SAP HANA — Обзор
SAP HANA представляет собой комбинацию базы данных HANA, моделирования данных, администрирования HANA и предоставления данных в одном пакете. В SAP HANA HANA обозначает высокопроизводительное аналитическое устройство.
По словам бывшего руководителя SAP д-ра Вишала Сикки, HANA означает новую архитектуру Hasso. К середине 2011 года интерес к HANA возрос, и различные компании из списка Fortune 500 начали рассматривать его как вариант для удовлетворения потребностей Business Warehouse после этого.
Особенности SAP HANA
Основные характеристики SAP HANA приведены ниже —
-
SAP HANA — это комбинация программных и аппаратных инноваций для обработки огромного количества данных в реальном времени.
-
Основан на многоядерной архитектуре в среде распределенных систем.
-
На основе типа строки и столбца хранения данных в базе данных.
-
Широко используется в Memory Computing Engine (IMCE) для обработки и анализа огромного количества данных в реальном времени.
-
Это снижает стоимость владения, повышает производительность приложений, позволяет новым приложениям работать в среде реального времени, что было невозможно раньше.
-
Он написан на C ++, поддерживает и работает только на одной операционной системе Suse Linux Enterprise Server 11 SP1 / 2.
SAP HANA — это комбинация программных и аппаратных инноваций для обработки огромного количества данных в реальном времени.
Основан на многоядерной архитектуре в среде распределенных систем.
На основе типа строки и столбца хранения данных в базе данных.
Широко используется в Memory Computing Engine (IMCE) для обработки и анализа огромного количества данных в реальном времени.
Это снижает стоимость владения, повышает производительность приложений, позволяет новым приложениям работать в среде реального времени, что было невозможно раньше.
Он написан на C ++, поддерживает и работает только на одной операционной системе Suse Linux Enterprise Server 11 SP1 / 2.
Потребность в SAP HANA
Сегодня большинство успешных компаний быстро реагируют на изменения рынка и новые возможности. Ключом к этому является эффективное и действенное использование данных и информации аналитиками и менеджерами.
HANA преодолевает ограничения, указанные ниже —
-
В связи с увеличением «объема данных» компаниям сложно обеспечить доступ к данным в реальном времени для анализа и использования в бизнесе.
-
Это связано с высокими затратами на обслуживание ИТ-компаний для хранения и обслуживания больших объемов данных.
-
Из-за недоступности данных в реальном времени результаты анализа и обработки задерживаются.
В связи с увеличением «объема данных» компаниям сложно обеспечить доступ к данным в реальном времени для анализа и использования в бизнесе.
Это связано с высокими затратами на обслуживание ИТ-компаний для хранения и обслуживания больших объемов данных.
Из-за недоступности данных в реальном времени результаты анализа и обработки задерживаются.
SAP HANA Продавцы
SAP сотрудничает с ведущими поставщиками ИТ-оборудования, такими как IBM, Dell, Cisco и т. Д., И объединила их с лицензионными услугами и технологиями SAP для продажи платформы SAP HANA.
Всего существует 11 поставщиков, которые производят устройства HANA и предоставляют поддержку на месте для установки и настройки системы HANA.
Лучшие несколько поставщиков включают в себя —
- IBM
- Dell
- HP
- Cisco
- Fujitsu
- Lenovo (Китай)
- NEC
- Huawei
Согласно статистике, предоставленной SAP, IBM является одним из основных поставщиков аппаратных устройств SAP HANA и имеет долю рынка 50-52%, но согласно другому исследованию рынка, проведенному клиентами HANA, IBM удерживает долю рынка до 70%.
Установка SAP HANA
Поставщики оборудования HANA предоставляют предварительно сконфигурированные устройства для оборудования, операционной системы и программного продукта SAP.
Поставщик завершает установку, устанавливая и настраивая компоненты HANA на месте. Это посещение на месте включает развертывание системы HANA в центре обработки данных, подключение к сети организации, адаптацию идентификатора системы SAP, обновления из Solution Manager, подключение к маршрутизатору SAP, включение SSL и другие настройки системы.
Клиент / клиент начинается с подключения системы источника данных и клиентов BI. Установка HANA Studio завершена в локальной системе, и добавлена система HANA для моделирования данных и администрирования.
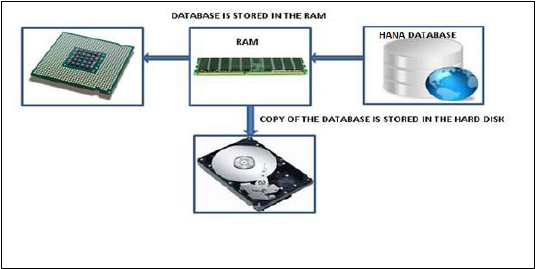
SAP HANA — вычислительная машина в памяти
База данных In-Memory означает, что все данные из исходной системы хранятся в оперативной памяти. В обычной системе базы данных все данные хранятся на жестком диске. База данных SAP HANA In-Memory не тратит время на загрузку данных с жесткого диска в оперативную память. Он обеспечивает более быстрый доступ к данным многоядерных процессоров для обработки и анализа информации.
Особенности базы данных в памяти
Основные характеристики базы данных SAP HANA в памяти:
-
SAP HANA — это гибридная база данных в памяти.
-
Он сочетает в себе технологию строк, столбцов и объектно-ориентированных технологий.
-
Он использует параллельную обработку с многоядерной архитектурой процессора.
-
Обычная база данных считывает данные памяти за 5 миллисекунд. База данных SAP HANA In-Memory считывает данные за 5 наносекунд.
SAP HANA — это гибридная база данных в памяти.
Он сочетает в себе технологию строк, столбцов и объектно-ориентированных технологий.
Он использует параллельную обработку с многоядерной архитектурой процессора.
Обычная база данных считывает данные памяти за 5 миллисекунд. База данных SAP HANA In-Memory считывает данные за 5 наносекунд.
Это означает, что чтения из памяти в базе данных HANA в 1 миллион раз быстрее, чем обычные операции чтения из жесткого диска базы данных.
Аналитики хотят видеть текущие данные немедленно в режиме реального времени и не хотят ждать, пока они будут загружены в систему SAP BW. Обработка SAP HANA In-Memory позволяет загружать данные в реальном времени с использованием различных методов предоставления данных.
Преимущества базы данных в памяти
-
База данных HANA использует преимущества обработки в памяти для обеспечения максимальной скорости извлечения данных, что привлекает компании, борющиеся с крупномасштабными онлайн-транзакциями или своевременным прогнозированием и планированием.
-
Дисковое хранилище по-прежнему является корпоративным стандартом, и цена оперативной памяти неуклонно снижается, поэтому архитектуры с интенсивным использованием памяти в конечном итоге заменят медленные диски с механическим вращением и снизят стоимость хранения данных.
-
Хранилище на основе столбцов в памяти обеспечивает сжатие данных до 11 раз, тем самым сокращая пространство хранения огромных данных.
-
Эти преимущества в скорости, предлагаемые системой хранения ОЗУ, дополнительно усиливаются за счет использования многоядерных процессоров, нескольких процессоров на узел и нескольких узлов на сервер в распределенной среде.
База данных HANA использует преимущества обработки в памяти для обеспечения максимальной скорости извлечения данных, что привлекает компании, борющиеся с крупномасштабными онлайн-транзакциями или своевременным прогнозированием и планированием.
Дисковое хранилище по-прежнему является корпоративным стандартом, и цена оперативной памяти неуклонно снижается, поэтому архитектуры с интенсивным использованием памяти в конечном итоге заменят медленные диски с механическим вращением и снизят стоимость хранения данных.
Хранилище на основе столбцов в памяти обеспечивает сжатие данных до 11 раз, тем самым сокращая пространство хранения огромных данных.
Эти преимущества в скорости, предлагаемые системой хранения ОЗУ, дополнительно усиливаются за счет использования многоядерных процессоров, нескольких процессоров на узел и нескольких узлов на сервер в распределенной среде.
SAP HANA — Студия
Студия SAP HANA — это инструмент на основе Eclipse. Студия SAP HANA является одновременно центральной средой разработки и основным инструментом администрирования системы HANA. Дополнительные функции —
-
Это клиентский инструмент, который можно использовать для доступа к локальной или удаленной системе HANA.
-
Он обеспечивает среду для администрирования HANA, информационного моделирования HANA и предоставления данных в базе данных HANA.
Это клиентский инструмент, который можно использовать для доступа к локальной или удаленной системе HANA.
Он обеспечивает среду для администрирования HANA, информационного моделирования HANA и предоставления данных в базе данных HANA.
SAP HANA Studio можно использовать на следующих платформах —
-
Microsoft Windows 32 и 64-разрядные версии: Windows XP, Windows Vista, Windows 7
-
SUSE Linux Enterprise Server SLES11: 64-разрядная версия x86
-
Mac OS, клиент HANA studio недоступен
Microsoft Windows 32 и 64-разрядные версии: Windows XP, Windows Vista, Windows 7
SUSE Linux Enterprise Server SLES11: 64-разрядная версия x86
Mac OS, клиент HANA studio недоступен
В зависимости от установки HANA Studio могут быть доступны не все функции. Во время установки Studio укажите функции, которые вы хотите установить в соответствии с ролью. Для работы с самой последней версией студии HANA для обновления клиента можно использовать Software Life Cycle Manager.
SAP HANA Studio Перспективы / Особенности
SAP HANA Studio предоставляет перспективы для работы со следующими функциями HANA. Вы можете выбрать Перспективу в HANA Studio из следующих опций —
HANA Studio → Окно → Открытая перспектива → Другое
Администрация студии Sap Hana
Набор инструментов для различных задач администрирования, за исключением переносимых объектов хранилища времени разработки. Общие инструменты устранения неполадок, такие как трассировка, браузер каталога и консоль SQL, также включены.
Разработка базы данных SAP HANA Studio
Он предоставляет набор инструментов для разработки контента. В частности, он касается сценариев DataMarts и ABAP в SAP HANA, которые не включают разработку собственных приложений SAP XANA (XS).
Разработка приложений SAP HANA Studio
Система SAP HANA содержит небольшой веб-сервер, который можно использовать для размещения небольших приложений. Он предоставляет набор инструментов для разработки собственных приложений SAP HANA, таких как код приложения, написанный на Java и HTML.
По умолчанию все функции установлены.
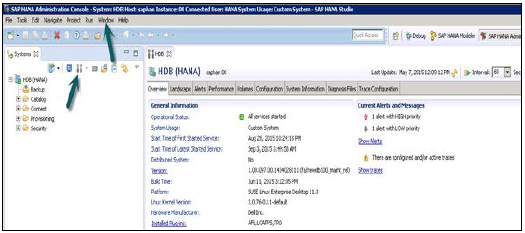
SAP HANA — представление администрирования студии
Для выполнения функций администрирования и мониторинга базы данных HANA можно использовать перспективу консоли администрирования SAP HANA.
Доступ к редактору администратора можно получить несколькими способами:
-
Из панели инструментов системного представления — выберите кнопку Открыть администрирование по умолчанию
-
В системном представлении — дважды щелкните по системе HANA или откройте перспективу
Из панели инструментов системного представления — выберите кнопку Открыть администрирование по умолчанию
В системном представлении — дважды щелкните по системе HANA или откройте перспективу
HANA Studio: редактор администратора
В административном представлении: HANA studio предоставляет несколько вкладок для проверки конфигурации и работоспособности системы HANA. Вкладка «Обзор» содержит общую информацию, такую как: рабочее состояние, время запуска первого и последнего запущенного сервиса, версия, дата и время сборки, платформа, производитель оборудования и т. Д.
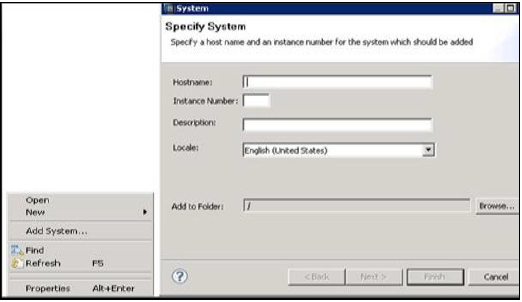
Добавление системы HANA в Studio
Одна или несколько систем могут быть добавлены в HANA studio для целей администрирования и информационного моделирования. Для добавления новой системы HANA требуются имя хоста, номер экземпляра, имя пользователя и пароль базы данных.
- Порт 3615 должен быть открыт для подключения к базе данных
- Порт 31015 Экземпляр № 10
- Порт 30015 Экземпляр № 00
- Порт SSh также должен быть открыт
Добавление системы в Hana Studio
Чтобы добавить систему в HANA studio, выполните следующие действия.
Щелкните правой кнопкой мыши в пространстве навигатора и выберите «Добавить систему». Введите сведения о системе HANA, например, имя хоста и номер экземпляра, и нажмите «Далее».
Введите имя пользователя и пароль базы данных для подключения к базе данных SAP HANA. Нажмите Далее и затем Готово.
После нажатия кнопки «Готово» система HANA будет добавлена в представление системы для целей администрирования и моделирования. Каждая система HANA имеет два основных подузла: каталог и контент.
Каталог и контент
Каталог
Он содержит все доступные схемы, т.е. все структуры данных, таблицы и данные, представления столбцов, процедуры, которые можно использовать на вкладке «Содержимое».
содержание
Вкладка «Содержимое» содержит репозиторий времени разработки, в котором хранится вся информация о моделях данных, созданных с помощью HANA Modeler. Эти модели организованы в пакеты. Узел контента предоставляет разные представления для одних и тех же физических данных.
SAP HANA — Системный монитор
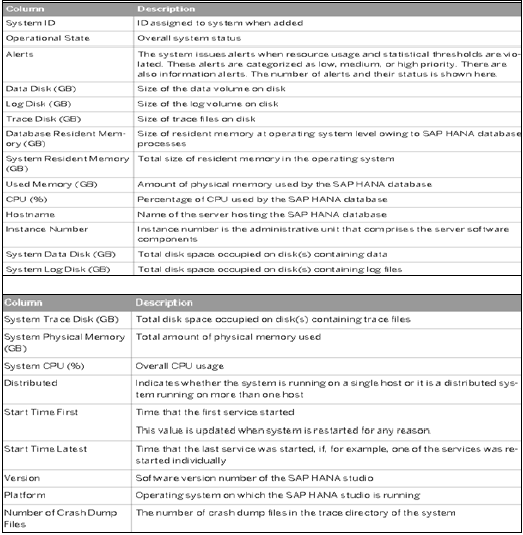
Системный монитор в HANA studio предоставляет обзор всей вашей системы HANA. Из системного монитора вы можете углубиться в детали отдельной системы в редакторе администрирования. В нем рассказывается о Диск с данными, Диск журнала, Диск трассировки, Оповещения об использовании ресурсов с приоритетом.
Следующая информация доступна в системном мониторе —
SAP HANA — информационный моделер
SAP HANA Information Modeler; также известный как HANA Data Modeler — это сердце системы HANA. Это позволяет создавать представления моделирования в верхней части таблиц базы данных и реализовывать бизнес-логику для создания содержательного отчета для анализа.
Особенности информационного моделера
-
Предоставляет несколько представлений транзакционных данных, хранящихся в физических таблицах базы данных HANA для целей анализа и бизнес-логики.
-
Информационное моделирование работает только для таблиц хранения на основе столбцов.
-
Представления информационного моделирования используются приложениями на основе Java или HTML или такими инструментами SAP, как SAP Lumira или Analysis Office, для целей отчетности.
-
Также возможно использовать сторонние инструменты, такие как MS Excel, для подключения к HANA и создания отчетов.
-
В представлениях моделирования SAP HANA используется реальная мощь SAP HANA.
Предоставляет несколько представлений транзакционных данных, хранящихся в физических таблицах базы данных HANA для целей анализа и бизнес-логики.
Информационное моделирование работает только для таблиц хранения на основе столбцов.
Представления информационного моделирования используются приложениями на основе Java или HTML или такими инструментами SAP, как SAP Lumira или Analysis Office, для целей отчетности.
Также возможно использовать сторонние инструменты, такие как MS Excel, для подключения к HANA и создания отчетов.
В представлениях моделирования SAP HANA используется реальная мощь SAP HANA.
Существует три типа информационных представлений, определяемых как —
- Просмотр атрибутов
- Аналитический взгляд
- Расчет Расчет
Row vs Column Store
Виды SAP HANA Modeler могут быть созданы только в верхней части таблиц на основе столбцов. Хранение данных в таблицах столбцов не является чем-то новым. Ранее предполагалось, что хранение данных в структуре на основе столбцов требует большего объема памяти, а не оптимизации производительности.
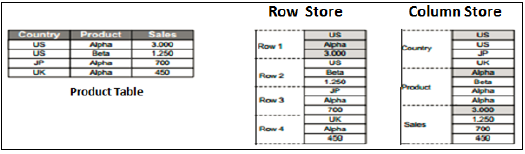
С развитием SAP HANA HANA использовала хранение данных на основе столбцов в представлениях информации и представила реальные преимущества столбчатых таблиц по сравнению с таблицами на основе строк.
Колонка Магазин
В таблице хранения столбцов данные хранятся вертикально. Итак, сходные типы данных объединяются, как показано в примере выше. Он обеспечивает более быстрые операции чтения и записи в памяти с помощью In-Memory Computing Engine.
В обычной базе данных данные хранятся в структуре на основе строк, то есть горизонтально. SAP HANA хранит данные как в строках, так и в колонках. Это обеспечивает оптимизацию производительности, гибкость и сжатие данных в базе данных HANA.
Хранение данных в столбцовой таблице имеет следующие преимущества:
-
Сжатие данных
-
Более быстрый доступ для чтения и записи к таблицам по сравнению с обычным хранилищем на основе строк
-
Гибкость и параллельная обработка
-
Выполнять агрегации и расчеты на более высокой скорости
Сжатие данных
Более быстрый доступ для чтения и записи к таблицам по сравнению с обычным хранилищем на основе строк
Гибкость и параллельная обработка
Выполнять агрегации и расчеты на более высокой скорости
Существуют различные методы и алгоритмы, как данные могут храниться в структуре на основе столбцов — словарь сжат, длина цикла сжат и многое другое.
В словаре Compressed ячейки хранятся в виде чисел в таблицах, а числовые ячейки всегда оптимизированы по сравнению с символами.
При сжатии длины цикла он сохраняет множитель со значением ячейки в числовом формате, а множитель показывает повторяющееся значение в таблице.
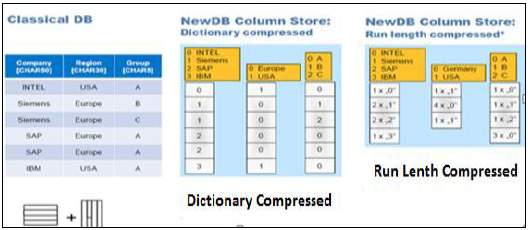
Функциональная разница — Row vs Column Store
Всегда желательно использовать хранилище на основе столбцов, если оператор SQL должен выполнять агрегатные функции и вычисления. Таблицы на основе столбцов всегда работают лучше при выполнении агрегатных функций, таких как Sum, Count, Max, Min.
Хранение на основе строк предпочтительнее, когда вывод должен возвращать полную строку. Приведенный ниже пример облегчает понимание.
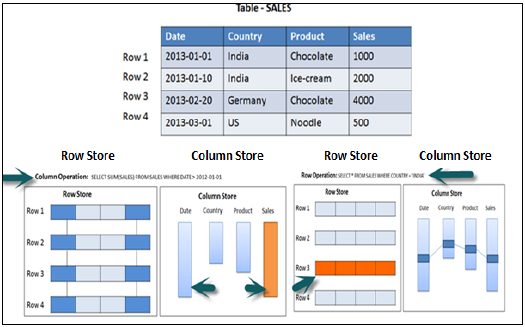
В приведенном выше примере при выполнении функции Aggregate (Sum) в столбце продаж с предложением Where будет использоваться только столбец Date и Sales при выполнении запроса SQL, поэтому, если это таблица хранения на основе столбцов, она будет оптимизирована по производительности, быстрее, чем данные требуется только из двух столбцов.
При выполнении простого запроса на выборку в выводе должна быть напечатана полная строка, поэтому рекомендуется сохранять таблицу как строку на основе этого сценария.
Представления информационного моделирования
Просмотр атрибутов
Атрибуты являются неизмеримыми элементами в таблице базы данных. Они представляют основные данные и аналогичны характеристикам BW. Представления атрибутов являются измерениями в базе данных или используются для объединения измерений или других представлений атрибутов в моделировании.
Важные особенности —
- Представления атрибутов используются в представлениях «Аналитика» и «Расчет».
- Представление атрибута представляет основные данные.
- Используется для фильтрации размеров таблиц измерений в аналитическом представлении и представлении расчета.
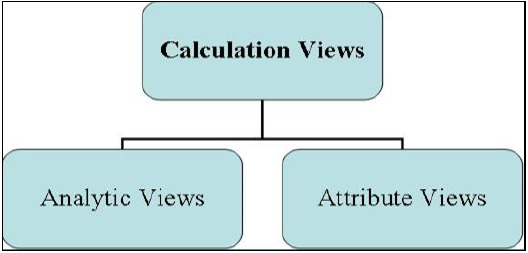
Аналитический взгляд
Аналитические представления используют возможности SAP HANA для выполнения вычислений и функций агрегирования таблиц в базе данных. Он имеет по крайней мере одну таблицу фактов, которая имеет меры и первичные ключи таблиц измерений и окружена таблицами измерений, содержащими основные данные.
Важные особенности —
-
Аналитические представления предназначены для выполнения запросов схемы Star.
-
Аналитические представления содержат как минимум одну таблицу фактов и несколько таблиц измерений с основными данными и выполняют вычисления и агрегирование
-
Они аналогичны инфо-кубам и инфо-объектам в SAP BW.
-
Аналитические представления могут создаваться поверх представлений атрибутов и таблиц фактов и выполнять вычисления, такие как количество проданных единиц, общая цена и т. Д.
Аналитические представления предназначены для выполнения запросов схемы Star.
Аналитические представления содержат как минимум одну таблицу фактов и несколько таблиц измерений с основными данными и выполняют вычисления и агрегирование
Они аналогичны инфо-кубам и инфо-объектам в SAP BW.
Аналитические представления могут создаваться поверх представлений атрибутов и таблиц фактов и выполнять вычисления, такие как количество проданных единиц, общая цена и т. Д.
Расчет просмотров
Представления вычислений используются поверх представлений Аналитики и Атрибутов для выполнения сложных вычислений, что невозможно в Аналитических представлениях. Представление «Расчет» представляет собой комбинацию таблиц базовых столбцов, представлений атрибутов и аналитических представлений для обеспечения бизнес-логики.
Важные особенности —
-
Виды вычислений определяются либо графически с использованием функции моделирования HANA, либо сценариями в SQL.
-
Он создан для выполнения сложных вычислений, которые невозможны для других представлений — атрибутов и аналитических представлений моделирующего устройства SAP HANA.
-
Одно или несколько представлений атрибутов и аналитических представлений используются с помощью встроенных функций, таких как проекты, объединение, объединение, ранжирование в представлении вычисления.
Виды вычислений определяются либо графически с использованием функции моделирования HANA, либо сценариями в SQL.
Он создан для выполнения сложных вычислений, которые невозможны для других представлений — атрибутов и аналитических представлений моделирующего устройства SAP HANA.
Одно или несколько представлений атрибутов и аналитических представлений используются с помощью встроенных функций, таких как проекты, объединение, объединение, ранжирование в представлении вычисления.
SAP HANA — основная архитектура
Изначально система SAP HANA была разработана на Java и C ++ и предназначена для работы только с операционной системой Suse Linux Enterprise Server 11. Система SAP HANA состоит из нескольких компонентов, отвечающих за выделение вычислительной мощности системы HANA.
-
Наиболее важным компонентом системы SAP HANA является Index Server, который содержит процессор SQL / MDX для обработки операторов запросов для базы данных.
-
Система HANA содержит сервер имен, сервер препроцессора, сервер статистики и механизм XS, который используется для связи и размещения небольших веб-приложений и различных других компонентов.
Наиболее важным компонентом системы SAP HANA является Index Server, который содержит процессор SQL / MDX для обработки операторов запросов для базы данных.
Система HANA содержит сервер имен, сервер препроцессора, сервер статистики и механизм XS, который используется для связи и размещения небольших веб-приложений и различных других компонентов.
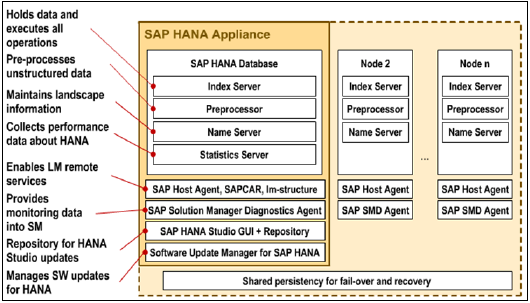
Индексный сервер
Индекс-сервер является сердцем системы баз данных SAP HANA. Он содержит фактические данные и механизмы для обработки этих данных. Когда SQL или MDX запускается для системы SAP HANA, сервер индексирования обрабатывает все эти запросы и обрабатывает их. Вся обработка HANA происходит на Index Server.
Индекс-сервер содержит механизмы обработки данных для обработки всех операторов SQL / MDX, поступающих в систему базы данных HANA. Он также имеет уровень сохраняемости, который отвечает за долговечность системы HANA и обеспечивает восстановление системы HANA в самое последнее состояние при повторном запуске сбоя системы.
Индекс-сервер также имеет Session and Transaction Manager, который управляет транзакциями и отслеживает все выполняемые и закрытые транзакции.
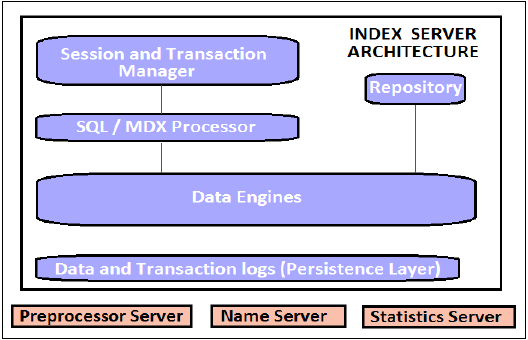
Index Server — Архитектура
Процессор SQL / MDX
Он отвечает за обработку транзакций SQL / MDX с механизмами данных, отвечающими за выполнение запросов. Он сегментирует все запросы и направляет их на исправление движка для оптимизации производительности.
Это также гарантирует, что все запросы SQL / MDX авторизованы, а также обеспечивает обработку ошибок для эффективной обработки этих операторов. Он содержит несколько механизмов и процессоров для выполнения запросов —
-
MDX (Multi Dimension Expression) — это язык запросов для систем OLAP, например, SQL используется для реляционной базы данных. MDX Engine отвечает за обработку запросов и управляет многомерными данными, хранящимися в кубах OLAP.
-
Механизм планирования отвечает за выполнение операций планирования в базе данных SAP HANA.
-
Механизм вычислений преобразует данные в модели вычислений для создания логического плана выполнения для поддержки параллельной обработки выписок.
-
Процессор хранимых процедур выполняет вызовы процедур для оптимизированной обработки; он преобразует кубы OLAP в кубы, оптимизированные для HANA.
MDX (Multi Dimension Expression) — это язык запросов для систем OLAP, например, SQL используется для реляционной базы данных. MDX Engine отвечает за обработку запросов и управляет многомерными данными, хранящимися в кубах OLAP.
Механизм планирования отвечает за выполнение операций планирования в базе данных SAP HANA.
Механизм вычислений преобразует данные в модели вычислений для создания логического плана выполнения для поддержки параллельной обработки выписок.
Процессор хранимых процедур выполняет вызовы процедур для оптимизированной обработки; он преобразует кубы OLAP в кубы, оптимизированные для HANA.
Управление транзакциями и сессиями
Он отвечает за координацию всех транзакций базы данных и отслеживание всех запущенных и закрытых транзакций.
Когда транзакция выполняется или не удалась, менеджер транзакций уведомляет соответствующий механизм обработки данных о необходимых действиях.
