Глубокая нейронная сеть (DNN) — это ANN с несколькими скрытыми слоями между входным и выходным слоями. Подобно мелким ANN, DNN могут моделировать сложные нелинейные отношения.
Основная цель нейронной сети состоит в том, чтобы получать набор входных данных, выполнять прогрессивно сложные вычисления и предоставлять выходные данные для решения реальных задач, таких как классификация. Мы ограничиваем себя для продвижения вперед нейронных сетей.
У нас есть вход, выход и поток последовательных данных в глубокой сети.
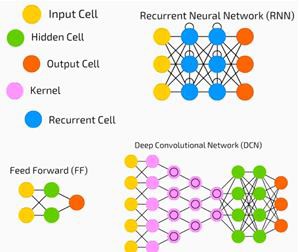
Нейронные сети широко используются в контролируемых задачах обучения и обучения. Эти сети основаны на наборе слоев, соединенных друг с другом.
При глубоком обучении количество скрытых слоев, в основном нелинейных, может быть большим; скажем около 1000 слоев.
Модели DL дают гораздо лучшие результаты, чем обычные сети ML.
В основном мы используем метод градиентного спуска для оптимизации сети и минимизации функции потерь.
Мы можем использовать Imagenet , хранилище миллионов цифровых изображений, чтобы классифицировать набор данных по категориям, таким как кошки и собаки. Сети DL все чаще используются для динамических изображений, кроме статических, а также для анализа временных рядов и текста.
Обучение наборов данных является важной частью моделей глубокого обучения. Кроме того, Backpropagation является основным алгоритмом обучения моделей DL.
DL занимается обучением больших нейронных сетей со сложными преобразованиями ввода-вывода.
Одним из примеров DL является сопоставление фотографии с именем человека (-ов) на фотографии, как это происходит в социальных сетях, и описание фотографии с помощью фразы — еще одно недавнее применение DL.
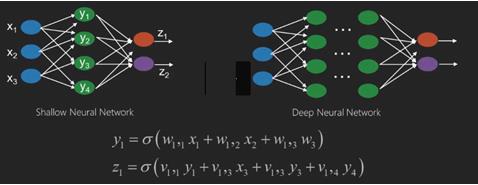
Нейронные сети — это функции, которые имеют входы, такие как x1, x2, x3…, которые преобразуются в выходы, такие как z1, z2, z3 и т. Д., В две (мелкие сети) или в несколько промежуточных операций, также называемых слоями (глубокие сети).
Веса и уклоны меняются от слоя к слою. «w» и «v» являются весами или синапсами слоев нейронных сетей.
Лучший вариант глубокого обучения — это контролируемая проблема обучения. Здесь у нас есть большой набор входных данных с желаемым набором выходных данных.
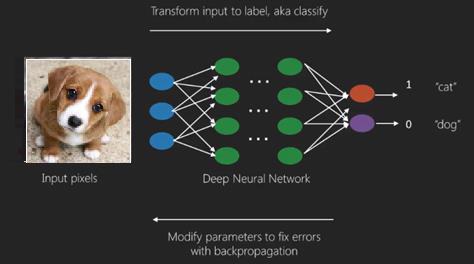
Здесь мы применяем алгоритм обратного распространения для получения правильного прогноза на выходе.
Самым базовым набором данных для глубокого изучения является MNIST, набор рукописных цифр.
Мы можем обучить глубокую сверточную нейронную сеть с Keras, чтобы классифицировать изображения рукописных цифр из этого набора данных.
Увольнение или активация классификатора нейронной сети дает оценку. Например, чтобы классифицировать пациентов как больных и здоровых, мы учитываем такие параметры, как рост, вес и температура тела, артериальное давление и т. Д.
Высокий балл означает, что пациент болен, а низкий балл означает, что он здоров.
Каждый узел в выходном и скрытом слоях имеет свои классификаторы. Входной слой получает входные данные и передает свои оценки следующему скрытому слою для дальнейшей активации, и это продолжается до тех пор, пока не будет достигнут вывод.
