В этой реализации глубокого обучения наша цель состоит в том, чтобы предсказать потери клиентов или данные о сбое определенного банка — какие клиенты, вероятно, покинут эту банковскую услугу. Используемый набор данных является относительно небольшим и содержит 10000 строк с 14 столбцами. Мы используем дистрибутив Anaconda и такие фреймворки, как Theano, TensorFlow и Keras. Keras построен поверх Tensorflow и Theano, которые функционируют как его бэкэнды.
# Artificial Neural Network # Installing Theano pip install --upgrade theano # Installing Tensorflow pip install –upgrade tensorflow # Installing Keras pip install --upgrade keras
Шаг 1: Предварительная обработка данных
In[]:
# Importing the libraries
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
# Importing the database
dataset = pd.read_csv('Churn_Modelling.csv')
Шаг 2
Мы создаем матрицы объектов набора данных и целевой переменной, которая является столбцом 14 и помечена как «Exited».
Первоначальный вид данных, как показано ниже —
In[]: X = dataset.iloc[:, 3:13].values Y = dataset.iloc[:, 13].values X
Выход
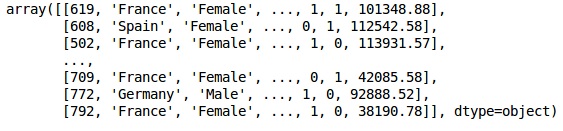
Шаг 3
Y
Выход
array([1, 0, 1, ..., 1, 1, 0], dtype = int64)
Шаг 4
Мы делаем анализ проще, кодируя строковые переменные. Мы используем функцию ScikitLearn LabelEncoder для автоматического кодирования различных меток в столбцах со значениями от 0 до n_classes-1.
from sklearn.preprocessing import LabelEncoder, OneHotEncoder labelencoder_X_1 = LabelEncoder() X[:,1] = labelencoder_X_1.fit_transform(X[:,1]) labelencoder_X_2 = LabelEncoder() X[:, 2] = labelencoder_X_2.fit_transform(X[:, 2]) X
Выход
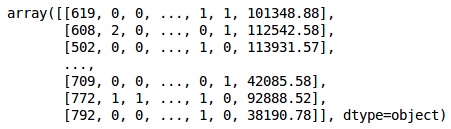
В приведенном выше выводе названия стран заменяются на 0, 1 и 2; в то время как мужчины и женщины заменены на 0 и 1.
Шаг 5
Маркировка закодированных данных
Мы используем ту же библиотеку ScikitLearn и другую функцию под названием OneHotEncoder, чтобы просто передать номер столбца, создавая фиктивную переменную.
onehotencoder = OneHotEncoder(categorical features = [1]) X = onehotencoder.fit_transform(X).toarray() X = X[:, 1:] X
Теперь первые 2 столбца представляют страну, а 4-й столбец представляет пол.
Выход
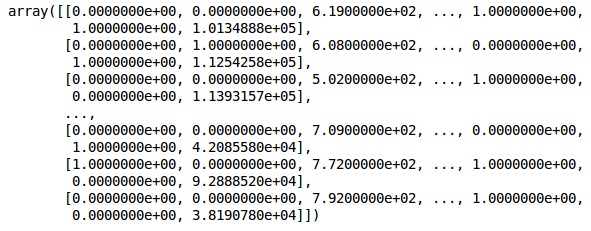
Мы всегда делим наши данные на части обучения и тестирования; мы обучаем нашу модель на данных обучения, а затем проверяем точность модели на данных тестирования, которая помогает оценить эффективность модели.
Шаг 6
Мы используем функцию train_test_split ScikitLearn для разделения наших данных на тренировочный набор и тестовый набор. Мы сохраняем соотношение между поездом и тестом как 80:20.
#Splitting the dataset into the Training set and the Test Set from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2)
Некоторые переменные имеют значения в тысячах, а некоторые имеют значения в десятках или единицах. Мы масштабируем данные так, чтобы они были более представительными.
Шаг 7
В этом коде мы подгоняем и трансформируем тренировочные данные, используя функцию StandardScaler . Мы стандартизируем наше масштабирование так, чтобы мы использовали тот же самый подобранный метод для преобразования / масштабирования тестовых данных.