Компонент управления сеансами отвечает за инициализацию и управление сеансами и соединениями для системы SAP HANA с использованием предварительно определенных параметров сеанса.
Постоянный слой
Он отвечает за долговечность и атомарность транзакций в системе HANA. Уровень персистентности обеспечивает встроенную систему аварийного восстановления для базы данных HANA.
Это гарантирует, что база данных восстановлена до самого последнего состояния, и гарантирует, что все транзакции завершены или отменены в случае сбоя системы или перезапуска.
Он также отвечает за управление данными и журналами транзакций, а также за резервное копирование данных, резервное копирование журналов и настройку системы HANA. Резервные копии хранятся в виде точек сохранения в томах данных с помощью координатора точек сохранения, который обычно настраивается на возврат каждые 5-10 минут.
Сервер препроцессора
Сервер препроцессора в системе SAP HANA используется для анализа текстовых данных.
Index Server использует сервер препроцессора для анализа текстовых данных и извлечения информации из текстовых данных при использовании возможностей текстового поиска.
Name Server
Сервер NAME содержит информацию о системном ландшафте системы HANA. В распределенной среде существует несколько узлов, каждый из которых имеет несколько ЦП, сервер имен хранит топологию системы HANA и содержит информацию обо всех работающих компонентах, а информация распространяется по всем компонентам.
-
Топология системы SAP HANA записана здесь.
-
Это сокращает время повторной индексации, поскольку содержит данные о том, какие данные находятся на каком сервере в распределенной среде.
Топология системы SAP HANA записана здесь.
Это сокращает время повторной индексации, поскольку содержит данные о том, какие данные находятся на каком сервере в распределенной среде.
Статистический сервер
Этот сервер проверяет и анализирует работоспособность всех компонентов в системе HANA. Статистический сервер отвечает за сбор данных, касающихся системных ресурсов, их распределение и потребление ресурсов, а также за общую производительность системы HANA.
Он также предоставляет исторические данные, относящиеся к производительности системы, для целей анализа, чтобы проверить и исправить проблемы, связанные с производительностью в системе HANA.
XS Engine
Механизм XS помогает внешним приложениям на основе Java и HTML получать доступ к системе HANA с помощью клиента XS. Поскольку система SAP HANA содержит веб-сервер, который может использоваться для размещения небольших приложений на основе JAVA / HTML.
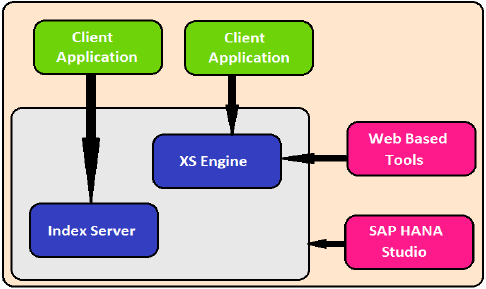
XS Engine преобразует модель постоянства, хранящуюся в базе данных, в модель потребления для клиентов, предоставляемых через HTTP / HTTPS.
SAP Host Agent
Агент хоста SAP должен быть установлен на всех компьютерах, входящих в систему SAP HANA Landscape. Агент хоста SAP используется диспетчером обновлений программного обеспечения SUM для установки автоматических обновлений всех компонентов системы HANA в распределенной среде.
Структура LM
Структура LM системы SAP HANA содержит информацию о текущих деталях установки. Эта информация используется диспетчером обновлений программного обеспечения для установки автоматических обновлений компонентов системы HANA.
Диагностический агент SAP Solution Manager (SAP SOLMAN)
Этот диагностический агент предоставляет все данные в SAP Solution Manager для мониторинга системы SAP HANA. Этот агент предоставляет всю информацию о базе данных HANA, которая включает текущее состояние базы данных и общую информацию.
Он предоставляет сведения о конфигурации системы HANA, когда SAP SOLMAN интегрируется с системой SAP HANA.
Репозиторий SAP HANA Studio
Репозиторий SAP HANA studio помогает разработчикам HANA обновить текущую версию HANA studio до последних версий. Studio Repository содержит код, который выполняет это обновление.
Диспетчер обновлений программного обеспечения для SAP HANA
SAP Market Place используется для установки обновлений для систем SAP. Диспетчер обновления программного обеспечения для системы HANA помогает в обновлении системы HANA из SAP Marketplace.
Он используется для загрузки программного обеспечения, сообщений клиентов, SAP Notes и запроса лицензионных ключей для системы HANA. Он также используется для распространения HANA studio для систем конечных пользователей.
SAP HANA — Моделирование
Опция SAP HANA Modeler используется для создания информационных представлений в верхней части схем → таблиц в базе данных HANA. Эти представления используются приложениями на основе JAVA / HTML или приложениями SAP, такими как SAP Lumira, Office Analysis или сторонним программным обеспечением, например MS Excel, для создания отчетов с целью соответствия бизнес-логике, а также для анализа и извлечения информации.
Моделирование HANA выполняется в верхней части таблиц, доступных на вкладке Каталог в разделе Схема в студии HANA, и все представления сохраняются в таблице содержимого в разделе Пакет.
Вы можете создать новый пакет на вкладке «Содержимое» в студии HANA, щелкнув правой кнопкой мыши «Содержимое» и «Новый».
Все виды моделирования, созданные внутри одного пакета, входят в один пакет в студии HANA и классифицируются в соответствии с типом представления.
Каждое представление имеет различную структуру для таблиц измерений и фактов. Таблицы затемнения определяются с помощью основных данных, а таблица фактов имеет первичный ключ для таблиц измерений и мер, таких как количество проданных единиц, среднее время задержки, общая цена и т. Д.
Таблица фактов и размеров
Таблица фактов содержит первичные ключи для таблицы измерений и мер. Они объединяются с таблицами измерений в представлениях HANA для соответствия бизнес-логике.
Пример мер — количество проданных единиц, общая цена, среднее время задержки и т. Д.
Таблица измерений содержит основные данные и объединена с одной или несколькими таблицами фактов для создания некоторой бизнес-логики. Таблицы измерений используются для создания схем с таблицами фактов и могут быть нормализованы.
Пример таблицы размеров — клиент, продукт и т. Д.
Предположим, что компания продает продукты клиентам. Каждая продажа — это факт, который происходит внутри компании, и таблица фактов используется для записи этих фактов.
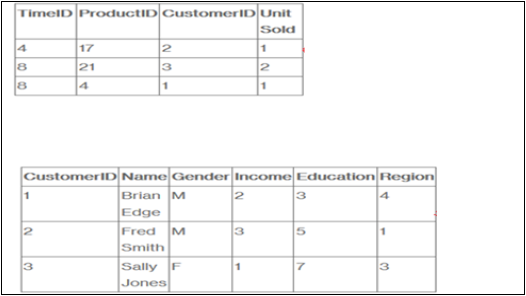
Например, строка 3 в таблице фактов записывает тот факт, что клиент 1 (Брайан) купил один товар в день 4. И, в полном примере, у нас также будет таблица продуктов и расписание, чтобы мы знали, что он купил и когда именно.
В таблице фактов перечислены события, которые происходят в нашей компании (или, по крайней мере, события, которые мы хотим проанализировать — количество проданных единиц, маржа и доход от продаж). В таблицах измерений перечислены факторы (клиент, время и продукт), по которым мы хотим проанализировать данные.
SAP HANA — схема в хранилище данных
Схемы представляют собой логическое описание таблиц в хранилище данных. Схемы создаются путем объединения нескольких таблиц фактов и измерений для соответствия некоторой бизнес-логике.
База данных использует реляционную модель для хранения данных. Однако хранилище данных использует схемы, объединяющие таблицы измерений и фактов для соответствия бизнес-логике. В хранилище данных используются три типа схем:
- Схема звезды
- Схема снежинок
- Галактика Схема
Схема звезды
В схеме «звезда» каждое измерение объединяется в одну таблицу фактов. Каждое измерение представлено только одним измерением и не нормализуется.
Таблица измерений содержит набор атрибутов, которые используются для анализа данных.
Пример. В приведенном ниже примере у нас есть таблица фактов FactSales, в которой есть первичные ключи для всех таблиц Dim, а также измеряются единицы_продано и продано долларов для анализа.
У нас есть четыре таблицы измерений — DimTime, DimItem, DimBranch, DimLocation
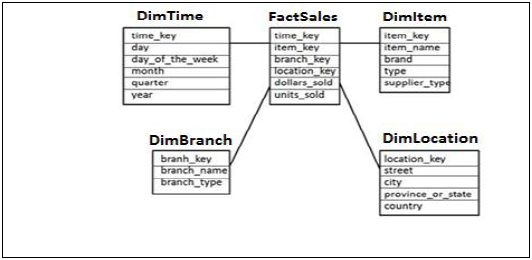
Каждая таблица измерений связана с таблицей фактов, поскольку таблица фактов имеет первичный ключ для каждой таблицы измерений, который используется для объединения двух таблиц.
Факты / показатели в таблице фактов используются для целей анализа вместе с атрибутом в таблицах измерений.
Схема снежинок
В схеме «Снежинки» некоторые таблицы измерений дополнительно нормализованы, а таблицы Dim связаны с одной таблицей фактов. Нормализация используется для организации атрибутов и таблиц базы данных, чтобы минимизировать избыточность данных.
Нормализация включает в себя разбиение таблицы на менее избыточные меньшие таблицы без потери какой-либо информации, и меньшие таблицы объединяются в таблицу измерений.
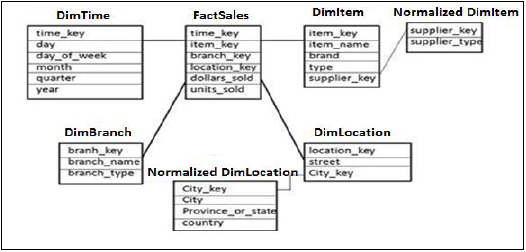
В приведенном выше примере таблицы измерений DimItem и DimLocation нормализуются без потери какой-либо информации. Это называется схемой «Снежинки», где таблицы измерений дополнительно нормализуются в меньшие таблицы.
Галактика Схема
В Galaxy Schema есть несколько таблиц фактов и таблиц измерений. В каждой таблице фактов хранятся первичные ключи нескольких таблиц измерений и показателей / фактов для проведения анализа.
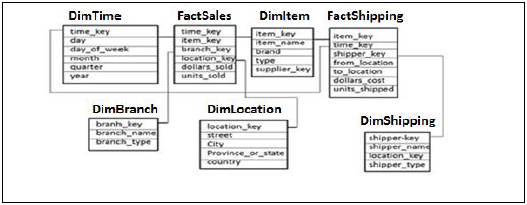
В приведенном выше примере две таблицы фактов FactSales, FactShipping и несколько таблиц измерений объединены в таблицы фактов. Каждая таблица фактов содержит первичный ключ для объединенных таблиц Dim и показатели / факты для выполнения анализа.
SAP HANA — Таблицы
Доступ к таблицам в базе данных HANA можно получить из HANA Studio на вкладке Каталог в разделе Схемы. Новые таблицы могут быть созданы с помощью двух методов, приведенных ниже —
- Использование редактора SQL
- Использование опции GUI
Редактор SQL в HANA Studio
Консоль SQL можно открыть, выбрав имя схемы, в которой необходимо создать новую таблицу, используя опцию System View SQL Editor или щелкнув правой кнопкой мыши имя схемы, как показано ниже:
После открытия редактора SQL имя схемы можно подтвердить по имени, написанному в верхней части редактора SQL. Новая таблица может быть создана с помощью оператора SQL Create Table —
Create column Table Test1 ( ID INTEGER, NAME VARCHAR(10), PRIMARY KEY (ID) );
В этом операторе SQL мы создали таблицу столбцов «Test1», определили типы данных таблицы и первичный ключ.
Как только вы напишите SQL-запрос «Создать таблицу», нажмите «Выполнить» в верхней части редактора SQL. Как только инструкция выполнена, мы получим подтверждающее сообщение, как показано на снимке экрана, приведенном ниже —
Оператор «Создать столбец таблицы Test1 (ID INTEGER, NAME VARCHAR (10), PRIMARY KEY (ID))»
успешно выполнено за 13 мс 761 мкс (время обработки сервером: 12 мс 979 мкс) — затронутые строки: 0
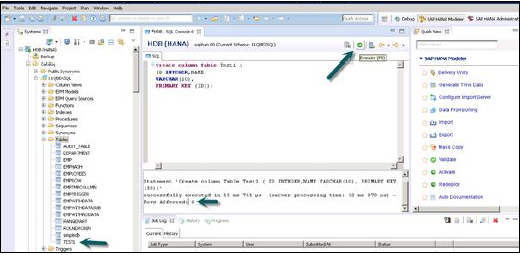
Оператор выполнения также сообщает о времени, затраченном на выполнение оператора. Как только инструкция успешно выполнена, щелкните правой кнопкой мыши на вкладке Таблица под именем схемы в представлении системы и обновите. Новая таблица будет отражена в списке таблиц под именем схемы.
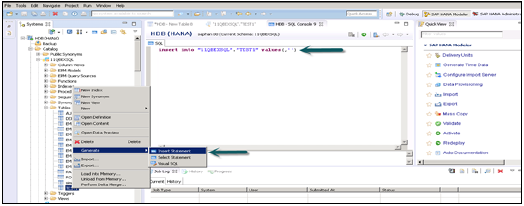
Оператор вставки используется для ввода данных в таблицу с помощью редактора SQL.
Insert into TEST1 Values (1,'ABCD') Insert into TEST1 Values (2,'EFGH');
Нажмите на Выполнить.
Вы можете щелкнуть правой кнопкой мыши на имени таблицы и использовать Open Data Definition, чтобы увидеть тип данных таблицы. Откройте Data Preview / Open Content, чтобы увидеть содержимое таблицы.
Создание таблицы с использованием опции GUI
Другой способ создания таблицы в базе данных HANA — использование опции GUI в HANA Studio.
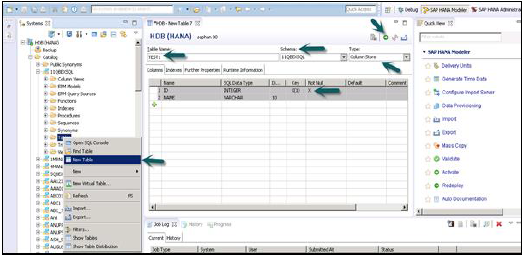
Щелкните правой кнопкой мыши вкладку «Таблица» в разделе «Схема» → выберите «Новая таблица», как показано на приведенном ниже снимке.
После того, как вы нажмете «Новая таблица» → откроется окно для ввода имени таблицы, выберите «Имя схемы» в раскрывающемся списке, «Определите тип таблицы» в раскрывающемся списке: хранилище столбцов или хранилище строк.
Определите тип данных, как показано ниже. Нажав на знак +, можно добавить столбцы. Чтобы выбрать основной ключ, щелкните ячейку в поле «Основной ключ» перед именем столбца. По умолчанию будет активен параметр «Не равно нулю».
После добавления столбцов нажмите «Выполнить».
Выполнив (F8), щелкните правой кнопкой мыши вкладку таблицы → Обновить. Новая таблица будет отражена в списке таблиц под выбранной схемой. Ниже опция вставки может быть использована для вставки данных в таблицу. Выберите оператор, чтобы увидеть содержание таблицы.
Вставка данных в таблицу с использованием графического интерфейса в студии HANA
Вы можете щелкнуть правой кнопкой мыши на имени таблицы и использовать Open Data Definition, чтобы увидеть тип данных таблицы. Откройте Data Preview / Open Content, чтобы увидеть содержимое таблицы.
Чтобы использовать таблицы из одной схемы для создания представлений, мы должны предоставить доступ к схеме для пользователя по умолчанию, который запускает все представления в моделировании HANA. Это можно сделать, перейдя в редактор SQL и выполнив этот запрос —
ВЫБРАТЬ ГРАНТ В СХЕМЕ «<SCHEMA_NAME>» ДЛЯ _SYS_REPO С ГРАНИТОМ
SAP HANA — Пакеты
Пакеты SAP HANA отображаются на вкладке «Содержимое» в студии HANA. Все моделирование HANA сохраняется внутри пакетов.
Вы можете создать новый пакет, щелкнув правой кнопкой мыши на вкладке содержимого → Новый → Пакет
Вы также можете создать подпакет под пакетом, щелкнув правой кнопкой мыши на имени пакета. Когда мы щелкаем правой кнопкой мыши по Пакету, мы получаем 7 опций: Мы можем создавать представления атрибутов видов HANA, аналитические представления и представления вычислений в пакете.
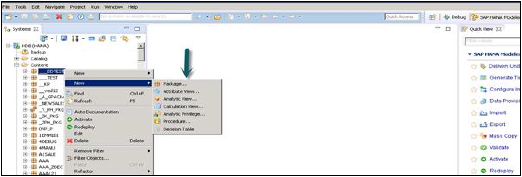
Вы также можете создать таблицу решений, определить аналитические привилегии и создать процедуры в пакете.
Когда вы щелкаете правой кнопкой мыши на Package и нажимаете New, вы также можете создавать подпакеты в Package. Вы должны ввести имя пакета, описание при создании пакета.
SAP HANA — Просмотр атрибутов
Представления атрибутов в моделировании SAP HANA создаются в верхней части таблиц измерений. Они используются для объединения таблиц измерений или других представлений атрибутов. Вы также можете скопировать новое представление атрибутов из уже существующих представлений атрибутов в других пакетах, но это не позволяет изменять атрибуты представления.
Характеристики атрибута просмотра
-
Представления атрибутов в HANA используются для соединения таблиц измерений или других представлений атрибутов.
-
Представления атрибутов используются в аналитических и расчетных представлениях для анализа для передачи основных данных.
-
Они аналогичны характеристикам в BM и содержат основные данные.
-
Представления атрибутов используются для оптимизации производительности в таблицах размеров большого размера. Вы можете ограничить количество атрибутов в представлении атрибутов, которые в дальнейшем используются для целей отчетности и анализа.
-
Представления атрибутов используются для моделирования основных данных, чтобы придать некоторый контекст.
Представления атрибутов в HANA используются для соединения таблиц измерений или других представлений атрибутов.
Представления атрибутов используются в аналитических и расчетных представлениях для анализа для передачи основных данных.
Они аналогичны характеристикам в BM и содержат основные данные.
Представления атрибутов используются для оптимизации производительности в таблицах размеров большого размера. Вы можете ограничить количество атрибутов в представлении атрибутов, которые в дальнейшем используются для целей отчетности и анализа.
Представления атрибутов используются для моделирования основных данных, чтобы придать некоторый контекст.
Как создать вид атрибута?
Выберите имя пакета, под которым вы хотите создать представление атрибутов. Щелкните правой кнопкой мыши на Package → Go to New → Attribute View.
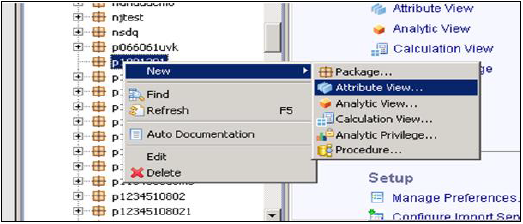
Когда вы нажмете на Вид атрибута, откроется Новое окно. Введите атрибут Просмотр имени и описания. В раскрывающемся списке выберите «Вид» и «Подтип». В подтипе есть три типа представлений атрибутов — Стандартное, Время и Производное.
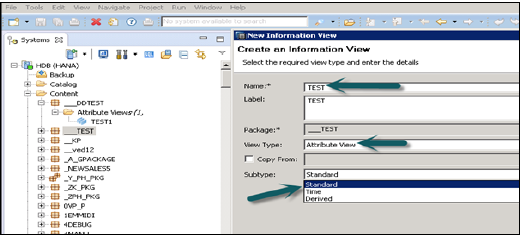
Представление атрибута подтипа времени — это особый вид представления атрибута, который добавляет измерение времени к основанию данных. Когда вы введете имя атрибута, тип и подтип и нажмете кнопку «Готово», откроются три рабочие области:
-
Панель сценариев с основанием данных и семантическим уровнем.
-
В области сведений отображается атрибут всех таблиц, добавленных в основание данных, и соединение между ними.
-
Панель вывода, куда мы можем добавить атрибуты из панели сведений для фильтрации в отчете.
Панель сценариев с основанием данных и семантическим уровнем.
В области сведений отображается атрибут всех таблиц, добавленных в основание данных, и соединение между ними.
Панель вывода, куда мы можем добавить атрибуты из панели сведений для фильтрации в отчете.
Вы можете добавить объекты в основание данных, нажав на знак «+» рядом с основанием данных. Вы можете добавить несколько таблиц измерений и представлений атрибутов на панели сценариев и объединить их с помощью первичного ключа.
Когда вы нажмете «Добавить объект в основании данных», вы получите панель поиска, откуда вы можете добавить таблицы измерений и представления атрибутов в панель сценариев. После добавления таблиц или представлений атрибутов в основание данных их можно объединить с использованием первичного ключа в области сведений, как показано ниже.
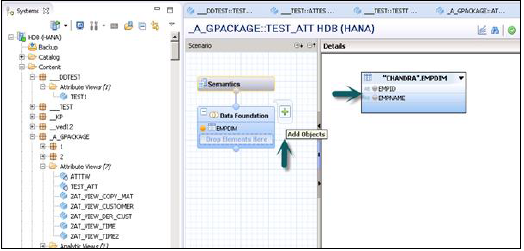
После завершения соединения выберите несколько атрибутов в области сведений, щелкните правой кнопкой мыши и выберите «Добавить в вывод». Все столбцы будут добавлены в панель вывода. Теперь нажмите на опцию Активировать, и вы получите подтверждающее сообщение в журнале работ.
Теперь вы можете щелкнуть правой кнопкой мыши по представлению атрибутов и перейти к предварительному просмотру данных.
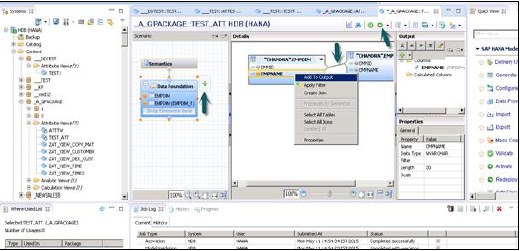
Примечание. Когда вид не активирован, на нем есть метка ромба. Однако, как только вы активируете его, этот бриллиант исчезает, что подтверждает, что просмотр был активирован успешно.
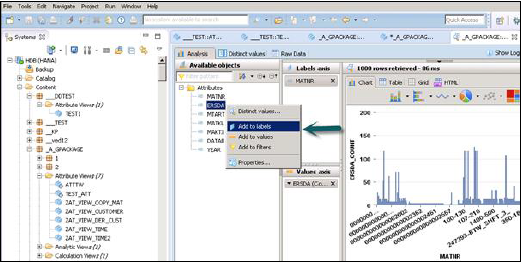
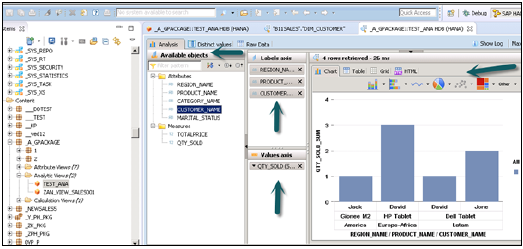
Как только вы нажмете на Предварительный просмотр данных, он покажет все атрибуты, которые были добавлены в панель «Вывод» в разделе «Доступные объекты».
Эти объекты можно добавить к оси «Ярлыки и значения», щелкнув правой кнопкой мыши и добавив или перетащив объекты, как показано ниже:
SAP HANA — Аналитическое представление
Аналитическое представление имеет вид схемы Star, в которой мы объединяем одну таблицу фактов с несколькими таблицами измерений. Аналитические представления используют реальную мощь SAP HANA для выполнения сложных вычислений и агрегирования функций путем объединения таблиц в форме звездообразной схемы и выполнения запросов звездообразной схемы.
Характеристики аналитического представления
Ниже приведены свойства аналитического представления SAP HANA.
-
Аналитические представления используются для выполнения сложных вычислений и агрегирования таких функций, как сумма, количество, мин, максимум и т. Д.
-
Аналитические представления предназначены для запуска запросов схемы запуска.
-
Каждое аналитическое представление имеет одну таблицу фактов, окруженную несколькими таблицами измерений. Таблица фактов содержит первичный ключ для каждой таблицы Dim и показателей.
-
Аналитические представления аналогичны информационным объектам и наборам информации SAP BW.
Аналитические представления используются для выполнения сложных вычислений и агрегирования таких функций, как сумма, количество, мин, максимум и т. Д.
Аналитические представления предназначены для запуска запросов схемы запуска.
Каждое аналитическое представление имеет одну таблицу фактов, окруженную несколькими таблицами измерений. Таблица фактов содержит первичный ключ для каждой таблицы Dim и показателей.
Аналитические представления аналогичны информационным объектам и наборам информации SAP BW.
Как создать аналитическое представление?
Выберите имя пакета, под которым вы хотите создать аналитическое представление. Щелкните правой кнопкой мыши на Package → Go to New → Analytic View. При нажатии на аналитическое представление откроется новое окно. Введите View name и Description и из выпадающего списка выберите View Type и Finish.
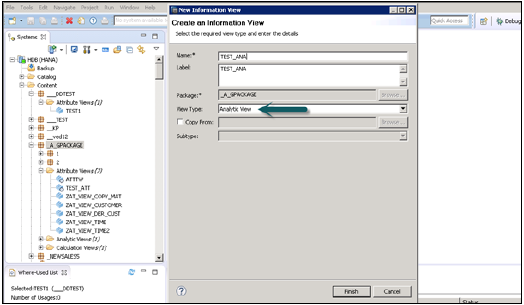
Когда вы нажмете кнопку «Готово», вы увидите аналитическое представление с основанием данных и опцией Star Join.
Нажмите на основание данных, чтобы добавить таблицы измерений и фактов. Нажмите на Star Join, чтобы добавить атрибуты просмотров.
Добавьте таблицы Dim и Fact в основание данных, используя знак «+». В приведенном ниже примере были добавлены 3 таблицы затемнения: DIM_CUSTOMER, DIM_PRODUCT, DIM_REGION и 1 таблица фактов FCT_SALES в области сведений. Соединение таблицы Dim с таблицей фактов с использованием первичных ключей, хранящихся в таблице фактов.
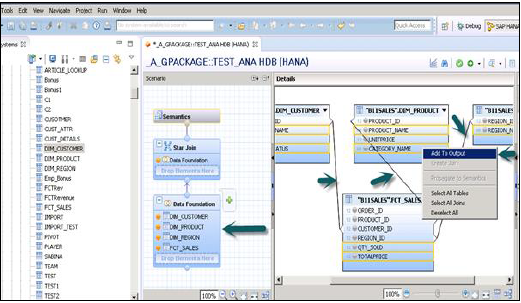
Выберите Атрибуты из таблицы Dim and Fact, чтобы добавить их в панель вывода, как показано на снимке, показанном выше. Теперь измените тип данных Фактов, от таблицы фактов до показателей.
Нажмите на семантическом слое, выберите факты и нажмите на знак мер, как показано ниже, чтобы изменить тип данных на меры и активировать представление.
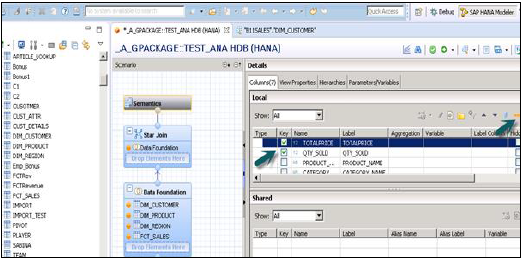
Как только вы активируете представление и нажмете на Предварительный просмотр данных, все атрибуты и меры будут добавлены в список Доступных объектов. Добавьте атрибуты к оси меток и измерьте к оси значений для целей анализа.
Существует возможность выбора различных типов диаграмм и графиков.
SAP HANA — представление расчета
Представления вычислений используются для использования других аналитических представлений, атрибутов и других представлений вычислений и таблиц базовых столбцов. Они используются для выполнения сложных вычислений, которые невозможны для других типов представлений.