Этот прогресс от входа к выходу слева направо в прямом направлении называется прямым распространением.
Путь кредитного присвоения (CAP) в нейронной сети — это последовательность преобразований, начинающихся от входа к выходу. САР вырабатывают возможные причинно-следственные связи между входом и выходом.
Глубина CAP для данной нейронной сети с прямой связью или глубина CAP — это количество скрытых слоев плюс один в качестве выходного слоя. Для рекуррентных нейронных сетей, где сигнал может распространяться через слой несколько раз, глубина CAP может быть потенциально безгранична.
Глубокие сети и мелкие сети
Нет четкого порога глубины, который отделяет мелкое обучение от глубокого обучения; но в основном согласны, что для глубокого обучения, которое имеет несколько нелинейных уровней, CAP должен быть больше двух.
Базовый узел в нейронной сети — это восприятие, имитирующее нейрон в биологической нейронной сети. Тогда у нас есть многослойное восприятие или MLP. Каждый набор входов модифицируется набором весов и смещений; каждое ребро имеет уникальный вес, а каждый узел имеет уникальный уклон.
Точность предсказания нейронной сети зависит от ее веса и смещения.
Процесс повышения точности нейронной сети называется обучением. Выходной сигнал из прямой сети поддержки сравнивается с тем значением, которое, как известно, является правильным.
Функция затрат или функция потерь — это разница между сгенерированным и фактическим выходом.
Смысл обучения заключается в том, чтобы сделать затраты на обучение как можно меньшими на миллионах примеров обучения. Для этого сеть изменяет веса и смещения до тех пор, пока прогноз не будет соответствовать правильному результату.
После хорошей подготовки нейронная сеть может каждый раз делать точный прогноз.
Когда шаблон становится сложным и вы хотите, чтобы ваш компьютер распознал их, вы должны использовать нейронные сети. В таких сложных сценариях шаблонов нейронная сеть превосходит все конкурирующие алгоритмы.
В настоящее время существуют графические процессоры, которые могут обучать их быстрее, чем когда-либо прежде. Глубокие нейронные сети уже революционизируют область ИИ
Компьютеры хорошо зарекомендовали себя, выполняя повторяющиеся вычисления и следуя подробным инструкциям, но не очень хорошо распознавали сложные шаблоны.
Если существует проблема распознавания простых шаблонов, то машина опорных векторов (svm) или классификатор логистической регрессии могут хорошо справиться с этой задачей, но, поскольку сложность шаблонов возрастает, нет другого выхода, кроме как перейти к глубоким нейронным сетям.
Поэтому для сложных моделей, таких как человеческое лицо, мелкие нейронные сети терпят неудачу и не имеют альтернативы, кроме как перейти к глубоким нейронным сетям с большим количеством слоев. Глубокие сети могут выполнять свою работу, разбивая сложные шаблоны на более простые. Например, человеческое лицо; Адепская сеть использовала бы края, чтобы обнаружить такие части, как губы, нос, глаза, уши и т. д., а затем объединить их вместе, чтобы сформировать человеческое лицо
Точность правильного предсказания стала настолько точной, что в последнее время на конкурсе Google Pattern Recognition Challenge человек сильно ударил.
Эта идея сети слоистых персептронов была известна уже давно; в этой области глубокие сети имитируют человеческий мозг. Но одним из недостатков этого является то, что они занимают много времени на обучение, аппаратное ограничение
Однако недавние высокопроизводительные графические процессоры смогли обучить такие глубокие сети менее чем за неделю; в то время как быстрый процессор мог сделать недели или месяцы, чтобы сделать то же самое.
Выбор глубокой сети
Как выбрать глубокую сеть? Мы должны решить, строим ли мы классификатор или пытаемся найти шаблоны в данных, и будем ли мы использовать обучение без контроля. Чтобы извлечь шаблоны из набора немаркированных данных, мы используем ограниченную машину Больцмана или автоматический кодировщик.
