Они реализованы как библиотечная функция с помощью шаблона Tuple из модуля std.typecons. Tuple использует TypeTuple из модуля std.typetuple для некоторых своих операций.
Tuple Использование tuple ()
Кортежи могут быть созданы функцией tuple (). Доступ к членам кортежа осуществляется через значения индекса. Пример показан ниже.
пример
import std.stdio; import std.typecons; void main() { auto myTuple = tuple(1, "Tuts"); writeln(myTuple); writeln(myTuple[0]); writeln(myTuple[1]); }
Когда приведенный выше код компилируется и выполняется, он дает следующий результат —
Tuple!(int, string)(1, "Tuts") 1 Tuts
Кортеж с использованием шаблона кортежа
Кортеж также может быть создан непосредственно по шаблону кортежа вместо функции tuple (). Тип и имя каждого члена указываются в виде двух последовательных параметров шаблона. Доступ к элементам по свойствам возможен при создании с использованием шаблонов.
import std.stdio; import std.typecons; void main() { auto myTuple = Tuple!(int, "id",string, "value")(1, "Tuts"); writeln(myTuple); writeln("by index 0 : ", myTuple[0]); writeln("by .id : ", myTuple.id); writeln("by index 1 : ", myTuple[1]); writeln("by .value ", myTuple.value); }
Когда приведенный выше код компилируется и выполняется, он дает следующий результат
Tuple!(int, "id", string, "value")(1, "Tuts") by index 0 : 1 by .id : 1 by index 1 : Tuts by .value Tuts
Расширение свойств и параметров функций
Члены Tuple могут быть расширены либо с помощью свойства .expand, либо путем нарезки. Это расширенное / нарезанное значение может быть передано как список аргументов функции. Пример показан ниже.
пример
import std.stdio; import std.typecons; void method1(int a, string b, float c, char d) { writeln("method 1 ",a,"\t",b,"\t",c,"\t",d); } void method2(int a, float b, char c) { writeln("method 2 ",a,"\t",b,"\t",c); } void main() { auto myTuple = tuple(5, "my string", 3.3, 'r'); writeln("method1 call 1"); method1(myTuple[]); writeln("method1 call 2"); method1(myTuple.expand); writeln("method2 call 1"); method2(myTuple[0], myTuple[$-2..$]); }
Когда приведенный выше код компилируется и выполняется, он дает следующий результат —
method1 call 1 method 1 5 my string 3.3 r method1 call 2 method 1 5 my string 3.3 r method2 call 1 method 2 5 3.3 r
TypeTuple
TypeTuple определяется в модуле std.typetuple. Разделенный запятыми список значений и типов. Простой пример использования TypeTuple приведен ниже. TypeTuple используется для создания списка аргументов, списка шаблонов и списка литералов массива.
import std.stdio; import std.typecons; import std.typetuple; alias TypeTuple!(int, long) TL; void method1(int a, string b, float c, char d) { writeln("method 1 ",a,"\t",b,"\t",c,"\t",d); } void method2(TL tl) { writeln(tl[0],"\t", tl[1] ); } void main() { auto arguments = TypeTuple!(5, "my string", 3.3,'r'); method1(arguments); method2(5, 6L); }
Когда приведенный выше код компилируется и выполняется, он дает следующий результат —
method 1 5 my string 3.3 r 5 6
D Программирование — Структуры
Структура является еще одним определяемым пользователем типом данных, доступным в D-программировании, который позволяет комбинировать элементы данных разных видов.
Структуры используются для представления записи. Предположим, вы хотите отслеживать свои книги в библиотеке. Вы можете отслеживать следующие атрибуты о каждой книге —
- заглавие
- автор
- Предмет
- ID книги
Определение структуры
Чтобы определить структуру, вы должны использовать инструкцию struct . Оператор struct определяет новый тип данных с более чем одним членом для вашей программы. Формат инструкции struct такой:
struct [structure tag] {
member definition;
member definition;
...
member definition;
} [one or more structure variables];
Тег структуры является необязательным, и каждое определение члена является обычным определением переменной, например int i; или плавать f; или любое другое допустимое определение переменной. В конце определения структуры перед точкой с запятой вы можете указать одну или несколько структурных переменных, которые являются необязательными. Вот как вы бы объявили структуру Книги —
struct Books {
char [] title;
char [] author;
char [] subject;
int book_id;
};
Доступ к членам структуры
Чтобы получить доступ к любому члену структуры, вы используете оператор доступа к члену (.) . Оператор доступа к элементу кодируется как точка между именем структурной переменной и элементом структуры, к которому мы хотим получить доступ. Вы должны использовать ключевое слово struct для определения переменных типа структуры. Следующий пример объясняет использование структуры —
import std.stdio; struct Books { char [] title; char [] author; char [] subject; int book_id; }; void main( ) { Books Book1; /* Declare Book1 of type Book */ Books Book2; /* Declare Book2 of type Book */ /* book 1 specification */ Book1.title = "D Programming".dup; Book1.author = "Raj".dup; Book1.subject = "D Programming Tutorial".dup; Book1.book_id = 6495407; /* book 2 specification */ Book2.title = "D Programming".dup; Book2.author = "Raj".dup; Book2.subject = "D Programming Tutorial".dup; Book2.book_id = 6495700; /* print Book1 info */ writeln( "Book 1 title : ", Book1.title); writeln( "Book 1 author : ", Book1.author); writeln( "Book 1 subject : ", Book1.subject); writeln( "Book 1 book_id : ", Book1.book_id); /* print Book2 info */ writeln( "Book 2 title : ", Book2.title); writeln( "Book 2 author : ", Book2.author); writeln( "Book 2 subject : ", Book2.subject); writeln( "Book 2 book_id : ", Book2.book_id); }
Когда приведенный выше код компилируется и выполняется, он дает следующий результат —
Book 1 title : D Programming Book 1 author : Raj Book 1 subject : D Programming Tutorial Book 1 book_id : 6495407 Book 2 title : D Programming Book 2 author : Raj Book 2 subject : D Programming Tutorial Book 2 book_id : 6495700
Структуры как аргументы функций
Вы можете передать структуру в качестве аргумента функции так же, как и любую другую переменную или указатель. Вы будете обращаться к структурным переменным аналогично тому, как вы это делали в приведенном выше примере:
import std.stdio; struct Books { char [] title; char [] author; char [] subject; int book_id; }; void main( ) { Books Book1; /* Declare Book1 of type Book */ Books Book2; /* Declare Book2 of type Book */ /* book 1 specification */ Book1.title = "D Programming".dup; Book1.author = "Raj".dup; Book1.subject = "D Programming Tutorial".dup; Book1.book_id = 6495407; /* book 2 specification */ Book2.title = "D Programming".dup; Book2.author = "Raj".dup; Book2.subject = "D Programming Tutorial".dup; Book2.book_id = 6495700; /* print Book1 info */ printBook( Book1 ); /* Print Book2 info */ printBook( Book2 ); } void printBook( Books book ) { writeln( "Book title : ", book.title); writeln( "Book author : ", book.author); writeln( "Book subject : ", book.subject); writeln( "Book book_id : ", book.book_id); }
Когда приведенный выше код компилируется и выполняется, он дает следующий результат —
Book title : D Programming Book author : Raj Book subject : D Programming Tutorial Book book_id : 6495407 Book title : D Programming Book author : Raj Book subject : D Programming Tutorial Book book_id : 6495700
Инициализация структур
Структуры могут быть инициализированы в двух формах, одна с использованием construtor, а другая с использованием формата {}. Пример показан ниже.
пример
import std.stdio; struct Books { char [] title; char [] subject = "Empty".dup; int book_id = -1; char [] author = "Raj".dup; }; void main( ) { Books Book1 = Books("D Programming".dup, "D Programming Tutorial".dup, 6495407 ); printBook( Book1 ); Books Book2 = Books("D Programming".dup, "D Programming Tutorial".dup, 6495407,"Raj".dup ); printBook( Book2 ); Books Book3 = {title:"Obj C programming".dup, book_id : 1001}; printBook( Book3 ); } void printBook( Books book ) { writeln( "Book title : ", book.title); writeln( "Book author : ", book.author); writeln( "Book subject : ", book.subject); writeln( "Book book_id : ", book.book_id); }
Когда приведенный выше код компилируется и выполняется, он дает следующий результат —
Book title : D Programming Book author : Raj Book subject : D Programming Tutorial Book book_id : 6495407 Book title : D Programming Book author : Raj Book subject : D Programming Tutorial Book book_id : 6495407 Book title : Obj C programming Book author : Raj Book subject : Empty Book book_id : 1001
Статические Члены
Статические переменные инициализируются только один раз. Например, чтобы иметь уникальные идентификаторы для книг, мы можем сделать book_id статическим и увеличить идентификатор книги. Пример показан ниже.
пример
import std.stdio; struct Books { char [] title; char [] subject = "Empty".dup; int book_id; char [] author = "Raj".dup; static int id = 1000; }; void main( ) { Books Book1 = Books("D Programming".dup, "D Programming Tutorial".dup,++Books.id ); printBook( Book1 ); Books Book2 = Books("D Programming".dup, "D Programming Tutorial".dup,++Books.id); printBook( Book2 ); Books Book3 = {title:"Obj C programming".dup, book_id:++Books.id}; printBook( Book3 ); } void printBook( Books book ) { writeln( "Book title : ", book.title); writeln( "Book author : ", book.author); writeln( "Book subject : ", book.subject); writeln( "Book book_id : ", book.book_id); }
Когда приведенный выше код компилируется и выполняется, он дает следующий результат —
Book title : D Programming Book author : Raj Book subject : D Programming Tutorial Book book_id : 1001 Book title : D Programming Book author : Raj Book subject : D Programming Tutorial Book book_id : 1002 Book title : Obj C programming Book author : Raj Book subject : Empty Book book_id : 1003
D Программирование — Союзы
Объединение — это специальный тип данных, доступный в D, который позволяет хранить разные типы данных в одной и той же ячейке памяти. Вы можете определить объединение со многими членами, но только один член может содержать значение в любой момент времени. Союзы предоставляют эффективный способ использования одной и той же области памяти для нескольких целей.
