MapReduce — это инфраструктура, которая используется для написания приложений для надежной обработки огромных объемов данных на больших кластерах аппаратного оборудования. В этой главе рассказывается о работе MapReduce в среде Hadoop с использованием Java.
Алгоритм MapReduce
Обычно парадигма MapReduce основана на отправке программ сокращения карт на компьютеры, где хранятся фактические данные.
-
Во время задания MapReduce Hadoop отправляет задачи Map и Reduce на соответствующие серверы в кластере.
-
Каркас управляет всеми деталями передачи данных, такими как выдача задач, проверка выполнения задач и копирование данных вокруг кластера между узлами.
-
Большая часть вычислений происходит на узлах с данными на локальных дисках, что снижает сетевой трафик.
-
После выполнения заданной задачи кластер собирает и сокращает данные, чтобы сформировать соответствующий результат, и отправляет их обратно на сервер Hadoop.
Во время задания MapReduce Hadoop отправляет задачи Map и Reduce на соответствующие серверы в кластере.
Каркас управляет всеми деталями передачи данных, такими как выдача задач, проверка выполнения задач и копирование данных вокруг кластера между узлами.
Большая часть вычислений происходит на узлах с данными на локальных дисках, что снижает сетевой трафик.
После выполнения заданной задачи кластер собирает и сокращает данные, чтобы сформировать соответствующий результат, и отправляет их обратно на сервер Hadoop.
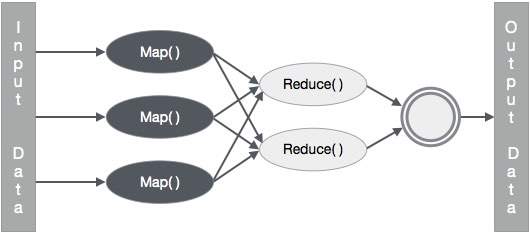
Входы и выходы (перспектива Java)
Каркас MapReduce работает с парами ключ-значение, то есть каркас рассматривает входные данные для задания в виде набора пар ключ-значение и создает набор пар ключ-значение в качестве выходных данных задания, предположительно различных типов.
Классы ключа и значения должны быть сериализуемы платформой, и, следовательно, необходимо реализовать интерфейс Writable. Кроме того, ключевые классы должны реализовывать интерфейс WritableComparable для облегчения сортировки в рамках.
Оба формата ввода и вывода задания MapReduce представлены в виде пар ключ-значение —
(Вход) <k1, v1> -> карта -> <k2, v2> -> уменьшить -> <k3, v3> (вывод).
| вход | Выход | |
|---|---|---|
| карта | <k1, v1> | список (<k2, v2>) |
| уменьшить | <k2, список (v2)> | список (<k3, v3>) |
Реализация MapReduce
В следующей таблице приведены данные, касающиеся потребления электроэнергии в организации. Таблица включает ежемесячное потребление электроэнергии и среднегодовое значение за пять лет подряд.
| январь | февраль | март | апрель | май | июнь | июль | август | сентябрь | октябрь | ноябрь | декабрь | в среднем | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1979 | 23 | 23 | 2 | 43 | 24 | 25 | 26 | 26 | 26 | 26 | 25 | 26 | 25 |
| 1980 | 26 | 27 | 28 | 28 | 28 | 30 | 31 | 31 | 31 | 30 | 30 | 30 | 29 |
| 1981 | 31 | 32 | 32 | 32 | 33 | 34 | 35 | 36 | 36 | 34 | 34 | 34 | 34 |
| 1984 | 39 | 38 | 39 | 39 | 39 | 41 | 42 | 43 | 40 | 39 | 38 | 38 | 40 |
| 1985 | 38 | 39 | 39 | 39 | 39 | 41 | 41 | 41 | 00 | 40 | 39 | 39 | 45 |
Нам нужно написать приложения для обработки входных данных в данной таблице, чтобы найти год максимального использования, год минимального использования и так далее. Эта задача проста для программистов с конечным количеством записей, поскольку они просто напишут логику для получения требуемого вывода и передадут данные в написанное приложение.