Характеристики вида расчета
Ниже приведены некоторые характеристики видов расчета —
-
Представления вычислений используются для использования аналитических представлений, атрибутов и других представлений вычислений.
-
Они используются для выполнения сложных вычислений, которые невозможны в других представлениях.
-
Существует два способа создания представлений расчета — редактор SQL или графический редактор.
-
Встроенные узлы объединения, соединения, проекции и агрегации.
Представления вычислений используются для использования аналитических представлений, атрибутов и других представлений вычислений.
Они используются для выполнения сложных вычислений, которые невозможны в других представлениях.
Существует два способа создания представлений расчета — редактор SQL или графический редактор.
Встроенные узлы объединения, соединения, проекции и агрегации.
Как создать представление расчета?
Выберите имя пакета, под которым вы хотите создать представление расчета. Нажмите правой кнопкой мыши на Пакет → Перейти к новому → Расчет. При нажатии на представление расчета открывается новое окно.
Введите имя вида, описание и выберите тип вида: вид расчета, стандарт подтипа или время (это особый вид, который добавляет измерение времени). Вы можете использовать два типа представления расчета — графический и SQL-скрипт.
Графические виды расчета
У него есть узлы по умолчанию, такие как агрегация, проекция, соединение и объединение. Он используется для использования других представлений атрибутов, аналитики и других вычислений.
Виды вычислений на основе SQL Script
Это написано в сценариях SQL, которые построены на командах SQL или определенных функциях HANA.
Категория данных
Куб в этом узле по умолчанию — Агрегация. Вы можете выбрать Звездное соединение с измерением Куб.
Измерение, в этом узле по умолчанию — Проекция.
Расчет с представлением Star Join
Он не позволяет добавлять базовые таблицы столбцов, представления атрибутов или аналитические представления в основании данных. Все таблицы измерений должны быть изменены на представления расчета размеров для использования в соединении звездой. Все таблицы фактов могут быть добавлены и могут использовать узлы по умолчанию в представлении расчета.
пример
В следующем примере показано, как мы можем использовать представление «Расчет» с соединением «звезда» —
У вас есть четыре таблицы, две таблицы Dim и две таблицы фактов. Вы должны найти список всех сотрудников с указанием даты их вступления, Emp Name, empId, Salary и Bonus.
Скопируйте и вставьте приведенный ниже скрипт в редактор SQL и выполните.
Тусклые столы — Empdim и Empdate
Create column table Empdim (empId nvarchar(3),Empname nvarchar(100)); Insert into Empdim values('AA1','John'); Insert into Empdim values('BB1','Anand'); Insert into Empdim values('CC1','Jason');
Create column table Empdate (caldate date, CALMONTH nvarchar(4) ,CALYEAR nvarchar(4)); Insert into Empdate values('20100101','04','2010'); Insert into Empdate values('20110101','05','2011'); Insert into Empdate values('20120101','06','2012');
Таблицы фактов — Empfact1, Empfact2
Create column table Empfact1 (empId nvarchar(3), Empdate date, Sal integer ); Insert into Empfact1 values('AA1','20100101',5000); Insert into Empfact1 values('BB1','20110101',10000); Insert into Empfact1 values('CC1','20120101',12000);
Create column table Empfact2 (empId nvarchar(3), deptName nvarchar(20), Bonus integer ); Insert into Empfact2 values ('AA1','SAP', 2000); Insert into Empfact2 values ('BB1','Oracle', 2500); Insert into Empfact2 values ('CC1','JAVA', 1500);
Теперь мы должны реализовать Расчет с помощью Star Join. Сначала измените обе таблицы Dim на представление расчета размеров.
Создайте представление расчета с помощью Star Join. В графической панели добавьте 2 прогноза для 2 таблиц фактов. Добавьте обе таблицы фактов в обе проекции и добавьте атрибуты этих проекций на панель вывода.
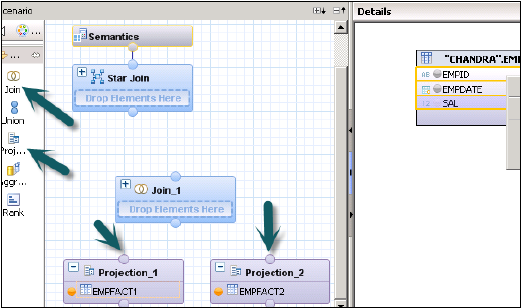
Добавьте соединение из узла по умолчанию и объедините обе таблицы фактов. Добавьте параметры Fact Join в панель вывода.
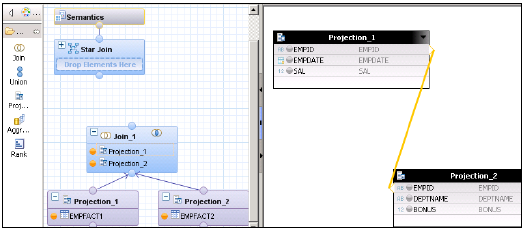
В Star Join добавьте оба вида расчета размеров и добавьте Fact Join к Star Join, как показано ниже. Выберите параметры на панели «Вывод» и активируйте вид.
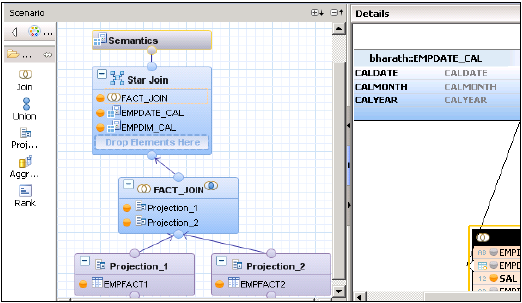
SAP HANA Расчет Расчет — Звездное соединение
После того, как представление успешно активировано, щелкните правой кнопкой мыши на имени представления и нажмите Предварительный просмотр данных. Добавьте атрибуты и меры к осям значений и меток и выполните анализ.
Преимущества использования Star Join
Это упрощает процесс проектирования. Вам не нужно создавать аналитические представления и представления атрибутов, и непосредственно таблицы фактов могут использоваться в качестве проекций.
3NF возможно с Star Join.
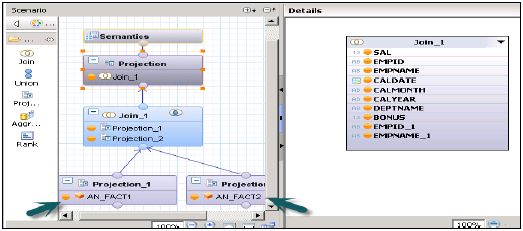
Расчет без звездного соединения
Создайте 2 представления атрибута на 2 Dim таблицах — добавьте вывод и активируйте оба представления.
Создайте 2 аналитических представления для таблиц фактов → Добавьте оба представления атрибутов и Fact1 / Fact2 в основании данных в аналитическом представлении.
Теперь создайте вид расчета → Размер (проекция). Создавайте проекции обоих аналитических видов и объединяйте их. Добавьте атрибуты этого соединения в панель вывода. Теперь присоединитесь к проекции и снова добавьте вывод.
Активируйте представление успешно и перейдите в Предварительный просмотр данных для анализа.
SAP HANA — Аналитические привилегии
Аналитические привилегии используются для ограничения доступа к информационным представлениям HANA. Вы можете назначать разные типы прав разным пользователям в разных компонентах представления в аналитических привилегиях.
Иногда требуется, чтобы данные в том же представлении не были доступны другим пользователям, у которых нет соответствующих требований к этим данным.
пример
Предположим, у вас есть аналитическое представление EmpDetails, в котором есть сведения о сотрудниках компании — имя Emp, идентификатор Emp, отдел, зарплата, дата присоединения, вход в Emp и т. Д. Теперь, если вы не хотите, чтобы ваш разработчик отчетов видел сведения о зарплате или Emp детали входа в систему всех сотрудников, вы можете скрыть это с помощью опции привилегий Analytic.
-
Аналитические привилегии применяются только к атрибутам в информационном представлении. Мы не можем добавлять меры для ограничения доступа в аналитических привилегиях.
-
Аналитические привилегии используются для управления доступом для чтения в информационных представлениях SAP HANA.
Аналитические привилегии применяются только к атрибутам в информационном представлении. Мы не можем добавлять меры для ограничения доступа в аналитических привилегиях.
Аналитические привилегии используются для управления доступом для чтения в информационных представлениях SAP HANA.
Таким образом, мы можем ограничить данные Empname, EmpId, Emp logon или Emp Dept, а не числовыми значениями, такими как зарплата, бонус.
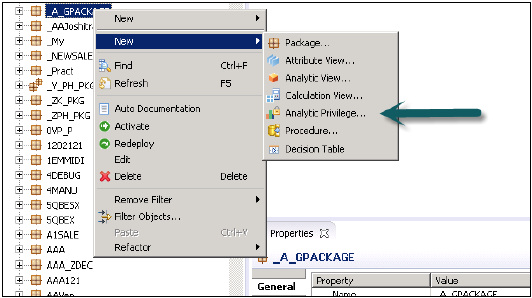
Создание аналитических привилегий
Щелкните правой кнопкой мыши на имени пакета и перейдите к новой привилегии аналитики, или вы можете открыть ее с помощью быстрого запуска HANA Modeler.
Введите имя и описание аналитической привилегии → Готово. Откроется новое окно.
Вы можете нажать кнопку «Далее» и добавить вид моделирования в этом окне, прежде чем нажать «Готово». Существует также возможность скопировать существующий пакет привилегий Analytic.
После того, как вы нажмете кнопку «Добавить», вы увидите все виды на вкладке «Содержимое».
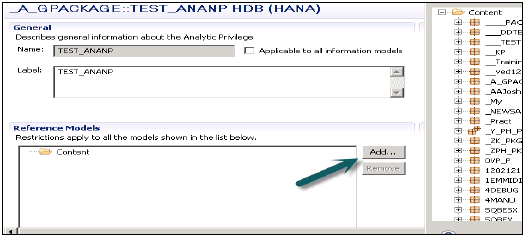
Выберите View, который вы хотите добавить в пакет Analytic Privilege, и нажмите OK. Выбранный вид будет добавлен в справочные модели.
Теперь, чтобы добавить атрибуты из выбранного представления в разделе «Права аналитики», нажмите кнопку «Добавить» в окне «Ограничения связанных атрибутов».
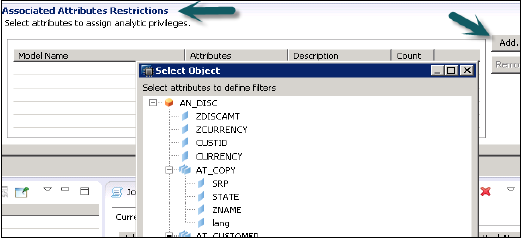
Добавьте объекты, которые вы хотите добавить к привилегиям Analytic, в опции выбора объекта и нажмите OK.
В параметре «Назначить ограничение» он позволяет добавлять значения, которые вы хотите скрыть в представлении моделирования от определенного пользователя. Вы можете добавить значение объекта, которое не будет отображаться в предварительном просмотре данных представления моделирования.
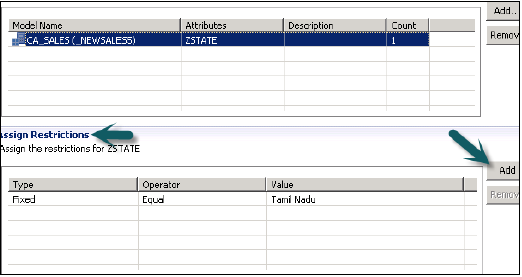
Мы должны активировать Analytic Privilege сейчас, нажав на зеленый круглый значок вверху. Сообщение о состоянии — завершено успешно, подтверждает успешную активацию в журнале заданий, и теперь мы можем использовать это представление, добавив к роли.
Теперь, чтобы добавить эту роль пользователю, перейдите на вкладку безопасности → Пользователь → Выбрать пользователя, к которому вы хотите применить эти аналитические привилегии.
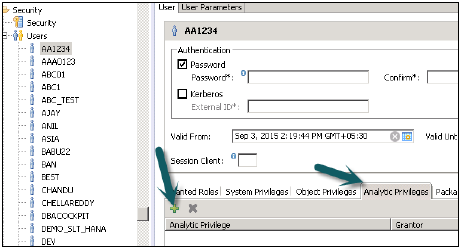
Search Analytic Привилегия, которую вы хотите применить с именем и нажмите кнопку ОК. Это представление будет добавлено к роли пользователя в разделе «Права аналитики».
Чтобы удалить аналитические привилегии от определенного пользователя, выберите вид на вкладке и используйте опцию «Удалить красный». Используйте Deploy (стрелка вверху или F8, чтобы применить это к профилю пользователя).
SAP HANA — Композитор информации
SAP HANA Information Composer — это среда моделирования самообслуживания, позволяющая конечным пользователям анализировать набор данных. Это позволяет импортировать данные из формата рабочей книги (.xls, .csv) в базу данных HANA и создавать представления моделирования для анализа.
Компоновщик информации сильно отличается от HANA Modeler, и оба предназначены для работы с отдельным набором пользователей. Технически здоровые люди, имеющие большой опыт в моделировании данных, используют HANA Modeler. Бизнес-пользователь, у которого нет технических знаний, использует Information Composer. Он предоставляет простые функциональные возможности с простым в использовании интерфейсом.
Особенности информационного композитора
-
Извлечение данных — Information Composer помогает извлекать данные, очищать данные, просматривать данные и автоматизировать процесс создания физической таблицы в базе данных HANA.
-
Манипулирование данными — это помогает нам объединить два объекта (физические таблицы, аналитическое представление, представление атрибутов и представления вычислений) и создать информационное представление, которое может использоваться такими инструментами SAP BO, как SAP Business Objects Analysis, SAP Business Objects Explorer и другими инструментами, такими как MS Excel.
-
Он предоставляет централизованную ИТ-службу в виде URL-адреса, к которой можно получить доступ из любого места.
Извлечение данных — Information Composer помогает извлекать данные, очищать данные, просматривать данные и автоматизировать процесс создания физической таблицы в базе данных HANA.
Манипулирование данными — это помогает нам объединить два объекта (физические таблицы, аналитическое представление, представление атрибутов и представления вычислений) и создать информационное представление, которое может использоваться такими инструментами SAP BO, как SAP Business Objects Analysis, SAP Business Objects Explorer и другими инструментами, такими как MS Excel.
Он предоставляет централизованную ИТ-службу в виде URL-адреса, к которой можно получить доступ из любого места.
Как загрузить данные с помощью Information Composer?
Это позволяет нам загружать большой объем данных (до 5 миллионов ячеек). Ссылка для доступа к информации Composer —
Http: // <сервер>: <порт> / IC
Войдите в SAP HANA Information Composer. Вы можете выполнить загрузку данных или манипулирование с помощью этого инструмента.
Для загрузки данных это можно сделать двумя способами:
- Загрузка файлов .xls, .csv непосредственно в базу данных HANA
- Другой способ — скопировать данные в буфер обмена и скопировать оттуда в базу данных HANA.
- Это позволяет загружать данные вместе с заголовком.
С левой стороны в Information Composer у вас есть три варианта —
Выберите Источник данных → Классифицировать данные → Опубликовать.
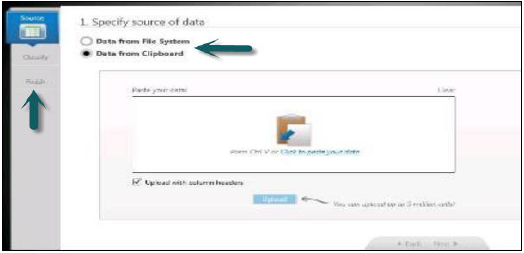
После публикации данных в базе данных HANA вы не можете переименовать таблицу. В этом случае вам необходимо удалить таблицу из схемы в базе данных HANA.
Схема «SAP_IC», где существуют таблицы, такие как IC_MODELS, IC_SPREADSHEETS. Под этими таблицами можно найти подробную информацию о таблицах, созданных с использованием IC.
Использование буфера обмена
Другой способ загрузки данных в IC — использование буфера обмена. Скопируйте данные в буфер обмена и загрузите их с помощью Information Composer. Information Composer также позволяет просматривать предварительный просмотр данных или даже предоставлять сводные данные во временном хранилище. Он имеет встроенную возможность очистки данных, которая используется для устранения любых несоответствий в данных.
После очистки данных вам необходимо классифицировать данные, независимо от того, приписаны ли они. IC имеет встроенную функцию для проверки типа данных загружаемых данных.
Последний шаг — публикация данных в физических таблицах в базе данных HANA. Укажите техническое имя и описание таблицы, и она будет загружена в схему IC_Tables.
Роли пользователя для использования данных, опубликованных с помощью Information Composer
Два набора пользователей могут быть определены для использования данных, опубликованных из IC.
-
IC_MODELER предназначен для создания физических таблиц, загрузки данных и создания информационных представлений.
-
IC_PUBLIC позволяет пользователям просматривать информационные представления, созданные другими пользователями. Эта роль не позволяет пользователю загружать или создавать какие-либо информационные представления с использованием IC.
IC_MODELER предназначен для создания физических таблиц, загрузки данных и создания информационных представлений.
IC_PUBLIC позволяет пользователям просматривать информационные представления, созданные другими пользователями. Эта роль не позволяет пользователю загружать или создавать какие-либо информационные представления с использованием IC.
Системные требования для информационного композитора
Требования к серверу —
-
Требуется минимум 2 ГБ доступной оперативной памяти.
-
Java 6 (64-разрядная версия) должна быть установлена на сервере.
-
Сервер Information Composer должен быть физически расположен рядом с сервером HANA.
Требуется минимум 2 ГБ доступной оперативной памяти.
Java 6 (64-разрядная версия) должна быть установлена на сервере.
Сервер Information Composer должен быть физически расположен рядом с сервером HANA.
Требования к клиенту —
- Internet Explorer с установленным Silverlight 4.
SAP HANA — экспорт и импорт
Опция экспорта и импорта HANA позволяет таблицам, информационным моделям, ландшафтам перемещаться в другую или существующую систему. Вам не нужно заново создавать все таблицы и информационные модели, поскольку вы можете просто экспортировать их в новую систему или импортировать в существующую целевую систему, чтобы уменьшить нагрузку.
Доступ к этой опции можно получить из меню «Файл» вверху или щелкнув правой кнопкой мыши по любой таблице или информационной модели в студии HANA.
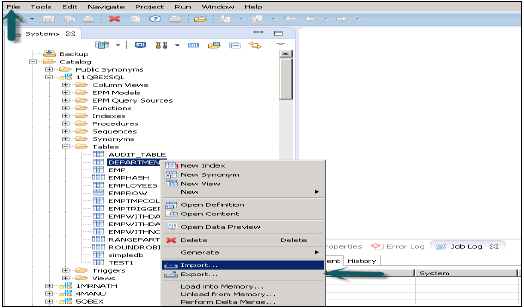
Экспорт таблицы / Информационная модель в HANA Studio
Перейдите в меню «Файл» → «Экспорт» → Вы увидите параметры, как показано ниже —
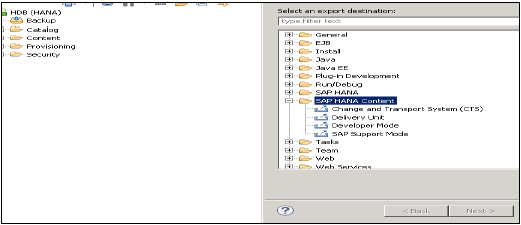
Опции экспорта в SAP HANA Content
Блок доставки
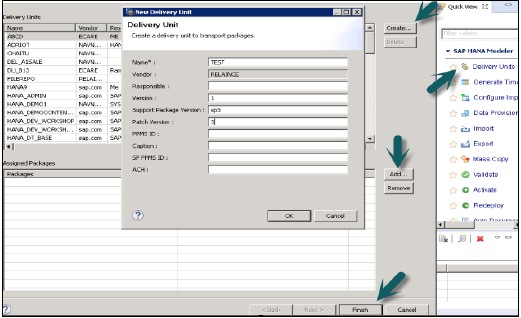
Единица доставки — это единая единица, которая может быть сопоставлена с несколькими пакетами и может быть экспортирована как одна единица, так что все пакеты, назначенные для Единицы доставки, могут рассматриваться как единая единица.
Пользователи могут использовать эту опцию, чтобы экспортировать все пакеты, составляющие единицу доставки, и соответствующие объекты, содержащиеся в ней, на сервер HANA или в локальное расположение клиента.
Пользователь должен создать модуль доставки до его использования.
Это можно сделать с помощью HANA Modeler → Единица доставки → Выбрать систему и Далее → Создать → Заполните данные, такие как Имя, Версия и т. Д. → OK → Добавить пакеты в Единицу доставки → Готово
После создания единицы доставки и присвоения ей пакетов пользователь может просмотреть список пакетов, используя опцию экспорта —
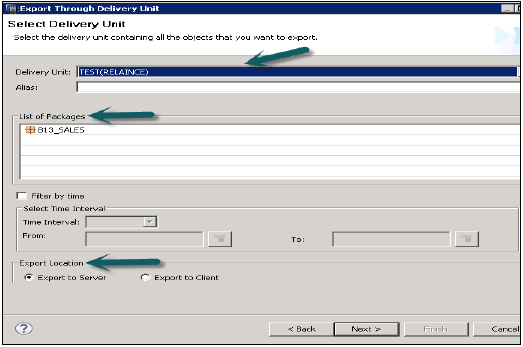
Перейдите в Файл → Экспорт → Единица доставки → Выберите Единицу доставки.
Вы можете увидеть список всех пакетов, назначенных единице доставки. Это дает возможность выбрать место экспорта —
- Экспорт на сервер
- Экспорт на клиента
Вы можете экспортировать модуль доставки либо в расположение сервера HANA, либо в расположение клиента, как показано.
Пользователь может ограничить экспорт через «Фильтр по времени», что означает, что только информационные представления, которые обновляются в течение указанного промежутка времени, будут экспортированы.
Выберите единицу доставки и место экспорта, а затем нажмите кнопку «Далее» → «Готово». Это позволит экспортировать выбранную единицу доставки в указанное место.
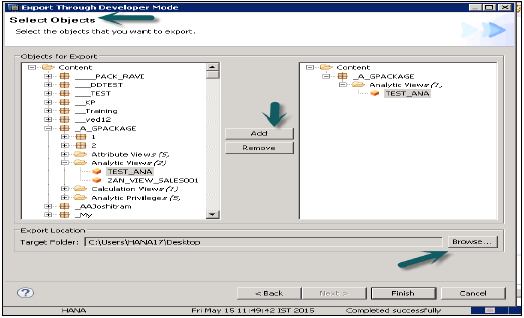
Режим разработчика
Эта опция может использоваться для экспорта отдельных объектов в местоположение в локальной системе. Пользователь может выбрать одно представление информации или группу представлений и пакетов, а также выбрать локальное расположение клиента для экспорта и завершения.
Это показано на снимке ниже.
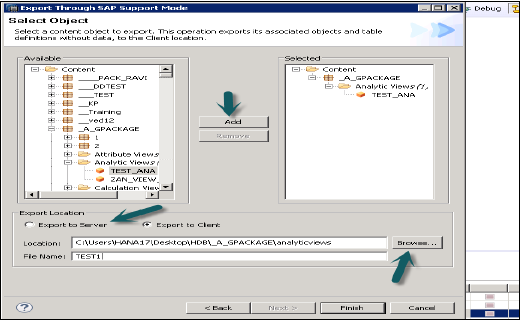
Режим поддержки
Это можно использовать для экспорта объектов вместе с данными в целях поддержки SAP. Это может быть использовано по запросу.
Пример — пользователь создает информационное представление, которое выдает ошибку, и он не может разрешить. В этом случае он может использовать эту опцию, чтобы экспортировать представление вместе с данными и поделиться им с SAP для целей отладки.
Параметры экспорта в SAP HANA Studio —
Пейзаж — для экспорта ландшафта из одной системы в другую.
Таблицы. Этот параметр можно использовать для экспорта таблиц вместе с их содержимым.
Опция импорта в SAP HANA Content
Перейдите в Файл → Импорт. Вы увидите все параметры, как показано ниже в разделе «Импорт».
Данные из локального файла
Это используется для импорта данных из плоского файла, такого как .xls или .csv.
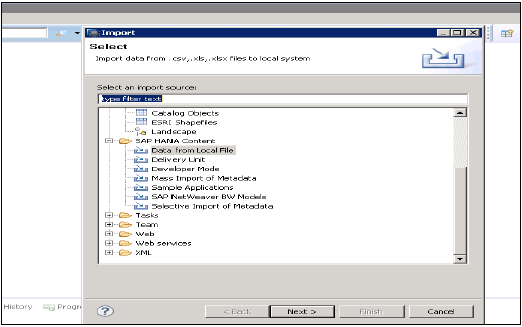
Нажмите на Nex → Выберите Target System → Define Import Properties.
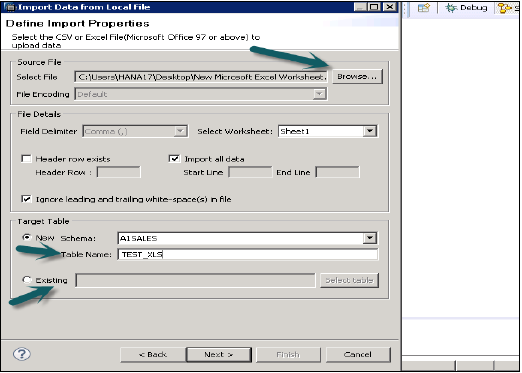
Выберите Исходный файл, просмотрев локальную систему. Это также дает возможность, если вы хотите сохранить строку заголовка. Это также дает возможность создать новую таблицу в существующей схеме или, если вы хотите импортировать данные из файла в существующую таблицу.
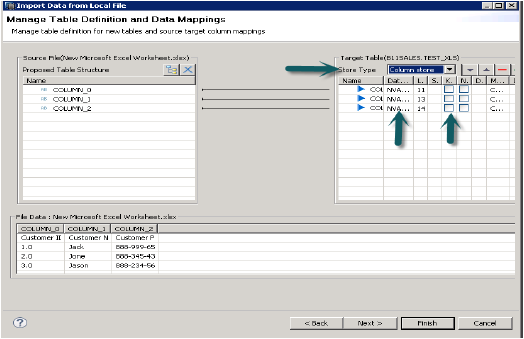
Когда вы нажимаете Далее, это дает возможность определить Первичный ключ, изменить тип данных столбцов, определить тип хранения таблицы, а также позволяет изменить предложенную структуру таблицы.
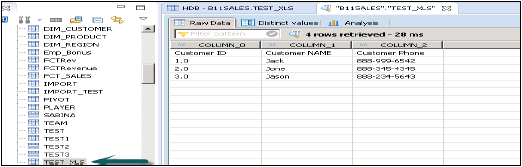
Когда вы нажмете «Готово», эта таблица будет заполнена списком таблиц в указанной схеме. Вы можете выполнить предварительный просмотр данных и проверить определение данных таблицы, и оно будет таким же, как и в файле .xls.
Блок доставки
Выберите Единицу доставки, перейдя в Файл → Импорт → Единица доставки. Вы можете выбрать сервер или локальный клиент.
Вы можете выбрать «Перезаписать неактивные версии», что позволяет перезаписывать любую неактивную версию существующих объектов. Если пользователь выбирает «Активировать объекты», то после импорта все импортированные объекты будут активированы по умолчанию. Пользователю не нужно запускать активацию вручную для импортированных представлений.
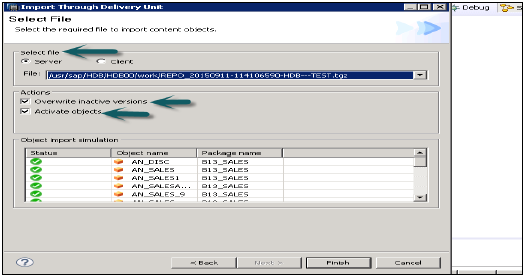
Нажмите «Готово» и после успешного завершения оно будет заполнено целевой системой.
