Кибана — Обзор
Kibana — это инструмент для визуализации на основе браузера с открытым исходным кодом, который в основном используется для анализа большого объема журналов в виде линейного графика, гистограммы, круговых диаграмм, тепловых карт, карт регионов, координатных карт, датчиков, целей, временных шкал и т. Д. Визуализация делает это Легко предсказать или увидеть изменения в тенденциях ошибок или других значительных событий источника ввода. Kibana работает синхронно с Elasticsearch и Logstash, которые вместе образуют так называемый стек ELK .
Что такое стек ELK?
ELK означает Elasticsearch, Logstash и Kibana. ELK является одной из популярных платформ управления журналом, используемой во всем мире для анализа журналов. В стеке ELK Logstash извлекает данные регистрации или другие события из разных источников ввода. Он обрабатывает события, а затем сохраняет их в Elasticsearch.
Kibana — это инструмент визуализации, который обращается к журналам Elasticsearch и может отображать их пользователю в виде линейного графика, гистограммы, круговых диаграмм и т. Д.
Основной поток ELK Stack показан на рисунке здесь —
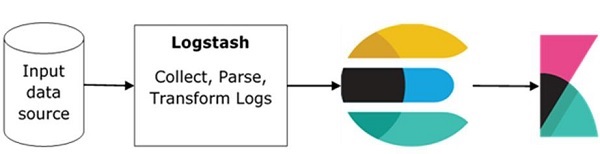
Logstash отвечает за сбор данных из всех удаленных источников, где хранятся журналы, и отправляет их в Elasticsearch.
Elasticsearch действует как база данных, в которой собираются данные, и Kibana использует данные из Elasticsearch для представления данных пользователю в виде гистограмм, круговых диаграмм, тепловых карт, как показано ниже —
Он показывает данные в режиме реального времени, например, днем или часом для пользователя. Интерфейс Kibana удобен для пользователя и очень прост для начинающего.
Особенности Кибана
Kibana предлагает своим пользователям следующие функции —
Визуализация
У Kibana есть много способов для простой визуализации данных. Некоторые из них обычно используются: вертикальная гистограмма, горизонтальная гистограмма, круговая диаграмма, линейный график, тепловая карта и т. Д.
Приборная доска
Когда у нас есть готовые визуализации, все они могут быть размещены на одной доске — панели инструментов. Наблюдение за различными разделами вместе дает вам четкое общее представление о том, что именно происходит.
Dev Tools
Вы можете работать со своими индексами, используя инструменты разработки. Начинающие могут добавлять фиктивные индексы из инструментов разработчика, а также добавлять, обновлять, удалять данные и использовать индексы для создания визуализации.
Отчеты
Все данные в форме визуализации и панели мониторинга могут быть преобразованы в отчеты (формат CSV), встроены в код или в виде URL-адресов для совместного использования с другими.
Фильтры и поисковый запрос
Вы можете использовать фильтры и поисковые запросы, чтобы получить необходимую информацию для конкретного ввода из панели мониторинга или инструмента визуализации.
Плагины
Вы можете добавить сторонние плагины, чтобы добавить новую визуализацию или другое дополнение пользовательского интерфейса в Kibana.
Карты координат и регионов
Карта координат и региона в Кибане помогает отображать визуализацию на географической карте, обеспечивая реалистичное представление данных.
Timelion
Timelion, также называемый временной шкалой, является еще одним инструментом визуализации, который в основном используется для анализа данных на основе времени. Для работы с временной шкалой нам нужно использовать простой язык выражений, который помогает нам подключаться к индексу, а также выполнять вычисления на данных для получения необходимых результатов. Это помогает больше в сравнении данных с предыдущим циклом по неделям, месяцам и т. Д.
холст
Холст — еще одна мощная особенность в Кибане. Используя визуализацию холста, вы можете представлять свои данные в различных цветовых сочетаниях, формах, текстах, на нескольких страницах, которые обычно называются рабочими панелями.
Преимущества Кибана
Kibana предлагает следующие преимущества для своих пользователей —
-
Содержит инструмент визуализации на основе браузера с открытым исходным кодом, который в основном используется для анализа большого объема журналов в виде линейного графика, гистограммы, круговых диаграмм, тепловых карт и т. Д.
-
Просто и легко для начинающих, чтобы понять.
-
Простота преобразования визуализации и панели инструментов в отчеты.
-
Визуализация холста помогает легко анализировать сложные данные.
-
Визуализация Timelion в Kibana помогает сравнивать данные в обратном направлении, чтобы лучше понять производительность.
Содержит инструмент визуализации на основе браузера с открытым исходным кодом, который в основном используется для анализа большого объема журналов в виде линейного графика, гистограммы, круговых диаграмм, тепловых карт и т. Д.
Просто и легко для начинающих, чтобы понять.
Простота преобразования визуализации и панели инструментов в отчеты.
Визуализация холста помогает легко анализировать сложные данные.
Визуализация Timelion в Kibana помогает сравнивать данные в обратном направлении, чтобы лучше понять производительность.
Недостатки Кибаны
-
Добавление плагинов в Kibana может быть очень утомительным, если есть несоответствие версий.
-
Вы склонны сталкиваться с проблемами, когда хотите обновить старую версию до новой.
Добавление плагинов в Kibana может быть очень утомительным, если есть несоответствие версий.
Вы склонны сталкиваться с проблемами, когда хотите обновить старую версию до новой.
Кибана — Настройка среды
Чтобы начать работать с Kibana, нам нужно установить Logstash, Elasticsearch и Kibana. В этой главе мы попытаемся разобраться в установке стека ELK здесь.
Мы обсудили бы следующие установки здесь —
- Установка Elasticsearch
- Установка Logstash
- Кибана Установка
Установка Elasticsearch
Подробная документация по Elasticsearch существует в нашей библиотеке. Вы можете проверить здесь для установки эластичного поиска . Чтобы установить Elasticsearch, вам нужно будет выполнить шаги, указанные в руководстве.
После завершения установки запустите сервер эластичного поиска следующим образом:
Шаг 1
Для Windows
> cd kibanaproject/elasticsearch-6.5.4/elasticsearch-6.5.4/bin > elasticsearch
Обратите внимание, что для пользователя Windows переменная JAVA_HOME должна быть установлена в путь java jdk.
Для линукса
$ cd kibanaproject/elasticsearch-6.5.4/elasticsearch-6.5.4/bin $ elasticsearch
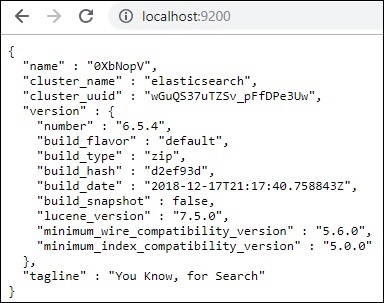
Порт по умолчанию дляasticsearch — 9200. Как только вы это сделаете, вы можете проверить эластичный поиск на порту 9200 на локальном хосте http: // localhost: 9200 /, как показано ниже —
Установка Logstash
Для установки Logstash, следуйте этой установке эластичного поиска, которая уже существует в нашей библиотеке.
Кибана Установка
Перейти на официальный сайт Kibana — https://www.elastic.co/products/kibana
Нажмите на ссылку для скачивания в правом верхнем углу, и она отобразит экран следующим образом:
Нажмите кнопку Загрузить для Kibana. Обратите внимание, что для работы с Kibana нам нужна 64-битная машина, и она не будет работать с 32-битной.
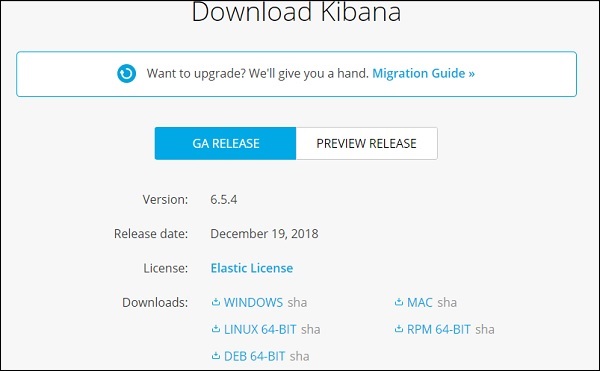
В этом уроке мы будем использовать Kibana версии 6. Вариант загрузки доступен для Windows, Mac и Linux. Вы можете скачать по вашему выбору.
Создайте папку и распакуйте загрузки tar / zip для kibana. Мы собираемся работать с примерами данных, загруженных в эластичный поиск. Итак, пока давайте посмотрим, как начать эластичный поиск и кибану. Для этого перейдите в папку, в которую распакован Kibana.
Для Windows
> cd kibanaproject/kibana-6.5.4/kibana-6.5.4/bin > kibana
Для линукса
$ cd kibanaproject/kibana-6.5.4/kibana-6.5.4/bin $ kibana
После запуска Kibana пользователь может увидеть следующий экран:
Как только вы увидите сигнал готовности в консоли, вы можете открыть Kibana в браузере, используя http: // localhost: 5601 / . Порт по умолчанию, на котором доступен kibana, — 5601.
Пользовательский интерфейс Kibana, как показано здесь —
В нашей следующей главе мы узнаем, как использовать пользовательский интерфейс Kibana. Чтобы узнать версию Kibana для пользовательского интерфейса Kibana, перейдите на вкладку «Управление» с левой стороны, и она покажет вам версию Kibana, которую мы используем в настоящее время.
Кибана — Введение в стек лося
Kibana — это инструмент визуализации с открытым исходным кодом, который в основном используется для анализа большого объема журналов в виде линейных графиков, гистограмм, круговых диаграмм, тепловых карт и т. Д. Kibana работает синхронно с Elasticsearch и Logstash, которые вместе образуют так называемый стек ELK .
ELK означает Elasticsearch, Logstash и Kibana. ELK является одной из популярных платформ управления журналом, используемой во всем мире для анализа журналов.
В стеке ELK —
-
Logstash извлекает данные регистрации или другие события из разных источников ввода. Он обрабатывает события, а затем сохраняет его в Elasticsearch.
-
Kibana — это инструмент визуализации, который обращается к журналам Elasticsearch и может отображать их пользователю в виде линейного графика, гистограммы, круговых диаграмм и т. Д.
Logstash извлекает данные регистрации или другие события из разных источников ввода. Он обрабатывает события, а затем сохраняет его в Elasticsearch.
Kibana — это инструмент визуализации, который обращается к журналам Elasticsearch и может отображать их пользователю в виде линейного графика, гистограммы, круговых диаграмм и т. Д.
В этом руководстве мы будем тесно сотрудничать с Kibana и Elasticsearch и визуализировать данные в различных формах.
В этой главе давайте разберемся, как работать вместе со стеком ELK. Кроме того, вы также увидите, как
- Загрузите данные CSV из Logstash в Elasticsearch.
- Используйте индексы от Elasticsearch в Кибане.
Загрузить данные CSV из Logstash в Elasticsearch
Мы собираемся использовать данные CSV для загрузки данных с помощью Logstash в Elasticsearch. Чтобы работать над анализом данных, мы можем получить данные с сайта kaggle.com. На сайт Kaggle.com загружаются все типы данных, и пользователи могут использовать его для анализа данных.
Мы взяли данные страны.csv здесь: https://www.kaggle.com/fernandol/countries-of-the-world . Вы можете скачать CSV-файл и использовать его.
Файл CSV, который мы собираемся использовать, имеет следующие детали.
Имя файла — countrydata.csv
Колонки — «Страна», «Регион», «Население», «Район»
Вы также можете создать фиктивный CSV-файл и использовать его. Мы будем использовать logstash для выгрузки этих данных из странdata.csv вasticsearch.
Запустите эластичный поиск и Kibana в своем терминале и продолжайте работать. Мы должны создать файл конфигурации для logstash, который будет содержать подробную информацию о столбцах файла CSV, а также другие детали, как показано в файле logstash-config, приведенном ниже —
input { file { path => "C:/kibanaproject/countriesdata.csv" start_position => "beginning" sincedb_path => "NUL" } } filter { csv { separator => "," columns => ["Country","Region","Population","Area"] } mutate {convert => ["Population", "integer"]} mutate {convert => ["Area", "integer"]} } output { elasticsearch { hosts => ["localhost:9200"] => "countriesdata-%{+dd.MM.YYYY}" } stdout {codec => json_lines } }
В конфигурационном файле мы создали 3 компонента —
вход
Нам нужно указать путь к входному файлу, который в нашем случае является CSV-файлом. Путь, где хранится CSV-файл, задается в поле пути.
Фильтр
Будет иметь компонент csv с разделителем, который в нашем случае является запятой, а также столбцы, доступные для нашего файла csv. Поскольку logstash рассматривает все данные, поступающие в виде строки, в случае, если мы хотим, чтобы любой столбец использовался как целое число, значение float должно быть указано с помощью mutate, как показано выше.
Выход
Для вывода нам нужно указать, куда нам нужно поместить данные. Здесь, в нашем случае мы используем эластичный поиск. Данные, которые должны быть переданы вasticsearch — это хосты, на которых он работает, мы упомянули их как localhost. Следующее поле — это индекс, которому мы дали название страны -currentdate. Мы должны использовать тот же индекс в Kibana после обновления данных в Elasticsearch.
Сохраните указанный выше файл конфигурации как logstash_countries.config . Обратите внимание, что нам нужно указать путь к этой конфигурации для команды logstash на следующем шаге.
Чтобы загрузить данные из файла csv вasticsearch, нам нужно запустить серверasticsearch —
Теперь запустите http: // localhost: 9200 в браузере, чтобы подтвердить, успешно ли работаетasticsearch.
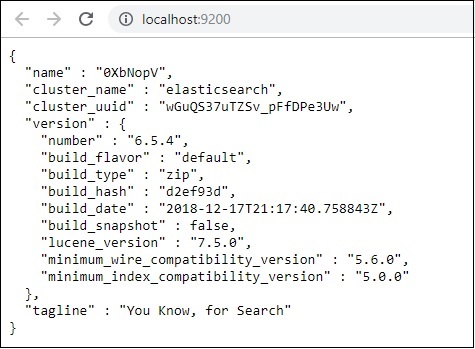
У нас работает эластичный поиск. Теперь перейдите по пути, где установлен logstash, и выполните следующую команду, чтобы загрузить данные вasticsearch.
> logstash -f logstash_countries.conf
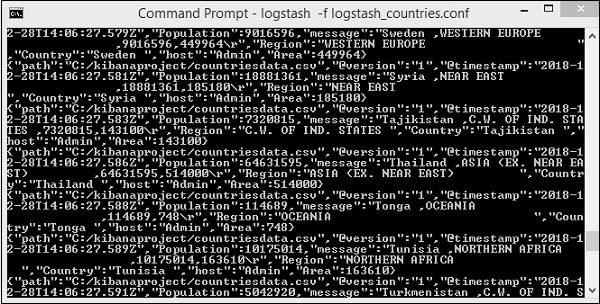
На приведенном выше экране показана загрузка данных из файла CSV в Elasticsearch. Чтобы узнать, есть ли у нас индекс, созданный в Elasticsearch, мы можем проверить то же самое следующим образом:
Мы можем видеть индекс странданных-28.12.2018, созданный, как показано выше.