Определение союза в D
Чтобы определить объединение, вы должны использовать оператор объединения очень похожим образом, как при определении структуры. Оператор union определяет новый тип данных с более чем одним членом для вашей программы. Формат заявления объединения следующий:
union [union tag] {
member definition;
member definition;
...
member definition;
} [one or more union variables];
Тег объединения является необязательным, и каждое определение члена является обычным определением переменной, например int i; или плавать f; или любое другое допустимое определение переменной. В конце определения объединения перед последней точкой с запятой вы можете указать одну или несколько переменных объединения, но это необязательно. Вот как вы можете определить тип объединения с именем Data, который имеет три члена i , f и str.
union Data {
int i;
float f;
char str[20];
} data;
Переменная типа данных может хранить целое число, число с плавающей запятой или строку символов. Это означает, что одна переменная (та же ячейка памяти) может использоваться для хранения нескольких типов данных. Вы можете использовать любые встроенные или определенные пользователем типы данных внутри объединения в зависимости от ваших требований.
Память, занятая профсоюзом, будет достаточно большой, чтобы вместить самого крупного члена профсоюза. Например, в приведенном выше примере тип данных будет занимать 20 байт пространства памяти, поскольку это максимальное пространство, которое может занимать символьная строка. В следующем примере показан общий объем памяти, занимаемый вышеуказанным объединением —
import std.stdio; union Data { int i; float f; char str[20]; }; int main( ) { Data data; writeln( "Memory size occupied by data : ", data.sizeof); return 0; }
Когда приведенный выше код компилируется и выполняется, он дает следующий результат —
Memory size occupied by data : 20
Доступ к членам Союза
Чтобы получить доступ к любому члену профсоюза, мы используем оператор доступа члена (.) . Оператор доступа к члену кодируется как точка между именем переменной объединения и членом объединения, к которому мы хотим получить доступ. Вы бы использовали ключевое слово union для определения переменных типа union.
пример
Следующий пример объясняет использование union —
import std.stdio; union Data { int i; float f; char str[13]; }; void main( ) { Data data; data.i = 10; data.f = 220.5; data.str = "D Programming".dup; writeln( "size of : ", data.sizeof); writeln( "data.i : ", data.i); writeln( "data.f : ", data.f); writeln( "data.str : ", data.str); }
Когда приведенный выше код компилируется и выполняется, он дает следующий результат —
size of : 16 data.i : 1917853764 data.f : 4.12236e+30 data.str : D Programming
Здесь вы можете видеть, что значения членов i и f объединения были повреждены, потому что окончательное значение, присвоенное переменной, заняло место в памяти, и это является причиной того, что значение члена str печатается очень хорошо.
Теперь давайте снова посмотрим на тот же пример, где мы будем использовать одну переменную за раз, что является основной целью объединения —
Модифицированный пример
import std.stdio; union Data { int i; float f; char str[13]; }; void main( ) { Data data; writeln( "size of : ", data.sizeof); data.i = 10; writeln( "data.i : ", data.i); data.f = 220.5; writeln( "data.f : ", data.f); data.str = "D Programming".dup; writeln( "data.str : ", data.str); }
Когда приведенный выше код компилируется и выполняется, он дает следующий результат —
size of : 16 data.i : 10 data.f : 220.5 data.str : D Programming
Здесь все участники печатаются очень хорошо, потому что один член используется за один раз.
D Программирование — Диапазоны
Диапазоны являются абстракцией доступа к элементам. Эта абстракция позволяет использовать большое количество алгоритмов для большого количества типов контейнеров. Диапазоны подчеркивают, как осуществляется доступ к элементам контейнера, а не к реализации контейнеров. Диапазоны — это очень простая концепция, основанная на том, определяет ли тип определенные наборы функций-членов.
Диапазоны являются неотъемлемой частью срезов D. D, как оказалось, являются реализациями самого мощного диапазона RandomAccessRange, и в Фобосе есть много функций диапазона. Многие алгоритмы Фобоса возвращают объекты временного диапазона. Например, filter () выбирает элементы, которые больше 10, в следующем коде фактически возвращает объект диапазона, а не массив.
Диапазоны номеров
Числовые диапазоны довольно часто используются, и эти числовые диапазоны имеют тип int. Несколько примеров для диапазонов номеров показаны ниже —
// Example 1 foreach (value; 3..7) // Example 2 int[] slice = array[5..10];
Фобосские хребты
Диапазоны, связанные со структурами и интерфейсами классов — это диапазоны Фобоса. Phobos — это официальная библиотека времени выполнения и стандартная библиотека, которая поставляется с компилятором языка D.
Существуют различные типы диапазонов, которые включают в себя —
- InputRange
- ForwardRange
- BidirectionalRange
- RandomAccessRange
- OutputRange
InputRange
Самый простой диапазон — это диапазон ввода. Другие диапазоны предъявляют больше требований к диапазону, на котором они основаны. Есть три функции, которые требует InputRange —
-
empty — указывает, пуст ли диапазон; он должен возвращать true, если диапазон считается пустым; ложь в противном случае.
-
front — обеспечивает доступ к элементу в начале диапазона.
-
popFront () — сокращает диапазон с начала, удаляя первый элемент.
empty — указывает, пуст ли диапазон; он должен возвращать true, если диапазон считается пустым; ложь в противном случае.
front — обеспечивает доступ к элементу в начале диапазона.
popFront () — сокращает диапазон с начала, удаляя первый элемент.
пример
import std.stdio; import std.string; struct Student { string name; int number; string toString() const { return format("%s(%s)", name, number); } } struct School { Student[] students; } struct StudentRange { Student[] students; this(School school) { this.students = school.students; } @property bool empty() const { return students.length == 0; } @property ref Student front() { return students[0]; } void popFront() { students = students[1 .. $]; } } void main() { auto school = School([ Student("Raj", 1), Student("John", 2), Student("Ram", 3)]); auto range = StudentRange(school); writeln(range); writeln(school.students.length); writeln(range.front); range.popFront; writeln(range.empty); writeln(range); }
Когда приведенный выше код компилируется и выполняется, он дает следующий результат —
[Raj(1), John(2), Ram(3)] 3 Raj(1) false [John(2), Ram(3)]
ForwardRange
ForwardRange дополнительно требует части функции-члена сохранения из трех других функций InputRange и возвращает копию диапазона при вызове функции сохранения.
import std.array; import std.stdio; import std.string; import std.range; struct FibonacciSeries { int first = 0; int second = 1; enum empty = false; // infinite range @property int front() const { return first; } void popFront() { int third = first + second; first = second; second = third; } @property FibonacciSeries save() const { return this; } } void report(T)(const dchar[] title, const ref T range) { writefln("%s: %s", title, range.take(5)); } void main() { auto range = FibonacciSeries(); report("Original range", range); range.popFrontN(2); report("After removing two elements", range); auto theCopy = range.save; report("The copy", theCopy); range.popFrontN(3); report("After removing three more elements", range); report("The copy", theCopy); }
Когда приведенный выше код компилируется и выполняется, он дает следующий результат —
Original range: [0, 1, 1, 2, 3] After removing two elements: [1, 2, 3, 5, 8] The copy: [1, 2, 3, 5, 8] After removing three more elements: [5, 8, 13, 21, 34] The copy: [1, 2, 3, 5, 8]
BidirectionalRange
BidirectionalRange дополнительно предоставляет две функции-члена над функциями-членами ForwardRange. Задняя функция, аналогичная передней, обеспечивает доступ к последнему элементу диапазона. Функция popBack похожа на функцию popFront и удаляет последний элемент из диапазона.
пример
import std.array; import std.stdio; import std.string; struct Reversed { int[] range; this(int[] range) { this.range = range; } @property bool empty() const { return range.empty; } @property int front() const { return range.back; // reverse } @property int back() const { return range.front; // reverse } void popFront() { range.popBack(); } void popBack() { range.popFront(); } } void main() { writeln(Reversed([ 1, 2, 3])); }
Когда приведенный выше код компилируется и выполняется, он дает следующий результат —
[3, 2, 1]
Infinite RandomAccessRange
opIndex () дополнительно требуется по сравнению с ForwardRange. Кроме того, значение пустой функции, которая будет известна во время компиляции как false. Простой пример поясняется диапазоном квадратов, который показан ниже.
import std.array; import std.stdio; import std.string; import std.range; import std.algorithm; class SquaresRange { int first; this(int first = 0) { this.first = first; } enum empty = false; @property int front() const { return opIndex(0); } void popFront() { ++first; } @property SquaresRange save() const { return new SquaresRange(first); } int opIndex(size_t index) const { /* This function operates at constant time */ immutable integerValue = first + cast(int)index; return integerValue * integerValue; } } bool are_lastTwoDigitsSame(int value) { /* Must have at least two digits */ if (value < 10) { return false; } /* Last two digits must be divisible by 11 */ immutable lastTwoDigits = value % 100; return (lastTwoDigits % 11) == 0; } void main() { auto squares = new SquaresRange(); writeln(squares[5]); writeln(squares[10]); squares.popFrontN(5); writeln(squares[0]); writeln(squares.take(50).filter!are_lastTwoDigitsSame); }
Когда приведенный выше код компилируется и выполняется, он дает следующий результат —
25 100 25 [100, 144, 400, 900, 1444, 1600, 2500]
Finite RandomAccessRange
opIndex () и длина дополнительно требуются при сравнении с двунаправленным диапазоном. Это объясняется с помощью подробного примера, который использует ряды Фибоначчи и пример квадратов, использованный ранее. Этот пример хорошо работает на обычном D-компиляторе, но не работает на онлайн-компиляторе.