Режим разработчика
Найдите местоположение локального клиента, в которое экспортируются виды, и выберите виды, которые нужно импортировать, пользователь может выбрать отдельные виды или группу видов и пакетов и нажать «Готово».
Массовый импорт метаданных
Перейдите в Файл → Импорт → Массовый импорт метаданных → Далее и выберите исходную и целевую систему.
Настройте систему для массового импорта и нажмите «Готово».
Выборочный импорт метаданных
Это позволяет вам выбирать таблицы и целевую схему для импорта метаданных из приложений SAP.
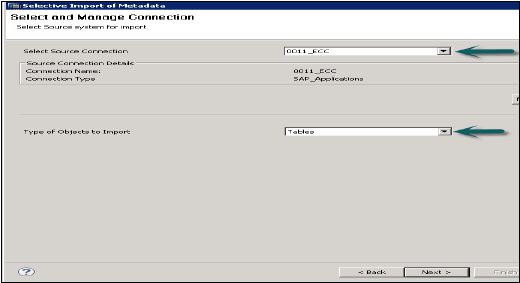
Перейдите в Файл → Импорт → Выборочный импорт метаданных → Далее
Выберите Исходное соединение типа «Приложения SAP». Помните, что хранилище данных должно быть уже создано типа SAP Applications → Click Next
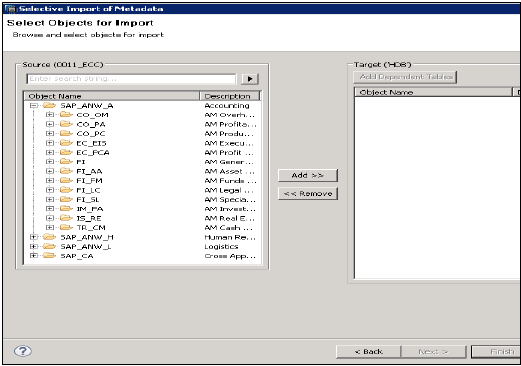
Выберите таблицы, которые вы хотите импортировать и при необходимости проверьте данные. Нажмите Finish после этого.
SAP HANA — представление отчетов
Мы знаем, что с помощью функции информационного моделирования в SAP HANA мы можем создавать различные представления атрибутов информационных представлений, аналитические представления, представления расчета. Эти представления могут использоваться различными инструментами отчетности, такими как SAP Business Object, SAP Lumira, Design Studio, Office Analysis и даже сторонними инструментами, такими как MS Excel.
Эти инструменты отчетности позволяют бизнес-менеджерам, аналитикам, менеджерам по продажам и руководителям высшего звена анализировать историческую информацию, создавать бизнес-сценарии и определять бизнес-стратегию компании.
Это порождает необходимость использования представлений моделирования HANA различными инструментами отчетности и создания отчетов и панелей мониторинга, которые легко понять конечным пользователям.
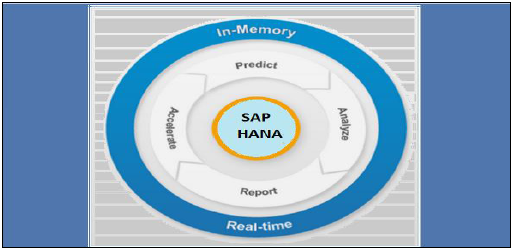
В большинстве компаний, где внедряется SAP, отчетность по HANA осуществляется с помощью инструментов платформ BI, которые используют запросы SQL и MDX с помощью реляционных и OLAP-соединений. Существует множество инструментов BI, таких как Web Intelligence, Crystal Reports, Dashboard, Explorer, Office Analysis и многие другие.
Bi 4.0 Подключение к Hana Views
Инструменты отчетности
Web Intelligence и Crystal Reports являются наиболее распространенными инструментами BI, которые используются для составления отчетов. WebI использует семантический слой под названием Universe для подключения к источнику данных, и эти Universe используются для создания отчетов в инструменте. Эти юниверсы разрабатываются с помощью инструмента проектирования юниверсов UDT или инструмента дизайна информации IDT. IDT поддерживает многоисточниковый источник данных. Однако UDT поддерживает только один источник.
Основные инструменты, которые используются для проектирования интерактивных информационных панелей — Design Studio и Dashboard Designer. Design Studio — это будущий инструмент для проектирования панели мониторинга, которая использует представления HANA через подключение BI-службы обслуживания потребителей BI. Конструкция панели мониторинга (xcelsius) использует IDT для использования схем в базе данных HANA с реляционным или OLAP-соединением.
SAP Lumira имеет встроенную функцию прямого подключения или загрузки данных из базы данных HANA. Представления HANA можно напрямую использовать в Lumira для визуализации и создания историй.
Office Analysis использует соединение OLAP для подключения к представлениям информации HANA. Это соединение OLAP может быть создано в CMC или IDT.
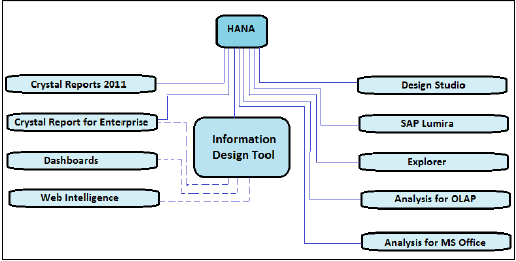
На приведенном выше рисунке показаны все инструменты BI со сплошными линиями, которые можно напрямую подключить и интегрировать с SAP HANA с использованием соединения OLAP. Он также изображает инструменты, которым требуется реляционное соединение с использованием IDT для подключения к HANA, показаны пунктирными линиями.
Реляционное соединение с OLAP
Идея в основном заключается в том, что если вам нужен доступ к данным из таблицы или обычной базы данных, то ваше соединение должно быть реляционным, но если ваш источник — приложение, а данные хранятся в кубе (многомерном, например, инфо-кубы, информационные модели), вы бы использовать соединение OLAP.
- Реляционное соединение может быть создано только в IDT / UDT.
- OLAP может быть создан как в IDT, так и в CMC.
Следует также отметить, что реляционное соединение всегда создает оператор SQL для запуска из отчета, в то время как соединение OLAP обычно создает оператор MDX.
Инструмент информационного дизайна
В средстве дизайна информации (IDT) вы можете создать реляционное соединение с представлением или таблицей SAP HANA с помощью драйверов JDBC или ODBC и построить Universe, используя это соединение, чтобы обеспечить доступ к инструментам клиента, таким как Dashboards и Web Intelligence, как показано на рисунке выше.
Вы можете создать прямое соединение с SAP HANA, используя драйверы JDBC или ODBC.
SAP HANA — Crystal Reports
Crystal Reports для предприятия
В Crystal Reports для Enterprise вы можете получить доступ к данным SAP HANA, используя существующее реляционное соединение, созданное с помощью инструмента дизайна информации.
Вы также можете подключиться к SAP HANA с помощью соединения OLAP, созданного с помощью средства дизайна информации или CMC.
Студия дизайна
Design Studio может получить доступ к данным SAP HANA с помощью существующего соединения OLAP, созданного в средстве дизайна информации или в CMC, аналогично Office Analysis.
Сводки
Панели мониторинга могут подключаться к SAP HANA только через реляционную вселенную. Клиентам, использующим панели мониторинга поверх SAP HANA, следует настоятельно рекомендовать создание новых панелей мониторинга с помощью Design Studio.
Веб-интеллект
Web Intelligence может подключаться к SAP HANA только через реляционную вселенную.
SAP Lumira
Lumira может напрямую подключаться к представлениям SAP HANA Analytic и Calculation. Он также может подключаться к SAP HANA через платформу SAP BI с использованием реляционного юниверса.
Office Analysis, выпуск для OLAP
В выпуске Office Analysis для OLAP вы можете подключиться к SAP HANA с помощью соединения OLAP, определенного в Central Management Console или в средстве дизайна информации.
исследователь
Вы можете создать информационное пространство на основе представления SAP HANA, используя драйверы JDBC.
Создание соединения OLAP в CMC
Мы можем создать соединение OLAP для всех инструментов BI, которые мы хотим использовать поверх представлений HANA, таких как OLAP для анализа, Crystal Report для предприятия, Design Studio. Реляционное соединение через IDT используется для соединения Web Intelligence и Dashboards с базой данных HANA.
Эти соединения могут быть созданы с использованием IDT, а CMC, и оба соединения сохраняются в хранилище BO.
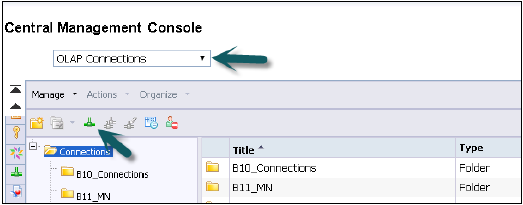
Войдите в CMC с именем пользователя и паролем.
В раскрывающемся списке соединений выберите соединение OLAP. Он также покажет уже созданные подключения в CMC. Чтобы создать новое соединение, перейдите к зеленому значку и нажмите на него.
Введите имя соединения OLAP и описание. Несколько человек для подключения к представлениям HANA в разных инструментах платформы BI могут использовать это соединение.
Провайдер — SAP HANA
Сервер — введите имя сервера HANA
Экземпляр — номер экземпляра
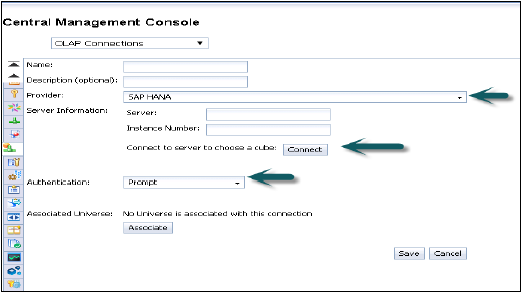
Он также дает возможность подключиться к одному кубу (вы также можете подключиться к одному аналитическому или расчетному представлению) или ко всей системе HANA.
Нажмите «Подключиться» и выберите вид моделирования, введя имя пользователя и пароль.
Типы аутентификации. При создании соединения OLAP в CMC возможны три типа аутентификации.
-
Предопределенный — он не будет запрашивать имя пользователя и пароль при использовании этого подключения.
-
Подсказка — Каждый раз, когда он спросит имя пользователя и пароль
-
SSO — для конкретного пользователя
-
Введите имя пользователя и пароль для системы HANA и сохраните, и новое соединение будет добавлено в существующий список соединений.
Предопределенный — он не будет запрашивать имя пользователя и пароль при использовании этого подключения.
Подсказка — Каждый раз, когда он спросит имя пользователя и пароль
SSO — для конкретного пользователя
Введите имя пользователя и пароль для системы HANA и сохраните, и новое соединение будет добавлено в существующий список соединений.
Теперь откройте BI Launchpad, чтобы открыть все инструменты платформы BI для отчетов, такие как Office Analysis for OLAP, и он попросит выбрать соединение. По умолчанию будет отображаться информационное представление, если вы указали его при создании этого соединения, в противном случае нажмите кнопку «Далее» и перейдите в папки → Выбрать представления (аналитические или расчетные представления).
Связь SAP Lumira с системой HANA
Откройте SAP Lumira из меню «Пуск», выберите «Файл» → «Создать» → «Добавить новый набор данных» → «Подключиться к SAP HANA» → «Далее».
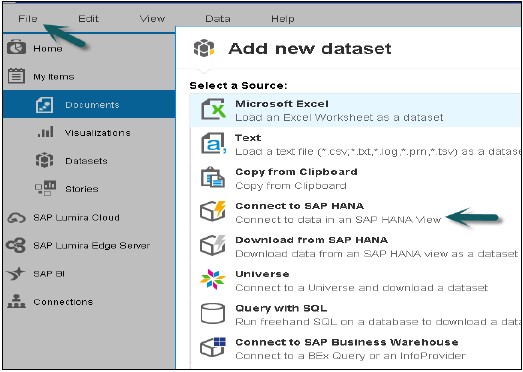
Разница между подключением к SAP HANA и загрузкой из SAP HANA заключается в том, что он будет загружать данные из системы Hana в репозиторий BO, и обновление данных не произойдет при изменениях в системе HANA. Введите имя сервера HANA и номер экземпляра. Введите имя пользователя и пароль → нажмите «Подключиться».
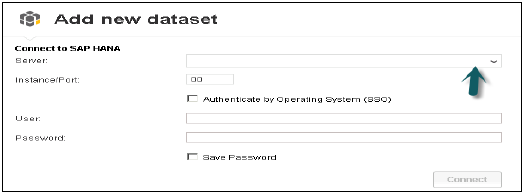
Он покажет все виды. Вы можете искать по названию вида → Выбрать Вид → Далее. Он покажет все размеры и размеры. Вы можете выбрать один из этих атрибутов, если хотите → нажмите на кнопку «Создать».
Внутри SAP Lumira есть четыре вкладки —
-
Подготовить — вы можете просмотреть данные и сделать любой пользовательский расчет.
-
Визуализация — вы можете добавить графики и диаграммы. Нажмите на ось X и ось Y + знак, чтобы добавить атрибуты.
-
Создать — этот параметр можно использовать для создания последовательности визуализации (истории) → нажмите на доску, чтобы добавить номера досок → создать →, она покажет все визуализации слева. Перетащите первую визуализацию, затем добавьте страницу, затем добавьте вторую визуализацию.
-
Поделиться — если он построен на SAP HANA, мы можем публиковать только на сервере SAP Lumira. В противном случае вы также можете опубликовать историю из SAP Lumira в SAP Community Network SCN или BI Platform.
Подготовить — вы можете просмотреть данные и сделать любой пользовательский расчет.
Визуализация — вы можете добавить графики и диаграммы. Нажмите на ось X и ось Y + знак, чтобы добавить атрибуты.
Создать — этот параметр можно использовать для создания последовательности визуализации (истории) → нажмите на доску, чтобы добавить номера досок → создать →, она покажет все визуализации слева. Перетащите первую визуализацию, затем добавьте страницу, затем добавьте вторую визуализацию.
Поделиться — если он построен на SAP HANA, мы можем публиковать только на сервере SAP Lumira. В противном случае вы также можете опубликовать историю из SAP Lumira в SAP Community Network SCN или BI Platform.
Сохраните файл, чтобы использовать его позже → Перейдите в File-Save → выберите Local → Save
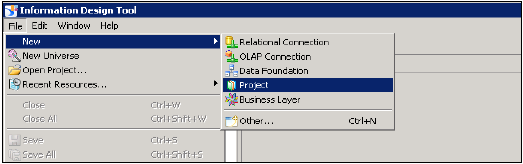
Создание реляционного соединения в IDT для использования с представлениями HANA в WebI и Dashboard —
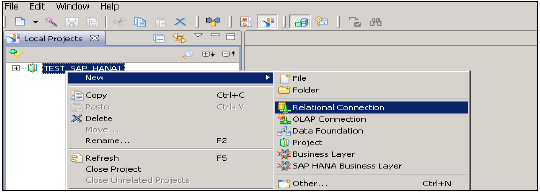
Откройте инструмент дизайна информации →, перейдя в Инструменты клиента BI Platform. Нажмите New → Project. Введите имя проекта → Finish.
Щелкните правой кнопкой мыши имя проекта → Перейти к новому → Выберите реляционное соединение → Введите имя соединения / ресурса → Далее → выберите SAP из списка для подключения к системе HANA → SAP HANA → Выберите драйверы JDBC / ODBC → нажмите Далее → Введите сведения о системе HANA → Нажмите Далее и Готово.
Вы также можете проверить это соединение, нажав на опцию Test Connection.
Проверить соединение → Успешно. Следующий шаг — опубликовать это соединение в репозитории, чтобы сделать его доступным для использования.
Щелкните правой кнопкой мыши по имени соединения → щелкните «Опубликовать соединение с репозиторием» → введите имя и пароль BO репозитория → нажмите «Подключиться» → «Далее» → «Готово» → «Да».
Это создаст новое реляционное соединение с расширением .cns.
.cns — тип соединения представляет защищенное соединение с репозиторием, которое следует использовать для создания основания данных.
.cnx — представляет локальное незащищенное соединение. Если вы используете это соединение при создании и публикации юниверса, оно не позволит вам опубликовать это в хранилище.
Выберите тип подключения .cns → Щелкните правой кнопкой мыши по этому → щелкните Новое основание данных → Введите Имя основания данных → Далее → Один источник / несколько источников → нажмите Далее → Готово.

Он покажет все таблицы в базе данных HANA с именем схемы в средней панели.
Импортируйте все таблицы из базы данных HANA в главную панель, чтобы создать юниверс. Соедините таблицы Dim и Fact с первичными ключами в таблицах Dim, чтобы создать схему.
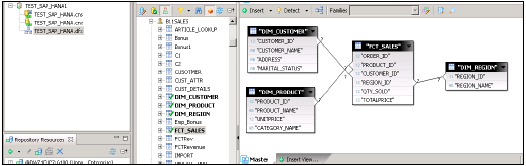
Дважды щелкните по объединениям и определите количество элементов → Определить → ОК → Сохранить все вверху. Теперь нам нужно создать новый бизнес-уровень на основании данных, который будет использоваться инструментами BI-приложений.
Щелкните правой кнопкой мыши на .dfx и выберите новый бизнес-уровень → Введите имя → Готово →. Он покажет все объекты автоматически, под главной панелью →. Замените Измерение на Меры (Тип-Мера измените Проекция по мере необходимости) → Сохранить все.
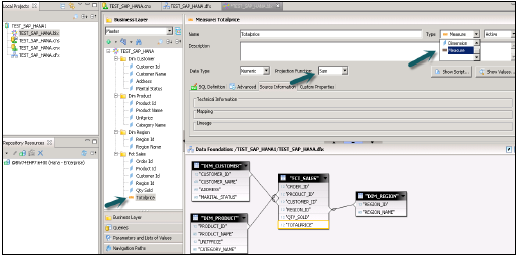
Щелкните правой кнопкой мыши файл .bfx → щелкните «Опубликовать» → «Хранилище» → нажмите «Далее» → «Готово» → «Юниверс опубликован успешно».
Теперь откройте WebI Report из BI Launchpad или Webi rich client из клиентских инструментов BI Platform → Создать → выберите Universe → TEST_SAP_HANA → OK.
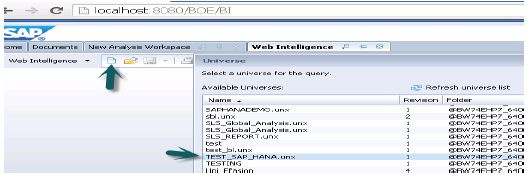
Все объекты будут добавлены на панель запросов. Вы можете выбрать атрибуты и показатели на левой панели и добавить их в объекты результатов. Запрос Run запустит SQL-запрос, и выходные данные будут сгенерированы в форме отчета в WebI, как показано ниже.
SAP HANA — интеграция с Excel
Microsoft Excel считается наиболее распространенным инструментом отчетности и анализа BI во многих организациях. Бизнес-менеджеры и аналитики могут подключить его к базе данных HANA для построения сводных таблиц и диаграмм для анализа.
Подключение MS Excel к HANA
Откройте Excel и перейдите на вкладку «Данные» → из других источников → нажмите «Мастер подключения к данным» → «Другое / Дополнительно» и нажмите «Далее» → Откроется окно свойств ссылки на данные.
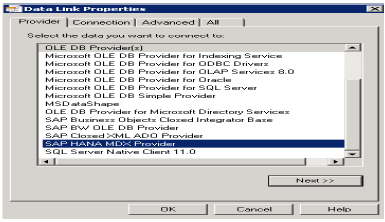
Выберите провайдера SAP HANA MDX из этого списка, чтобы подключиться к любому источнику данных MDX → Введите сведения о системе HANA (имя сервера, экземпляр, имя пользователя и пароль) → нажмите «Проверить соединение» → «Соединение установлено» → «ОК».
Это даст вам список всех пакетов в выпадающем списке, которые доступны в системе HANA. Вы можете выбрать информационное представление → нажмите Далее → Выбрать сводную таблицу / другие → OK.
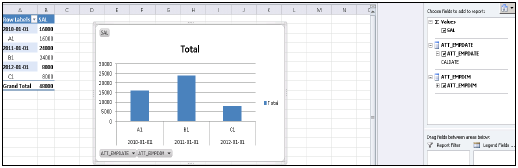
Все атрибуты из информационного представления будут добавлены в MS Excel. Вы можете выбрать различные атрибуты и показатели для отчета, как показано, и вы можете выбрать различные диаграммы, такие как круговые диаграммы и гистограммы, из варианта дизайна вверху.
Все атрибуты из информационного представления будут добавлены в MS Excel. Вы можете выбрать различные атрибуты и показатели для отчета, как показано, и вы можете выбрать различные диаграммы, такие как круговые диаграммы и гистограммы, из варианта дизайна вверху.
SAP HANA — Обзор безопасности
Безопасность означает защиту важных данных компании от несанкционированного доступа и использования, а также обеспечение соответствия требованиям и стандартам в соответствии с политикой компании. SAP HANA позволяет заказчику внедрять различные политики и процедуры безопасности и соответствовать требованиям соответствия компании.
SAP HANA поддерживает несколько баз данных в одной системе HANA, и это называется контейнерами для многопользовательских баз данных. Система HANA также может содержать несколько контейнеров многопользовательской базы данных. Система с несколькими контейнерами всегда имеет ровно одну системную базу данных и любое количество контейнеров многопользовательских баз данных. Система SAP HANA, установленная в этой среде, идентифицируется одним идентификатором системы (SID). Контейнеры базы данных в системе HANA идентифицируются по SID и имени базы данных. Клиент SAP HANA, известный как HANA studio, подключается к конкретным базам данных.
SAP HANA предоставляет все функции, связанные с безопасностью, такие как аутентификация, авторизация, шифрование и аудит, а также некоторые дополнительные функции, которые не поддерживаются в других многопользовательских базах данных.
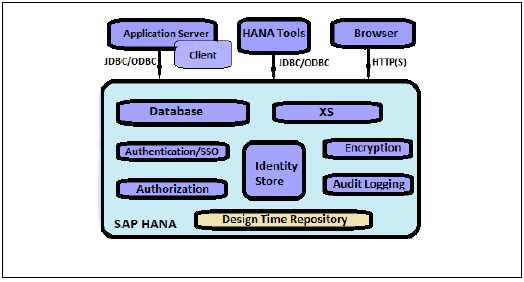
Ниже приведен список функций, связанных с безопасностью, предоставляемых SAP HANA —
- Управление пользователями и ролями
- Аутентификация и единый вход
- авторизация
- Шифрование передачи данных в сети
- Шифрование данных в слое постоянства
Дополнительные функции в многопользовательской базе данных HANA —
-
Изоляция базы данных — включает в себя предотвращение кросс-арендаторских атак через механизм операционной системы.
-
Черный список изменений конфигурации — включает предотвращение изменения определенных системных свойств администраторами базы данных клиентов
-
Ограниченные функции — включает в себя отключение определенных функций базы данных, которые обеспечивают прямой доступ к файловой системе, сети или другим ресурсам.
Изоляция базы данных — включает в себя предотвращение кросс-арендаторских атак через механизм операционной системы.
Черный список изменений конфигурации — включает предотвращение изменения определенных системных свойств администраторами базы данных клиентов
Ограниченные функции — включает в себя отключение определенных функций базы данных, которые обеспечивают прямой доступ к файловой системе, сети или другим ресурсам.
SAP HANA Управление пользователями и ролями
Конфигурация управления пользователями и ролями SAP HANA зависит от архитектуры вашей системы HANA.
-
Если SAP HANA интегрируется с инструментами платформы BI и выступает в качестве базы данных отчетов, то конечный пользователь и роль управляются на сервере приложений.
-
Если конечный пользователь напрямую подключается к базе данных SAP HANA, то для конечных пользователей и администраторов требуются пользователь и роль на уровне базы данных системы HANA.
Если SAP HANA интегрируется с инструментами платформы BI и выступает в качестве базы данных отчетов, то конечный пользователь и роль управляются на сервере приложений.
Если конечный пользователь напрямую подключается к базе данных SAP HANA, то для конечных пользователей и администраторов требуются пользователь и роль на уровне базы данных системы HANA.
Каждый пользователь, желающий работать с базой данных HANA, должен иметь пользователя базы данных с необходимыми привилегиями. Пользователь, получающий доступ к системе HANA, может быть техническим пользователем или конечным пользователем в зависимости от требований доступа. После успешного входа в систему проверяется авторизация пользователя для выполнения требуемой операции. Выполнение этой операции зависит от привилегий, предоставленных пользователю. Эти привилегии могут быть предоставлены с использованием ролей в HANA Security. HANA Studio является одним из мощных инструментов для управления пользователями и ролями в системе баз данных HANA.
Типы пользователей
Типы пользователей различаются в зависимости от политик безопасности и разных привилегий, назначенных в профиле пользователя. Тип пользователя может быть пользователем технической базы данных или конечному пользователю необходим доступ в системе HANA для целей отчетности или для манипулирования данными.
Стандартные пользователи
Обычные пользователи — это пользователи, которые могут создавать объекты в своих собственных схемах и иметь доступ для чтения в информационных моделях системы. Доступ на чтение обеспечивается ролью PUBLIC, которая назначается каждому стандартному пользователю.
Ограниченные пользователи
Ограниченные пользователи — это те пользователи, которые обращаются к системе HANA с помощью некоторых приложений, и у них нет привилегий SQL в системе HANA. Когда эти пользователи созданы, у них нет доступа изначально.
Если мы сравним ограниченных пользователей со стандартными пользователями —
-
Ограниченные пользователи не могут создавать объекты в базе данных HANA или в своих собственных схемах.
-
У них нет доступа к просмотру каких-либо данных в базе данных, поскольку они не имеют общей роли Public, добавленной в профиль, как обычные пользователи.
-
Они могут подключаться к базе данных HANA только через HTTP / HTTPS.
Ограниченные пользователи не могут создавать объекты в базе данных HANA или в своих собственных схемах.
У них нет доступа к просмотру каких-либо данных в базе данных, поскольку они не имеют общей роли Public, добавленной в профиль, как обычные пользователи.
Они могут подключаться к базе данных HANA только через HTTP / HTTPS.
Администрирование пользователей и управление ролями
Пользователи технической базы данных используются только для административных целей, таких как создание новых объектов в базе данных, назначение прав другим пользователям, пакетам, приложениям и т. Д.
Администрирование пользователей SAP HANA
В зависимости от потребностей бизнеса и конфигурации системы HANA, существуют различные действия пользователя, которые могут быть выполнены с использованием инструмента администрирования пользователя, такого как HANA studio.
Наиболее распространенные виды деятельности включают в себя —
- Создать пользователей
- Предоставлять роли пользователям
- Определить и создать роли
- Удаление пользователей
- Сброс паролей пользователей
- Реактивация пользователей после слишком многих неудачных попыток входа
- Деактивация пользователей, когда это требуется
Как создать пользователей в HANA Studio?
Только пользователи базы данных с системной привилегией ROLE ADMIN могут создавать пользователей и роли в HANA studio. Чтобы создать пользователей и роли в HANA studio, перейдите на консоль администратора HANA. Вы увидите вкладку безопасности в системном представлении —
Когда вы открываете вкладку «Безопасность», она предоставляет опцию «Пользователь и роли». Чтобы создать нового пользователя, щелкните правой кнопкой мыши на «Пользователь» и перейдите к «Новый пользователь». Откроется новое окно, в котором вы определяете параметры пользователя и пользователя.
Введите Имя пользователя (мандат) и в поле Аутентификация введите пароль. Пароль применяется при сохранении пароля для нового пользователя. Вы также можете создать ограниченного пользователя.
Указанное имя роли не должно совпадать с именем существующего пользователя или роли. Правила пароля включают минимальную длину пароля и определение того, какие типы символов (нижний, верхний, цифровой, специальные символы) должны быть частью пароля.
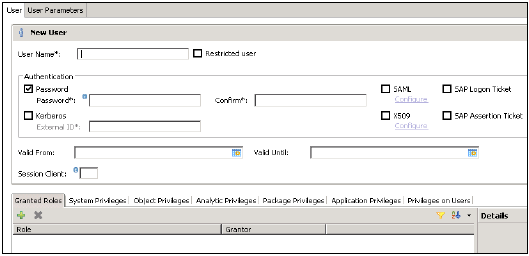
Можно настроить различные методы авторизации, такие как SAML, сертификаты X509, билет SAP Logon и т. Д. Пользователи в базе данных могут проходить проверку подлинности с помощью различных механизмов —
Механизм внутренней аутентификации с использованием пароля.
