Поиск информации (IR) может быть определен как программное обеспечение, которое занимается организацией, хранением, поиском и оценкой информации из хранилищ документов, в частности текстовой информации. Система помогает пользователям найти требуемую информацию, но не дает явных ответов на вопросы. Он информирует о наличии и местонахождении документов, которые могут состоять из необходимой информации. Документы, которые удовлетворяют требованиям пользователя, называются соответствующими документами. Идеальная система IR будет получать только соответствующие документы.
С помощью следующей диаграммы мы можем понять процесс поиска информации (IR) —
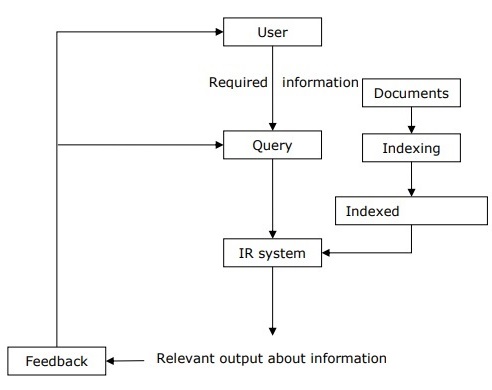
Из вышеприведенной диаграммы видно, что пользователю, которому нужна информация, необходимо будет сформулировать запрос в форме запроса на естественном языке. Затем система IR ответит путем извлечения соответствующих выходных данных в форме документов о требуемой информации.
Классическая проблема в информационно-поисковой (ИК) системе
Основная цель исследования IR состоит в том, чтобы разработать модель для извлечения информации из хранилищ документов. Здесь мы собираемся обсудить классическую проблему, названную специальной поисковой проблемой , связанной с системой IR.
В специальном поиске пользователь должен ввести запрос на естественном языке, который описывает необходимую информацию. Затем система IR вернет необходимые документы, связанные с желаемой информацией. Например, предположим, что мы что-то ищем в Интернете, и он дает некоторые точные страницы, которые соответствуют нашему требованию, но могут быть и некоторые не относящиеся к делу страницы. Это связано со специальной проблемой поиска.
Аспекты специального поиска
Ниже приведены некоторые аспекты специального поиска, которые рассматриваются в исследованиях IR —
-
Как пользователи с помощью обратной связи по релевантности могут улучшить оригинальную формулировку запроса?
-
Как реализовать объединение баз данных, т. Е. Как результаты из разных текстовых баз данных можно объединить в один набор результатов?
-
Как обрабатывать частично поврежденные данные? Какие модели подходят для одного и того же?
Как пользователи с помощью обратной связи по релевантности могут улучшить оригинальную формулировку запроса?
Как реализовать объединение баз данных, т. Е. Как результаты из разных текстовых баз данных можно объединить в один набор результатов?
Как обрабатывать частично поврежденные данные? Какие модели подходят для одного и того же?
Модель поиска информации (IR)
Математически, модели используются во многих научных областях, имеющих целью понять некоторые явления в реальном мире. Модель поиска информации предсказывает и объясняет, что пользователь найдет в связи с заданным запросом. Модель IR в основном представляет собой шаблон, который определяет вышеупомянутые аспекты процедуры поиска и состоит из следующего:
-
Модель для документов.
-
Модель для запросов.
-
Функция сопоставления, которая сравнивает запросы с документами.
Модель для документов.
Модель для запросов.
Функция сопоставления, которая сравнивает запросы с документами.
Математически поисковая модель состоит из —
D — Представление для документов.
R — Представление для запросов.
F — Каркас моделирования для D, Q вместе с отношениями между ними.
R (q, di) — функция сходства, которая упорядочивает документы по запросу. Это также называется рейтингом.
Типы модели поиска информации (IR)
Модель информационной модели (IR) может быть классифицирована на следующие три модели:
Классическая модель IR
Это самая простая и легко реализуемая модель IR. Эта модель основана на математических знаниях, которые также легко распознавались и понимались. Boolean, Vector и Probabilistic — это три классические ИК-модели.
Неклассическая ИК модель
Это полностью противоположно классической модели IR. Такие модели IR основаны на принципах, отличных от подобия, вероятности, логических операций. Информационно-логическая модель, модель теории ситуаций и модели взаимодействия являются примерами неклассической ИК-модели.
