Что такое машинное обучение?
Машинное обучение — это система, которая может учиться на примере путем самосовершенствования и без явного программирования программистом. Прорыв приходит с идеей, что машина может по отдельности учиться на данных (например, на примере) для получения точных результатов.
Машинное обучение объединяет данные со статистическими инструментами для прогнозирования результатов. Этот результат затем используется корпорацией, чтобы сделать действенные идеи. Машинное обучение тесно связано с интеллектуальным анализом данных и байесовским прогнозным моделированием. Машина получает данные в качестве входных данных, использует алгоритм для формулирования ответов.
Типичными задачами машинного обучения являются предоставление рекомендаций. Для тех, кто имеет учетную запись Netflix, все рекомендации фильмов или сериалов основаны на исторических данных пользователя. Технологические компании используют неконтролируемое обучение для улучшения взаимодействия с персонализированными рекомендациями.
Машинное обучение также используется для решения различных задач, таких как обнаружение мошенничества, профилактическое обслуживание, оптимизация портфеля, автоматизация задачи и так далее.
В этом базовом уроке вы узнаете
- Что такое машинное обучение?
- Машинное обучение против традиционного программирования
- Как работает машинное обучение?
- Алгоритмы машинного обучения и где они используются?
- Как выбрать алгоритм машинного обучения
- Проблемы и ограничения машинного обучения
- Применение машинного обучения
- Почему машинное обучение важно?
Машинное обучение против традиционного программирования
Традиционное программирование существенно отличается от машинного обучения. В традиционном программировании программист кодирует все правила в консультации с экспертом в отрасли, для которой разрабатывается программное обеспечение. Каждое правило основано на логической основе; машина выполнит вывод, следующий за логическим утверждением. Когда система становится сложной, необходимо написать больше правил. Это может быстро стать неприемлемым для поддержания.
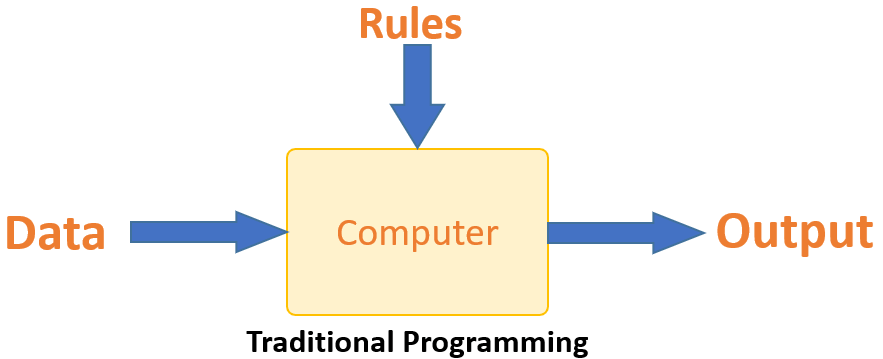
Машинное обучение должно преодолеть эту проблему. Машина узнает, как соотносятся входные и выходные данные, и записывает правило. Программистам не нужно писать новые правила каждый раз, когда появляются новые данные. Алгоритмы адаптируются в ответ на новые данные и опыт для повышения эффективности с течением времени.

Как работает машинное обучение?
Машинное обучение — это мозг, где происходит все обучение. То, как машина учится, похоже на человека. Люди учатся на опыте. Чем больше мы знаем, тем легче нам предсказать. По аналогии, когда мы сталкиваемся с неизвестной ситуацией, вероятность успеха ниже известной ситуации. Машины обучены одинаково. Чтобы сделать точный прогноз, машина видит пример. Когда мы дадим машине аналогичный пример, он может выяснить результат. Однако, как и человек, если его подавать на невиданный ранее пример, машине сложно прогнозировать.
Основной целью машинного обучения является обучение и умозаключение . Прежде всего, машина учится благодаря открытию закономерностей. Это открытие сделано благодаря данным . Одна из важнейших задач исследователя данных — тщательно выбирать, какие данные предоставить машине. Список атрибутов, используемых для решения проблемы, называется вектором объектов. Вы можете думать о векторе признаков как о подмножестве данных, которое используется для решения проблемы.
Машина использует некоторые причудливые алгоритмы, чтобы упростить реальность и преобразовать это открытие в модель . Поэтому этап обучения используется для описания данных и их обобщения в модель.
