MapReduce — Введение
MapReduce — это модель программирования для написания приложений, которые могут обрабатывать большие данные параллельно на нескольких узлах. MapReduce предоставляет аналитические возможности для анализа огромных объемов сложных данных.
Что такое большие данные?
Большие данные — это набор больших наборов данных, которые не могут быть обработаны с использованием традиционных вычислительных технологий. Например, объем данных, которые Facebook или Youtube должны требовать для ежедневного сбора и обработки, может подпадать под категорию больших данных. Однако большие данные касаются не только масштаба и объема, но и одного или нескольких из следующих аспектов — скорость, разнообразие, объем и сложность.
Почему MapReduce?
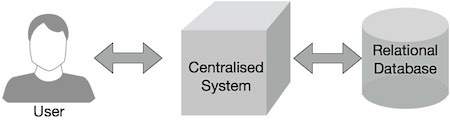
Традиционные корпоративные системы обычно имеют централизованный сервер для хранения и обработки данных. Следующая иллюстрация изображает схематическое представление традиционной системы предприятия. Традиционная модель, безусловно, не подходит для обработки огромных объемов масштабируемых данных и не может быть размещена на стандартных серверах баз данных. Более того, централизованная система создает слишком много узких мест при одновременной обработке нескольких файлов.
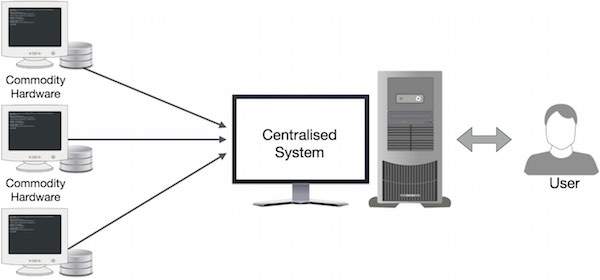
Google решил эту проблему, используя алгоритм MapReduce. MapReduce делит задачу на маленькие части и назначает их многим компьютерам. Позже результаты собираются в одном месте и объединяются для формирования результирующего набора данных.
Как работает MapReduce?
Алгоритм MapReduce содержит две важные задачи, а именно Map и Reduce.
-
Задача «Карта» берет набор данных и преобразует его в другой набор данных, где отдельные элементы разбиваются на кортежи (пары ключ-значение).
-
Задача Reduce принимает выходные данные из карты в качестве входных данных и объединяет эти кортежи данных (пары ключ-значение) в меньший набор кортежей.
Задача «Карта» берет набор данных и преобразует его в другой набор данных, где отдельные элементы разбиваются на кортежи (пары ключ-значение).
Задача Reduce принимает выходные данные из карты в качестве входных данных и объединяет эти кортежи данных (пары ключ-значение) в меньший набор кортежей.
Задача уменьшения всегда выполняется после задания карты.
Давайте теперь внимательно рассмотрим каждый из этапов и попытаемся понять их значение.
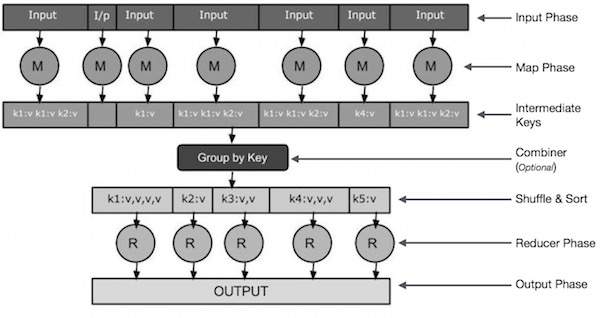
-
Фаза ввода — Здесь у нас есть Record Reader, который переводит каждую запись во входной файл и отправляет проанализированные данные в маппер в виде пар ключ-значение.
-
Карта — Карта — это пользовательская функция, которая принимает серию пар ключ-значение и обрабатывает каждую из них, чтобы сгенерировать ноль или более пар ключ-значение.
-
Промежуточные ключи — пары «ключ-значение», генерируемые картографом, называются промежуточными ключами.
-
Объединитель — объединитель — это тип локального редуктора, который группирует аналогичные данные из фазы карты в идентифицируемые наборы. Он принимает промежуточные ключи от преобразователя в качестве входных данных и применяет пользовательский код для агрегирования значений в небольшой области одного преобразователя. Он не является частью основного алгоритма MapReduce; это необязательно.
-
Перемешать и отсортировать — задача «Восстановитель» начинается с шага «Перемешать и сортировать». Он загружает сгруппированные пары ключ-значение на локальный компьютер, на котором работает редуктор. Отдельные пары ключ-значение сортируются по ключу в больший список данных. Список данных группирует эквивалентные ключи вместе, так что их значения могут быть легко повторены в задаче Reducer.
-
Редуктор — Редуктор принимает сгруппированные парные данные ключ-значение в качестве входных данных и запускает функцию Редуктор для каждого из них. Здесь данные могут быть агрегированы, отфильтрованы и объединены различными способами, что требует широкого спектра обработки. Как только выполнение закончено, он дает ноль или более пар ключ-значение для последнего шага.
-
Фаза вывода. На этапе вывода у нас есть выходной форматер, который переводит конечные пары ключ-значение из функции Reducer и записывает их в файл с помощью средства записи.
Фаза ввода — Здесь у нас есть Record Reader, который переводит каждую запись во входной файл и отправляет проанализированные данные в маппер в виде пар ключ-значение.
Карта — Карта — это пользовательская функция, которая принимает серию пар ключ-значение и обрабатывает каждую из них, чтобы сгенерировать ноль или более пар ключ-значение.
Промежуточные ключи — пары «ключ-значение», генерируемые картографом, называются промежуточными ключами.
Объединитель — объединитель — это тип локального редуктора, который группирует аналогичные данные из фазы карты в идентифицируемые наборы. Он принимает промежуточные ключи от преобразователя в качестве входных данных и применяет пользовательский код для агрегирования значений в небольшой области одного преобразователя. Он не является частью основного алгоритма MapReduce; это необязательно.
Перемешать и отсортировать — задача «Восстановитель» начинается с шага «Перемешать и сортировать». Он загружает сгруппированные пары ключ-значение на локальный компьютер, на котором работает редуктор. Отдельные пары ключ-значение сортируются по ключу в больший список данных. Список данных группирует эквивалентные ключи вместе, так что их значения могут быть легко повторены в задаче Reducer.
Редуктор — Редуктор принимает сгруппированные парные данные ключ-значение в качестве входных данных и запускает функцию Редуктор для каждого из них. Здесь данные могут быть агрегированы, отфильтрованы и объединены различными способами, что требует широкого спектра обработки. Как только выполнение закончено, он дает ноль или более пар ключ-значение для последнего шага.
Фаза вывода. На этапе вывода у нас есть выходной форматер, который переводит конечные пары ключ-значение из функции Reducer и записывает их в файл с помощью средства записи.
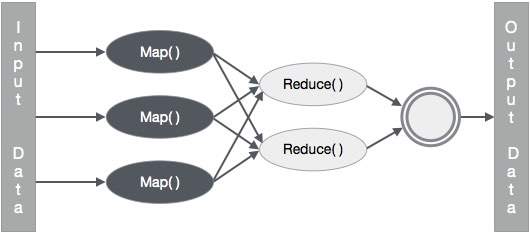
Давайте попробуем понять две задачи Map & f Reduce с помощью небольшой диаграммы —
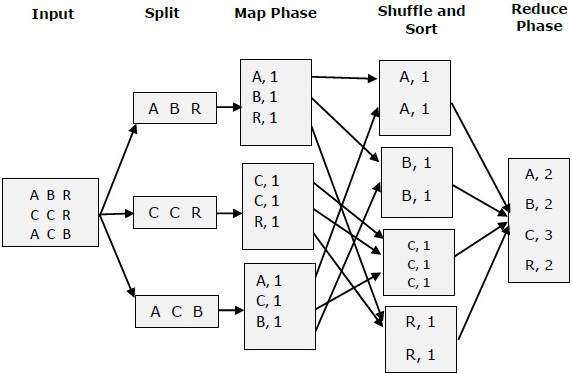
MapReduce-пример
Давайте возьмем пример из реальной жизни, чтобы понять мощь MapReduce. Twitter получает около 500 миллионов твитов в день, то есть почти 3000 твитов в секунду. На следующем рисунке показано, как Tweeter управляет своими твитами с помощью MapReduce.
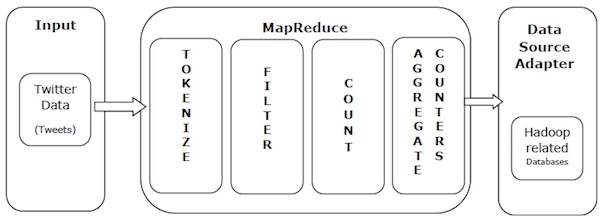
Как показано на рисунке, алгоритм MapReduce выполняет следующие действия:
-
Tokenize — токенизирует твиты в карты токенов и записывает их в виде пар ключ-значение.
-
Фильтр — Фильтрует нежелательные слова из карт токенов и записывает отфильтрованные карты в виде пар ключ-значение.
-
Count — генерирует счетчик токенов на слово.
-
Сводные счетчики — готовит совокупность аналогичных значений счетчиков в небольшие управляемые единицы.
Tokenize — токенизирует твиты в карты токенов и записывает их в виде пар ключ-значение.
Фильтр — Фильтрует нежелательные слова из карт токенов и записывает отфильтрованные карты в виде пар ключ-значение.
Count — генерирует счетчик токенов на слово.
Сводные счетчики — готовит совокупность аналогичных значений счетчиков в небольшие управляемые единицы.
MapReduce — Алгоритм
Алгоритм MapReduce содержит две важные задачи, а именно Map и Reduce.
