Язык — это способ общения, с помощью которого мы можем говорить, читать и писать. Например, мы думаем, мы принимаем решения, планы и многое другое на естественном языке; точно, на словах. Однако, большой вопрос, который стоит перед нами в эту эпоху ИИ, заключается в том, можем ли мы так же общаться с компьютерами. Другими словами, могут ли люди общаться с компьютерами на их естественном языке? Для нас непросто разрабатывать приложения НЛП, поскольку компьютерам нужны структурированные данные, но человеческая речь неструктурирована и часто неоднозначна по своей природе.
В этом смысле мы можем сказать, что обработка естественного языка (NLP) — это подразделение компьютерных наук, особенно искусственного интеллекта (ИИ), которое занимается предоставлением компьютерам возможности понимать и обрабатывать человеческий язык. Технически, основной задачей НЛП было бы программирование компьютеров для анализа и обработки огромного количества данных на естественном языке.
История НЛП
Мы разделили историю НЛП на четыре этапа. Фазы имеют отличительные проблемы и стили.
Первая фаза (фаза машинного перевода) — конец 1940-х — конец 1960-х годов
Работа, проделанная на этом этапе, была сосредоточена главным образом на машинном переводе (MT). Этот этап был периодом энтузиазма и оптимизма.
Давайте теперь посмотрим, что было на первом этапе —
-
Исследование НЛП началось в начале 1950-х годов после расследования Бута и Риченса и меморандума Уивера по машинному переводу в 1949 году.
-
1954 год был годом, когда в эксперименте Джорджтаун-IBM был продемонстрирован ограниченный эксперимент по автоматическому переводу с русского на английский.
-
В том же году началась публикация журнала MT (Machine Translation).
-
Первая международная конференция по машинному переводу (МТ) состоялась в 1952 году, а вторая — в 1956 году.
-
В 1961 году кульминацией этого этапа стала работа, представленная на Международной конференции по машинному переводу языков и прикладному языку в Теддингтоне.
Исследование НЛП началось в начале 1950-х годов после расследования Бута и Риченса и меморандума Уивера по машинному переводу в 1949 году.
1954 год был годом, когда в эксперименте Джорджтаун-IBM был продемонстрирован ограниченный эксперимент по автоматическому переводу с русского на английский.
В том же году началась публикация журнала MT (Machine Translation).
Первая международная конференция по машинному переводу (МТ) состоялась в 1952 году, а вторая — в 1956 году.
В 1961 году кульминацией этого этапа стала работа, представленная на Международной конференции по машинному переводу языков и прикладному языку в Теддингтоне.
Вторая фаза (фаза влияния ИИ) — конец 1960-х — конец 1970-х годов
На этом этапе проделанная работа была в основном связана с мировым знанием и его ролью в построении и манипулировании смысловыми представлениями. Вот почему эта фаза также называется AI-ароматизированной фазой.
Этап был в нем, следующее —
-
В начале 1961 года началась работа над проблемами решения и построения базы данных или знаний. Эта работа была под влиянием AI.
-
В том же году была разработана система ответов на вопросы BASEBALL. Вход в эту систему был ограничен, и языковая обработка была простой.
-
Очень продвинутая система была описана в Минском (1968). Эта система, по сравнению с системой ответов на вопросы BASEBALL, была признана и предусмотрена для необходимости определения базы знаний при интерпретации и реагировании на ввод языка.
В начале 1961 года началась работа над проблемами решения и построения базы данных или знаний. Эта работа была под влиянием AI.
В том же году была разработана система ответов на вопросы BASEBALL. Вход в эту систему был ограничен, и языковая обработка была простой.
Очень продвинутая система была описана в Минском (1968). Эта система, по сравнению с системой ответов на вопросы BASEBALL, была признана и предусмотрена для необходимости определения базы знаний при интерпретации и реагировании на ввод языка.
Третья фаза (грамматико-логическая фаза) — конец 1970-х — конец 1980-х годов
Эта фаза может быть описана как грамматико-логическая фаза. Из-за неудачи практического построения системы на последнем этапе исследователи перешли к использованию логики для представления знаний и рассуждения в ИИ.
