Что такое индексирование?
INDEXING — это метод структуры данных, который позволяет вам быстро извлекать записи из файла базы данных. Индекс — это небольшая таблица, имеющая всего два столбца. Первый столбец содержит копию первичного или потенциального ключа таблицы. Его второй столбец содержит набор указателей для хранения адреса дискового блока, где хранится это конкретное значение ключа.
Индекс —
- Принимает ключ поиска в качестве ввода
- Эффективно возвращает коллекцию совпадающих записей.
Из этого руководства по индексированию СУБД вы узнаете:
- Типы индексации
- Первичная индексация
- Вторичный индекс
- Индекс кластеризации
- Что такое многоуровневый индекс?
- B-Tree Index
- Преимущества индексации
- Недостатки индексации
Типы индексации
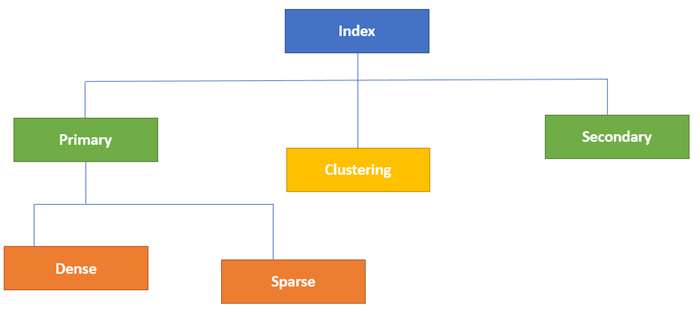
Индексация базы данных определяется на основе ее атрибутов индексации. Два основных типа методов индексации:
- Первичная индексация
- Вторичная индексация
Первичная индексация
Первичный индекс — это упорядоченный файл с фиксированной длиной и двумя полями. Первое поле — это тот же первичный ключ, а второе поле указывает на этот конкретный блок данных. В первичном индексе всегда существует отношение один к одному между записями в таблице индекса.
Первичная индексация также делится на два типа.
- Плотный индекс
- Разреженный индекс
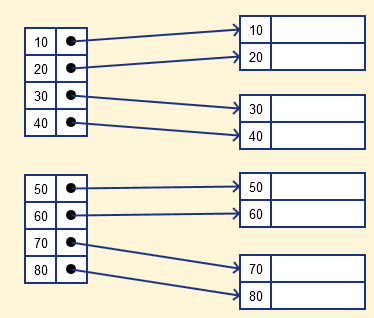
Плотный индекс
В плотном индексе запись создается для каждого поискового ключа, оцененного в базе данных. Это помогает быстрее выполнять поиск, но требует больше места для хранения записей индекса. В этом индексировании записи метода содержат значение ключа поиска и указывают на реальную запись на диске.
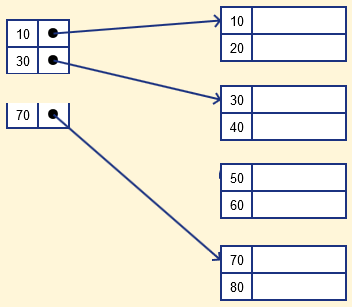
Разреженный индекс
Это индексная запись, которая отображается только для некоторых значений в файле. Разреженный индекс поможет вам решить проблемы плотного индексирования. В этом методе методики индексирования диапазон столбцов индекса хранит один и тот же адрес блока данных, и когда данные должны быть извлечены, адрес блока будет выбран.
Однако разреженный индекс хранит записи индекса только для некоторых значений ключа поиска. Ему требуется меньше места, меньше затрат на обслуживание для вставки и удаления, но он медленнее по сравнению с плотным индексом для поиска записей.
Пример разреженного индекса
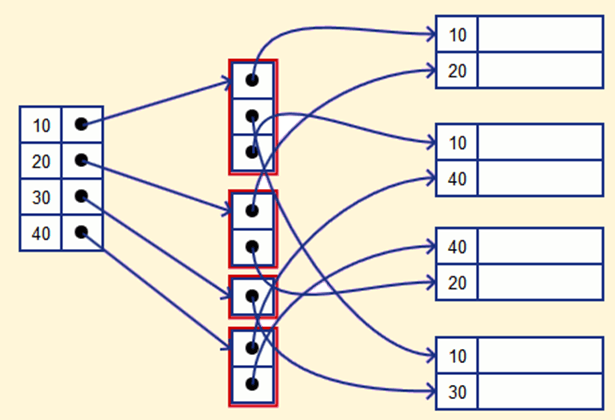
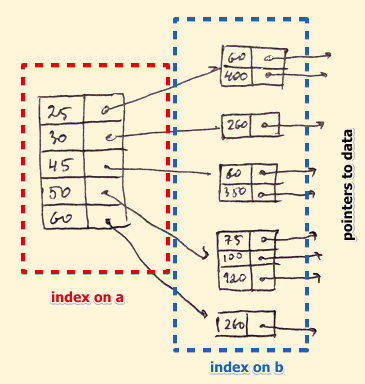
Вторичный индекс
Вторичный индекс может быть создан с помощью поля, которое имеет уникальное значение для каждой записи, и это должен быть ключ-кандидат. Он также известен как некластеризованный индекс.