Внешние механизмы, такие как Kerberos, SAML, SAP Logon Ticket, SAP Assertion Ticket или X.509.
Пользователь может быть аутентифицирован более чем одним механизмом одновременно. Однако только один пароль и одно основное имя для Kerberos могут быть действительными одновременно. Необходимо указать один механизм аутентификации, чтобы пользователь мог подключаться и работать с экземпляром базы данных.
Он также дает возможность определить срок действия пользователя, вы можете указать интервал действия, выбрав даты. Спецификация допустимости является необязательным пользовательским параметром.
Некоторые пользователи, которые по умолчанию поставляются с базой данных SAP HANA, — SYS, SYSTEM, _SYS_REPO, _SYS_STATISTICS.
Как только это будет сделано, следующим шагом будет определение привилегий для профиля пользователя. Существуют различные типы привилегий, которые можно добавить в профиль пользователя.
Предоставленные роли пользователю
Это используется для добавления встроенных ролей SAP.HANA в профиль пользователя или для добавления пользовательских ролей, созданных на вкладке Роли. Пользовательские роли позволяют вам определять роли в соответствии с требованием доступа, и вы можете добавлять эти роли непосредственно в профиль пользователя. Это устраняет необходимость запоминать и добавлять объекты в профиль пользователя каждый раз для разных типов доступа.
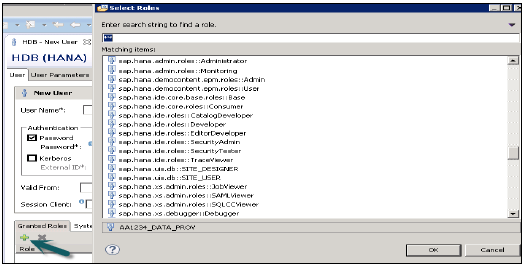
PUBLIC — это общая роль, которая назначается всем пользователям базы данных по умолчанию. Эта роль содержит доступ только для чтения к системным представлениям и привилегии выполнения для некоторых процедур. Эти роли не могут быть отозваны.

моделирование
Он содержит все привилегии, необходимые для использования средства моделирования информации в студии SAP HANA.
Системные привилегии
Существуют различные типы системных привилегий, которые можно добавить в профиль пользователя. Чтобы добавить системные привилегии в профиль пользователя, нажмите + знак.
Системные привилегии используются для резервного копирования / восстановления, администрирования пользователей, запуска и остановки экземпляра и т. Д.
Администратор контента
Он содержит те же привилегии, что и в роли МОДЕЛИРОВАНИЕ, но с добавлением, что этой роли разрешено предоставлять эти привилегии другим пользователям. Он также содержит привилегии хранилища для работы с импортированными объектами.
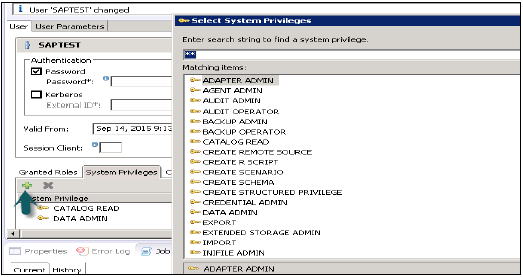
Администратор данных
Это тип привилегии, необходимый для добавления данных из объектов в профиль пользователя.
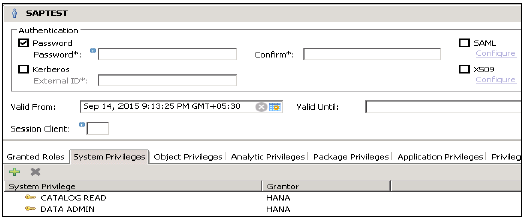
Ниже приведены общие поддерживаемые системные привилегии —
Прикрепить отладчик
Он разрешает отладку вызова процедуры, вызванного другим пользователем. Кроме того, требуется привилегия DEBUG для соответствующей процедуры.
Аудит Админ
Управляет выполнением следующих связанных с аудитом команд — СОЗДАТЬ ПОЛИТИКУ АУДИТА, ПОЛИТИКУ УДАЛЕНИЯ АУДИТА и АЛТЕРНУЮ ПОЛИТИКУ АУДИТА и изменения конфигурации аудита. Также позволяет получить доступ к системному представлению AUDIT_LOG.
Аудитор Оператор
Он разрешает выполнение следующей команды — ALTER SYSTEM CLEAR AUDIT LOG. Также позволяет получить доступ к системному представлению AUDIT_LOG.
Администратор резервного копирования
Он авторизует команды BACKUP и RECOVERY для определения и запуска процедур резервного копирования и восстановления.
Оператор резервного копирования
Он разрешает команде BACKUP инициировать процесс резервного копирования.
Каталог Читать
Он разрешает пользователям иметь нефильтрованный доступ только для чтения ко всем системным представлениям. Обычно содержимое этих представлений фильтруется на основании привилегий пользователя, осуществляющего доступ.
Создать схему
Он разрешает создание схем базы данных с помощью команды CREATE SCHEMA. По умолчанию каждый пользователь владеет одной схемой, с этой привилегией ему разрешено создавать дополнительные схемы.
СОЗДАТЬ СТРУКТУРНУЮ ПРИВИЛЕГИЮ
Он разрешает создание структурированных привилегий (аналитических привилегий). Только владелец аналитической привилегии может предоставлять или отзывать эту привилегию другим пользователям или ролям.
Администратор учетных данных
Он разрешает команды учетных данных — CREATE / ALTER / DROP CREDENTIAL.
Администратор данных
Он разрешает чтение всех данных в системных представлениях. Он также позволяет выполнять любые команды языка определения данных (DDL) в базе данных SAP HANA.
Пользователь, обладающий этой привилегией, не может выбирать или изменять таблицы с хранимыми данными, для которых у него нет прав доступа, но он может удалить таблицы или изменить определения таблиц.
Администратор базы данных
Он разрешает все команды, связанные с базами данных в нескольких базах данных, таких как CREATE, DROP, ALTER, RENAME, BACKUP, RECOVERY.
экспорт
Он разрешает операции экспорта в базу данных с помощью команды EXPORT TABLE.
Обратите внимание, что помимо этой привилегии пользователю требуется экспортировать привилегию SELECT для исходных таблиц.
Импортировать
Он авторизует операции импорта в базе данных с помощью команд IMPORT.
Обратите внимание, что помимо этой привилегии пользователю требуется импортировать привилегию INSERT для таблиц назначения.
Inifile Admin
Это разрешает изменение настроек системы.
Лицензионный администратор
Он разрешает команде SET SYSTEM LICENSE установить новую лицензию.
Администратор журнала
Он разрешает командам ALTER SYSTEM LOGGING [ON | OFF] включать или отключать механизм очистки журнала.
Администратор монитора
Он авторизует команды ALTER SYSTEM для СОБЫТИЙ.
Администратор оптимизатора
Он авторизует команды ALTER SYSTEM, касающиеся команд SQL PLAN CACHE и ALTER SYSTEM UPDATE STATISTICS, которые влияют на поведение оптимизатора запросов.
Resource Admin
Эта привилегия авторизует команды, касающиеся системных ресурсов. Например, «ALTER SYSTEM RECLAIM DATAVOLUME» и «ALTER SYSTEM RESET RESIT MONITORING VIEW». Он также авторизует многие команды, доступные в консоли управления.
Роль Админ
Эта привилегия разрешает создание и удаление ролей с помощью команд CREATE ROLE и DROP ROLE. Он также разрешает предоставление и отзыв ролей с помощью команд GRANT и REVOKE.
Активированные роли, то есть роли, создателем которых является предопределенный пользователь _SYS_REPO, не могут быть предоставлены другим ролям или пользователям и не удалены напрямую. Даже пользователи с правами ROLE ADMIN не могут этого сделать. Пожалуйста, проверьте документацию относительно активированных объектов.
Администратор точки сохранения
Он разрешает выполнение процесса сохранения с помощью команды ALTER SYSTEM SAVEPOINT.
Компоненты базы данных SAP HANA могут создавать новые системные привилегии. Эти привилегии используют имя компонента в качестве первого идентификатора системной привилегии и имя компонента в качестве второго идентификатора.
Привилегии объекта / SQL
Привилегии объекта также известны как привилегии SQL. Эти привилегии используются для предоставления доступа к объектам, таким как Выбор, Вставка, Обновление и Удаление таблиц, Представления или Схемы.
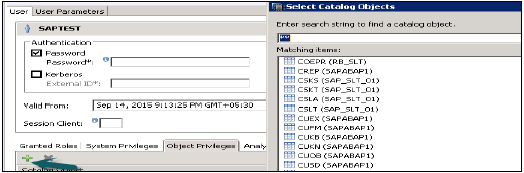
Ниже приведены возможные типы привилегий объекта —
-
Привилегия объекта для объектов базы данных, которые существуют только во время выполнения
-
Привилегия объекта для активированных объектов, созданных в хранилище, например, представления для расчета
-
Объектная привилегия в схеме, содержащей активированные объекты, созданные в хранилище,
-
Привилегии объекта / SQL — это совокупность всех привилегий DDL и DML для объектов базы данных.
Привилегия объекта для объектов базы данных, которые существуют только во время выполнения
Привилегия объекта для активированных объектов, созданных в хранилище, например, представления для расчета
Объектная привилегия в схеме, содержащей активированные объекты, созданные в хранилище,
Привилегии объекта / SQL — это совокупность всех привилегий DDL и DML для объектов базы данных.
Ниже приведены общие поддерживаемые права доступа к объектам.
В базе данных HANA имеется несколько объектов базы данных, поэтому не все привилегии применимы ко всем видам объектов базы данных.
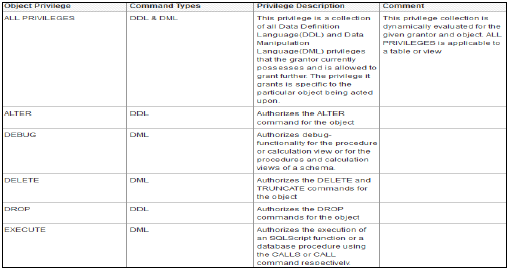
Объектные привилегии и их применимость к объектам базы данных —
Аналитические привилегии
Иногда требуется, чтобы данные в том же представлении не были доступны для других пользователей, у которых нет соответствующих требований к этим данным.
Аналитические привилегии используются для ограничения доступа к информационным представлениям HANA на уровне объекта. Мы можем применить безопасность на уровне строк и столбцов в Аналитических привилегиях.
Аналитические привилегии используются для —
- Выделение безопасности на уровне строк и столбцов для определенного диапазона значений.
- Выделение безопасности на уровне строк и столбцов для модельных представлений.
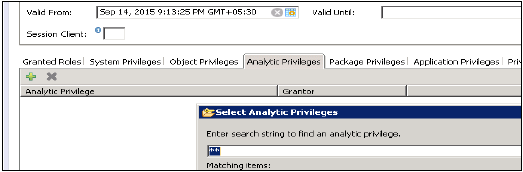
Пакетные привилегии
В репозитории SAP HANA вы можете установить полномочия пакета для конкретного пользователя или для роли. Пакетные привилегии используются для предоставления доступа к моделям данных — аналитическим представлениям или представлениям расчета или к объектам репозитория. Все привилегии, которые назначены пакету репозитория, назначены также всем подпакетам. Вы также можете указать, могут ли назначенные полномочия пользователя передаваться другим пользователям.
Действия по добавлению пакета привилегий в профиль пользователя —
-
Нажмите на вкладку «Права доступа к пакетам» в студии HANA в разделе «Создание пользователя» → «Выбрать +», чтобы добавить один или несколько пакетов. Используйте клавишу Ctrl, чтобы выбрать несколько пакетов.
-
В диалоговом окне «Выбрать пакет репозитория» используйте имя пакета полностью или частично, чтобы найти пакет репозитория, доступ к которому вы хотите разрешить.
-
Выберите один или несколько пакетов репозитория, к которым вы хотите авторизовать доступ, выбранные пакеты появятся на вкладке «Права доступа к пакетам».
Нажмите на вкладку «Права доступа к пакетам» в студии HANA в разделе «Создание пользователя» → «Выбрать +», чтобы добавить один или несколько пакетов. Используйте клавишу Ctrl, чтобы выбрать несколько пакетов.
В диалоговом окне «Выбрать пакет репозитория» используйте имя пакета полностью или частично, чтобы найти пакет репозитория, доступ к которому вы хотите разрешить.
Выберите один или несколько пакетов репозитория, к которым вы хотите авторизовать доступ, выбранные пакеты появятся на вкладке «Права доступа к пакетам».
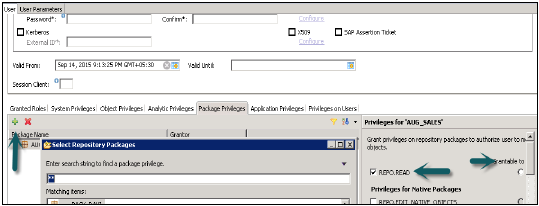
Ниже приведены привилегии предоставления, которые используются в пакетах репозитория для авторизации пользователя на изменение объектов.
-
REPO.READ — доступ для чтения к выбранному пакету и объектам времени разработки (как собственным, так и импортированным)
-
REPO.EDIT_NATIVE_OBJECTS — авторизация для изменения объектов в пакетах.
-
Предоставляется другим — если вы выберете «Да» для этого, это позволит назначенному пользователю передавать полномочия другим пользователям.
REPO.READ — доступ для чтения к выбранному пакету и объектам времени разработки (как собственным, так и импортированным)
REPO.EDIT_NATIVE_OBJECTS — авторизация для изменения объектов в пакетах.
Предоставляется другим — если вы выберете «Да» для этого, это позволит назначенному пользователю передавать полномочия другим пользователям.
Привилегии приложений
Привилегии приложения в профиле пользователя используются для определения авторизации доступа к приложению HANA XS. Это может быть назначено отдельному пользователю или группе пользователей. Привилегии приложения также можно использовать для обеспечения различного уровня доступа к одному и тому же приложению, например, для предоставления расширенных функций администраторам базы данных и доступа только для чтения для обычных пользователей.
Чтобы определить специфичные для Приложения привилегии в профиле пользователя или добавить группу пользователей, следует использовать следующие привилегии:
- Файл привилегий приложения (.xsprivileges)
- Файл доступа к приложению (.xsaccess)
- Файл определения роли (<RoleName> .hdbrole)
SAP HANA — Аутентификации
Все пользователи SAP HANA, имеющие доступ к базе данных HANA, проверяются с использованием другого метода аутентификации. Система SAP HANA поддерживает различные типы методов аутентификации, и все эти методы входа в систему настраиваются во время создания профиля.
Ниже приведен список методов аутентификации, поддерживаемых SAP HANA.
- Имя пользователя Пароль
- Kerberos
- SAML 2.0
- SAP Logon билеты
- X.509
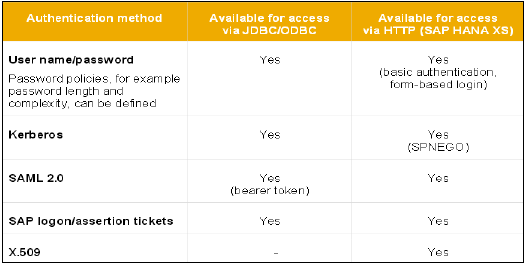
Имя пользователя Пароль
Этот метод требует, чтобы пользователь HANA вводил имя пользователя и пароль для входа в базу данных. Этот профиль пользователя создается в разделе «Управление пользователями» в HANA Studio → вкладка «Безопасность».
Пароль должен соответствовать политике паролей, т.е. длина, сложность пароля, строчные и прописные буквы и т. Д.
Вы можете изменить политику паролей в соответствии со стандартами безопасности вашей организации. Обратите внимание, что политика паролей не может быть деактивирована.
Kerberos
Все пользователи, которые подключаются к системе базы данных HANA с использованием метода внешней аутентификации, также должны иметь пользователя базы данных. Требуется сопоставить внешний вход в систему с пользователем внутренней базы данных.
Этот метод позволяет пользователям аутентифицировать систему HANA напрямую, используя драйверы JDBC / ODBC через сеть или с помощью приложений переднего плана в SAP Business Objects.
Это также позволяет HTTP-доступ в расширенной службе HANA с использованием механизма HANA XS. Он использует механизм SPENGO для аутентификации Kerberos.
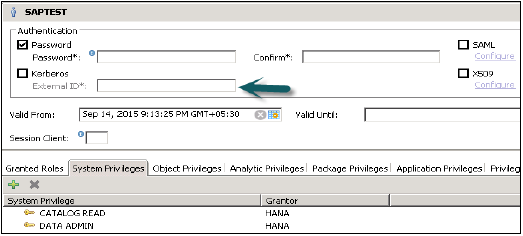
SAML
SAML расшифровывается как язык разметки безопасности и может использоваться для аутентификации пользователей, обращающихся к системе HANA напрямую с клиентов ODBC / JDBC. Он также может использоваться для аутентификации пользователей в системе HANA, поступающей по протоколу HTTP через механизм HANA XS.
SAML используется только для аутентификации, а не для авторизации.
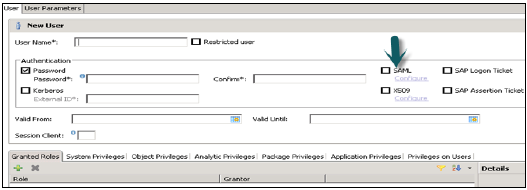
Билеты на вход и утверждение SAP
Билеты на вход / утверждение SAP можно использовать для аутентификации пользователей в системе HANA. Эти билеты выдаются пользователям при входе в систему SAP, которая настроена на выдачу таких билетов, как SAP Portal и т. Д. Пользователь, указанный в билетах входа SAP, должен быть создан в системе HANA, поскольку он не обеспечивает поддержку сопоставления пользователей.
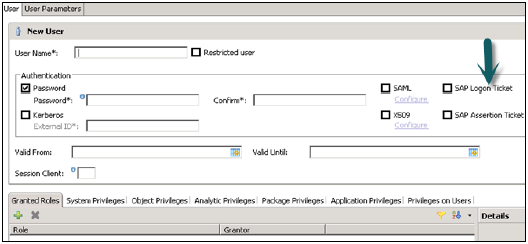
Клиентские сертификаты X.509
Сертификаты X.509 также можно использовать для входа в систему HANA через HTTP-запрос доступа от механизма HANA XS. Пользователи аутентифицируются сертифицированными, подписанными доверенным центром сертификации, который хранится в системе HANA XS.
Пользователь в доверенном сертификате должен существовать в системе HANA, поскольку отсутствует поддержка сопоставления пользователей.
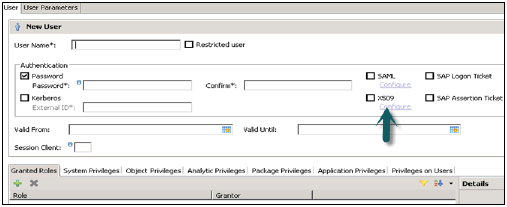
Единый вход в систему HANA
Единый вход может быть настроен в системе HANA, что позволяет пользователям входить в систему HANA с первоначальной аутентификации на клиенте. Пользователь регистрируется в клиентских приложениях, используя разные методы аутентификации, а SSO позволяет пользователю напрямую обращаться к системе HANA.
SSO может быть настроен на следующих методах настройки —
- SAML
- Kerberos
- Клиентские сертификаты X.509 для HTTP-доступа из движка HANA XS
- SAP Logon / Утверждение билетов
SAP HANA — Методы авторизации
Авторизация проверяется, когда пользователь пытается подключиться к базе данных HANA и выполнить некоторые операции с базой данных. Когда пользователь подключается к базе данных HANA с помощью клиентских инструментов через JDBC / ODBC или через HTTP для выполнения некоторых операций над объектами базы данных, соответствующее действие определяется доступом, предоставленным пользователю.
Привилегии, предоставляемые пользователю, определяются объектными привилегиями, назначенными для профиля пользователя или роли, которая была предоставлена пользователю. Авторизация — это комбинация обоих доступов. Когда пользователь пытается выполнить какую-либо операцию с базой данных HANA, система выполняет проверку авторизации. Когда все необходимые привилегии найдены, система останавливает эту проверку и предоставляет запрошенный доступ.
Существуют различные типы привилегий, которые используются в SAP HANA, как указано в разделе «Роль пользователя и управление».
Системные привилегии
Они применимы к системе и авторизации базы данных для пользователей и деятельности системы управления. Они используются для административных задач, таких как создание схем, резервное копирование данных, создание пользователей и ролей и так далее. Системные привилегии также используются для выполнения операций репозитория.
Привилегии объекта
Они применимы к операциям базы данных и применяются к объектам базы данных, таким как таблицы, схемы и т. Д. Они используются для управления объектами базы данных, такими как таблицы и представления. Различные действия, такие как выбор, выполнение, изменение, удаление, удаление могут быть определены на основе объектов базы данных.
Они также используются для управления удаленными объектами данных, которые связаны через SMART-доступ к данным в SAP HANA.
Аналитические привилегии
Они применимы к данным внутри всех пакетов, созданных в репозитории HANA. Они используются для управления представлениями моделирования, которые создаются внутри пакетов, таких как представление атрибутов, аналитическое представление и представление расчета. Они применяют безопасность на уровне строк и столбцов к атрибутам, которые определены в представлениях моделирования в пакетах HANA.
Пакетные привилегии
Они применимы для предоставления доступа и возможности использовать пакеты, созданные в хранилище базы данных HANA. Пакет содержит различные представления моделирования, такие как представления атрибутов, аналитики и расчета, а также аналитические привилегии, определенные в базе данных репозитория HANA.
Привилегии приложений
Они применимы к приложению HANA XS, которое обращается к базе данных HANA через HTTP-запрос. Они используются для управления доступом к приложениям, созданным с помощью механизма HANA XS.
Привилегии приложений могут быть применены к пользователям / ролям напрямую с использованием HANA studio, но предпочтительно, чтобы они применялись к ролям, созданным в репозитории во время разработки.
Авторизация репозитория в базе данных SAP HANA
_SYS_REPO — пользователь владеет всеми объектами в хранилище HANA. Этот пользователь должен получить внешнюю авторизацию для объектов, на которых моделируются объекты репозитория в системе HANA. _SYS_REPO является владельцем всех объектов, поэтому его можно использовать только для предоставления доступа к этим объектам, никакой другой пользователь не может войти в систему как пользователь _SYS_REPO.
ВЫБРАТЬ ГРАНТ В СХЕМЕ «<SCHEMA_NAME>» ДЛЯ _SYS_REPO С ГРАНИТОМ
SAP HANA — Управление лицензиями
SAP HANA Управление лицензиями и ключи необходимы для использования базы данных HANA. Вы можете установить или удалить лицензионные ключи HANA, используя HANA studio.
Типы лицензионных ключей
Система SAP HANA поддерживает два типа лицензионных ключей —
-
Временный лицензионный ключ — временные лицензионные ключи автоматически устанавливаются при установке базы данных HANA. Эти ключи действительны только в течение 90 дней, и вы должны запросить постоянные лицензионные ключи у SAP Marketplace до истечения этого 90-дневного периода после установки.
-
Ключ постоянной лицензии. Ключи постоянной лицензии действительны только до истечения срока действия. Лицензионные ключи определяют объем памяти, выделенной для целевой установки HANA. Их можно установить из SAP Marketplace на вкладке Ключи и запросы. Когда срок действия постоянного Лицензионного ключа истек, выдается временный лицензионный ключ, который действителен только в течение 28 дней. В течение этого периода вам необходимо снова установить постоянный лицензионный ключ.
Временный лицензионный ключ — временные лицензионные ключи автоматически устанавливаются при установке базы данных HANA. Эти ключи действительны только в течение 90 дней, и вы должны запросить постоянные лицензионные ключи у SAP Marketplace до истечения этого 90-дневного периода после установки.
Ключ постоянной лицензии. Ключи постоянной лицензии действительны только до истечения срока действия. Лицензионные ключи определяют объем памяти, выделенной для целевой установки HANA. Их можно установить из SAP Marketplace на вкладке Ключи и запросы. Когда срок действия постоянного Лицензионного ключа истек, выдается временный лицензионный ключ, который действителен только в течение 28 дней. В течение этого периода вам необходимо снова установить постоянный лицензионный ключ.
Существует два типа постоянных лицензионных ключей для системы HANA —
-
Unenforced — если установлен неисполненный лицензионный ключ и потребление системы HANA превышает объем лицензии, то в этом случае на работу SAP HANA не влияют.
-
Enforced — если установлен лицензионный ключ Enforced и потребление системы HANA превышает объем лицензии, то система HANA блокируется. В этом случае необходимо перезапустить систему HANA или запросить и установить новый лицензионный ключ.
Unenforced — если установлен неисполненный лицензионный ключ и потребление системы HANA превышает объем лицензии, то в этом случае на работу SAP HANA не влияют.
Enforced — если установлен лицензионный ключ Enforced и потребление системы HANA превышает объем лицензии, то система HANA блокируется. В этом случае необходимо перезапустить систему HANA или запросить и установить новый лицензионный ключ.
Существуют различные сценарии лицензирования, которые можно использовать в системе HANA, в зависимости от ландшафта системы (Автономный, HANA Cloud, BW на HANA и т. Д.), И не все эти модели основаны на памяти установки системы HANA.
Как проверить лицензионные свойства HANA
Щелкните правой кнопкой мыши на системе HANA → Свойства → Лицензия
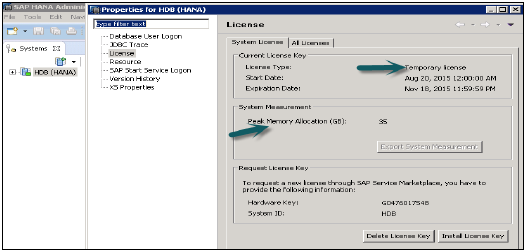
В нем рассказывается о типе лицензии, дате начала и дате истечения срока действия, распределении памяти и информации (аппаратный ключ, идентификатор системы), которая требуется для запроса новой лицензии через SAP Market Place.
Установить лицензионный ключ → Обзор → Ввести путь, используется для установки нового лицензионного ключа, а опция удаления — для удаления любого старого ключа с истекшим сроком действия.
На вкладке Все лицензии в разделе Лицензия указывается название продукта, описание, аппаратный ключ, время первой установки и т. Д.
SAP HANA — Аудит
Политика аудита SAP HANA сообщает о действиях, подлежащих аудиту, а также об условии, при котором действие должно выполняться, чтобы иметь отношение к аудиту. Политика аудита определяет, какие действия были выполнены в системе HANA, и кто и когда выполнял эти действия.
Функция аудита базы данных SAP HANA позволяет отслеживать действия, выполняемые в системе HANA. Политика использования SAP HANA должна быть активирована в системе HANA для ее использования. Когда действие выполнено, политика вызывает событие аудита для записи в журнал аудита. Вы также можете удалить записи аудита в журнале аудита.
В распределенной среде, где у вас есть несколько баз данных, политика аудита может быть включена в каждой отдельной системе. Для системной базы данных политика аудита определяется в файле nameserver.ini, а для базы данных арендатора — в файле global.ini.
Активация политики аудита
Для определения политики аудита в системе HANA у вас должна быть системная привилегия — Audit Admin.
Перейдите к опции «Безопасность» в системе HANA → Аудит
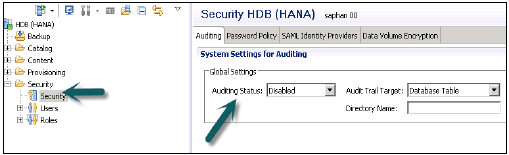
В разделе Глобальные настройки → установите статус аудита как включенный.
