Что такое индекс?
Индекс — это ключ, построенный из одного или нескольких столбцов в базе данных, который ускоряет выборку строк из таблицы или представления. Этот ключ помогает базе данных, такой как Oracle, SQL Server, MySQL и т. Д., Быстро найти строку, связанную со значениями ключа.
Два типа индексов:
- Кластерный индекс
- Некластерный индекс
В этом уроке вы узнаете:
- Что такое индекс?
- Что такое кластерный индекс?
- Что такое некластеризованный индекс?
- Характеристика кластерного индекса
- Характеристики некластеризованных индексов
- Пример кластерного индекса
- Пример некластеризованного индекса
- Различия между кластерным индексом и некластеризованным индексом
- Преимущества кластерного индекса
- Преимущества некластеризованного индекса
- Недостатки кластерного индекса
- Недостатки некластеризованного индекса
Что такое кластерный индекс?
Индекс кластера — это тип индекса, который сортирует строки данных в таблице по их ключевым значениям. В базе данных существует только один кластеризованный индекс на таблицу.
Кластерный индекс определяет порядок, в котором данные хранятся в таблице и могут быть отсортированы только одним способом. Таким образом, для каждой таблицы может быть только один кластеризованный индекс. В РСУБД, как правило, первичный ключ позволяет создавать кластерный индекс на основе этого конкретного столбца.
Что такое некластеризованный индекс?
Некластеризованный индекс хранит данные в одном месте и индексы в другом месте. Индекс содержит указатели на местоположение этих данных. Одна таблица может иметь много некластеризованных индексов, поскольку индекс в некластеризованном индексе хранится в разных местах.
Например, книга может иметь более одного индекса, один в начале, который отображает содержание книги, а второй индекс показывает индекс терминов в алфавитном порядке.
Некластеризованный индекс определяется в неупорядоченном поле таблицы. Этот тип метода индексации помогает повысить производительность запросов, использующих ключи, которые не назначены в качестве первичного ключа. Некластеризованный индекс позволяет добавить уникальный ключ для таблицы.
Характеристика кластерного индекса
- Стандартное и отсортированное хранилище данных
- Используйте только один или несколько столбцов для индекса
- Помогает хранить данные и индексировать вместе
- фрагментация
- операции
- Сканирование кластеризованного индекса и поиск индекса
- Поиск ключей
Характеристики некластеризованных индексов
- Хранить только значения ключей
- Указатели на строки кучи / кластерного индекса
- Позволяет вторичный доступ к данным
- Мост к данным
- Операции сканирования индекса и поиска индекса
- Вы можете создать некластеризованный индекс для таблицы или представления
- Каждая строка индекса в некластеризованном индексе хранит значение некластеризованного ключа и локатор строк.
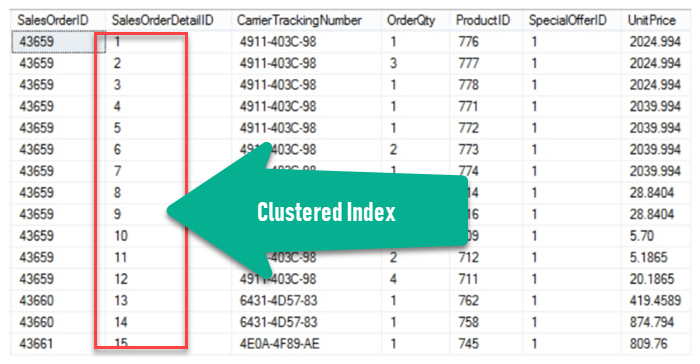
Пример кластерного индекса
В приведенном ниже примере SalesOrderDetailID является кластеризованным индексом. Пример запроса для получения данных
SELECT CarrierTrackingNumber, UnitPrice FROM SalesData WHERE SalesOrderDetailID = 6
Пример некластеризованного индекса
В следующем примере некластеризованный индекс создается для OrderQty и ProductID следующим образом
CREATE INDEX myIndex ON SalesData (ProductID, OrderQty)
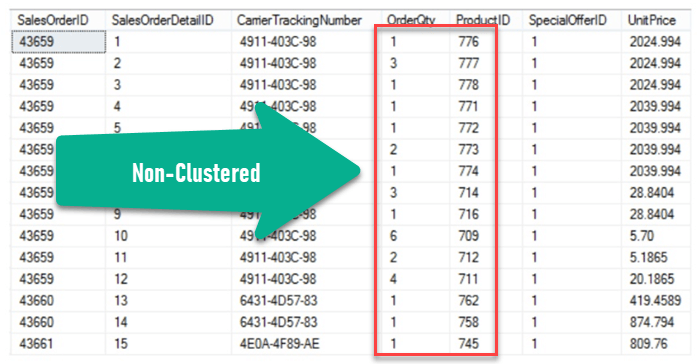
Следующий запрос будет получен быстрее по сравнению с кластерным индексом.