пример
import std.array; import std.stdio; import std.string; import std.range; import std.algorithm; struct FibonacciSeries { int first = 0; int second = 1; enum empty = false; // infinite range @property int front() const { return first; } void popFront() { int third = first + second; first = second; second = third; } @property FibonacciSeries save() const { return this; } } void report(T)(const dchar[] title, const ref T range) { writefln("%40s: %s", title, range.take(5)); } class SquaresRange { int first; this(int first = 0) { this.first = first; } enum empty = false; @property int front() const { return opIndex(0); } void popFront() { ++first; } @property SquaresRange save() const { return new SquaresRange(first); } int opIndex(size_t index) const { /* This function operates at constant time */ immutable integerValue = first + cast(int)index; return integerValue * integerValue; } } bool are_lastTwoDigitsSame(int value) { /* Must have at least two digits */ if (value < 10) { return false; } /* Last two digits must be divisible by 11 */ immutable lastTwoDigits = value % 100; return (lastTwoDigits % 11) == 0; } struct Together { const(int)[][] slices; this(const(int)[][] slices ...) { this.slices = slices.dup; clearFront(); clearBack(); } private void clearFront() { while (!slices.empty && slices.front.empty) { slices.popFront(); } } private void clearBack() { while (!slices.empty && slices.back.empty) { slices.popBack(); } } @property bool empty() const { return slices.empty; } @property int front() const { return slices.front.front; } void popFront() { slices.front.popFront(); clearFront(); } @property Together save() const { return Together(slices.dup); } @property int back() const { return slices.back.back; } void popBack() { slices.back.popBack(); clearBack(); } @property size_t length() const { return reduce!((a, b) => a + b.length)(size_t.init, slices); } int opIndex(size_t index) const { /* Save the index for the error message */ immutable originalIndex = index; foreach (slice; slices) { if (slice.length > index) { return slice[index]; } else { index -= slice.length; } } throw new Exception( format("Invalid index: %s (length: %s)", originalIndex, this.length)); } } void main() { auto range = Together(FibonacciSeries().take(10).array, [ 777, 888 ], (new SquaresRange()).take(5).array); writeln(range.save); }
Когда приведенный выше код компилируется и выполняется, он дает следующий результат —
[0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 777, 888, 0, 1, 4, 9, 16]
OutputRange
OutputRange представляет потоковый вывод элемента, аналогично отправке символов в стандартный вывод. OutputRange требует поддержки операции put (range, element). put () — это функция, определенная в модуле std.range. Он определяет возможности диапазона и элемента во время компиляции и использует наиболее подходящий метод для вывода элементов. Простой пример показан ниже.
import std.algorithm; import std.stdio; struct MultiFile { string delimiter; File[] files; this(string delimiter, string[] fileNames ...) { this.delimiter = delimiter; /* stdout is always included */ this.files ~= stdout; /* A File object for each file name */ foreach (fileName; fileNames) { this.files ~= File(fileName, "w"); } } void put(T)(T element) { foreach (file; files) { file.write(element, delimiter); } } } void main() { auto output = MultiFile("\n", "output_0", "output_1"); copy([ 1, 2, 3], output); copy([ "red", "blue", "green" ], output); }
Когда приведенный выше код компилируется и выполняется, он дает следующий результат —
[1, 2, 3] ["red", "blue", "green"]
D Программирование — Псевдонимы
Псевдоним, как следует из названия, предоставляет альтернативное имя для существующих имен. Синтаксис для псевдонима показан ниже.
alias new_name = existing_name;
Ниже приведен старый синтаксис, на случай, если вы обратитесь к некоторым старым примерам форматов. Настоятельно не рекомендуется использовать это.
alias existing_name new_name;
Существует также другой синтаксис, который используется с выражением, и он приведен ниже, в котором мы можем напрямую использовать псевдоним вместо выражения.
alias expression alias_name ;
Как вы, возможно, знаете, typedef добавляет возможность создавать новые типы. Псевдоним может выполнять работу typedef и даже больше. Ниже приведен простой пример использования псевдонима, в котором используется заголовок std.conv, который обеспечивает возможность преобразования типов.
import std.stdio; import std.conv:to; alias to!(string) toString; void main() { int a = 10; string s = "Test"~toString(a); writeln(s); }
Когда приведенный выше код компилируется и выполняется, он дает следующий результат —
Test10
В приведенном выше примере вместо использования!! String (a) мы присвоили его псевдониму toString, что делает его более удобным и простым для понимания.
Псевдоним для кортежа
Давайте посмотрим на другой пример, где мы можем установить псевдоним для кортежа.
import std.stdio; import std.typetuple; alias TypeTuple!(int, long) TL; void method1(TL tl) { writeln(tl[0],"\t", tl[1] ); } void main() { method1(5, 6L); }
Когда приведенный выше код компилируется и выполняется, он дает следующий результат —
5 6
В приведенном выше примере кортежу типа присваивается переменная псевдонима, что упрощает определение метода и доступ к переменным. Этот вид доступа еще более полезен, когда мы пытаемся использовать кортежи такого типа.
Псевдоним для типов данных
Много раз мы можем определить общие типы данных, которые должны использоваться в приложении. Когда несколько программистов кодируют приложение, это могут быть случаи, когда один человек использует int, другой double и так далее. Чтобы избежать таких конфликтов, мы часто используем типы для типов данных. Простой пример показан ниже.
пример
import std.stdio; alias int myAppNumber; alias string myAppString; void main() { myAppNumber i = 10; myAppString s = "TestString"; writeln(i,s); }
Когда приведенный выше код компилируется и выполняется, он дает следующий результат —
10TestString
Псевдоним для переменных класса
Часто существует требование, когда нам нужно получить доступ к переменным-членам суперкласса в подклассе, это можно сделать с помощью псевдонима, возможно, под другим именем.
Если вы новичок в понятии классов и наследования, ознакомьтесь с руководством по классам и наследованию, прежде чем начинать с этого раздела.
пример
Простой пример показан ниже.
import std.stdio; class Shape { int area; } class Square : Shape { string name() const @property { return "Square"; } alias Shape.area squareArea; } void main() { auto square = new Square; square.squareArea = 42; writeln(square.name); writeln(square.squareArea); }
Когда приведенный выше код компилируется и выполняется, он дает следующий результат —
Square 42
Алиас это
Псевдоним это обеспечивает возможность автоматического преобразования типов пользовательских типов. Синтаксис показан ниже, где ключевые слова псевдоним и это написано по обе стороны от переменной-члена или функции-члена.
alias member_variable_or_member_function this;
пример
Ниже показан пример, демонстрирующий силу псевдонима this.
import std.stdio; struct Rectangle { long length; long breadth; double value() const @property { return cast(double) length * breadth; } alias value this; } double volume(double rectangle, double height) { return rectangle * height; } void main() { auto rectangle = Rectangle(2, 3); writeln(volume(rectangle, 5)); }
В приведенном выше примере вы можете видеть, что прямоугольник структуры преобразуется в двойное значение с помощью псевдонима этого метода.
Когда приведенный выше код компилируется и выполняется, он дает следующий результат —
30
D Программирование — Mixins
Миксины — это структуры, которые позволяют смешивать сгенерированный код с исходным кодом. Mixins могут быть следующих типов —
- Струнные миксины
- Шаблон Mixins
- Смешанные пространства имен
Струнные миксины
D имеет возможность вставлять код в виде строки, если эта строка известна во время компиляции. Синтаксис строковых миксинов показан ниже —
mixin (compile_time_generated_string)
пример
Простой пример для строковых миксинов показан ниже.
import std.stdio; void main() { mixin(`writeln("Hello World!");`); }
Когда приведенный выше код компилируется и выполняется, он дает следующий результат —
Hello World!
Вот еще один пример, где мы можем передать строку во время компиляции, чтобы миксины могли использовать функции для повторного использования кода. Это показано ниже.
import std.stdio; string print(string s) { return `writeln("` ~ s ~ `");`; } void main() { mixin (print("str1")); mixin (print("str2")); }
Когда приведенный выше код компилируется и выполняется, он дает следующий результат —
str1 str2
Шаблон Mixins
Шаблоны D определяют общие шаблоны кода, чтобы компилятор генерировал реальные экземпляры из этого шаблона. Шаблоны могут генерировать функции, структуры, объединения, классы, интерфейсы и любой другой допустимый D-код. Синтаксис шаблонных миксов приведен ниже.
mixin a_template!(template_parameters)
Простой пример для строковых миксинов показан ниже, где мы создаем шаблон с классом Department и миксином, создаем экземпляр шаблона и, следовательно, делаем функции setName и printNames доступными для структурного колледжа.
