Combiner, также известный как полуредуктор, является необязательным классом, который работает, принимая входные данные из класса Map и затем передавая выходные пары ключ-значение в класс Reducer.
Основная функция Combiner состоит в том, чтобы суммировать выходные записи карты с одним и тем же ключом. Выход (сбор значения ключа) объединителя будет отправлен по сети фактической задаче «Редуктор» в качестве входных данных.
Сумматор
Класс Combiner используется между классом Map и классом Reduce для уменьшения объема передачи данных между Map и Reduce. Обычно выходные данные задачи карты большие, а данные, передаваемые в задачу сокращения, большие.
На следующей диаграмме задачи MapReduce показана ФАЗА КОМБИНИРОВАНИЯ.
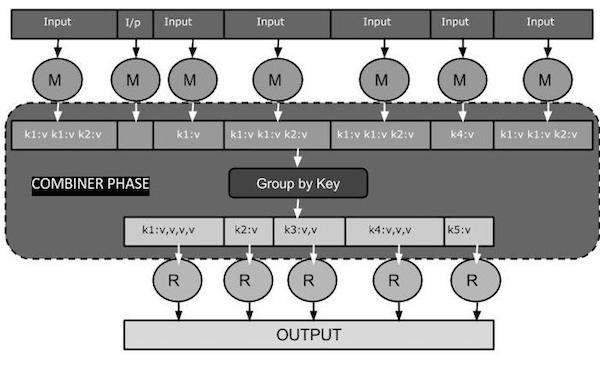
Как работает Combiner?
Вот краткое описание того, как работает MapReduce Combiner:
-
У объединителя нет предопределенного интерфейса, и он должен реализовывать метод Redu () интерфейса Reducer.
-
Комбайнер работает с каждым ключом вывода карты. Он должен иметь те же типы значений выходного ключа, что и класс Reducer.
-
Объединитель может создавать сводную информацию из большого набора данных, поскольку он заменяет исходный вывод карты.
У объединителя нет предопределенного интерфейса, и он должен реализовывать метод Redu () интерфейса Reducer.
Комбайнер работает с каждым ключом вывода карты. Он должен иметь те же типы значений выходного ключа, что и класс Reducer.
Объединитель может создавать сводную информацию из большого набора данных, поскольку он заменяет исходный вывод карты.
Хотя Combiner не является обязательным, он помогает разделить данные на несколько групп для фазы сокращения, что упрощает обработку.
Реализация MapReduce Combiner
Следующий пример дает теоретическое представление о комбайнерах. Предположим, у нас есть следующий входной текстовый файл с именем input.txt для MapReduce.
What do you mean by Object What do you know about Java What is Java Virtual Machine How Java enabled High Performance
Важные этапы программы MapReduce с Combiner обсуждаются ниже.
Record Reader
Это первая фаза MapReduce, где Record Reader считывает каждую строку из входного текстового файла в виде текста и выдает выходные данные в виде пар ключ-значение.
Ввод — построчно текст из входного файла.
Выход — формирует пары ключ-значение. Ниже приведен набор ожидаемых пар ключ-значение.
<1, What do you mean by Object> <2, What do you know about Java> <3, What is Java Virtual Machine> <4, How Java enabled High Performance>
Фаза карты
Фаза Map принимает входные данные из Record Reader, обрабатывает их и создает выходные данные в виде другого набора пар ключ-значение.
Вход — следующая пара ключ-значение — это вход, полученный от устройства чтения записей.
<1, What do you mean by Object> <2, What do you know about Java> <3, What is Java Virtual Machine> <4, How Java enabled High Performance>
Фаза Map считывает каждую пару ключ-значение, делит каждое слово на значение, используя StringTokenizer, обрабатывает каждое слово как ключ, а счетчик этого слова — как значение. В следующем фрагменте кода показаны класс Mapper и функция map.
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> { private final static IntWritable one = new IntWritable(1); private Text word = new Text(); public void map(Object key, Text value, Context context) throws IOException, InterruptedException { StringTokenizer itr = new StringTokenizer(value.toString()); while (itr.hasMoreTokens()) { word.set(itr.nextToken()); context.write(word, one); } } }
Вывод — ожидаемый вывод выглядит следующим образом —
<What,1> <do,1> <you,1> <mean,1> <by,1> <Object,1> <What,1> <do,1> <you,1> <know,1> <about,1> <Java,1> <What,1> <is,1> <Java,1> <Virtual,1> <Machine,1> <How,1> <Java,1> <enabled,1> <High,1> <Performance,1>
Фаза Combiner
Фаза Combiner берет каждую пару ключ-значение из фазы Map, обрабатывает ее и создает выходные данные в виде пар набора ключ-значение .
Ввод — следующая пара ключ-значение является вводом, взятым из фазы карты.
<What,1> <do,1> <you,1> <mean,1> <by,1> <Object,1> <What,1> <do,1> <you,1> <know,1> <about,1> <Java,1> <What,1> <is,1> <Java,1> <Virtual,1> <Machine,1> <How,1> <Java,1> <enabled,1> <High,1> <Performance,1>
Фаза Combiner считывает каждую пару ключ-значение, объединяет общие слова как ключ и значения как коллекцию. Как правило, код и работа для Combiner аналогичны таковым для Reducer. Ниже приведен фрагмент кода для объявления классов Mapper, Combiner и Reducer.
job.setMapperClass(TokenizerMapper.class); job.setCombinerClass(IntSumReducer.class); job.setReducerClass(IntSumReducer.class);
Вывод — ожидаемый вывод выглядит следующим образом —
<What,1,1,1> <do,1,1> <you,1,1> <mean,1> <by,1> <Object,1> <know,1> <about,1> <Java,1,1,1> <is,1> <Virtual,1> <Machine,1> <How,1> <enabled,1> <High,1> <Performance,1>
Фаза редуктора
Фаза редуктора берет каждую пару сбора ключ-значение из фазы Combiner, обрабатывает ее и передает выходные данные в виде пар ключ-значение. Обратите внимание, что функциональность Combiner такая же, как и у Reducer.