SELECT Product ID, OrderQty FROM SalesData WHERE ProductID = 714

Различия между кластерным индексом и некластеризованным индексом

| параметры | кластерный | Некластерированных |
|---|---|---|
| Использовать для | Вы можете сортировать записи и физически хранить кластерный индекс в памяти в соответствии с порядком. | Некластеризованный индекс помогает вам создать логический порядок для строк данных и использует указатели для физических файлов данных. |
| Метод хранения | Позволяет хранить страницы данных в конечных узлах индекса. | Этот метод индексации никогда не сохраняет страницы данных в конечных узлах индекса. |
| Размер | Размер кластерного индекса довольно велик. | Размер некластеризованного индекса невелик по сравнению с кластеризованным индексом. |
| Доступ к данным | Быстрее | Медленнее по сравнению с кластерным индексом |
| Дополнительное дисковое пространство | Не требуется | Требуется хранить индекс отдельно |
| Тип ключа | По умолчанию первичные ключи таблицы являются кластерным индексом. | Его можно использовать с уникальным ограничением на таблицу, которое действует как составной ключ. |
| Главная особенность | Кластерный индекс может повысить производительность поиска данных. | Он должен быть создан на столбцах, которые используются в соединениях. |
Преимущества кластерного индекса
Плюсы / преимущества кластерного индекса:
- Кластерные индексы являются идеальным вариантом для диапазона или группы с запросами типа max, min, count
- В этом типе индекса поиск может идти прямо к определенной точке данных, чтобы вы могли продолжать последовательное чтение оттуда.
- Метод кластеризованного индекса использует механизм определения местоположения для определения позиции индекса в начале диапазона.
- Это эффективный метод для поиска диапазона, когда запрашивается диапазон значений ключа поиска.
- Помогает минимизировать передачу страниц и максимизировать попадания в кэш.
Преимущества некластеризованного индекса
Плюсы использования некластеризованного индекса:
- Некластеризованный индекс помогает быстро получать данные из таблицы базы данных.
- Помогает избежать накладных расходов, связанных с кластерным индексом
- Таблица может иметь несколько некластеризованных индексов в РСУБД. Таким образом, его можно использовать для создания более одного индекса.
Недостатки кластерного индекса
Вот минусы / недостатки использования кластерного индекса:
- Много вставок в непоследовательном порядке
- Кластерный индекс создает множество постоянных разбиений страниц, включая страницы данных и страницы индекса.
- Дополнительная работа для SQL для вставки, обновления и удаления.
- Кластерный индекс занимает больше времени для обновления записей при изменении полей в кластерном индексе.
- Конечные узлы в основном содержат страницы данных в кластерном индексе.
Недостатки некластеризованного индекса
Вот минусы / недостатки использования некластеризованного индекса:
- Некластеризованный индекс помогает хранить данные в логическом порядке, но не позволяет сортировать строки данных физически.
- Процесс поиска по некластеризованному индексу становится дорогостоящим.
- Каждый раз, когда ключ кластеризации обновляется, требуется соответствующее обновление для некластеризованного индекса, поскольку он хранит ключ кластеризации.
КЛЮЧЕВАЯ РАЗНИЦА
- Кластерный индекс — это тип индекса, который сортирует строки данных в таблице по их ключевым значениям, тогда как некластеризованный индекс хранит данные в одном месте и индексы в другом месте.
- Кластерный индекс хранит страницы данных в конечных узлах индекса, в то время как метод некластеризованного индекса никогда не сохраняет страницы данных в конечных узлах индекса.
- Кластерный индекс не требует дополнительного дискового пространства, тогда как некластеризованный индекс требует дополнительного дискового пространства.
- Кластерный индекс предлагает более быстрый доступ к данным, с другой стороны, некластеризованный индекс медленнее.