Что такое хеширование в СУБД?
В СУБД хеширование — это метод прямого поиска местоположения нужных данных на диске без использования структуры индекса. Данные хранятся в форме блоков данных, адрес которых генерируется путем применения хеш-функции в ячейке памяти, где хранятся эти записи, известной как блок данных или блок данных .
В этом уроке по СУБД вы узнаете,
- Что такое техника хеширования в СУБД?
- Зачем нам хеширование?
- Важные термины, используемые в хешировании
- Хеширование статики:
- Открытое Хеширование
- Динамическое хеширование
- Сравнение упорядоченного индексирования и хеширования
- Что такое Столкновение?
- Как бороться с Hashing Collision?
Зачем нам хеширование?
Вот ситуации в СУБД, где вам нужно применить метод хеширования:
- Для огромной структуры базы данных сложно выполнить поиск всех значений индекса по всему его уровню, а затем вам нужно добраться до целевого блока данных, чтобы получить нужные данные.
- Метод хеширования используется для индексации и извлечения элементов в базе данных, поскольку более быстрый поиск этого конкретного элемента выполняется с использованием более короткого хешированного ключа вместо использования его исходного значения.
- Хеширование является идеальным методом для вычисления прямого расположения записи данных на диске без использования структуры индекса.
- Это также полезный метод для реализации словарей.
Важные термины, используемые в хешировании
Здесь приведены важные термины, которые используются в хешировании:
- Контейнер данных — Контейнеры данных — это области памяти, в которых хранятся записи. Это также известно как Единица Хранения.
- Ключ : ключ СУБД — это атрибут или набор атрибутов, которые помогают идентифицировать строку (кортеж) в отношении (таблице). Это позволяет найти связь между двумя таблицами.
- Хеш-функция : хеш-функция — это функция отображения, которая отображает весь набор ключей поиска на адрес, на котором размещены фактические записи.
- Линейное зондирование — Линейное зондирование — это фиксированный интервал между зондами. В этом методе следующий доступный блок данных используется для ввода новой записи вместо перезаписи более старой записи.
- Квадратичное зондирование — помогает определить новый адрес корзины. Это поможет вам добавить интервал между датчиками, добавив последовательный вывод квадратичного полинома к начальному значению, заданному исходным вычислением.
- Индекс хеша — это адрес блока данных. Хеш-функция может быть простой математической функцией даже сложной математической функции.
- Двойное хеширование — двойное хеширование — это метод компьютерного программирования, используемый в хеш-таблицах для разрешения проблем, связанных с коллизиями.
- Переполнение корзины : условие переполнения корзины называется столкновением. Это смертельная стадия для любой статики, которая должна функционировать.
Существует в основном два типа методов хеширования SQL:
- Статическое хеширование
- Динамическое хеширование
Статическое хеширование
При статическом хешировании результирующий адрес блока данных всегда будет оставаться неизменным.
Следовательно, если вы сгенерируете адрес, скажем Student_ID = 10, используя хеш-функцию mod (3) , результирующий адрес сегмента всегда будет равен 1 . Таким образом, вы не увидите никаких изменений в адресе корзины.
Следовательно, в этом методе статического хеширования количество сегментов данных в памяти всегда остается постоянным.
Статические хэш-функции
- Вставка записи : когда новую запись необходимо вставить в таблицу, вы можете сгенерировать адрес для новой записи, используя ее хэш-ключ. Когда адрес генерируется, запись автоматически сохраняется в этом месте.
- Поиск : когда вам нужно извлечь запись, та же хеш-функция должна быть полезна для получения адреса корзины, в которой должны храниться данные.
- Удалить запись : Используя хеш-функцию, вы можете сначала получить запись, которую вы хотите удалить. Затем вы можете удалить записи для этого адреса в памяти.
Статическое хеширование далее делится на
- Открытое хеширование
- Закрыть хеширование.