Детали индекса — страны-28.12.2018 выглядит следующим образом —
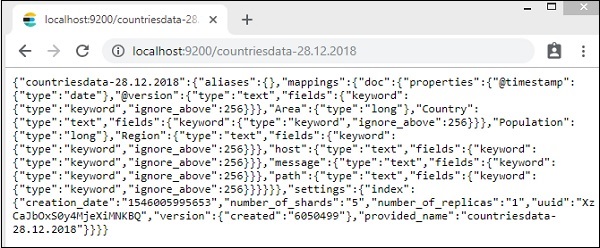
Обратите внимание, что детали сопоставления со свойствами создаются при загрузке данных из logstash вasticsearch.
Использовать данные из Elasticsearch в Кибане
В настоящее время Kibana работает на локальном хосте, порт 5601 — http: // localhost: 5601 . Пользовательский интерфейс Кибана показан здесь —
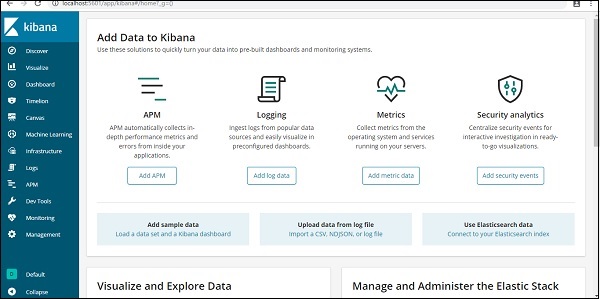
Обратите внимание, что у нас уже есть Kibana, подключенный к Elasticsearch, и мы должны увидеть индекс стран-28.12.2018 внутри Kibana.
В пользовательском интерфейсе Kibana выберите пункт «Меню управления» слева.
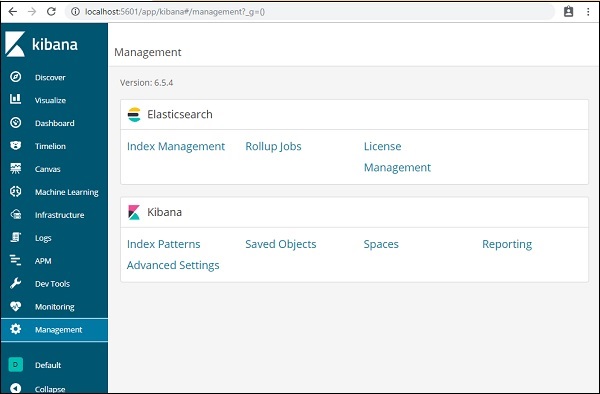
Теперь нажмите Управление индексами —
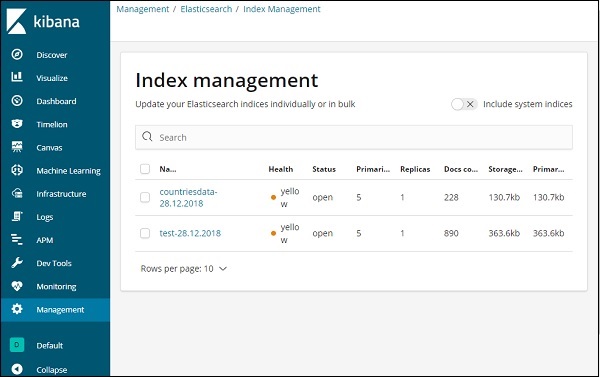
Индексы, присутствующие в Elasticsearch, отображаются в управлении индексами. Индекс, который мы собираемся использовать в Кибане, это countrydata-28.12.2018.
Таким образом, поскольку у нас уже есть индекс эластичного поиска в Кибане, следующий поймет, как использовать индекс в Кибане для визуализации данных в виде круговой диаграммы, гистограммы, линейного графика и т. Д.
Кибана — загрузка данных примера
Мы видели, как загружать данные из logstash вasticsearch. Мы будем загружать данные, используя logstash иasticsearch здесь. Но о данных, которые имеют поля даты, долготы и широты, которые нам нужно использовать, мы узнаем в следующих главах. Мы также увидим, как загружать данные непосредственно в Kibana, если у нас нет файла CSV.
В этой главе мы рассмотрим следующие темы:
- Использование Logstash для загрузки данных с полями даты, долготы и широты в Elasticsearch
- Использование инструментов Dev для загрузки больших объемов данных
Использование загрузки Logstash для данных, имеющих поля в Elasticsearch
Мы собираемся использовать данные в форме CSV, и то же самое взято с Kaggle.com, который имеет дело с данными, которые вы можете использовать для анализа.
Данные по домашним медицинским визитам, которые будут здесь использованы, взяты с сайта Kaggle.com.
Ниже приведены поля, доступные для файла CSV —
["Visit_Status","Time_Delay","City","City_id","Patient_Age","Zipcode","Latitude","Longitude", "Pathology","Visiting_Date","Id_type","Id_personal","Number_Home_Visits","Is_Patient_Minor","Geo_point"]
Home_visits.csv выглядит следующим образом —
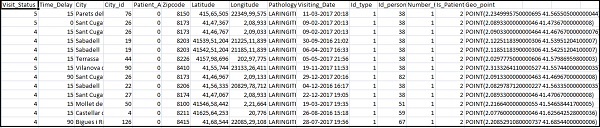
Ниже приведен файл conf, который будет использоваться с logstash:
input { file { path => "C:/kibanaproject/home_visits.csv" start_position => "beginning" sincedb_path => "NUL" } } filter { csv { separator => "," columns => ["Visit_Status","Time_Delay","City","City_id","Patient_Age", "Zipcode","Latitude","Longitude","Pathology","Visiting_Date", "Id_type","Id_personal","Number_Home_Visits","Is_Patient_Minor","Geo_point"] } date { match => ["Visiting_Date","dd-MM-YYYY HH:mm"] target => "Visiting_Date" } mutate {convert => ["Number_Home_Visits", "integer"]} mutate {convert => ["City_id", "integer"]} mutate {convert => ["Id_personal", "integer"]} mutate {convert => ["Id_type", "integer"]} mutate {convert => ["Zipcode", "integer"]} mutate {convert => ["Patient_Age", "integer"]} mutate { convert => { "Longitude" => "float" } convert => { "Latitude" => "float" } } mutate { rename => { "Longitude" => "[location][lon]" "Latitude" => "[location][lat]" } } } output { elasticsearch { hosts => ["localhost:9200"] index => "medicalvisits-%{+dd.MM.YYYY}" } stdout {codec => json_lines } }
По умолчанию logstash рассматривает все, что будет загружено в эластичный поиск, как строку. Если в вашем CSV-файле есть поле даты, вам необходимо выполнить следующее, чтобы получить формат даты.
Для поля даты —
date { match => ["Visiting_Date","dd-MM-YYYY HH:mm"] target => "Visiting_Date" }
В случае географического местоположения эластичный поиск понимает так же, как —
"location": { "lat":41.565505000000044, "lon": 2.2349995750000695 }
Таким образом, мы должны убедиться, что у нас есть долгота и широта в том формате, в котором она нужна. Итак, сначала нам нужно преобразовать долготу и широту в float, а затем переименовать ее, чтобы она была доступна как часть объекта location json с lat и lon . Код для того же самого показан здесь —
mutate { convert => { "Longitude" => "float" } convert => { "Latitude" => "float" } } mutate { rename => { "Longitude" => "[location][lon]" "Latitude" => "[location][lat]" } }
Для преобразования полей в целые числа используйте следующий код —
mutate {convert => ["Number_Home_Visits", "integer"]} mutate {convert => ["City_id", "integer"]} mutate {convert => ["Id_personal", "integer"]} mutate {convert => ["Id_type", "integer"]} mutate {convert => ["Zipcode", "integer"]} mutate {convert => ["Patient_Age", "integer"]}
После того, как с полями позаботятся, выполните следующую команду для загрузки данных вasticsearch —
- Зайдите в каталог Logstash bin и выполните следующую команду.
logstash -f logstash_homevisists.conf
- Когда вы закончите, вы должны увидеть индекс, упомянутый в файле conf logstash вasticsearch, как показано ниже —
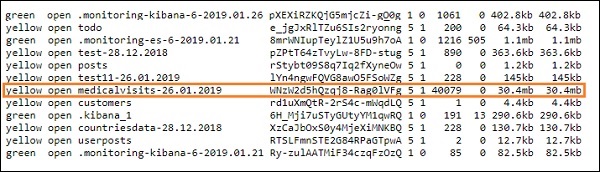
Теперь мы можем создать шаблон индекса для загруженного выше индекса и использовать его для создания визуализации.
Использование Dev Tools для загрузки групповых данных
Мы собираемся использовать Dev Tools из Kibana UI. Dev Tools полезен для загрузки данных в Elasticsearch без использования Logstash. Мы можем публиковать, размещать, удалять, искать нужные нам данные в Kibana, используя Dev Tools.
В этом разделе мы попытаемся загрузить примеры данных в самой Kibana. Мы можем использовать его, чтобы попрактиковаться с образцами данных и поиграть с функциями Kibana, чтобы получить хорошее представление о Kibana.
Давайте возьмем данные json из следующего URL и загрузим их в Kibana. Точно так же вы можете попробовать любые образцы данных JSON, которые будут загружены в Kibana.
Перед тем, как мы начнем загружать пример данных, нам нужно иметь данные json с индексами, которые будут использоваться вasticsearch. Когда мы загружаем его с помощью logstash, logstash заботится о добавлении индексов, и пользователю не нужно беспокоиться об индексах, которые требуются эластичным поиском.
Нормальные данные Json
[
{"type":"act","line_id":1,"play_name":"Henry IV",
"speech_number":"","line_number":"","speaker":"","text_entry":"ACT I"},
{"type":"scene","line_id":2,"play_name":"Henry IV",
"speech_number":"","line_number":"","speaker":"","text_entry":"SCENE I.London. The palace."},
{"type":"line","line_id":3,"play_name":"Henry IV",
"speech_number":"","line_number":"","speaker":"","text_entry":
"Enter KING HENRY, LORD JOHN OF LANCASTER, the
EARL of WESTMORELAND, SIR WALTER BLUNT, and others"}
]
Код json, используемый в Kibana, должен быть проиндексирован следующим образом:
{"index":{"_index":"shakespeare","_id":0}}
{"type":"act","line_id":1,"play_name":"Henry IV",
"speech_number":"","line_number":"","speaker":"","text_entry":"ACT I"}
{"index":{"_index":"shakespeare","_id":1}}
{"type":"scene","line_id":2,"play_name":"Henry IV",
"speech_number":"","line_number":"","speaker":"",
"text_entry":"SCENE I. London. The palace."}
{"index":{"_index":"shakespeare","_id":2}}
{"type":"line","line_id":3,"play_name":"Henry IV",
"speech_number":"","line_number":"","speaker":"","text_entry":
"Enter KING HENRY, LORD JOHN OF LANCASTER, the EARL
of WESTMORELAND, SIR WALTER BLUNT, and others"}
Обратите внимание, что в jsonfile есть дополнительные данные — {«index»: {«_ index»: «nameofindex», «_ id»: key}} .
Чтобы преобразовать любой пример json-файла, совместимого сasticsearch, здесь у нас есть небольшой код в php, который выведет json-файл, предоставленный в формате, который требуетсявести-поиск —
PHP код
<?php $myfile = fopen("todo.json", "r") or die("Unable to open file!"); // your json file here $alldata = fread($myfile,filesize("todo.json")); fclose($myfile); $farray = json_decode($alldata); $afinalarray = []; $index_name = "todo"; $i=0; $myfile1 = fopen("todonewfile.json", "w") or die("Unable to open file!"); // writes a new file to be used in kibana dev tool foreach ($farray as $a => $value) { $_index = json_decode('{"index": {"_index": "'.$index_name.'", "_id": "'.$i.'"}}'); fwrite($myfile1, json_encode($_index)); fwrite($myfile1, "\n"); fwrite($myfile1, json_encode($value)); fwrite($myfile1, "\n"); $i++; } ?>
Мы взяли jdo-файл todo с https://jsonplaceholder.typicode.com/todos и используем php-код для преобразования в формат, который нам нужен для загрузки в Kibana.
Чтобы загрузить пример данных, откройте вкладку dev tools, как показано ниже —
Теперь мы будем использовать консоль, как показано выше. Мы возьмем данные json, которые мы получили после запуска через php-код.
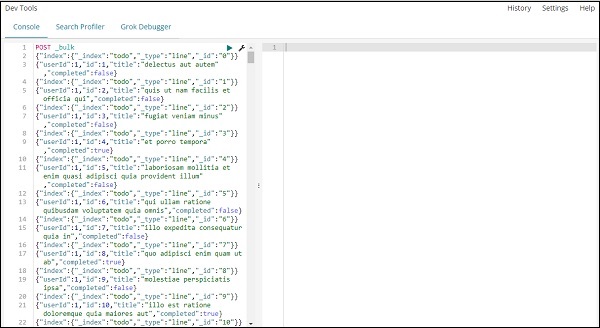
Команда, которая будет использоваться в инструментах разработки для загрузки данных JSON, —
POST _bulk
Обратите внимание, что имя индекса, который мы создаем, — todo .
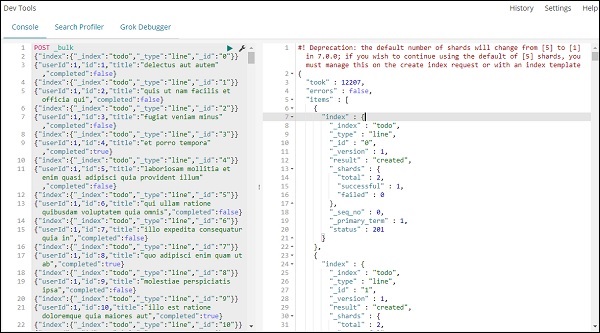
После того, как вы нажмете зеленую кнопку, данные загружены, вы можете проверить, создан ли индекс или нет вasticsearch следующим образом:
Вы можете проверить то же самое в инструментах разработчика, как показано ниже:
Команда —
GET /_cat/indices
Если вы хотите найти что-то в своем индексе: todo, вы можете сделать это, как показано ниже —
Команда в инструменте разработки
GET /todo/_search
Результат поиска выше как показано ниже —
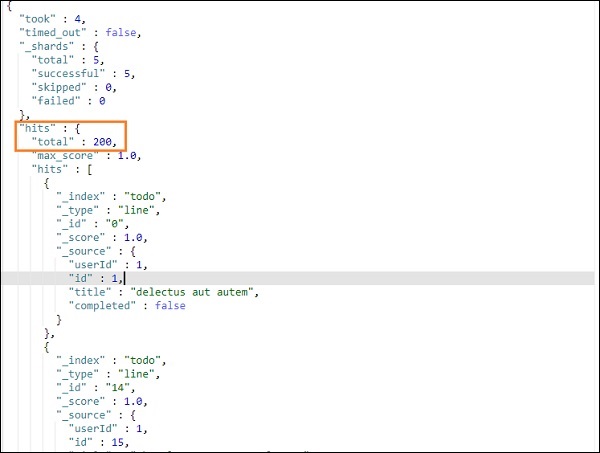
Это дает все записи, присутствующие в todoindex. Всего записей мы получаем 200.
Поиск записи в индексе todo
Мы можем сделать это с помощью следующей команды —
GET /todo/_search
{
"query":{
"match":{
"title":"delectusautautem"
}
}
}
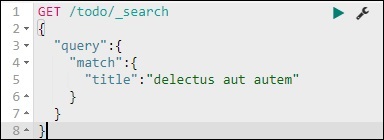
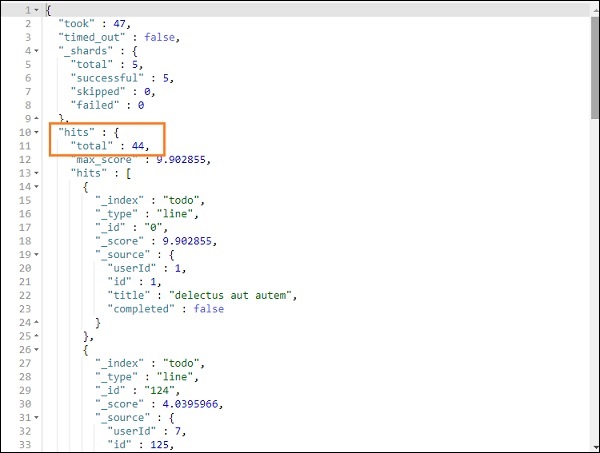
Мы можем получить записи, которые соответствуют названию, которое мы дали.
Кибана — Управление
Раздел «Управление» в Кибане используется для управления шаблонами индексов. В этой главе мы обсудим следующее:
- Создать шаблон индекса без поля фильтра времени
- Создать шаблон индекса с полем фильтра времени
Поле «Создать шаблон индекса без фильтра времени»
Для этого перейдите в пользовательский интерфейс Kibana и нажмите «Управление» —
Чтобы работать с Kibana, мы сначала должны создать индекс, который заполняется из эластичного поиска. Вы можете получить все доступные индексы в Elasticsearch → Управление индексами, как показано на рисунке —
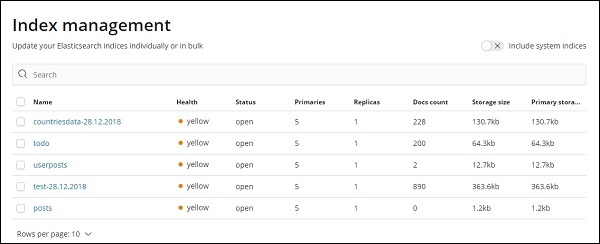
В настоящее время эластичный поиск имеет вышеуказанные показатели. Количество документов говорит нам об отсутствии записей, доступных в каждом из индексов. Если есть какой-либо индекс, который обновляется, количество документов будет меняться. Основное хранилище сообщает размер каждого загруженного индекса.
Чтобы создать новый индекс в Kibana, нам нужно нажать на шаблоны индекса, как показано ниже —

После того, как вы нажмете «Шаблоны индекса», мы получим следующий экран
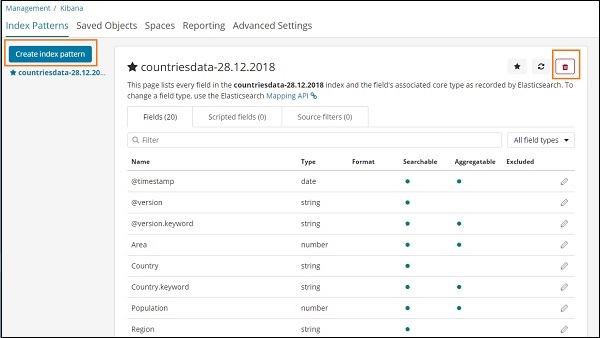
Обратите внимание, что кнопка «Создать шаблон индекса» используется для создания нового индекса. Напомним, что у нас уже есть countrydata-28.12.2018, созданная в самом начале урока.
Создать шаблон индекса с полем фильтра времени
Нажмите на Создать индексный шаблон, чтобы создать новый индекс.
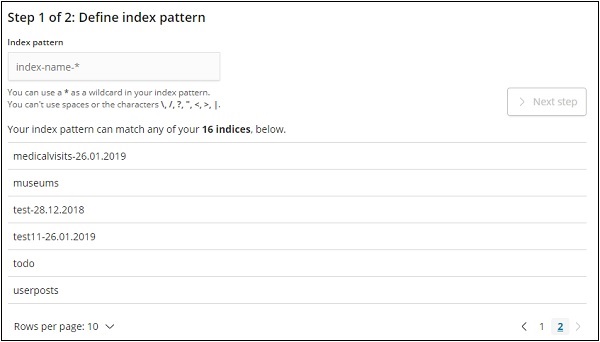
Индексы из эластичного поиска отображаются, выберите один, чтобы создать новый индекс.
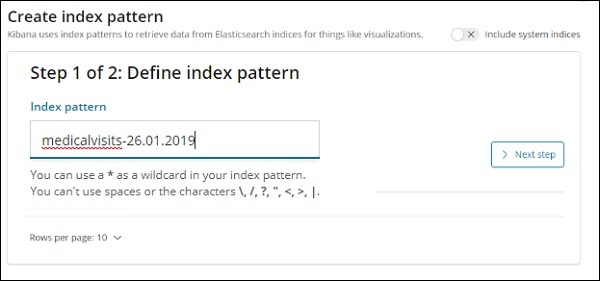
Теперь нажмите Next step .
Следующим шагом является настройка параметра, в который необходимо ввести следующее:
-
Имя поля временного фильтра используется для фильтрации данных по времени. В раскрывающемся списке отображаются все поля даты и времени из индекса.
Имя поля временного фильтра используется для фильтрации данных по времени. В раскрывающемся списке отображаются все поля даты и времени из индекса.
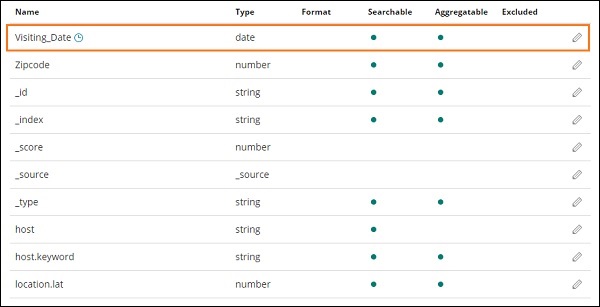
На изображении ниже показано Visiting_Date в качестве поля даты. Выберите Visiting_Date в качестве имени поля Time Filter.
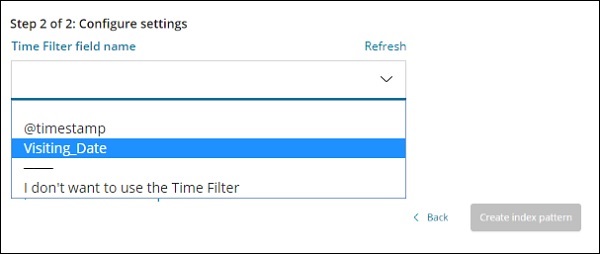
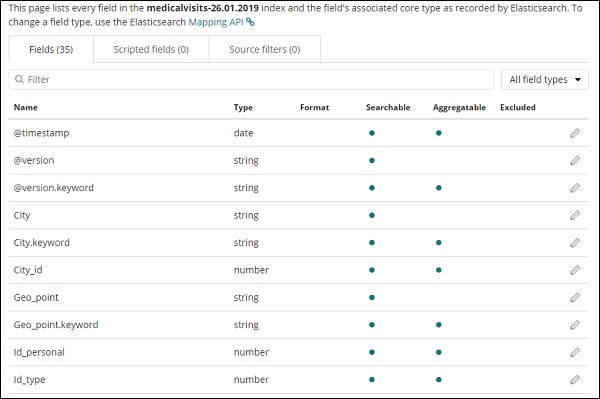
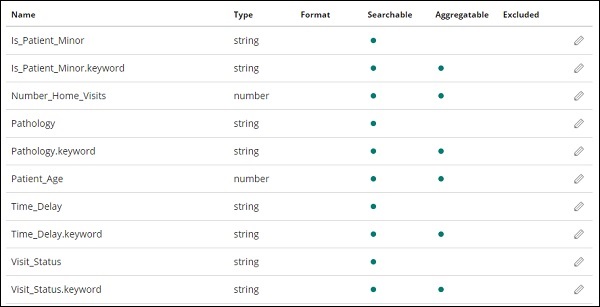
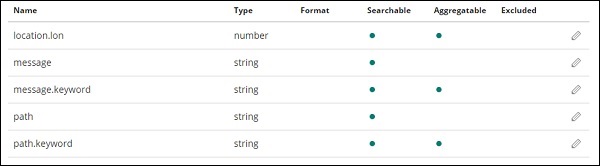
Нажмите кнопку Создать шаблон индекса , чтобы создать индекс. После этого будут отображены все поля, присутствующие в вашем индексе medicalvisits-26.01.2019, как показано ниже —
У нас есть следующие поля в индексе medicalvisits-26.01.2019 —
["Visit_Status","Time_Delay","City","City_id","Patient_Age","Zipcode","Latitude ","Longitude","Pathology","Visiting_Date","Id_type","Id_personal","Number_Home_ Visits","Is_Patient_Minor","Geo_point"].
В индексе есть все данные для домашних медицинских визитов. Есть некоторые дополнительные поля, добавляемые эластичным поиском при вставке из logstash.
Кибана — Откройте для себя
В этой главе обсуждается вкладка «Обнаружение» в пользовательском интерфейсе Kibana. Мы подробно узнаем о следующих понятиях —
- Индекс без поля даты
- Индекс с полем даты
Индекс без поля даты
Выберите Обнаружение в боковом меню слева, как показано ниже —
Справа отображаются подробные данные, доступные в страновом индексе 28.12.2018, который мы создали в предыдущей главе.
В верхнем левом углу отображается общее количество доступных записей —

Мы можем получить подробную информацию о данных в индексе (countrydata-28.12.2018) на этой вкладке. В верхнем левом углу экрана, показанного выше, мы видим такие кнопки, как «Создать», «Сохранить», «Открыть», «Поделиться», «Проверить» и «Автообновление».
Если вы нажмете Автообновление, появится экран, как показано ниже —
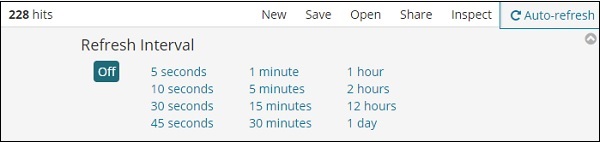
Вы можете установить интервал автоматического обновления, нажав на секунды, минуты или часы сверху. Kibana автоматически обновит экран и получит свежие данные после каждого установленного таймера.
Данные из индекса: countrydata-28.12.2018 отображаются, как показано ниже —
Все поля вместе с данными показаны построчно. Нажмите на стрелку, чтобы развернуть строку, и она предоставит вам подробную информацию в формате таблицы или JSON.

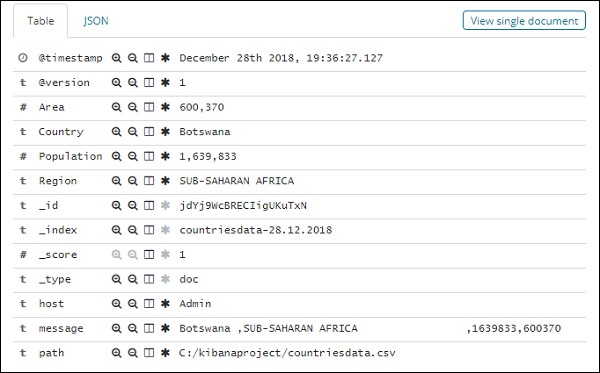
JSON формат
С левой стороны есть кнопка «Просмотр одного документа».
Если вы щелкните по нему, он отобразит строку или данные, присутствующие в строке внутри страницы, как показано ниже —
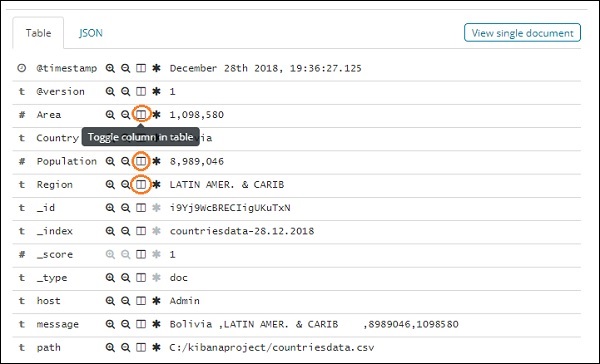
Несмотря на то, что мы получаем все данные здесь, нам сложно пройти каждый из них.
Теперь давайте попробуем получить данные в табличном формате. Ниже показан один из способов развернуть одну из строк и выбрать параметр столбца-переключателя, доступный для каждого поля.
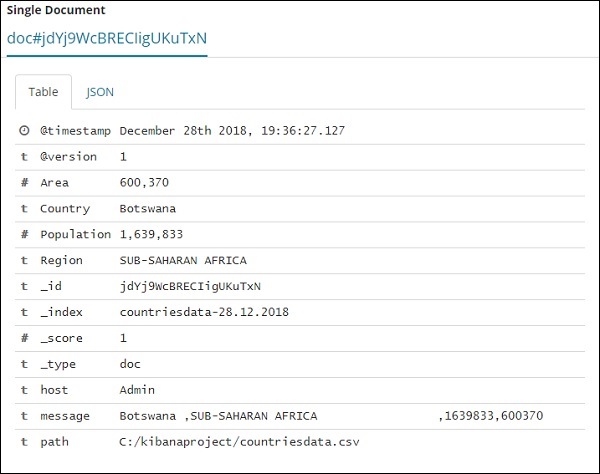
Нажмите на опцию Toggle column в таблице, доступную для каждого, и вы увидите, что данные отображаются в формате таблицы —

Здесь мы выбрали поля Страна, Область, Регион и Население. Сверните развернутую строку, и вы должны увидеть все данные в табличном формате.
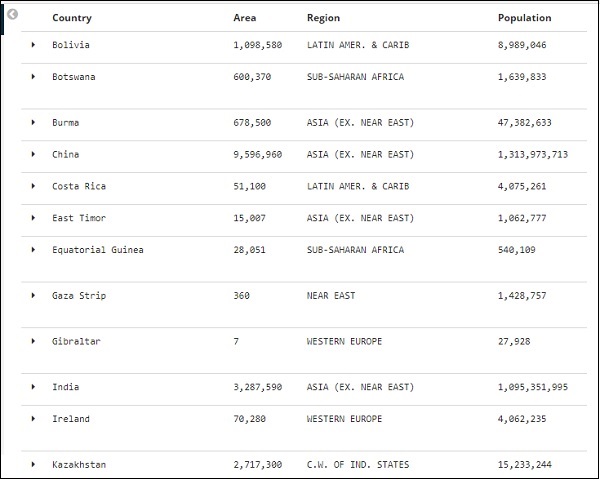
Выбранные нами поля отображаются в левой части экрана, как показано ниже —
Обратите внимание, что есть 2 варианта — Выбранные поля и Доступные поля . Поля, которые мы выбрали для отображения в табличном формате, являются частью выбранных полей. В случае, если вы хотите удалить любое поле, вы можете сделать это, нажав кнопку «Удалить», которая будет отображаться через имя поля в выбранной опции поля.
После удаления поле будет доступно внутри доступных полей, где вы можете добавить его обратно, нажав кнопку «Добавить», которая будет отображаться в нужном вам поле. Вы также можете использовать этот метод для получения ваших данных в табличном формате, выбрав необходимые поля из доступных полей .
У нас есть опция поиска в Discover, которую мы можем использовать для поиска данных внутри индекса. Давайте попробуем примеры, связанные с опцией поиска здесь —
Предположим, вы хотите найти страну Индия, вы можете сделать следующее —
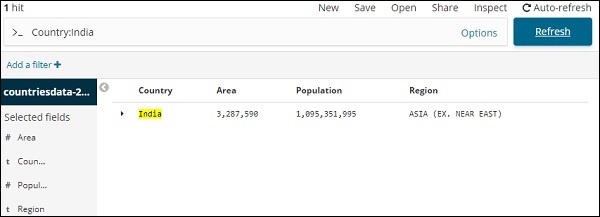
Вы можете ввести свои данные поиска и нажать кнопку Обновить. Если вы хотите искать страны, начинающиеся с Aus, вы можете сделать это следующим образом:

Нажмите Обновить, чтобы увидеть результаты
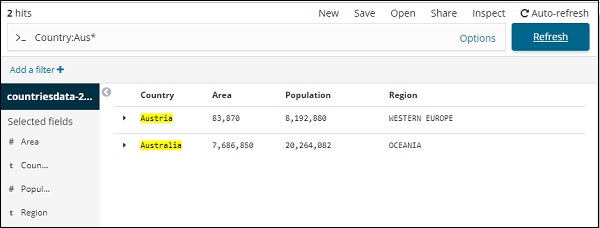
Здесь у нас есть две страны, начинающиеся с Aus *. В поле поиска есть кнопка «Параметры», как показано выше. Когда пользователь щелкает по нему, отображается кнопка переключения, которая при включении помогает в написании поискового запроса.
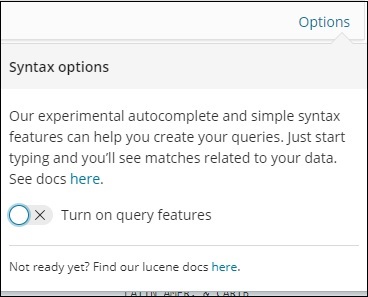
Включите функции запроса и введите имя поля в поиске, он будет отображать параметры, доступные для этого поля.
Например, поле Страна является строкой и отображает следующие параметры для поля строки:
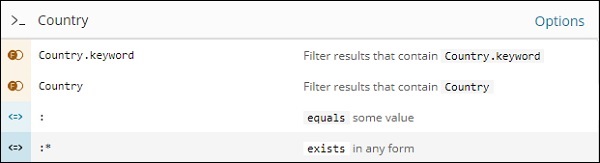
Аналогично, Area — это поле Number, в котором отображаются следующие параметры поля Number:
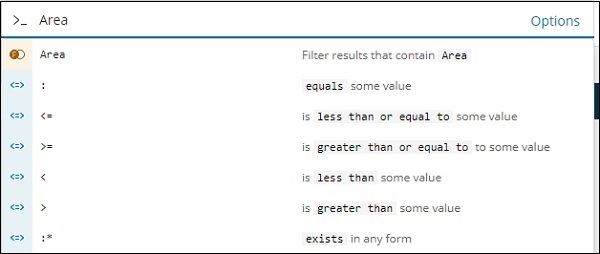
Вы можете попробовать разные комбинации и отфильтровать данные по вашему выбору в поле «Найти». Данные на вкладке «Обнаружение» можно сохранить с помощью кнопки «Сохранить», чтобы вы могли использовать ее для будущих целей.
Чтобы сохранить данные внутри обнаружения, нажмите кнопку «Сохранить» в правом верхнем углу, как показано ниже —
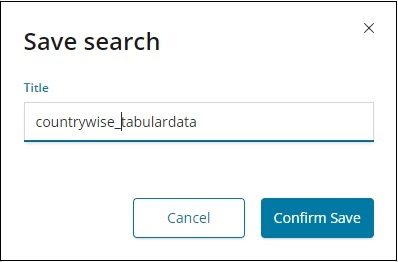
Дайте название вашему поиску и нажмите «Подтвердить», чтобы сохранить его. После сохранения в следующий раз, когда вы посетите вкладку «Обнаружение», вы можете нажать кнопку «Открыть» в верхнем правом углу, чтобы получить сохраненные заголовки, как показано ниже —
Вы также можете поделиться данными с другими, используя кнопку «Поделиться», доступную в верхнем правом углу. Если вы нажмете на нее, вы можете найти варианты обмена, как показано ниже —
Вы можете поделиться им с помощью отчетов CSV или в виде постоянных ссылок.
Опция, доступная по щелчку в отчетах CSV:
Нажмите «Создать CSV», чтобы получить доступ к отчету для других.
Опция, доступная по клику Постоянных ссылок, выглядит следующим образом:
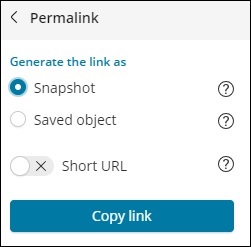
Опция Снимок даст ссылку Kibana, которая будет отображать данные, доступные в поиске в настоящее время.
Опция Сохраненный объект даст ссылку на Kibana, которая отобразит последние данные, доступные в вашем поиске.
Снимок — http: // localhost: 5601 / goto / 309a983483fccd423950cfb708fabfa5 Сохраненный объект: http: // localhost: 5601 / app / kibana # / Discover / 40bd89d0-10b1-11e9-9876-4f3d759b471e? _G = ()
Вы можете работать с вкладкой «Обнаружение» и доступными параметрами поиска, а полученный результат можно сохранить и поделиться с другими.
Индекс с полем даты
Перейдите на вкладку «Обнаружение» и выберите индекс: medicalvisits-26.01.2019
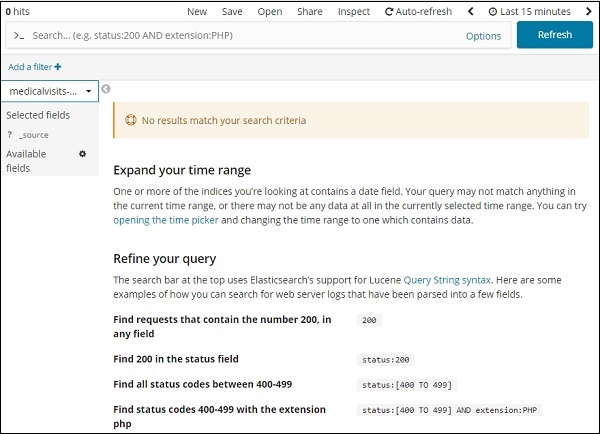
В течение последних 15 минут по выбранному нами индексу отображается сообщение «Результаты не соответствуют критериям поиска». Индекс имеет данные за 2015,2016,2017 и 2018 годы.
Измените временной диапазон, как показано ниже —
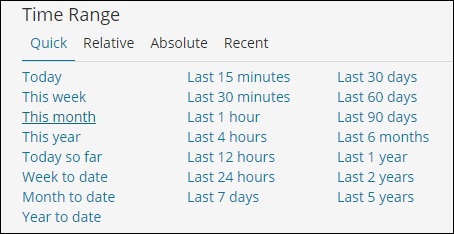
Нажмите вкладку Абсолют.
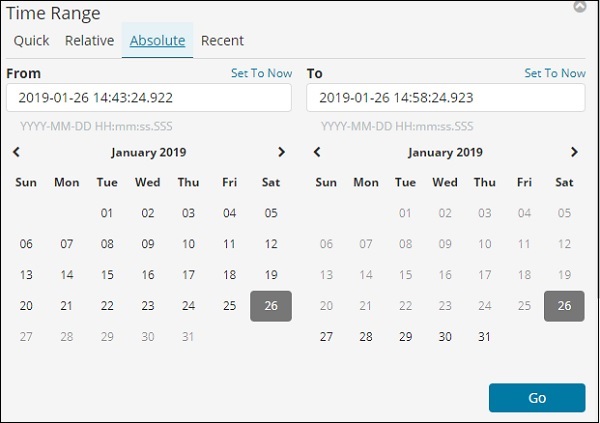
Выберите дату с 1 января 2017 года и до 31 декабря 2017 года, так как мы будем анализировать данные за 2017 год.
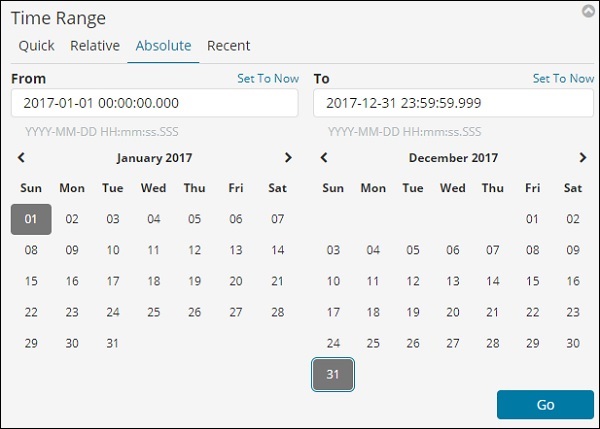
Нажмите кнопку «Перейти», чтобы добавить временной интервал. Он покажет вам данные и гистограмму следующим образом —
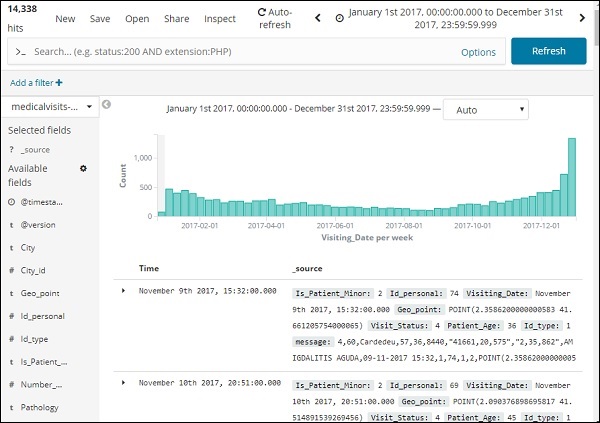
Это месячные данные за 2017 год —
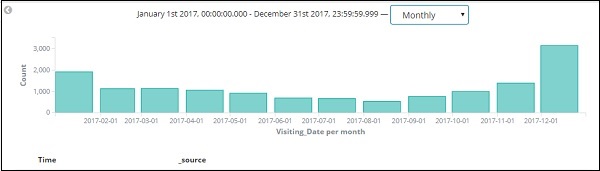
Поскольку у нас также есть время, сохраненное вместе с датой, мы можем фильтровать данные также по часам и минутам.
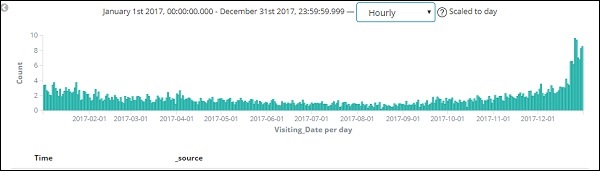
На приведенном выше рисунке показаны почасовые данные за 2017 год.
Здесь отображаются поля из индекса — medicalvisits-26.01.2019

