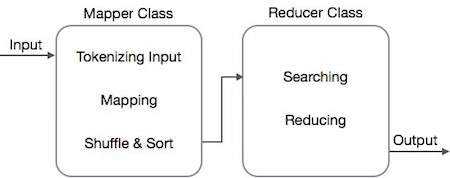
Алгоритм MapReduce содержит две важные задачи, а именно Map и Reduce.
- Задача карты выполняется с помощью Mapper Class
- Задача уменьшения выполняется с помощью класса редуктора.
Класс Mapper принимает входные данные, маркирует их, отображает и сортирует их. Выходные данные класса Mapper используются в качестве входных данных классом Reducer, который, в свою очередь, ищет совпадающие пары и сокращает их.
MapReduce реализует различные математические алгоритмы, чтобы разделить задачу на маленькие части и назначить их нескольким системам. С технической точки зрения алгоритм MapReduce помогает отправлять задачи Map & Reduce на соответствующие серверы в кластере.
Эти математические алгоритмы могут включать в себя следующее:
- Сортировка
- поиск
- индексирование
- TF-IDF
Сортировка
Сортировка является одним из основных алгоритмов MapReduce для обработки и анализа данных. MapReduce реализует алгоритм сортировки для автоматической сортировки выходных пар ключ-значение из преобразователя по их ключам.
-
Методы сортировки реализованы в самом классе mapper.
-
На этапе перемешивания и сортировки после токенизации значений в классе сопоставления класс Context (определенный пользователем класс) собирает совпадающие значения ключей в виде коллекции.
-
Чтобы собрать похожие пары ключ-значение (промежуточные ключи), класс Mapper использует класс RawComparator для сортировки пар ключ-значение.
-
Набор промежуточных пар ключ-значение для данного редуктора автоматически сортируется Hadoop для формирования значений ключа (K2, {V2, V2,…}) до их представления редуктору.
Методы сортировки реализованы в самом классе mapper.
На этапе перемешивания и сортировки после токенизации значений в классе сопоставления класс Context (определенный пользователем класс) собирает совпадающие значения ключей в виде коллекции.
Чтобы собрать похожие пары ключ-значение (промежуточные ключи), класс Mapper использует класс RawComparator для сортировки пар ключ-значение.
Набор промежуточных пар ключ-значение для данного редуктора автоматически сортируется Hadoop для формирования значений ключа (K2, {V2, V2,…}) до их представления редуктору.
поиск
Поиск играет важную роль в алгоритме MapReduce. Это помогает в фазе объединителя (опция) и в фазе редуктора. Давайте попробуем понять, как поиск работает на примере.
пример
В следующем примере показано, как MapReduce использует алгоритм поиска, чтобы узнать подробности о сотруднике, который получает самую высокую зарплату в данном наборе данных сотрудников.
-
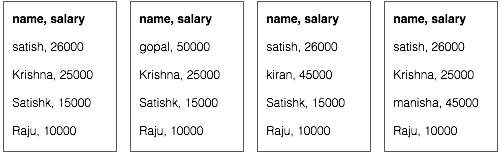
Предположим, у нас есть данные о сотрудниках в четырех разных файлах — A, B, C и D. Предположим также, что во всех четырех файлах есть дубликаты записей о сотрудниках из-за повторного импорта данных о сотрудниках из всех таблиц базы данных. Смотрите следующую иллюстрацию.
Предположим, у нас есть данные о сотрудниках в четырех разных файлах — A, B, C и D. Предположим также, что во всех четырех файлах есть дубликаты записей о сотрудниках из-за повторного импорта данных о сотрудниках из всех таблиц базы данных. Смотрите следующую иллюстрацию.
-
Фаза Map обрабатывает каждый входной файл и предоставляет данные о сотруднике в парах ключ-значение (<k, v>: <emp name, salary>). Смотрите следующую иллюстрацию.
Фаза Map обрабатывает каждый входной файл и предоставляет данные о сотруднике в парах ключ-значение (<k, v>: <emp name, salary>). Смотрите следующую иллюстрацию.