При выборе глубокой сети учитывайте следующие моменты:
-
Для обработки текста, анализа настроений, анализа и распознавания имен мы используем рекуррентную сеть или рекурсивную нейронную тензорную сеть или RNTN;
-
Для любой языковой модели, которая работает на уровне символов, мы используем рекуррентную сеть.
-
Для распознавания изображений мы используем глубокую веру в сеть DBN или сверточную сеть.
-
Для распознавания объектов мы используем RNTN или сверточную сеть.
-
Для распознавания речи мы используем рекуррентную сеть.
Для обработки текста, анализа настроений, анализа и распознавания имен мы используем рекуррентную сеть или рекурсивную нейронную тензорную сеть или RNTN;
Для любой языковой модели, которая работает на уровне символов, мы используем рекуррентную сеть.
Для распознавания изображений мы используем глубокую веру в сеть DBN или сверточную сеть.
Для распознавания объектов мы используем RNTN или сверточную сеть.
Для распознавания речи мы используем рекуррентную сеть.
В целом, сети глубокого убеждения и многослойные персептроны с выпрямленными линейными единицами или RELU являются хорошими вариантами классификации.
Для анализа временных рядов всегда рекомендуется использовать рекуррентную сеть.
Нейронные сети существуют уже более 50 лет; но только теперь они стали заметными. Причина в том, что их трудно тренировать; Когда мы пытаемся обучить их с помощью метода, называемого обратным распространением, мы сталкиваемся с проблемой, называемой исчезновением или взрывом градиентов. Когда это происходит, обучение занимает больше времени, а точность отходит на второй план. При обучении набора данных мы постоянно вычисляем функцию стоимости, которая является разницей между прогнозируемым результатом и фактическим выходом из набора маркированных данных обучения. Затем функция стоимости минимизируется путем корректировки значений весов и смещений до самого низкого значения получается. В тренировочном процессе используется градиент, который представляет собой скорость, с которой стоимость будет изменяться по отношению к изменению значений веса или смещения.
Ограниченные сети Больцмана или автоэнкодеры — RBN
В 2006 году был достигнут прорыв в решении проблемы исчезающих градиентов. Джефф Хинтон разработал новую стратегию, которая привела к разработке Restricted Boltzman Machine — RBM , мелкой двухслойной сетки.
Первый слой — это видимый слой, а второй слой — это скрытый слой. Каждый узел в видимом слое связан с каждым узлом в скрытом слое. Сеть известна как ограниченная, так как никаким двум уровням в пределах одного уровня не разрешено совместно использовать соединение.
Автоэнкодеры — это сети, которые кодируют входные данные как векторы. Они создают скрытое или сжатое представление необработанных данных. Векторы полезны в уменьшении размерности; вектор сжимает необработанные данные в меньшее количество существенных измерений. Автоэнкодеры соединены с декодерами, что позволяет реконструировать входные данные на основе их скрытого представления.
RBM — это математический эквивалент двустороннего переводчика. Прямой проход принимает входные данные и переводит их в набор чисел, который кодирует входные данные. Обратный проход тем временем берет этот набор чисел и переводит их обратно в восстановленные входные данные. Хорошо обученная сеть выполняет подпорку с высокой степенью точности.
На обоих этапах вес и смещения играют критическую роль; они помогают RBM в декодировании взаимосвязей между входами и в определении того, какие входы важны для обнаружения шаблонов. Посредством прямого и обратного проходов RBM обучается восстанавливать входные данные с различными весами и смещениями до тех пор, пока входные данные и конструкция там не станут как можно ближе. Интересным аспектом RBM является то, что данные не должны быть помечены. Это оказывается очень важным для наборов данных реального мира, таких как фотографии, видео, голоса и данные датчиков, которые, как правило, не имеют маркировки. Вместо ручной маркировки данных людьми, RBM автоматически сортирует данные; путем правильной настройки весов и смещений, RBM может извлечь важные функции и реконструировать входные данные. RBM является частью семейства нейронных сетей экстракторов признаков, которые предназначены для распознавания присущих им данных в данных. Они также называются авто-кодерами, потому что они должны кодировать свою собственную структуру.