пример
import std.stdio; template Department(T, size_t count) { T[count] names; void setName(size_t index, T name) { names[index] = name; } void printNames() { writeln("The names"); foreach (i, name; names) { writeln(i," : ", name); } } } struct College { mixin Department!(string, 2); } void main() { auto college = College(); college.setName(0, "name1"); college.setName(1, "name2"); college.printNames(); }
Когда приведенный выше код компилируется и выполняется, он дает следующий результат —
The names 0 : name1 1 : name2
Смешанные пространства имен
Пространства имен миксинов используются, чтобы избежать неоднозначностей в миксинах шаблонов. Например, может быть две переменные, одна из которых определена явно в main, а другая смешана. Когда смешанное имя совпадает с именем, которое находится в окружающей области видимости, тогда имя, которое находится в окружающей области видимости, получает используемый. Этот пример показан ниже.
пример
import std.stdio; template Person() { string name; void print() { writeln(name); } } void main() { string name; mixin Person a; name = "name 1"; writeln(name); a.name = "name 2"; print(); }
Когда приведенный выше код компилируется и выполняется, он дает следующий результат —
name 1 name 2
D Программирование — Модули
Модули являются строительными блоками D. Они основаны на простой концепции. Каждый исходный файл является модулем. Соответственно, отдельные файлы, в которые мы пишем программы, являются отдельными модулями. По умолчанию имя модуля совпадает с именем файла без расширения .d.
При явном указании имя модуля определяется ключевым словом module, которое должно отображаться как первая строка без комментариев в исходном файле. Например, предположим, что имя исходного файла — «employee.d». Затем имя модуля указывается ключевым словом модуля, за которым следует сотрудник . Это как показано ниже.
module employee; class Employee { // Class definition goes here. }
Линия модуля является необязательной. Если не указано, оно совпадает с именем файла без расширения .d.
Имена файлов и модулей
D поддерживает Unicode в исходном коде и именах модулей. Однако поддержка файловых систем в Юникоде может быть разной. Например, хотя большинство файловых систем Linux поддерживают Unicode, имена файлов в файловых системах Windows могут не различаться строчными и прописными буквами. Кроме того, большинство файловых систем ограничивают символы, которые могут использоваться в именах файлов и каталогов. По причинам переносимости, я рекомендую использовать только строчные буквы ASCII в именах файлов. Например, «employee.d» будет подходящим именем файла для класса с именем employee.
Соответственно, название модуля также будет состоять из букв ASCII —
module employee; // Module name consisting of ASCII letters
class eëmployëë { }
D пакеты
Комбинация связанных модулей называется пакетом. Пакеты D также являются простой концепцией: исходные файлы, находящиеся в одном каталоге, считаются принадлежащими одному и тому же пакету. Имя каталога становится именем пакета, которое также должно быть указано в качестве первых частей имен модулей.
Например, если «employee.d» и «office.d» находятся внутри каталога «company», то указание имени каталога вместе с именем модуля делает их частью одного пакета —
module company.employee;
class Employee { }
Аналогично для офисного модуля —
module company.office;
class Office { }
Поскольку имена пакетов соответствуют именам каталогов, имена пакетов модулей, которые находятся глубже одного уровня каталогов, должны отражать эту иерархию. Например, если каталог «company» включает каталог «branch», имя модуля внутри этого каталога также будет включать в себя филиал.
module company.branch.employee;
Использование модулей в программах
Ключевое слово import, которое мы использовали почти во всех программах, предназначено для введения модуля в текущий модуль —
import std.stdio;
Имя модуля также может содержать имя пакета. Например, станд. часть выше указывает, что stdio является модулем, который является частью пакета std.
Расположение модулей
Компилятор находит файлы модуля путем преобразования имен пакетов и модулей непосредственно в имена каталогов и файлов.
Например, два модуля employee и office будут расположены как «company / employee.d» и «animal / office.d» соответственно (или «company \ employee.d» и «company \ office.d», в зависимости от файловая система) для company.employee и company.office.
Длинные и короткие имена модулей
Имена, используемые в программе, могут быть прописаны вместе с именами модулей и пакетов, как показано ниже.
import company.employee; auto employee0 = Employee(); auto employee1 = company.employee.Employee();
Длинные имена обычно не нужны, но иногда возникают конфликты имен. Например, при обращении к имени, которое появляется в более чем одном модуле, компилятор не может решить, какое из них имеется в виду. В следующей программе прописаны длинные имена, позволяющие различать две отдельные структуры сотрудников , которые определены в двух отдельных модулях: компания и колледж. ,
Первый сотрудник модуля в папке компании выглядит следующим образом.
module company.employee; import std.stdio; class Employee { public: string str; void print() { writeln("Company Employee: ",str); } }
Второй сотрудник модуля в папке колледжа работает следующим образом.
module college.employee; import std.stdio; class Employee { public: string str; void print() { writeln("College Employee: ",str); } }
Основной модуль в hello.d должен быть сохранен в папке, содержащей папки колледжа и компании. Это так.
import company.employee; import college.employee; import std.stdio; void main() { auto myemployee1 = new company.employee.Employee(); myemployee1.str = "emp1"; myemployee1.print(); auto myemployee2 = new college.employee.Employee(); myemployee2.str = "emp2"; myemployee2.print(); }
Ключевого слова import недостаточно для того, чтобы модули стали частью программы. Он просто делает доступными функции модуля внутри текущего модуля. Это нужно только для компиляции кода.
Для создания вышеуказанной программы в строке компиляции также должны быть указаны «company / employee.d» и «College / employee.d».
Когда приведенный выше код компилируется и выполняется, он дает следующий результат —
$ dmd hello.d company/employee.d college/employee.d -ofhello.amx $ ./hello.amx Company Employee: emp1 College Employee: emp2
D Программирование — Шаблоны
Шаблоны являются основой общего программирования, которое включает в себя написание кода способом, независимым от какого-либо конкретного типа.
Шаблон — это план или формула для создания универсального класса или функции.
Шаблоны — это функция, которая позволяет описывать код как шаблон, чтобы компилятор автоматически генерировал программный код. Части исходного кода могут быть оставлены для заполнения компилятором до тех пор, пока эта часть не будет фактически использована в программе. Компилятор заполняет недостающие части.
Шаблон функции
Определение функции в качестве шаблона оставляет один или несколько типов, которые она использует, как неопределенные, которые будут выведены позднее компилятором. Типы, которые остаются неопределенными, определяются в списке параметров шаблона, который находится между именем функции и списком параметров функции. По этой причине шаблоны функций имеют два списка параметров:
- список параметров шаблона
- список параметров функции
import std.stdio; void print(T)(T value) { writefln("%s", value); } void main() { print(42); print(1.2); print("test"); }
Если мы скомпилируем и запустим приведенный выше код, это даст следующий результат —
42 1.2 test
Шаблон функции с несколькими типами параметров
Может быть несколько типов параметров. Они показаны в следующем примере.
import std.stdio; void print(T1, T2)(T1 value1, T2 value2) { writefln(" %s %s", value1, value2); } void main() { print(42, "Test"); print(1.2, 33); }
Если мы скомпилируем и запустим приведенный выше код, это даст следующий результат —
42 Test 1.2 33
Шаблоны классов
Так же, как мы можем определять шаблоны функций, мы также можем определять шаблоны классов. В следующем примере определяется класс Stack и реализуются универсальные методы для выталкивания и извлечения элементов из стека.
import std.stdio; import std.string; class Stack(T) { private: T[] elements; public: void push(T element) { elements ~= element; } void pop() { --elements.length; } T top() const @property { return elements[$ - 1]; } size_t length() const @property { return elements.length; } } void main() { auto stack = new Stack!string; stack.push("Test1"); stack.push("Test2"); writeln(stack.top); writeln(stack.length); stack.pop; writeln(stack.top); writeln(stack.length); }
Когда приведенный выше код компилируется и выполняется, он дает следующий результат —
Test2 2 Test1 1
D Программирование — Неизменный
Мы часто используем переменные, которые могут изменяться, но во многих случаях изменчивость не требуется. В таких случаях можно использовать неизменяемые переменные. Ниже приведены несколько примеров, где можно использовать неизменяемую переменную.
-
В случае математических констант, таких как пи, которые никогда не меняются.
-
В случае массивов, где мы хотим сохранить значения, а это не требования мутации.
В случае математических констант, таких как пи, которые никогда не меняются.
В случае массивов, где мы хотим сохранить значения, а это не требования мутации.
Неизменность позволяет понять, являются ли переменные неизменяемыми или изменяемыми, гарантируя, что определенные операции не изменяют определенные переменные. Это также снижает риск некоторых типов программных ошибок. Концепция неизменяемости D представлена постоянными и неизменяемыми ключевыми словами. Хотя эти два слова близки по значению, их обязанности в программах различны и иногда они несовместимы.
Концепция неизменяемости D представлена постоянными и неизменяемыми ключевыми словами. Хотя эти два слова близки по значению, их обязанности в программах различны и иногда они несовместимы.
Типы неизменяемых переменных в D
Существует три типа определяющих переменных, которые никогда не могут быть изменены.
- константы перечисления
- неизменяемые переменные
- константные переменные
константы перечисления в D
Константы enum позволяют связать постоянные значения с осмысленными именами. Простой пример показан ниже.
пример
import std.stdio; enum Day{ Sunday = 1, Monday, Tuesday, Wednesday, Thursday, Friday, Saturday } void main() { Day day; day = Day.Sunday; if (day == Day.Sunday) { writeln("The day is Sunday"); } }
Когда приведенный выше код компилируется и выполняется, он дает следующий результат —
The day is Sunday
Неизменяемые переменные в D
Неизменные переменные могут быть определены во время выполнения программы. Он просто указывает компилятору, что после инициализации он становится неизменным. Простой пример показан ниже.