Вы также можете выбрать цели аудита. Возможны следующие цели контрольного журнала —
-
Системный журнал (по умолчанию) — система регистрации операционной системы Linux.
-
Таблица базы данных — внутренняя таблица базы данных, пользователь, имеющий системную привилегию Audit admin или Audit operator, может выполнять только операцию выбора для этой таблицы.
-
Текст CSV — этот тип контрольного журнала используется только для целей тестирования в непроизводственной среде.
Системный журнал (по умолчанию) — система регистрации операционной системы Linux.
Таблица базы данных — внутренняя таблица базы данных, пользователь, имеющий системную привилегию Audit admin или Audit operator, может выполнять только операцию выбора для этой таблицы.
Текст CSV — этот тип контрольного журнала используется только для целей тестирования в непроизводственной среде.
Вы также можете создать новую политику аудита в области «Политики аудита» → выбрать «Создать новую политику». Введите название политики и действия для аудита.
Сохраните новую политику, используя кнопку Deploy. Новая политика включается автоматически, когда выполняется условие действия, в таблице журнала аудита создается запись аудита. Вы можете отключить политику, изменив статус, чтобы отключить, или вы также можете удалить политику.
SAP HANA — Обзор репликации данных
Репликация SAP HANA позволяет переносить данные из исходных систем в базу данных SAP HANA. Простой способ перенести данные из существующей системы SAP в HANA — использовать различные методы репликации данных.
Репликация системы может быть настроена на консоли через командную строку или с помощью HANA studio. Основной ECC или транзакционные системы могут оставаться в сети во время этого процесса. У нас есть три типа методов репликации данных в системе HANA —
- Метод репликации SAP LT
- Инструмент ETL Метод службы данных бизнес-объекта SAP (BODS)
- Метод прямого подключения экстрактора (DXC)
Метод репликации SAP LT
Репликация преобразования ландшафта SAP — это метод репликации данных на основе триггера в системе HANA. Это идеальное решение для репликации данных в режиме реального времени или репликации на основе расписания из источников SAP и сторонних производителей. Он имеет сервер репликации SAP LT, который отвечает за все триггерные запросы. Сервер репликации может быть установлен как автономный сервер или может работать в любой системе SAP с SAP NW 7.02 или выше.
Существует надежное RFC-соединение между БД HANA и транзакционной системой ECC, которое обеспечивает репликацию данных на основе триггера в системной среде HANA.
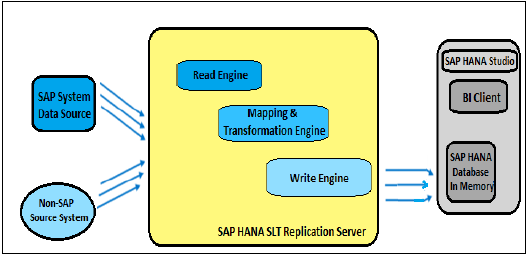
Преимущества репликации SLT
-
Метод SLT Replication позволяет реплицировать данные из нескольких исходных систем в одну систему HANA, а также из одной исходной системы в несколько систем HANA.
-
SAP LT использует триггерный подход. Он не оказывает заметного влияния на производительность исходной системы.
-
Он также обеспечивает преобразование данных и возможность фильтрации перед загрузкой в базу данных HANA.
-
Он позволяет реплицировать данные в режиме реального времени, реплицируя только соответствующие данные в HANA из исходных систем SAP и сторонних производителей.
-
Он полностью интегрирован с системой HANA и студией HANA.
Метод SLT Replication позволяет реплицировать данные из нескольких исходных систем в одну систему HANA, а также из одной исходной системы в несколько систем HANA.
SAP LT использует триггерный подход. Он не оказывает заметного влияния на производительность исходной системы.
Он также обеспечивает преобразование данных и возможность фильтрации перед загрузкой в базу данных HANA.
Он позволяет реплицировать данные в режиме реального времени, реплицируя только соответствующие данные в HANA из исходных систем SAP и сторонних производителей.
Он полностью интегрирован с системой HANA и студией HANA.
Создание надежного RFC-соединения в системе ECC
В вашей исходной системе SAP AA1 вы хотите установить доверенный RFC для целевой системы BB1. Когда это будет сделано, это будет означать, что когда вы вошли на AA1 и у вашего пользователя достаточно авторизации на BB1, вы можете использовать RFC-соединение и войти на BB1 без необходимости повторного ввода имени пользователя и пароля.
Используя доверительные / доверительные отношения RFC между двумя системами SAP: от доверенной системы RFC до доверяющей системы, пароль для входа в доверяющую систему не требуется.
Откройте систему SAP ECC, используя вход в систему SAP. Введите номер транзакции sm59 → это номер транзакции для создания нового доверенного RFC-соединения → Нажмите на 3- й значок, чтобы открыть мастер нового соединения → нажмите «Создать», и откроется новое окно.
RFC-адрес ECCHANA (введите имя RFC-адресата) Тип подключения — 3 (для системы ABAP)
Перейти к технической настройке
Введите Target host — имя системы ECC, IP и введите номер системы.
Перейдите на вкладку Вход в систему и безопасность, введите язык, клиент, имя пользователя и пароль системы ECC.
Нажмите на опцию Сохранить вверху.

Нажмите на Test Connection, и он успешно проверит соединение.
Настроить RFC-соединение
Запустите транзакцию — ltr (для настройки RFC-соединения) → Откроется новый браузер → введите имя пользователя и пароль системы ECC и войдите в систему.

Нажмите New → Откроется новое окно → Введите имя конфигурации → Нажмите Next → Enter RFC Destination (имя подключения, созданное ранее), используйте опцию поиска, выберите имя и нажмите Next.
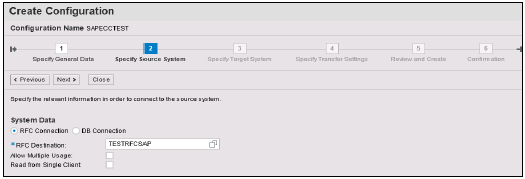
В поле «Укажите целевую систему» введите имя пользователя и пароль администратора системы HANA, имя хоста, номер экземпляра и нажмите «Далее». Введите Нет заданий передачи данных, например 007 (не может быть 000) → Далее → Создать конфигурацию.
Теперь перейдите в HANA Studio, чтобы использовать это соединение —
Перейдите в HANA Studio → Нажмите «Предоставление данных» → выберите систему HANA.
Выберите исходную систему (имя надежного RFC-соединения) и имя целевой схемы, куда вы хотите загрузить таблицы из системы ECC. Выберите таблицы, которые вы хотите переместить в базу данных HANA → ДОБАВИТЬ → Готово.
Выбранные таблицы будут перемещены в выбранную схему в базе данных HANA.
SAP HANA — Репликация на основе ETL
Репликация на основе SAP HANA ETL использует SAP Data Services для переноса данных из исходной системы SAP или не-SAP в целевую базу данных HANA. Система BODS — это инструмент ETL, используемый для извлечения, преобразования и загрузки данных из исходной системы в целевую систему.
Это позволяет читать бизнес-данные на уровне приложений. Вам необходимо определить потоки данных в службах данных, запланировать задание репликации и определить исходную и целевую системы в хранилище данных в конструкторе служб данных.
Как использовать репликацию на основе ETL SAP HANA Data Services?
Войдите в Data Services Designer (выберите «Репозиторий») → Создать хранилище данных
Для системы SAP ECC выберите базу данных в качестве приложений SAP, введите имя сервера ECC, имя пользователя и пароль для системы ECC, на вкладке «Дополнительно» выберите детали в качестве номера экземпляра, номера клиента и т. Д. И примените.
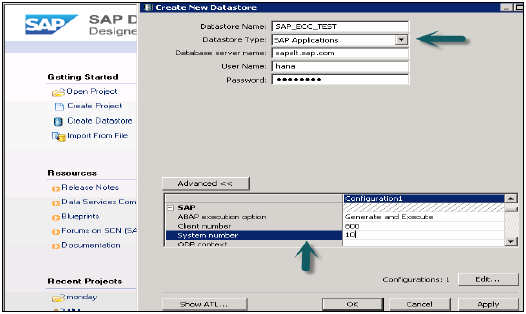
Это хранилище данных попадет в локальную библиотеку объектов, если вы развернете ее, в ней нет таблицы.
Щелкните правой кнопкой мыши Таблица → Импорт по имени → Введите таблицу ECC для импорта из системы ECC (MARA является таблицей по умолчанию в системе ECC) → Импорт → Теперь разверните Таблица → MARA → Просмотр данных правой кнопкой мыши. Если данные отображаются, подключение к хранилищу данных в порядке.
Теперь, чтобы выбрать целевую систему в качестве базы данных HANA, создайте новое хранилище данных. Создать хранилище данных → Имя хранилища данных SAP_HANA_TEST → Тип хранилища данных (база данных) → Тип базы данных SAP HANA → Версия базы данных HANA 1.x.
Введите имя сервера HANA, имя пользователя и пароль для системы HANA и OK.
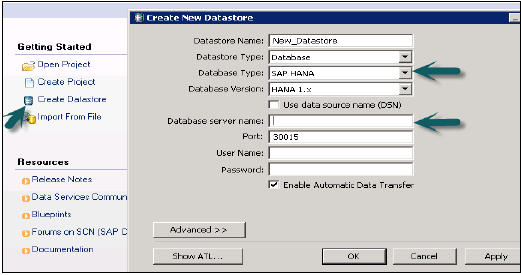
Это хранилище данных будет добавлено в локальную библиотеку объектов. Вы можете добавить таблицу, если хотите переместить данные из исходной таблицы в какую-то конкретную таблицу в базе данных HANA. Обратите внимание, что таблица назначения должна иметь тот же тип данных, что и исходная таблица.
Создание задания репликации
Создайте новый проект → введите имя проекта → щелкните правой кнопкой мыши имя проекта → новое пакетное задание → введите имя задания.
На правой боковой вкладке выберите рабочий поток → введите имя рабочего потока → дважды щелкните, чтобы добавить его в пакетное задание → введите поток данных → введите имя потока данных → дважды щелкните, чтобы добавить его в пакетное задание в области проекта.

Перетащите таблицу из First Data Store ECC (MARA) в рабочую область. Выберите его и щелкните правой кнопкой мыши → Добавить новую → Шаблонную таблицу, чтобы создать новую таблицу с аналогичными типами данных в БД HANA → Введите имя таблицы, Хранилище данных ECC_HANA_TEST2 → Имя владельца (имя схемы) → OK
Перетащите таблицу вперед и соедините обе таблицы → сохранить все. Теперь перейдите к пакетному заданию → Щелкните правой кнопкой мыши → Выполнить → Да → ОК.
Выполнив задание репликации, вы получите подтверждение того, что задание было успешно завершено.
Перейдите в HANA studio → Разверните схему → Таблицы → Проверьте данные. Это ручное выполнение пакетного задания.
Планирование пакетной работы
Вы также можете запланировать пакетное задание, перейдя в консоль управления службами данных. Войдите в консоль управления службами данных.
Выберите хранилище с левой стороны → Перейдите на вкладку «Конфигурация пакетных заданий», где вы увидите список заданий → По заданию, которое вы хотите запланировать → нажмите «Добавить расписание» → Введите «имя расписания» и установите параметры, такие как ( время, дата, повторение и т. д.) в зависимости от ситуации и нажмите «Применить».
SAP HANA — Репликация на основе журнала
Это также известно как Sybase Replication в системе HANA. Основными компонентами этого метода репликации являются агент репликации Sybase, который является частью исходной системы приложений SAP, агент репликации и сервер репликации Sybase, который должен быть реализован в системе SAP HANA.
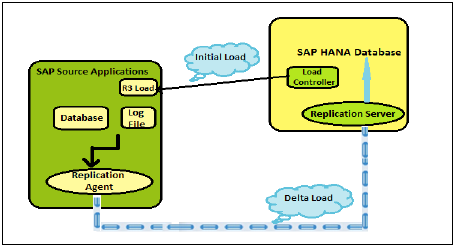
Начальная загрузка в методе Sybase Replication инициируется Load Controller и запускается администратором в SAP HANA. Он сообщает R3 Load для передачи начальной загрузки в базу данных HANA. Загрузка R3 в исходной системе экспортирует данные для выбранных таблиц в исходной системе и передает эти данные в компоненты загрузки R3 в системе HANA. Загрузка R3 в целевой системе импортирует данные в базу данных SAP HANA.
Агент хоста SAP управляет аутентификацией между исходной системой и целевой системой, которая является частью исходной системы. Агент Sybase Replication обнаруживает любые изменения данных во время начальной загрузки и обеспечивает завершение каждого отдельного изменения. Когда происходит изменение, обновление и удаление записей таблицы в исходной системе, создается журнал таблицы. Этот журнал таблицы перемещает данные из исходной системы в базу данных HANA.
Дельта-репликация после начальной загрузки
Дельта-репликация фиксирует изменения данных в исходной системе в режиме реального времени после завершения начальной загрузки и репликации. Все дальнейшие изменения в исходной системе регистрируются и реплицируются из исходной системы в базу данных HANA с использованием вышеупомянутого метода.
Этот метод был частью первоначального предложения для репликации SAP HANA, но больше не позиционировался / не поддерживался из-за проблем с лицензированием и сложности, а также SLT предоставляет те же функции.
Примечание. Этот метод поддерживает только систему SAP ERP в качестве источника данных и DB2 в качестве базы данных.
SAP HANA — метод DXC
Репликация данных Direct Extractor Connection повторно использует существующий механизм извлечения, преобразования и загрузки, встроенный в системы SAP Business Suite, через простое соединение HTTP (S) с SAP HANA. Это пакетная техника репликации данных. Он рассматривается как метод для извлечения, преобразования и загрузки с ограниченными возможностями для извлечения данных.
DXC — это пакетный процесс, и во многих случаях достаточно извлечения данных с использованием DXC через определенный интервал. Например, вы можете установить интервал при выполнении пакетного задания: каждые 20 минут, и в большинстве случаев достаточно извлечь данные с помощью этих пакетных заданий через определенные промежутки времени.
Преимущества репликации данных DXC
-
Этот метод не требует дополнительного сервера или приложения в системном ландшафте SAP HANA.
-
Метод DXC уменьшает сложность моделирования данных в SAP HANA, когда данные отправляются в HANA после применения всех логик извлечения данных в исходной системе.
-
Это ускоряет сроки для проекта внедрения SAP HANA
-
Он предоставляет семантически насыщенные данные из SAP Business Suite в SAP HANA
-
Он использует существующий собственный механизм извлечения, преобразования и загрузки, встроенный в системы SAP Business Suite, через простое соединение HTTP (S) с SAP HANA.
Этот метод не требует дополнительного сервера или приложения в системном ландшафте SAP HANA.
Метод DXC уменьшает сложность моделирования данных в SAP HANA, когда данные отправляются в HANA после применения всех логик извлечения данных в исходной системе.
Это ускоряет сроки для проекта внедрения SAP HANA
Он предоставляет семантически насыщенные данные из SAP Business Suite в SAP HANA
Он использует существующий собственный механизм извлечения, преобразования и загрузки, встроенный в системы SAP Business Suite, через простое соединение HTTP (S) с SAP HANA.
Ограничения репликации данных DXC
-
Источник данных должен иметь предопределенный механизм извлечения, преобразования и загрузки, а если нет, то нам нужно определить его.
-
Для этого требуется система Business Suite, основанная на Net Weaver 7.0 или более поздней версии, но не ниже SP: выпуск 700 SAPKW70021 (стек SP 19, ноябрь 2008 г.).
Источник данных должен иметь предопределенный механизм извлечения, преобразования и загрузки, а если нет, то нам нужно определить его.
Для этого требуется система Business Suite, основанная на Net Weaver 7.0 или более поздней версии, но не ниже SP: выпуск 700 SAPKW70021 (стек SP 19, ноябрь 2008 г.).
Настройка репликации данных DXC
Включение службы XS Engine на вкладке «Конфигурация» в HANA Studio — Перейдите на вкладку «Администратор» в HANA Studio системы. Перейдите в Конфигурация → xsengine.ini и установите значение экземпляра равным 1.
Включение службы ICM Web Dispatcher в HANA Studio — Перейдите в раздел Конфигурация → webdispatcher.ini и установите значение экземпляра равным 1.
Он включает службу ICM Web Dispatcher в системе HANA. Веб-диспетчер использует метод ICM для чтения и загрузки данных в систему HANA.
Настройка прямого подключения экстрактора SAP HANA — загрузите блок доставки DXC в SAP HANA. Вы можете импортировать устройство в папку / usr / sap / HDB / SYS / global / hdb / content.
Импортируйте модуль с помощью диалога импорта в узле контента SAP HANA → Настройте сервер приложений XS для использования DXC → Измените значение application_container на libxsdxc
Создание HTTP-соединения в SAP BW. Теперь нам нужно создать http-соединение в SAP BW с использованием кода транзакции SM59.
Входные параметры — введите имя RFC-соединения, имя хоста HANA и <номер экземпляра>
На вкладке «Вход в систему» введите пользователя DXC, созданного в HANA studio, используя базовый метод аутентификации —
Настройка параметров BW для HANA — необходимо настроить следующие параметры в BW с помощью транзакции SE 38. Список параметров —
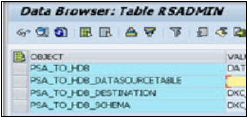
-
PSA_TO_HDB_DESTINATION — нам нужно указать, куда нам нужно переместить входящие данные (имя соединения, созданное с помощью SM 59)
-
PSA_TO_HDB_SCHEMA — какой схеме необходимо присвоить реплицированные данные
-
PSA_TO_HDB — GLOBAL для репликации всех источников данных в HANA. SYSTEM — указанные клиенты для использования DXC. DATASOURCE — Только указанный источник данных используется для
-
PSA_TO_HDB_DATASOURCETABLE — необходимо дать имя таблицы, имеющей список источников данных, которые используются для DXC.
PSA_TO_HDB_DESTINATION — нам нужно указать, куда нам нужно переместить входящие данные (имя соединения, созданное с помощью SM 59)
PSA_TO_HDB_SCHEMA — какой схеме необходимо присвоить реплицированные данные
PSA_TO_HDB — GLOBAL для репликации всех источников данных в HANA. SYSTEM — указанные клиенты для использования DXC. DATASOURCE — Только указанный источник данных используется для
PSA_TO_HDB_DATASOURCETABLE — необходимо дать имя таблицы, имеющей список источников данных, которые используются для DXC.
Репликация источника данных
Установите источник данных в ECC, используя RSA5.
Реплицируйте метаданные, используя указанный компонент приложения (версия источника данных Требуется 7.0, если у нас есть источник данных версии 3.5, нам нужно перенести его. Активируйте источник данных в SAP BW. После активации источника данных в SAP BW будет создана следующая таблица. в определенной схеме —
-
/ BIC / A <источник данных> 00 — IMDSO Active Table
-
/ BIC / A <источник данных> 40 — Очередь активации IMDSO
-
/ BIC / A <источник данных> 70 — Таблица обработки режима записи
-
/ BIC / A <источник данных> 80 — Таблица информации запроса и идентификатора пакета
-
/ BIC / A <источник данных> A0 — Запрос таблицы временных отметок
-
RSODSO_IMOLOG — таблица, связанная с IMDSO. Хранит информацию обо всех источниках данных, связанных с DXC.
/ BIC / A <источник данных> 00 — IMDSO Active Table
/ BIC / A <источник данных> 40 — Очередь активации IMDSO
/ BIC / A <источник данных> 70 — Таблица обработки режима записи
/ BIC / A <источник данных> 80 — Таблица информации запроса и идентификатора пакета
/ BIC / A <источник данных> A0 — Запрос таблицы временных отметок
RSODSO_IMOLOG — таблица, связанная с IMDSO. Хранит информацию обо всех источниках данных, связанных с DXC.
Теперь данные успешно загружены в таблицу / BIC / A0FI_AA_2000 после их активации.
SAP HANA — метод CTL
Откройте SAP HANA Studio → Создать схему на вкладке Каталог. <Начните здесь>
Подготовьте данные и сохраните их в формате csv. Теперь создайте файл с расширением «ctl» со следующим синтаксисом —
--------------------------------------- import data into table Schema."Table name" from 'file.csv' records delimited by '\n' fields delimited by ',' Optionally enclosed by '"' error log 'table.err' -----------------------------------------
Передайте этот файл «ctl» на FTP и выполните этот файл для импорта данных —
импорт из ‘table.ctl’
Проверьте данные в таблице, перейдя в HANA Studio → Каталог → Схема → Таблицы → Просмотр содержимого
SAP HANA — поставщик MDX
Поставщик MDX используется для подключения MS Excel к системе баз данных SAP HANA. Он предоставляет драйвер для подключения системы HANA к Excel и, кроме того, используется для моделирования данных. Вы можете использовать Microsoft Office Excel 2010/2013 для подключения к HANA как для 32-битной, так и для 64-битной Windows.
SAP HANA поддерживает оба языка запросов — SQL и MDX. Можно использовать оба языка: JDBC и ODBC для SQL, а ODBO используется для обработки MDX. Таблицы Excel Pivot используют MDX в качестве языка запросов для чтения данных из системы SAP HANA. MDX определяется как часть спецификации ODBO (OLE DB для OLAP) от Microsoft и используется для выбора данных, расчетов и макета. MDX поддерживает многомерную модель данных и поддерживает отчетность и требования к анализу.
Поставщик MDX позволяет использовать представления информации, определенные в HANA studio инструментами отчетности SAP и других производителей. Существующие физические таблицы и схемы представляют основу данных для информационных моделей.
Выбрав поставщика SAP HANA MDX из списка источника данных, к которому вы хотите подключиться, передайте сведения о системе HANA, такие как имя хоста, номер экземпляра, имя пользователя и пароль.
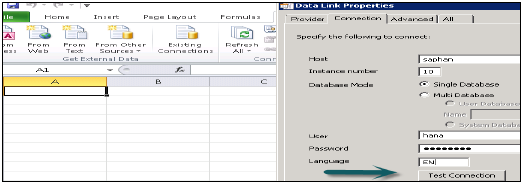
После успешного подключения вы можете выбрать Имя пакета → Представления HANA Modeling, чтобы создать сводные таблицы.
MDX тесно интегрирован в базу данных HANA. Управление подключением и сеансами базы данных HANA обрабатывает операторы, выполняемые HANA. Когда эти операторы выполняются, они анализируются интерфейсом MDX, и для каждого оператора MDX генерируется модель расчета. Эта модель расчета создает план выполнения, который генерирует стандартные результаты для MDX. Эти результаты напрямую используются клиентами OLAP.
Для подключения MDX к базе данных HANA требуются клиентские инструменты HANA. Вы можете загрузить этот клиентский инструмент с рынка SAP. После завершения установки клиента HANA в списке источника данных в MS Excel вы увидите вариант поставщика SAP HANA MDX.
SAP HANA — мониторинг и оповещение
Мониторинг предупреждений SAP HANA используется для мониторинга состояния системных ресурсов и служб, работающих в системе HANA. Мониторинг оповещений используется для обработки критических оповещений, таких как загрузка процессора, заполнение диска, порог достижения FS и т. Д. Компонент мониторинга системы HANA постоянно собирает информацию о работоспособности, использовании и производительности всех компонентов базы данных HANA. Он выдает предупреждение, когда какой-либо компонент нарушает установленное пороговое значение.
Приоритет оповещения, поднятый в системе HANA, говорит о серьезности проблемы и зависит от проверки, выполняемой для компонента. Пример. Если загрузка процессора составляет 80%, будет выдано предупреждение с низким приоритетом. Однако, если он достигнет 96%, система выдаст предупреждение с высоким приоритетом.
Системный монитор является наиболее распространенным способом мониторинга системы HANA и проверки доступности всех компонентов системы SAP HANA. Системный монитор используется для проверки всех ключевых компонентов и служб системы HANA.
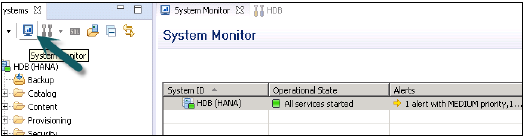
Вы также можете углубиться в детали отдельной системы в Редакторе администрирования. В нем рассказывается о Диск с данными, Журнал диска, Trace Disk, оповещения об использовании ресурсов с приоритетом.
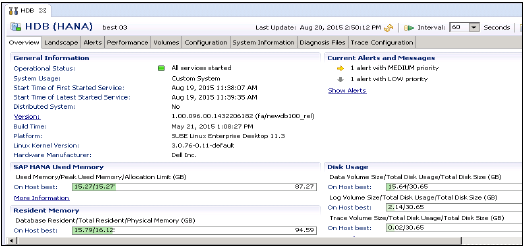
Вкладка Alert в редакторе Administrator используется для проверки текущих и всех предупреждений в системе HANA.
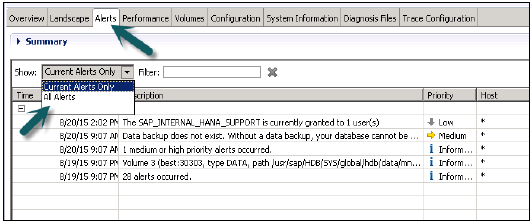
Он также сообщает о времени, когда было выдано предупреждение, описание предупреждения, приоритет предупреждения и т. Д.
Панель мониторинга SAP HANA рассказывает о ключевых аспектах работоспособности и конфигурации системы —
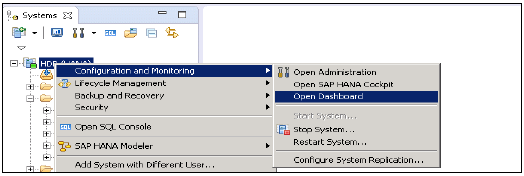
- Предупреждения о высоком и среднем приоритете.
- Использование памяти и процессора
- Резервное копирование данных
SAP HANA — постоянный уровень
Уровень персистентности базы данных SAP HANA отвечает за управление журналами всех транзакций, обеспечивая стандартное резервное копирование данных и функцию восстановления системы.
Это гарантирует, что база данных может быть восстановлена до самого последнего зафиксированного состояния после перезапуска или после сбоя системы, а транзакции выполнены полностью или полностью отменены. Постоянный уровень SAP HANA является частью сервера индексирования и содержит тома данных и журналов транзакций для системы HANA, и данные в памяти регулярно сохраняются на этих томах. В системе HANA есть сервисы, которые имеют свое постоянство. Он также предоставляет точки сохранения и журналы для всех транзакций базы данных с последней точки сохранения.
Зачем базе данных SAP HANA постоянный уровень?
-
Основная память является энергозависимой, поэтому данные теряются при перезапуске или отключении питания.
-
Данные должны храниться на постоянном носителе.
-
Резервное копирование и восстановление доступно.
-
Это гарантирует, что база данных будет восстановлена до самого последнего зафиксированного состояния после перезапуска и что транзакция либо полностью выполнена, либо полностью отменена.
Основная память является энергозависимой, поэтому данные теряются при перезапуске или отключении питания.
Данные должны храниться на постоянном носителе.
Резервное копирование и восстановление доступно.
Это гарантирует, что база данных будет восстановлена до самого последнего зафиксированного состояния после перезапуска и что транзакция либо полностью выполнена, либо полностью отменена.
Объемы данных и журнала транзакций
База данных всегда может быть восстановлена до самого последнего состояния, чтобы эти изменения данных в базе данных регулярно копировались на диск. Файлы журнала, содержащие изменения данных и некоторые события транзакций, также регулярно сохраняются на диск. Данные и журналы системы хранятся в журналах томов.
В томах данных хранятся данные SQL и данные журнала отмены, а также данные моделирования информации SAP HANA. Эта информация хранится на страницах данных, которые называются блоками. Эти блоки записываются в тома данных через регулярный интервал времени, который называется точкой сохранения.
В томах журнала хранится информация об изменениях данных. Изменения, сделанные между двумя точками журнала, записываются в тома журнала и называются записями журнала. Они сохраняются в буфере журнала при фиксации транзакции.
