Что такое стек ELK?
ELK Stack — это коллекция из трех продуктов с открытым исходным кодом — Elasticsearch, Logstash и Kibana. Все они разработаны, управляются и обслуживаются компанией Elastic.
- E обозначает ElasticSearch: используется для хранения логов
- L означает LogStash: используется как для доставки, так и для обработки и хранения журналов
- K означает Kibana: это инструмент визуализации (веб-интерфейс), который размещается через Nginx или Apache.
ELK Stack предназначен для того, чтобы пользователи могли получать данные из любого источника в любом формате, а также осуществлять поиск, анализ и визуализацию этих данных в режиме реального времени.
ELK обеспечивает централизованное ведение журналов, что полезно при попытке выявления проблем с серверами или приложениями. Это позволяет вам искать все ваши журналы в одном месте. Это также помогает находить проблемы, возникающие на нескольких серверах, подключая их журналы в течение определенного периода времени.
В этом уроке вы узнаете
- Что такое стек ELK?
- ELK Stack Архитектура
- Что такое Elasticsearch?
- Что такое Logstash?
- Что такое кибана?
- Лось против спленка
- Тематические исследования
- Преимущества и недостатки стека ELK
ELK Stack Архитектура
Вот простая архитектура стека ELK
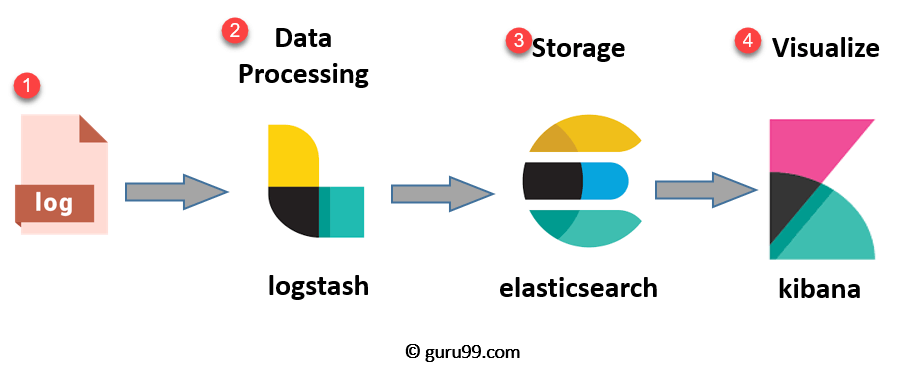
- Журналы: идентифицируются журналы сервера, которые необходимо проанализировать
- Logstash: сбор журналов и данных о событиях. Он даже анализирует и преобразует данные
- ElasticSearch: преобразованные данные из Logstash — это Store, Search и indexed.
- Kibana: Kibana использует Elasticsearch DB для исследования, визуализации и обмена
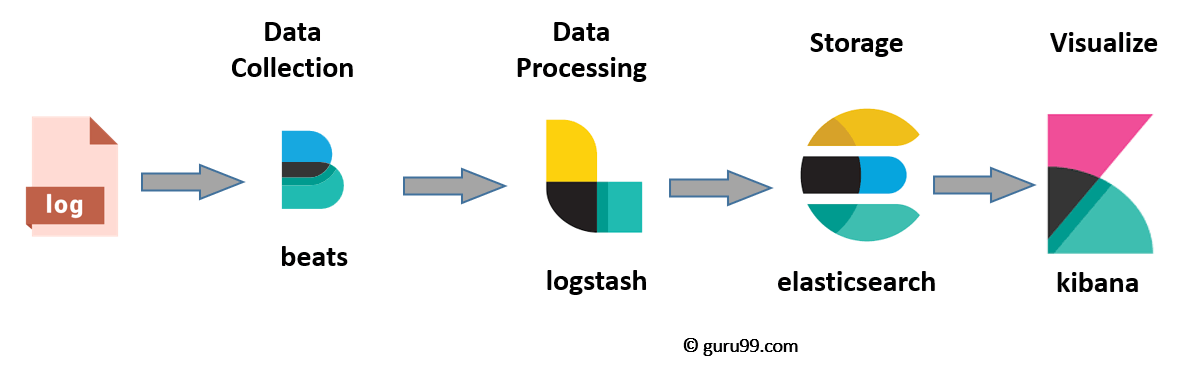
Тем не менее, необходим еще один компонент или сбор данных под названием Beats. Это привело Elastic к переименованию ELK в Elastic Stack.
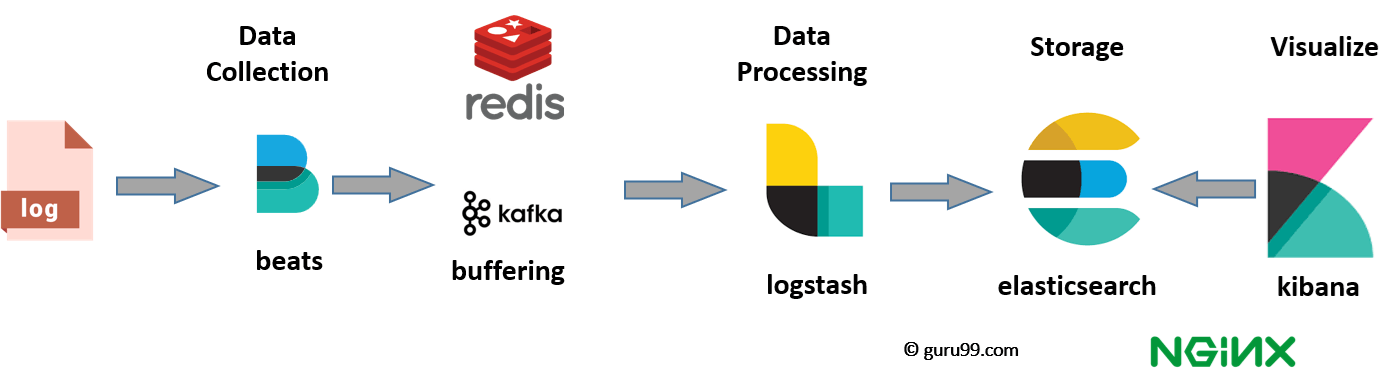
При работе с очень большими объемами данных вам может понадобиться Kafka, RabbitMQ для буферизации и устойчивости. Для безопасности можно использовать nginx.
Давайте подробно рассмотрим все эти продукты с открытым исходным кодом:
Что такое Elasticsearch?
Elasticsearch — это база данных NoSQL. Он основан на поисковой системе Lucene и построен на основе RESTful APIS. Он предлагает простое развертывание, максимальную надежность и простое управление. Он также предлагает расширенные запросы для детального анализа и централизованно хранит все данные. Это полезно для быстрого поиска документов.
Elasticsearch также позволяет хранить, искать и анализировать большой объем данных. Он в основном используется в качестве основного движка для поддержки приложений, которые выполнили требования поиска. Он был принят на платформах поисковых систем для современных веб и мобильных приложений. Помимо быстрого поиска, инструмент также предлагает сложную аналитику и множество дополнительных функций.