Давайте теперь поднимем масштаб входных данных. Предположим, мы должны проанализировать потребление электроэнергии всеми крупными отраслями конкретного государства. Когда мы пишем приложения для обработки таких массовых данных,
-
Они займут много времени, чтобы выполнить.
-
При переносе данных из источника на сетевой сервер будет большой сетевой трафик.
Они займут много времени, чтобы выполнить.
При переносе данных из источника на сетевой сервер будет большой сетевой трафик.
Для решения этих проблем у нас есть инфраструктура MapReduce.
Входные данные
Приведенные выше данные сохраняются как sample.txt и передаются в качестве входных данных. Входной файл выглядит так, как показано ниже.
| 1979 | 23 | 23 | 2 | 43 | 24 | 25 | 26 | 26 | 26 | 26 | 25 | 26 | 25 |
| 1980 | 26 | 27 | 28 | 28 | 28 | 30 | 31 | 31 | 31 | 30 | 30 | 30 | 29 |
| 1981 | 31 | 32 | 32 | 32 | 33 | 34 | 35 | 36 | 36 | 34 | 34 | 34 | 34 |
| 1984 | 39 | 38 | 39 | 39 | 39 | 41 | 42 | 43 | 40 | 39 | 38 | 38 | 40 |
| 1985 | 38 | 39 | 39 | 39 | 39 | 41 | 41 | 41 | 00 | 40 | 39 | 39 | 45 |
Пример программы
Следующая программа для примера данных использует каркас MapReduce.
package hadoop; import java.util.*; import java.io.IOException; import java.io.IOException; import org.apache.hadoop.fs.Path; import org.apache.hadoop.conf.*; import org.apache.hadoop.io.*; import org.apache.hadoop.mapred.*; import org.apache.hadoop.util.*; public class ProcessUnits { //Mapper class public static class E_EMapper extends MapReduceBase implements Mapper<LongWritable, /*Input key Type */ Text, /*Input value Type*/ Text, /*Output key Type*/ IntWritable> /*Output value Type*/ { //Map function public void map(LongWritable key, Text value, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException { String line = value.toString(); String lasttoken = null; StringTokenizer s = new StringTokenizer(line,"\t"); String year = s.nextToken(); while(s.hasMoreTokens()){ lasttoken=s.nextToken(); } int avgprice = Integer.parseInt(lasttoken); output.collect(new Text(year), new IntWritable(avgprice)); } } //Reducer class public static class E_EReduce extends MapReduceBase implements Reducer< Text, IntWritable, Text, IntWritable > { //Reduce function public void reduce(Text key, Iterator <IntWritable> values, OutputCollector>Text, IntWritable> output, Reporter reporter) throws IOException { int maxavg=30; int val=Integer.MIN_VALUE; while (values.hasNext()) { if((val=values.next().get())>maxavg) { output.collect(key, new IntWritable(val)); } } } } //Main function public static void main(String args[])throws Exception { JobConf conf = new JobConf(Eleunits.class); conf.setJobName("max_eletricityunits"); conf.setOutputKeyClass(Text.class); conf.setOutputValueClass(IntWritable.class); conf.setMapperClass(E_EMapper.class); conf.setCombinerClass(E_EReduce.class); conf.setReducerClass(E_EReduce.class); conf.setInputFormat(TextInputFormat.class); conf.setOutputFormat(TextOutputFormat.class); FileInputFormat.setInputPaths(conf, new Path(args[0])); FileOutputFormat.setOutputPath(conf, new Path(args[1])); JobClient.runJob(conf); } }
Сохраните вышеуказанную программу в ProcessUnits.java . Компиляция и выполнение программы приведены ниже.
