Текстовые базы данных состоят из огромной коллекции документов. Они собирают эту информацию из нескольких источников, таких как новостные статьи, книги, электронные библиотеки, сообщения электронной почты, веб-страницы и т. Д. Из-за увеличения объема информации текстовые базы данных быстро растут. Во многих текстовых базах данных данные частично структурированы.
Например, документ может содержать несколько структурированных полей, таких как title, author, publishing_date и т. Д. Но наряду со структурными данными документ также содержит неструктурированные текстовые компоненты, такие как аннотация и содержимое. Не зная, что может быть в документах, сложно сформулировать эффективные запросы для анализа и извлечения полезной информации из данных. Пользователям требуются инструменты для сравнения документов и ранжирования их важности и актуальности. Таким образом, интеллектуальный анализ текста стал популярной и важной темой в интеллектуальном анализе данных.
Поиск информации
Под поиском информации понимается извлечение информации из большого количества текстовых документов. Некоторые из систем баз данных обычно не присутствуют в информационно-поисковых системах, поскольку обе они обрабатывают различные виды данных. Примеры информационно-поисковой системы включают в себя —
- Система каталогов онлайн-библиотеки
- Системы управления документами онлайн
- Системы веб-поиска и т. Д.
Примечание . Основная проблема в информационно-поисковой системе — найти соответствующие документы в коллекции документов на основе запроса пользователя. Этот вид запроса пользователя состоит из нескольких ключевых слов, описывающих информационную потребность.
В таких задачах поиска пользователь берет на себя инициативу по извлечению соответствующей информации из коллекции. Это целесообразно, когда у пользователя есть специальная потребность в информации, то есть краткосрочная потребность. Но если у пользователя есть долгосрочная потребность в информации, тогда поисковая система также может предпринять инициативу для передачи любого вновь поступившего информационного элемента пользователю.
Этот вид доступа к информации называется фильтрацией информации. И соответствующие системы известны как системы фильтрации или системы рекомендаций.
Основные меры для поиска текста
Нам нужно проверить точность системы, когда она получает ряд документов на основе ввода пользователя. Пусть набор документов, относящихся к запросу, будет обозначен как {Соответствующий}, а набор извлеченных документов — как {Восстановленный}. Набор документов, которые являются релевантными и извлеченными, можно обозначить как {Соответствующий} ∩ {Полученный}. Это может быть показано в виде диаграммы Венна следующим образом:
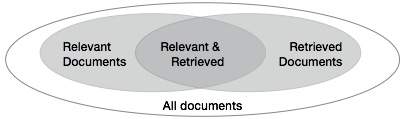
Существует три основных критерия оценки качества поиска текста:
- точность
- Отзыв
- F-оценка
точность
Точность — это процент найденных документов, которые действительно имеют отношение к запросу. Точность может быть определена как —
Precision= |{Relevant} ∩ {Retrieved}| / |{Retrieved}|
Отзыв
Напомним, это процент документов, которые имеют отношение к запросу и были фактически получены. Напомним, определяется как —
Recall = |{Relevant} ∩ {Retrieved}| / |{Relevant}|
F-оценка
F-оценка является широко используемым компромиссом. Информационно-поисковая система часто нуждается в компромиссе для точности или наоборот. F-оценка определяется как среднее гармонического запоминания или точности следующим образом: