Что такое контролируемое машинное обучение?
При обучении под наблюдением вы обучаете машину, используя данные, которые хорошо «помечены ». Это означает, что некоторые данные уже помечены с правильным ответом. Это можно сравнить с обучением, которое происходит в присутствии руководителя или учителя.
Алгоритм контролируемого обучения учится на помеченных данных обучения, помогает вам прогнозировать результаты непредвиденных данных.
Успешное создание, масштабирование и развертывание точных контролируемых моделей машинного обучения требует времени и технических знаний от команды высококвалифицированных специалистов по обработке данных. Более того, специалист по обработке данных должен перестроить модели, чтобы убедиться, что предоставленная информация остается верной, пока ее данные не изменятся.
В этом уроке вы узнаете:
- Что такое контролируемое машинное обучение?
- Как работает контролируемое обучение
- Типы контролируемых алгоритмов машинного обучения
- Методы машинного обучения под надзором и без присмотра
- Проблемы контролируемого машинного обучения
- Преимущества контролируемого обучения:
- Недостатки контролируемого обучения
- Лучшие практики для контролируемого обучения
Как работает контролируемое обучение
Например, вы хотите обучить машину, которая поможет вам предсказать, сколько времени вам потребуется, чтобы отвезти вас домой с работы. Здесь вы начинаете с создания набора помеченных данных. Эти данные включают
- Погодные условия
- Время суток
- каникулы
Все эти детали ваши входные данные. Вывод — это количество времени, которое потребовалось, чтобы вернуться домой в тот день.

Вы инстинктивно знаете, что если на улице идет дождь, то вам потребуется больше времени, чтобы доехать до дома. Но машине нужны данные и статистика.
Let’s see now how you can develop a supervised learning model of this example which help the user to determine the commute time. The first thing you requires to create is a training set. This training set will contain the total commute time and corresponding factors like weather, time, etc. Based on this training set, your machine might see there’s a direct relationship between the amount of rain and time you will take to get home.
So, it ascertains that the more it rains, the longer you will be driving to get back to your home. It might also see the connection between the time you leave work and the time you’ll be on the road.
The closer you’re to 6 p.m. the longer it takes for you to get home. Your machine may find some of the relationships with your labeled data.
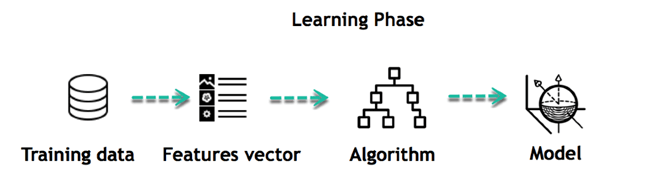
This is the start of your Data Model. It begins to impact how rain impacts the way people drive. It also starts to see that more people travel during a particular time of day.
Types of Supervised Machine Learning Algorithms
Regression:
Regression technique predicts a single output value using training data.
Example: You can use regression to predict the house price from training data. The input variables will be locality, size of a house, etc.
Strengths: Outputs always have a probabilistic interpretation, and the algorithm can be regularized to avoid overfitting.
Weaknesses: Logistic regression may underperform when there are multiple or non-linear decision boundaries. This method is not flexible, so it does not capture more complex relationships.
Logistic Regression:
Logistic regression method used to estimate discrete values based on given a set of independent variables. It helps you to predicts the probability of occurrence of an event by fitting data to a logit function. Therefore, it is also known as logistic regression. As it predicts the probability, its output value lies between 0 and 1.
Here are a few types of Regression Algorithms
Classification:
Classification means to group the output inside a class. If the algorithm tries to label input into two distinct classes, it is called binary classification. Selecting between more than two classes is referred to as multiclass classification.
Example: Determining whether or not someone will be a defaulter of the loan.
Strengths: Classification tree perform very well in practice
Weaknesses: Unconstrained, individual trees are prone to overfitting.