Открытое Хеширование
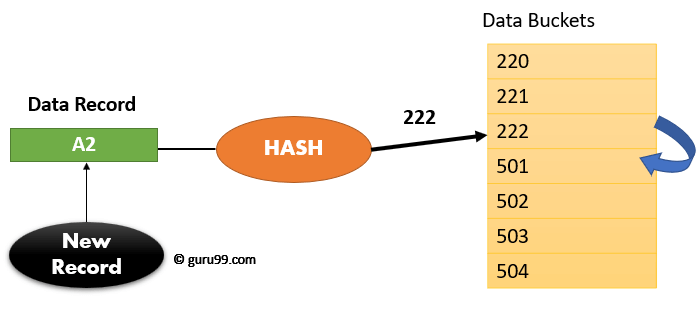
В методе открытого хеширования, вместо перезаписи старого, для ввода новой записи используется следующий доступный блок данных. Этот метод также известен как линейное зондирование.
Например, A2 — это новая запись, которую вы хотите вставить. Хеш-функция генерирует адрес как 222. Но он уже занят каким-то другим значением. Вот почему система ищет следующий блок 501 данных и назначает ему A2.
Закрыть Хеширование
В методе закрытого хеширования, когда сегменты заполнены, новый блок выделяется для того же хэша, и результат связывается после предыдущего.
Динамическое хеширование
Динамическое хеширование предлагает механизм, в котором корзины данных добавляются и удаляются динамически и по требованию. В этом хешировании хеш-функция помогает вам создавать большое количество значений.
Сравнение упорядоченного индексирования и хеширования
| параметры | Индексирование заказа | Хэш |
| Хранение адреса | Адреса в памяти сортируются в соответствии со значением ключа, называемым первичным ключом | Адреса всегда генерируются с использованием хеш-функции на значении ключа. |
| Представление | Это может уменьшиться, когда данные увеличиваются в хэш-файле. Поскольку он хранит данные в отсортированном виде, когда выполняется какая-либо операция (вставка / удаление / обновление), которая снижает ее производительность. | Производительность хеширования будет наилучшей, когда происходит постоянное добавление и удаление данных. Однако, когда база данных огромна, организация хэш-файлов и ее обслуживание будут более дорогостоящими. |
| Использовать для | Предпочтителен для извлечения данных из диапазона — это означает, что при наличии данных для поиска в определенном диапазоне этот метод является идеальным вариантом. | Это идеальный метод, когда вы хотите получить определенную запись на основе ключа поиска. Тем не менее, он будет работать хорошо только тогда, когда хеш-функция находится на ключе поиска. |
| Управление памятью | Из-за операции удаления / обновления будет много неиспользуемых блоков данных. Эти блоки данных не могут быть освобождены для повторного использования. Вот почему регулярное обслуживание памяти не требуется. | В статических и динамических методах хеширования память всегда управляется. Переполнение ведра также отлично обрабатывается для расширения статического хеширования. |
Что такое Столкновение?
Хеш-коллизия — это состояние, когда результирующие хеши из двух или более данных в наборе данных ошибочно отображают одно и то же место в хеш-таблице.
Как бороться с Hashing Collision?
Есть две техники, которые вы можете использовать, чтобы избежать коллизии хеша:
- Перефразирование : этот метод вызывает вторичную хеш-функцию, которая применяется непрерывно, пока не будет найден пустой слот, где должна быть размещена запись.
- Цепочка : метод цепочки строит связанный список элементов, ключ которых хэширует одно и то же значение. Этот метод требует дополнительного поля ссылки для каждой позиции таблицы.
Резюме:
- В СУБД хеширование — это метод прямого поиска местоположения нужных данных на диске без использования структуры индекса.
- Метод хеширования используется для индексации и извлечения элементов в базе данных, поскольку более быстрый поиск этого конкретного элемента выполняется с использованием более короткого хешированного ключа вместо использования его исходного значения.
- Ведро данных, ключ, функция хеширования, линейное зондирование, квадратичное зондирование, хэш-индекс, двойное хеширование, переполнение ведра — важные термины, используемые при хешировании
- Два типа методов хеширования: 1) статическое хеширование 2) динамическое хеширование
- При статическом хешировании результирующий адрес блока данных всегда будет оставаться неизменным.
- Динамическое хеширование предлагает механизм, в котором корзины данных добавляются и удаляются динамически и по требованию.
- Порядок индексирования адресов в памяти сортируется в соответствии с критическим значением, тогда как при хешировании адреса всегда генерируются с использованием хеш-функции для значения ключа.
- Хеш-коллизия — это состояние, когда результирующие хеши из двух или более данных в наборе данных ошибочно отображают одно и то же место в хеш-таблице.
- Перефразировка и сцепление — это два метода, которые помогут вам избежать столкновения хэширования.