У нас есть доступные поля на левой стороне, как показано ниже —
Вы можете выбрать поля из доступных полей и преобразовать данные в табличный формат, как показано ниже. Здесь мы выбрали следующие поля —
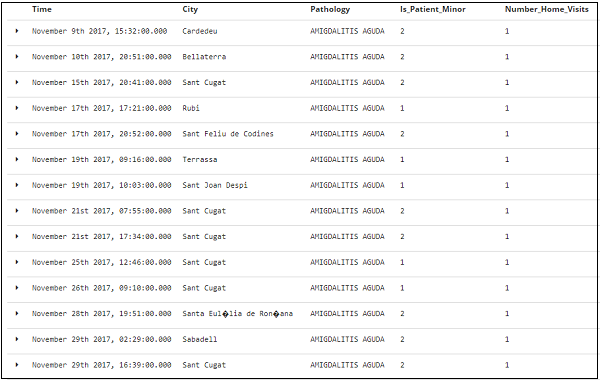
Табличные данные для вышеуказанных полей показаны здесь —
Кибана — агрегация и метрика
Во время изучения Кибаны вы часто сталкиваетесь с двумя терминами: Bucket и Metrics Aggregation. В этой главе обсуждается, какую роль они играют в Кибане, и более подробно о них.
Что такое агрегация кибана?
Агрегация — это совокупность документов или набор документов, полученных из определенного поискового запроса или фильтра. Агрегация формирует основную концепцию построения желаемой визуализации в Кибане.
Всякий раз, когда вы выполняете какую-либо визуализацию, вам необходимо определить критерии, которые означают, каким образом вы хотите сгруппировать данные для выполнения метрики на них.
В этом разделе мы обсудим два типа агрегации:
- Агрегация ковшей
- Метрическая агрегация
Агрегация ковшей
Ведро в основном состоит из ключа и документа. Когда агрегирование выполнено, документы помещаются в соответствующее ведро. Таким образом, в конце у вас должен быть список сегментов, каждый со списком документов. Список Bucket Aggregation, который вы увидите при создании визуализации в Kibana, показан ниже —
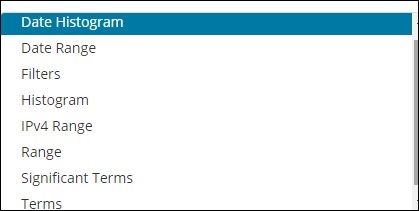
Bucket Aggregation имеет следующий список —
- Гистограмма даты
- Диапазон дат
- фильтры
- Гистограмма
- Диапазон IPv4
- Спектр
- Существенные условия
- термины
При создании необходимо выбрать один из них для объединения сегментов, т. Е. Группировать документы внутри сегментов.
В качестве примера для анализа рассмотрим данные по странам, которые мы загрузили в начале этого урока. Поля, доступные в индексе стран — это название страны, площадь, население, регион. В данных по странам у нас есть название страны вместе с населением, регионом и территорией.
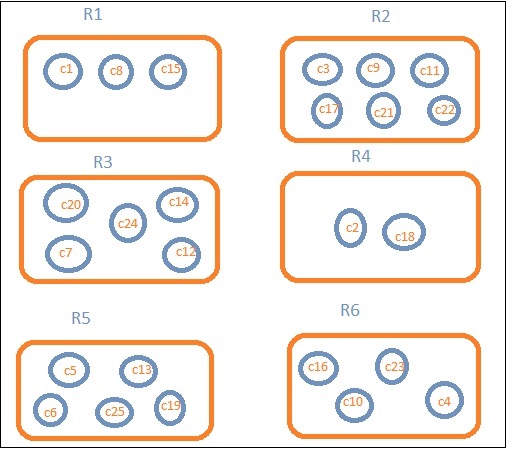
Допустим, нам нужны данные по регионам. Затем страны, доступные в каждом регионе, становятся нашим поисковым запросом, поэтому в этом случае регион будет формировать наши корзины. Приведенная ниже блок-схема показывает, что R1, R2, R3, R4, R5 и R6 — это сегменты, которые мы получили, а c1, c2 ..c25 — список документов, которые являются частью сегментов R1-R6.
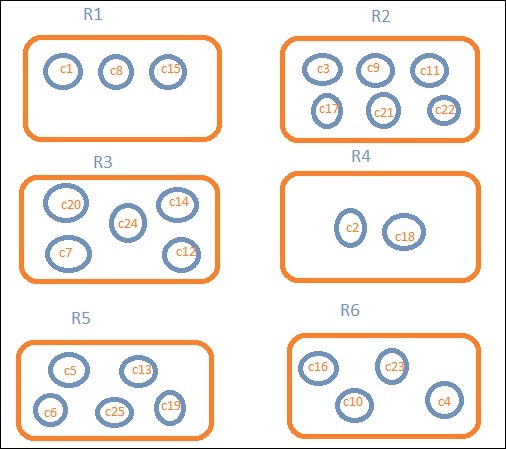
Мы видим, что в каждом ведре есть несколько кругов. Они представляют собой набор документов, основанных на критериях поиска и считающихся падающими в каждое ведро. В корзине R1 у нас есть документы c1, c8 и c15. Эти документы являются странами, которые попадают в этот регион, то же самое для других. Таким образом, если мы посчитаем страны в Ведре R1, это 3, 6 для R2, 6 для R3, 2 для R4, 5 для R5 и 4 для R6.
Таким образом, с помощью агрегирования сегментов мы можем агрегировать документы в сегменты и получать список документов в этих сегментах, как показано выше.
Список агрегации ведра, который у нас есть, —
- Гистограмма даты
- Диапазон дат
- фильтры
- Гистограмма
- Диапазон IPv4
- Спектр
- Существенные условия
- термины
Давайте теперь обсудим, как формировать эти ведра по одному подробно.
Гистограмма даты
Агрегирование гистограммы даты используется в поле даты. Таким образом, индекс, который вы используете для визуализации, если у вас есть поле даты в этом индексе, может использоваться только этот тип агрегации. Это агрегация с несколькими сегментами, что означает, что некоторые документы могут быть частью более одного сегмента. Для этой агрегации необходимо использовать интервал, подробности которого приведены ниже:
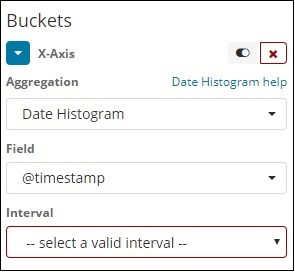
Когда вы выбираете объединение сегментов в качестве гистограммы даты, будет отображаться параметр Поле, в котором будут отображаться только поля, связанные с датой. После того, как вы выбрали свое поле, вам нужно выбрать интервал, который имеет следующие детали —
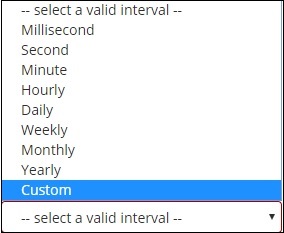
Таким образом, документы из индекса, выбранного и основанного на выбранном поле и интервале, будут классифицировать документы по группам. Например, если вы выбрали интервал как ежемесячный, документы, основанные на дате, будут конвертированы в сегменты и на основе месяца, т.е. января-декабря, документы будут помещены в сегменты. Здесь январь, февраль, декабрь будут ведрами.
Диапазон дат
Вам нужно поле даты, чтобы использовать этот тип агрегации. Здесь у нас будет диапазон дат, то есть от даты и до даты. Ведра будут иметь свои документы на основе формы и на сегодняшний день.
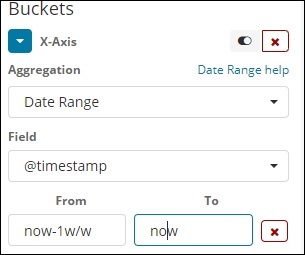
фильтры
При агрегации типов фильтров сегменты будут формироваться на основе фильтра. Здесь вы получите несколько сегментов, сформированных на основе критериев фильтрации, когда один документ может существовать в одном или нескольких сегментах.
Используя фильтры, пользователи могут писать свои запросы в опции фильтра, как показано ниже —
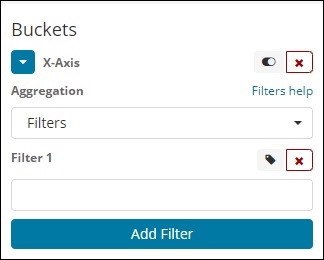
Вы можете добавить несколько фильтров на ваш выбор с помощью кнопки Добавить фильтр.
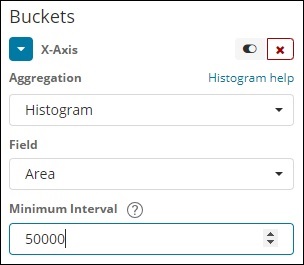
Гистограмма
Этот тип агрегации применяется к числовому полю и группирует документы в сегменте на основе примененного интервала. Например, 0-50,50-100,100-150 и т. Д.
Диапазон IPv4
Этот тип агрегации используется и в основном используется для IP-адресов.
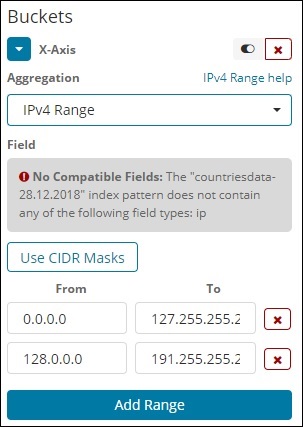
Индекс, который у нас есть, это contriesdata-28.12.2018, не имеет поля типа IP, поэтому он отображает сообщение, как показано выше. Если у вас есть поле IP, вы можете указать в нем значения От и До, как показано выше.
Спектр
Этот тип агрегации требует, чтобы поля имели номер типа. Вам необходимо указать диапазон, и документы будут перечислены в списках, попадающих в диапазон.
Вы можете добавить больше диапазона, если требуется, нажав на кнопку Добавить диапазон.
Существенные условия
Этот тип агрегации в основном используется в строковых полях.
термины
Этот тип агрегации используется во всех доступных полях, а именно: число, строка, дата, логическое значение, IP-адрес, отметка времени и т. Д. Обратите внимание, что это агрегация, которую мы собираемся использовать во всей нашей визуализации, над которой мы будем работать в этом руководство.
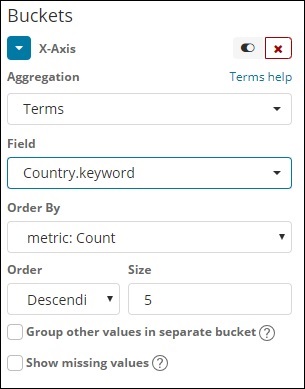
У нас есть опционный порядок, по которому мы будем группировать данные на основе выбранной метрики. Размер относится к количеству сегментов, которые вы хотите отобразить в визуализации.
Далее, давайте поговорим о метрической агрегации.
Метрическая агрегация
Метрическая агрегация в основном относится к математическим расчетам, выполненным для документов, представленных в корзине. Например, если вы выбираете числовое поле, вычисление метрики, которое вы можете сделать, это COUNT, SUM, MIN, MAX, AVERAGE и т. Д.
Список агрегации метрик, который мы обсудим, приведен здесь —
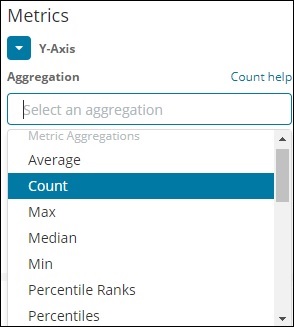
В этом разделе давайте обсудим важные из них, которые мы будем часто использовать —
- Средний
- подсчитывать
- Максимум
- Min
- сумма
Метрика будет применяться к агрегации отдельных сегментов, о которой мы уже говорили выше.
Далее, давайте обсудим список агрегирования метрик здесь —
Средний
Это даст среднее значение для документов, представленных в корзинах. Например —
R1 — R6 — ведра. В R1 у нас есть c1, c8 и c15. Рассмотрим значение с1, равное 300, с8, равное 500, и с15, равное 700. Теперь, чтобы получить среднее значение корзины R1
R1 = значение c1 + значение c8 + значение c15 / 3 = 300 + 500 + 700/3 = 500.
В среднем 500 за ведро R1. Здесь значение документа может быть таким, как если бы вы рассматривали данные стран, это может быть область страны в этом регионе.
подсчитывать
Это даст количество документов, представленных в ведре. Предположим, вы хотите подсчитать количество стран, присутствующих в регионе, это будет общее количество документов, представленных в корзинах. Например, R1 будет 3, R2 = 6, R3 = 5, R4 = 2, R5 = 5 и R6 = 4.
Максимум
Это даст максимальное значение документа, представленного в корзине. Рассматривая приведенный выше пример, если у нас есть данные по странам в области региона. Максимумом для каждого региона будет страна с максимальной площадью. Таким образом, он будет иметь одну страну от каждого региона, то есть от R1 до R6.
в
Это даст минимальное значение документа, представленного в корзине. Рассмотрим приведенный выше пример, если у нас есть данные по странам в области региона. Мин для каждого региона будет страна с минимальной площадью. Таким образом, он будет иметь одну страну от каждого региона, то есть от R1 до R6.
сумма
Это даст сумму значений документа, представленного в корзине. Например, если вы рассмотрите приведенный выше пример, если нам нужна общая площадь или страны региона, это будет сумма документов, представленных в регионе.
Например, чтобы узнать общее количество стран в регионе, R1 будет равно 3, R2 = 6, R3 = 5, R4 = 2, R5 = 5 и R6 = 4.
В случае, если у нас есть документы с областью в регионе, то от R1 до R6 будет суммирована область страны для региона.
Кибана — Создать визуализацию
Мы можем визуализировать имеющиеся у нас данные в виде гистограмм, линейных графиков, круговых диаграмм и т. Д. В этой главе мы поймем, как создавать визуализацию.
Создать визуализацию
Перейти к визуализации Kibana, как показано ниже —
У нас нет созданной визуализации, поэтому она отображается пустой и есть кнопка для ее создания.
Нажмите кнопку Создать визуализацию, как показано на экране выше, и вы попадете на экран, как показано ниже —
Здесь вы можете выбрать опцию, которая вам нужна для визуализации ваших данных. Мы подробно разберемся с каждым из них в следующих главах. Прямо сейчас выберу круговую диаграмму для начала.
После того, как вы выбрали тип визуализации, теперь вам нужно выбрать индекс, над которым вы хотите работать, и он выведет вас на экран, как показано ниже —
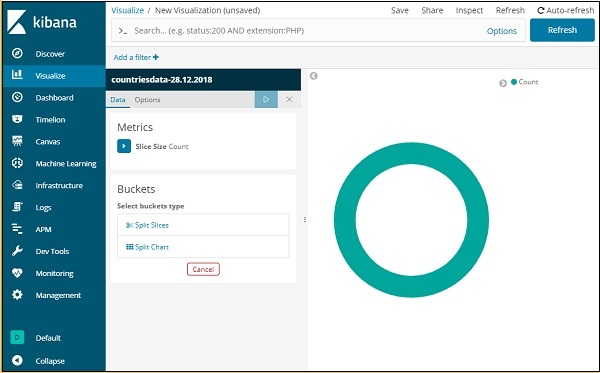
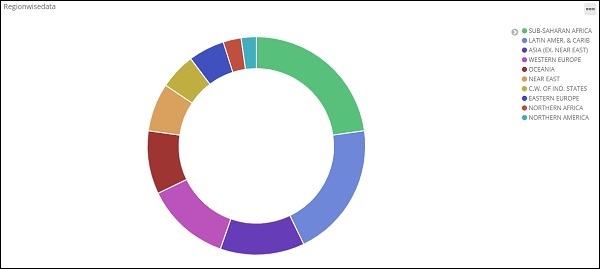
Теперь у нас есть круговая диаграмма по умолчанию. Мы будем использовать countrydata-28.12.2018, чтобы получить количество регионов, доступных в данных стран, в формате круговой диаграммы.
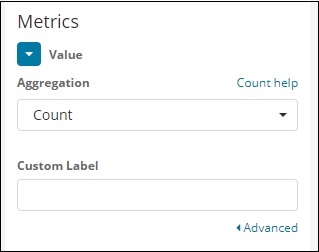
Ведро и метрическая агрегация
Левая сторона имеет метрики, которые мы выберем как количество. В Buckets есть 2 варианта разделить ломтики и разделить график. Мы будем использовать опцию Split ломтиками.
Теперь выберите Split Slices, и он отобразит следующие параметры:
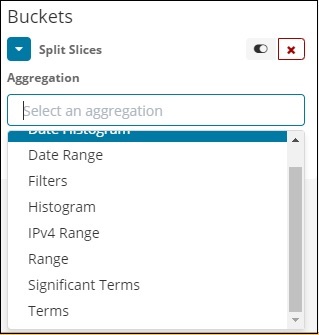
Теперь выберите Агрегирование в качестве Условий, и на нем появятся дополнительные параметры, которые необходимо ввести следующим образом:
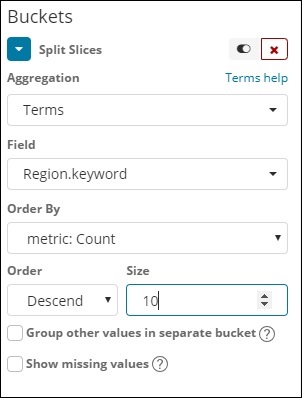
В раскрывающемся списке Поля будут отображены все поля из индекса: выбранные страны. Мы выбрали поле Регион и Заказ по. Обратите внимание, что мы выбрали метрику Count для Order By. Мы закажем его по убыванию и размер, который мы взяли равным 10. Это означает, что здесь мы получим 10 лучших регионов по индексу стран.
Теперь нажмите кнопку анализа, как показано ниже, и вы увидите обновленную круговую диаграмму справа.
Круговая диаграмма
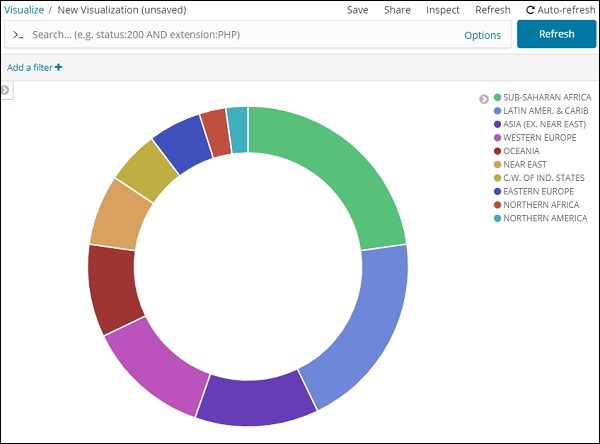
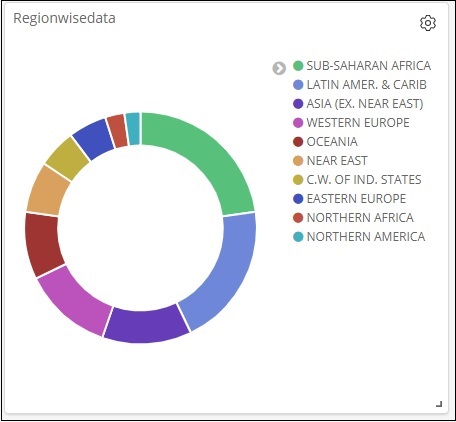
Все области перечислены в правом верхнем углу с цветами, и тот же цвет показан на круговой диаграмме. Если вы наведите курсор мыши на круговую диаграмму, она даст счетчик региона, а также название региона, как показано ниже —
Таким образом, это говорит нам о том, что 22,77% региона занято Африкой к югу от Сахары из данных стран, которые мы загрузили.
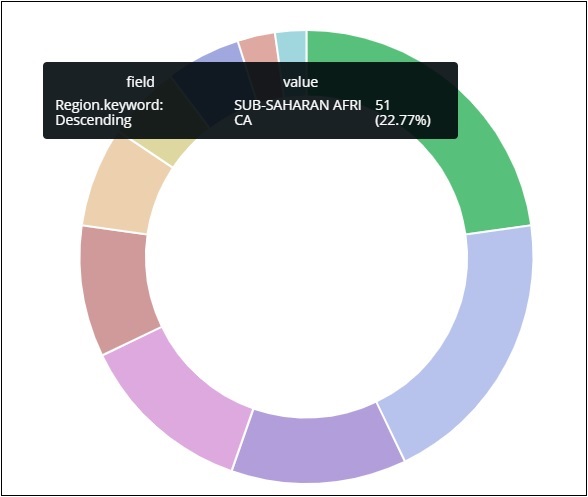
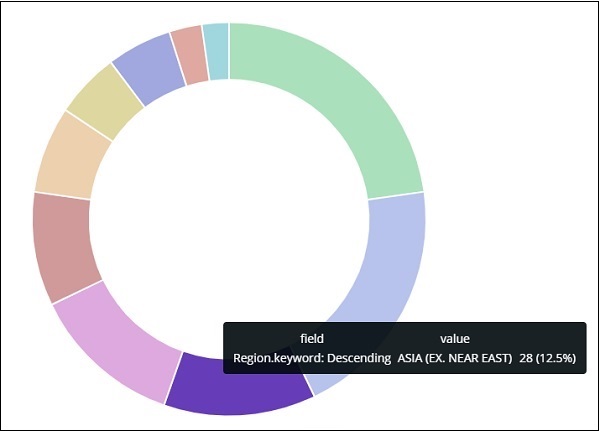
Азиатский регион занимает 12,5%, а количество составляет 28.
Теперь мы можем сохранить визуализацию, нажав кнопку «Сохранить» в правом верхнем углу, как показано ниже —

Теперь сохраните визуализацию, чтобы ее можно было использовать позже.
Мы также можем получить данные, как мы хотим, используя опцию поиска, как показано ниже —
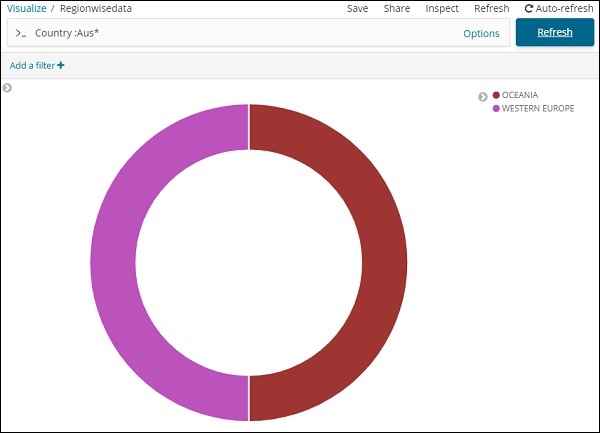
Мы отфильтровали данные для стран, начинающихся с Aus *. Мы поймем больше о круговой диаграмме и другой визуализации в следующих главах.
Кибана — работа с диаграммами
Давайте изучим и поймем наиболее часто используемые диаграммы в визуализации.
- Горизонтальная гистограмма
- Вертикальная гистограмма
- Круговая диаграмма
Ниже приведены шаги, которые необходимо выполнить для создания вышеуказанной визуализации. Давайте начнем с турника.
Горизонтальная гистограмма
Откройте Kibana и щелкните вкладку «Визуализация» с левой стороны, как показано ниже —
Нажмите кнопку +, чтобы создать новую визуализацию —
Нажмите на горизонтальную полосу, указанную выше. Вам нужно будет выбрать индекс, который вы хотите визуализировать.
Выберите указатель странданные-28.12.2018, как показано выше. При выборе индекса отображается экран, как показано ниже —
Показывает счетчик по умолчанию. Теперь давайте нарисуем горизонтальный график, на котором мы можем увидеть данные 10 лучших стран по населению.
Для этого нам нужно выбрать то, что мы хотим на оси Y и X. Следовательно, выберите Bucket and Metric Aggregation —
Теперь, если вы нажмете на ось Y, появится экран, как показано ниже —
Теперь выберите нужную агрегацию из показанных здесь вариантов —
Обратите внимание, что здесь мы выберем максимальную агрегацию, так как мы хотим отображать данные в соответствии с максимальной доступной популяцией.
Далее мы должны выбрать поле, максимальное значение которого требуется. В индексе countrydata-28.12.2018 у нас есть только 2 числа поля — площадь и население.
Поскольку нам нужна максимальная численность населения, мы выбираем поле Население, как показано ниже —
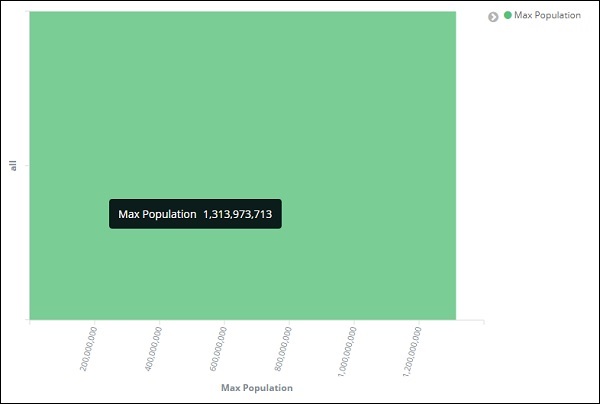
По этому мы закончили с осью Y. Вывод, который мы получаем для оси Y, показан ниже:
Теперь давайте выберем ось X, как показано ниже —
Если вы выберете X-Axis, вы получите следующий вывод:
Выберите Агрегирование в качестве Условий.
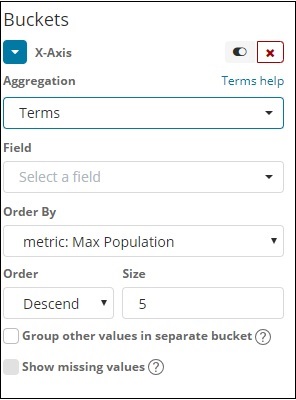
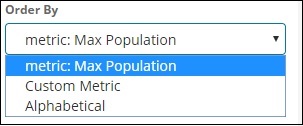
Выберите поле из выпадающего списка. Мы хотим, чтобы население страны было мудрым, поэтому выберите поле страны. Заказать у нас есть следующие варианты —
Мы будем выбирать порядок по максимальному населению, так как хотим, чтобы страна с наибольшим населением отображалась первой и так далее. После добавления нужных нам данных нажмите кнопку «Применить изменения» в верхней части данных метрик, как показано ниже.
Как только вы нажмете «Применить изменения», у нас появится горизонтальный график, на котором мы увидим, что Китай — страна с наибольшим населением, за которой следуют Индия, США и т. Д.
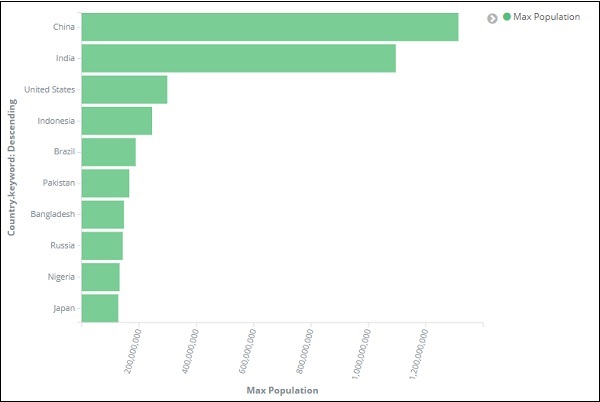
Точно так же вы можете построить различные графики, выбрав нужное поле. Далее мы сохраним эту визуализацию как max_population, чтобы позже использовать ее для создания панели мониторинга.
В следующем разделе мы создадим вертикальную гистограмму.
Вертикальная гистограмма
Перейдите на вкладку «Визуализация» и создайте новую визуализацию, используя вертикальную черту и индекс в качестве странданных-28.12.2018 .
В этой визуализации вертикальной полосы мы создадим гистограмму с областью, соответствующей странам, т.е. страны будут отображаться с самой высокой областью.
Итак, давайте выберем оси Y и X, как показано ниже —
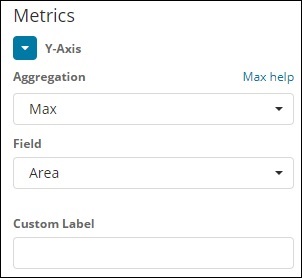
Ось ординат
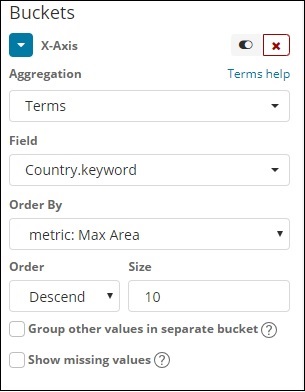
Ось абсцисс
Когда мы применяем изменения здесь, мы можем видеть результат, как показано ниже —
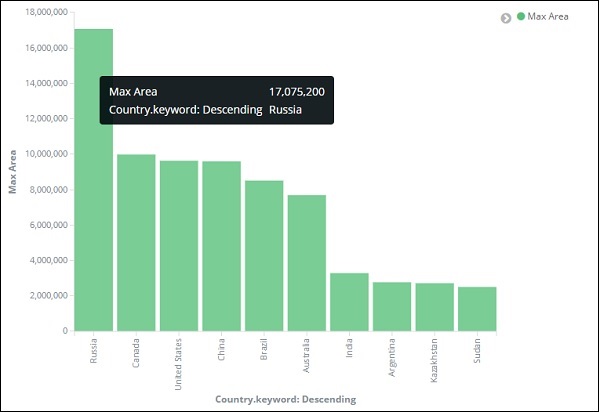
Из графика видно, что у России самая высокая площадь, за ней следуют Канада и США. Обратите внимание, что эти данные взяты из индекса странданных и его фиктивных данных, поэтому цифры могут быть неверными с данными в реальном времени.
Давайте сохраним эту визуализацию как countrywise_maxarea, чтобы позже использовать ее с приборной панелью.
Далее, давайте работать над круговой диаграммой.
Круговая диаграмма
Поэтому сначала создайте визуализацию и выберите круговую диаграмму с индексом в качестве страновых данных. Мы собираемся отобразить количество регионов, доступных в данных о странах, в формате круговой диаграммы.
Левая сторона имеет метрики, которые подсчитывают. В Buckets есть 2 варианта: Разделить фрагменты и разделить график. Теперь мы будем использовать опцию Split ломтиками.
Теперь, если вы выберете «Разделить ломтики», на нем отобразятся следующие параметры:
Выберите Агрегирование в качестве Условий, и в нем отобразятся дополнительные параметры, которые необходимо ввести следующим образом:
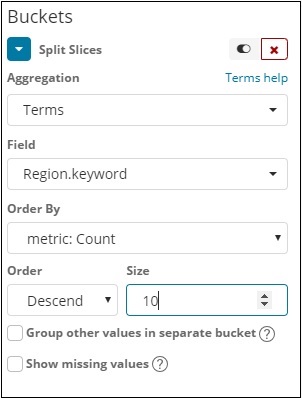
В раскрывающемся списке Поля будут отображены все поля из выбранного индекса. Мы выбрали поле Region и Order By, что мы выбрали в качестве Count. Мы закажем его по убыванию, а его размер будет равен 10. Итак, здесь мы получим 10 регионов из индекса стран.
Теперь нажмите кнопку воспроизведения, как показано ниже, и вы увидите обновленную круговую диаграмму с правой стороны.
Круговая диаграмма
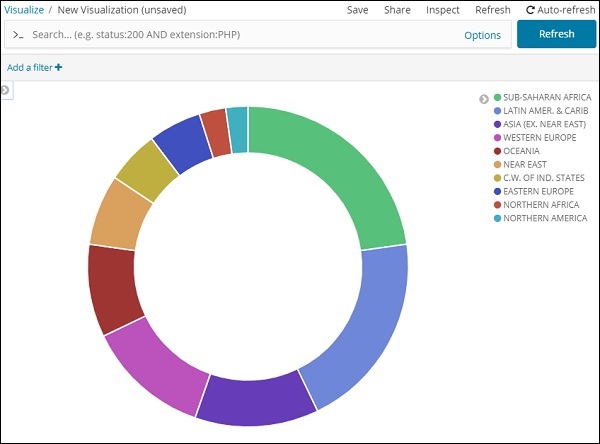
Все области перечислены в правом верхнем углу с цветами, и тот же цвет показан на круговой диаграмме. Если вы наведите курсор мыши на круговую диаграмму, она даст счетчик региона, а также название региона, как показано ниже —
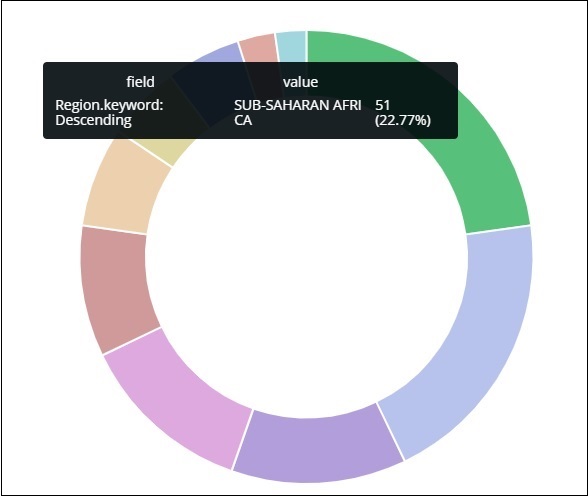
Таким образом, это говорит нам о том, что 22,77% региона занято Африкой к югу от Сахары в данных по странам, которые мы загрузили.
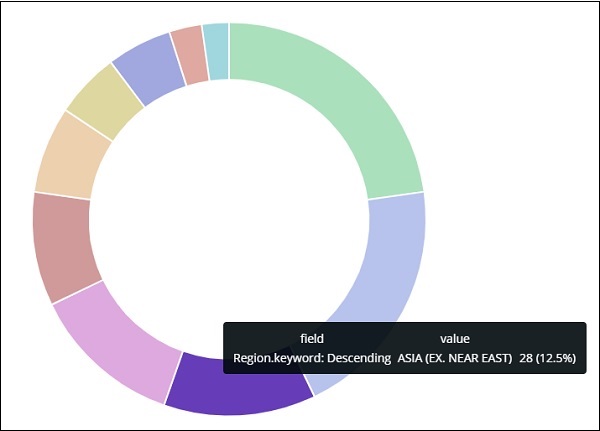
На круговой диаграмме обратите внимание, что азиатский регион занимает 12,5%, а количество составляет 28.
Теперь мы можем сохранить визуализацию, нажав кнопку «Сохранить» в правом верхнем углу, как показано ниже —