Альтернативная модель IR
Это расширение классической модели IR, использующее некоторые специфические методы из некоторых других областей. Кластерная модель, нечеткая модель и модели скрытой семантической индексации (LSI) являются примером альтернативной модели IR.
Конструктивные особенности информационно-поисковых (ИК) систем
Давайте теперь узнаем о конструктивных особенностях ИК систем —
Перевернутый индекс
Первичная структура данных большинства ИК-систем представлена в форме инвертированного индекса. Мы можем определить инвертированный индекс как структуру данных, которая перечисляет для каждого слова все документы, которые его содержат, и частоту вхождений в документе. Это облегчает поиск «совпадений» в слове запроса.
Остановить удаление слов
Стоп-слова — это те высокочастотные слова, которые вряд ли пригодятся для поиска. У них меньше смысловых весов. Все подобные слова находятся в списке, называемом стоп-листом. Например, статьи «a», «an», «the» и такие предлоги, как «in», «of», «for», «at» и т. Д., Являются примерами стоп-слов. Размер инвертированного индекса может быть значительно уменьшен с помощью стоп-листа. Согласно закону Ципфа, стоп-лист, охватывающий несколько десятков слов, уменьшает размер инвертированного индекса почти вдвое. С другой стороны, иногда удаление стоп-слова может привести к удалению термина, который полезен для поиска. Например, если мы исключим алфавит «А» из «Витамина А», это не будет иметь никакого значения.
Морфологический
Стемминг, упрощенная форма морфологического анализа, — это эвристический процесс выделения базовой формы слов путем обрезания концов слов. Например, слова «смеяться, смеяться, смеяться» будут ограничены корнем слова «смеяться».
В наших последующих разделах мы обсудим некоторые важные и полезные модели IR.
Булева Модель
Это самая старая информационно-поисковая (ИК) модель. Модель основана на теории множеств и булевой алгебре, где документы — это наборы терминов, а запросы — это булевы выражения для терминов. Булева модель может быть определена как —
-
D — Набор слов, то есть термины индексации, присутствующие в документе. Здесь каждый член либо присутствует (1), либо отсутствует (0).
-
Q — логическое выражение, где термины — это термины индекса, а операторы — логические продукты — И, логическая сумма — ИЛИ и логическая разница — НЕ
-
F — булева алгебра над множествами терминов, а также над множествами документов
Если мы говорим об обратной связи по релевантности, то в логической модели IR прогноз релевантности можно определить следующим образом:
-
R — Документ прогнозируется как релевантный выражению запроса, если и только если он удовлетворяет выражению запроса как —
D — Набор слов, то есть термины индексации, присутствующие в документе. Здесь каждый член либо присутствует (1), либо отсутствует (0).
Q — логическое выражение, где термины — это термины индекса, а операторы — логические продукты — И, логическая сумма — ИЛИ и логическая разница — НЕ
F — булева алгебра над множествами терминов, а также над множествами документов
Если мы говорим об обратной связи по релевантности, то в логической модели IR прогноз релевантности можно определить следующим образом:
R — Документ прогнозируется как релевантный выражению запроса, если и только если он удовлетворяет выражению запроса как —
((???? ˅ ???????????) ˄ ???????? ˄ ˜ ?ℎ????)
Мы можем объяснить эту модель термином запроса как однозначное определение набора документов.
Например, термин запроса «экономический» определяет набор документов, которые индексируются термином «экономический» .
Теперь, каков будет результат после объединения терминов с логическим оператором AND? Он определит набор документов, который меньше или равен наборам документов любого из отдельных терминов. Например, запрос с терминами «социальный» и «экономический» приведет к набору документов, индексируемому обоими терминами. Другими словами, документ установлен с пересечением обоих наборов.
Теперь, каков будет результат после объединения терминов с логическим оператором ИЛИ? Он определит набор документов, который больше или равен наборам документов любого из отдельных терминов. Например, запрос с терминами «социальный» или «экономический» приведет к набору документов, индексируемому с помощью термина «социальный» или «экономический» . Другими словами, документ установлен с объединением обоих наборов.
Преимущества булева режима
Преимущества булевой модели следующие:
-
Простейшая модель, основанная на множествах.
-
Легко понять и реализовать.
-
Он только получает точные совпадения
-
Это дает пользователю ощущение контроля над системой.
Простейшая модель, основанная на множествах.
Легко понять и реализовать.
Он только получает точные совпадения
Это дает пользователю ощущение контроля над системой.