- Задача карты выполняется с помощью Mapper Class
- Задача уменьшения выполняется с помощью класса редуктора.
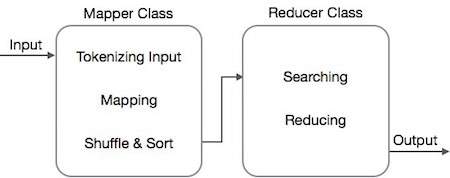
Класс Mapper принимает входные данные, маркирует их, отображает и сортирует их. Выходные данные класса Mapper используются в качестве входных данных классом Reducer, который, в свою очередь, ищет совпадающие пары и сокращает их.
MapReduce реализует различные математические алгоритмы, чтобы разделить задачу на маленькие части и назначить их нескольким системам. С технической точки зрения алгоритм MapReduce помогает отправлять задачи Map & Reduce на соответствующие серверы в кластере.
Эти математические алгоритмы могут включать в себя следующее:
- Сортировка
- поиск
- индексирование
- TF-IDF
Сортировка
Сортировка является одним из основных алгоритмов MapReduce для обработки и анализа данных. MapReduce реализует алгоритм сортировки для автоматической сортировки выходных пар ключ-значение из преобразователя по их ключам.
-
Методы сортировки реализованы в самом классе mapper.
-
На этапе перемешивания и сортировки после токенизации значений в классе сопоставления класс Context (определенный пользователем класс) собирает совпадающие значения ключей в виде коллекции.
-
Чтобы собрать похожие пары ключ-значение (промежуточные ключи), класс Mapper использует класс RawComparator для сортировки пар ключ-значение.
-
Набор промежуточных пар ключ-значение для данного редуктора автоматически сортируется Hadoop для формирования значений ключа (K2, {V2, V2,…}) до их представления редуктору.
Методы сортировки реализованы в самом классе mapper.
На этапе перемешивания и сортировки после токенизации значений в классе сопоставления класс Context (определенный пользователем класс) собирает совпадающие значения ключей в виде коллекции.
Чтобы собрать похожие пары ключ-значение (промежуточные ключи), класс Mapper использует класс RawComparator для сортировки пар ключ-значение.
Набор промежуточных пар ключ-значение для данного редуктора автоматически сортируется Hadoop для формирования значений ключа (K2, {V2, V2,…}) до их представления редуктору.
поиск
Поиск играет важную роль в алгоритме MapReduce. Это помогает в фазе объединителя (опция) и в фазе редуктора. Давайте попробуем понять, как поиск работает на примере.
пример
В следующем примере показано, как MapReduce использует алгоритм поиска, чтобы узнать подробности о сотруднике, который получает самую высокую зарплату в данном наборе данных сотрудников.
-
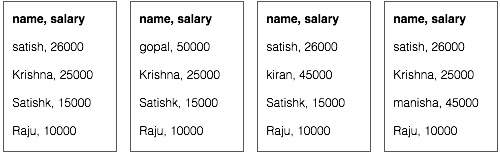
Предположим, у нас есть данные о сотрудниках в четырех разных файлах — A, B, C и D. Предположим также, что во всех четырех файлах есть дубликаты записей о сотрудниках из-за повторного импорта данных о сотрудниках из всех таблиц базы данных. Смотрите следующую иллюстрацию.
Предположим, у нас есть данные о сотрудниках в четырех разных файлах — A, B, C и D. Предположим также, что во всех четырех файлах есть дубликаты записей о сотрудниках из-за повторного импорта данных о сотрудниках из всех таблиц базы данных. Смотрите следующую иллюстрацию.
-
Фаза Map обрабатывает каждый входной файл и предоставляет данные о сотруднике в парах ключ-значение (<k, v>: <emp name, salary>). Смотрите следующую иллюстрацию.
Фаза Map обрабатывает каждый входной файл и предоставляет данные о сотруднике в парах ключ-значение (<k, v>: <emp name, salary>). Смотрите следующую иллюстрацию.

-
Фаза объединителя (метод поиска) будет принимать входные данные из фазы карты в виде пары ключ-значение с именем сотрудника и зарплатой. Используя технику поиска, комбинатор проверит всю зарплату сотрудника, чтобы найти сотрудника с наибольшим окладом в каждом файле. Смотрите следующий фрагмент.
Фаза объединителя (метод поиска) будет принимать входные данные из фазы карты в виде пары ключ-значение с именем сотрудника и зарплатой. Используя технику поиска, комбинатор проверит всю зарплату сотрудника, чтобы найти сотрудника с наибольшим окладом в каждом файле. Смотрите следующий фрагмент.
<k: employee name, v: salary> Max= the salary of an first employee. Treated as max salary if(v(second employee).salary > Max){ Max = v(salary); } else{ Continue checking; }
Ожидаемый результат заключается в следующем —
|
<сатиш, 26000>
<гопал, 50000>
<Киран, 45000>
<Маниша, 45000>
-
Этап сокращения — Сформируйте каждый файл, вы найдете самый высокооплачиваемый сотрудник. Чтобы избежать избыточности, проверьте все пары <k, v> и удалите дублирующиеся записи, если таковые имеются. Тот же алгоритм используется между четырьмя парами <k, v>, которые поступают из четырех входных файлов. Окончательный результат должен быть следующим:
Этап сокращения — Сформируйте каждый файл, вы найдете самый высокооплачиваемый сотрудник. Чтобы избежать избыточности, проверьте все пары <k, v> и удалите дублирующиеся записи, если таковые имеются. Тот же алгоритм используется между четырьмя парами <k, v>, которые поступают из четырех входных файлов. Окончательный результат должен быть следующим:
<gopal, 50000>
индексирование
Обычно индексация используется для указания на конкретные данные и их адрес. Он выполняет пакетную индексацию входных файлов для определенного Mapper.
Техника индексирования, которая обычно используется в MapReduce, называется инвертированным индексом. Поисковые системы, такие как Google и Bing, используют метод перевернутой индексации. Давайте попробуем понять, как работает индексирование, на простом примере.
пример
Следующий текст является вводом для инвертированной индексации. Здесь T [0], T [1] и t [2] — имена файлов, а их содержимое заключено в двойные кавычки.
T[0] = "it is what it is" T[1] = "what is it" T[2] = "it is a banana"
После применения алгоритма индексирования мы получаем следующий вывод:
"a": {2}
"banana": {2}
"is": {0, 1, 2}
"it": {0, 1, 2}
"what": {0, 1}
Здесь «a»: {2} подразумевает, что термин «a» появляется в файле T [2]. Аналогично, «is»: {0, 1, 2} подразумевает, что термин «is» появляется в файлах T [0], T [1] и T [2].
TF-IDF
TF-IDF — это алгоритм обработки текста, сокращенный от Term Frequency — Inverse Document Frequency. Это один из распространенных алгоритмов веб-анализа. Здесь термин «частота» относится к числу раз, когда термин появляется в документе.
Термин частота (TF)
Он измеряет, как часто конкретный термин встречается в документе. Он рассчитывается по количеству появлений слова в документе, деленному на общее количество слов в этом документе.
TF(the) = (Number of times term the ‘the’ appears in a document) / (Total number of terms in the document)
Частота обратных документов (IDF)
Он измеряет важность термина. Он рассчитывается по количеству документов в текстовой базе данных, деленному на количество документов, в которых появляется конкретный термин.
При вычислении TF все термины считаются одинаково важными. Это означает, что TF подсчитывает частоту термина для обычных слов, таких как «есть», «а», «что» и т. Д. Таким образом, нам нужно знать частые термины при увеличении количества редких, вычисляя следующее:
IDF(the) = log_e(Total number of documents / Number of documents with term ‘the’ in it).
Алгоритм объяснен ниже с помощью небольшого примера.
пример
Рассмотрим документ, содержащий 1000 слов, в котором слово улей появляется 50 раз. Тогда TF для улья (50/1000) = 0,05.
Теперь предположим, что у нас есть 10 миллионов документов и слово « куст» появляется в 1000 из них. Затем IDF рассчитывается как log (10 000 000/1000) = 4.
Вес TF-IDF является произведением этих количеств — 0,05 × 4 = 0,20.
MapReduce — Установка
MapReduce работает только в операционных системах со вкусом Linux и поставляется с Hadoop Framework. Нам нужно выполнить следующие шаги для установки фреймворка Hadoop.
Проверка установки JAVA
Java должна быть установлена в вашей системе перед установкой Hadoop. Используйте следующую команду, чтобы проверить, установлена ли у вас Java в вашей системе.
$ java –version
Если Java уже установлена в вашей системе, вы увидите следующий ответ:
java version "1.7.0_71" Java(TM) SE Runtime Environment (build 1.7.0_71-b13) Java HotSpot(TM) Client VM (build 25.0-b02, mixed mode)
Если в вашей системе не установлена Java, выполните следующие действия.
Установка Java
Шаг 1
Скачать последнюю версию Java можно по следующей ссылке — этой ссылке .
После загрузки вы можете найти файл jdk-7u71-linux-x64.tar.gz в папке «Загрузки».
Шаг 2
Используйте следующие команды для извлечения содержимого jdk-7u71-linux-x64.gz.
$ cd Downloads/ $ ls jdk-7u71-linux-x64.gz $ tar zxf jdk-7u71-linux-x64.gz $ ls jdk1.7.0_71 jdk-7u71-linux-x64.gz
Шаг 3
Чтобы сделать Java доступным для всех пользователей, вы должны переместить его в папку «/ usr / local /». Зайдите в root и введите следующие команды —
$ su password: # mv jdk1.7.0_71 /usr/local/java # exit
Шаг 4
Для настройки переменных PATH и JAVA_HOME добавьте следующие команды в файл ~ / .bashrc.
export JAVA_HOME=/usr/local/java export PATH=$PATH:$JAVA_HOME/bin
Примените все изменения к текущей работающей системе.
