Что такое обучение усилению?
Укрепление обучения определяется как метод машинного обучения, который связан с тем, как программные агенты должны выполнять действия в среде. Укрепление обучения является частью метода глубокого обучения, который помогает вам максимизировать некоторую часть совокупного вознаграждения.
Этот метод обучения нейронной сети помогает вам научиться достигать сложной цели или максимизировать конкретное измерение за несколько этапов.
В учебном пособии по усиленному обучению вы изучите:
- Что такое обучение усилению?
- Важные термины, используемые в методе глубокого обучения
- Как работает Укрепление обучения?
- Укрепление алгоритмов обучения
- Характеристики Укрепления Обучения
- Типы Усиления обучения
- Учебные модели армирования
- Усиленное обучение против контролируемого обучения
- Применение Укрепления Обучения
- Зачем использовать Укрепление обучения?
- Когда не использовать обучение с подкреплением?
- Проблемы обучения с подкреплением
Важные термины, используемые в методе глубокого обучения
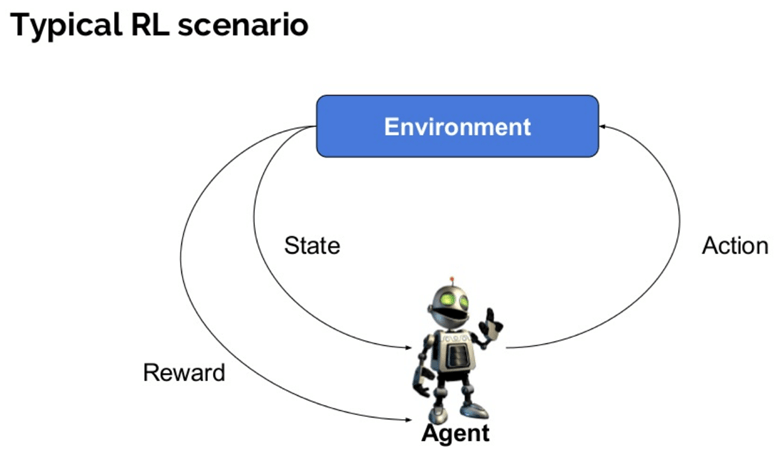
Вот некоторые важные термины, используемые в армировании AI:
- Агент: это предполагаемый объект, который выполняет действия в среде, чтобы получить некоторое вознаграждение.
- Среда (e): сценарий, с которым должен столкнуться агент.
- Награда (R): немедленное возвращение агенту, когда он или она выполняет определенное действие или задачу.
- Состояние (я): Состояние относится к текущей ситуации, возвращаемой окружающей средой.
- Политика (π): это стратегия, которая применяется агентом для определения следующего действия на основе текущего состояния.
- Значение (V): ожидается долгосрочный доход с дисконтом по сравнению с краткосрочным вознаграждением.
- Значение Функция: Она определяет значение состояния , которое является общей суммой вознаграждения. Это агент, которого следует ожидать, начиная с этого состояния.
- Модель окружающей среды: это имитирует поведение окружающей среды. Это поможет вам сделать выводы, а также определить, как будет вести себя окружающая среда.
- Методы, основанные на модели: это метод для решения задач обучения с подкреплением, который использует методы, основанные на модели.
- Значение Q или значение действия (Q): значение Q очень похоже на значение. Единственное различие между ними состоит в том, что он принимает дополнительный параметр в качестве текущего действия.
Как работает Укрепление обучения?
Давайте рассмотрим простой пример, который поможет вам проиллюстрировать механизм обучения с подкреплением.
Рассмотрим сценарий обучения новым трюкам вашей кошки
- Поскольку кошка не понимает английский или любой другой человеческий язык, мы не можем прямо сказать ей, что делать. Вместо этого мы следуем другой стратегии.
- Мы подражаем ситуации, и кошка пытается ответить по-разному. Если ответ кошки желаемый, мы дадим ей рыбу.
- Теперь, когда кошка подвергается той же ситуации, она выполняет подобное действие с еще большим энтузиазмом в ожидании получения большей награды (еды).
- Это все равно что учиться тому, что кошка получает от «того, что делать» из положительного опыта.
- В то же время кошка также учится тому, чего не следует делать, когда сталкивается с негативным опытом.