пример
import std.stdio; import std.random; void main() { int min = 1; int max = 10; immutable number = uniform(min, max + 1); // cannot modify immutable expression number // number = 34; typeof(number) value = 100; writeln(typeof(number).stringof, number); writeln(typeof(value).stringof, value); }
Когда приведенный выше код компилируется и выполняется, он дает следующий результат —
immutable(int)4 immutable(int)100
В приведенном выше примере вы можете увидеть, как можно перенести тип данных в другую переменную и использовать stringof при печати.
Переменные Const в D
Переменные Const нельзя изменить аналогично неизменяемым. неизменяемые переменные могут быть переданы в функции как их неизменяемые параметры, и поэтому рекомендуется использовать неизменяемое значение по сравнению с const. Тот же самый пример, который использовался ранее, модифицируется для const, как показано ниже.
пример
import std.stdio; import std.random; void main() { int min = 1; int max = 10; const number = uniform(min, max + 1); // cannot modify const expression number| // number = 34; typeof(number) value = 100; writeln(typeof(number).stringof, number); writeln(typeof(value).stringof, value); }
Если мы скомпилируем и запустим приведенный выше код, это даст следующий результат —
const(int)7 const(int)100
Неизменные параметры в D
const стирает информацию о том, является ли исходная переменная изменяемой или неизменной, и, следовательно, использование неизменяемой заставляет ее передавать ей другие функции с сохранением исходного типа. Простой пример показан ниже.
пример
import std.stdio; void print(immutable int[] array) { foreach (i, element; array) { writefln("%s: %s", i, element); } } void main() { immutable int[] array = [ 1, 2 ]; print(array); }
Когда приведенный выше код компилируется и выполняется, он дает следующий результат —
0: 1 1: 2
D Программирование — Файловый ввод / вывод
Файлы представлены структурой File модуля std.stdio. Файл представляет собой последовательность байтов, не имеет значения, является ли это текстовым файлом или двоичным файлом.
Язык программирования D обеспечивает доступ к функциям высокого уровня, а также к вызовам низкого уровня (уровня ОС) для обработки файлов на ваших устройствах хранения.
Открытие файлов в D
Стандартные потоки ввода и вывода stdin и stdout уже открыты, когда программы запускаются. Они готовы к использованию. С другой стороны, сначала необходимо открыть файлы, указав имя файла и необходимые права доступа.
File file = File(filepath, "mode");
Здесь имя файла является строковым литералом, который вы используете для именования файла, и режим доступа может иметь одно из следующих значений:
| Sr.No. | Режим и описание |
|---|---|
| 1 |
р Открывает существующий текстовый файл для чтения. |
| 2 |
вес Открывает текстовый файл для записи, если он не существует, то создается новый файл. Здесь ваша программа начнет запись содержимого с начала файла. |
| 3 |
Открывает текстовый файл для записи в режиме добавления, если он не существует, то создается новый файл. Здесь ваша программа начнет добавлять содержимое в существующий файл содержимого. |
| 4 |
г + Открывает текстовый файл для чтения и записи как. |
| 5 |
ш + Открывает текстовый файл для чтения и записи как. Сначала он обрезает файл до нулевой длины, если он существует, в противном случае создайте файл, если он не существует. |
| 6 |
а + Открывает текстовый файл для чтения и записи как. Он создает файл, если он не существует. Чтение начнется с самого начала, но запись может быть только добавлена. |
р
Открывает существующий текстовый файл для чтения.
вес
Открывает текстовый файл для записи, если он не существует, то создается новый файл. Здесь ваша программа начнет запись содержимого с начала файла.
Открывает текстовый файл для записи в режиме добавления, если он не существует, то создается новый файл. Здесь ваша программа начнет добавлять содержимое в существующий файл содержимого.
г +
Открывает текстовый файл для чтения и записи как.
ш +
Открывает текстовый файл для чтения и записи как. Сначала он обрезает файл до нулевой длины, если он существует, в противном случае создайте файл, если он не существует.
а +
Открывает текстовый файл для чтения и записи как. Он создает файл, если он не существует. Чтение начнется с самого начала, но запись может быть только добавлена.
Закрытие файла в D
Чтобы закрыть файл, используйте функцию file.close (), где file содержит ссылку на файл. Прототип этой функции —
file.close();
Любой файл, который был открыт программой, должен быть закрыт, когда программа заканчивает использовать этот файл. В большинстве случаев файлы не нужно закрывать явно; они закрываются автоматически, когда объекты File завершаются.
Запись файла в D
file.writeln используется для записи в открытый файл.
file.writeln("hello");
import std.stdio; import std.file; void main() { File file = File("test.txt", "w"); file.writeln("hello"); file.close(); }
Когда приведенный выше код компилируется и выполняется, он создает новый файл test.txt в каталоге, в котором он был запущен (в рабочем каталоге программы).
Чтение файла в D
Следующий метод читает одну строку из файла —
string s = file.readln();
Полный пример чтения и записи приведен ниже.
import std.stdio; import std.file; void main() { File file = File("test.txt", "w"); file.writeln("hello"); file.close(); file = File("test.txt", "r"); string s = file.readln(); writeln(s); file.close(); }
Когда приведенный выше код компилируется и выполняется, он читает файл, созданный в предыдущем разделе, и выдает следующий результат:
hello
Вот еще один пример для чтения файла до конца файла.
import std.stdio; import std.string; void main() { File file = File("test.txt", "w"); file.writeln("hello"); file.writeln("world"); file.close(); file = File("test.txt", "r"); while (!file.eof()) { string line = chomp(file.readln()); writeln("line -", line); } }
Когда приведенный выше код компилируется и выполняется, он читает файл, созданный в предыдущем разделе, и выдает следующий результат:
line -hello line -world line -
В приведенном выше примере вы можете видеть пустую третью строку, поскольку writeln переносит ее на следующую строку после ее выполнения.
D Программирование — Параллелизм
Параллельность — это выполнение программы одновременно несколькими потоками. Примером параллельной программы является веб-сервер, отвечающий одновременно нескольким клиентам. Параллелизм прост с передачей сообщений, но очень трудно писать, если они основаны на обмене данными.
Данные, которые передаются между потоками, называются сообщениями. Сообщения могут состоять из любого типа и любого количества переменных. Каждый поток имеет идентификатор, который используется для указания получателей сообщений. Любой поток, который запускает другой поток, называется владельцем нового потока.
Инициирование потоков в D
Функция spawn () принимает указатель в качестве параметра и запускает новый поток из этой функции. Любые операции, выполняемые этой функцией, включая другие функции, которые она может вызывать, будут выполняться в новом потоке. Владелец и рабочий оба начинают выполняться отдельно, как если бы они были независимыми программами.
пример
import std.stdio; import std.stdio; import std.concurrency; import core.thread; void worker(int a) { foreach (i; 0 .. 4) { Thread.sleep(1); writeln("Worker Thread ",a + i); } } void main() { foreach (i; 1 .. 4) { Thread.sleep(2); writeln("Main Thread ",i); spawn(≈worker, i * 5); } writeln("main is done."); }
Когда приведенный выше код компилируется и выполняется, он читает файл, созданный в предыдущем разделе, и выдает следующий результат:
Main Thread 1 Worker Thread 5 Main Thread 2 Worker Thread 6 Worker Thread 10 Main Thread 3 main is done. Worker Thread 7 Worker Thread 11 Worker Thread 15 Worker Thread 8 Worker Thread 12 Worker Thread 16 Worker Thread 13 Worker Thread 17 Worker Thread 18
Идентификаторы потока в D
Переменная thisTid, доступная глобально на уровне модуля, всегда является идентификатором текущего потока. Также вы можете получить threadId при вызове spawn. Пример показан ниже.
пример
import std.stdio; import std.concurrency; void printTid(string tag) { writefln("%s: %s, address: %s", tag, thisTid, &thisTid); } void worker() { printTid("Worker"); } void main() { Tid myWorker = spawn(&worker); printTid("Owner "); writeln(myWorker); }
Когда приведенный выше код компилируется и выполняется, он читает файл, созданный в предыдущем разделе, и выдает следующий результат:
Owner : Tid(std.concurrency.MessageBox), address: 10C71A59C Worker: Tid(std.concurrency.MessageBox), address: 10C71A59C Tid(std.concurrency.MessageBox)
Передача сообщений в D
Функция send () отправляет сообщения, а функция receiveOnly () ожидает сообщения определенного типа. Есть другие функции с именем prioritySend (), receive () и receiveTimeout (), которые будут объяснены позже.
Владелец в следующей программе отправляет своему работнику сообщение типа int и ожидает сообщения от работника типа double. Потоки продолжают отправлять сообщения туда и обратно, пока владелец не отправит отрицательный int. Пример показан ниже.