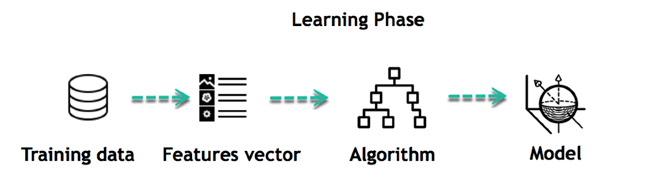
Например, машина пытается понять взаимосвязь между заработной платой человека и вероятностью пойти в модный ресторан. Оказывается, машина находит позитивную связь между заработной платой и посещением элитного ресторана: это модель
Выведение
Когда модель построена, можно проверить, насколько мощной она является для данных, которые ранее не видели. Новые данные преобразуются в вектор признаков, проходят модель и дают прогноз. Это все прекрасная часть машинного обучения. Нет необходимости обновлять правила или заново тренировать модель. Вы можете использовать ранее обученную модель, чтобы сделать вывод о новых данных.
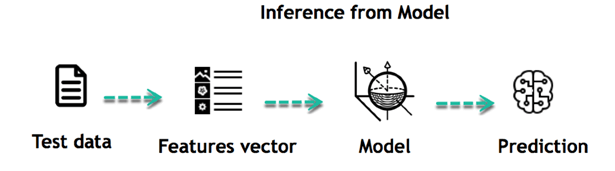
Жизнь программ машинного обучения проста и может быть кратко изложена в следующих пунктах:
- Определите вопрос
- Собирать данные
- Визуализируйте данные
- Алгоритм поезда
- Протестируйте алгоритм
- Собирать отзывы
- Уточните алгоритм
- Цикл 4-7, пока результаты не будут удовлетворительными
- Используйте модель, чтобы сделать прогноз
Как только алгоритм научится делать правильные выводы, он применяет эти знания к новым наборам данных.
Алгоритмы машинного обучения и где они используются?
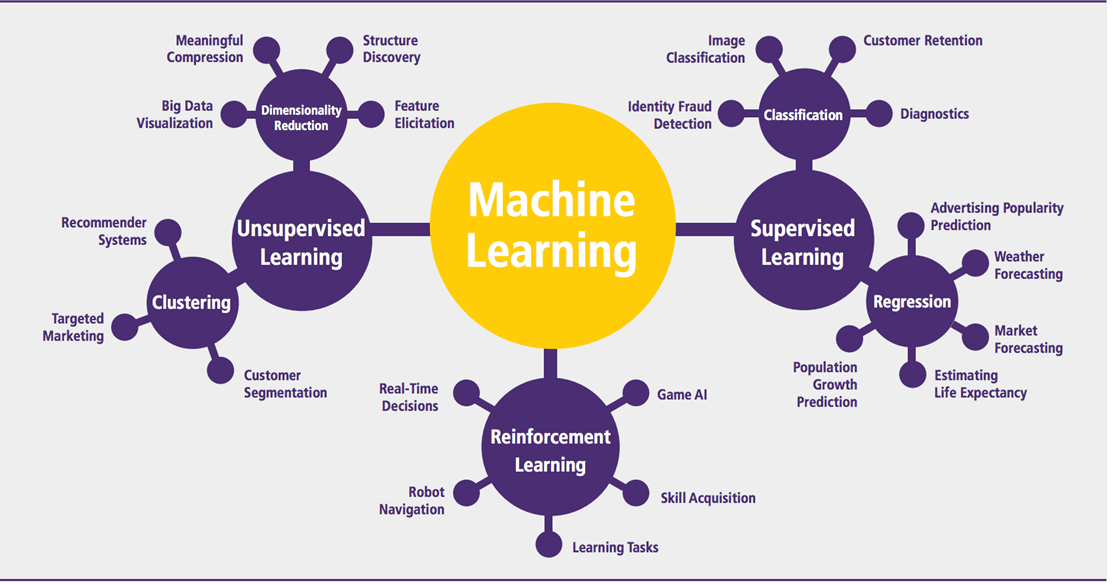
Машинное обучение может быть сгруппировано в две широкие учебные задачи: контролируемое и неконтролируемое. Есть много других алгоритмов
Контролируемое обучение
Алгоритм использует обучающие данные и обратную связь от людей, чтобы узнать связь данных входов с данным выходом. Например, практикующий врач может использовать маркетинговые расходы и прогноз погоды в качестве входных данных для прогнозирования продаж банок.
Вы можете использовать контролируемое обучение, когда выходные данные известны. Алгоритм будет предсказывать новые данные.
Есть две категории контролируемого обучения:
- Классификационное задание
- Регрессионное задание
классификация
Представьте, что вы хотите предсказать пол клиента для рекламы. Вы начнете собирать данные о росте, весе, работе, зарплате, корзине покупок и т. Д. Из своей базы данных клиентов. Вы знаете пол каждого вашего клиента, это может быть только мужчина или женщина. Целью классификатора будет назначение вероятности быть мужчиной или женщиной (т. Е. Метка) на основе информации (т. Е. Особенностей, которые вы собрали). Когда модель узнала, как распознать мужчину или женщину, вы можете использовать новые данные, чтобы сделать прогноз. Например, вы только что получили новую информацию от неизвестного покупателя и хотите узнать, мужчина это или женщина. Если классификатор предсказывает, что мужчина = 70%, это означает, что алгоритм уверен на 70%, что этот клиент — мужчина, а 30% — женщина.