$ source ~/.bashrc
Шаг 5
Используйте следующие команды для настройки альтернатив Java —
# alternatives --install /usr/bin/java java usr/local/java/bin/java 2 # alternatives --install /usr/bin/javac javac usr/local/java/bin/javac 2 # alternatives --install /usr/bin/jar jar usr/local/java/bin/jar 2 # alternatives --set java usr/local/java/bin/java # alternatives --set javac usr/local/java/bin/javac # alternatives --set jar usr/local/java/bin/jar
Теперь проверьте установку с помощью команды java -version из терминала.
Проверка правильности установки Hadoop
Hadoop должен быть установлен в вашей системе перед установкой MapReduce. Давайте проверим установку Hadoop с помощью следующей команды —
$ hadoop version
Если Hadoop уже установлен в вашей системе, вы получите следующий ответ:
Hadoop 2.4.1 -- Subversion https://svn.apache.org/repos/asf/hadoop/common -r 1529768 Compiled by hortonmu on 2013-10-07T06:28Z Compiled with protoc 2.5.0 From source with checksum 79e53ce7994d1628b240f09af91e1af4
Если Hadoop не установлен в вашей системе, выполните следующие действия.
Загрузка Hadoop
Загрузите Hadoop 2.4.1 с Apache Software Foundation и извлеките его содержимое с помощью следующих команд.
$ su password: # cd /usr/local # wget http://apache.claz.org/hadoop/common/hadoop-2.4.1/ hadoop-2.4.1.tar.gz # tar xzf hadoop-2.4.1.tar.gz # mv hadoop-2.4.1/* to hadoop/ # exit
Установка Hadoop в псевдо-распределенном режиме
Следующие шаги используются для установки Hadoop 2.4.1 в псевдораспределенном режиме.
Шаг 1 — Настройка Hadoop
Вы можете установить переменные среды Hadoop, добавив следующие команды в файл ~ / .bashrc.
export HADOOP_HOME=/usr/local/hadoop export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
Примените все изменения к текущей работающей системе.
$ source ~/.bashrc
Шаг 2 — Настройка Hadoop
Вы можете найти все файлы конфигурации Hadoop в папке «$ HADOOP_HOME / etc / hadoop». Вам необходимо внести соответствующие изменения в эти файлы конфигурации в соответствии с вашей инфраструктурой Hadoop.
$ cd $HADOOP_HOME/etc/hadoop
Для разработки программ Hadoop с использованием Java вам необходимо сбросить переменные среды Java в файле hadoop-env.sh , заменив значение JAVA_HOME местоположением Java в вашей системе.
export JAVA_HOME=/usr/local/java
Вы должны отредактировать следующие файлы для настройки Hadoop —
- ядро-site.xml
- HDFS-site.xml
- Пряжа-site.xml
- mapred-site.xml
ядро-site.xml
core-site.xml содержит следующую информацию:
- Номер порта, используемый для экземпляра Hadoop
- Память, выделенная для файловой системы
- Ограничение памяти для хранения данных
- Размер буферов чтения / записи
Откройте файл core-site.xml и добавьте следующие свойства между тегами <configuration> и </ configuration>.
<configuration> <property> <name>fs.default.name</name> <value>hdfs://localhost:9000 </value> </property> </configuration>
HDFS-site.xml
hdfs-site.xml содержит следующую информацию —
- Значение данных репликации
- Наменодская дорожка
- Путь к датоде ваших локальных файловых систем (место, где вы хотите хранить инфраструктуру Hadoop)
Допустим, следующие данные.
dfs.replication (data replication value) = 1 (In the following path /hadoop/ is the user name. hadoopinfra/hdfs/namenode is the directory created by hdfs file system.) namenode path = //home/hadoop/hadoopinfra/hdfs/namenode (hadoopinfra/hdfs/datanode is the directory created by hdfs file system.) datanode path = //home/hadoop/hadoopinfra/hdfs/datanode
Откройте этот файл и добавьте следующие свойства между тегами <configuration>, </ configuration>.
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.name.dir</name> <value>file:///home/hadoop/hadoopinfra/hdfs/namenode</value> </property> <property> <name>dfs.data.dir</name> <value>file:///home/hadoop/hadoopinfra/hdfs/datanode </value> </property> </configuration>
Примечание. В приведенном выше файле все значения свойств определяются пользователем, и вы можете вносить изменения в соответствии с инфраструктурой Hadoop.
Пряжа-site.xml
Этот файл используется для настройки пряжи в Hadoop. Откройте файл yarn-site.xml и добавьте следующие свойства между тегами <configuration>, </ configuration>.
<configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration>
mapred-site.xml
Этот файл используется для указания используемой нами структуры MapReduce. По умолчанию Hadoop содержит шаблон yarn-site.xml. Прежде всего вам необходимо скопировать файл из mapred-site.xml.template в файл mapred-site.xml с помощью следующей команды.
$ cp mapred-site.xml.template mapred-site.xml
Откройте файл mapred-site.xml и добавьте следующие свойства между тегами <configuration>, </ configuration>.
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
Проверка правильности установки Hadoop
Следующие шаги используются для проверки установки Hadoop.
Шаг 1 — Настройка узла имени
Настройте namenode с помощью команды «hdfs namenode -format» следующим образом:
$ cd ~ $ hdfs namenode -format
Ожидаемый результат заключается в следующем —
10/24/14 21:30:55 INFO namenode.NameNode: STARTUP_MSG: /************************************************************ STARTUP_MSG: Starting NameNode STARTUP_MSG: host = localhost/192.168.1.11 STARTUP_MSG: args = [-format] STARTUP_MSG: version = 2.4.1 ... ... 10/24/14 21:30:56 INFO common.Storage: Storage directory /home/hadoop/hadoopinfra/hdfs/namenode has been successfully formatted. 10/24/14 21:30:56 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0 10/24/14 21:30:56 INFO util.ExitUtil: Exiting with status 0 10/24/14 21:30:56 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at localhost/192.168.1.11 ************************************************************/
Шаг 2 — Проверка Hadoop dfs
Выполните следующую команду, чтобы запустить файловую систему Hadoop.
$ start-dfs.sh
Ожидаемый результат следующий:
10/24/14 21:37:56 Starting namenodes on [localhost] localhost: starting namenode, logging to /home/hadoop/hadoop- 2.4.1/logs/hadoop-hadoop-namenode-localhost.out localhost: starting datanode, logging to /home/hadoop/hadoop- 2.4.1/logs/hadoop-hadoop-datanode-localhost.out Starting secondary namenodes [0.0.0.0]
Шаг 3 — Проверка скрипта пряжи
Следующая команда используется для запуска скрипта пряжи. Выполнение этой команды запустит ваши демоны пряжи.
$ start-yarn.sh
Ожидаемый результат следующий:
starting yarn daemons starting resourcemanager, logging to /home/hadoop/hadoop- 2.4.1/logs/yarn-hadoop-resourcemanager-localhost.out localhost: starting node manager, logging to /home/hadoop/hadoop- 2.4.1/logs/yarn-hadoop-nodemanager-localhost.out
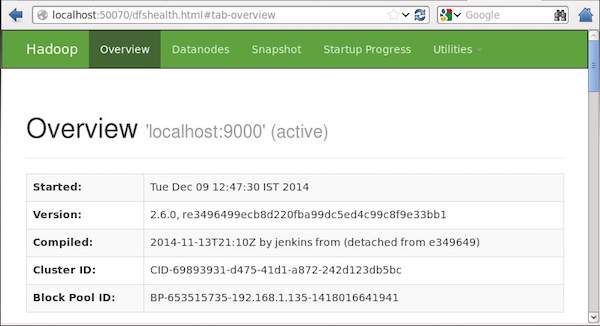
Шаг 4 — Доступ к Hadoop в браузере
Номер порта по умолчанию для доступа к Hadoop — 50070. Используйте следующий URL-адрес, чтобы получить службы Hadoop в своем браузере.
http://localhost:50070/
На следующем снимке экрана показан браузер Hadoop.
Шаг 5 — Проверьте все приложения кластера
Номер порта по умолчанию для доступа ко всем приложениям кластера — 8088. Используйте следующий URL для использования этой службы.
http://localhost:8088/
На следующем снимке экрана показан кластерный браузер Hadoop.
MapReduce — API
В этой главе мы подробно рассмотрим классы и их методы, которые участвуют в операциях программирования MapReduce. В первую очередь мы сосредоточимся на следующем:
- Интерфейс JobContext
- Класс работы
- Mapper Class
- Класс редуктора
Интерфейс JobContext
Интерфейс JobContext — это суперинтерфейс для всех классов, который определяет различные задания в MapReduce. Это дает вам доступ только для чтения к заданию, которое предоставляется задачам во время их выполнения.
Ниже приведены подинтерфейсы интерфейса JobContext.
| S.No. | Подинтерфейс Описание |
|---|---|
| 1. | MapContext <KEYIN, VALUEIN, KEYOUT, VALUEOUT>
Определяет контекст, который предоставляется Mapper. |
| 2. | ReduceContext <KEYIN, VALUEIN, KEYOUT, VALUEOUT>
Определяет контекст, который передается редуктору. |
Определяет контекст, который предоставляется Mapper.
Определяет контекст, который передается редуктору.
Класс Job — это основной класс, который реализует интерфейс JobContext.
Класс работы
Класс Job является наиболее важным классом в API MapReduce. Это позволяет пользователю настраивать задание, отправлять его, контролировать его выполнение и запрашивать состояние. Методы set работают только до отправки задания, после чего они генерируют исключение IllegalStateException.
Обычно пользователь создает приложение, описывает различные аспекты задания, а затем отправляет задание и отслеживает его выполнение.