Особенности эластичного поиска:
- Поисковый сервер с открытым исходным кодом написан с использованием Java
- Используется для индексации любых разнородных данных
- Имеет веб-интерфейс REST API с выводом JSON
- Полнотекстовый поиск
- Поиск в реальном времени (NRT)
- Sharded, реплицируемый с возможностью поиска, хранилище документов JSON
- Распределенное хранилище документов без схем, REST & JSON
- Поддержка нескольких языков и геолокации
Преимущества Elasticsearch
- Хранить данные без схемы, а также создает схему для ваших данных
- Управляйте своей записью данных с помощью многодокументных API
- Выполните фильтрацию и запрос ваших данных для понимания
- Основан на Apache Lucene и предоставляет RESTful API
- Обеспечивает горизонтальную масштабируемость, надежность и возможность работы с несколькими арендаторами для использования индексации в реальном времени, что ускоряет поиск
- Помогает вам масштабировать вертикально и горизонтально
Важные термины, используемые в Elastic Search
| Срок | Применение |
| кластер | Кластер — это совокупность узлов, которые вместе хранят данные и предоставляют объединенные возможности индексации и поиска. |
| Узел | Узел является экземпляром эластичного поиска. Он создается при запуске экземпляра эластичного поиска. |
| Индекс | Индекс представляет собой набор документов, который имеет сходные характеристики. например, данные клиента, каталог продукции. Это очень полезно при выполнении операций индексации, поиска, обновления и удаления. Это позволяет вам определить как можно больше индексов в одном кластере. |
| Документ | Это основная единица информации, которая может быть проиндексирована. Выражается в паре JSON (ключ: значение). ‘{«user»: «nullcon»}’. Каждый отдельный документ связан с типом и уникальным идентификатором. |
| осколок | Каждый индекс можно разбить на несколько сегментов, чтобы можно было распространять данные. Осколок — это атомная часть индекса, которая может быть распределена по кластеру, если вы хотите добавить больше узлов. |
Что такое Logstash?
Logstash is the data collection pipeline tool. It collects data inputs and feeds into the Elasticsearch. It gathers all types of data from the different source and makes it available for further use.
Logstash can unify data from disparate sources and normalize the data into your desired destinations. It allows you to cleanse and democratize all your data for analytics and visualization of use cases.
It consists of three components:
- Input: passing logs to process them into machine understandable
format
- Filters: It is a set of conditions to perform a particular action or event
- Output: Decision maker for processed event or log
Features of Logstash
- Events are passed through each phase using internal queues
- Allows different inputs for your logs
- Filtering/parsing for your logs
Advantage of Logstash
- Offers centralize the data processing
- It analyzes a large variety of structured/unstructured data and events
- Offers plugins to connect with various types of input sources and platforms
What is Kibana?
Kibana is a data visualization which completes the ELK stack. This tool is used for visualizing the Elasticsearch documents and helps developers to have a quick insight into it. Kibana dashboard offers various interactive diagrams, geospatial data, and graphs to visualize complex quires.
It can be used for search, view, and interact with data stored in Elasticsearch directories. Kibana helps you to perform advanced data analysis and visualize your data in a variety of tables, charts, and maps.
In Kibana there are different methods for performing searches on your data.
Here are the most common search types:
| Search Type | Usage |
| Free text searches | It is used for searching a specific string |
| Field-level searches | It is used for searching for a string within a specific field |
| Logical statements | It is used to combine searches into a logical statement. |
| Proximity searches | It is used for searching terms within specific character proximity. |
Features of Kinbana:
- Powerful front-end dashboard which is capable of visualizing indexed information from the elastic cluster
- Enables real-time search of indexed information
- You can search, View, and interact with data stored in Elasticsearch
- Execute queries on data & visualize results in charts, tables, and maps
- Configurable dashboard to slice and dice logstash logs in elasticsearch
- Capable of providing historical data in the form of graphs, charts, etc.
- Real-time dashboards which is easily configurable
- Enables real-time search of indexed information
Advantages and Disadvantages of Kinbana
- Easy visualizing
- Fully integrated with Elasticsearch
- Visualization tool
- Offers real-time analysis, charting, summarization, and debugging capabilities
- Provides instinctive and user-friendly interface
- Allows sharing of snapshots of the logs searched through
- Permits saving the dashboard and managing multiple dashboards
Why Log Analysis?
In cloud-based environment infrastructures, performance, and isolation is very important. The performance of virtual machines in the cloud may vary based on the specific loads, environments, and number of active users in the system. Therefore, reliability and node failure can become a significant issue.
Log management platform can monitor all above-given issues as well as process operating system logs, NGINX, IIS server log for web traffic analysis, application logs, and logs on AWS (Amazon web services).