# Feature Scaling
fromsklearn.preprocessing import StandardScaler sc = StandardScaler() X_train = sc.fit_transform(X_train) X_test = sc.transform(X_test)
Выход
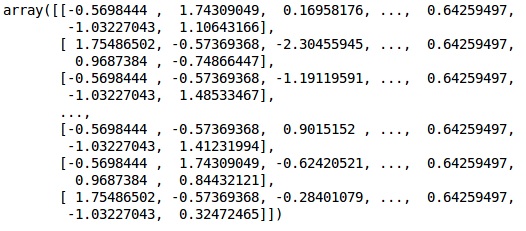
Данные теперь масштабируются правильно. Наконец, мы закончили с предварительной обработкой данных. Теперь мы начнем с нашей модели.
Шаг 8
Мы импортируем необходимые модули здесь. Нам нужен последовательный модуль для инициализации нейронной сети и плотный модуль для добавления скрытых слоев.
# Importing the Keras libraries and packages import keras from keras.models import Sequential from keras.layers import Dense
Шаг 9
Мы назовем модель классификатором, поскольку наша цель — классифицировать отток клиентов. Затем мы используем последовательный модуль для инициализации.
#Initializing Neural Network classifier = Sequential()
Шаг 10
Мы добавляем скрытые слои один за другим, используя плотную функцию. В приведенном ниже коде мы увидим много аргументов.
Наш первый параметр — output_dim . Это количество узлов, которые мы добавляем в этот слой. init — это инициализация стохастического градиента. В нейронной сети мы присваиваем веса каждому узлу. При инициализации веса должны быть близки к нулю, и мы случайным образом инициализируем веса, используя равномерную функцию. Параметр input_dim необходим только для первого слоя, так как модель не знает количество наших входных переменных. Здесь общее количество входных переменных равно 11. Во втором слое модель автоматически знает количество входных переменных из первого скрытого слоя.
Выполните следующую строку кода, чтобы добавить входной слой и первый скрытый слой —
classifier.add(Dense(units = 6, kernel_initializer = 'uniform', activation = 'relu', input_dim = 11))
Выполните следующую строку кода, чтобы добавить второй скрытый слой —
classifier.add(Dense(units = 6, kernel_initializer = 'uniform', activation = 'relu'))
Выполните следующую строку кода, чтобы добавить выходной слой —
classifier.add(Dense(units = 1, kernel_initializer = 'uniform', activation = 'sigmoid'))
Шаг 11
Компиляция ANN
Мы добавили несколько слоев в наш классификатор до сих пор. Теперь мы скомпилируем их, используя метод compile . Аргументы, добавленные в окончательный контроль компиляции, завершают работу нейронной сети. Итак, нам нужно быть осторожным на этом этапе.
Вот краткое объяснение аргументов.
Первый аргумент — Оптимизатор. Это алгоритм, используемый для поиска оптимального набора весов. Этот алгоритм называется стохастическим градиентным спуском (SGD) . Здесь мы используем один из нескольких типов, называемый «оптимизатором Адама». SGD зависит от потерь, поэтому наш второй параметр — потери. Если наша зависимая переменная является двоичной, мы используем функцию логарифмической потери, называемую «binary_crossentropy» , и если наша зависимая переменная имеет более двух категорий в выводе, то мы используем «categoryorical_crossentropy» . Мы хотим улучшить производительность нашей нейронной сети на основе точности , поэтому мы добавляем метрики в качестве точности.
# Compiling Neural Network classifier.compile(optimizer = 'adam', loss = 'binary_crossentropy', metrics = ['accuracy'])
Шаг 12
На этом этапе необходимо выполнить несколько кодов.
Установка ANN в тренировочный набор
Теперь мы обучаем нашу модель на тренировочных данных. Мы используем метод подгонки, чтобы соответствовать нашей модели. Мы также оптимизируем веса для повышения эффективности моделей. Для этого мы должны обновить веса. Размер партии — это число наблюдений, после которого мы обновляем весы. Epoch — общее количество итераций. Значения размера партии и эпохи выбираются методом проб и ошибок.
classifier.fit(X_train, y_train, batch_size = 10, epochs = 50)
Делать прогнозы и оценивать модель
# Predicting the Test set results y_pred = classifier.predict(X_test) y_pred = (y_pred > 0.5)
Прогнозирование одного нового наблюдения
# Predicting a single new observation """Our goal is to predict if the customer with the following data will leave the bank: Geography: Spain Credit Score: 500 Gender: Female Age: 40 Tenure: 3 Balance: 50000 Number of Products: 2 Has Credit Card: Yes Is Active Member: Yes
Шаг 13
Прогнозирование результата теста
Результат прогноза даст вам вероятность того, что клиент покинет компанию. Мы преобразуем эту вероятность в двоичные 0 и 1.
# Predicting the Test set results y_pred = classifier.predict(X_test) y_pred = (y_pred > 0.5)
new_prediction = classifier.predict(sc.transform (np.array([[0.0, 0, 500, 1, 40, 3, 50000, 2, 1, 1, 40000]]))) new_prediction = (new_prediction > 0.5)
Шаг 14
Это последний шаг, где мы оцениваем производительность нашей модели. У нас уже есть оригинальные результаты, и, таким образом, мы можем построить путаницу для проверки точности нашей модели.
Создание матрицы путаницы
from sklearn.metrics import confusion_matrix cm = confusion_matrix(y_test, y_pred) print (cm)
Выход
loss: 0.3384 acc: 0.8605 [ [1541 54] [230 175] ]
Из матрицы путаницы, точность нашей модели может быть рассчитана как —
Accuracy = 1541+175/2000=0.858
Мы достигли 85,8% точности , что хорошо.
Алгоритм прямого распространения
В этом разделе мы узнаем, как написать код для прямого распространения (прогнозирования) для простой нейронной сети —
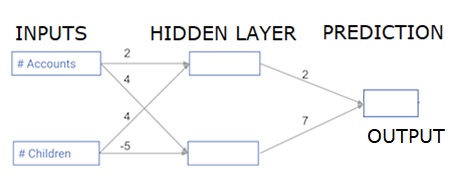
Каждая точка данных является клиентом. Первый вход — сколько у них учетных записей, а второй — сколько у них детей. Модель будет прогнозировать, сколько транзакций совершит пользователь в следующем году.
Входные данные предварительно загружаются в качестве входных данных, а весовые коэффициенты находятся в словаре, называемом весовыми коэффициентами. Массив весов для первого узла в скрытом слое указывается в весах [‘node_0’], а для второго узла в скрытом слое — в весах [‘node_1’] соответственно.
Веса, подающие в выходной узел, доступны в весах.
Выпрямленная функция линейной активации
«Функция активации» — это функция, которая работает на каждом узле. Это преобразовывает вход узла в некоторый вывод.
Выпрямленная функция линейной активации (называемая ReLU ) широко используется в очень высокопроизводительных сетях. Эта функция принимает одно число как вход, возвращая 0, если вход отрицательный, и ввод как выход, если вход положительный.
Вот несколько примеров —
- relu (4) = 4
- relu (-2) = 0
Заполним определение функции relu () —
- Мы используем функцию max (), чтобы вычислить значение для вывода relu ().
- Мы применяем функцию relu () к node_0_input для вычисления node_0_output.
- Мы применяем функцию relu () к node_1_input для вычисления node_1_output.
import numpy as np input_data = np.array([-1, 2]) weights = { 'node_0': np.array([3, 3]), 'node_1': np.array([1, 5]), 'output': np.array([2, -1]) } node_0_input = (input_data * weights['node_0']).sum() node_0_output = np.tanh(node_0_input) node_1_input = (input_data * weights['node_1']).sum() node_1_output = np.tanh(node_1_input) hidden_layer_output = np.array(node_0_output, node_1_output) output =(hidden_layer_output * weights['output']).sum() print(output) def relu(input): '''Define your relu activation function here''' # Calculate the value for the output of the relu function: output output = max(input,0) # Return the value just calculated return(output) # Calculate node 0 value: node_0_output node_0_input = (input_data * weights['node_0']).sum() node_0_output = relu(node_0_input) # Calculate node 1 value: node_1_output node_1_input = (input_data * weights['node_1']).sum() node_1_output = relu(node_1_input) # Put node values into array: hidden_layer_outputs hidden_layer_outputs = np.array([node_0_output, node_1_output]) # Calculate model output (do not apply relu) odel_output = (hidden_layer_outputs * weights['output']).sum() print(model_output)# Print model output
Выход
0.9950547536867305 -3
Применение сети ко многим наблюдениям / рядам данных
В этом разделе мы узнаем, как определить функцию под названиемgnast_With_Network (). Эта функция будет генерировать прогнозы для нескольких наблюдений данных, взятых из сети выше, взятой как input_data. Веса, указанные в приведенной выше сети, используются. Определение функции relu () также используется.