Точки сохранения
В базе данных SAP HANA измененные данные автоматически сохраняются из памяти на диск. Эти регулярные интервалы называются точками сохранения, и по умолчанию они устанавливаются каждые пять минут. Уровень сохраняемости в базе данных SAP HANA выполняет эти точки сохранения с регулярным интервалом. Во время этой операции измененные данные записываются на диск, а журналы повторов также сохраняются на диск.
Данные, принадлежащие точке сохранения, сообщают непротиворечивое состояние данных на диске и остаются там до завершения следующей операции точки сохранения. Записи журнала повторов записываются в тома журналов для всех изменений в постоянных данных. В случае перезапуска базы данных данные с последней завершенной точки сохранения могут быть считаны с томов данных, а записи журнала повторяются в томах журналов.
Частота сохранения может быть настроена с помощью файла global.ini. Точки сохранения могут быть инициированы другими операциями, такими как выключение базы данных или перезагрузка системы. Вы также можете запустить точку сохранения, выполнив следующую команду —
Система ALTER SAVEPOINT
Чтобы сохранить данные и восстановить журналы в томах журналов, необходимо убедиться, что на диске достаточно места для их записи, в противном случае система выдаст событие заполнения диска и база данных перестанет работать.
Во время установки системы HANA в качестве места хранения данных и томов журналов создаются следующие каталоги по умолчанию —
- / USR / сок / <SID> / SYS / глобальный / HDB / данные
- / USR / сок / <SID> / SYS / глобальный / HDB / журнал
Эти каталоги определены в файле global.ini и могут быть изменены на более позднем этапе.
Обратите внимание, что точки сохранения не влияют на производительность транзакций, выполняемых в системе HANA. Во время операции сохранения точки транзакции продолжают выполняться как обычно. При работе системы HANA на надлежащем оборудовании влияние точек сохранения на производительность системы незначительно.
SAP HANA — Резервное копирование и восстановление
Резервное копирование и восстановление SAP HANA используется для резервного копирования системы HANA и восстановления системы в случае сбоя базы данных.
Обзорная вкладка
Он сообщает о состоянии выполняющегося в данный момент резервного копирования данных и последнего успешного резервного копирования данных.
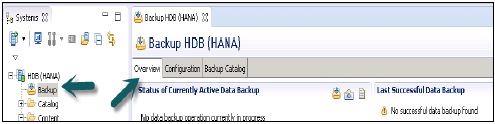
Опцию резервного копирования сейчас можно использовать для запуска мастера резервного копирования данных.
Вкладка конфигурации
В нем рассказывается о настройках интервала резервного копирования, настройках резервного копирования на основе файлов и настройке резервного копирования на основе журналов.

Настройки резервного копирования
Настройки Backint дают возможность использовать сторонний инструмент для данных и выполнить резервное копирование с настройкой агента поддержки.
Настройте соединение со сторонним средством резервного копирования, указав файл параметров для агента Backint.
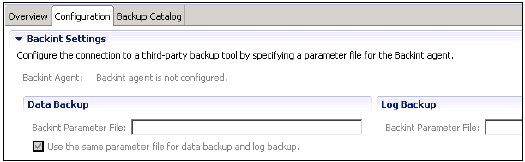
Настройки резервного копирования данных на основе файлов и журналов
Параметр резервного копирования данных на основе файлов указывает папку, в которой вы хотите сохранить резервную копию данных в системе HANA. Вы можете изменить свою резервную папку.
Вы также можете ограничить размер файлов резервных копий данных. Если резервная копия системных данных превышает этот заданный размер файла, она будет разделена на несколько файлов.
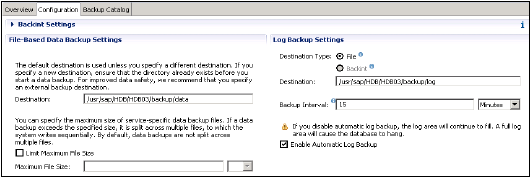
Настройки резервного копирования журнала указывают папку назначения, где вы хотите сохранить резервную копию журнала на внешнем сервере. Вы можете выбрать тип назначения для резервного копирования журнала
Файл — гарантирует, что в системе достаточно места для хранения резервных копий
Backint — это специальный именованный канал, существующий в файловой системе, но не требующий места на диске.
Вы можете выбрать интервал резервного копирования из выпадающего списка. Он сообщает самое большое количество времени, которое может пройти перед записью новой резервной копии журнала. Интервал резервного копирования: может быть в секундах, минутах или часах.
Включите опцию автоматического резервного копирования журнала: это поможет вам сохранить свободное место в журнале. Если вы отключите эту область журнала, она продолжит заполняться, что может привести к зависанию базы данных.
Open Backup Wizard — для запуска резервного копирования системы.
Мастер резервного копирования используется для указания настроек резервного копирования. В нем указывается тип резервной копии, тип места назначения, папка места назначения, префикс резервной копии, размер резервной копии и т. Д.
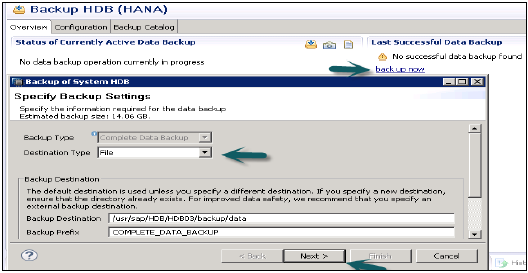
При нажатии на кнопку Далее → Просмотр настроек резервного копирования → Готово
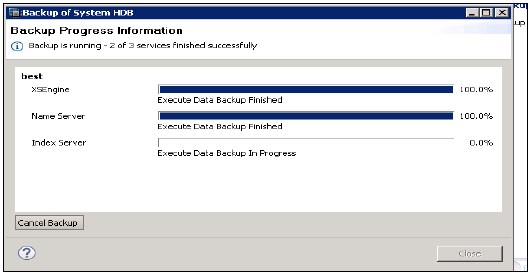
Он выполняет резервное копирование системы и сообщает время для завершения резервного копирования для каждого сервера.
Восстановление системы HANA
Для восстановления базы данных SAP HANA ее необходимо отключить. Следовательно, во время восстановления конечные пользователи или приложения SAP не могут получить доступ к базе данных.
Восстановление базы данных SAP HANA требуется в следующих ситуациях —
-
Диск в области данных непригоден для использования или диск в области журнала непригоден для использования.
-
Как следствие логической ошибки, база данных должна быть сброшена в свое состояние в определенный момент времени.
-
Вы хотите создать копию базы данных.
Диск в области данных непригоден для использования или диск в области журнала непригоден для использования.
Как следствие логической ошибки, база данных должна быть сброшена в свое состояние в определенный момент времени.
Вы хотите создать копию базы данных.
Как восстановить систему HANA?
Выберите систему HANA → Щелкните правой кнопкой мыши → Назад и восстановление → Восстановить систему.
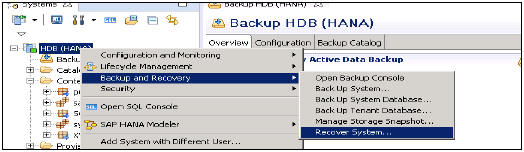
Типы восстановления в системе HANA
Самое последнее состояние — используется для восстановления базы данных до времени, максимально приближенного к текущему времени. Для этого восстановления должны быть доступны резервная копия данных и резервная копия журнала, поскольку для выполнения восстановления вышеупомянутого типа требуется последняя резервная копия данных и область журнала.
Точка во времени — используется для восстановления базы данных до определенного момента времени. Для этого восстановления должны быть доступны резервная копия данных и резервная копия журнала, поскольку для выполнения восстановления вышеуказанного типа требуется последняя резервная копия данных и область журнала.
Специальное резервное копирование данных — используется для восстановления базы данных в указанное резервное копирование данных. Для вышеупомянутого варианта восстановления требуется специальное резервное копирование данных.
Определенная позиция журнала — этот тип восстановления является расширенным параметром, который можно использовать в исключительных случаях, когда предыдущее восстановление не удалось.
Примечание. Для запуска мастера восстановления у вас должны быть права администратора в системе HANA.
SAP HANA — высокая доступность
SAP HANA предоставляет механизм обеспечения непрерывности бизнеса и аварийного восстановления после системных сбоев и ошибок программного обеспечения. Высокая доступность в системе HANA определяет набор методов, которые помогают обеспечить непрерывность бизнеса в случае сбоя, например, сбоя питания в центрах обработки данных, стихийных бедствий, таких как пожар, наводнение и т. Д., Или любых аппаратных сбоев.
Высокая доступность SAP HANA обеспечивает отказоустойчивость и способность системы возобновлять работу системы после простоя с минимальными потерями для бизнеса.
На следующем рисунке показаны фазы высокой доступности в системе HANA —
Первая фаза готовится к ошибке. Ошибка может быть обнаружена автоматически или административным действием. Резервное копирование данных и резервные системы принимают на себя операции. Процесс восстановления, приведенный в действие, включает восстановление неисправной системы и восстановление исходной системы до предыдущей конфигурации.
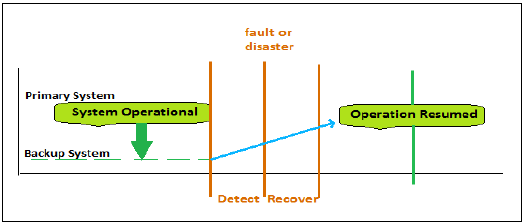
Для достижения высокой доступности в системе HANA ключевым является включение дополнительных компонентов, которые не нужны для функционирования и использования в случае выхода из строя других компонентов. Он включает в себя аппаратное резервирование, сетевое резервирование и избыточность центра обработки данных. SAP HANA обеспечивает несколько уровней аппаратного и программного резервирования, как показано ниже:
Резервирование аппаратного обеспечения системы HANA
Поставщики устройств SAP HANA предлагают несколько уровней резервного оборудования, программного обеспечения и сетевых компонентов, таких как резервные блоки питания и вентиляторы, блоки памяти с исправлением ошибок, полностью резервированные сетевые коммутаторы и маршрутизаторы и источники бесперебойного питания (ИБП). Дисковая система хранения гарантирует запись даже при наличии сбоя питания и использует функции чередования и зеркалирования для обеспечения избыточности для автоматического восстановления после сбоев диска.
Избыточность программного обеспечения SAP HANA
SAP HANA основана на SUSE Linux Enterprise 11 для SAP и включает в себя предварительные конфигурации безопасности.
Системное программное обеспечение SAP HANA включает функцию сторожевого таймера, которая автоматически перезапускает сконфигурированные сервисы (сервер индекса, сервер имен и т. Д.) В случае обнаружения остановки (сбой или сбой).
SAP HANA Постоянство резервирования
SAP HANA обеспечивает постоянство журналов транзакций, точек сохранения и снимков для поддержки перезапуска системы и восстановления после сбоев с минимальной задержкой и без потери данных.
Система HANA в режиме ожидания и отработки отказа
Система SAP HANA включает в себя отдельные резервные хосты, которые используются для отработки отказа в случае сбоя основной системы. Это повышает доступность системы HANA за счет сокращения времени восстановления после сбоя.
SAP HANA — Конфигурация журнала
Система SAP HANA регистрирует все транзакции, которые изменяют данные приложения или каталог базы данных, в записях журнала и сохраняет их в области журнала. Эти записи журнала используются в области журнала для отката или повторения операторов SQL. Файлы журналов доступны в системе HANA и доступны через HANA studio на странице файлов диагностики в редакторе администратора.
В процессе резервного копирования журнала только фактические данные сегментов журнала записываются из области журнала в файлы резервных копий журнала для конкретной службы или в стороннее средство резервного копирования.
После сбоя системы может потребоваться восстановить записи журнала из резервных копий журнала, чтобы восстановить базу данных до нужного состояния.
Если служба базы данных с постоянством останавливается, важно убедиться, что она перезапущена, иначе восстановление будет возможно только до того момента, пока служба не будет остановлена.
Настройка тайм-аута резервного копирования журнала
Тайм-аут резервного копирования журнала определяет интервал резервного копирования сегментов журнала, если за этот интервал произошла фиксация. Вы можете настроить время ожидания резервного копирования журнала, используя Консоль резервного копирования в SAP HANA studio —
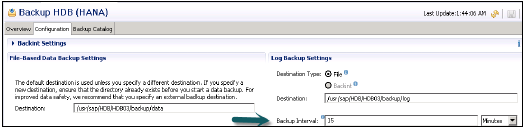
Вы также можете настроить интервал log_backup_timeout_s в файле конфигурации global.ini.
Резервное копирование журнала в «Файл» и режим резервного копирования «НОРМАЛЬНЫЙ» являются настройками по умолчанию для функции автоматического резервного копирования журнала после установки системы SAP HANA. Автоматическое резервное копирование журнала работает, только если было выполнено хотя бы одно полное резервное копирование данных.
После выполнения первого полного резервного копирования данных активируется функция автоматического резервного копирования журнала. SAP HANA studio можно использовать для включения / отключения функции автоматического резервного копирования журнала. Рекомендуется оставить автоматическое резервное копирование журнала, в противном случае область журнала продолжит заполняться. Полная область журнала может привести к зависанию базы данных в системе HANA.
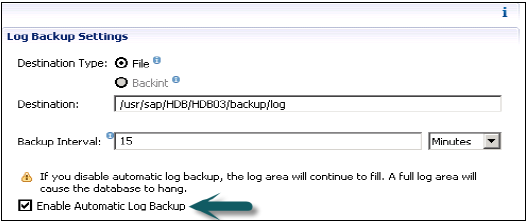
Вы также можете изменить параметр enable_auto_log_backup в разделе постоянства файла конфигурации global.ini.
SAP HANA — Обзор SQL
SQL расшифровывается как язык структурированных запросов.
Это стандартизированный язык для общения с базой данных. SQL используется для извлечения данных, хранения или манипулирования данными в базе данных.
Операторы SQL выполняют следующие функции:
- Определение данных и манипулирование
- Управление системой
- Управление сессиями
- Управление транзакциями
- Определение схемы и манипулирование
Набор расширений SQL, которые позволяют разработчикам помещать данные в базу данных, называется сценариями SQL .
Язык манипулирования данными (DML)
Операторы DML используются для управления данными в объектах схемы. Некоторые примеры —
-
SELECT — получить данные из базы данных
-
INSERT — вставить данные в таблицу
-
ОБНОВЛЕНИЕ — обновляет существующие данные в таблице
SELECT — получить данные из базы данных
INSERT — вставить данные в таблицу
ОБНОВЛЕНИЕ — обновляет существующие данные в таблице
Язык определения данных (DDL)
Операторы DDL используются для определения структуры или схемы базы данных. Некоторые примеры —
-
CREATE — для создания объектов в базе данных
-
ALTER — изменяет структуру базы данных
-
DROP — удалить объекты из базы данных
CREATE — для создания объектов в базе данных
ALTER — изменяет структуру базы данных
DROP — удалить объекты из базы данных
Язык управления данными (DCL)
Некоторые примеры операторов DCL:
-
GRANT — дает пользователю права доступа к базе данных
-
REVOKE — отменить привилегии доступа, заданные командой GRANT
GRANT — дает пользователю права доступа к базе данных
REVOKE — отменить привилегии доступа, заданные командой GRANT
Зачем нам нужен SQL?
Когда мы создаем информационные представления в SAP HANA Modeler, мы создаем его поверх некоторых приложений OLTP. Все это в бэк-энде работает на SQL. База данных понимает только этот язык.
Чтобы проверить, соответствует ли наш отчет бизнес-требованиям, мы должны запустить SQL-оператор в базе данных, если вывод соответствует требованиям.
Представления HANA Calculation могут быть созданы двумя способами — графическим или с использованием сценария SQL. Когда мы создаем более сложные представления вычислений, нам, возможно, придется использовать прямые сценарии SQL.
Как открыть консоль SQL в HANA Studio?
Выберите систему HANA и выберите опцию консоли SQL в системном представлении. Вы также можете открыть консоль SQL, щелкнув правой кнопкой мыши по вкладке Каталог или по любому имени схемы.
SAP HANA может действовать как в качестве реляционной, так и в качестве базы данных OLAP. Когда мы используем BW в HANA, мы создаем кубы в BW и HANA, которые действуют как реляционные базы данных и всегда создают оператор SQL. Однако, когда мы напрямую обращаемся к представлениям HANA с использованием соединения OLAP, оно будет действовать как база данных OLAP, и будет создан MDX.
SAP HANA — Типы данных
Вы можете создавать таблицы хранения строк или столбцов в SAP HANA, используя опцию создания таблиц. Таблицу можно создать, выполнив определение данных, создать оператор таблицы или используя графический параметр в студии HANA.
Когда вы создаете таблицу, вам также необходимо определить атрибуты внутри нее.
Оператор SQL для создания таблицы в консоли HANA Studio SQL —
Create column Table TEST ( ID INTEGER, NAME VARCHAR(10), PRIMARY KEY (ID) );
Создание таблицы в HANA studio с использованием опции GUI —
Когда вы создаете таблицу, вам нужно определить имена столбцов и типы данных SQL. В поле «Размер» указывается длина значения и параметр «Ключ» для определения его в качестве первичного ключа.
SAP HANA поддерживает следующие типы данных в таблице:
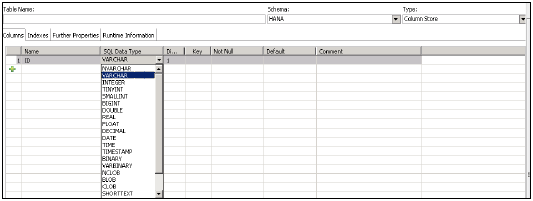
SAP HANA поддерживает 7 категорий типов данных SQL, и это зависит от типа данных, которые вы должны хранить в столбце.
- числовой
- Персонаж / Строка
- логический
- Дата Время
- двоичный
- Большие объекты
- Multi-значных
В следующей таблице приведен список типов данных в каждой категории —

Дата Время
Эти типы данных используются для хранения даты и времени в таблице в базе данных HANA.
-
ДАТА — тип данных состоит из года, месяца и дня, для представления значения даты в столбце. Формат по умолчанию для типа данных Date — ГГГГ-ММ-ДД.
-
TIME — тип данных состоит из значений часов, минут и секунд в таблице в базе данных HANA. Формат по умолчанию для типа данных Time: ЧЧ: МИ: СС.
-
ВТОРАЯ ДАТА — тип данных состоит из значения года, месяца, дня, часа, минуты, секунды в таблице в базе данных HANA. Формат по умолчанию для типа данных SECONDDATE: ГГГГ-ММ-ДД ЧЧ: ММ: СС.
-
TIMESTAMP — тип данных состоит из информации о дате и времени в таблице в базе данных HANA. Формат по умолчанию для типа данных TIMESTAMP: ГГГГ-ММ-ДД ЧЧ: ММ: СС: FFn, где FFn представляет долю секунды.
ДАТА — тип данных состоит из года, месяца и дня, для представления значения даты в столбце. Формат по умолчанию для типа данных Date — ГГГГ-ММ-ДД.
TIME — тип данных состоит из значений часов, минут и секунд в таблице в базе данных HANA. Формат по умолчанию для типа данных Time: ЧЧ: МИ: СС.
ВТОРАЯ ДАТА — тип данных состоит из значения года, месяца, дня, часа, минуты, секунды в таблице в базе данных HANA. Формат по умолчанию для типа данных SECONDDATE: ГГГГ-ММ-ДД ЧЧ: ММ: СС.
TIMESTAMP — тип данных состоит из информации о дате и времени в таблице в базе данных HANA. Формат по умолчанию для типа данных TIMESTAMP: ГГГГ-ММ-ДД ЧЧ: ММ: СС: FFn, где FFn представляет долю секунды.
числовой
-
TinyINT — хранит 8-битное целое число без знака. Минимальное значение: 0 и максимальное значение: 255
-
SMALLINT — хранит 16-битное целое число со знаком . Минимальное значение: -32,768 и максимальное значение: 32,767
-
Integer — хранит 32-битное целое число со знаком. Минимальное значение: -2 147 483 648 и максимальное значение: 2 147 483 648
-
BIGINT — хранит 64-битное целое число со знаком. Минимальное значение: -9,223,372,036,854,775,808 и максимальное значение: 9,223,372,036,854,775,808
-
МАЛЕНЬКИЙ — Десятичный и десятичный: минимальное значение: -10 ^ 38 +1 и максимальное значение: 10 ^ 38 -1
-
REAL — минимальное значение: -3.40E + 38 и максимальное значение: 3.40E + 38
-
DOUBLE — хранит 64-битное число с плавающей точкой. Минимальное значение: -1,7976931348623157E308 и максимальное значение: 1,796931348623157E308
TinyINT — хранит 8-битное целое число без знака. Минимальное значение: 0 и максимальное значение: 255
SMALLINT — хранит 16-битное целое число со знаком . Минимальное значение: -32,768 и максимальное значение: 32,767
Integer — хранит 32-битное целое число со знаком. Минимальное значение: -2 147 483 648 и максимальное значение: 2 147 483 648
BIGINT — хранит 64-битное целое число со знаком. Минимальное значение: -9,223,372,036,854,775,808 и максимальное значение: 9,223,372,036,854,775,808
МАЛЕНЬКИЙ — Десятичный и десятичный: минимальное значение: -10 ^ 38 +1 и максимальное значение: 10 ^ 38 -1
REAL — минимальное значение: -3.40E + 38 и максимальное значение: 3.40E + 38
DOUBLE — хранит 64-битное число с плавающей точкой. Минимальное значение: -1,7976931348623157E308 и максимальное значение: 1,796931348623157E308
логический
Булевы типы данных хранят логические значения, которые ИСТИНА, ЛОЖЬ
символ
-
Varchar — максимум 8000 символов.
-
Нварчар — максимальная длина 4000 символов
-
ALPHANUM — хранит буквенно-цифровые символы. Значение для целого числа составляет от 1 до 127.
-
SHORTTEXT — хранит символьную строку переменной длины, которая поддерживает функции текстового поиска и функции поиска строки.
Varchar — максимум 8000 символов.
Нварчар — максимальная длина 4000 символов
ALPHANUM — хранит буквенно-цифровые символы. Значение для целого числа составляет от 1 до 127.
SHORTTEXT — хранит символьную строку переменной длины, которая поддерживает функции текстового поиска и функции поиска строки.
двоичный
Двоичные типы используются для хранения байтов двоичных данных.
VARBINARY — хранит двоичные данные в байтах. Максимальная длина целого числа составляет от 1 до 5000.
Большие объекты
LARGEOBJECTS используются для хранения большого количества данных, таких как текстовые документы и изображения.
-
NCLOB — хранит большой символьный объект UNICODE.
-
BLOB — хранит большое количество двоичных данных.
-
CLOB — хранит большое количество символьных данных ASCII.
-
ТЕКСТ — включает функции текстового поиска. Этот тип данных может быть определен только для таблиц столбцов, но не для таблиц хранилища строк.
-
BINTEXT — поддерживает функции текстового поиска, но есть возможность вставлять двоичные данные.
NCLOB — хранит большой символьный объект UNICODE.
BLOB — хранит большое количество двоичных данных.
CLOB — хранит большое количество символьных данных ASCII.
ТЕКСТ — включает функции текстового поиска. Этот тип данных может быть определен только для таблиц столбцов, но не для таблиц хранилища строк.
BINTEXT — поддерживает функции текстового поиска, но есть возможность вставлять двоичные данные.
Многозначные
Многозначные типы данных используются для хранения коллекции значений с одинаковым типом данных.
массив
Массивы хранят коллекции значений с одинаковым типом данных. Они также могут содержать нулевые значения.
SAP HANA — операторы SQL
Оператор — это специальный символ, используемый в основном в операторах SQL с предложением WHERE для выполнения операций, таких как сравнения и арифметические операции. Они используются для передачи условий в запросе SQL.
Типы операторов, приведенные ниже, могут использоваться в инструкциях SQL в HANA —
- Арифметические Операторы
- Операторы сравнения / отношения
- Логические Операторы
- Операторы множества
Арифметические Операторы
Арифметические операторы используются для выполнения простых функций вычисления, таких как сложение, вычитание, умножение, деление и процент.
| оператор | Описание |
|---|---|
| + | Добавление — добавляет значения по обе стороны от оператора |
| — | Вычитание — вычитает правый операнд из левого операнда |
| * | Умножение — умножает значения по обе стороны от оператора |
| / | Деление — делит левый операнд на правый операнд |
| % | Модуль — Делит левый операнд на правый операнд и возвращает остаток |
Операторы сравнения
Операторы сравнения используются для сравнения значений в операторе SQL.
| оператор | Описание |
|---|---|
| знак равно | Проверяет, равны ли значения двух операндов или нет, если да, тогда условие становится истинным. |
| знак равно | Проверяет, равны ли значения двух операндов или нет, если значения не равны, тогда условие становится истинным. |
| <> | Проверяет, равны ли значения двух операндов или нет, если значения не равны, тогда условие становится истинным. |
| > | Проверяет, больше ли значение левого операнда, чем значение правого операнда, если да, тогда условие становится истинным. |
| < | Проверяет, меньше ли значение левого операнда, чем значение правого операнда, если да, тогда условие становится истинным. |
| > = | Проверяет, больше ли значение левого операнда или равно значению правого операнда, если да, тогда условие становится истинным. |
| <= | Проверяет, меньше ли значение левого операнда или равно значению правого операнда, если да, тогда условие становится истинным. |
| <! | Проверяет, является ли значение левого операнда не меньше, чем значение правого операнда, если да, тогда условие становится истинным. |
| !> | Проверяет, не превышает ли значение левого операнда значение правого операнда, если да, тогда условие становится истинным. |
Логические операторы
Логические операторы используются для передачи нескольких условий в выражении SQL или для манипулирования результатами условий.
| оператор | Описание |
|---|---|
| ВСЕ | Оператор ALL используется для сравнения значения со всеми значениями в другом наборе значений. |
| А ТАКЖЕ | Оператор AND допускает существование нескольких условий в предложении WHERE оператора SQL. |
| ЛЮБОЙ | ЛЮБОЙ оператор используется для сравнения значения с любым применимым значением в списке в соответствии с условием. |
| МЕЖДУ | Оператор BETWEEN используется для поиска значений, которые находятся в пределах набора значений, учитывая минимальное значение и максимальное значение. |
| СУЩЕСТВУЕТ | Оператор EXISTS используется для поиска наличия строки в указанной таблице, которая соответствует определенным критериям. |
| В | Оператор IN используется для сравнения значения со списком литеральных значений, которые были указаны. |
| ЛАЙК | Оператор LIKE используется для сравнения значения с аналогичными значениями с использованием подстановочных операторов. |
| НЕ | Оператор NOT меняет значение логического оператора, с которым он используется. Например — НЕ СУЩЕСТВУЕТ, НЕ МЕЖДУ, НЕ В и т. Д. Это оператор отрицания . |
| ИЛИ ЖЕ | Оператор OR используется для сравнения нескольких условий в предложении WHERE оператора SQL. |
| НУЛЕВОЙ | Оператор NULL используется для сравнения значения со значением NULL. |
| УНИКАЛЬНАЯ | Оператор UNIQUE ищет в каждой строке указанной таблицы уникальность (без дубликатов). |
Операторы множества
Операторы множеств используются для объединения результатов двух запросов в один результат. Тип данных должен быть одинаковым для обеих таблиц.
-
UNION — объединяет результаты двух или более операторов Select. Однако это устранит дубликаты строк.
-
UNION ALL — этот оператор похож на Union, но он также показывает повторяющиеся строки.
-
INTERSECT — операция Intersect используется для объединения двух операторов SELECT и возвращает записи, которые являются общими для обоих операторов SELECT. В случае Intersect количество столбцов и тип данных должны быть одинаковыми в обеих таблицах.
-
MINUS — Операция минус объединяет результат двух операторов SELECT и возвращает только те результаты, которые принадлежат первому набору результатов и исключают строки во втором операторе из выходных данных первого.
UNION — объединяет результаты двух или более операторов Select. Однако это устранит дубликаты строк.
UNION ALL — этот оператор похож на Union, но он также показывает повторяющиеся строки.