Метка может быть двух или более классов. В приведенном выше примере есть только два класса, но если классификатор должен предсказать объект, он имеет десятки классов (например, стекло, стол, обувь и т. Д. Каждый объект представляет класс)
регрессия
Когда выходные данные являются непрерывным значением, задача является регрессией. Например, финансовому аналитику может потребоваться прогнозировать стоимость акций на основе ряда характеристик, таких как капитал, предыдущие показатели акций, макроэкономический индекс. Система будет обучена оценивать цены акций с минимально возможной ошибкой.
| Название алгоритма | Описание | Тип |
| Линейная регрессия | Находит способ соотнести каждую функцию с выходными данными, чтобы помочь предсказать будущие значения. | регрессия |
| Логистическая регрессия | Расширение линейной регрессии, которая используется для задач классификации. Выходная переменная 3 является двоичной (например, только черный или белый), а не непрерывной (например, бесконечный список потенциальных цветов) | классификация |
| Древо решений | Высоко интерпретируемая модель классификации или регрессии, которая разделяет значения признаков данных на ветви в узлах принятия решения (например, если признак является цветом, каждый возможный цвет становится новой ветвью) до тех пор, пока не будет сделан окончательный вывод решения | Регрессионная классификация |
| Наивный байесовский | Байесовский метод — это метод классификации, использующий теорему Байеса. Теорема обновляет предварительное знание события с независимой вероятностью каждого признака, который может повлиять на событие. | Регрессионная классификация |
| Машина опорных векторов | Машина опорных векторов, или SVM, обычно используется для задачи классификации. Алгоритм SVM находит гиперплоскость, которая оптимально разделяет классы. Лучше всего использовать с нелинейным решателем. | Регрессионная (не очень распространенная) классификация |
| Случайный лес | Алгоритм построен на дереве решений для значительного повышения точности. Случайный лес генерирует многократно простые деревья решений и использует метод «большинства голосов», чтобы решить, какую метку вернуть. Для задачи классификации окончательным прогнозом будет тот, который получит наибольшее количество голосов; в то время как для задачи регрессии среднее предсказание всех деревьев является окончательным предсказанием. | Регрессионная классификация |
| AdaBoost | Техника классификации или регрессии, которая использует множество моделей для принятия решения, но взвешивает их на основе их точности в прогнозировании результата | Регрессионная классификация |
| Повышающие градиент деревья | Деревья, повышающие градиент, — это современная техника классификации / регрессии. Он фокусируется на ошибке, допущенной предыдущими деревьями, и пытается ее исправить. | Регрессионная классификация |
Неконтролируемое обучение
При неконтролируемом обучении алгоритм исследует входные данные без указания явной выходной переменной (например, исследует демографические данные клиента для выявления закономерностей)
Вы можете использовать его, когда вы не знаете, как классифицировать данные, и вы хотите, чтобы алгоритм нашел шаблоны и классифицировал данные для вас.
| Алгоритм | Описание |
Тип |
|
K-означает кластеризацию |
Разбивает данные на несколько групп (k), каждая из которых содержит данные с похожими характеристиками (как определено моделью, а не заранее людьми) |
Кластеризация |
|
Модель гауссовой смеси |
Обобщение кластеризации k-средних, обеспечивающее большую гибкость в отношении размера и формы групп (кластеров). |
Кластеризация |
|
Иерархическая кластеризация |
Разбивает кластеры по иерархическому дереву для формирования системы классификации. Может быть использован для клиента карты лояльности Кластера |
Кластеризация |
|
Рекомендательная система |
Помогите определить соответствующие данные для вынесения рекомендации. |
Кластеризация |
|
РС / Т-СНЭ |
В основном используется для уменьшения размерности данных. Алгоритмы уменьшают количество признаков до 3 или 4 векторов с наибольшей дисперсией. |
Уменьшение размеров |
Как выбрать алгоритм машинного обучения
Существует множество алгоритмов машинного обучения. Выбор алгоритма основан на цели.
В приведенном ниже примере задача состоит в том, чтобы предсказать тип цветка среди трех сортов. Прогнозы основаны на длине и ширине лепестка. На рисунке изображены результаты десяти различных алгоритмов. Картинка вверху слева — это набор данных. Данные подразделяются на три категории: красный, светло-синий и темно-синий. Есть несколько группировок. Например, на втором изображении все в верхнем левом углу относится к красной категории, в средней части — смесь неопределенности и светло-голубого, а нижняя соответствует темной категории. Другие изображения показывают разные алгоритмы и то, как они пытаются классифицировать данные.