пример
import std.stdio; import std.concurrency; import core.thread; import std.conv; void workerFunc(Tid tid) { int value = 0; while (value >= 0) { value = receiveOnly!int(); auto result = to!double(value) * 5; tid.send(result); } } void main() { Tid worker = spawn(&workerFunc,thisTid); foreach (value; 5 .. 10) { worker.send(value); auto result = receiveOnly!double(); writefln("sent: %s, received: %s", value, result); } worker.send(-1); }
Когда приведенный выше код компилируется и выполняется, он читает файл, созданный в предыдущем разделе, и выдает следующий результат:
sent: 5, received: 25 sent: 6, received: 30 sent: 7, received: 35 sent: 8, received: 40 sent: 9, received: 45
Передача сообщения с ожиданием в D
Простой пример передачи сообщения с ожиданием показан ниже.
import std.stdio; import std.concurrency; import core.thread; import std.conv; void workerFunc(Tid tid) { Thread.sleep(dur!("msecs")( 500 ),); tid.send("hello"); } void main() { spawn(&workerFunc,thisTid); writeln("Waiting for a message"); bool received = false; while (!received) { received = receiveTimeout(dur!("msecs")( 100 ), (string message) { writeln("received: ", message); }); if (!received) { writeln("... no message yet"); } } }
Когда приведенный выше код компилируется и выполняется, он читает файл, созданный в предыдущем разделе, и выдает следующий результат:
Waiting for a message ... no message yet ... no message yet ... no message yet ... no message yet received: hello
D Программирование — обработка исключений
Исключением является проблема, возникающая при выполнении программы. Исключение AD — это ответ на исключительное обстоятельство, которое возникает во время работы программы, например, попытка деления на ноль.
Исключения предоставляют способ передачи управления из одной части программы в другую. Обработка исключений D построена на трех ключевых словах: try , catch и throw .
-
throw — программа выдает исключение при обнаружении проблемы. Это делается с помощью ключевого слова throw .
-
catch — программа ловит исключение с помощью обработчика исключений в том месте программы, где вы хотите решить проблему. Ключевое слово catch указывает на перехват исключения.
-
try — блок try идентифицирует блок кода, для которого активируются определенные исключения. За ним следует один или несколько блоков улова.
throw — программа выдает исключение при обнаружении проблемы. Это делается с помощью ключевого слова throw .
catch — программа ловит исключение с помощью обработчика исключений в том месте программы, где вы хотите решить проблему. Ключевое слово catch указывает на перехват исключения.
try — блок try идентифицирует блок кода, для которого активируются определенные исключения. За ним следует один или несколько блоков улова.
Предполагая, что блок вызовет исключение, метод перехватывает исключение, используя комбинацию ключевых слов try и catch . Вокруг кода помещается блок try / catch, который может генерировать исключение. Код в блоке try / catch называется защищенным кодом, и синтаксис использования try / catch выглядит следующим образом:
try {
// protected code
}
catch( ExceptionName e1 ) {
// catch block
}
catch( ExceptionName e2 ) {
// catch block
}
catch( ExceptionName eN ) {
// catch block
}
Вы можете перечислить несколько операторов catch для перехвата различных типов исключений в случае, если ваш блок try вызывает более одного исключения в разных ситуациях.
Бросать исключения в D
Исключения могут быть выброшены в любом месте блока кода с помощью операторов throw . Операнд операторов throw определяет тип исключения и может быть любым выражением, а тип результата выражения определяет тип создаваемого исключения.
В следующем примере выдается исключение, когда происходит деление на ноль —
пример
double division(int a, int b) { if( b == 0 ) { throw new Exception("Division by zero condition!"); } return (a/b); }
Поймать исключения в D
Блок catch, следующий за блоком try, перехватывает любое исключение. Вы можете указать, какой тип исключения вы хотите перехватить, и это определяется объявлением исключения, которое появляется в скобках после ключевого слова catch.
try { // protected code } catch( ExceptionName e ) { // code to handle ExceptionName exception }
Приведенный выше код перехватывает исключение типа ExceptionName . Если вы хотите указать, что блок catch должен обрабатывать исключение любого типа, которое выдается в блоке try, вы должны поместить многоточие, …, в круглые скобки, содержащие объявление исключения, следующим образом:
try { // protected code } catch(...) { // code to handle any exception }
В следующем примере показано исключение деления на ноль. Это пойман в блоке улова.
import std.stdio; import std.string; string division(int a, int b) { string result = ""; try { if( b == 0 ) { throw new Exception("Cannot divide by zero!"); } else { result = format("%s",a/b); } } catch (Exception e) { result = e.msg; } return result; } void main () { int x = 50; int y = 0; writeln(division(x, y)); y = 10; writeln(division(x, y)); }
Когда приведенный выше код компилируется и выполняется, он читает файл, созданный в предыдущем разделе, и выдает следующий результат:
Cannot divide by zero! 5
D — Программирование контракта
Контрактное программирование в D-программировании направлено на предоставление простых и понятных средств обработки ошибок. Контрактное программирование в D осуществляется тремя типами блоков кода:
- блок кузова
- в блоке
- вне блока
Блок кузова в D
Блок body содержит актуальный код функциональности исполнения. Блоки in и out являются необязательными, а блок body — обязательным. Простой синтаксис показан ниже.
return_type function_name(function_params)
in {
// in block
}
out (result) {
// in block
}
body {
// actual function block
}
В блоке для предварительных условий в D
Блок in предназначен для простых предварительных условий, которые проверяют, являются ли входные параметры приемлемыми и находятся в диапазоне, который может обрабатываться кодом. Преимущество блока in заключается в том, что все входные условия могут храниться вместе и отделяться от фактического тела функции. Простое предварительное условие для подтверждения пароля для его минимальной длины показано ниже.
import std.stdio; import std.string; bool isValid(string password) in { assert(password.length>=5); } body { // other conditions return true; } void main() { writeln(isValid("password")); }
Когда приведенный выше код компилируется и выполняется, он читает файл, созданный в предыдущем разделе, и выдает следующий результат:
true
Выходные блоки для условий публикации в D
Блок out заботится о возвращаемых значениях из функции. Это подтверждает, что возвращаемое значение находится в ожидаемом диапазоне. Ниже показан простой пример, содержащий как вход, так и выход, который преобразует месяцы, год в комбинированную десятичную возрастную форму.
import std.stdio; import std.string; double getAge(double months,double years) in { assert(months >= 0); assert(months <= 12); } out (result) { assert(result>=years); } body { return years + months/12; } void main () { writeln(getAge(10,12)); }
Когда приведенный выше код компилируется и выполняется, он читает файл, созданный в предыдущем разделе, и выдает следующий результат:
12.8333
D Программирование — условная компиляция
Условная компиляция — это процесс выбора, какой код компилировать, а какой код не компилировать, аналогично #if / #else / #endif в C и C ++. Любое утверждение, которое не скомпилировано, должно быть синтаксически правильным.
Условная компиляция включает в себя проверки условий, которые можно оценить во время компиляции. Условные операторы времени выполнения, такие как if, for, не являются условными компонентами компиляции. Следующие особенности D предназначены для условной компиляции —
- отлаживать
- версия
- статический, если
Отладка оператора в D
Отладка полезна при разработке программы. Выражения и операторы, помеченные как отладочные, компилируются в программу только при включенном параметре компилятора -debug.
debug a_conditionally_compiled_expression;
debug {
// ... conditionally compiled code ...
} else {
// ... code that is compiled otherwise ...
}
Предложение else является необязательным. И отдельное выражение, и приведенный выше блок кода компилируются только при включенном ключе компилятора -debug.
Вместо полного удаления строки могут быть помечены как отладочные.
debug writefln("%s debug only statement", value);
Такие строки включаются в программу, только если включен параметр компилятора -debug.
dmd test.d -oftest -w -debug
Отладка (тег) оператор в D
Операторам отладки могут быть заданы имена (теги) для выборочного включения в программу.
debug(mytag) writefln("%s not found", value);
Такие строки включаются в программу, только если включен параметр компилятора -debug.
dmd test.d -oftest -w -debug = mytag
Блоки отладки также могут иметь теги.
debug(mytag) { // }
Можно включить более одного тега отладки одновременно.
dmd test.d -oftest -w -debug = mytag1 -debug = mytag2
Отладка (уровень) Заявление в D
Иногда полезно связать операторы отладки по числовым уровням. Повышение уровня может предоставить более подробную информацию.
import std.stdio; void myFunction() { debug(1) writeln("debug1"); debug(2) writeln("debug2"); } void main() { myFunction(); }
Выражения отладки и блоки, которые ниже или равны указанному уровню, будут скомпилированы.
$ dmd test.d -oftest -w -debug = 1 $ ./test debug1
Версия (тег) и версия (уровень) Заявления в D
Версия похожа на отладку и используется таким же образом. Предложение else является необязательным. Хотя версия работает по сути так же, как и отладка, наличие отдельных ключевых слов помогает различать их несвязанное использование. Как и в случае с отладкой, можно включить более одной версии.
import std.stdio; void myFunction() { version(1) writeln("version1"); version(2) writeln("version2"); } void main() { myFunction(); }
Выражения отладки и блоки, которые ниже или равны указанному уровню, будут скомпилированы.
$ dmd test.d -oftest -w -version = 1 $ ./test version1
Статическое если
Статический if является эквивалентом времени компиляции оператора if. Точно так же, как оператор if, static if принимает логическое выражение и оценивает его. В отличие от оператора if, статический if не относится к потоку выполнения; скорее он определяет, должен ли фрагмент кода быть включен в программу или нет.
Выражение if не связано с оператором is, который мы видели ранее, как синтаксически, так и семантически. Он оценивается во время компиляции. Он выдает значение типа int либо 0, либо 1; в зависимости от выражения, указанного в скобках. Хотя выражение, которое оно принимает, не является логическим выражением, само выражение is используется как логическое выражение времени компиляции. Это особенно полезно в статических условных и шаблонных ограничениях.
import std.stdio; enum Days { sun, mon, tue, wed, thu, fri, sat }; void myFunction(T)(T mytemplate) { static if (is (T == class)) { writeln("This is a class type"); } else static if (is (T == enum)) { writeln("This is an enum type"); } } void main() { Days day; myFunction(day); }
Когда мы скомпилируем и запустим, мы получим следующий вывод:
This is an enum type
D Программирование — Классы и Объекты
Классы — это центральная особенность D-программирования, которая поддерживает объектно-ориентированное программирование и часто называется пользовательскими типами.