Недостатки булевой модели
Недостатки булевой модели следующие:
-
Функция подобия модели является логической. Следовательно, не будет частичных совпадений. Это может раздражать пользователей.
-
В этой модели использование логического оператора имеет гораздо большее влияние, чем критическое слово.
-
Язык запросов выразителен, но он также сложен.
-
Нет рейтинга для найденных документов.
Функция подобия модели является логической. Следовательно, не будет частичных совпадений. Это может раздражать пользователей.
В этой модели использование логического оператора имеет гораздо большее влияние, чем критическое слово.
Язык запросов выразителен, но он также сложен.
Нет рейтинга для найденных документов.
Модель векторного пространства
Из-за вышеупомянутых недостатков булевой модели Джерард Солтон и его коллеги предложили модель, основанную на критерии сходства Луна. Критерий подобия, сформулированный Луном, гласит: «Чем больше двух представлений согласовано в данных элементах и их распределении, тем выше будет вероятность того, что они представят подобную информацию».
Рассмотрим следующие важные моменты, чтобы понять больше о модели векторного пространства —
-
Индексные представления (документы) и запросы рассматриваются как векторы, вложенные в евклидово пространство большой размерности.
-
Мера сходства вектора документа с вектором запроса обычно представляет собой косинус угла между ними.
Индексные представления (документы) и запросы рассматриваются как векторы, вложенные в евклидово пространство большой размерности.
Мера сходства вектора документа с вектором запроса обычно представляет собой косинус угла между ними.
Формула измерения сходства косинусов
Косинус является нормализованным точечным произведением, которое можно рассчитать с помощью следующей формулы:
Score lgroup vecd vecq rgroup= frac summk=1dk.Qk sqrt summk=1 lgroupdk rgroup2. Sqrt summk=1m lgroupqk rgroup2
Score lgroup vecd vecq rgroup=1когдаd=q
Score lgroup vecd vecq rgroup=0когдаdиqподелитьсяnoitems
Представление векторного пространства с запросом и документом
Запрос и документы представлены двумерным векторным пространством. Условия — автомобиль и страховка . В векторном пространстве есть один запрос и три документа.
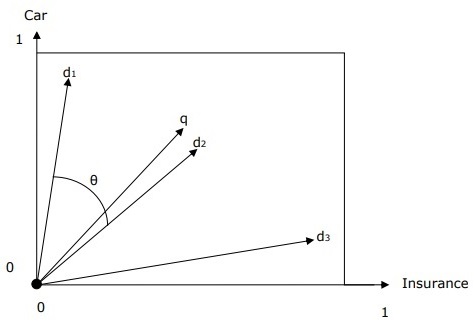
Документом с самым высоким рейтингом в ответ на термины автомобиль и страховка будет документ d 2, поскольку угол между q и d 2 является наименьшим. Причиной этого является то, что концепт-кар и страховка имеют значение в d 2 и, следовательно, имеют большой вес. С другой стороны, d 1 и d 3 также упоминают оба термина, но в каждом случае один из них не является центрально важным термином в документе.
Срок взвешивания
Взвешивание терминов означает веса в терминах в векторном пространстве. Чем выше вес термина, тем больше будет влияние термина на косинус. Большим весам следует присваивать более важные термины в модели. Теперь возникает вопрос: как мы можем смоделировать это?
Один из способов сделать это состоит в том, чтобы считать слова в документе как его вес термина. Однако, вы думаете, это будет эффективный метод?
Другой способ, который является более эффективным, заключается в использовании термина частота (tf ij ), частота документа (df i ) и частота сбора (cf i ) .
Термин частота (TF IJ )
Это может быть определено как число вхождений w i в d j . Информация, получаемая по частоте термина, — это то, насколько значимым является слово в данном документе, или, другими словами, мы можем сказать, что чем выше частота термина, тем больше это слово является хорошим описанием содержания этого документа.
Частота документов (df i )
Он может быть определен как общее количество документов в коллекции, в которой он находится. Это показатель информативности. Семантически сфокусированные слова будут встречаться в документе несколько раз, в отличие от семантически сфокусированных слов.
Частота сбора (ср. Я )
Это может быть определено как общее количество вхождений w i в коллекцию.
Математически, dfi leqcfiи sumjtfij=cfi
Формы взвешивания по частоте документов
Давайте теперь узнаем о различных формах взвешивания частоты документа. Формы описаны ниже —
Термин частотный фактор
Это также классифицируется как термин частотный коэффициент, что означает, что если термин t часто встречается в документе, запрос, содержащий t, должен извлечь этот документ. Мы можем объединить частоту слова (tf ij ) и частоту документа (df i ) в один вес следующим образом:
weight left(i,j right)= begincase(1+log(tfij))log fracNdfiiftfi,j geq10 :iftfi,j=0 endcase
Здесь N — общее количество документов.
Частота обратных документов (IDF)
Это еще одна форма взвешивания частоты документа и часто называемая IDF-взвешиванием или обратным взвешиванием частоты документа. Важным моментом взвешивания IDF является то, что нехватка термина во всей коллекции является показателем его важности, а важность обратно пропорциональна частоте встречаемости.
Математически,
idft=log left(1+ fracNnt right)
idft=log left( fracN−ntnt right)
Вот,
N = документы в коллекции
n t = документы, содержащие термин t
Улучшение пользовательских запросов
Основной целью любой информационно-поисковой системы должна быть точность — производить соответствующие документы в соответствии с требованиями пользователя. Однако возникает вопрос: как мы можем улучшить вывод, улучшив стиль формирования запросов пользователя. Конечно, вывод любой ИК-системы зависит от запроса пользователя, и хорошо отформатированный запрос даст более точные результаты. Пользователь может улучшить свой запрос с помощью обратной связи по релевантности , что является важным аспектом любой модели IR.
Актуальность Обратная связь
Релевантная обратная связь принимает выходные данные, которые первоначально возвращаются из данного запроса. Этот начальный вывод можно использовать для сбора информации о пользователе и для выяснения, является ли этот вывод релевантным для выполнения нового запроса или нет. Отзывы могут быть классифицированы следующим образом —
Явная обратная связь
Это может быть определено как обратная связь, полученная от экспертов по релевантности. Эти оценщики также укажут актуальность документа, извлеченного из запроса. Чтобы повысить производительность поиска запросов, информацию обратной связи по релевантности необходимо интерполировать с исходным запросом.
Оценщики или другие пользователи системы могут явно указать актуальность, используя следующие системы релевантности:
-
Бинарная система релевантности. Эта система обратной связи по релевантности указывает, что документ является релевантным (1) или неактуальным (0) для данного запроса.
-
Система градуированной релевантности — система обратной связи градуированной релевантности указывает релевантность документа для данного запроса на основе классификации с использованием цифр, букв или описаний. Описание может быть как «не релевантно», «несколько релевантно», «очень актуально» или «актуально».
Бинарная система релевантности. Эта система обратной связи по релевантности указывает, что документ является релевантным (1) или неактуальным (0) для данного запроса.
Система градуированной релевантности — система обратной связи градуированной релевантности указывает релевантность документа для данного запроса на основе классификации с использованием цифр, букв или описаний. Описание может быть как «не релевантно», «несколько релевантно», «очень актуально» или «актуально».
Скрытая обратная связь
Это обратная связь, которая выводится из поведения пользователя. Поведение включает в себя продолжительность времени, которое пользователь потратил на просмотр документа, какой документ выбран для просмотра, а какой нет, действия по просмотру страниц и прокрутке и т. Д. Одним из лучших примеров неявной обратной связи является время задержки , которое является мерой того, как много времени пользователь тратит на просмотр страницы, на которую ссылается результат поиска.
Псевдо-обратная связь
Это также называется слепой обратной связью. Он предоставляет метод для автоматического локального анализа. Ручная часть обратной связи по релевантности автоматизируется с помощью псевдо-релевантной обратной связи, так что пользователь получает улучшенную производительность поиска без расширенного взаимодействия. Основным преимуществом этой системы обратной связи является то, что она не требует от оценщиков, как в случае системы обратной связи с явным соответствием.
Рассмотрим следующие шаги для реализации этой обратной связи —
Шаг 1 — Во-первых, результат, возвращаемый начальным запросом, должен быть принят как соответствующий результат. Диапазон релевантных результатов должен быть в топ-10-50 результатов.
Шаг 2 — Теперь выберите верхние 20-30 терминов из документов, используя, например, вес частоты (tf), обратный частоте документа (idf).
Шаг 3 — Добавьте эти условия в запрос и сопоставьте возвращенные документы. Затем верните наиболее актуальные документы.