Вот пример того, как подать заявку —
// Create a new Job
Job job = new Job(new Configuration());
job.setJarByClass(MyJob.class);
// Specify various job-specific parameters
job.setJobName("myjob");
job.setInputPath(new Path("in"));
job.setOutputPath(new Path("out"));
job.setMapperClass(MyJob.MyMapper.class);
job.setReducerClass(MyJob.MyReducer.class);
// Submit the job, then poll for progress until the job is complete
job.waitForCompletion(true);
Конструкторы
Ниже приводится краткое описание конструктора класса Job.
| S.No | Сводка конструктора |
|---|---|
| 1 | Работа () |
| 2 | Job (Конфиг конфигурации) |
| 3 | Job (Конфигурация conf, String jobName) |
методы
Вот некоторые из важных методов класса Job:
| S.No | Описание метода |
|---|---|
| 1 | getJobName ()
Заданное пользователем имя задания. |
| 2 | getJobState ()
Возвращает текущее состояние задания. |
| 3 | завершено()
Проверяет, закончена ли работа или нет. |
| 4 | setInputFormatClass ()
Устанавливает InputFormat для работы. |
| 5 | setJobName (имя строки)
Устанавливает заданное пользователем имя задания. |
| 6 | setOutputFormatClass ()
Устанавливает формат вывода для работы. |
| 7 | setMapperClass (класс)
Устанавливает Mapper для работы. |
| 8 | setReducerClass (класс)
Устанавливает Редуктор для работы. |
| 9 | setPartitionerClass (класс)
Устанавливает Partitioner для работы. |
| 10 | setCombinerClass (класс)
Устанавливает Combiner для работы. |
Заданное пользователем имя задания.
Возвращает текущее состояние задания.
Проверяет, закончена ли работа или нет.
Устанавливает InputFormat для работы.
Устанавливает заданное пользователем имя задания.
Устанавливает формат вывода для работы.
Устанавливает Mapper для работы.
Устанавливает Редуктор для работы.
Устанавливает Partitioner для работы.
Устанавливает Combiner для работы.
Mapper Class
Класс Mapper определяет задание Map. Сопоставляет входные пары ключ-значение с набором промежуточных пар ключ-значение. Карты — это отдельные задачи, которые преобразуют входные записи в промежуточные записи. Преобразованные промежуточные записи не обязательно должны быть того же типа, что и входные записи. Заданная входная пара может отображаться на ноль или на множество выходных пар.
метод
карта является наиболее известным методом класса Mapper. Синтаксис определен ниже —
map(KEYIN key, VALUEIN value, org.apache.hadoop.mapreduce.Mapper.Context context)
Этот метод вызывается один раз для каждой пары ключ-значение во входном разбиении.
Класс редуктора
Класс Reducer определяет задание Reduce в MapReduce. Это уменьшает набор промежуточных значений, которые разделяют ключ, до меньшего набора значений. Реализации редуктора могут получить доступ к Конфигурации для задания через метод JobContext.getConfiguration (). Редуктор имеет три основных этапа — перемешивание, сортировка и уменьшение.
-
Перемешать — Редуктор копирует отсортированный вывод из каждого Mapper, используя HTTP по всей сети.
-
Сортировать — платформа объединяет сортировку входов Редуктора по ключам (поскольку разные Mappers могут выводить один и тот же ключ). Фазы тасования и сортировки происходят одновременно, т. Е. Во время выборки выходов они объединяются.
-
Сокращение — На этом этапе метод Redu (Object, Iterable, Context) вызывается для каждого <ключа, (набора значений)> в отсортированных входных данных.
Перемешать — Редуктор копирует отсортированный вывод из каждого Mapper, используя HTTP по всей сети.
Сортировать — платформа объединяет сортировку входов Редуктора по ключам (поскольку разные Mappers могут выводить один и тот же ключ). Фазы тасования и сортировки происходят одновременно, т. Е. Во время выборки выходов они объединяются.
Сокращение — На этом этапе метод Redu (Object, Iterable, Context) вызывается для каждого <ключа, (набора значений)> в отсортированных входных данных.
метод
Редукция — самый известный метод класса Редукторов. Синтаксис определен ниже —
reduce (KEYIN key, Iterable<VALUEIN> values, org.apache.hadoop.mapreduce.Reducer.Context context)
Этот метод вызывается один раз для каждого ключа в коллекции пар ключ-значение.
MapReduce — реализация Hadoop
MapReduce — это инфраструктура, которая используется для написания приложений для надежной обработки огромных объемов данных на больших кластерах аппаратного оборудования. В этой главе рассказывается о работе MapReduce в среде Hadoop с использованием Java.
Алгоритм MapReduce
Обычно парадигма MapReduce основана на отправке программ сокращения карт на компьютеры, где хранятся фактические данные.
-
Во время задания MapReduce Hadoop отправляет задачи Map и Reduce на соответствующие серверы в кластере.
-
Каркас управляет всеми деталями передачи данных, такими как выдача задач, проверка выполнения задач и копирование данных вокруг кластера между узлами.
-
Большая часть вычислений происходит на узлах с данными на локальных дисках, что снижает сетевой трафик.
-
После выполнения заданной задачи кластер собирает и сокращает данные, чтобы сформировать соответствующий результат, и отправляет их обратно на сервер Hadoop.
Во время задания MapReduce Hadoop отправляет задачи Map и Reduce на соответствующие серверы в кластере.
Каркас управляет всеми деталями передачи данных, такими как выдача задач, проверка выполнения задач и копирование данных вокруг кластера между узлами.
Большая часть вычислений происходит на узлах с данными на локальных дисках, что снижает сетевой трафик.
После выполнения заданной задачи кластер собирает и сокращает данные, чтобы сформировать соответствующий результат, и отправляет их обратно на сервер Hadoop.
Входы и выходы (перспектива Java)
Каркас MapReduce работает с парами ключ-значение, то есть каркас рассматривает входные данные для задания в виде набора пар ключ-значение и создает набор пар ключ-значение в качестве выходных данных задания, предположительно различных типов.
Классы ключа и значения должны быть сериализуемы платформой, и, следовательно, необходимо реализовать интерфейс Writable. Кроме того, ключевые классы должны реализовывать интерфейс WritableComparable для облегчения сортировки в рамках.
Оба формата ввода и вывода задания MapReduce представлены в виде пар ключ-значение —
(Вход) <k1, v1> -> карта -> <k2, v2> -> уменьшить -> <k3, v3> (вывод).
| вход | Выход | |
|---|---|---|
| карта | <k1, v1> | список (<k2, v2>) |
| уменьшить | <k2, список (v2)> | список (<k3, v3>) |
Реализация MapReduce
В следующей таблице приведены данные, касающиеся потребления электроэнергии в организации. Таблица включает ежемесячное потребление электроэнергии и среднегодовое значение за пять лет подряд.
| январь | февраль | март | апрель | май | июнь | июль | август | сентябрь | октябрь | ноябрь | декабрь | в среднем | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1979 | 23 | 23 | 2 | 43 | 24 | 25 | 26 | 26 | 26 | 26 | 25 | 26 | 25 |
| 1980 | 26 | 27 | 28 | 28 | 28 | 30 | 31 | 31 | 31 | 30 | 30 | 30 | 29 |
| 1981 | 31 | 32 | 32 | 32 | 33 | 34 | 35 | 36 | 36 | 34 | 34 | 34 | 34 |
| 1984 | 39 | 38 | 39 | 39 | 39 | 41 | 42 | 43 | 40 | 39 | 38 | 38 | 40 |
| 1985 | 38 | 39 | 39 | 39 | 39 | 41 | 41 | 41 | 00 | 40 | 39 | 39 | 45 |
Нам нужно написать приложения для обработки входных данных в данной таблице, чтобы найти год максимального использования, год минимального использования и так далее. Эта задача проста для программистов с конечным количеством записей, поскольку они просто напишут логику для получения требуемого вывода и передадут данные в написанное приложение.
Давайте теперь поднимем масштаб входных данных. Предположим, мы должны проанализировать потребление электроэнергии всеми крупными отраслями конкретного государства. Когда мы пишем приложения для обработки таких массовых данных,
-
Они займут много времени, чтобы выполнить.
-
При переносе данных из источника на сетевой сервер будет большой сетевой трафик.
Они займут много времени, чтобы выполнить.
При переносе данных из источника на сетевой сервер будет большой сетевой трафик.
Для решения этих проблем у нас есть инфраструктура MapReduce.