Пояснение к примеру:
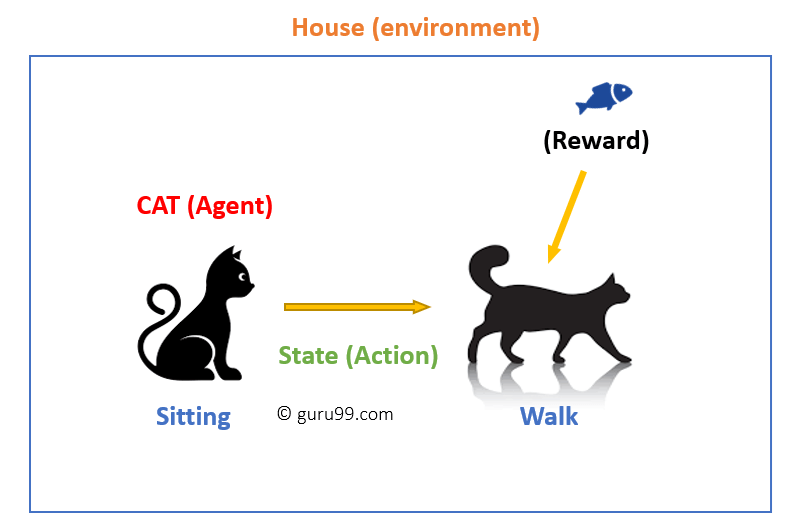
В этом случае,
- Ваша кошка является агентом, который подвергается воздействию окружающей среды. В данном случае это ваш дом. Примером состояния может быть ваша кошка, сидящая, и вы используете определенное слово, чтобы кошка могла ходить.
- Наш агент реагирует, выполняя переход действия из одного «состояния» в другое «состояние».
- Например, ваша кошка переходит от сидения к прогулке.
- Реакция агента — это действие, а политика — это метод выбора действия с учетом состояния в ожидании лучших результатов.
- После перехода они могут получить вознаграждение или штраф в ответ.
Укрепление алгоритмов обучения
Существует три подхода для реализации алгоритма обучения подкреплению.
Значение на основе:
В методе обучения на основе значений, основанного на значениях, вы должны попытаться максимизировать функцию значения V (s) . В этом методе агент ожидает долгосрочный возврат текущих состояний по политике π .
На основе политик:
В методе RL на основе политики вы пытаетесь придумать такую политику, чтобы действие, выполняемое в каждом состоянии, помогло вам получить максимальное вознаграждение в будущем.
Два типа основанных на политике методов:
- Детерминистический: для любого состояния, то же действие производится политикой π.
- Стохастик: Каждое действие имеет определенную вероятность, которая определяется следующим уравнением. Политика Стохастика:
n{a\s) = P\A, = a\S, =S]
Модель на основе:
В этом методе обучения подкреплению вам необходимо создать виртуальную модель для каждой среды. Агент учится работать в этой конкретной среде.
Характеристики Укрепления Обучения
Вот важные характеристики подкрепления обучения
- Там нет руководителя, только реальный номер или сигнал вознаграждения
- Последовательное принятие решений
- Время играет решающую роль в задачах подкрепления
- Обратная связь всегда задерживается, а не мгновенная
- Действия агента определяют последующие данные, которые он получает
Типы Усиления обучения
Два вида методов обучения подкрепления:
Положительный:
Он определяется как событие, которое происходит из-за определенного поведения. Это увеличивает силу и частоту поведения и положительно влияет на действия, предпринимаемые агентом.
Этот тип армирования помогает вам максимизировать производительность и поддерживать изменения в течение более длительного периода. Однако слишком большое усиление может привести к чрезмерной оптимизации состояния, что может повлиять на результаты.
Отрицательный:
Отрицательное подкрепление определяется как усиление поведения, которое происходит из-за негативного состояния, которое следует остановить или избежать. Это поможет вам определить минимальный уровень производительности. Однако недостатком этого метода является то, что он обеспечивает достаточно, чтобы соответствовать минимальному поведению.
Учебные модели армирования
В обучении с подкреплением есть две важные модели обучения:
- Марковский процесс принятия решений
- Q обучения
Марковский процесс принятия решений
Для получения решения используются следующие параметры:
- Набор действий — А
- Набор состояний -S
- Награда-R
- Полис
- Значение-V
Математический подход для картирования решения в обучении с подкреплением представляет собой Марковский процесс принятия решений или (MDP).
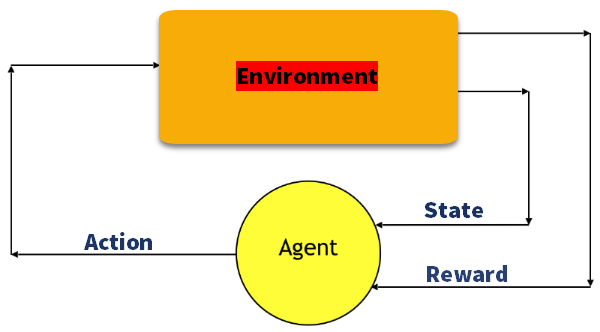
Q-Learning
Q обучение — это основанный на значении метод предоставления информации для информирования о том, какое действие должен предпринять агент.