Класс используется для указания формы объекта, и он объединяет представление данных и методы для манипулирования этими данными в одном аккуратном пакете. Данные и функции внутри класса называются членами класса.
Определения класса D
Когда вы определяете класс, вы определяете план для типа данных. На самом деле это не определяет какие-либо данные, но определяет, что означает имя класса, то есть, из чего будет состоять объект класса и какие операции могут быть выполнены с таким объектом.
Определение класса начинается с ключевого слова class, за которым следует имя класса; и тело класса, заключенное в пару фигурных скобок. Определение класса должно сопровождаться точкой с запятой или списком объявлений. Например, мы определили тип данных Box, используя ключевое слово class следующим образом:
class Box { public: double length; // Length of a box double breadth; // Breadth of a box double height; // Height of a box }
Ключевое слово public определяет атрибуты доступа членов класса, которые следуют за ним. Доступ к общедоступному члену может осуществляться вне класса в любом месте области видимости объекта класса. Вы также можете указать членов класса как частные или защищенные, что мы обсудим в подразделе.
Определение объектов D
Класс предоставляет чертежи для объектов, поэтому в основном объект создается из класса. Вы объявляете объекты класса точно так же, как вы объявляете переменные базовых типов. Следующие операторы объявляют два объекта класса Box —
Box Box1; // Declare Box1 of type Box Box Box2; // Declare Box2 of type Box
Оба объекта Box1 и Box2 имеют свои собственные копии элементов данных.
Доступ к членам данных
Доступ к открытым данным членов объектов класса можно получить с помощью оператора прямого доступа к члену (.). Давайте попробуем следующий пример, чтобы прояснить ситуацию:
import std.stdio; class Box { public: double length; // Length of a box double breadth; // Breadth of a box double height; // Height of a box } void main() { Box box1 = new Box(); // Declare Box1 of type Box Box box2 = new Box(); // Declare Box2 of type Box double volume = 0.0; // Store the volume of a box here // box 1 specification box1.height = 5.0; box1.length = 6.0; box1.breadth = 7.0; // box 2 specification box2.height = 10.0; box2.length = 12.0; box2.breadth = 13.0; // volume of box 1 volume = box1.height * box1.length * box1.breadth; writeln("Volume of Box1 : ",volume); // volume of box 2 volume = box2.height * box2.length * box2.breadth; writeln("Volume of Box2 : ", volume); }
Когда приведенный выше код компилируется и выполняется, он дает следующий результат —
Volume of Box1 : 210 Volume of Box2 : 1560
Важно отметить, что частные и защищенные члены не могут быть доступны напрямую с помощью оператора прямого доступа (.). Вскоре вы узнаете, как получить доступ к закрытым и защищенным пользователям.
Классы и объекты в D
Пока у вас есть очень общее представление о классах D и объектах. Существуют и другие интересные концепции, относящиеся к D-классам и объектам, которые мы обсудим в различных подразделах, перечисленных ниже.
| Sr.No. | Концепция и описание |
|---|---|
| 1 | Функции члена класса
Функция-член класса — это функция, которая имеет свое определение или свой прототип в определении класса, как и любая другая переменная. |
| 2 | Модификаторы доступа к классу
Член класса может быть определен как открытый, закрытый или защищенный. По умолчанию участники будут считаться закрытыми. |
| 3 | Конструктор и деструктор
Конструктор класса — это специальная функция в классе, которая вызывается при создании нового объекта класса. Деструктор также является специальной функцией, которая вызывается при удалении созданного объекта. |
| 4 | Этот указатель в D
Каждый объект имеет специальный указатель this, который указывает на сам объект. |
| 5 | Указатель на D классы
Указатель на класс выполняется точно так же, как указатель на структуру. На самом деле класс — это просто структура с функциями в нем. |
| 6 | Статические члены класса
И члены-данные, и члены-функции класса могут быть объявлены как статические. |
Функция-член класса — это функция, которая имеет свое определение или свой прототип в определении класса, как и любая другая переменная.
Член класса может быть определен как открытый, закрытый или защищенный. По умолчанию участники будут считаться закрытыми.
Конструктор класса — это специальная функция в классе, которая вызывается при создании нового объекта класса. Деструктор также является специальной функцией, которая вызывается при удалении созданного объекта.
Каждый объект имеет специальный указатель this, который указывает на сам объект.
Указатель на класс выполняется точно так же, как указатель на структуру. На самом деле класс — это просто структура с функциями в нем.
И члены-данные, и члены-функции класса могут быть объявлены как статические.
D Программирование — Наследование
Одним из наиболее важных понятий в объектно-ориентированном программировании является наследование. Наследование позволяет определять класс в терминах другого класса, что облегчает создание и поддержку приложения. Это также дает возможность повторно использовать функциональность кода и быстрое время реализации.
При создании класса, вместо того, чтобы писать совершенно новые члены-данные и функции-члены, программист может указать, что новый класс должен наследовать члены существующего класса. Этот существующий класс называется базовым классом, а новый класс называется производным классом.
Идея наследования реализует отношения. Например, млекопитающее IS-A животное, собака IS-A млекопитающее, следовательно, собака IS-A животное, а также и так далее.
Базовые классы и производные классы в D
Класс может быть производным от нескольких классов, что означает, что он может наследовать данные и функции от нескольких базовых классов. Чтобы определить производный класс, мы используем список деривации классов, чтобы указать базовый класс (ы). Список деривации классов называет один или несколько базовых классов и имеет вид —
class derived-class: base-class
Рассмотрим базовый класс Shape и его производный класс Rectangle следующим образом:
import std.stdio; // Base class class Shape { public: void setWidth(int w) { width = w; } void setHeight(int h) { height = h; } protected: int width; int height; } // Derived class class Rectangle: Shape { public: int getArea() { return (width * height); } } void main() { Rectangle Rect = new Rectangle(); Rect.setWidth(5); Rect.setHeight(7); // Print the area of the object. writeln("Total area: ", Rect.getArea()); }
Когда приведенный выше код компилируется и выполняется, он дает следующий результат —
Total area: 35
Контроль доступа и наследование
Производный класс может получить доступ ко всем не закрытым членам своего базового класса. Таким образом, члены базового класса, которые не должны быть доступны для функций-членов производных классов, должны быть объявлены закрытыми в базовом классе.
Производный класс наследует все методы базового класса со следующими исключениями:
- Конструкторы, деструкторы и конструкторы копирования базового класса.
- Перегруженные операторы базового класса.
Многоуровневое наследование
Наследование может быть нескольких уровней, и это показано в следующем примере.
import std.stdio; // Base class class Shape { public: void setWidth(int w) { width = w; } void setHeight(int h) { height = h; } protected: int width; int height; } // Derived class class Rectangle: Shape { public: int getArea() { return (width * height); } } class Square: Rectangle { this(int side) { this.setWidth(side); this.setHeight(side); } } void main() { Square square = new Square(13); // Print the area of the object. writeln("Total area: ", square.getArea()); }
Когда приведенный выше код компилируется и выполняется, он дает следующий результат —
Total area: 169
D Программирование — Перегрузка
D позволяет вам указать более одного определения для имени функции или оператора в одной и той же области видимости, что называется перегрузкой функций и перегрузкой операторов соответственно.
Перегруженное объявление — это объявление, которое было объявлено с тем же именем, что и предыдущее объявление в той же области, за исключением того, что оба объявления имеют разные аргументы и, очевидно, разное определение (реализацию).
Когда вы вызываете перегруженную функцию или оператор , компилятор определяет наиболее подходящее определение для использования, сравнивая типы аргументов, которые вы использовали для вызова функции или оператора, с типами параметров, указанными в определениях. Процесс выбора наиболее подходящей перегруженной функции или оператора называется разрешением перегрузки. ,
Перегрузка функций
Вы можете иметь несколько определений для одного и того же имени функции в одной и той же области. Определение функции должно отличаться друг от друга типами и / или количеством аргументов в списке аргументов. Вы не можете перегружать объявления функций, которые отличаются только типом возвращаемого значения.
пример
В следующем примере одна и та же функция print () используется для печати разных типов данных.
import std.stdio; import std.string; class printData { public: void print(int i) { writeln("Printing int: ",i); } void print(double f) { writeln("Printing float: ",f ); } void print(string s) { writeln("Printing string: ",s); } }; void main() { printData pd = new printData(); // Call print to print integer pd.print(5); // Call print to print float pd.print(500.263); // Call print to print character pd.print("Hello D"); }
Когда приведенный выше код компилируется и выполняется, он дает следующий результат —
Printing int: 5 Printing float: 500.263 Printing string: Hello D
Перегрузка оператора
Вы можете переопределить или перегрузить большинство встроенных операторов, доступных в D. Таким образом, программист может также использовать операторы с пользовательскими типами.
Операторы могут быть перегружены с использованием строки op, за которой следует Add, Sub и т. Д., В зависимости от оператора, который перегружается. Мы можем перегрузить оператор +, чтобы добавить два поля, как показано ниже.