Теперь сохраните визуализацию, чтобы позже ее можно было использовать в панели управления.
Кибана — работа с графиками
В этой главе мы обсудим два типа графиков, используемых при визуализации:
- Линейный график
- Площадь
Линейный график
Для начала давайте создадим визуализацию, выбрав линейный график для отображения данных и используя contriesdata в качестве индекса. Нам нужно создать ось Y и ось X, и детали для них показаны ниже —
Для оси Y
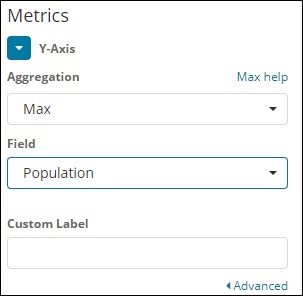
Заметьте, что мы взяли Макса в качестве Агрегации. Итак, здесь мы собираемся показать представление данных в виде графика. Теперь мы построим график, который покажет максимальную численность населения страны. Поле, которое мы выбрали, — «Население», так как нам нужно максимальное население страны.
Для оси X
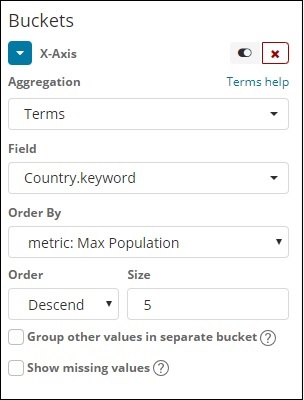
На оси абсцисс мы взяли термины как агрегацию, Country.keyword как поле и метрику: максимальное население для Order By, а размер заказа равен 5. Таким образом, он построит 5 лучших стран с максимальным населением. После применения изменений вы можете увидеть линейный график, как показано ниже —
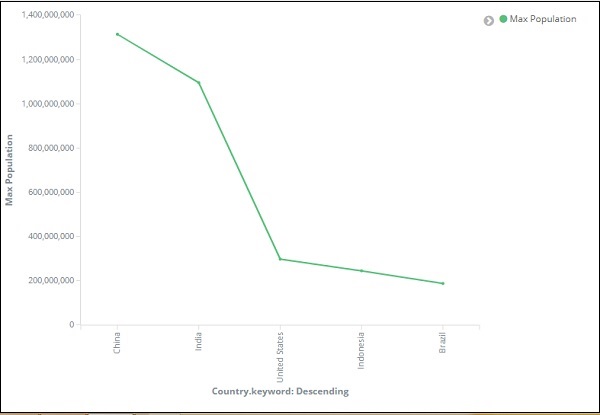
Таким образом, у нас есть максимальное население в Китае, за которым следуют Индия, США, Индонезия и Бразилия, как 5 лучших стран по численности населения.
Теперь давайте сохраним этот линейный график, чтобы позже его можно было использовать в панели инструментов.
Нажмите Подтвердить Сохранить, и вы можете сохранить визуализацию.
Граф области
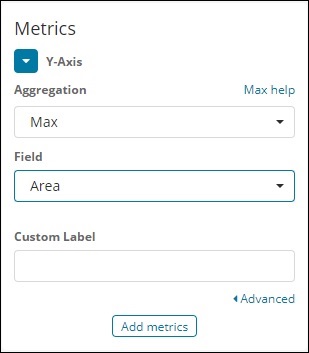
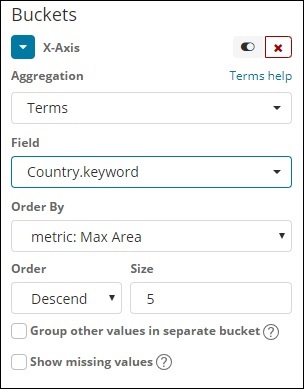
Перейдите к визуализации и выберите область с индексом в качестве данных страны. Нам нужно выбрать ось Y и X. Мы построим график площади для максимальной площади для страны.
Таким образом, здесь оси X и Y будут такими, как показано ниже —
После того, как вы нажмете кнопку «Применить изменения», мы увидим следующий результат:
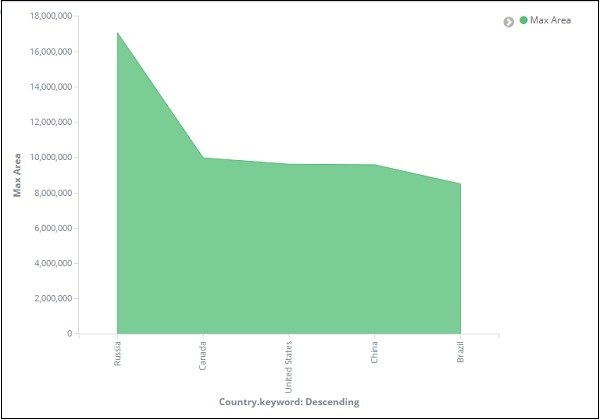
Из графика видно, что Россия имеет самую высокую площадь, за ней следуют Канада, США, Китай и Бразилия. Сохраните визуализацию, чтобы использовать ее позже.
Кибана — Работа с тепловой картой
В этой главе мы поймем, как работать с тепловой картой. Тепловая карта будет отображать представление данных в разных цветах для диапазона, выбранного в метриках данных.
Начало работы с тепловой картой
Для начала нам нужно создать визуализацию, нажав на вкладку визуализации с левой стороны, как показано ниже —
Выберите тип визуализации в качестве тепловой карты, как показано выше. Он попросит вас выбрать индекс, как показано ниже —
Выберите индекс странданные-28.12.2018, как показано выше. После выбора индекса у нас есть данные для выбора, как показано ниже —
Выберите метрики, как показано ниже —
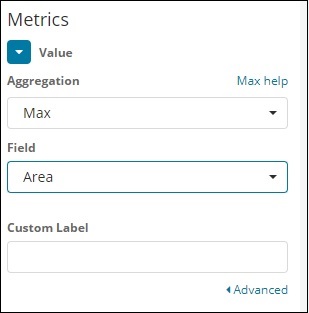
Выберите Max Aggregation из выпадающего списка, как показано ниже —
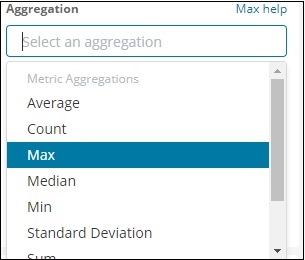
Мы выбрали Макс, так как мы хотим построить Макс Площадь по стране.
Теперь выберем значения для Buckets, как показано ниже —
Теперь давайте выберем ось X, как показано ниже —
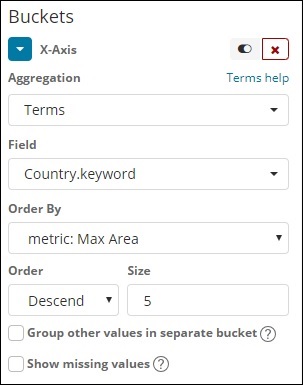
Мы использовали Агрегацию как Термины, Поле как Страна и Порядок по Макс. Площади. Нажмите на Применить изменения, как показано ниже —
Если вы нажмете «Применить изменения», тепловая карта будет выглядеть так, как показано ниже —
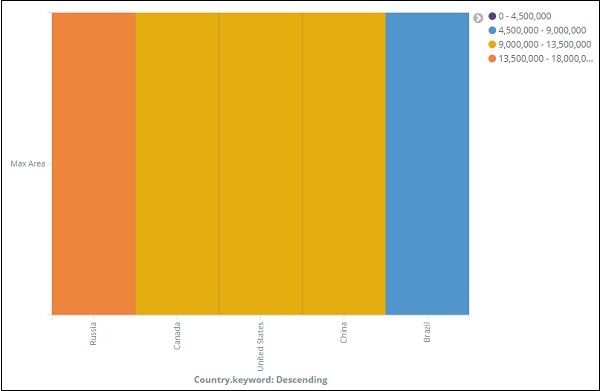
Тепловая карта показана разными цветами, а диапазон областей показан справа. Вы можете изменить цвет, нажав на маленькие кружочки рядом с диапазоном области, как показано ниже —
Кибана — Работа с картой координат
Карты координат в Кибане покажут вам географическую область и отметят эту область кружками на основе указанной вами агрегации.
Создать индекс для карты координат
Агрегация Bucket, используемая для карты координат, является агрегацией геохеша. Для этого типа агрегации ваш индекс, который вы собираетесь использовать, должен иметь поле типа географической точки. Географическая точка — это сочетание широты и долготы.
Мы создадим индекс с помощью инструментов разработчика Kibana и добавим к нему объемные данные. Мы добавим отображение и добавим нужный нам тип geo_point.
Данные, которые мы собираемся использовать, показаны здесь —
{"index":{"_id":1}}
{"location": "2.089330000000046,41.47367000000008", "city": "SantCugat"}
{"index":{"_id":2}}
{"location": "2.2947825000000677,41.601800991000076", "city": "Granollers"}
{"index":{"_id":3}}
{"location": "2.1105957495300474,41.5496295760424", "city": "Sabadell"}
{"index":{"_id":4}}
{"location": "2.132605678083895,41.5370461908878", "city": "Barbera"}
{"index":{"_id":5}}
{"location": "2.151270020052683,41.497779918345415", "city": "Cerdanyola"}
{"index":{"_id":6}}
{"location": "2.1364609496220606,41.371303520399344", "city": "Barcelona"}
{"index":{"_id":7}}
{"location": "2.0819450306711165,41.385491966414705", "city": "Sant Just Desvern"}
{"index":{"_id":8}}
{"location": "2.00532082278266,41.542294286427385", "city": "Rubi"}
{"index":{"_id":9}}
{"location": "1.9560805366930398,41.56142635214226", "city": "Viladecavalls"}
{"index":{"_id":10}}
{"location": "2.09205348251486,41.39327140161001", "city": "Esplugas de Llobregat"}
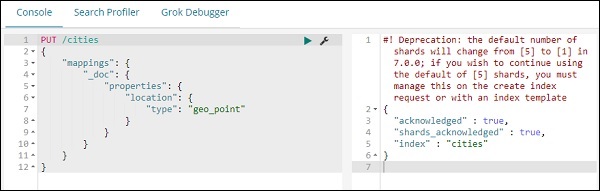
Теперь выполните следующие команды в Kibana Dev Tools, как показано ниже:
PUT /cities
{
"mappings": {
"_doc": {
"properties": {
"location": {
"type": "geo_point"
}
}
}
}
}
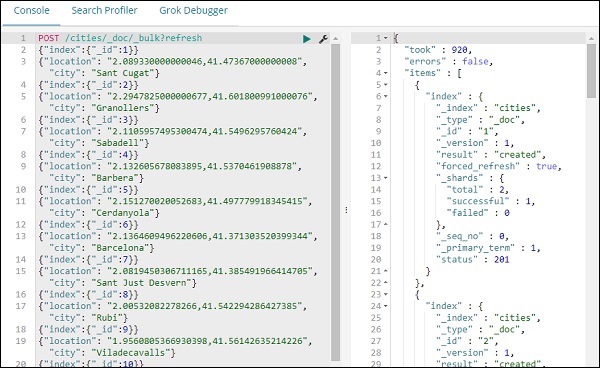
POST /cities/_city/_bulk?refresh
{"index":{"_id":1}}
{"location": "2.089330000000046,41.47367000000008", "city": "SantCugat"}
{"index":{"_id":2}}
{"location": "2.2947825000000677,41.601800991000076", "city": "Granollers"}
{"index":{"_id":3}}
{"location": "2.1105957495300474,41.5496295760424", "city": "Sabadell"}
{"index":{"_id":4}}
{"location": "2.132605678083895,41.5370461908878", "city": "Barbera"}
{"index":{"_id":5}}
{"location": "2.151270020052683,41.497779918345415", "city": "Cerdanyola"}
{"index":{"_id":6}}
{"location": "2.1364609496220606,41.371303520399344", "city": "Barcelona"}
{"index":{"_id":7}}
{"location": "2.0819450306711165,41.385491966414705", "city": "Sant Just Desvern"}
{"index":{"_id":8}}
{"location": "2.00532082278266,41.542294286427385", "city": "Rubi"}
{"index":{"_id":9}}
{"location": "1.9560805366930398,41.56142635214226", "city": "Viladecavalls"}
{"index":{"_id":10}}
{"location": "2.09205348251486,41.3s9327140161001", "city": "Esplugas de Llobregat"}
Теперь запустите вышеуказанные команды в инструментах разработчика Kibana —
Приведенное выше будет создавать города с индексными именами типа _doc, а расположение поля — типа geo_point.
Теперь давайте добавим данные в индекс: города —
Мы закончили создание сайтов именных указателей с данными. Теперь давайте создадим шаблон индекса для городов, используя вкладку «Управление».
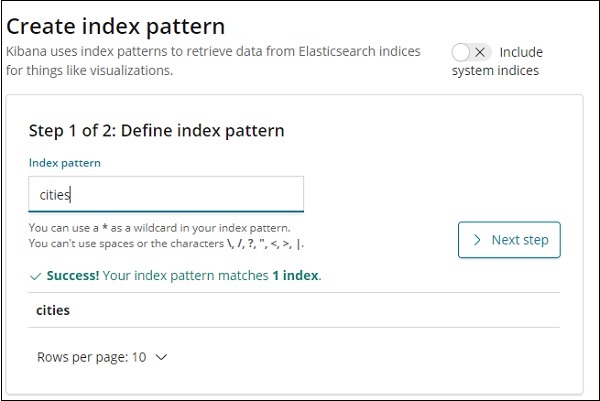
Детали полей внутри индекса города показаны здесь —
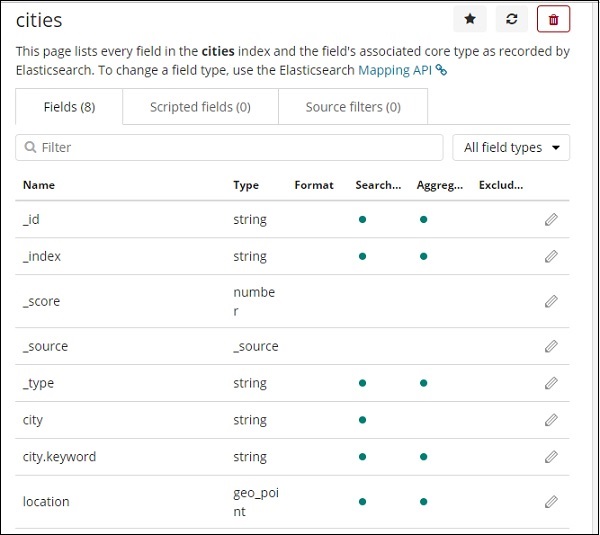
Мы можем видеть, что местоположение имеет тип geo_point. Теперь мы можем использовать его для создания визуализации.
Начало работы с картами координат
Перейдите в раздел Визуализация и выберите карты координат.
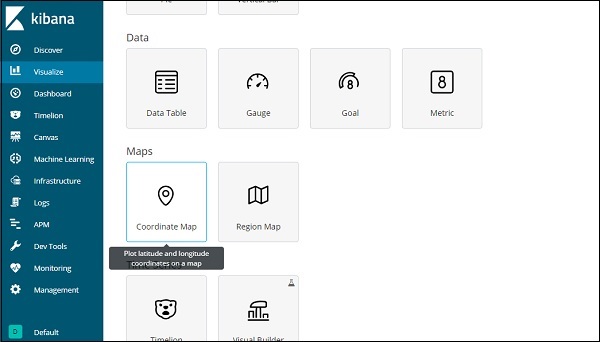
Выберите города шаблона индекса и настройте метрику и корзину агрегации, как показано ниже —
Если вы нажмете кнопку «Анализ», вы увидите следующий экран —
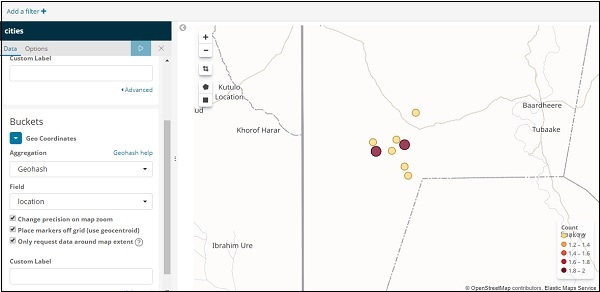
В зависимости от долготы и широты круги наносятся на карту, как показано выше.
Кибана — Работа с картой региона
С помощью этой визуализации вы видите данные, представленные на географической карте мира. В этой главе давайте рассмотрим это подробно.
Создать индекс для карты региона
Мы создадим новый индекс для работы с визуализацией карты региона. Данные, которые мы собираемся загрузить, показаны здесь —
{"index":{"_id":1}} {"country": "China", "population": "1313973713"} {"index":{"_id":2}} {"country": "India", "population": "1095351995"} {"index":{"_id":3}} {"country": "United States", "population": "298444215"} {"index":{"_id":4}} {"country": "Indonesia", "population": "245452739"} {"index":{"_id":5}} {"country": "Brazil", "population": "188078227"} {"index":{"_id":6}} {"country": "Pakistan", "population": "165803560"} {"index":{"_id":7}} {"country": "Bangladesh", "population": "147365352"} {"index":{"_id":8}} {"country": "Russia", "population": "142893540"} {"index":{"_id":9}} {"country": "Nigeria", "population": "131859731"} {"index":{"_id":10}} {"country": "Japan", "population": "127463611"}
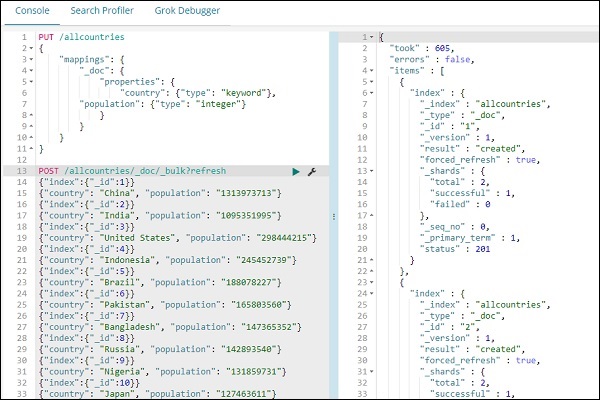
Обратите внимание, что мы будем использовать _bulk upload в инструментах разработчика для загрузки данных.
Теперь перейдите к Kibana Dev Tools и выполните следующие запросы —
PUT /allcountries { "mappings": { "_doc": { "properties": { "country": {"type": "keyword"}, "population": {"type": "integer"} } } } } POST /allcountries/_doc/_bulk?refresh {"index":{"_id":1}} {"country": "China", "population": "1313973713"} {"index":{"_id":2}} {"country": "India", "population": "1095351995"} {"index":{"_id":3}} {"country": "United States", "population": "298444215"} {"index":{"_id":4}} {"country": "Indonesia", "population": "245452739"} {"index":{"_id":5}} {"country": "Brazil", "population": "188078227"} {"index":{"_id":6}} {"country": "Pakistan", "population": "165803560"} {"index":{"_id":7}} {"country": "Bangladesh", "population": "147365352"} {"index":{"_id":8}} {"country": "Russia", "population": "142893540"} {"index":{"_id":9}} {"country": "Nigeria", "population": "131859731"} {"index":{"_id":10}} {"country": "Japan", "population": "127463611"}
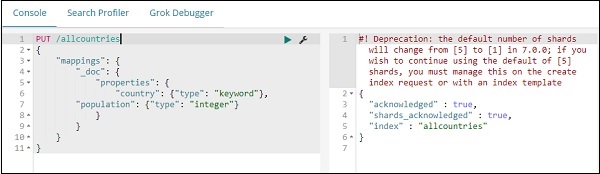
Далее давайте создадим индекс allcountries. Мы указали тип поля страны в качестве ключевого слова —
PUT /allcountries { "mappings": { "_doc": { "properties": { "country": {"type": "keyword"}, "population": {"type": "integer"} } } } }
Примечание. Для работы с картами регионов необходимо указать тип поля, который будет использоваться с агрегацией в качестве типа ключевого слова.
После этого загрузите данные с помощью команды _bulk.
Теперь мы создадим шаблон индекса. Перейдите на вкладку Kibana Management и выберите «Создать шаблон индекса».
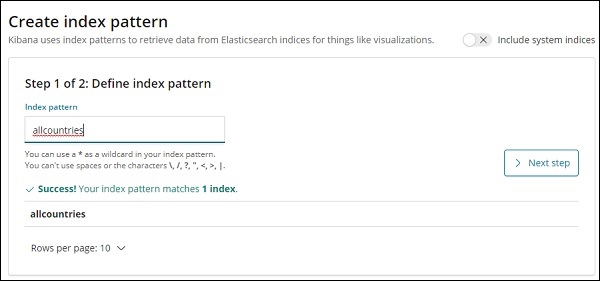
Вот поля, отображаемые из индекса всех стран.
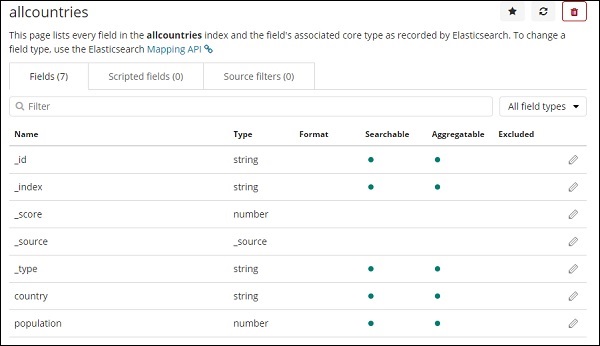
Начало работы с картами регионов
Теперь мы создадим визуализацию, используя Карты регионов. Перейдите в раздел «Визуализация» и выберите «Карты регионов».
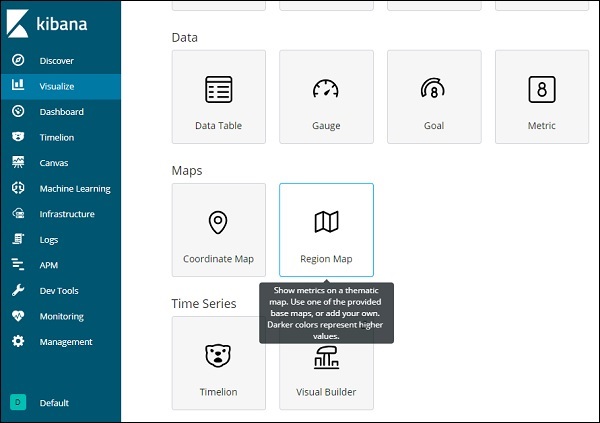
После этого выберите индекс как все страны и продолжайте.
Выберите Метрики агрегации и Метрики корзины, как показано ниже —
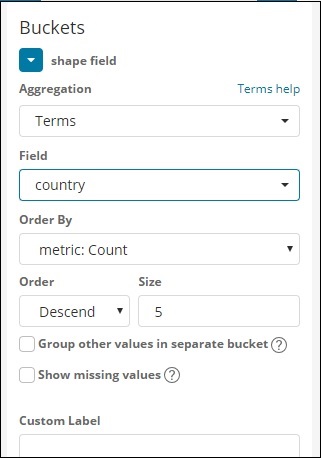
Здесь мы выбрали поле в качестве страны, так как я хочу показать то же самое на карте мира.
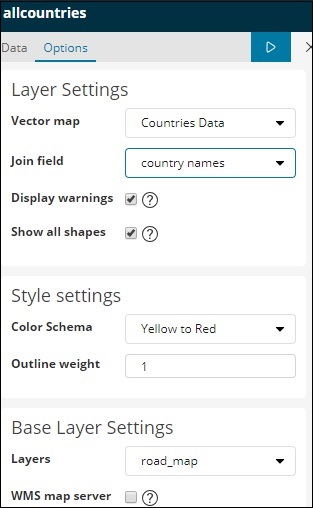
Векторная карта и поле соединения для карты региона
Для карт регионов нам также нужно выбрать вкладки «Параметры», как показано ниже —
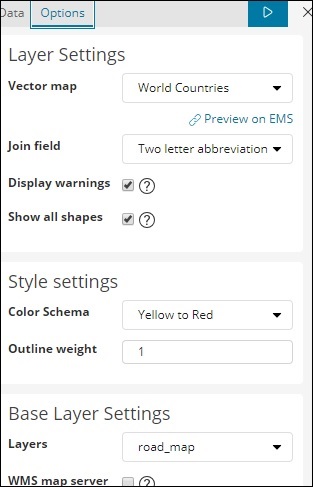
Вкладка параметров имеет конфигурацию Layer Settings, которая необходима для отображения данных на карте мира.
Векторная карта имеет следующие параметры —
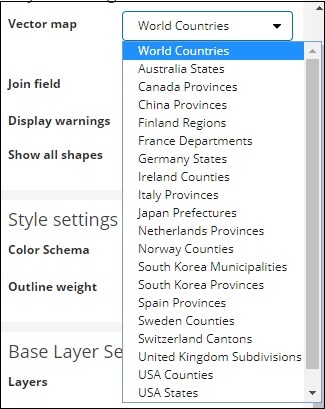
Здесь мы выберем страны мира, так как у меня есть данные стран.
Поле Присоединения имеет следующие детали —
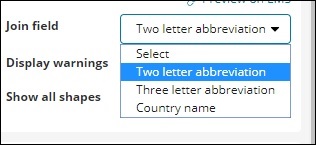
В нашем индексе у нас есть название страны, поэтому мы выберем название страны.
В настройках стиля вы можете выбрать цвет для отображения стран —
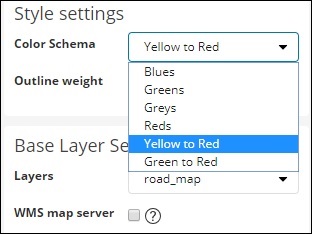
Мы выберем красные. Мы не будем касаться остальных деталей.
Теперь нажмите кнопку «Анализ», чтобы увидеть детали стран, нанесенных на карту мира, как показано ниже —
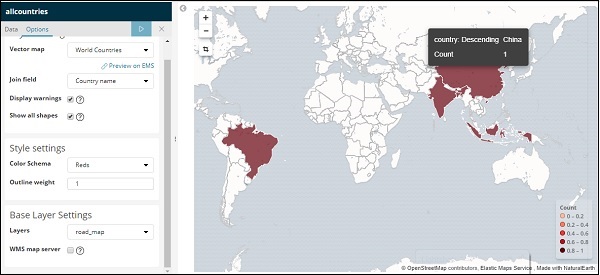
Самостоятельная векторная карта и поле присоединения в Кибане
Вы также можете добавить свои собственные настройки Kibana для векторной карты и поля присоединения. Для этого перейдите в kibana.yml из папки конфигурации kibana и добавьте следующую информацию:
regionmap: includeElasticMapsService: false layers: - name: "Countries Data" url: "http://localhost/kibana/worldcountries.geojson" attribution: "INRAP" fields: - name: "Country" description: "country names"
Векторная карта из вкладки параметров будет заполнена вышеуказанными данными вместо данных по умолчанию. Обратите внимание, что указанный URL-адрес должен быть включен CORS, чтобы Kibana мог загрузить его. Используемый файл json должен быть таким, чтобы координаты были в продолжении. Например —
https://vector.maps.elastic.co/blob/5659313586569216?elastic_tile_service_tos=agree
Вкладка параметров, когда данные векторной карты региона размещаются самостоятельно, показана ниже —
Кибана — работа с манерой и целями
Визуализация датчика показывает, как ваша метрика, рассматриваемая на данных, попадает в предопределенный диапазон.
Визуализация цели рассказывает о вашей цели и о том, как ваша метрика в ваших данных продвигается к цели.
Работа с калибром
Чтобы начать использовать Gauge, перейдите к визуализации и выберите вкладку «Визуализация» в пользовательском интерфейсе Kibana.
Нажмите на Gauge и выберите индекс, который вы хотите использовать.
Собираемся работать по медицинскому посещению — индекс 26.01.2019 .
Выберите временной диапазон февраля 2017
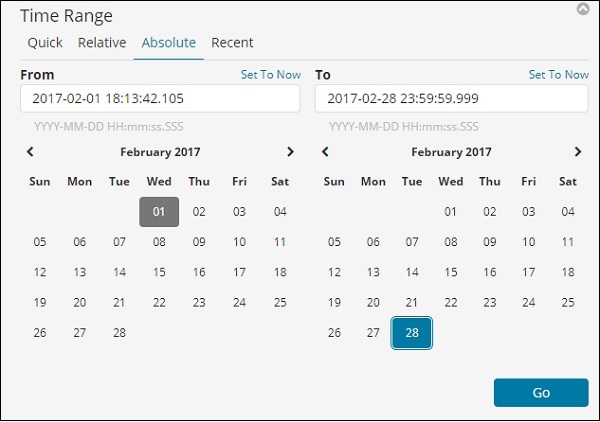
Теперь вы можете выбрать метрику и совокупность сегментов.
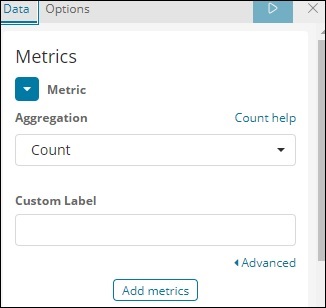
Мы выбрали агрегацию метрик в качестве количества.
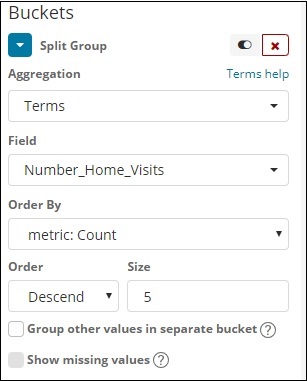
Агрегирование сегмента, которое мы выбрали Термины, и поле, выбранное Number_Home_Visits.
На вкладке Параметры данных выбранные параметры показаны ниже —
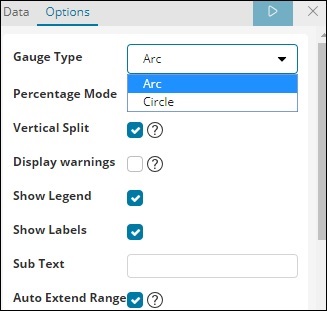
Тип датчика может быть в форме круга или дуги. Мы выбрали в качестве дуги и оставим все остальные в качестве значений по умолчанию.
Предопределенный диапазон, который мы добавили, показан здесь —
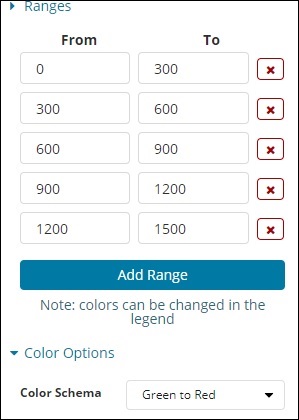
Цвет выбран зеленый к красному.
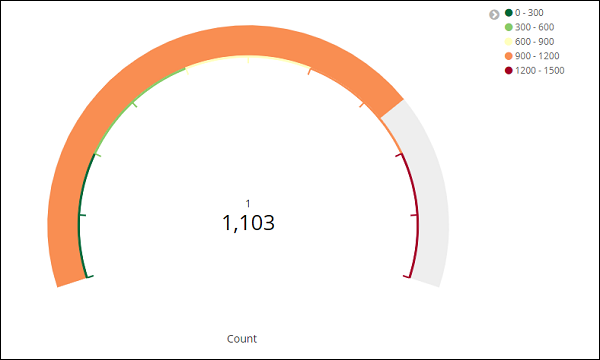
Теперь, нажмите кнопку «Анализ», чтобы увидеть визуализацию в форме датчика, как показано ниже —
Работа с целью
Перейдите на вкладку «Визуализация» и выберите «Цель», как показано ниже —
Выберите Цель и выберите индекс.
Использовать medicalvisits-26.01.2019 в качестве индекса.
Выберите агрегирование метрик и группирование.
Метрическая агрегация
Мы выбрали количество в качестве метрической агрегации.
Агрегация ковшей
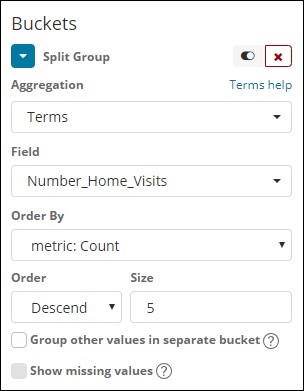
Мы выбрали Термины как совокупность сегментов, и поле Number_Home_Visits.
Выбранные параметры следующие:
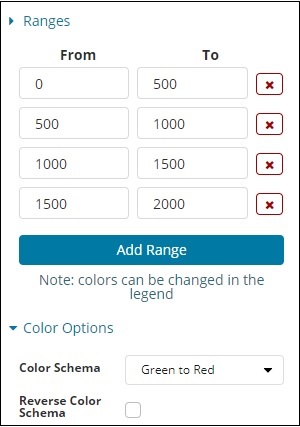
Выбранный диапазон выглядит следующим образом:
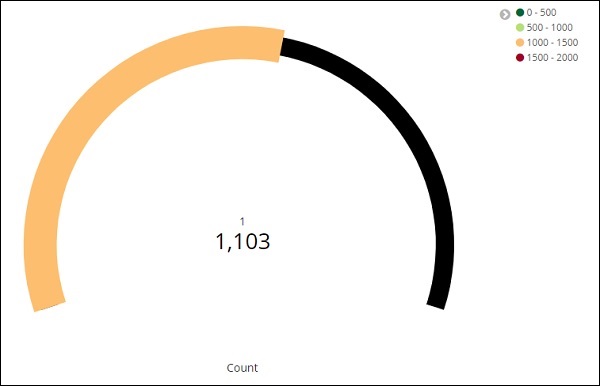
Нажмите «Анализ», и вы увидите, что цель отображается следующим образом:
Кибана — работа с холстом
Холст — еще одна мощная особенность в Кибане. Используя визуализацию холста, вы можете представлять свои данные в различных цветовых сочетаниях, формах, тексте, многостраничных настройках и т. Д.
Нам нужны данные, чтобы показать на холсте. Теперь давайте загрузим некоторые образцы данных, уже имеющиеся в Кибане.
Загрузка образцов данных для создания холста
Чтобы получить пример данных, перейдите на домашнюю страницу Kibana и нажмите «Добавить пример данных», как показано ниже —