Входные данные
Приведенные выше данные сохраняются как sample.txt и передаются в качестве входных данных. Входной файл выглядит так, как показано ниже.
| 1979 | 23 | 23 | 2 | 43 | 24 | 25 | 26 | 26 | 26 | 26 | 25 | 26 | 25 |
| 1980 | 26 | 27 | 28 | 28 | 28 | 30 | 31 | 31 | 31 | 30 | 30 | 30 | 29 |
| 1981 | 31 | 32 | 32 | 32 | 33 | 34 | 35 | 36 | 36 | 34 | 34 | 34 | 34 |
| 1984 | 39 | 38 | 39 | 39 | 39 | 41 | 42 | 43 | 40 | 39 | 38 | 38 | 40 |
| 1985 | 38 | 39 | 39 | 39 | 39 | 41 | 41 | 41 | 00 | 40 | 39 | 39 | 45 |
Пример программы
Следующая программа для примера данных использует каркас MapReduce.
package hadoop; import java.util.*; import java.io.IOException; import java.io.IOException; import org.apache.hadoop.fs.Path; import org.apache.hadoop.conf.*; import org.apache.hadoop.io.*; import org.apache.hadoop.mapred.*; import org.apache.hadoop.util.*; public class ProcessUnits { //Mapper class public static class E_EMapper extends MapReduceBase implements Mapper<LongWritable, /*Input key Type */ Text, /*Input value Type*/ Text, /*Output key Type*/ IntWritable> /*Output value Type*/ { //Map function public void map(LongWritable key, Text value, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException { String line = value.toString(); String lasttoken = null; StringTokenizer s = new StringTokenizer(line,"\t"); String year = s.nextToken(); while(s.hasMoreTokens()){ lasttoken=s.nextToken(); } int avgprice = Integer.parseInt(lasttoken); output.collect(new Text(year), new IntWritable(avgprice)); } } //Reducer class public static class E_EReduce extends MapReduceBase implements Reducer< Text, IntWritable, Text, IntWritable > { //Reduce function public void reduce(Text key, Iterator <IntWritable> values, OutputCollector>Text, IntWritable> output, Reporter reporter) throws IOException { int maxavg=30; int val=Integer.MIN_VALUE; while (values.hasNext()) { if((val=values.next().get())>maxavg) { output.collect(key, new IntWritable(val)); } } } } //Main function public static void main(String args[])throws Exception { JobConf conf = new JobConf(Eleunits.class); conf.setJobName("max_eletricityunits"); conf.setOutputKeyClass(Text.class); conf.setOutputValueClass(IntWritable.class); conf.setMapperClass(E_EMapper.class); conf.setCombinerClass(E_EReduce.class); conf.setReducerClass(E_EReduce.class); conf.setInputFormat(TextInputFormat.class); conf.setOutputFormat(TextOutputFormat.class); FileInputFormat.setInputPaths(conf, new Path(args[0])); FileOutputFormat.setOutputPath(conf, new Path(args[1])); JobClient.runJob(conf); } }
Сохраните вышеуказанную программу в ProcessUnits.java . Компиляция и выполнение программы приведены ниже.
Компиляция и выполнение программы ProcessUnits
Предположим, мы находимся в домашнем каталоге пользователя Hadoop (например, / home / hadoop).
Следуйте инструкциям ниже, чтобы скомпилировать и выполнить вышеуказанную программу.
Шаг 1 — Используйте следующую команду, чтобы создать каталог для хранения скомпилированных классов Java.
$ mkdir units
Шаг 2 — Загрузите Hadoop-core-1.2.1.jar, который используется для компиляции и выполнения программы MapReduce. Загрузите банку с mvnrepository.com . Предположим, что папка для загрузки — / home / hadoop /.
Шаг 3 — Следующие команды используются для компиляции программы ProcessUnits.java и для создания jar для программы.
$ javac -classpath hadoop-core-1.2.1.jar -d units ProcessUnits.java $ jar -cvf units.jar -C units/ .
Шаг 4 — Следующая команда используется для создания входного каталога в HDFS.
$HADOOP_HOME/bin/hadoop fs -mkdir input_dir
Шаг 5 — Следующая команда используется для копирования входного файла с именем sample.txt во входной каталог HDFS.
$HADOOP_HOME/bin/hadoop fs -put /home/hadoop/sample.txt input_dir
Шаг 6 — Следующая команда используется для проверки файлов во входном каталоге
$HADOOP_HOME/bin/hadoop fs -ls input_dir/
Шаг 7 — Следующая команда используется для запуска приложения Eleunit_max путем извлечения входных файлов из входного каталога.
$HADOOP_HOME/bin/hadoop jar units.jar hadoop.ProcessUnits input_dir output_dir
Подождите некоторое время, пока файл не запустится. После выполнения выходные данные содержат несколько входных разбиений, задачи Map, задачи Reducer и т. Д.
INFO mapreduce.Job: Job job_1414748220717_0002 completed successfully 14/10/31 06:02:52 INFO mapreduce.Job: Counters: 49 File System Counters FILE: Number of bytes read=61 FILE: Number of bytes written=279400 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=546 HDFS: Number of bytes written=40 HDFS: Number of read operations=9 HDFS: Number of large read operations=0 HDFS: Number of write operations=2 Job Counters Launched map tasks=2 Launched reduce tasks=1 Data-local map tasks=2 Total time spent by all maps in occupied slots (ms)=146137 Total time spent by all reduces in occupied slots (ms)=441 Total time spent by all map tasks (ms)=14613 Total time spent by all reduce tasks (ms)=44120 Total vcore-seconds taken by all map tasks=146137 Total vcore-seconds taken by all reduce tasks=44120 Total megabyte-seconds taken by all map tasks=149644288 Total megabyte-seconds taken by all reduce tasks=45178880 Map-Reduce Framework Map input records=5 Map output records=5 Map output bytes=45 Map output materialized bytes=67 Input split bytes=208 Combine input records=5 Combine output records=5 Reduce input groups=5 Reduce shuffle bytes=6 Reduce input records=5 Reduce output records=5 Spilled Records=10 Shuffled Maps =2 Failed Shuffles=0 Merged Map outputs=2 GC time elapsed (ms)=948 CPU time spent (ms)=5160 Physical memory (bytes) snapshot=47749120 Virtual memory (bytes) snapshot=2899349504 Total committed heap usage (bytes)=277684224 File Output Format Counters Bytes Written=40
Шаг 8 — Следующая команда используется для проверки результирующих файлов в выходной папке.
$HADOOP_HOME/bin/hadoop fs -ls output_dir/
Шаг 9 — Следующая команда используется для просмотра выходных данных в файле Part-00000 . Этот файл создан HDFS.
$HADOOP_HOME/bin/hadoop fs -cat output_dir/part-00000
Ниже приводится вывод, сгенерированный программой MapReduce —
| 1981 | 34 |
| 1984 | 40 |
| 1985 | 45 |
Шаг 10 — Следующая команда используется для копирования выходной папки из HDFS в локальную файловую систему.
$HADOOP_HOME/bin/hadoop fs -cat output_dir/part-00000/bin/hadoop dfs -get output_dir /home/hadoop
MapReduce — Partitioner
Секционер работает как условие при обработке входного набора данных. Фаза разбиения происходит после фазы Map и до фазы Reduce.
Количество секционеров равно количеству редукторов. Это означает, что разделитель разделит данные в соответствии с числом редукторов. Следовательно, данные, передаваемые с одного разделителя, обрабатываются одним редуктором.
Разметка
Разделитель разделяет пары ключ-значение промежуточных выходов Map. Он разделяет данные, используя пользовательское условие, которое работает как хэш-функция. Общее количество разделов совпадает с количеством заданий Reducer для задания. Давайте рассмотрим пример, чтобы понять, как работает разделитель.
Внедрение MapReduce Partitioner
Для удобства предположим, что у нас есть небольшая таблица Employee со следующими данными. Мы будем использовать этот пример данных в качестве нашего входного набора данных, чтобы продемонстрировать, как работает разделитель.
| Я бы | название | Возраст | Пол | Оплата труда |
|---|---|---|---|---|
| 1201 | Гопал | 45 | мужчина | 50000 |
| 1202 | Маниша | 40 | женский | 50000 |
| 1203 | Халил | 34 | мужчина | 30000 |
| 1204 | Prasanth | 30 | мужчина | 30000 |
| 1205 | Киран | 20 | мужчина | 40000 |
| 1206 | Лакшми | 25 | женский | 35000 |
| 1207 | Бхавайя | 20 | женский | 15000 |
| 1208 | Reshma | 19 | женский | 15000 |
| 1209 | kranthi | 22 | мужчина | 22000 |
| +1210 | Сатиш | 24 | мужчина | 25000 |
| 1211 | Кришна | 25 | мужчина | 25000 |
| 1212 | Аршад | 28 | мужчина | 20000 |
| 1213 | Лаванья | 18 | женский | 8000 |
Мы должны написать заявление для обработки входного набора данных, чтобы найти работника с наибольшим окладом по полу в разных возрастных группах (например, ниже 20 лет, от 21 до 30 лет, выше 30 лет).
Входные данные
Приведенные выше данные сохраняются в файле input.txt в каталоге «/ home / hadoop / hadoopPartitioner» и передаются в качестве входных данных.
| 1201 | Гопал | 45 | мужчина | 50000 |
| 1202 | Маниша | 40 | женский | 51000 |
| 1203 | Khaleel | 34 | мужчина | 30000 |
| 1204 | Prasanth | 30 | мужчина | 31000 |
| 1205 | Киран | 20 | мужчина | 40000 |
| 1206 | Лакшми | 25 | женский | 35000 |
| 1207 | Бхавайя | 20 | женский | 15000 |
| 1208 | Reshma | 19 | женский | 14 000 |
| 1209 | kranthi | 22 | мужчина | 22000 |
| +1210 | Сатиш | 24 | мужчина | 25000 |
| 1211 | Кришна | 25 | мужчина | 26000 |
| 1212 | Аршад | 28 | мужчина | 20000 |
| 1213 | Лаванья | 18 | женский | 8000 |
Основываясь на данном входе, ниже приводится алгоритмическое объяснение программы.
Задачи карты
Задача карты принимает пары ключ-значение в качестве входных данных, пока у нас есть текстовые данные в текстовом файле. Входные данные для этой задачи карты следующие:
Ввод — ключом будет шаблон, такой как «любая специальная клавиша + имя файла + номер строки» (пример: ключ = @ input1), а значением будут данные в этой строке (пример: значение = 1201 \ t gopal \ t 45 \ т мужской \ т 50000).
Метод — Работа этой задачи карты заключается в следующем —
-
Прочитайте значение (запись данных), которое поступает в качестве входного значения из списка аргументов в строке.
-
Используя функцию split, разделите пол и сохраните в строковую переменную.
Прочитайте значение (запись данных), которое поступает в качестве входного значения из списка аргументов в строке.
Используя функцию split, разделите пол и сохраните в строковую переменную.
String[] str = value.toString().split("\t", -3);
String gender=str[3];
-
Отправьте информацию о поле и значение записи в виде пары выходной ключ-значение из задачи сопоставления в задачу разбиения .
Отправьте информацию о поле и значение записи в виде пары выходной ключ-значение из задачи сопоставления в задачу разбиения .
context.write(new Text(gender), new Text(value));
-
Повторите все вышеперечисленные шаги для всех записей в текстовом файле.
Повторите все вышеперечисленные шаги для всех записей в текстовом файле.
Вывод. Вы получите половые данные и данные записи в виде пар ключ-значение.
Задача Partitioner
Задача секционера принимает пары ключ-значение из задачи карты в качестве входных данных. Разделение подразумевает разделение данных на сегменты. В соответствии с заданными условными критериями разделов входные парные данные ключ-значение могут быть разделены на три части на основе возрастных критериев.
Ввод — все данные в коллекции пар ключ-значение.
ключ = значение поля пола в записи.
значение = значение всей записи данных этого пола.
Метод . Процесс логики разбиения выполняется следующим образом.
- Считайте значение поля возраста из пары ключ-значение.
String[] str = value.toString().split("\t");
int age = Integer.parseInt(str[2]);
-
Проверьте значение возраста с соблюдением следующих условий.
- Возраст не более 20
- Возраст больше 20 и меньше или равно 30.
- Возраст старше 30.
Проверьте значение возраста с соблюдением следующих условий.
if(age<=20) { return 0; } else if(age>20 && age<=30) { return 1 % numReduceTasks; } else { return 2 % numReduceTasks; }
Вывод . Все данные пар ключ-значение сегментированы на три набора пар ключ-значение. Редуктор работает индивидуально на каждую коллекцию.
Уменьшить задачи
Количество задач секционирования равно количеству задач редуктора. Здесь у нас есть три задачи секционирования, и, следовательно, у нас есть три задачи редуктора, которые нужно выполнить.
Ввод — Редуктор будет выполняться три раза с различным набором пар ключ-значение.
ключ = значение поля пола в записи.
значение = все данные записи этого пола.
Метод — следующая логика будет применяться к каждой коллекции.
- Прочитайте значение поля Зарплата каждой записи.
String [] str = val.toString().split("\t", -3);
Note: str[4] have the salary field value.
-
Проверьте зарплату с помощью переменной max. Если str [4] является максимальной зарплатой, присвойте str [4] значение max, в противном случае пропустите шаг.
Проверьте зарплату с помощью переменной max. Если str [4] является максимальной зарплатой, присвойте str [4] значение max, в противном случае пропустите шаг.
if(Integer.parseInt(str[4])>max) { max=Integer.parseInt(str[4]); }
-
Повторите шаги 1 и 2 для каждой коллекции ключей (мужские и женские — ключевые коллекции). Выполнив эти три шага, вы найдете одну максимальную зарплату из коллекции ключей для мужчин и одну максимальную зарплату из коллекции ключей для женщин.
Повторите шаги 1 и 2 для каждой коллекции ключей (мужские и женские — ключевые коллекции). Выполнив эти три шага, вы найдете одну максимальную зарплату из коллекции ключей для мужчин и одну максимальную зарплату из коллекции ключей для женщин.
context.write(new Text(key), new IntWritable(max));
Вывод. Наконец, вы получите набор данных пары ключ-значение в трех коллекциях разных возрастных групп. Он содержит максимальную зарплату из коллекции мужчин и максимальную зарплату из коллекции женщин в каждой возрастной группе соответственно.
После выполнения задач Map, Partitioner и Reduce три набора данных пары ключ-значение сохраняются в трех разных файлах в качестве выходных данных.
Все три задачи рассматриваются как задания MapReduce. Следующие требования и спецификации этих заданий должны быть указаны в Конфигурациях —
- Название работы
- Форматы ввода и вывода ключей и значений
- Отдельные классы для задач Map, Reduce и Partitioner
Configuration conf = getConf(); //Create Job Job job = new Job(conf, "topsal"); job.setJarByClass(PartitionerExample.class); // File Input and Output paths FileInputFormat.setInputPaths(job, new Path(arg[0])); FileOutputFormat.setOutputPath(job,new Path(arg[1])); //Set Mapper class and Output format for key-value pair. job.setMapperClass(MapClass.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(Text.class); //set partitioner statement job.setPartitionerClass(CaderPartitioner.class); //Set Reducer class and Input/Output format for key-value pair. job.setReducerClass(ReduceClass.class); //Number of Reducer tasks. job.setNumReduceTasks(3); //Input and Output format for data job.setInputFormatClass(TextInputFormat.class); job.setOutputFormatClass(TextOutputFormat.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(Text.class);
Пример программы
Следующая программа показывает, как реализовать разделители для заданных критериев в программе MapReduce.
package partitionerexample; import java.io.*; import org.apache.hadoop.io.*; import org.apache.hadoop.mapreduce.*; import org.apache.hadoop.conf.*; import org.apache.hadoop.conf.*; import org.apache.hadoop.fs.*; import org.apache.hadoop.mapreduce.lib.input.*; import org.apache.hadoop.mapreduce.lib.output.*; import org.apache.hadoop.util.*; public class PartitionerExample extends Configured implements Tool { //Map class public static class MapClass extends Mapper<LongWritable,Text,Text,Text> { public void map(LongWritable key, Text value, Context context) { try{ String[] str = value.toString().split("\t", -3); String gender=str[3]; context.write(new Text(gender), new Text(value)); } catch(Exception e) { System.out.println(e.getMessage()); } } } //Reducer class public static class ReduceClass extends Reducer<Text,Text,Text,IntWritable> { public int max = -1; public void reduce(Text key, Iterable <Text> values, Context context) throws IOException, InterruptedException { max = -1; for (Text val : values) { String [] str = val.toString().split("\t", -3); if(Integer.parseInt(str[4])>max) max=Integer.parseInt(str[4]); } context.write(new Text(key), new IntWritable(max)); } } //Partitioner class public static class CaderPartitioner extends Partitioner < Text, Text > { @Override public int getPartition(Text key, Text value, int numReduceTasks) { String[] str = value.toString().split("\t"); int age = Integer.parseInt(str[2]); if(numReduceTasks == 0) { return 0; } if(age<=20) { return 0; } else if(age>20 && age<=30) { return 1 % numReduceTasks; } else { return 2 % numReduceTasks; } } } @Override public int run(String[] arg) throws Exception { Configuration conf = getConf(); Job job = new Job(conf, "topsal"); job.setJarByClass(PartitionerExample.class); FileInputFormat.setInputPaths(job, new Path(arg[0])); FileOutputFormat.setOutputPath(job,new Path(arg[1])); job.setMapperClass(MapClass.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(Text.class); //set partitioner statement job.setPartitionerClass(CaderPartitioner.class); job.setReducerClass(ReduceClass.class); job.setNumReduceTasks(3); job.setInputFormatClass(TextInputFormat.class); job.setOutputFormatClass(TextOutputFormat.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(Text.class); System.exit(job.waitForCompletion(true)? 0 : 1); return 0; } public static void main(String ar[]) throws Exception { int res = ToolRunner.run(new Configuration(), new PartitionerExample(),ar); System.exit(0); } }
Сохраните приведенный выше код как PartitionerExample.java в «/ home / hadoop / hadoopPartitioner». Компиляция и выполнение программы приведены ниже.
Компиляция и выполнение
Предположим, мы находимся в домашнем каталоге пользователя Hadoop (например, / home / hadoop).
Следуйте инструкциям ниже, чтобы скомпилировать и выполнить вышеуказанную программу.
Шаг 1 — Загрузите Hadoop-core-1.2.1.jar, который используется для компиляции и запуска программы MapReduce. Вы можете скачать банку с mvnrepository.com .
Допустим, загруженная папка имеет вид «/ home / hadoop / hadoopPartitioner»
Шаг 2 — Следующие команды используются для компиляции программы PartitionerExample.java и создания jar для программы.
$ javac -classpath hadoop-core-1.2.1.jar -d ProcessUnits.java $ jar -cvf PartitionerExample.jar -C .
Шаг 3 — Используйте следующую команду для создания входного каталога в HDFS.
$HADOOP_HOME/bin/hadoop fs -mkdir input_dir
Шаг 4 — Используйте следующую команду, чтобы скопировать входной файл с именем input.txt во входной каталог HDFS.
$HADOOP_HOME/bin/hadoop fs -put /home/hadoop/hadoopPartitioner/input.txt input_dir
Шаг 5 — Используйте следующую команду, чтобы проверить файлы во входном каталоге.
$HADOOP_HOME/bin/hadoop fs -ls input_dir/
Шаг 6 — Используйте следующую команду, чтобы запустить приложение Top salary, взяв входные файлы из входного каталога.
$HADOOP_HOME/bin/hadoop jar PartitionerExample.jar partitionerexample.PartitionerExample input_dir/input.txt output_dir
Подождите некоторое время, пока файл не запустится. После выполнения выходные данные содержат несколько входных разбиений, задач сопоставления и задач редуктора.
15/02/04 15:19:51 INFO mapreduce.Job: Job job_1423027269044_0021 completed successfully 15/02/04 15:19:52 INFO mapreduce.Job: Counters: 49 File System Counters FILE: Number of bytes read=467 FILE: Number of bytes written=426777 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=480 HDFS: Number of bytes written=72 HDFS: Number of read operations=12 HDFS: Number of large read operations=0 HDFS: Number of write operations=6 Job Counters Launched map tasks=1 Launched reduce tasks=3 Data-local map tasks=1 Total time spent by all maps in occupied slots (ms)=8212 Total time spent by all reduces in occupied slots (ms)=59858 Total time spent by all map tasks (ms)=8212 Total time spent by all reduce tasks (ms)=59858 Total vcore-seconds taken by all map tasks=8212 Total vcore-seconds taken by all reduce tasks=59858 Total megabyte-seconds taken by all map tasks=8409088 Total megabyte-seconds taken by all reduce tasks=61294592 Map-Reduce Framework Map input records=13 Map output records=13 Map output bytes=423 Map output materialized bytes=467 Input split bytes=119 Combine input records=0 Combine output records=0 Reduce input groups=6 Reduce shuffle bytes=467 Reduce input records=13 Reduce output records=6 Spilled Records=26 Shuffled Maps =3 Failed Shuffles=0 Merged Map outputs=3 GC time elapsed (ms)=224 CPU time spent (ms)=3690 Physical memory (bytes) snapshot=553816064 Virtual memory (bytes) snapshot=3441266688 Total committed heap usage (bytes)=334102528 Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0 File Input Format Counters Bytes Read=361 File Output Format Counters Bytes Written=72
Шаг 7 — Используйте следующую команду для проверки результирующих файлов в выходной папке.