Box opAdd(Box b) { Box box = new Box(); box.length = this.length + b.length; box.breadth = this.breadth + b.breadth; box.height = this.height + b.height; return box; }
В следующем примере показана концепция перегрузки операторов с использованием функции-члена. Здесь объект передается в качестве аргумента, свойства которого доступны с использованием этого объекта. К объекту, который вызывает этот оператор, можно получить доступ, используя этот оператор, как объяснено ниже —
import std.stdio; class Box { public: double getVolume() { return length * breadth * height; } void setLength( double len ) { length = len; } void setBreadth( double bre ) { breadth = bre; } void setHeight( double hei ) { height = hei; } Box opAdd(Box b) { Box box = new Box(); box.length = this.length + b.length; box.breadth = this.breadth + b.breadth; box.height = this.height + b.height; return box; } private: double length; // Length of a box double breadth; // Breadth of a box double height; // Height of a box }; // Main function for the program void main( ) { Box box1 = new Box(); // Declare box1 of type Box Box box2 = new Box(); // Declare box2 of type Box Box box3 = new Box(); // Declare box3 of type Box double volume = 0.0; // Store the volume of a box here // box 1 specification box1.setLength(6.0); box1.setBreadth(7.0); box1.setHeight(5.0); // box 2 specification box2.setLength(12.0); box2.setBreadth(13.0); box2.setHeight(10.0); // volume of box 1 volume = box1.getVolume(); writeln("Volume of Box1 : ", volume); // volume of box 2 volume = box2.getVolume(); writeln("Volume of Box2 : ", volume); // Add two object as follows: box3 = box1 + box2; // volume of box 3 volume = box3.getVolume(); writeln("Volume of Box3 : ", volume); }
Когда приведенный выше код компилируется и выполняется, он дает следующий результат —
Volume of Box1 : 210 Volume of Box2 : 1560 Volume of Box3 : 5400
Типы перегрузки операторов
В основном, есть три типа перегрузки операторов, как указано ниже.
| Sr.No. | Типы перегрузки |
|---|---|
| 1 | Перегрузка унарных операторов |
| 2 | Перегрузка бинарных операторов |
| 3 | Перегрузка операторов сравнения |
D Программирование — Инкапсуляция
Все программы D состоят из следующих двух основных элементов:
-
Программные операторы (код) — это часть программы, которая выполняет действия, и они называются функциями.
-
Данные программы — это информация о программе, на которую влияют функции программы.
Программные операторы (код) — это часть программы, которая выполняет действия, и они называются функциями.
Данные программы — это информация о программе, на которую влияют функции программы.
Инкапсуляция — это концепция объектно-ориентированного программирования, которая связывает данные и функции, которые манипулируют данными, и защищает их от внешнего вмешательства и неправильного использования. Инкапсуляция данных привела к важной ООП-концепции сокрытия данных .
Инкапсуляция данных — это механизм связывания данных, а функции, которые их используют, и абстракция данных — это механизм раскрытия только интерфейсов и скрытия деталей реализации от пользователя.
D поддерживает свойства инкапсуляции и сокрытия данных посредством создания пользовательских типов, называемых классами . Мы уже изучали, что класс может содержать частных , защищенных и открытых членов. По умолчанию все элементы, определенные в классе, являются частными. Например —
class Box { public: double getVolume() { return length * breadth * height; } private: double length; // Length of a box double breadth; // Breadth of a box double height; // Height of a box };
Переменные длина, ширина и высота являются частными . Это означает, что к ним могут получить доступ только другие члены класса Box, а не любая другая часть вашей программы. Это один из способов инкапсуляции.
Чтобы сделать части класса общедоступными (то есть доступными для других частей вашей программы), вы должны объявить их после открытого ключевого слова. Все переменные или функции, определенные после открытого спецификатора, доступны всем другим функциям в вашей программе.
Создание одного класса другом другого раскрывает детали реализации и уменьшает инкапсуляцию. Идеально хранить как можно больше деталей каждого класса скрытыми от всех других классов.
Инкапсуляция данных в D
Любая D-программа, в которой вы реализуете класс с открытыми и закрытыми членами, является примером инкапсуляции данных и абстракции данных. Рассмотрим следующий пример —
пример
import std.stdio; class Adder { public: // constructor this(int i = 0) { total = i; } // interface to outside world void addNum(int number) { total += number; } // interface to outside world int getTotal() { return total; }; private: // hidden data from outside world int total; } void main( ) { Adder a = new Adder(); a.addNum(10); a.addNum(20); a.addNum(30); writeln("Total ",a.getTotal()); }
Когда приведенный выше код компилируется и выполняется, он дает следующий результат —
Total 60
Выше класс складывает числа вместе и возвращает сумму. Открытые члены addNum и getTotal являются интерфейсами с внешним миром, и пользователь должен знать их, чтобы использовать класс. Общее число закрытых членов — это то, что скрыто от внешнего мира, но необходимо для правильной работы класса.
Стратегия проектирования классов в D
Большинство из нас с помощью горького опыта научились делать членов класса закрытыми по умолчанию, если только нам действительно не нужно их разоблачать. Это просто хорошая инкапсуляция .
Эта мудрость чаще всего применяется к элементам данных, но она в равной степени относится ко всем элементам, включая виртуальные функции.
D Программирование — Интерфейсы
Интерфейс — это способ заставить наследуемые классы реализовать определенные функции или переменные. Функции не должны быть реализованы в интерфейсе, потому что они всегда реализуются в классах, которые наследуются от интерфейса.
Интерфейс создается с использованием ключевого слова interface вместо ключевого слова class, хотя они во многом похожи. Если вы хотите наследовать от интерфейса, а класс уже наследует от другого класса, тогда вам нужно разделить имя класса и имя интерфейса запятой.
Давайте посмотрим на простой пример, который объясняет использование интерфейса.
пример
import std.stdio; // Base class interface Shape { public: void setWidth(int w); void setHeight(int h); } // Derived class class Rectangle: Shape { int width; int height; public: void setWidth(int w) { width = w; } void setHeight(int h) { height = h; } int getArea() { return (width * height); } } void main() { Rectangle Rect = new Rectangle(); Rect.setWidth(5); Rect.setHeight(7); // Print the area of the object. writeln("Total area: ", Rect.getArea()); }
Когда приведенный выше код компилируется и выполняется, он дает следующий результат —
Total area: 35
Интерфейс с конечными и статическими функциями в D
Интерфейс может иметь конечный и статический метод, для которого определения должны быть включены в сам интерфейс. Эти функции не могут быть переопределены производным классом. Простой пример показан ниже.
пример
import std.stdio; // Base class interface Shape { public: void setWidth(int w); void setHeight(int h); static void myfunction1() { writeln("This is a static method"); } final void myfunction2() { writeln("This is a final method"); } } // Derived class class Rectangle: Shape { int width; int height; public: void setWidth(int w) { width = w; } void setHeight(int h) { height = h; } int getArea() { return (width * height); } } void main() { Rectangle rect = new Rectangle(); rect.setWidth(5); rect.setHeight(7); // Print the area of the object. writeln("Total area: ", rect.getArea()); rect.myfunction1(); rect.myfunction2(); }
Когда приведенный выше код компилируется и выполняется, он дает следующий результат —
Total area: 35 This is a static method This is a final method
D Программирование — Абстрактные классы
Абстракция относится к способности сделать класс абстрактным в ООП. Абстрактный класс — это класс, который не может быть создан. Все остальные функциональные возможности класса все еще существуют, и к его полям, методам и конструкторам обращаются одинаково. Вы просто не можете создать экземпляр абстрактного класса.
Если класс является абстрактным и не может быть создан, класс не имеет большого применения, если он не является подклассом. Как правило, именно так создаются абстрактные классы на этапе проектирования. Родительский класс содержит общие функциональные возможности коллекции дочерних классов, но сам родительский класс слишком абстрактный, чтобы использовать его самостоятельно.
Использование абстрактного класса в D
Используйте ключевое слово abstract для объявления абстрактного класса. Ключевое слово появляется в объявлении класса где-то перед ключевым словом класса. Ниже приведен пример того, как абстрактный класс может наследоваться и использоваться.
пример
import std.stdio; import std.string; import std.datetime; abstract class Person { int birthYear, birthDay, birthMonth; string name; int getAge() { SysTime sysTime = Clock.currTime(); return sysTime.year - birthYear; } } class Employee : Person { int empID; } void main() { Employee emp = new Employee(); emp.empID = 101; emp.birthYear = 1980; emp.birthDay = 10; emp.birthMonth = 10; emp.name = "Emp1"; writeln(emp.name); writeln(emp.getAge); }
Когда мы скомпилируем и запустим вышеуказанную программу, мы получим следующий вывод.
Emp1 37
Абстрактные функции
Подобно функциям, классы также могут быть абстрактными. Реализация такой функции не дана в ее классе, но должна быть предоставлена в классе, который наследует класс с абстрактной функцией. Приведенный выше пример обновляется с помощью абстрактной функции.
пример
import std.stdio; import std.string; import std.datetime; abstract class Person { int birthYear, birthDay, birthMonth; string name; int getAge() { SysTime sysTime = Clock.currTime(); return sysTime.year - birthYear; } abstract void print(); } class Employee : Person { int empID; override void print() { writeln("The employee details are as follows:"); writeln("Emp ID: ", this.empID); writeln("Emp Name: ", this.name); writeln("Age: ",this.getAge); } } void main() { Employee emp = new Employee(); emp.empID = 101; emp.birthYear = 1980; emp.birthDay = 10; emp.birthMonth = 10; emp.name = "Emp1"; emp.print(); }
Когда мы скомпилируем и запустим вышеуказанную программу, мы получим следующий вывод.