Управление журналами помогает инженерам DevOps, системному администратору принимать лучшие бизнес-решения. Следовательно, анализ журнала через Elastic Stack или подобные инструменты важен.
ELK vs. Splunk
| лось | Splunk |
| Elk — инструмент с открытым исходным кодом | Splunk — это коммерческий инструмент. |
| Стек лося не предлагает переносимость Solaris из-за Kibana. | Splunk предлагает переносимость Solaris. |
| Скорость обработки строго ограничена. | Предлагает точные и быстрые процессы. |
| ELK — это технологический стек, созданный с помощью комбинации Elastic Search-Logstash-Kibana. | Splunk — это проприетарный инструмент. Он предоставляет как локальные, так и облачные решения. |
| В ELK Поиск, Анализ и Визуализация будут возможны только после настройки стека ELK. | Splunk — это полный пакет управления данными в вашем распоряжении. |
| ELK не поддерживает интеграцию с другими инструментами. | Splunk — это полезный инструмент для настройки интеграции с другими инструментами. |
Тематические исследования
NetFlix
Netflix сильно зависит от стека ELK. Компания использует стек ELK для мониторинга и анализа журнала безопасности операций обслуживания клиентов. Это позволяет им индексировать, хранить и искать документы из более чем пятнадцати кластеров, которые содержат почти 800 узлов.
Известный сайт маркетинга в социальных сетях LinkedIn использует стек ELK для мониторинга производительности и безопасности. ИТ-команда интегрировала ELK с Kafka для поддержки их загрузки в режиме реального времени. Их работа ELK включает в себя более 100 кластеров в шести различных центрах обработки данных.
Tripwire:
Tripwire — это всемирная система управления информационными событиями безопасности. Компания использует ELK для поддержки анализа журналов информационных пакетов.
Средний:
Medium — известная платформа для публикации блогов. Они используют стек ELK для устранения своих производственных проблем. Компания также использует ELK для обнаружения горячих точек DynamoDB. Более того, используя этот стек, компания может поддерживать 25 миллионов уникальных читателей, а также тысячи публикуемых постов каждую неделю.
Преимущества и недостатки стека ELK
преимущества
- ELK лучше всего работает, когда журналы из различных приложений предприятия объединяются в один экземпляр ELK
- Он предоставляет удивительные возможности для этого единственного экземпляра, а также устраняет необходимость входа в сотни различных источников данных журнала.
- Быстрая установка на месте
- Легко развернуть Весы вертикально и горизонтально
- Elastic предлагает множество языковых клиентов, включая Ruby. Python. PHP, Perl, .NET, Java и JavaScript и многое другое
- Наличие библиотек для разных языков программирования и скриптовых языков.
Недостатки
- Различные компоненты в стеке могут стать сложными для обработки при переходе к сложной настройке
- Там нет ничего, как проб и ошибок. Таким образом, чем больше вы делаете, тем больше вы узнаете по пути
Резюме
- Централизованная регистрация может быть полезна при попытке идентифицировать проблемы с серверами или приложениями
- Стек ELK полезен для решения проблем, связанных с централизованной системой регистрации
- ELK stack представляет собой набор из трех инструментов с открытым исходным кодом Elasticsearch, Logstash Kibana
- Elasticsearch является базой данных NoSQL
- Logstash — это инструмент для сбора данных
- Kibana — это визуализация данных, которая дополняет стек ELK
- В инфраструктуре облачной среды производительность и изоляция очень важны
- В стеке ELK скорость обработки строго ограничена, тогда как Splunk предлагает точные и быстрые процессы
- Netflix, LinkedIn, Tripware, Medium — все используют стек ELK для своего бизнеса
- ELK лучше всего работает, когда журналы из различных приложений предприятия объединяются в один экземпляр ELK
- Различные компоненты в стеке могут стать сложными для обработки при переходе к сложной настройке