Here are a few types of Classification Algorithms
Naïve Bayes Classifiers
Naïve Bayesian model (NBN) is easy to build and very useful for large datasets. This method is composed of direct acyclic graphs with one parent and several children. It assumes independence among child nodes separated from their parent.
Decision Trees
Decisions trees classify instance by sorting them based on the feature value. In this method, each mode is the feature of an instance. It should be classified, and every branch represents a value which the node can assume. It is a widely used technique for classification. In this method, classification is a tree which is known as a decision tree.
It helps you to estimate real values (cost of purchasing a car, number of calls, total monthly sales, etc.).
Support Vector Machine
Support vector machine (SVM) is a type of learning algorithm developed in 1990. This method is based on results from statistical learning theory introduced by Vap Nik.
SVM machines are also closely connected to kernel functions which is a central concept for most of the learning tasks. The kernel framework and SVM are used in a variety of fields. It includes multimedia information retrieval, bioinformatics, and pattern recognition.
Supervised vs. Unsupervised Machine learning techniques
| Based On | Supervised machine learning technique | Unsupervised machine learning technique |
| Input Data | Algorithms are trained using labeled data. | Algorithms are used against data which is not labelled |
| Computational Complexity | Контролируемое обучение является более простым методом. | Неуправляемое обучение является вычислительно сложным |
| точность | Высокоточный и заслуживающий доверия метод. | Менее точный и заслуживающий доверия метод. |
Проблемы контролируемого машинного обучения
Вот проблемы, стоящие перед контролируемым машинным обучением:
- Нерелевантная функция ввода данных о тренировке может дать неточные результаты
- Подготовка и предварительная обработка данных — это всегда сложная задача.
- Точность страдает, когда невозможно, маловероятно, и в качестве обучающих данных были введены неполные значения
- Если заинтересованного эксперта нет, тогда другой подход — «грубая сила». Это означает, что вы должны думать, что правильные функции (входные переменные) для обучения машины. Это может быть неточным.
Преимущества контролируемого обучения:
- Обучение под наблюдением позволяет вам собирать данные или производить вывод данных из предыдущего опыта
- Помогает оптимизировать критерии производительности, используя опыт
- Управляемое машинное обучение помогает вам решать различные типы реальных вычислительных задач.
Недостатки контролируемого обучения
- Граница принятия решения может быть перегружена, если в вашем тренировочном наборе нет примеров, которые вы хотите иметь в классе
- Вам нужно выбрать много хороших примеров из каждого класса, пока вы тренируете классификатор.
- Классификация больших данных может быть реальной проблемой.
- Тренинг для контролируемого обучения требует много вычислительного времени.
Лучшие практики для контролируемого обучения
- Прежде чем делать что-либо еще, вы должны решить, какие данные будут использоваться в качестве учебного набора
- Вам необходимо определиться со структурой изучаемой функции и алгоритма обучения.
- Соберите соответствующие результаты или от человеческих экспертов или от измерений
Резюме
- При обучении под наблюдением вы обучаете машину, используя данные, которые хорошо «помечены».
- Вы хотите обучить машину, которая поможет вам предсказать, сколько времени вам потребуется, чтобы отвезти вас домой с работы — пример обучения под наблюдением
- Регрессия и классификация являются двумя типами контролируемых методов машинного обучения.
- Контролируемое обучение является более простым методом, в то время как неконтролируемое обучение является сложным методом.
- Самая большая проблема в контролируемом обучении заключается в том, что несоответствующая функция ввода данных о тренировке может дать неточные результаты.
- Основным преимуществом контролируемого обучения является то, что оно позволяет вам собирать данные или производить вывод данных из предыдущего опыта.
- Недостаток этой модели заключается в том, что граница принятия решения может быть перегружена, если в вашем учебном наборе нет примеров, которые вы хотите иметь в классе.
- В качестве лучшей практики надзора за обучением сначала необходимо решить, какие данные следует использовать в качестве учебного набора.