На третьем этапе было следующее:
-
Грамматико-логический подход к концу десятилетия помог нам с мощными процессорами предложений общего назначения, такими как Core Language Engine и Теория репрезентации дискурса, которые предлагали средства для решения более расширенного дискурса.
-
На этом этапе мы получили некоторые практические ресурсы и инструменты, такие как парсеры, например Alvey Natural Language Tools, а также более оперативные и коммерческие системы, например, для запросов к базе данных.
-
Работа над лексикой в 1980-х годах также указала в направлении грамматического подхода.
Грамматико-логический подход к концу десятилетия помог нам с мощными процессорами предложений общего назначения, такими как Core Language Engine и Теория репрезентации дискурса, которые предлагали средства для решения более расширенного дискурса.
На этом этапе мы получили некоторые практические ресурсы и инструменты, такие как парсеры, например Alvey Natural Language Tools, а также более оперативные и коммерческие системы, например, для запросов к базе данных.
Работа над лексикой в 1980-х годах также указала в направлении грамматического подхода.
Четвертая фаза (Lexical & Corpus Phase) — 1990-е годы
Мы можем описать это как лексическую и корпусную фазу. Эта фаза имела лексический подход к грамматике, который появился в конце 1980-х годов и приобрел все большее влияние. В этом десятилетии произошла революция в обработке естественного языка с введением алгоритмов машинного обучения для обработки языка.
Изучение человеческих языков
Язык является важнейшим компонентом человеческой жизни, а также самым фундаментальным аспектом нашего поведения. Мы можем испытать это в основном в двух формах — письменной и устной. В письменной форме это способ передать наши знания из поколения в поколение. В разговорной форме это является первичной средой для координации людей друг с другом в их повседневном поведении. Язык изучается в различных академических дисциплинах. Каждая дисциплина имеет свой собственный набор проблем и набор решений для их решения.
Рассмотрим следующую таблицу, чтобы понять это —
| дисциплина | Проблемы | инструменты |
|---|---|---|
|
Лингвисты |
Как фразы и предложения могут быть составлены из слов? Что ограничивает возможный смысл предложения? |
Интуиция о правильности и значении. Математическая модель строения. Например, теоретическая семантика модели, теория формального языка. |
|
психолингвистов |
Как люди могут определить структуру предложений? Как определить значение слов? Когда происходит понимание? |
Экспериментальные методы в основном для измерения производительности людей. Статистический анализ наблюдений. |
|
Философы |
Как слова и предложения приобретают смысл? Как объекты идентифицируются по словам? Что это значит? |
Аргументация естественного языка с помощью интуиции. Математические модели, такие как логика и теория моделей. |
|
Вычислительные лингвисты |
Как мы можем определить структуру предложения Как можно смоделировать знания и рассуждения? Как мы можем использовать язык для выполнения конкретных задач? |
Алгоритмы Структуры данных Формальные модели представления и рассуждения. AI методы, такие как методы поиска и представления. |
Лингвисты
Как фразы и предложения могут быть составлены из слов?
Что ограничивает возможный смысл предложения?
Интуиция о правильности и значении.
Математическая модель строения. Например, теоретическая семантика модели, теория формального языка.
психолингвистов
Как люди могут определить структуру предложений?
Как определить значение слов?
Когда происходит понимание?
Экспериментальные методы в основном для измерения производительности людей.
Статистический анализ наблюдений.
Философы
Как слова и предложения приобретают смысл?
Как объекты идентифицируются по словам?
Что это значит?
Аргументация естественного языка с помощью интуиции.
Математические модели, такие как логика и теория моделей.
Вычислительные лингвисты
Как мы можем определить структуру предложения
Как можно смоделировать знания и рассуждения?
Как мы можем использовать язык для выполнения конкретных задач?
Алгоритмы
Структуры данных
Формальные модели представления и рассуждения.
AI методы, такие как методы поиска и представления.