Вход — следующая пара ключ-значение является входом, взятым из фазы Combiner.
<What,1,1,1> <do,1,1> <you,1,1> <mean,1> <by,1> <Object,1> <know,1> <about,1> <Java,1,1,1> <is,1> <Virtual,1> <Machine,1> <How,1> <enabled,1> <High,1> <Performance,1>
Фаза редуктора считывает каждую пару ключ-значение. Ниже приведен фрагмент кода для Combiner.
public static class IntSumReducer extends Reducer<Text,IntWritable,Text,IntWritable> { private IntWritable result = new IntWritable(); public void reduce(Text key, Iterable<IntWritable> values,Context context) throws IOException, InterruptedException { int sum = 0; for (IntWritable val : values) { sum += val.get(); } result.set(sum); context.write(key, result); } }
Выходные данные — ожидаемый выходной сигнал от фазы редуктора следующий —
<What,3> <do,2> <you,2> <mean,1> <by,1> <Object,1> <know,1> <about,1> <Java,3> <is,1> <Virtual,1> <Machine,1> <How,1> <enabled,1> <High,1> <Performance,1>
Record Writer
Это последняя фаза MapReduce, где Record Writer записывает каждую пару ключ-значение из фазы Reducer и отправляет вывод в виде текста.
Ввод — каждая пара ключ-значение из фазы редуктора вместе с форматом вывода.
Вывод — он дает вам пары ключ-значение в текстовом формате. Ниже приводится ожидаемый результат.
What 3 do 2 you 2 mean 1 by 1 Object 1 know 1 about 1 Java 3 is 1 Virtual 1 Machine 1 How 1 enabled 1 High 1 Performance 1
Пример программы
Следующий блок кода подсчитывает количество слов в программе.
import java.io.IOException; import java.util.StringTokenizer; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class WordCount { public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> { private final static IntWritable one = new IntWritable(1); private Text word = new Text(); public void map(Object key, Text value, Context context) throws IOException, InterruptedException { StringTokenizer itr = new StringTokenizer(value.toString()); while (itr.hasMoreTokens()) { word.set(itr.nextToken()); context.write(word, one); } } } public static class IntSumReducer extends Reducer<Text,IntWritable,Text,IntWritable> { private IntWritable result = new IntWritable(); public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int sum = 0; for (IntWritable val : values) { sum += val.get(); } result.set(sum); context.write(key, result); } } public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); Job job = Job.getInstance(conf, "word count"); job.setJarByClass(WordCount.class); job.setMapperClass(TokenizerMapper.class); job.setCombinerClass(IntSumReducer.class); job.setReducerClass(IntSumReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); System.exit(job.waitForCompletion(true) ? 0 : 1); } }
Сохраните вышеуказанную программу как WordCount.java . Компиляция и выполнение программы приведены ниже.
Компиляция и выполнение
Предположим, мы находимся в домашнем каталоге пользователя Hadoop (например, / home / hadoop).
Следуйте инструкциям ниже, чтобы скомпилировать и выполнить вышеуказанную программу.
Шаг 1 — Используйте следующую команду, чтобы создать каталог для хранения скомпилированных классов Java.
$ mkdir units
Шаг 2 — Загрузите Hadoop-core-1.2.1.jar, который используется для компиляции и выполнения программы MapReduce. Вы можете скачать банку с mvnrepository.com .
Давайте предположим, что загруженная папка — / home / hadoop /.
Шаг 3 — Используйте следующие команды для компиляции программы WordCount.java и для создания jar для программы.
$ javac -classpath hadoop-core-1.2.1.jar -d units WordCount.java $ jar -cvf units.jar -C units/ .
Шаг 4 — Используйте следующую команду для создания входного каталога в HDFS.
$HADOOP_HOME/bin/hadoop fs -mkdir input_dir
Шаг 5 — Используйте следующую команду, чтобы скопировать входной файл с именем input.txt во входной каталог HDFS.
$HADOOP_HOME/bin/hadoop fs -put /home/hadoop/input.txt input_dir
Шаг 6 — Используйте следующую команду, чтобы проверить файлы во входном каталоге.
$HADOOP_HOME/bin/hadoop fs -ls input_dir/
Шаг 7 — Используйте следующую команду, чтобы запустить приложение Word count, взяв входные файлы из входного каталога.
$HADOOP_HOME/bin/hadoop jar units.jar hadoop.ProcessUnits input_dir output_dir
Подождите некоторое время, пока файл не запустится. После выполнения выходные данные содержат несколько входных разбиений, задачи Map и задачи Reducer.
Шаг 8 — Используйте следующую команду для проверки результирующих файлов в выходной папке.
$HADOOP_HOME/bin/hadoop fs -ls output_dir/
Шаг 9 — Используйте следующую команду, чтобы увидеть выходные данные в файле Part-00000 . Этот файл создан HDFS.
$HADOOP_HOME/bin/hadoop fs -cat output_dir/part-00000
Ниже приводится вывод, сгенерированный программой MapReduce.