Синтаксический анализ, синтаксический анализ или синтаксический анализ — это третья фаза НЛП. Цель этого этапа — нарисовать точное значение, или вы можете сказать значение словаря из текста. Синтаксический анализ проверяет текст на предмет значимости по сравнению с правилами формальной грамматики. Например, предложение типа «горячее мороженое» будет отклонено семантическим анализатором.
В этом смысле синтаксический анализ или синтаксический анализ могут быть определены как процесс анализа строк символов на естественном языке в соответствии с правилами формальной грамматики. Происхождение слова «парсинг» происходит от латинского слова «парс», что означает «часть» .
Концепция парсера
Используется для реализации задачи разбора. Он может быть определен как программный компонент, предназначенный для сбора входных данных (текста) и обеспечения структурного представления входных данных после проверки правильности синтаксиса в соответствии с формальной грамматикой. Он также строит структуру данных, как правило, в форме дерева разбора или абстрактного синтаксического дерева или другой иерархической структуры.
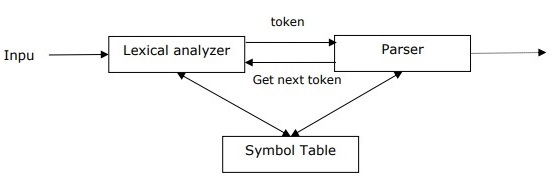
Основные роли разбора включают в себя —
-
Чтобы сообщить о любой синтаксической ошибке.
-
Для восстановления после часто встречающейся ошибки, чтобы можно было продолжить обработку оставшейся части программы.
-
Создать дерево разбора.
-
Создать таблицу символов.
-
Производить промежуточные представления (IR).
Чтобы сообщить о любой синтаксической ошибке.
Для восстановления после часто встречающейся ошибки, чтобы можно было продолжить обработку оставшейся части программы.
Создать дерево разбора.
Создать таблицу символов.
Производить промежуточные представления (IR).
Типы разбора
Вывод делит синтаксический анализ на следующие два типа:
-
Разбор сверху вниз
-
Анализ снизу вверх
Разбор сверху вниз
Анализ снизу вверх
Разбор сверху вниз
При таком разборе синтаксический анализатор начинает строить дерево разбора из начального символа, а затем пытается преобразовать начальный символ во входные данные. Наиболее распространенная форма синтаксического анализа сверху вниз использует рекурсивную процедуру для обработки ввода. Основным недостатком разбора рекурсивного спуска является возврат.
Анализ снизу вверх
При таком анализе синтаксический анализатор начинается с входного символа и пытается построить дерево синтаксического анализатора до начального символа.
Концепция деривации
Чтобы получить входную строку, нам нужна последовательность правил производства. Вывод — это набор правил производства. Во время синтаксического анализа нам нужно выбрать нетерминал, который должен быть заменен, вместе с решением производственного правила, с помощью которого нетерминал будет заменен.
Типы деривации
В этом разделе мы узнаем о двух типах дериваций, которые можно использовать, чтобы решить, какой нетерминал следует заменить производственным правилом —
Самый левый вывод
В самом левом выводе предложенная форма ввода сканируется и заменяется слева направо. Форма предложения в этом случае называется формой слева.
Самый правый вывод
В крайнем левом выводе предложенная форма ввода сканируется и заменяется справа налево. Форма предложения в этом случае называется формой предложения справа.
Концепция разбора дерева
Это может быть определено как графическое изображение деривации. Начальный символ деривации служит корнем дерева разбора. В каждом дереве разбора конечные узлы являются терминалами, а внутренние узлы — нетерминалами. Свойство дерева разбора состоит в том, что обход по порядку будет производить исходную входную строку.
Концепция грамматики
Грамматика очень важна и важна для описания синтаксической структуры правильно сформированных программ. В литературном смысле они обозначают синтаксические правила общения на естественных языках. Лингвистика пыталась определить грамматику с момента появления естественных языков, таких как английский, хинди и т. Д.
Теория формальных языков также применима в области компьютерных наук, главным образом, в языках программирования и структуре данных. Например, в языке «C» правила точной грамматики определяют, как функции создаются из списков и операторов.
Математическая модель грамматики была дана Ноамом Хомским в 1956 году, которая эффективна для написания компьютерных языков.
Математически грамматика G может быть формально записана как 4-кортеж (N, T, S, P), где —
-
N или V N = набор нетерминальных символов, т. Е. Переменных.
-
T или ∑ = набор терминальных символов.
-
S = начальный символ, где S ∈ N
-
P обозначает Производственные правила для Терминалов, а также для Нетерминалов. Он имеет вид α → β, где α и β — строки на V N ∪ ∑, и хотя бы один символ α принадлежит V N
N или V N = набор нетерминальных символов, т. Е. Переменных.
T или ∑ = набор терминальных символов.
S = начальный символ, где S ∈ N
P обозначает Производственные правила для Терминалов, а также для Нетерминалов. Он имеет вид α → β, где α и β — строки на V N ∪ ∑, и хотя бы один символ α принадлежит V N
Структура фразы или грамматика избирательного округа
Фраза грамматической структуры, представленная Ноамом Хомским, основана на отношении избирателей. Вот почему это также называется избирательной грамматикой. Это противоположно грамматике зависимости.