Компиляция и выполнение программы ProcessUnits
Предположим, мы находимся в домашнем каталоге пользователя Hadoop (например, / home / hadoop).
Следуйте инструкциям ниже, чтобы скомпилировать и выполнить вышеуказанную программу.
Шаг 1 — Используйте следующую команду, чтобы создать каталог для хранения скомпилированных классов Java.
$ mkdir units
Шаг 2 — Загрузите Hadoop-core-1.2.1.jar, который используется для компиляции и выполнения программы MapReduce. Загрузите банку с mvnrepository.com . Предположим, что папка для загрузки — / home / hadoop /.
Шаг 3 — Следующие команды используются для компиляции программы ProcessUnits.java и для создания jar для программы.
$ javac -classpath hadoop-core-1.2.1.jar -d units ProcessUnits.java $ jar -cvf units.jar -C units/ .
Шаг 4 — Следующая команда используется для создания входного каталога в HDFS.
$HADOOP_HOME/bin/hadoop fs -mkdir input_dir
Шаг 5 — Следующая команда используется для копирования входного файла с именем sample.txt во входной каталог HDFS.
$HADOOP_HOME/bin/hadoop fs -put /home/hadoop/sample.txt input_dir
Шаг 6 — Следующая команда используется для проверки файлов во входном каталоге
$HADOOP_HOME/bin/hadoop fs -ls input_dir/
Шаг 7 — Следующая команда используется для запуска приложения Eleunit_max путем извлечения входных файлов из входного каталога.
$HADOOP_HOME/bin/hadoop jar units.jar hadoop.ProcessUnits input_dir output_dir
Подождите некоторое время, пока файл не запустится. После выполнения выходные данные содержат несколько входных разбиений, задачи Map, задачи Reducer и т. Д.
INFO mapreduce.Job: Job job_1414748220717_0002 completed successfully 14/10/31 06:02:52 INFO mapreduce.Job: Counters: 49 File System Counters FILE: Number of bytes read=61 FILE: Number of bytes written=279400 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=546 HDFS: Number of bytes written=40 HDFS: Number of read operations=9 HDFS: Number of large read operations=0 HDFS: Number of write operations=2 Job Counters Launched map tasks=2 Launched reduce tasks=1 Data-local map tasks=2 Total time spent by all maps in occupied slots (ms)=146137 Total time spent by all reduces in occupied slots (ms)=441 Total time spent by all map tasks (ms)=14613 Total time spent by all reduce tasks (ms)=44120 Total vcore-seconds taken by all map tasks=146137 Total vcore-seconds taken by all reduce tasks=44120 Total megabyte-seconds taken by all map tasks=149644288 Total megabyte-seconds taken by all reduce tasks=45178880 Map-Reduce Framework Map input records=5 Map output records=5 Map output bytes=45 Map output materialized bytes=67 Input split bytes=208 Combine input records=5 Combine output records=5 Reduce input groups=5 Reduce shuffle bytes=6 Reduce input records=5 Reduce output records=5 Spilled Records=10 Shuffled Maps =2 Failed Shuffles=0 Merged Map outputs=2 GC time elapsed (ms)=948 CPU time spent (ms)=5160 Physical memory (bytes) snapshot=47749120 Virtual memory (bytes) snapshot=2899349504 Total committed heap usage (bytes)=277684224 File Output Format Counters Bytes Written=40
Шаг 8 — Следующая команда используется для проверки результирующих файлов в выходной папке.
$HADOOP_HOME/bin/hadoop fs -ls output_dir/
Шаг 9 — Следующая команда используется для просмотра выходных данных в файле Part-00000 . Этот файл создан HDFS.
$HADOOP_HOME/bin/hadoop fs -cat output_dir/part-00000
Ниже приводится вывод, сгенерированный программой MapReduce —
| 1981 | 34 |
| 1984 | 40 |
| 1985 | 45 |
Шаг 10 — Следующая команда используется для копирования выходной папки из HDFS в локальную файловую систему.