-
Фаза объединителя (метод поиска) будет принимать входные данные из фазы карты в виде пары ключ-значение с именем сотрудника и зарплатой. Используя технику поиска, комбинатор проверит всю зарплату сотрудника, чтобы найти сотрудника с наибольшим окладом в каждом файле. Смотрите следующий фрагмент.
Фаза объединителя (метод поиска) будет принимать входные данные из фазы карты в виде пары ключ-значение с именем сотрудника и зарплатой. Используя технику поиска, комбинатор проверит всю зарплату сотрудника, чтобы найти сотрудника с наибольшим окладом в каждом файле. Смотрите следующий фрагмент.
<k: employee name, v: salary> Max= the salary of an first employee. Treated as max salary if(v(second employee).salary > Max){ Max = v(salary); } else{ Continue checking; }
Ожидаемый результат заключается в следующем —
|
<сатиш, 26000>
<гопал, 50000>
<Киран, 45000>
<Маниша, 45000>
-
Этап сокращения — Сформируйте каждый файл, вы найдете самый высокооплачиваемый сотрудник. Чтобы избежать избыточности, проверьте все пары <k, v> и удалите дублирующиеся записи, если таковые имеются. Тот же алгоритм используется между четырьмя парами <k, v>, которые поступают из четырех входных файлов. Окончательный результат должен быть следующим:
Этап сокращения — Сформируйте каждый файл, вы найдете самый высокооплачиваемый сотрудник. Чтобы избежать избыточности, проверьте все пары <k, v> и удалите дублирующиеся записи, если таковые имеются. Тот же алгоритм используется между четырьмя парами <k, v>, которые поступают из четырех входных файлов. Окончательный результат должен быть следующим:
<gopal, 50000>
индексирование
Обычно индексация используется для указания на конкретные данные и их адрес. Он выполняет пакетную индексацию входных файлов для определенного Mapper.
Техника индексирования, которая обычно используется в MapReduce, называется инвертированным индексом. Поисковые системы, такие как Google и Bing, используют метод перевернутой индексации. Давайте попробуем понять, как работает индексирование, на простом примере.
пример
Следующий текст является вводом для инвертированной индексации. Здесь T [0], T [1] и t [2] — имена файлов, а их содержимое заключено в двойные кавычки.
T[0] = "it is what it is" T[1] = "what is it" T[2] = "it is a banana"
После применения алгоритма индексирования мы получаем следующий вывод:
"a": {2}
"banana": {2}
"is": {0, 1, 2}
"it": {0, 1, 2}
"what": {0, 1}
Здесь «a»: {2} подразумевает, что термин «a» появляется в файле T [2]. Аналогично, «is»: {0, 1, 2} подразумевает, что термин «is» появляется в файлах T [0], T [1] и T [2].
TF-IDF
TF-IDF — это алгоритм обработки текста, сокращенный от Term Frequency — Inverse Document Frequency. Это один из распространенных алгоритмов веб-анализа. Здесь термин «частота» относится к числу раз, когда термин появляется в документе.
Термин частота (TF)
Он измеряет, как часто конкретный термин встречается в документе. Он рассчитывается по количеству появлений слова в документе, деленному на общее количество слов в этом документе.
TF(the) = (Number of times term the ‘the’ appears in a document) / (Total number of terms in the document)
Частота обратных документов (IDF)
Он измеряет важность термина. Он рассчитывается по количеству документов в текстовой базе данных, деленному на количество документов, в которых появляется конкретный термин.
При вычислении TF все термины считаются одинаково важными. Это означает, что TF подсчитывает частоту термина для обычных слов, таких как «есть», «а», «что» и т. Д. Таким образом, нам нужно знать частые термины при увеличении количества редких, вычисляя следующее:
IDF(the) = log_e(Total number of documents / Number of documents with term ‘the’ in it).
Алгоритм объяснен ниже с помощью небольшого примера.
пример
Рассмотрим документ, содержащий 1000 слов, в котором слово улей появляется 50 раз. Тогда TF для улья (50/1000) = 0,05.
Теперь предположим, что у нас есть 10 миллионов документов и слово « куст» появляется в 1000 из них. Затем IDF рассчитывается как log (10 000 000/1000) = 4.
Вес TF-IDF является произведением этих количеств — 0,05 × 4 = 0,20.