Проблемы и ограничения машинного обучения
Основной проблемой машинного обучения является отсутствие данных или разнообразие в наборе данных. Машина не может учиться, если нет доступных данных. Кроме того, набор данных с отсутствием разнообразия доставляет машине трудные времена. Машина должна иметь неоднородность, чтобы научиться осмысленному пониманию. Редко когда алгоритм может извлекать информацию, когда нет или мало изменений. Рекомендуется иметь не менее 20 наблюдений на группу, чтобы помочь машине научиться. Это ограничение приводит к плохой оценке и прогнозу.
Применение машинного обучения
Увеличение :
- Машинное обучение, которое помогает людям справляться с повседневными задачами лично или в коммерческих целях, не имея полного контроля над результатами. Такое машинное обучение используется различными способами, такими как виртуальный помощник, анализ данных, программные решения. Основной пользователь должен уменьшить ошибки из-за предвзятости человека.
Автоматизация :
- Машинное обучение, которое работает полностью автономно в любой области без необходимости вмешательства человека. Например, роботы, выполняющие основные технологические этапы на производственных предприятиях.
Финансовая индустрия
- Машинное обучение набирает популярность в финансовой сфере. Банки в основном используют ML для нахождения шаблонов внутри данных, а также для предотвращения мошенничества.
Правительственная организация
- Правительство использует ОД для управления общественной безопасностью и коммунальными услугами. Возьмите пример Китая с массивным распознаванием лиц. Правительство использует искусственный интеллект, чтобы предотвратить сойку.
Индустрия здравоохранения
- Здравоохранение было одной из первых в отрасли, которая использовала машинное обучение с обнаружением изображений.
маркетинг
- Широкое использование ИИ осуществляется в маркетинге благодаря обширному доступу к данным. До появления массовых данных исследователи разрабатывали передовые математические инструменты, такие как байесовский анализ, для оценки ценности клиента. С бумом данных, отдел маркетинга полагается на ИИ для оптимизации отношений с клиентами и маркетинговой кампании.
Пример применения машинного обучения в цепочке поставок
Машинное обучение дает потрясающие результаты для визуального распознавания образов, открывая множество потенциальных приложений для физического осмотра и технического обслуживания во всей сети цепочки поставок.
Обучение без учителя может быстро найти сопоставимые шаблоны в разнообразном наборе данных. В свою очередь, машина может выполнять проверку качества на всем протяжении логистического центра, отгрузки с повреждениями и износом.
Например, платформа IBM Watson может определять повреждение транспортировочного контейнера. Watson объединяет визуальные и системные данные для отслеживания, составления отчетов и предоставления рекомендаций в режиме реального времени.
В прошлом году управляющий акциями в значительной степени опирался на основной метод оценки и прогнозирования запасов. При объединении больших данных и машинного обучения были внедрены лучшие методы прогнозирования (улучшение на 20-30% по сравнению с традиционными инструментами прогнозирования). С точки зрения продаж это означает увеличение на 2–3% из-за потенциального снижения стоимости запасов.
Пример машинного обучения Google Car
Например, все знают машину Google. Автомобиль полон лазеров на крыше, которые говорят ему, где он находится вокруг. Спереди установлен радар, который информирует автомобиль о скорости и движении всех автомобилей вокруг него. Он использует все эти данные, чтобы выяснить не только, как вести машину, но также чтобы выяснить и предсказать, что будут делать потенциальные водители вокруг машины. Что впечатляет, так это то, что машина обрабатывает почти гигабайт в секунду данных.
Почему машинное обучение важно?
На данный момент машинное обучение — лучший инструмент для анализа, понимания и определения закономерностей в данных. Одна из основных идей машинного обучения заключается в том, что компьютер можно обучить для автоматизации задач, которые были бы исчерпывающими или невозможными для человека. Очевидным недостатком традиционного анализа является то, что машинное обучение может принимать решения с минимальным вмешательством человека.
Возьмите следующий пример; розничный агент может оценить цену дома на основе своего собственного опыта и своих знаний о рынке.
Машину можно обучить переводить знания эксперта в особенности. Особенности — это все характеристики дома, района, экономической среды и т. Д., Которые влияют на цену. Для эксперта ему понадобилось несколько лет, чтобы овладеть искусством оценки цены дома. Его опыт становится все лучше и лучше после каждой продажи.
Для машины требуются миллионы данных (например, пример), чтобы овладеть этим искусством. В самом начале своего обучения машина совершает ошибку, как и младший продавец. Как только машина увидит все примеры, у нее будет достаточно знаний, чтобы ее оценить. В то же время, с невероятной точностью. Машина также может соответствующим образом исправить свою ошибку.
Большинство крупных компаний поняли ценность машинного обучения и хранения данных. МакКинсите подсчитал , что стоимость аналитики колеблется от $ 9500000000000 до $ 15400000000000 в то время как $ 5 до 7 триллионов можно отнести к наиболее передовым методам искусственного интеллекта.