Этот двухуровневый метод индексации базы данных используется для уменьшения размера отображения первого уровня. Для первого уровня из-за этого выбирается большой диапазон чисел; размер отображения всегда остается небольшим.
Пример вторичной индексации
В базе данных банковского счета данные хранятся последовательно с помощью acc_no; Вы можете найти все счета в конкретном отделении банка ABC.
Здесь вы можете иметь вторичный индекс для каждого поискового ключа. Индексная запись — это точка записи в корзину, которая содержит указатели на все записи с определенным значением ключа поиска.
Индекс кластеризации
В кластеризованном индексе сами записи хранятся в индексе, а не в указателях. Иногда индекс создается для столбцов не первичного ключа, которые могут быть не уникальными для каждой записи. В такой ситуации вы можете сгруппировать два или более столбцов, чтобы получить уникальные значения и создать индекс, который называется кластеризованным индексом. Это также поможет вам быстрее идентифицировать запись.
Пример:
Давайте предположим, что компания набрала много сотрудников в различных отделах. В этом случае кластерная индексация должна быть создана для всех сотрудников, принадлежащих к одному отделу.
Он рассматривается в одном кластере, а индексные точки указывают на кластер в целом. Здесь Department _no — неуникальный ключ.
Что такое многоуровневый индекс?
Многоуровневое индексирование создается, когда первичный индекс не помещается в памяти. В этом методе индексации вы можете сократить число обращений к диску, чтобы сократить любую запись и сохранить ее на диске в виде последовательного файла, а также создать разреженную базу для этого файла.
B-Tree Index
Индекс B-дерева — это широко используемые структуры данных для индексации. Это метод многоуровневого индексного формата, который сбалансирован бинарными деревьями поиска. Все конечные узлы дерева B обозначают фактические указатели данных.
Более того, все конечные узлы связаны между собой списком ссылок, что позволяет дереву B поддерживать как произвольный, так и последовательный доступ.
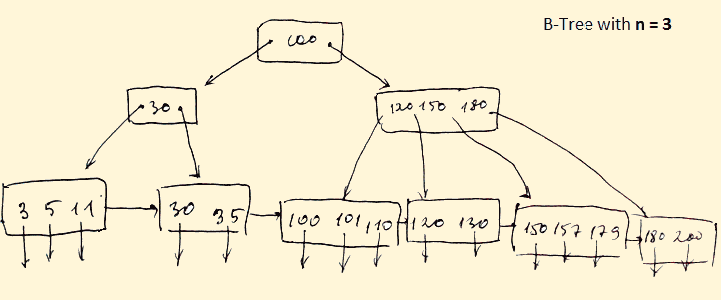
- Ведущие узлы должны иметь от 2 до 4 значений.
- Каждый путь от корня до листа в основном одинаковой длины.
- Нелистовые узлы, кроме корневого, имеют от 3 до 5 дочерних узлов.
- Каждый узел, который не является корнем или листом, имеет от n / 2] до n дочерних узлов.
Преимущества индексации
Важные плюсы / преимущества индексирования:
- Это помогает сократить общее количество операций ввода-вывода, необходимых для извлечения этих данных, поэтому вам не нужно обращаться к строке в базе данных из структуры индекса.
- Предлагает более быстрый поиск и поиск данных для пользователей.
- Индексирование также помогает сократить табличное пространство, поскольку вам не нужно ссылаться на строку в таблице, поскольку нет необходимости хранить ROWID в индексе. Таким образом вы сможете уменьшить табличное пространство.
- Вы не можете сортировать данные в ведущих узлах, так как значение первичного ключа классифицирует их.
Недостатки индексации
Важными недостатками / минусами индексации являются:
- Для выполнения системы управления базами данных индексирования вам необходим первичный ключ в таблице с уникальным значением.
- Вы не можете выполнять какие-либо другие индексы для проиндексированных данных.
- Вам не разрешено разбивать организованную по индексу таблицу.
- Индексирование SQL Снижение производительности в запросах INSERT, DELETE и UPDATE.
Резюме:
- Индексирование — это небольшая таблица, состоящая из двух столбцов.
- Два основных типа методов индексации: 1) первичная индексация 2) вторичная индексация.
- Первичный индекс — это упорядоченный файл с фиксированной длиной и двумя полями.
- Первичная индексация также делится на два типа: 1) плотный индекс 2) разреженный индекс.
- В плотном индексе запись создается для каждого поискового ключа, оцененного в базе данных.
- Метод разреженной индексации помогает решить проблемы плотной индексации.
- Вторичный индекс — это метод индексации, ключ поиска которого определяет порядок, отличный от последовательного порядка файла.
- Индекс кластеризации определяется как файл данных заказа.
- Многоуровневое индексирование создается, когда первичный индекс не помещается в памяти.
- Самым большим преимуществом индексирования является то, что оно помогает вам сократить общее количество операций ввода-вывода, необходимых для извлечения этих данных.
- Самый большой недостаток для выполнения системы управления базами данных индексации, вам нужен первичный ключ в таблице с уникальным значением.