Существует две формы анализа данных, которые можно использовать для извлечения моделей, описывающих важные классы, или для прогнозирования будущих трендов данных. Эти две формы следующие:
- классификация
- прогнозирование
Классификационные модели предсказывают категориальные метки классов; и модели прогнозирования предсказывают непрерывные функции. Например, мы можем построить классификационную модель, чтобы классифицировать банковские кредитные заявки как безопасные или рискованные, или прогнозную модель для прогнозирования расходов в долларах потенциальных клиентов на компьютерное оборудование с учетом их доходов и профессии.
Что такое классификация?
Ниже приведены примеры случаев, когда задачей анализа данных является классификация.
-
Сотрудник банка по кредитам хочет проанализировать данные, чтобы узнать, какой клиент (соискатель кредита) является рискованным или кто в безопасности.
-
Менеджер по маркетингу в компании должен проанализировать клиента с заданным профилем, который купит новый компьютер.
Сотрудник банка по кредитам хочет проанализировать данные, чтобы узнать, какой клиент (соискатель кредита) является рискованным или кто в безопасности.
Менеджер по маркетингу в компании должен проанализировать клиента с заданным профилем, который купит новый компьютер.
В обоих приведенных выше примерах модель или классификатор строятся для прогнозирования категориальных меток. Эти ярлыки опасны или безопасны для данных заявки на кредит и да или нет для данных маркетинга.
Что такое прогноз?
Ниже приведены примеры случаев, когда задачей анализа данных является прогнозирование.
Предположим, что менеджер по маркетингу должен предсказать, сколько данный клиент потратит во время продажи в своей компании. В этом примере мы пытаемся предсказать числовое значение. Поэтому задача анализа данных является примером численного прогнозирования. В этом случае будет построена модель или предиктор, который предсказывает непрерывную функцию или упорядоченное значение.
Примечание. Регрессионный анализ — это статистическая методология, которая чаще всего используется для численного прогнозирования.
Как работает классификация?
С помощью заявки на получение банковского кредита, о которой мы говорили выше, давайте разберемся в работе классификации. Процесс классификации данных включает два этапа:
- Построение классификатора или модели
- Использование классификатора для классификации
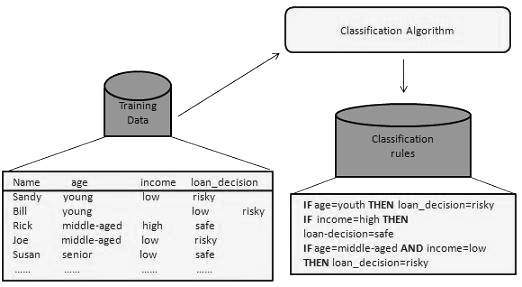
Построение классификатора или модели
-
Этот этап является этапом обучения или этапом обучения.
-
На этом этапе алгоритмы классификации строят классификатор.
-
Классификатор построен из обучающего набора, состоящего из кортежей базы данных и связанных с ними меток классов.
-
Каждый кортеж, составляющий тренировочный набор, называется категорией или классом. Эти кортежи также могут называться образцами, объектами или точками данных.
Этот этап является этапом обучения или этапом обучения.
На этом этапе алгоритмы классификации строят классификатор.
Классификатор построен из обучающего набора, состоящего из кортежей базы данных и связанных с ними меток классов.
Каждый кортеж, составляющий тренировочный набор, называется категорией или классом. Эти кортежи также могут называться образцами, объектами или точками данных.
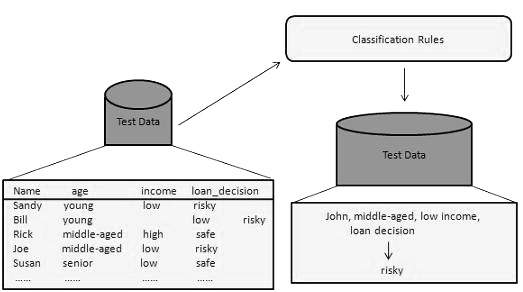
Использование классификатора для классификации
На этом этапе классификатор используется для классификации. Здесь данные теста используются для оценки точности правил классификации. Правила классификации могут применяться к новым кортежам данных, если точность считается приемлемой.
Вопросы классификации и прогнозирования
Основная проблема заключается в подготовке данных для классификации и прогнозирования. Подготовка данных включает в себя следующие действия —
-
Очистка данных — Очистка данных включает в себя удаление шума и обработку пропущенных значений. Шум удаляется путем применения методов сглаживания, а проблема пропущенных значений решается путем замены пропущенного значения наиболее часто встречающимся значением для этого атрибута.
-
Анализ релевантности — база данных также может иметь нерелевантные атрибуты. Корреляционный анализ используется, чтобы узнать, связаны ли какие-либо два заданных атрибута.
-
Преобразование и сокращение данных — данные могут быть преобразованы любым из следующих способов.
-
Нормализация — данные преобразуются с использованием нормализации. Нормализация включает в себя масштабирование всех значений для данного атрибута, чтобы они попадали в небольшой заданный диапазон. Нормализация используется, когда на этапе обучения используются нейронные сети или методы, включающие измерения.
-
Обобщение — данные также можно преобразовать, обобщив их в более высокую концепцию. Для этого мы можем использовать иерархию понятий.
-
Очистка данных — Очистка данных включает в себя удаление шума и обработку пропущенных значений. Шум удаляется путем применения методов сглаживания, а проблема пропущенных значений решается путем замены пропущенного значения наиболее часто встречающимся значением для этого атрибута.
Анализ релевантности — база данных также может иметь нерелевантные атрибуты. Корреляционный анализ используется, чтобы узнать, связаны ли какие-либо два заданных атрибута.
Преобразование и сокращение данных — данные могут быть преобразованы любым из следующих способов.
Нормализация — данные преобразуются с использованием нормализации. Нормализация включает в себя масштабирование всех значений для данного атрибута, чтобы они попадали в небольшой заданный диапазон. Нормализация используется, когда на этапе обучения используются нейронные сети или методы, включающие измерения.
Обобщение — данные также можно преобразовать, обобщив их в более высокую концепцию. Для этого мы можем использовать иерархию понятий.
Примечание. Данные также можно сократить с помощью некоторых других методов, таких как вейвлет-преобразование, группирование, анализ гистограмм и кластеризация.
Сравнение методов классификации и прогнозирования
Вот критерии для сравнения методов классификации и прогнозирования —
Точность — Точность классификатора относится к способности классификатора. Он правильно предсказывает метку класса, а точность предиктора указывает, насколько хорошо данный предиктор может угадать значение прогнозируемого атрибута для новых данных.
Скорость — это относится к вычислительным затратам при создании и использовании классификатора или предиктора.
Надежность — относится к способности классификатора или предиктора делать правильные прогнозы на основе данных с шумом.
Масштабируемость — Масштабируемость относится к способности эффективно построить классификатор или предиктор; учитывая большое количество данных.
Интерпретируемость. Относится к тому, в какой степени понимает классификатор или предиктор.