Нажмите «Загрузить набор данных» и панель управления Kibana. Вы попадете на экран, как показано ниже —
Нажмите кнопку «Добавить» для образцов заказов электронной коммерции. Загрузка данных примера займет некоторое время. После этого вы получите сообщение с предупреждением «Загружены образцы данных электронной коммерции».
Начало работы с Canvas Visualization
Теперь перейдите к визуализации холста, как показано ниже —
Нажмите на холст, и он покажет экран, как показано ниже —
Мы добавили примеры данных электронной коммерции и веб-трафика. Мы можем создать новый рабочий стол или использовать существующий.
Здесь мы выберем существующий. Выберите Имя рабочей панели для отслеживания доходов электронной коммерции, и появится экран, как показано ниже —
![]()
Клонирование существующей рабочей панели в Canvas
Мы будем клонировать рабочую панель, чтобы внести в нее изменения. Чтобы клонировать существующую рабочую панель, нажмите на имя рабочей панели, показанной слева внизу —
Нажмите на имя и выберите опцию клонирования, как показано ниже —
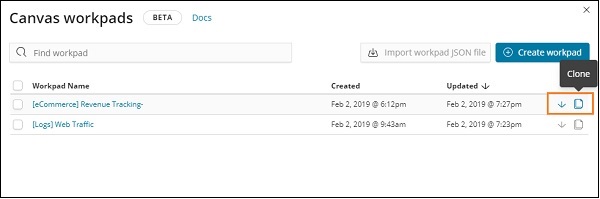
Нажмите на кнопку клонирования, и она создаст копию рабочей панели отслеживания доходов электронной торговли. Вы можете найти его, как показано ниже —
В этом разделе давайте разберемся, как пользоваться рабочим столом. Если вы видите выше рабочий стол, есть 2 страницы для него. Таким образом, на холсте мы можем представить данные на нескольких страницах.
Отображение страницы 2 показано ниже —