Давайте разберем этот метод на следующем примере:
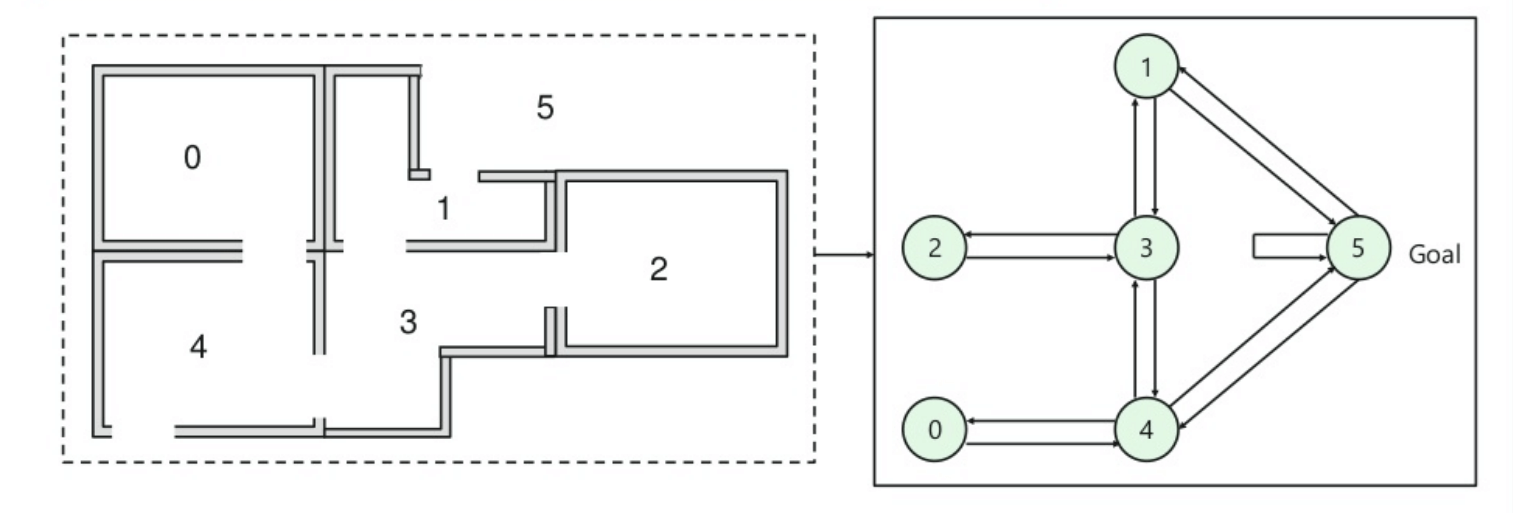
- В здании пять комнат, соединенных дверями.
- Каждая комната пронумерована от 0 до 4
- Снаружи здания может быть одна большая наружная территория (5)
- Двери № 1 и 4 ведут в здание из комнаты 5
Далее вам нужно связать значение вознаграждения с каждой дверью:
- Двери, ведущие прямо к цели, получают награду в 100
- Двери, которые не связаны напрямую с целевой комнатой, дают нулевое вознаграждение
- Так как двери двухсторонние, и для каждой комнаты назначены две стрелки
- Каждая стрелка на изображении выше содержит значение мгновенного вознаграждения
Объяснение:
На этом изображении вы можете увидеть, что комната представляет собой состояние
Перемещение агента из одной комнаты в другую представляет собой действие
На приведенном ниже изображении состояние описывается как узел, а стрелки показывают действие.