Неопределенность и неопределенность в языке
Неоднозначность, обычно используемая в обработке естественного языка, может быть названа как способность быть понятой более чем одним способом. Проще говоря, мы можем сказать, что двусмысленность — это способность быть понятой более чем одним способом. Естественный язык очень неоднозначен. НЛП имеет следующие виды неясностей —
Лексическая Неоднозначность
Неоднозначность одного слова называется лексической двусмысленностью. Например, рассматривая слово серебро как существительное, прилагательное или глагол.
Синтаксическая Неопределенность
Такая двусмысленность возникает, когда предложение разбирается по-разному. Например, предложение «Мужчина увидел девушку с телескопом». Не ясно, видел ли мужчина девушку с телескопом или видел ее через телескоп.
Семантическая двусмысленность
Такая двусмысленность возникает, когда значение самих слов может быть неправильно истолковано. Другими словами, семантическая неоднозначность возникает, когда предложение содержит неоднозначное слово или фразу. Например, предложение «Автомобиль врезался в столб, когда он двигался», имеет семантическую двусмысленность, потому что интерпретации могут быть такими: «Автомобиль, двигаясь, врезается в столб» и «Автомобиль врезался в столб, когда столб двигался».
Анафорическая Неоднозначность
Такая двусмысленность возникает из-за использования в дискурсе анафорных сущностей. Например, лошадь побежала в гору. Это было очень круто. Скоро надоело. Здесь анафорическая ссылка на «это» в двух ситуациях вызывает неоднозначность.
Прагматическая двусмысленность
Такая двусмысленность относится к ситуации, когда контекст фразы дает ей несколько толкований. Проще говоря, мы можем сказать, что прагматическая двусмысленность возникает, когда утверждение не является конкретным. Например, предложение «ты мне тоже нравишься» может иметь несколько толкований, как ты мне нравишься (так же, как я тебе нравлюсь), ты мне нравишься (точно так же, как кто-то другой).
Фазы НЛП
Следующая диаграмма показывает фазы или логические шаги в обработке естественного языка —
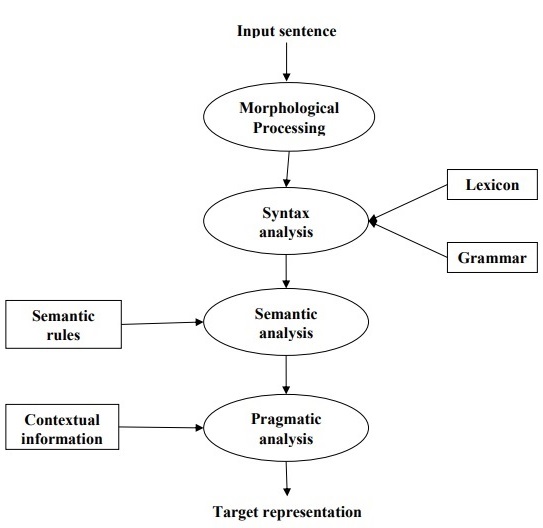
Морфологическая обработка
Это первая фаза НЛП. Целью этого этапа является разбиение фрагментов ввода языка на наборы токенов, соответствующих абзацам, предложениям и словам. Например, слово типа «непростое» можно разбить на два токена подслов как «непростое» .
Синтаксический анализ
Это вторая фаза НЛП. Цель этого этапа состоит в двух направлениях: проверить, правильно ли сформировано предложение или нет, и разбить его на структуру, которая показывает синтаксические отношения между различными словами. Например, предложение типа «Школа идет к мальчику» будет отклонено синтаксическим анализатором или анализатором.
Семантический анализ
Это третья фаза НЛП. Цель этого этапа — нарисовать точное значение, или вы можете сказать значение словаря из текста. Текст проверен на осмысленность. Например, семантический анализатор отклонил бы предложение типа «Горячее мороженое».
Прагматический анализ
Это четвертая фаза НЛП. Прагматический анализ просто сопоставляет фактические объекты / события, которые существуют в данном контексте, с объектными ссылками, полученными на последнем этапе (семантический анализ). Например, предложение «Положите банан в корзину на полке» может иметь две семантические интерпретации, и прагматический анализатор будет выбирать между этими двумя возможностями.