$HADOOP_HOME/bin/hadoop fs -ls output_dir/
Вы найдете выходные данные в трех файлах, потому что вы используете в своей программе три секционера и три редуктора.
Шаг 8 — Используйте следующую команду, чтобы увидеть выходные данные в файле Part-00000 . Этот файл создан HDFS.
$HADOOP_HOME/bin/hadoop fs -cat output_dir/part-00000
Выход в Part-00000
Female 15000 Male 40000
Используйте следующую команду, чтобы увидеть выходные данные в файле Part-00001 .
$HADOOP_HOME/bin/hadoop fs -cat output_dir/part-00001
Выход в Part-00001
Female 35000 Male 31000
Используйте следующую команду, чтобы увидеть выходные данные в файле Part-00002 .
$HADOOP_HOME/bin/hadoop fs -cat output_dir/part-00002
Выход в Part-00002
Female 51000 Male 50000
MapReduce — Combiners
Combiner, также известный как полуредуктор, является необязательным классом, который работает, принимая входные данные из класса Map и затем передавая выходные пары ключ-значение в класс Reducer.
Основная функция Combiner состоит в том, чтобы суммировать выходные записи карты с одним и тем же ключом. Выход (сбор значения ключа) объединителя будет отправлен по сети фактической задаче «Редуктор» в качестве входных данных.
Сумматор
Класс Combiner используется между классом Map и классом Reduce для уменьшения объема передачи данных между Map и Reduce. Обычно выходные данные задачи карты большие, а данные, передаваемые в задачу сокращения, большие.
На следующей диаграмме задачи MapReduce показана ФАЗА КОМБИНИРОВАНИЯ.
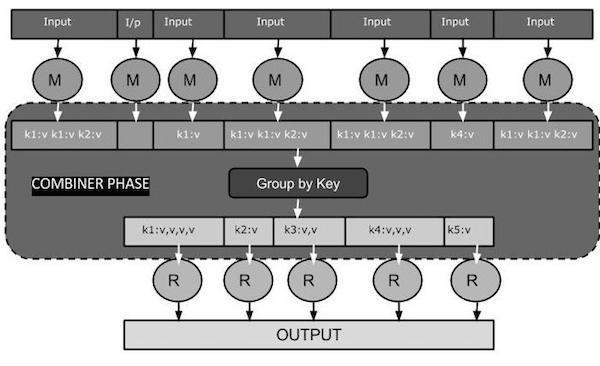
Как работает Combiner?
Вот краткое описание того, как работает MapReduce Combiner:
-
У объединителя нет предопределенного интерфейса, и он должен реализовывать метод Redu () интерфейса Reducer.
-
Комбайнер работает с каждым ключом вывода карты. Он должен иметь те же типы значений выходного ключа, что и класс Reducer.
-
Объединитель может создавать сводную информацию из большого набора данных, поскольку он заменяет исходный вывод карты.
У объединителя нет предопределенного интерфейса, и он должен реализовывать метод Redu () интерфейса Reducer.
Комбайнер работает с каждым ключом вывода карты. Он должен иметь те же типы значений выходного ключа, что и класс Reducer.
Объединитель может создавать сводную информацию из большого набора данных, поскольку он заменяет исходный вывод карты.
Хотя Combiner не является обязательным, он помогает разделить данные на несколько групп для фазы сокращения, что упрощает обработку.
Реализация MapReduce Combiner
Следующий пример дает теоретическое представление о комбайнерах. Предположим, у нас есть следующий входной текстовый файл с именем input.txt для MapReduce.
What do you mean by Object What do you know about Java What is Java Virtual Machine How Java enabled High Performance
Важные этапы программы MapReduce с Combiner обсуждаются ниже.
Record Reader
Это первая фаза MapReduce, где Record Reader считывает каждую строку из входного текстового файла в виде текста и выдает выходные данные в виде пар ключ-значение.
Ввод — построчно текст из входного файла.
Выход — формирует пары ключ-значение. Ниже приведен набор ожидаемых пар ключ-значение.
<1, What do you mean by Object> <2, What do you know about Java> <3, What is Java Virtual Machine> <4, How Java enabled High Performance>
Фаза карты
Фаза Map принимает входные данные из Record Reader, обрабатывает их и создает выходные данные в виде другого набора пар ключ-значение.
Вход — следующая пара ключ-значение — это вход, полученный от устройства чтения записей.
<1, What do you mean by Object> <2, What do you know about Java> <3, What is Java Virtual Machine> <4, How Java enabled High Performance>
Фаза Map считывает каждую пару ключ-значение, делит каждое слово на значение, используя StringTokenizer, обрабатывает каждое слово как ключ, а счетчик этого слова — как значение. В следующем фрагменте кода показаны класс Mapper и функция map.
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> { private final static IntWritable one = new IntWritable(1); private Text word = new Text(); public void map(Object key, Text value, Context context) throws IOException, InterruptedException { StringTokenizer itr = new StringTokenizer(value.toString()); while (itr.hasMoreTokens()) { word.set(itr.nextToken()); context.write(word, one); } } }
Вывод — ожидаемый вывод выглядит следующим образом —
<What,1> <do,1> <you,1> <mean,1> <by,1> <Object,1> <What,1> <do,1> <you,1> <know,1> <about,1> <Java,1> <What,1> <is,1> <Java,1> <Virtual,1> <Machine,1> <How,1> <Java,1> <enabled,1> <High,1> <Performance,1>
Фаза Combiner
Фаза Combiner берет каждую пару ключ-значение из фазы Map, обрабатывает ее и создает выходные данные в виде пар набора ключ-значение .
Ввод — следующая пара ключ-значение является вводом, взятым из фазы карты.
<What,1> <do,1> <you,1> <mean,1> <by,1> <Object,1> <What,1> <do,1> <you,1> <know,1> <about,1> <Java,1> <What,1> <is,1> <Java,1> <Virtual,1> <Machine,1> <How,1> <Java,1> <enabled,1> <High,1> <Performance,1>
Фаза Combiner считывает каждую пару ключ-значение, объединяет общие слова как ключ и значения как коллекцию. Как правило, код и работа для Combiner аналогичны таковым для Reducer. Ниже приведен фрагмент кода для объявления классов Mapper, Combiner и Reducer.
job.setMapperClass(TokenizerMapper.class); job.setCombinerClass(IntSumReducer.class); job.setReducerClass(IntSumReducer.class);
Вывод — ожидаемый вывод выглядит следующим образом —
<What,1,1,1> <do,1,1> <you,1,1> <mean,1> <by,1> <Object,1> <know,1> <about,1> <Java,1,1,1> <is,1> <Virtual,1> <Machine,1> <How,1> <enabled,1> <High,1> <Performance,1>
Фаза редуктора
Фаза редуктора берет каждую пару сбора ключ-значение из фазы Combiner, обрабатывает ее и передает выходные данные в виде пар ключ-значение. Обратите внимание, что функциональность Combiner такая же, как и у Reducer.
Вход — следующая пара ключ-значение является входом, взятым из фазы Combiner.
<What,1,1,1> <do,1,1> <you,1,1> <mean,1> <by,1> <Object,1> <know,1> <about,1> <Java,1,1,1> <is,1> <Virtual,1> <Machine,1> <How,1> <enabled,1> <High,1> <Performance,1>
Фаза редуктора считывает каждую пару ключ-значение. Ниже приведен фрагмент кода для Combiner.
public static class IntSumReducer extends Reducer<Text,IntWritable,Text,IntWritable> { private IntWritable result = new IntWritable(); public void reduce(Text key, Iterable<IntWritable> values,Context context) throws IOException, InterruptedException { int sum = 0; for (IntWritable val : values) { sum += val.get(); } result.set(sum); context.write(key, result); } }
Выходные данные — ожидаемый выходной сигнал от фазы редуктора следующий —
<What,3> <do,2> <you,2> <mean,1> <by,1> <Object,1> <know,1> <about,1> <Java,3> <is,1> <Virtual,1> <Machine,1> <How,1> <enabled,1> <High,1> <Performance,1>
Record Writer
Это последняя фаза MapReduce, где Record Writer записывает каждую пару ключ-значение из фазы Reducer и отправляет вывод в виде текста.
Ввод — каждая пара ключ-значение из фазы редуктора вместе с форматом вывода.
Вывод — он дает вам пары ключ-значение в текстовом формате. Ниже приводится ожидаемый результат.
What 3 do 2 you 2 mean 1 by 1 Object 1 know 1 about 1 Java 3 is 1 Virtual 1 Machine 1 How 1 enabled 1 High 1 Performance 1
Пример программы
Следующий блок кода подсчитывает количество слов в программе.
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount {
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable>
{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context) throws IOException, InterruptedException
{
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens())
{
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer extends Reducer<Text,IntWritable,Text,IntWritable>
{
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException
{
int sum = 0;
for (IntWritable val : values)
{
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception
{
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
Сохраните вышеуказанную программу как WordCount.java . Компиляция и выполнение программы приведены ниже.
Компиляция и выполнение
Предположим, мы находимся в домашнем каталоге пользователя Hadoop (например, / home / hadoop).