Сети глубокого убеждения — DBNs
Сети глубокого убеждения (DBN) формируются путем объединения RBM и внедрения умного метода обучения. У нас есть новая модель, которая окончательно решает проблему исчезающего градиента. Джефф Хинтон изобрел RBM, а также сети Deep Belief как альтернативу обратному распространению.
DBN похожа по структуре на MLP (многослойный персептрон), но очень отличается, когда дело доходит до обучения. это обучение, которое позволяет DBNs превзойти своих мелких коллег
DBN может быть визуализирован как стек RBM, где скрытый уровень одного RBM является видимым уровнем RBM над ним. Первый RBM обучен, чтобы реконструировать свой вклад как можно точнее.
Скрытый уровень первого RBM берется в качестве видимого уровня второго RBM, и второй RBM обучается с использованием выходных данных первого RBM. Этот процесс повторяется до тех пор, пока каждый слой в сети не будет обучен.
В DBN каждый RBM изучает весь ввод. DBN работает глобально, точно настраивая весь вход последовательно, поскольку модель медленно улучшается, как объектив камеры, медленно фокусирующий изображение. Стек RBM превосходит один RBM, так как многослойный персептрон MLP превосходит один персептрон.
На этом этапе RBM обнаружили характерные шаблоны в данных, но без каких-либо имен или меток. Чтобы завершить обучение DBN, мы должны ввести метки в шаблоны и настроить сеть с помощью контролируемого обучения.
Нам нужен очень маленький набор помеченных образцов, чтобы функции и шаблоны могли быть связаны с именем. Этот небольшой набор данных используется для обучения. Этот набор помеченных данных может быть очень маленьким по сравнению с исходным набором данных.
Веса и смещения слегка изменяются, что приводит к небольшому изменению восприятия сеткой шаблонов и часто к небольшому увеличению общей точности.
Обучение также может быть завершено за разумное время с использованием графических процессоров, дающих очень точные результаты по сравнению с мелкими сетями, и мы также видим решение проблемы исчезновения градиента.
Генеративные Состязательные Сети — ГАН
Генеративные противоборствующие сети — это глубокие нейронные сети, состоящие из двух сетей, расположенных друг против друга, таким образом, это «состязательное» название.
GAN были представлены в статье, опубликованной исследователями из Университета Монреаля в 2014 году. Эксперт по искусственному искусству Facebook Янн ЛеКан, ссылаясь на GAN, назвал состязательное обучение «самой интересной идеей за последние 10 лет в ML».
Потенциал GAN огромен, так как сканирование сети учится имитировать любое распределение данных. GAN можно научить создавать параллельные миры, поразительно похожие на наши, в любой области: изображения, музыка, речь, проза. Они в некотором роде художники-роботы, и их продукция впечатляет.
В GAN одна нейронная сеть, известная как генератор, генерирует новые экземпляры данных, а другая, дискриминатор, оценивает их на подлинность.
Допустим, мы пытаемся сгенерировать рукописные цифры, подобные найденным в наборе данных MNIST, который взят из реального мира. Работа дискриминатора, когда показан экземпляр из истинного набора данных MNIST, заключается в распознавании их как подлинных.
Теперь рассмотрим следующие шаги ГАН —
-
Сеть генераторов принимает входные данные в виде случайных чисел и возвращает изображение.
-
Это сгенерированное изображение передается в качестве входных данных в сеть дискриминатора вместе с потоком изображений, взятых из фактического набора данных.
-
Дискриминатор принимает как реальные, так и поддельные изображения и возвращает вероятности, числа от 0 до 1, где 1 представляет прогноз подлинности, а 0 — поддельный.
-
Таким образом, у вас есть двойной цикл обратной связи —
-
Дискриминатор находится в петле обратной связи с основополагающей правдой изображений, которые мы знаем.
-
Генератор находится в контуре обратной связи с дискриминатором.
-
Сеть генераторов принимает входные данные в виде случайных чисел и возвращает изображение.
Это сгенерированное изображение передается в качестве входных данных в сеть дискриминатора вместе с потоком изображений, взятых из фактического набора данных.