Выберите страницу 1 и нажмите на общий объем продаж, показанный слева, как показано ниже —
На правой стороне вы получите данные, связанные с ним —
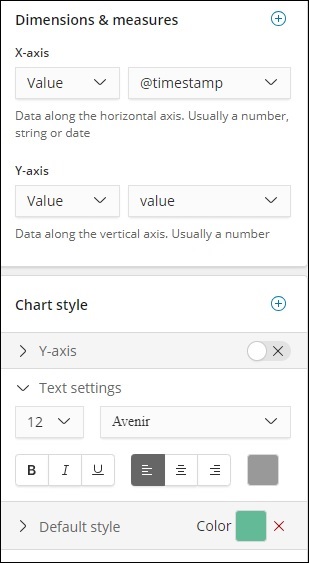
Прямо сейчас используется стиль по умолчанию зеленого цвета. Мы можем изменить цвет здесь и проверить отображение так же.
Мы также изменили шрифт и размер для настроек текста, как показано ниже —
Добавление новой страницы на рабочий стол внутри Canvas
Чтобы добавить новую страницу в рабочую панель, сделайте, как показано ниже —
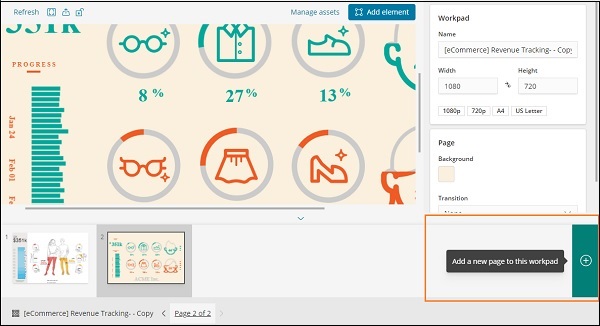
Как только страница создана, как показано ниже —
Нажмите на элемент Добавить, и он отобразит все возможные визуализации, как показано ниже —
Мы добавили два элемента Data table и Area Chart, как показано ниже
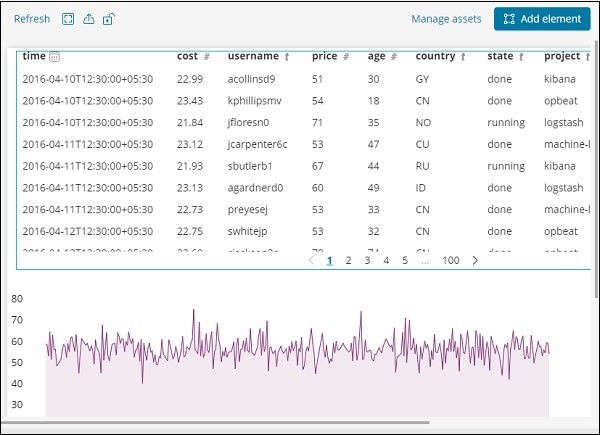
Вы можете добавить больше элементов данных на ту же страницу или добавить больше страниц.
Kibana — Создать панель инструментов
В наших предыдущих главах мы видели, как создавать визуализацию в форме вертикальной, горизонтальной, круговой диаграмм и т. Д. В этой главе мы узнаем, как объединить их в виде панели мониторинга. Панель инструментов — это коллекция созданных вами визуализаций, так что вы можете взглянуть на все это одновременно.
Начало работы с Dashboard
Чтобы создать Dashboard в Kibana, нажмите на опцию Dashboard, доступную, как показано ниже —
Теперь нажмите кнопку Создать новую панель, как показано выше. Это приведет нас к экрану, как показано ниже —
Заметьте, что у нас пока нет созданной панели инструментов. Вверху есть параметры, в которых мы можем сохранить, отменить, добавить, параметры, поделиться, автоматическое обновление, а также изменить время для получения данных на нашей информационной панели. Мы создадим новую панель мониторинга, нажав на кнопку «Добавить», показанную выше.
Добавить визуализацию на панель инструментов
Когда мы нажимаем кнопку «Добавить» (верхний левый угол), она отображает нам визуализацию, которую мы создали, как показано ниже —
Выберите визуализацию, которую вы хотите добавить на свою панель инструментов. Мы выберем первые три визуализации, как показано ниже —
Вот как это видно на экране вместе —
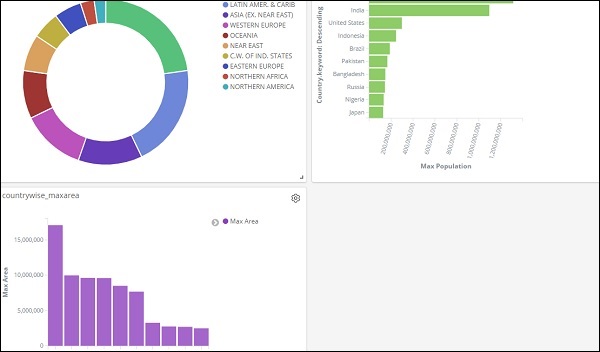
Таким образом, как пользователь, вы можете получить общую информацию о загруженных нами данных — в зависимости от страны с полями название страны, регион, район и население.
Итак, теперь мы знаем все доступные регионы, максимальную численность населения страны в порядке убывания, максимальную площадь и т. Д.
Это всего лишь пример визуализации данных, который мы загрузили, но в реальном мире становится очень просто отслеживать детали вашего бизнеса, например, если у вас есть веб-сайт, который получает миллионы посещений в месяц или ежедневно, вы хотите отслеживать продажи выполняется каждый день, час, минуту, секунды, и если у вас есть свой стек ELK, Kibana может показывать вам визуализацию продаж прямо перед вашими глазами каждый час, минуту, секунду, как вы хотите видеть. Он отображает данные в реальном времени, как это происходит в реальном мире.
Kibana, в целом, играет очень важную роль в извлечении точных подробностей о вашей бизнес-транзакции за день, час или каждую минуту, поэтому компания знает, как идет работа.
Сохранить панель инструментов
Вы можете сохранить панель инструментов, используя кнопку «Сохранить» вверху.
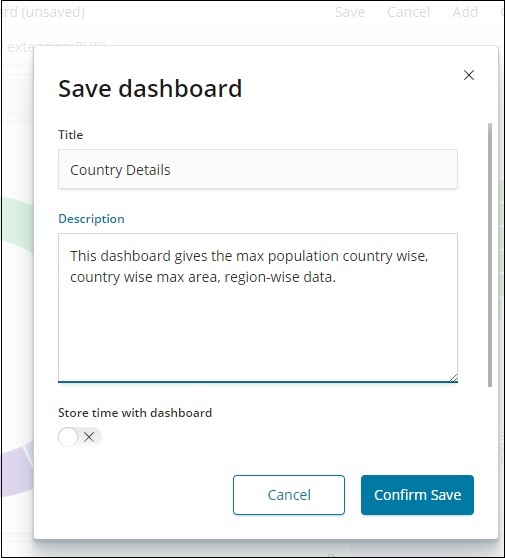
Существует заголовок и описание, где вы можете ввести имя панели мониторинга и краткое описание, в котором рассказывается, что делает панель мониторинга. Теперь нажмите «Подтвердить сохранение», чтобы сохранить панель управления.
Изменение диапазона времени для панели инструментов
В настоящее время вы можете увидеть данные за последние 15 минут. Обратите внимание, что это статические данные без какого-либо временного поля, поэтому отображаемые данные не изменятся. Когда у вас есть данные, подключенные к системе реального времени, меняющие время, также будут отображаться данные, отражающие.
По умолчанию вы увидите последние 15 минут, как показано ниже —
Нажмите на последние 15 минут, и он покажет вам временной диапазон, который вы можете выбрать согласно вашему выбору.
Обратите внимание, что есть варианты Быстрая, Относительная, Абсолютная и Недавняя. На следующем снимке экрана показаны детали для опции Quick —
Теперь нажмите на Относительный, чтобы увидеть доступную опцию —
Здесь вы можете указать дату и время в минутах, часах, секундах, месяцах, годах назад.
Опция Абсолют имеет следующие детали —
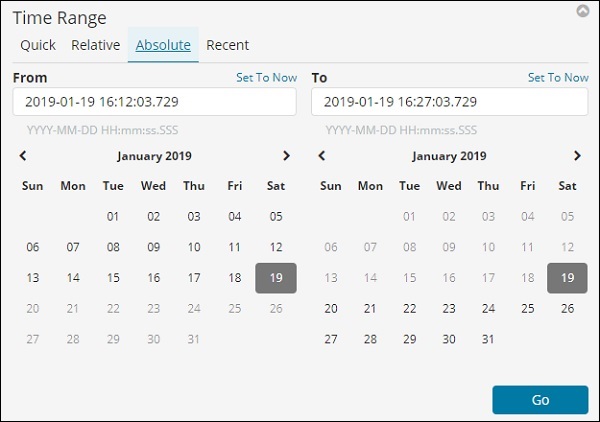
Вы можете увидеть опцию календаря и можете выбрать диапазон дат.
Последняя опция вернет опцию «Последние 15 минут», а также другую опцию, которую вы выбрали недавно. Выбор временного диапазона обновит данные, поступающие в этот временной диапазон.
Использование поиска и фильтра на панели инструментов
Мы также можем использовать поиск и фильтр на панели инструментов. В поиске предположим, что если мы хотим получить подробную информацию о конкретном регионе, мы можем добавить поиск, как показано ниже —

В приведенном выше поиске мы использовали поле Регион и хотим отобразить детали региона: ОКЕАНИЯ.
Мы получаем следующие результаты —
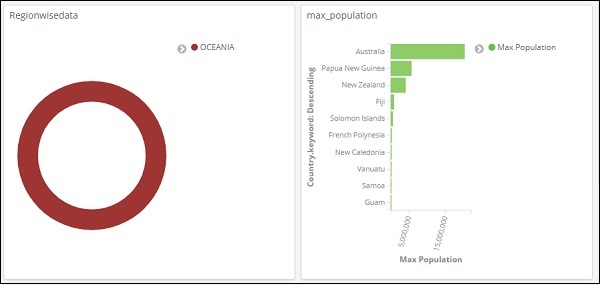
Глядя на приведенные выше данные, мы можем сказать, что в регионе Океания, Австралия имеет максимальное население и площадь.
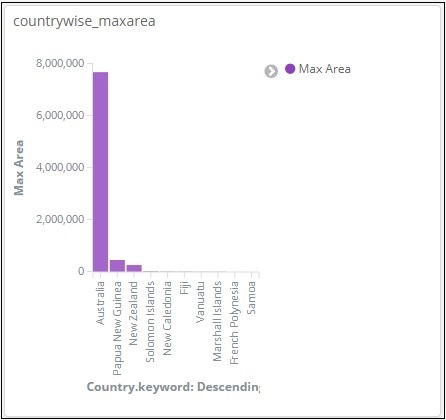
Точно так же мы можем добавить фильтр, как показано ниже —
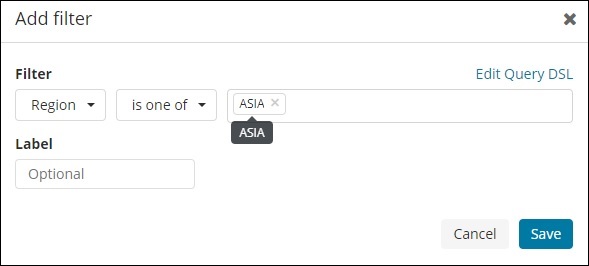
Затем нажмите кнопку Добавить фильтр, и она отобразит подробную информацию о поле, доступном в вашем индексе, как показано ниже —
Выберите поле, по которому вы хотите фильтровать. Я буду использовать поле Регион, чтобы получить подробную информацию о регионе ASIA, как показано ниже —
Сохраните фильтр, и вы должны увидеть фильтр следующим образом —
Данные теперь будут отображаться согласно добавленному фильтру —
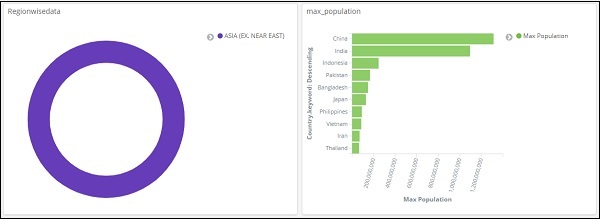
Вы также можете добавить больше фильтров, как показано ниже —
Вы можете отключить фильтр, установив флажок отключения, как показано ниже.

Вы можете активировать фильтр, нажав на этот же флажок, чтобы активировать его. Обратите внимание, что есть кнопка удаления, чтобы удалить фильтр. Кнопка Изменить, чтобы редактировать фильтр или изменить параметры фильтра.
Для отображаемой визуализации вы заметите три точки, как показано ниже —
Нажмите на него, и он покажет параметры, как показано ниже —
Осмотреть и полноэкранный
Нажмите на Inspect, и он даст подробную информацию о регионе в табличном формате, как показано ниже —
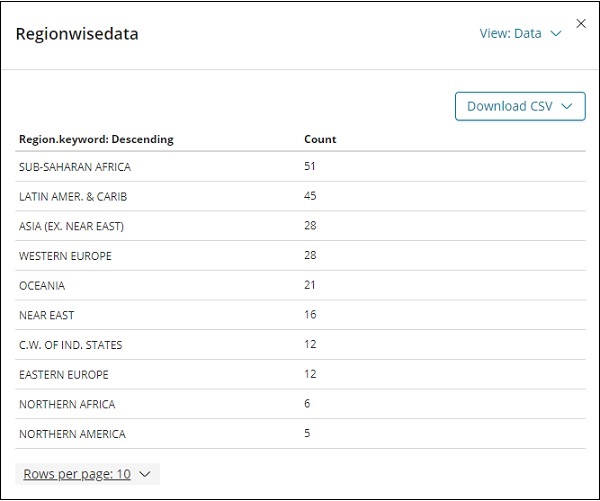
Существует возможность загрузить визуализацию в формате CSV на тот случай, если вы хотите увидеть ее в листе Excel.
Следующая опция fullscreen получит визуализацию в полноэкранном режиме, как показано ниже —
Вы можете использовать ту же кнопку, чтобы выйти из полноэкранного режима.
Обмен приборной панелью
Мы можем поделиться приборной панелью, используя кнопку поделиться. Нажав на кнопку «Поделиться», вы увидите следующее:
Вы также можете использовать код для встраивания, чтобы показать панель управления на своем сайте, или использовать постоянные ссылки, которые будут ссылками, которыми можно поделиться с другими.
URL будет следующим —
http://localhost:5601/goto/519c1a088d5d0f8703937d754923b84b
Кибана — Timelion
Timelion, также называемый временной шкалой, является еще одним инструментом визуализации, который в основном используется для анализа данных на основе времени. Для работы с временной шкалой нам нужно использовать простой язык выражений, который поможет нам подключиться к индексу, а также выполнить вычисления для данных, чтобы получить нужные нам результаты.
Где мы можем использовать Timelion?
Timelion используется, когда вы хотите сравнить данные, связанные со временем. Например, у вас есть сайт, и вы ежедневно просматриваете его. Вы хотите проанализировать данные, в которых вы хотите сравнить данные текущей недели с предыдущей неделей, т. Е. Понедельник-понедельник, вторник-вторник и т. Д., На предмет различий между представлениями и трафиком.
Начало работы с Timelion
Чтобы начать работать с Timelion, нажмите Timelion, как показано ниже —

Timelion по умолчанию показывает временную шкалу всех индексов, как показано ниже —
Timelion работает с синтаксисом выражений.
Примечание — es (*) => означает все индексы.
Чтобы получить подробную информацию о функции, доступной для использования с Timelion, просто нажмите на область текста, как показано ниже —

Он дает вам список функций, которые будут использоваться с синтаксисом выражения.
Как только вы начинаете с Timelion, он отображает приветственное сообщение, как показано ниже. Выделенный раздел, т. Е. Переход к справочнику функций, дает подробную информацию обо всех функциях, доступных для использования с timelion.
Timelion Приветственное сообщение
Приветственное сообщение Timelion показано ниже:
Нажмите на следующую кнопку, и он проведет вас через его основные функциональные возможности и использование. Теперь, когда вы нажимаете кнопку Далее, вы можете увидеть следующие детали —
Справочник по функции Timelion
Нажмите на кнопку Справка, чтобы получить подробную информацию о функции, доступной для Timelion —
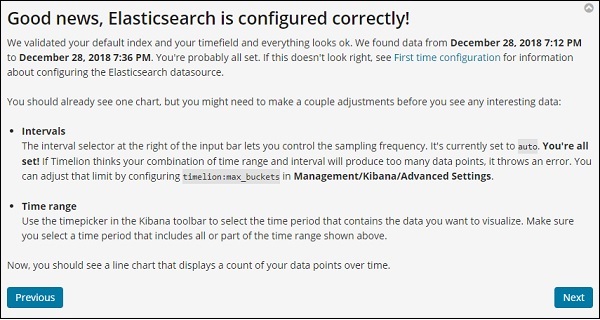
Конфигурация Timelion
Настройки для timelion выполняются в Kibana Management → Расширенные настройки.
Нажмите на Дополнительные настройки и выберите Timelion из категории
После выбора Timelion отобразятся все необходимые поля, необходимые для настройки Timelion.
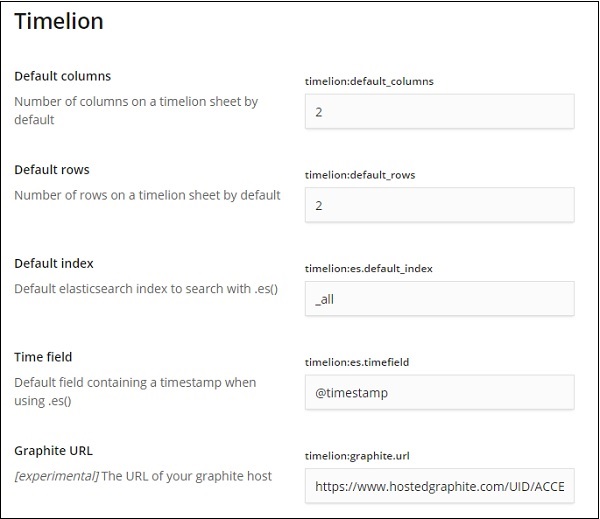
В следующих полях вы можете изменить индекс по умолчанию и поле времени, которое будет использоваться в индексе:
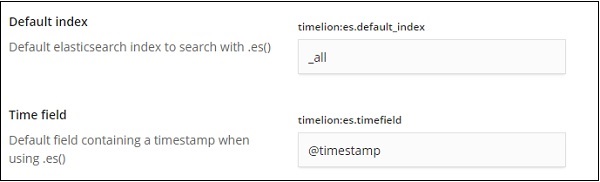
По умолчанию это _all, а timefield — @timestamp. Мы оставили бы все как есть и изменили бы индекс и временное поле в самом таймлионе.
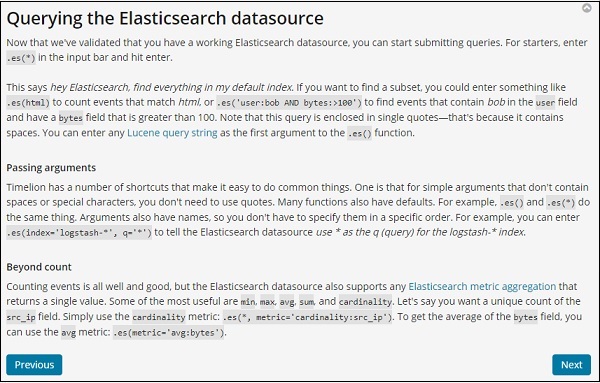
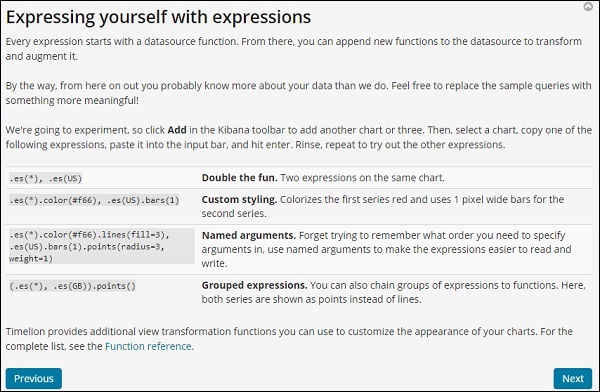
Использование Timelion для визуализации данных
Мы собираемся использовать индекс: medicalvisits-26.01.2019 . Ниже приведены данные, отображаемые с временной шкалы за 1 января 2017 года по 31 декабря 2017 года.
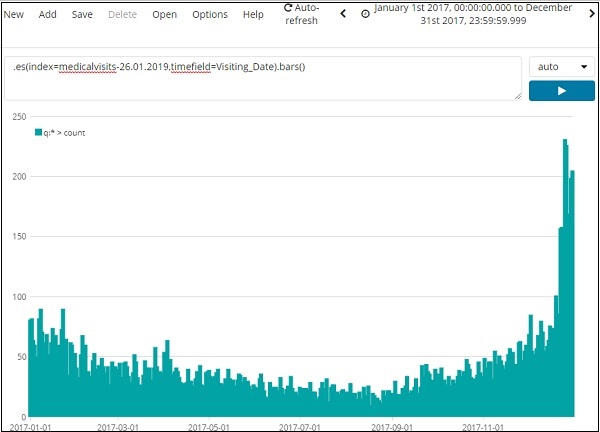
Выражение, используемое для приведенной выше визуализации, выглядит следующим образом:
.es(index=medicalvisits-26.01.2019,timefield=Visiting_Date).bars()
Мы использовали индекс medicalvisits-26.01.2019, а временным полем для этого индекса является Visiting_Date и использовалась функция баров.
Ниже мы проанализировали 2 города за январь 2017 года, по дням.
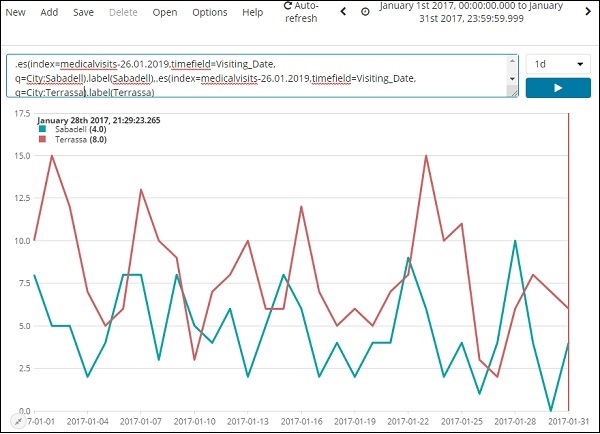
Используемое выражение —
.es(index=medicalvisits-26.01.2019,timefield=Visiting_Date, q=City:Sabadell).label(Sabadell),.es(index=medicalvisits-26.01.2019, timefield=Visiting_Date, q=City:Terrassa).label(Terrassa)
Сравнение сроков на 2 дня показано здесь —
выражение
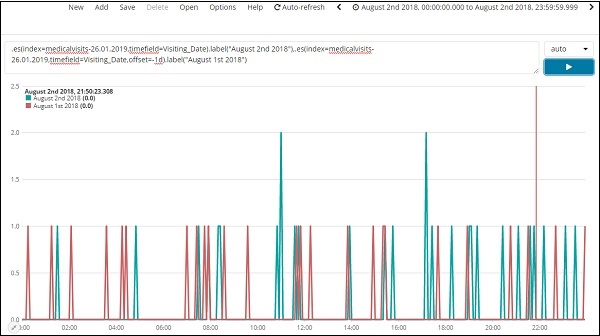
.es(index=medicalvisits-26.01.2019,timefield=Visiting_Date).label("August 2nd 2018"),
.es(index=medicalvisits-26.01.2019,timefield=Visiting_Date,offset=-1d).label("August 1st 2018")
Здесь мы использовали смещение и дали разницу в 1 день. Мы выбрали текущую дату 2 августа 2018 года. Таким образом, она дает разницу в данных за 2 августа 2018 года и 1 августа 2018 года.
Список 5 лучших городов за январь 2017 года представлен ниже. Выражение, которое мы здесь использовали, приведено ниже —
.es(index=medicalvisits-26.01.2019,timefield=Visiting_Date,split=City.keyword:5)
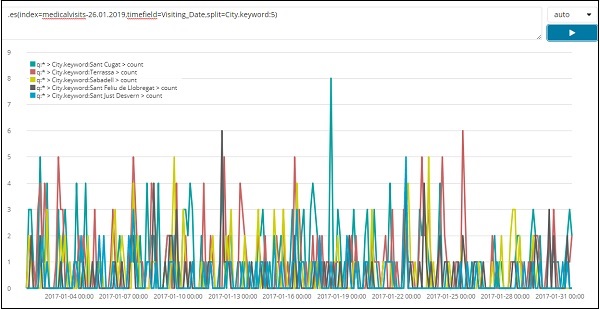
Мы использовали split и дали имя поля в качестве city, и поскольку нам нужны первые пять городов из индекса, мы дали его в виде split = City.keyword: 5
Он дает счетчик каждого города и перечисляет их названия, как показано на графике.
Kibana — Dev Tools
Мы можем использовать Dev Tools для загрузки данных в Elasticsearch, без использования Logstash. Мы можем публиковать, размещать, удалять, искать нужные нам данные в Kibana, используя Dev Tools.
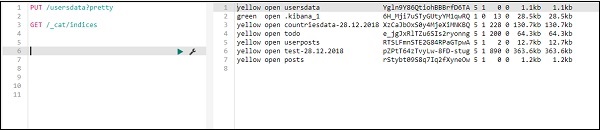
Для создания нового индекса в Kibana мы можем использовать следующую команду в dev tools —
Создать индекс с помощью PUT
Команда для создания индекса, как показано здесь —
PUT /usersdata?pretty
Как только вы выполните это, создается пустой индекс пользовательских данных.
Мы закончили с созданием индекса. Теперь добавим данные в индекс —
Добавить данные в индекс с помощью PUT
Вы можете добавить данные в индекс следующим образом:

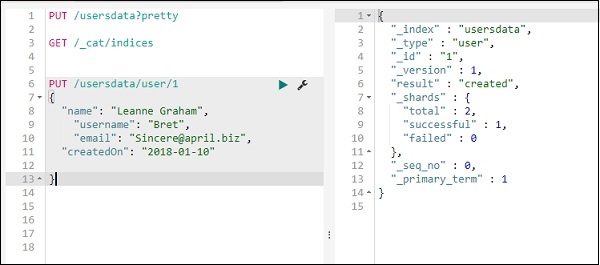
Мы добавим еще одну запись в индекс userdata —
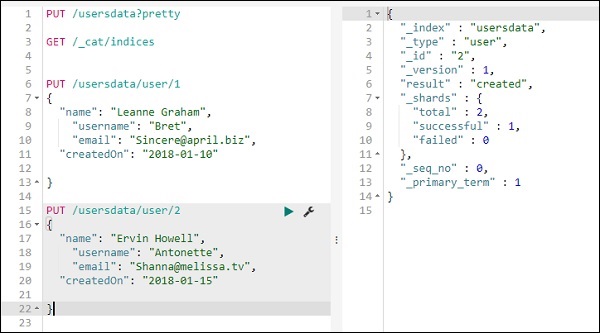
Итак, у нас есть 2 записи в индексе usersdata.
Получить данные из индекса с помощью GET
Мы можем получить детали записи 1 следующим образом:
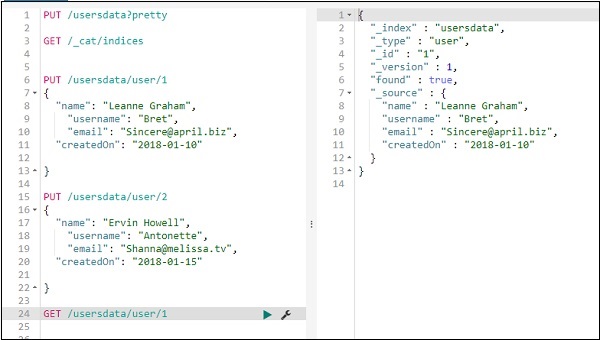
Вы можете получить все записи следующим образом —
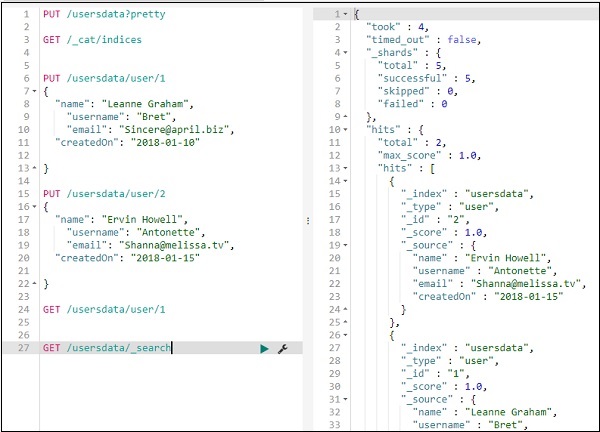
Таким образом, мы можем получить все записи из usersdata, как показано выше.
Обновить данные в индексе с помощью PUT
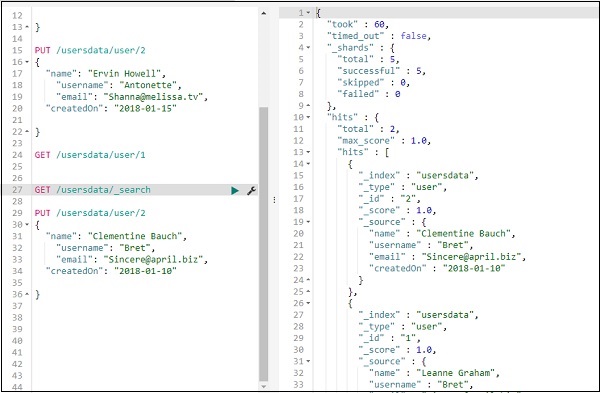
Чтобы обновить запись, вы можете сделать следующее:
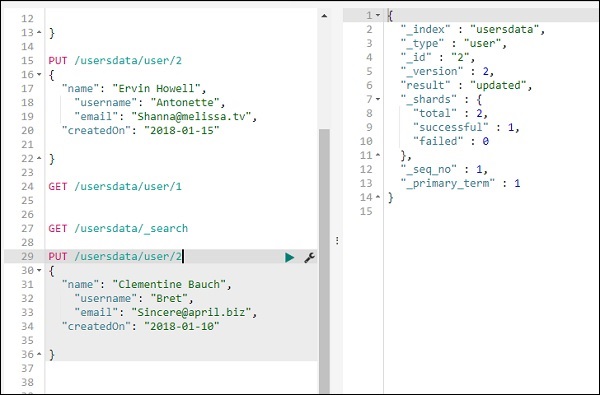
Мы изменили название с «Эрвин Хауэлл» на «Клементина Бауч». Теперь мы можем получить все записи из индекса и увидеть обновленную запись следующим образом:
Удалить данные из индекса, используя DELETE
Вы можете удалить запись, как показано здесь —
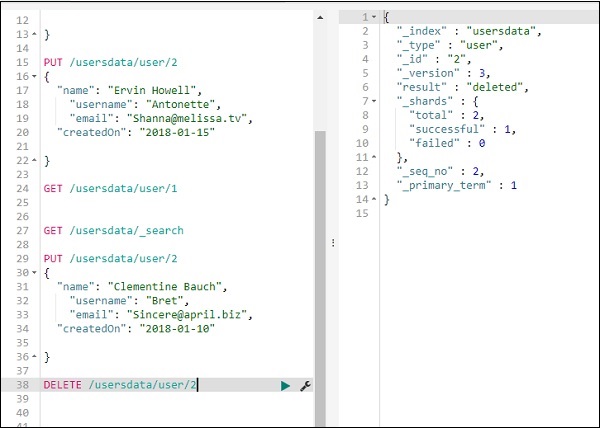
Теперь, если вы увидите общее количество записей, у нас будет только одна запись —
Мы можем удалить индекс, созданный следующим образом —
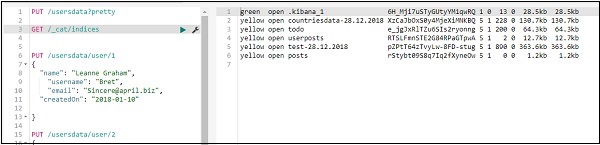
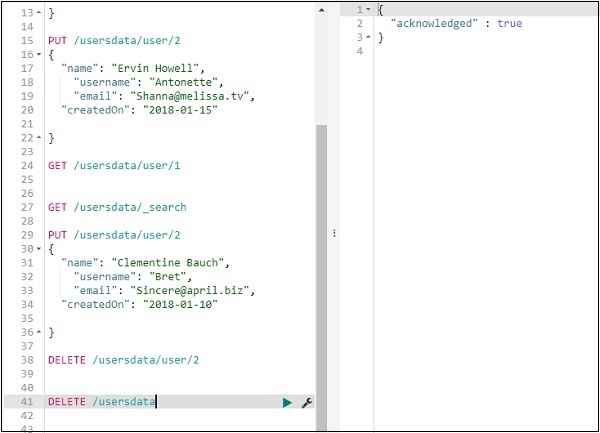
Теперь, если вы проверите доступные индексы, у нас не будет индекса данных пользователя, поскольку он был удален.
Кибана — Мониторинг
Kibana Monitoring дает подробную информацию о производительности стека ELK. Мы можем получить подробную информацию об используемой памяти, времени отклика и т. Д.
Детали мониторинга
Чтобы получить подробную информацию о мониторинге в Kibana, нажмите на вкладку мониторинга, как показано ниже —
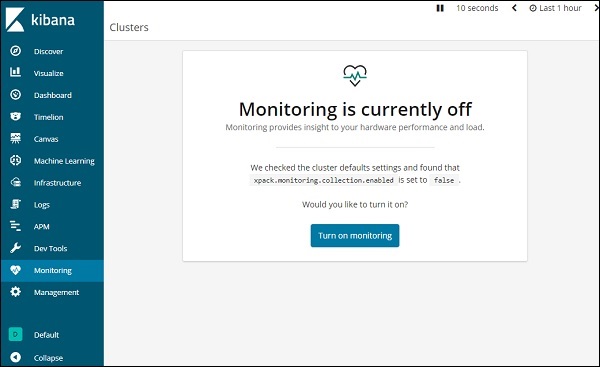
Поскольку мы используем мониторинг впервые, нам нужно его включить. Для этого нажмите кнопку Включить мониторинг, как показано выше. Вот детали, отображаемые для Elasticsearch —
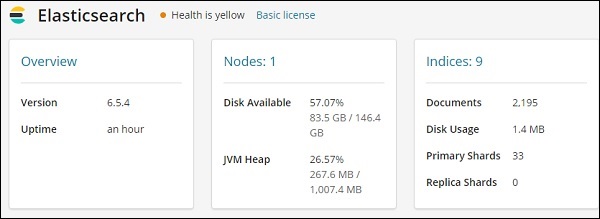
Он предоставляет версию эластичного поиска, доступный диск, индексы, добавленные к эластичному поиску, использование диска и т. Д.
Детали мониторинга для Кибана показаны здесь —
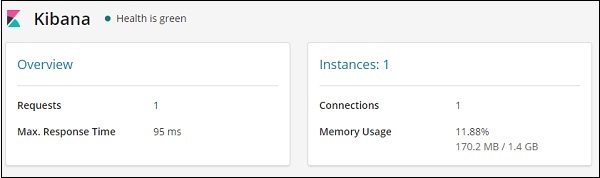
Он дает запросы и максимальное время ответа на запрос, а также запущенные экземпляры и использование памяти.
Kibana — Создание отчетов с использованием Kibana
Отчеты могут быть легко созданы с помощью кнопки «Поделиться», доступной в пользовательском интерфейсе Kibana.
Отчеты в Кибане доступны в следующих двух формах —
- Permalinks
- CSV отчет
Сообщить как постоянные ссылки
Выполняя визуализацию, вы можете делиться так же, как показано ниже:
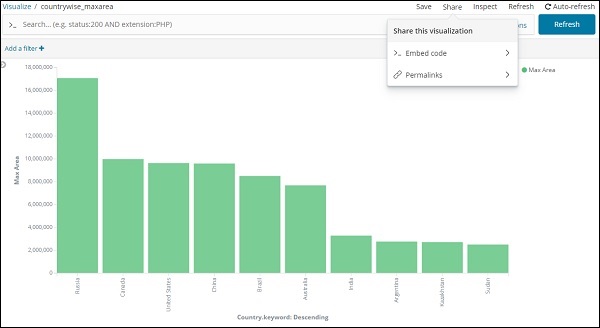
Используйте кнопку «Поделиться», чтобы поделиться визуализацией с другими в качестве кода вставки или постоянных ссылок.
В случае встраивания кода вы получаете следующие опции —
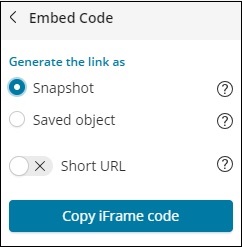
Вы можете создать код iframe в виде короткого или длинного URL для снимка или сохраненного объекта. Снимок не предоставит последние данные, и пользователь сможет увидеть данные, сохраненные, когда ссылка была опубликована. Любые изменения, сделанные позже, не будут отражены.
В случае сохраненного объекта вы получите последние изменения, внесенные в эту визуализацию.
Код снимка IFrame для длинного URL —
<iframe src="http://localhost:5601/app/kibana#/visualize/edit/87af cb60-165f-11e9-aaf1-3524d1f04792?embed=true&_g=()&_a=(filters:!(),linked:!f,query:(language:lucene,query:''), uiState:(),vis:(aggs:!((enabled:!t,id:'1',params:(field:Area),schema:metric,type:max),(enabled:!t,id:'2',p arams:(field:Country.keyword,missingBucket:!f,missingBucketLabel:Missing,order:desc,orderBy:'1',otherBucket:! f,otherBucketLabel:Other,size:10),schema:segment,type:terms)),params:(addLegend:!t,addTimeMarker:!f,addToo ltip:!t,categoryAxes:!((id:CategoryAxis-1,labels:(show:!t,truncate:100),position:bottom,scale:(type:linear), show:!t,style:(),title:(),type:category)),grid:(categoryLines:!f,style:(color:%23eee)),legendPosition:right, seriesParams:!((data:(id:'1',label:'Max+Area'),drawLi nesBetweenPoints:!t,mode:stacked,show:true,showCircles:!t,type:histogram,valueAxis:ValueAxis-1)),times:!(), type:histogram,valueAxes:!((id:ValueAxis-1,labels:(filter:!f,rotate:0,show:!t,truncate:100),name:LeftAxis-1, position:left,scale:(mode:normal,type:linear),show:!t,style:(),title:(text:'Max+Area'),type:value))),title: 'countrywise_maxarea+',type:histogram))" height="600" width="800"></iframe>
Снимок кода Iframe для короткого URL —
<iframe src="http://localhost:5601/goto/f0a6c852daedcb6b4fa74cce8c2ff6c4?embed=true" height="600" width="800"><iframe>
Как снимок и выстрелил URL.
С коротким URL —
http://localhost:5601/goto/f0a6c852daedcb6b4fa74cce8c2ff6c4
Если короткий URL отключен, ссылка выглядит так:
http://localhost:5601/app/kibana#/visualize/edit/87afcb60-165f-11e9-aaf1-3524d1f04792?_g=()&_a=(filters:!( ),linked:!f,query:(language:lucene,query:''),uiState:(),vis:(aggs:!((enabled:!t,id:'1',params:(field:Area), schema:metric,type:max),(enabled:!t,id:'2',params:(field:Country.keyword,missingBucket:!f,missingBucketLabel: Missing,order:desc,orderBy:'1',otherBucket:!f,otherBucketLabel:Other,size:10),schema:segment,type:terms)), params:(addLegend:!t,addTimeMarker:!f,addTooltip:!t,categoryAxes:!((id:CategoryAxis-1,labels:(show:!t,trun cate:100),position:bottom,scale:(type:linear),show:!t,style:(),title:(),type:category)),grid:(categoryLine s:!f,style:(color:%23eee)),legendPosition:right,seriesParams:!((data:(id:'1',label:'Max%20Area'),drawLines BetweenPoints:!t,mode:stacked,show:true,showCircles:!t,type:histogram,valueAxis:ValueAxis-1)),times:!(), type:histogram,valueAxes:!((id:ValueAxis-1,labels:(filter:!f,rotate:0,show:!t,truncate:100),name:LeftAxis-1, position:left,scale:(mode:normal,type:linear),show:!t,style:(),title:(text:'Max%20Area'),type:value))),title:'countrywise_maxarea%20',type:histogram))
Когда вы нажмете на ссылку выше в браузере, вы получите ту же визуализацию, как показано выше. Приведенные выше ссылки размещаются локально, поэтому они не будут работать при использовании вне локальной среды.
CSV отчет
Вы можете получить отчет CSV в Кибане, где есть данные, которые в основном находятся на вкладке Обнаружение.
Перейдите на вкладку «Обнаружение» и выберите любой индекс, для которого вы хотите получить данные. Здесь мы взяли индекс: странданные-26.12.2018 . Вот данные, отображаемые из индекса —

Вы можете создавать табличные данные из данных выше, как показано ниже —
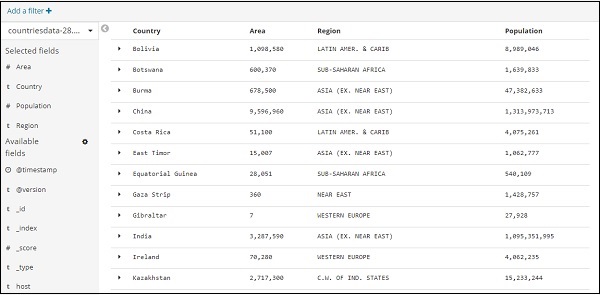
Мы выбрали поля из списка Доступные поля, а ранее просмотренные данные преобразуются в табличный формат.
Вы можете получить вышеуказанные данные в отчете CSV, как показано ниже —
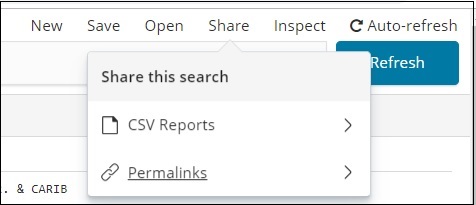
Кнопка «Поделиться» имеет опцию для отчета CSV и постоянные ссылки. Вы можете нажать на отчет CSV и скачать его.
Обратите внимание, чтобы получить отчеты CSV, необходимые для сохранения ваших данных.
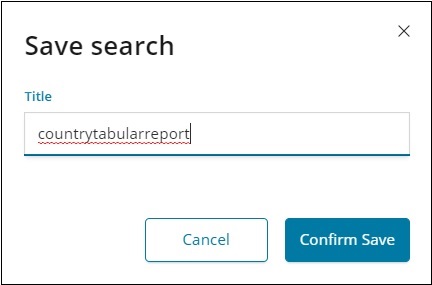
Подтвердите сохранение и нажмите кнопку «Поделиться» и отчеты CSV. Вы получите следующий дисплей —
Нажмите «Создать CSV», чтобы получить отчет. После этого он попросит вас перейти на вкладку управления.
Перейдите на вкладку «Управление» → «Отчеты».
Он отображает имя отчета, созданный в, статус и действия. Вы можете нажать на кнопку загрузки, как указано выше, и получить отчет CSV.
Файл CSV, который мы только что скачали, показан здесь —