Следуйте инструкциям ниже, чтобы скомпилировать и выполнить вышеуказанную программу.
Шаг 1 — Используйте следующую команду, чтобы создать каталог для хранения скомпилированных классов Java.
$ mkdir units
Шаг 2 — Загрузите Hadoop-core-1.2.1.jar, который используется для компиляции и выполнения программы MapReduce. Вы можете скачать банку с mvnrepository.com .
Давайте предположим, что загруженная папка — / home / hadoop /.
Шаг 3 — Используйте следующие команды для компиляции программы WordCount.java и для создания jar для программы.
$ javac -classpath hadoop-core-1.2.1.jar -d units WordCount.java $ jar -cvf units.jar -C units/ .
Шаг 4 — Используйте следующую команду для создания входного каталога в HDFS.
$HADOOP_HOME/bin/hadoop fs -mkdir input_dir
Шаг 5 — Используйте следующую команду, чтобы скопировать входной файл с именем input.txt во входной каталог HDFS.
$HADOOP_HOME/bin/hadoop fs -put /home/hadoop/input.txt input_dir
Шаг 6 — Используйте следующую команду, чтобы проверить файлы во входном каталоге.
$HADOOP_HOME/bin/hadoop fs -ls input_dir/
Шаг 7 — Используйте следующую команду, чтобы запустить приложение Word count, взяв входные файлы из входного каталога.
$HADOOP_HOME/bin/hadoop jar units.jar hadoop.ProcessUnits input_dir output_dir
Подождите некоторое время, пока файл не запустится. После выполнения выходные данные содержат несколько входных разбиений, задачи Map и задачи Reducer.
Шаг 8 — Используйте следующую команду для проверки результирующих файлов в выходной папке.
$HADOOP_HOME/bin/hadoop fs -ls output_dir/
Шаг 9 — Используйте следующую команду, чтобы увидеть выходные данные в файле Part-00000 . Этот файл создан HDFS.
$HADOOP_HOME/bin/hadoop fs -cat output_dir/part-00000
Ниже приводится вывод, сгенерированный программой MapReduce.
What 3 do 2 you 2 mean 1 by 1 Object 1 know 1 about 1 Java 3 is 1 Virtual 1 Machine 1 How 1 enabled 1 High 1 Performance 1
MapReduce — Администрирование Hadoop
В этой главе описывается администрирование Hadoop, которое включает администрирование HDFS и MapReduce.
-
Администрирование HDFS включает в себя мониторинг файловой структуры HDFS, расположения и обновленных файлов.
-
Администрирование MapReduce включает мониторинг списка приложений, конфигурации узлов, состояния приложений и т. Д.
Администрирование HDFS включает в себя мониторинг файловой структуры HDFS, расположения и обновленных файлов.
Администрирование MapReduce включает мониторинг списка приложений, конфигурации узлов, состояния приложений и т. Д.
HDFS мониторинг
HDFS (распределенная файловая система Hadoop) содержит пользовательские каталоги, входные и выходные файлы. Используйте команды MapReduce, put и get, для хранения и извлечения.
После запуска инфраструктуры Hadoop (демонов), передав команду «start-all.sh» в «/ $ HADOOP_HOME / sbin», передайте следующий URL-адрес в браузер «http: // localhost: 50070». Вы должны увидеть следующий экран в вашем браузере.
На следующем снимке экрана показано, как просматривать HDFS.
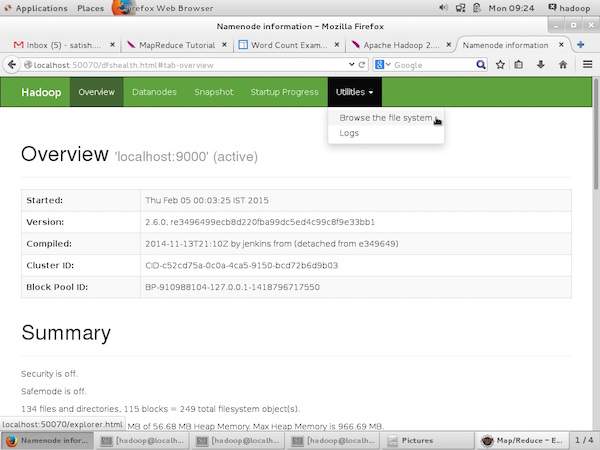
На следующем снимке экрана показана файловая структура HDFS. Он показывает файлы в каталоге «/ user / hadoop».
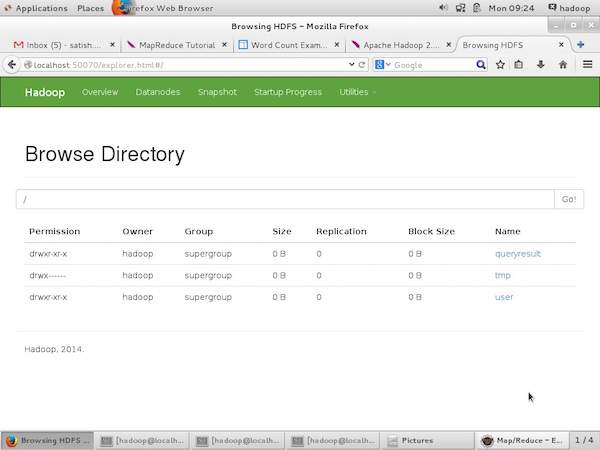
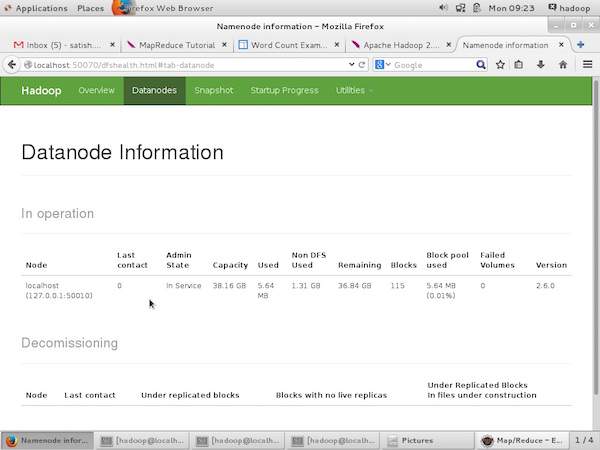
На следующем снимке экрана показана информация Datanode в кластере. Здесь вы можете найти один узел с его конфигурациями и возможностями.
MapReduce Job Monitoring
Приложение MapReduce представляет собой набор заданий (задание Map, Combiner, Partitioner и Reduce job). Обязательно следить и поддерживать следующее —
- Конфигурация датододы, где приложение подходит.
- Количество датододов и ресурсов, используемых в приложении.
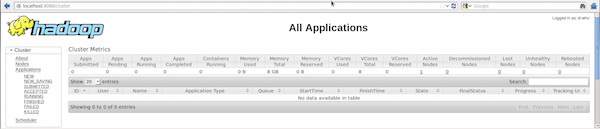
Чтобы контролировать все эти вещи, обязательно, чтобы у нас был пользовательский интерфейс. После запуска инфраструктуры Hadoop, передав команду «start-all.sh» в «/ $ HADOOP_HOME / sbin», передайте следующий URL-адрес в браузер «http: // localhost: 8080». Вы должны увидеть следующий экран в вашем браузере.
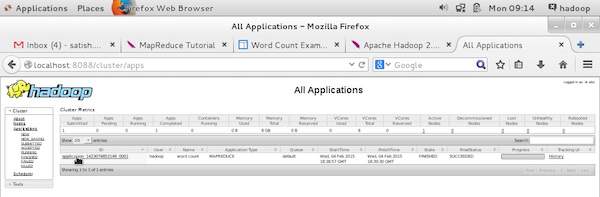
На приведенном выше снимке экрана указатель руки находится на идентификаторе приложения. Просто нажмите на него, чтобы найти следующий экран в вашем браузере. Это описывает следующее —
-
На каком пользователе запущено текущее приложение
-
Название приложения
-
Тип этого приложения
-
Текущий статус, Финальный статус
-
Время запуска приложения, прошедшее (завершенное время), если оно завершено во время мониторинга
-
История этого приложения, т.е. информация журнала
-
И, наконец, информация об узлах, т. Е. Об узлах, которые участвовали в запуске приложения.
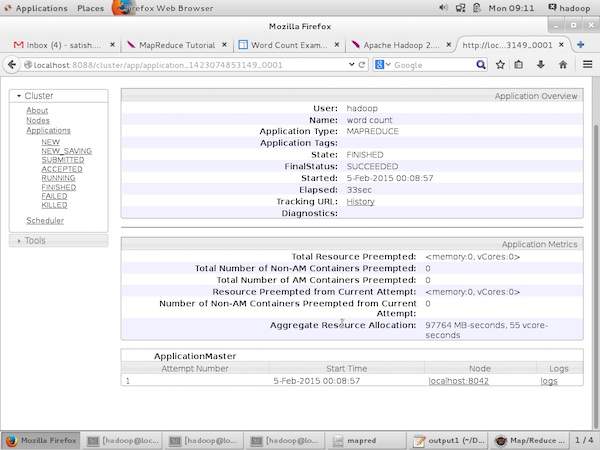
На каком пользователе запущено текущее приложение
Название приложения
Тип этого приложения
Текущий статус, Финальный статус
Время запуска приложения, прошедшее (завершенное время), если оно завершено во время мониторинга
История этого приложения, т.е. информация журнала
И, наконец, информация об узлах, т. Е. Об узлах, которые участвовали в запуске приложения.
На следующем снимке экрана показаны детали конкретного приложения.
На следующем снимке экрана показана информация о запущенных узлах. Здесь скриншот содержит только один узел. Указатель руки показывает адрес локального хоста работающего узла.