Дискриминатор принимает как реальные, так и поддельные изображения и возвращает вероятности, числа от 0 до 1, где 1 представляет прогноз подлинности, а 0 — поддельный.
Таким образом, у вас есть двойной цикл обратной связи —
Дискриминатор находится в петле обратной связи с основополагающей правдой изображений, которые мы знаем.
Генератор находится в контуре обратной связи с дискриминатором.
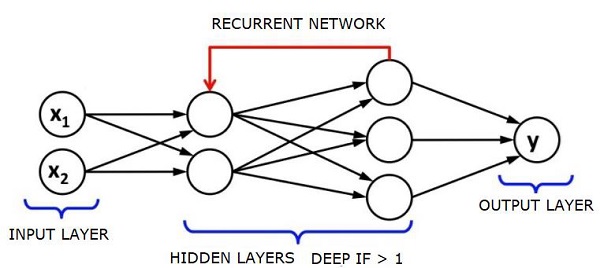
Рекуррентные нейронные сети — RNNs
RNN Саре нейронных сетей, в которых данные могут передаваться в любом направлении. Эти сети используются для таких приложений, как моделирование языка или обработка естественного языка (NLP).
Основная концепция, лежащая в основе RNN, заключается в использовании последовательной информации. В нормальной нейронной сети предполагается, что все входы и выходы независимы друг от друга. Если мы хотим предсказать следующее слово в предложении, мы должны знать, какие слова предшествовали ему.
RNN называются рекуррентными, поскольку они повторяют одну и ту же задачу для каждого элемента последовательности, причем выходные данные основаны на предыдущих вычислениях. Таким образом, можно сказать, что RNN имеют «память», которая захватывает информацию о том, что было вычислено ранее. Теоретически, RNN могут использовать информацию в очень длинных последовательностях, но в действительности они могут оглянуться назад лишь на несколько шагов.
Сети с кратковременной памятью (LSTM) являются наиболее часто используемыми сетями RNN.
Вместе с сверточными нейронными сетями RNN использовались как часть модели для создания описаний немаркированных изображений. Удивительно, насколько хорошо это работает.
Сверточные глубокие нейронные сети — CNNs
Если мы увеличиваем количество слоев в нейронной сети, чтобы сделать ее глубже, это увеличивает сложность сети и позволяет нам моделировать более сложные функции. Однако количество весов и уклонов будет экспоненциально увеличиваться. На самом деле, изучение таких сложных проблем может стать невозможным для обычных нейронных сетей. Это приводит к решению, сверточные нейронные сети.
CNN широко используются в компьютерном зрении; были применены также в акустическом моделировании для автоматического распознавания речи.
Идея, лежащая в основе сверточных нейронных сетей, заключается в идее «движущегося фильтра», который проходит через изображение. Этот движущийся фильтр, или свертка, применяется к определенной окрестности узлов, которые, например, могут быть пикселями, где примененный фильтр равен 0,5 x значению узла —
Известный исследователь Янн ЛеКан был пионером сверточных нейронных сетей. Facebook как программное обеспечение для распознавания лиц использует эти сети. CNN был идеальным решением для проектов машинного зрения. Существует много слоев в сверточной сети. В конкурсе Imagenet в 2015 году машина смогла победить человека при распознавании объекта.
Короче говоря, сверточные нейронные сети (CNN) являются многослойными нейронными сетями. Слои иногда до 17 или более и предполагают, что входными данными являются изображения.
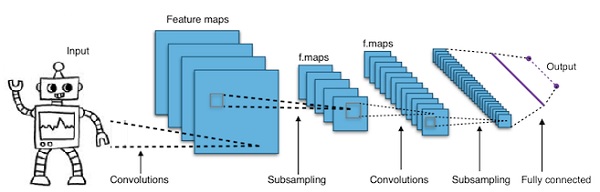
CNN резко сокращают количество параметров, которые необходимо настроить. Таким образом, CNN эффективно справляются с высокой размерностью необработанных изображений.