Давайте определим функцию под названиемgnestt_with_network (), которая принимает два аргумента — input_data_row и weights — и возвращает прогноз из сети в качестве вывода.
Мы вычисляем входные и выходные значения для каждого узла, сохраняя их как: node_0_input, node_0_output, node_1_input и node_1_output.
Чтобы вычислить входное значение узла, мы умножаем соответствующие массивы вместе и вычисляем их сумму.
Чтобы вычислить выходное значение узла, мы применяем функцию relu () к входному значению узла. Мы используем цикл for для перебора входных данных —
Мы также используем нашу Предикат_with_network () для генерации прогнозов для каждой строки input_data — input_data_row. Мы также добавляем каждый прогноз к результатам.
# Define predict_with_network() def predict_with_network(input_data_row, weights): # Calculate node 0 value node_0_input = (input_data_row * weights['node_0']).sum() node_0_output = relu(node_0_input) # Calculate node 1 value node_1_input = (input_data_row * weights['node_1']).sum() node_1_output = relu(node_1_input) # Put node values into array: hidden_layer_outputs hidden_layer_outputs = np.array([node_0_output, node_1_output]) # Calculate model output input_to_final_layer = (hidden_layer_outputs*weights['output']).sum() model_output = relu(input_to_final_layer) # Return model output return(model_output) # Create empty list to store prediction results results = [] for input_data_row in input_data: # Append prediction to results results.append(predict_with_network(input_data_row, weights)) print(results)# Print results
Выход
[0, 12]
Здесь мы использовали функцию relu, где relu (26) = 26 и relu (-13) = 0 и так далее.
Глубокие многослойные нейронные сети
Здесь мы пишем код для прямого распространения для нейронной сети с двумя скрытыми слоями. Каждый скрытый слой имеет два узла. Входные данные были предварительно загружены как input_data . Узлы в первом скрытом слое называются node_0_0 и node_0_1.
Их веса предварительно загружены в виде весов [‘node_0_0’] и весов [‘node_0_1’] соответственно.
Узлы во втором скрытом слое называются node_1_0 и node_1_1 . Их веса предварительно загружены как веса [‘node_1_0’] и веса [‘node_1_1’] соответственно.
Затем мы создаем вывод модели из скрытых узлов, используя веса, предварительно загруженные в качестве весов [‘output’] .
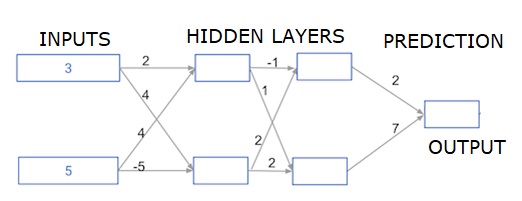
Мы рассчитываем node_0_0_input с использованием его весовых весов [‘node_0_0’] и заданных input_data. Затем примените функцию relu (), чтобы получить node_0_0_output.
Мы делаем то же самое, что и выше для node_0_1_input, чтобы получить node_0_1_output.
Мы вычисляем node_1_0_input, используя его веса weights [‘node_1_0’] и выходные данные первого скрытого слоя — hidden_0_outputs. Затем мы применяем функцию relu () для получения node_1_0_output.
Мы делаем то же самое, что и выше для node_1_1_input, чтобы получить node_1_1_output.
Мы рассчитываем model_output, используя weights [‘output’] и выходные данные из второго скрытого массива hidden_1_outputs. Мы не применяем функцию relu () к этому выводу.