пример
Прежде чем приводить пример грамматики избирательного округа, нам необходимо знать основные положения о грамматике избирательного округа и взаимоотношениях с избирателями.
-
Все связанные структуры рассматривают структуру предложения с точки зрения отношения избирателей.
-
Отношение избирательных округов происходит от субъектно-предикатного разделения латинской и греческой грамматики.
-
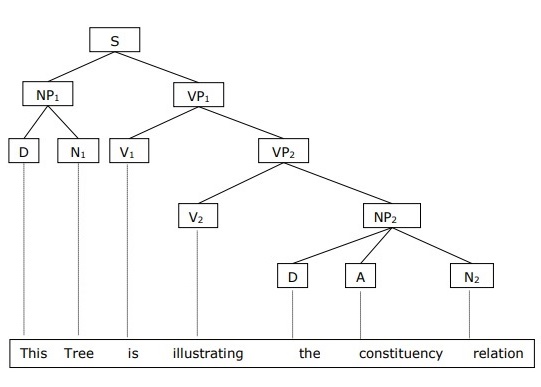
Основная структура предложения понимается в терминах именной группы NP и глагольной фразы VP .
Все связанные структуры рассматривают структуру предложения с точки зрения отношения избирателей.
Отношение избирательных округов происходит от субъектно-предикатного разделения латинской и греческой грамматики.
Основная структура предложения понимается в терминах именной группы NP и глагольной фразы VP .
Мы можем написать предложение «Это дерево иллюстрирует отношение избирателей» следующим образом:
Грамматика зависимости
Это противоположно грамматике избирательного округа и основано на отношении зависимости. Он был представлен Люсьеном Теснере. Грамматика зависимости (DG) противоположна грамматике избирательного округа, потому что в ней отсутствуют фразовые узлы.
пример
Перед тем, как привести пример грамматики зависимости, нам нужно знать основные моменты, касающиеся грамматики зависимости и отношения зависимости.
-
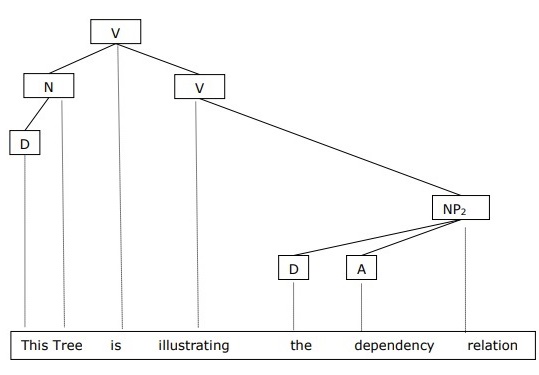
В ГД лингвистические единицы, т. Е. Слова, связаны друг с другом направленными ссылками.
-
Глагол становится центром структуры предложения.
-
Все остальные синтаксические единицы связаны с глаголом в терминах направленной связи. Эти синтаксические единицы называются зависимостями .
В ГД лингвистические единицы, т. Е. Слова, связаны друг с другом направленными ссылками.
Глагол становится центром структуры предложения.
Все остальные синтаксические единицы связаны с глаголом в терминах направленной связи. Эти синтаксические единицы называются зависимостями .
Мы можем написать предложение «Это дерево иллюстрирует отношение зависимости» следующим образом;
Дерево синтаксического анализа, которое использует грамматику постоянных групп, называется основанным на избирательном округе деревом анализа; и деревья разбора, которые используют грамматику зависимости, называются основанным на зависимости деревом разбора.
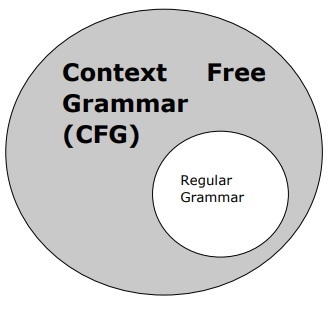
Контекстная бесплатная грамматика
Контекстно-свободная грамматика, также называемая CFG, является нотацией для описания языков и надмножеством регулярной грамматики. Это можно увидеть на следующей диаграмме —
Определение CFG
CFG состоит из конечного набора правил грамматики со следующими четырьмя компонентами:
Набор нетерминалов
Он обозначается буквой V. Нетерминалы — это синтаксические переменные, обозначающие наборы строк, которые дополнительно помогают определить язык, генерируемый грамматикой.
Набор терминалов
Он также называется токеном и определяется как. Строки сформированы с основными символами терминалов.
Набор произведений
Обозначается буквой P. Набор определяет, как клеммы и нетерминалы могут быть объединены. Каждое производство (P) состоит из нетерминалов, стрелки и терминалов (последовательность терминалов). Нетерминалы называются левой стороной производства, а терминалы называются правой стороной производства.
Начальный символ
Производство начинается с начального символа. Он обозначается символом S. Нетерминальный символ всегда обозначается как начальный символ.