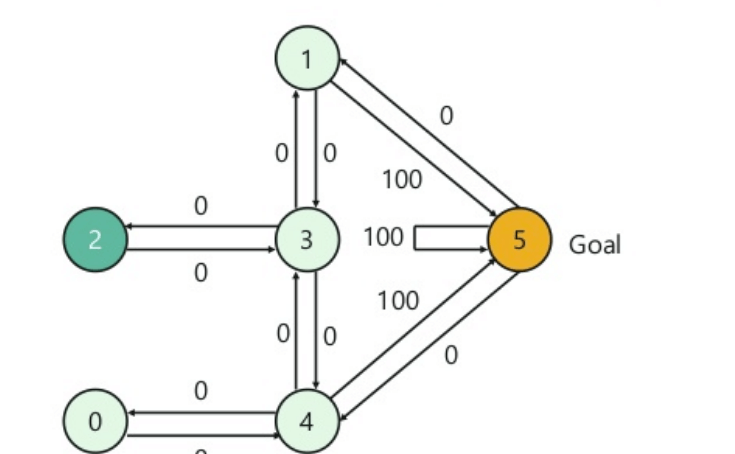
Например, агент переходит из комнаты № 2 в 5
- Начальное состояние = состояние 2
- Состояние 2-> состояние 3
- Состояние 3 -> состояние (2,1,4)
- Штат 4-> Штат (0,5,3)
- Штат 1-> штат (5,3)
- Состояние 0-> состояние 4
Усиленное обучение против контролируемого обучения
| параметры | Усиление обучения | Контролируемое обучение |
| Стиль решения | Обучение подкреплению помогает вам принимать ваши решения последовательно. | В этом методе решение принимается на входе, данном в начале. |
| Работает на | Работает на взаимодействие с окружающей средой. | Работает на примерах или данных образца. |
| Зависимость от решения | В RL метод обучения решение зависит. Поэтому вы должны давать ярлыки всем зависимым решениям. | Контролировал изучение решений, которые не зависят друг от друга, поэтому ярлыки присваиваются каждому решению. |
| Лучше всего подходит | Поддерживает и лучше работает в искусственном интеллекте, где преобладает человеческое взаимодействие. | Он в основном работает с интерактивной системой программного обеспечения или приложений. |
| пример | Шахматы | Распознавание объектов |
Применение Укрепления Обучения
Вот приложения Укрепления Обучения:
- Робототехника для промышленной автоматизации.
- Планирование бизнес стратегии
- Машинное обучение и обработка данных
- Это помогает вам создавать системы обучения, которые предоставляют индивидуальные инструкции и материалы в соответствии с требованиями студентов.
- Управление самолетом и управление движением робота
Зачем использовать Укрепление обучения?
Вот основные причины использования обучения с подкреплением:
- Это поможет вам найти, какая ситуация требует действий
- Помогает вам узнать, какое действие приносит наибольшее вознаграждение за более длительный период.
- Укрепление обучения также предоставляет обучающему агенту функцию вознаграждения.
- Это также позволяет ему найти лучший способ получения больших наград.
Когда не использовать обучение с подкреплением?
Вы не можете применить модель обучения подкрепления во всех ситуациях. Вот некоторые условия, когда вы не должны использовать модель обучения с подкреплением.
- Когда у вас есть достаточно данных, чтобы решить проблему с помощью контролируемого метода обучения
- Вы должны помнить, что обучение в области подкрепления требует больших вычислительных ресурсов и времени. в частности, когда пространство действия велико.
Проблемы обучения с подкреплением
Вот основные проблемы, с которыми вы столкнетесь, зарабатывая подкрепление:
- Особенность / награда дизайн, который должен быть очень вовлечен
- Параметры могут влиять на скорость обучения.
- Реалистичные среды могут иметь частичную наблюдаемость.
- Слишком сильное усиление может привести к перегрузке состояний, что может уменьшить результаты.
- Реалистичная среда может быть нестационарной.
Резюме:
- Укрепление обучения является методом машинного обучения
- Помогает вам узнать, какое действие приносит наибольшее вознаграждение за более длительный период.
- Существует три метода обучения с подкреплением: 1) основанное на ценностях 2) основанное на политике и основанное на модели обучение.
- Агент, Состояние, Вознаграждение, Среда, Функция ценности. Модель среды, Методы, основанные на модели, — некоторые важные термины, используемые в методе обучения RL.
- Примером обучения с подкреплением является то, что ваша кошка является агентом, который подвергается воздействию окружающей среды.
- Самая большая особенность этого метода — отсутствие руководителя, только реальное число или сигнал вознаграждения.
- Два типа обучения подкрепления: 1) положительный 2) отрицательный
- Две широко используемые модели обучения: 1) Марковский процесс принятия решения 2) Q обучение
- Метод обучения с подкреплением работает на взаимодействие с окружающей средой, в то время как метод обучения под наблюдением работает на данных образца или пример.
- Прикладные или вспомогательные методы обучения: Робототехника для промышленной автоматизации и планирования бизнес-стратегии.
- Вы не должны использовать этот метод, когда у вас есть достаточно данных, чтобы решить проблему
- Самая большая проблема этого метода заключается в том, что параметры могут влиять на скорость обучения