INTERSECT — операция Intersect используется для объединения двух операторов SELECT и возвращает записи, которые являются общими для обоих операторов SELECT. В случае Intersect количество столбцов и тип данных должны быть одинаковыми в обеих таблицах.
MINUS — Операция минус объединяет результат двух операторов SELECT и возвращает только те результаты, которые принадлежат первому набору результатов и исключают строки во втором операторе из выходных данных первого.
SAP HANA — функции SQL
В базе данных SAP HANA предусмотрены различные функции SQL —
- Числовые функции
- Строковые функции
- Полнотекстовые функции
- Функции даты и времени
- Агрегатные функции
- Функции преобразования типов данных
- Функции окна
- Функции данных серии
- Разные функции
Числовые функции
Это встроенные числовые функции в SQL, которые используются в скриптах. Он принимает числовые значения или строки с числовыми символами и возвращает числовые значения.
-
ABS — возвращает абсолютное значение числового аргумента.
ABS — возвращает абсолютное значение числового аргумента.
Example − SELECT ABS (-1) "abs" FROM TEST; abs 1
ACOS, ASIN, ATAN, ATAN2 (эти функции возвращают тригонометрическое значение аргумента)
-
BINTOHEX — преобразует двоичное значение в шестнадцатеричное значение.
-
BITAND — выполняет операцию AND над битами переданного аргумента.
-
BITCOUNT — выполняет подсчет количества установленных битов в аргументе.
-
BITNOT — выполняет битовую операцию НЕ над битами аргумента.
-
BITOR — выполняет операцию ИЛИ над битами переданного аргумента.
-
BITSET — используется для установки битов в 1 в <target_num> из позиции <start_bit>.
-
BITUNSET — используется для установки битов в 0 в <target_num> из позиции <start_bit>.
-
BITXOR — выполняет операцию XOR для битов переданного аргумента.
-
CEIL — возвращает первое целое число, которое больше или равно переданному значению.
-
COS, COSH, COT ((Эти функции возвращают тригонометрическое значение аргумента)
-
EXP — Возвращает результат основания натуральных логарифмов e, возведенных в степень переданного значения.
-
FLOOR — возвращает наибольшее целое число, не превышающее числовой аргумент.
-
HEXTOBIN — Преобразует шестнадцатеричное значение в двоичное значение.
-
LN — возвращает натуральный логарифм аргумента.
-
LOG — возвращает значение алгоритма переданного положительного значения. Как базовое, так и логарифмическое значение должны быть положительными.
BINTOHEX — преобразует двоичное значение в шестнадцатеричное значение.
BITAND — выполняет операцию AND над битами переданного аргумента.
BITCOUNT — выполняет подсчет количества установленных битов в аргументе.
BITNOT — выполняет битовую операцию НЕ над битами аргумента.
BITOR — выполняет операцию ИЛИ над битами переданного аргумента.
BITSET — используется для установки битов в 1 в <target_num> из позиции <start_bit>.
BITUNSET — используется для установки битов в 0 в <target_num> из позиции <start_bit>.
BITXOR — выполняет операцию XOR для битов переданного аргумента.
CEIL — возвращает первое целое число, которое больше или равно переданному значению.
COS, COSH, COT ((Эти функции возвращают тригонометрическое значение аргумента)
EXP — Возвращает результат основания натуральных логарифмов e, возведенных в степень переданного значения.
FLOOR — возвращает наибольшее целое число, не превышающее числовой аргумент.
HEXTOBIN — Преобразует шестнадцатеричное значение в двоичное значение.
LN — возвращает натуральный логарифм аргумента.
LOG — возвращает значение алгоритма переданного положительного значения. Как базовое, так и логарифмическое значение должны быть положительными.
Также могут использоваться различные другие числовые функции — MOD, POWER, RAND, ROUND, SIGN, SIN, SINH, SQRT, TAN, TANH, UMINUS
Строковые функции
Различные строковые функции SQL могут использоваться в HANA со сценариями SQL. Наиболее распространенные строковые функции —
-
ASCII — возвращает целочисленное значение ASCII переданной строки.
-
CHAR — возвращает символ, связанный с переданным значением ASCII.
-
CONCAT — это оператор конкатенации, который возвращает объединенные переданные строки.
-
LCASE — конвертирует все символы строки в нижний регистр.
-
LEFT — возвращает первые символы переданной строки согласно указанному значению.
-
ДЛИНА — возвращает количество символов в переданной строке.
-
LOCATE — возвращает позицию подстроки в переданной строке.
-
НИЖЕ — Преобразует все символы в строке в строчные.
-
NCHAR — возвращает символ Unicode с переданным целочисленным значением.
-
REPLACE — выполняет поиск в переданной исходной строке всех вхождений строки поиска и заменяет их строкой замены.
-
ВПРАВО — возвращает самые правые переданные значения символов указанной строки.
-
UPPER — преобразует все символы в переданной строке в верхний регистр.
-
UCASE — идентично функции UPPER. Он преобразует все символы в переданной строке в верхний регистр.
ASCII — возвращает целочисленное значение ASCII переданной строки.
CHAR — возвращает символ, связанный с переданным значением ASCII.
CONCAT — это оператор конкатенации, который возвращает объединенные переданные строки.
LCASE — конвертирует все символы строки в нижний регистр.
LEFT — возвращает первые символы переданной строки согласно указанному значению.
ДЛИНА — возвращает количество символов в переданной строке.
LOCATE — возвращает позицию подстроки в переданной строке.
НИЖЕ — Преобразует все символы в строке в строчные.
NCHAR — возвращает символ Unicode с переданным целочисленным значением.
REPLACE — выполняет поиск в переданной исходной строке всех вхождений строки поиска и заменяет их строкой замены.
ВПРАВО — возвращает самые правые переданные значения символов указанной строки.
UPPER — преобразует все символы в переданной строке в верхний регистр.
UCASE — идентично функции UPPER. Он преобразует все символы в переданной строке в верхний регистр.
Другие строковые функции, которые можно использовать: LPAD, LTRIM, RTRIM, STRTOBIN, SUBSTR_AFTER, SUBSTR_BEFORE, SUBSTRING, TRIM, UNICODE, RPAD, BINTOSTR
Функции даты и времени
Существуют различные функции даты и времени, которые можно использовать в HANA в сценариях SQL. Наиболее распространенные функции даты и времени —
-
CURRENT_DATE — возвращает текущую локальную системную дату.
-
CURRENT_TIME — возвращает текущее локальное системное время.
-
CURRENT_TIMESTAMP — возвращает текущие данные о локальной системной отметке времени (ГГГГ-ММ-ДД ЧЧ: ММ: СС: ФФ).
-
CURRENT_UTCDATE — Возвращает текущую дату UTC (средняя дата по Гринвичу).
-
CURRENT_UTCTIME — Возвращает текущее время по Гринвичу (UTC).
-
CURRENT_UTCTIMESTAMP
-
DAYOFMONTH — возвращает целочисленное значение дня в переданной дате в аргументе.
-
HOUR — возвращает целочисленное значение часа в прошедшем времени в аргументе.
-
ГОД — Возвращает значение года прошедшей даты.
CURRENT_DATE — возвращает текущую локальную системную дату.
CURRENT_TIME — возвращает текущее локальное системное время.
CURRENT_TIMESTAMP — возвращает текущие данные о локальной системной отметке времени (ГГГГ-ММ-ДД ЧЧ: ММ: СС: ФФ).
CURRENT_UTCDATE — Возвращает текущую дату UTC (средняя дата по Гринвичу).
CURRENT_UTCTIME — Возвращает текущее время по Гринвичу (UTC).
CURRENT_UTCTIMESTAMP
DAYOFMONTH — возвращает целочисленное значение дня в переданной дате в аргументе.
HOUR — возвращает целочисленное значение часа в прошедшем времени в аргументе.
ГОД — Возвращает значение года прошедшей даты.
Другими функциями даты и времени являются: DAYOFYEAR, DAYNAME, DAYS_BETWEEN, EXTRACT, NANO100_BETWEEN, NEXT_DAY, NOW, QUARTER, SECOND, SECONDS_BETWEEN, UTCTOLOCAL, WEEK, WEEKD, MONT, DAY, DAYTOWD, DAYDAY, DAYDAY, DAYTAYTAYDAYDAYDAYTAYDAYDAYDAYTAYDAYE ADD_SECONDS, ADD_WORKDAYS
Функции преобразования типов данных
Эти функции используются для преобразования одного типа данных в другой или для проверки, возможно ли преобразование или нет.
Наиболее распространенные функции преобразования типов данных, используемые в HANA в сценариях SQL —
-
CAST — возвращает значение выражения, преобразованного в предоставленный тип данных.
-
TO_ALPHANUM — преобразует переданное значение в тип данных ALPHANUM
-
TO_REAL — преобразовывает значение в тип данных REAL.
-
TO_TIME — преобразует строку прошедшего времени в тип данных TIME.
-
TO_CLOB — преобразует значение в тип данных CLOB.
CAST — возвращает значение выражения, преобразованного в предоставленный тип данных.
TO_ALPHANUM — преобразует переданное значение в тип данных ALPHANUM
TO_REAL — преобразовывает значение в тип данных REAL.
TO_TIME — преобразует строку прошедшего времени в тип данных TIME.
TO_CLOB — преобразует значение в тип данных CLOB.
Другие аналогичные функции преобразования типов данных: TO_BIGINT, TO_BINARY, TO_BLOB, TO_DATE, TO_DATS, TO_DECIMAL, TO_DOUBLE, TO_FIXEDCHAR, TO_INT, TO_INTEGER, TO_NCLOB, TO_NVARCHAR, TO_TIMESTAMP, TO_TECAL, TO_TSALS, TO_TSALS, TO_TINS, TO_TINSINT,
Существуют также различные Windows и другие разные функции, которые можно использовать в сценариях HANA SQL.
-
Current_Schema — возвращает строку, содержащую имя текущей схемы.
-
Session_User — возвращает имя пользователя текущего сеанса
Current_Schema — возвращает строку, содержащую имя текущей схемы.
Session_User — возвращает имя пользователя текущего сеанса
SAP HANA — выражения SQL
Выражение используется для оценки предложения для возврата значений. В HANA могут использоваться различные выражения SQL:
- Case выражения
- Функциональные выражения
- Совокупные выражения
- Подзапросы в выражениях
Выражение регистра
Это используется для передачи нескольких условий в выражении SQL. Это позволяет использовать логику IF-ELSE-THEN без использования процедур в инструкциях SQL.
пример
SELECT COUNT( CASE WHEN sal < 2000 THEN 1 ELSE NULL END ) count1, COUNT( CASE WHEN sal BETWEEN 2001 AND 4000 THEN 1 ELSE NULL END ) count2, COUNT( CASE WHEN sal > 4000 THEN 1 ELSE NULL END ) count3 FROM emp;
Этот оператор возвратит count1, count2, count3 с целочисленным значением в соответствии с переданным условием.
Функциональные выражения
Выражения функций включают встроенные функции SQL, которые будут использоваться в выражениях.
Совокупные выражения
Агрегатные функции используются для выполнения сложных вычислений, таких как Сумма, Процент, Мин, Макс, Счет, Режим, Медиана и т. Д. Агрегатное выражение использует агрегирующие функции для вычисления одного значения из нескольких значений.
Агрегатные функции — сумма, количество, минимум, максимум. Они применяются к значениям меры (фактам) и всегда связаны с измерением.
Общие агрегатные функции включают в себя —
- Средний ()
- Count ()
- Максимум ()
- Медиана ()
- Минимум ()
- Режим ()
- Сумма ()
Подзапросы в выражениях
Подзапрос как выражение является оператором Select. Когда он используется в выражении, он возвращает ноль или одно значение.
Подзапрос используется для возврата данных, которые будут использоваться в основном запросе в качестве условия для дальнейшего ограничения данных, подлежащих извлечению.
Подзапросы могут использоваться с операторами SELECT, INSERT, UPDATE и DELETE вместе с такими операторами, как =, <,>,> =, <=, IN, BETWEEN и т. Д.
Есть несколько правил, которым должны следовать подзапросы —
-
Подзапросы должны быть заключены в круглые скобки.
-
У подзапроса может быть только один столбец в предложении SELECT, если в основном запросе нет нескольких столбцов для подзапроса для сравнения его выбранных столбцов.
-
ORDER BY нельзя использовать в подзапросе, хотя основной запрос может использовать ORDER BY. GROUP BY может использоваться для выполнения той же функции, что и ORDER BY в подзапросе.
-
Подзапросы, которые возвращают более одной строки, могут использоваться только с несколькими операторами значений, такими как оператор IN.
-
Список SELECT не может содержать ссылки на значения, которые оцениваются как BLOB, ARRAY, CLOB или NCLOB.
-
Подзапрос не может быть сразу заключен в функцию набора.
-
Оператор BETWEEN нельзя использовать с подзапросом; тем не менее, оператор BETWEEN может использоваться внутри подзапроса.
Подзапросы должны быть заключены в круглые скобки.
У подзапроса может быть только один столбец в предложении SELECT, если в основном запросе нет нескольких столбцов для подзапроса для сравнения его выбранных столбцов.
ORDER BY нельзя использовать в подзапросе, хотя основной запрос может использовать ORDER BY. GROUP BY может использоваться для выполнения той же функции, что и ORDER BY в подзапросе.
Подзапросы, которые возвращают более одной строки, могут использоваться только с несколькими операторами значений, такими как оператор IN.
Список SELECT не может содержать ссылки на значения, которые оцениваются как BLOB, ARRAY, CLOB или NCLOB.
Подзапрос не может быть сразу заключен в функцию набора.
Оператор BETWEEN нельзя использовать с подзапросом; тем не менее, оператор BETWEEN может использоваться внутри подзапроса.
Подзапросы с оператором SELECT
Подзапросы чаще всего используются с оператором SELECT. Основной синтаксис выглядит следующим образом —
пример
SELECT * FROM CUSTOMERS WHERE ID IN (SELECT ID FROM CUSTOMERS WHERE SALARY > 4500) ;
+----+----------+-----+---------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+---------+----------+ | 4 | Chaitali | 25 | Mumbai | 6500.00 | | 5 | Hardik | 27 | Bhopal | 8500.00 | | 7 | Muffy | 24 | Indore | 10000.00 | +----+----------+-----+---------+----------+
SAP HANA — хранимые процедуры SQL
Процедура позволяет вам сгруппировать оператор SQL в один блок. Хранимые процедуры используются для достижения определенного результата в разных приложениях. Набор операторов SQL и логика, используемая для выполнения определенной задачи, хранятся в хранимых процедурах SQL. Эти хранимые процедуры выполняются приложениями для выполнения этой задачи.
Хранимые процедуры могут возвращать данные в виде выходных параметров (целое число или символ) или переменной курсора. Это также может привести к набору операторов Select, которые используются другими хранимыми процедурами.
Хранимые процедуры также используются для оптимизации производительности, так как содержат ряд операторов SQL, а результаты одного набора операторов определяют следующий набор операторов, которые должны быть выполнены. Хранимые процедуры не позволяют пользователям видеть сложность и детализацию таблиц в базе данных. Поскольку хранимые процедуры содержат определенную бизнес-логику, пользователям необходимо выполнять или вызывать имя процедуры.
Не нужно продолжать переиздавать отдельные заявления, но можно ссылаться на процедуру базы данных.
Пример заявления для создания процедур
Create procedure prc_name (in inp integer, out opt "EFASION"."ARTICLE_LOOKUP") as begin opt = select * from "EFASION"."ARTICLE_LOOKUP" where article_id = :inp ; end;
SAP HANA — SQL-последовательности
Последовательность — это набор целых чисел 1, 2, 3, которые генерируются в порядке по требованию. Последовательности часто используются в базах данных, поскольку многие приложения требуют, чтобы каждая строка в таблице содержала уникальное значение, а последовательности предоставляют простой способ их создания.
Использование столбца AUTO_INCREMENT
Самый простой способ использования последовательностей в MySQL — это определить столбец как AUTO_INCREMENT и оставить все остальное на усмотрение MySQL.
пример
Попробуйте следующий пример. Это создаст таблицу, и после этого он вставит несколько строк в эту таблицу, где не требуется указывать идентификатор записи, потому что он автоматически увеличивается MySQL.
mysql> CREATE TABLE INSECT -> ( -> id INT UNSIGNED NOT NULL AUTO_INCREMENT, -> PRIMARY KEY (id), -> name VARCHAR(30) NOT NULL, # type of insect -> date DATE NOT NULL, # date collected -> origin VARCHAR(30) NOT NULL # where collected ); Query OK, 0 rows affected (0.02 sec) mysql> INSERT INTO INSECT (id,name,date,origin) VALUES -> (NULL,'housefly','2001-09-10','kitchen'), -> (NULL,'millipede','2001-09-10','driveway'), -> (NULL,'grasshopper','2001-09-10','front yard'); Query OK, 3 rows affected (0.02 sec) Records: 3 Duplicates: 0 Warnings: 0 mysql> SELECT * FROM INSECT ORDER BY id;
+----+-------------+------------+------------+ | id | name | date | origin | +----+-------------+------------+------------+ | 1 | housefly | 2001-09-10 | kitchen | | 2 | millipede | 2001-09-10 | driveway | | 3 | grasshopper | 2001-09-10 | front yard | +----+-------------+------------+------------+ 3 rows in set (0.00 sec)
Получить значения AUTO_INCREMENT
LAST_INSERT_ID () — это функция SQL, поэтому вы можете использовать ее из любого клиента, который понимает, как создавать операторы SQL. В противном случае сценарии PERL и PHP предоставляют эксклюзивные функции для извлечения автоматически увеличенного значения последней записи.
Пример PERL
Используйте атрибут mysql_insertid для получения значения AUTO_INCREMENT, сгенерированного запросом. Этот атрибут доступен через дескриптор базы данных или дескриптор оператора, в зависимости от того, как вы выполняете запрос. Следующий пример ссылается на него через дескриптор базы данных —
$dbh->do ("INSERT INTO INSECT (name,date,origin) VALUES('moth','2001-09-14','windowsill')"); my $seq = $dbh->{mysql_insertid};
Пример PHP
После выдачи запроса, который генерирует значение AUTO_INCREMENT, извлеките значение, вызвав mysql_insert_id () —
mysql_query ("INSERT INTO INSECT (name,date,origin) VALUES('moth','2001-09-14','windowsill')", $conn_id); $seq = mysql_insert_id ($conn_id);
Изменение нумерации существующей последовательности
Возможен случай, когда вы удалили много записей из таблицы и хотите повторно упорядочить все записи. Это может быть сделано с помощью простого трюка, но вы должны быть очень осторожны, если ваша таблица соединяется с другой таблицей.
Если вы решите, что повторное упорядочение столбца AUTO_INCREMENT является неизбежным, способ сделать это — удалить столбец из таблицы, а затем добавить его снова. В следующем примере показано, как изменить нумерацию значений идентификатора в таблице насекомых с помощью этого метода.
mysql> ALTER TABLE INSECT DROP id; mysql> ALTER TABLE insect -> ADD id INT UNSIGNED NOT NULL AUTO_INCREMENT FIRST, -> ADD PRIMARY KEY (id);
Начало последовательности по определенному значению
По умолчанию MySQL запускает последовательность с 1, но вы можете указать и любой другой номер во время создания таблицы. Ниже приведен пример, где MySQL начнет последовательность с 100.
mysql> CREATE TABLE INSECT -> ( -> id INT UNSIGNED NOT NULL AUTO_INCREMENT = 100, -> PRIMARY KEY (id), -> name VARCHAR(30) NOT NULL, # type of insect -> date DATE NOT NULL, # date collected -> origin VARCHAR(30) NOT NULL # where collected );
Кроме того, вы можете создать таблицу, а затем установить начальное значение последовательности с помощью ALTER TABLE.
SAP HANA — триггеры SQL
Триггеры — это хранимые программы, которые автоматически выполняются или запускаются при возникновении некоторых событий. Фактически триггеры записываются для выполнения в ответ на любое из следующих событий:
-
Оператор манипулирования базой данных (DML) (DELETE, INSERT или UPDATE).
-
Оператор определения базы данных (DDL) (CREATE, ALTER или DROP).
-
Операция базы данных (SERVERERROR, LOGON, LOGOFF, STARTUP или SHUTDOWN).
Оператор манипулирования базой данных (DML) (DELETE, INSERT или UPDATE).
Оператор определения базы данных (DDL) (CREATE, ALTER или DROP).
Операция базы данных (SERVERERROR, LOGON, LOGOFF, STARTUP или SHUTDOWN).
Триггеры могут быть определены в таблице, представлении, схеме или базе данных, с которыми связано событие.
Преимущества триггеров
Триггеры могут быть написаны для следующих целей —
- Генерация некоторых производных значений столбцов автоматически
- Обеспечение ссылочной целостности
- Регистрация событий и хранение информации о доступе к таблице
- Аудиторская проверка
- Синхронная репликация таблиц
- Внедрение авторизации безопасности
- Предотвращение недействительных транзакций
SAP HANA — синоним SQL
Синонимы SQL — это псевдоним таблицы или объекта схемы в базе данных. Они используются для защиты клиентских приложений от изменений, внесенных в имя или местоположение объекта.
Синонимы позволяют приложениям функционировать независимо от пользователя, которому принадлежит таблица и в какой базе данных содержится таблица или объект.
Оператор Create Synonym используется для создания синонима для таблицы, представления, пакета, процедуры, объектов и т. Д.
пример
Есть таблица Customer efashion, расположенная на Сервере1. Чтобы получить доступ к этому с Server2, клиентское приложение должно будет использовать имя как Server1.efashion.Customer. Теперь мы изменим расположение таблицы Customer, клиентское приложение должно быть изменено, чтобы отразить это изменение.
Для решения этих проблем мы можем создать синоним таблицы клиента Cust_Table на сервере Server2 для таблицы на сервере Server1. Поэтому теперь клиентское приложение должно использовать однокомпонентное имя Cust_Table для ссылки на эту таблицу. Теперь, если местоположение этой таблицы изменится, вам придется изменить синоним, чтобы указать новое местоположение таблицы.
Поскольку оператор ALTER SYNONYM отсутствует, необходимо удалить синоним Cust_Table, а затем заново создать синоним с тем же именем и указать синоним на новом месте таблицы Customer.
Общедоступные синонимы
Публичные синонимы принадлежат схеме PUBLIC в базе данных. На общедоступные синонимы могут ссылаться все пользователи в базе данных. Они создаются владельцем приложения для таблиц и других объектов, таких как процедуры и пакеты, чтобы пользователи приложения могли видеть объекты.
Синтаксис
CREATE PUBLIC SYNONYM Cust_table for efashion.Customer;
Чтобы создать синоним PUBLIC, вы должны использовать ключевое слово PUBLIC, как показано на рисунке.
Частные синонимы
Частные синонимы используются в схеме базы данных, чтобы скрыть истинное имя таблицы, процедуры, представления или любого другого объекта базы данных.
На частные синонимы может ссылаться только схема, которой принадлежит таблица или объект.
Синтаксис
CREATE SYNONYM Cust_table FOR efashion.Customer;
Удалить синоним
Синонимы могут быть удалены с помощью команды DROP Synonym. Если вы удаляете публичный синоним, вы должны использовать ключевое слово public в операторе удаления.
Синтаксис
DROP PUBLIC Synonym Cust_table; DROP Synonym Cust_table;
SAP HANA — Планы объяснения SQL
Планы объяснения SQL используются для генерации подробного объяснения операторов SQL. Они используются для оценки плана выполнения, которого придерживается база данных SAP HANA для выполнения операторов SQL.
Результаты плана объяснения сохраняются в EXPLAIN_PLAN_TABLE для оценки. Чтобы использовать план объяснения, переданный SQL-запрос должен быть языком манипулирования данными (DML).
Общие заявления DML
-
SELECT — получить данные из базы данных
-
INSERT — вставить данные в таблицу
-
ОБНОВЛЕНИЕ — обновляет существующие данные в таблице
SELECT — получить данные из базы данных
INSERT — вставить данные в таблицу
ОБНОВЛЕНИЕ — обновляет существующие данные в таблице
Планы объяснения SQL нельзя использовать с операторами SQL DDL и DCL.
ОБЪЯСНИТЬ ПЛАН ПЛАНА в базе данных
EXPLAIN PLAN_TABLE в базе данных состоит из нескольких столбцов. Несколько общих имен столбцов — OPERATOR_NAME, OPERATOR_ID, PARENT_OPERATOR_ID, LEVEL и POSITION и т. Д.
Значение COLUMN SEARCH указывает начальную позицию операторов движка колонны.
Значение ROW SEARCH указывает начальную позицию операторов движка строки.
Чтобы создать EXPLAIN PLAN STATEMENT для SQL-запроса
EXPLAIN PLAN SET STATEMENT_NAME = ‘statement_name’ FOR <SQL DML statement>
Чтобы увидеть значения в EXPLAIN PLAN TABLE
SELECT Operator_Name, Operator_ID FROM explain_plan_table WHERE statement_name = 'statement_name';
Чтобы удалить выписку в EXPLAIN PLAN TABLE
DELETE FROM explain_plan_table WHERE statement_name = 'TPC-H Q10';
SAP HANA — Профилирование данных SQL
Задача «Профилирование данных SQL» используется для понимания и анализа данных из нескольких источников данных. Он используется для удаления неверных, неполных данных и предотвращения проблем с качеством данных до их загрузки в хранилище данных.
Вот преимущества задач SQL Data Profiling —
-
Это помогает более эффективно анализировать исходные данные.
-
Это помогает лучше понять исходные данные.
-
Он удаляет неверные, неполные данные и улучшает качество данных перед их загрузкой в хранилище данных.
-
Используется с заданием извлечения, преобразования и загрузки.
Это помогает более эффективно анализировать исходные данные.
Это помогает лучше понять исходные данные.
Он удаляет неверные, неполные данные и улучшает качество данных перед их загрузкой в хранилище данных.
Используется с заданием извлечения, преобразования и загрузки.
Задача «Профилирование данных» проверяет профили, которые помогают понять источник данных и выявить проблемы в данных, которые необходимо исправить.
Вы можете использовать задачу «Профилирование данных» в пакете служб Integration Services для профилирования данных, хранящихся в SQL Server, и для выявления потенциальных проблем с качеством данных.
Примечание. Задача «Профилирование данных» работает только с источниками данных SQL Server и не поддерживает какие-либо другие источники данных на основе файлов или сторонних производителей.
Требование доступа
Чтобы запустить пакет, содержащий задачу «Профилирование данных», учетная запись пользователя должна иметь разрешения на чтение / запись с разрешениями CREATE TABLE для базы данных tempdb.
Data Profiler Viewer
Data Profile Viewer используется для просмотра результатов профилировщика. Средство просмотра профиля данных также поддерживает возможность детализации, чтобы помочь вам понять проблемы с качеством данных, выявленные в выходных данных профиля. Эта возможность детализации отправляет прямые запросы в исходный источник данных.
Настройка и проверка задачи профилирования данных
Настройка задачи профилирования данных
Он включает в себя выполнение пакета, содержащего задачу Data Profiling для вычисления профилей. Задача сохраняет вывод в формате XML в файл или переменную пакета.
Просмотр профилей
Чтобы просмотреть профили данных, отправьте вывод в файл, а затем используйте средство просмотра профилей данных. Это средство просмотра является автономной утилитой, которая отображает выходные данные профиля в кратком и подробном формате с дополнительной возможностью детализации.
Профилирование данных — параметры конфигурации
Задача «Профилирование данных» имеет следующие удобные параметры конфигурации:
Подстановочные столбцы
При настройке запроса профиля задача принимает подстановочный знак «*» вместо имени столбца. Это упрощает настройку и облегчает обнаружение характеристик незнакомых данных. Когда задача выполняется, она профилирует каждый столбец с соответствующим типом данных.
Быстрый профиль
Вы можете выбрать Quick Profile для быстрой настройки задачи. Быстрый профиль профилирует таблицу или представление с использованием всех стандартных профилей и настроек.
Задача «Профилирование данных» может вычислять восемь различных профилей данных. Пять из этих профилей могут проверять отдельные столбцы, а остальные три — анализировать несколько столбцов или взаимосвязи между столбцами.
Профилирование данных — выходы задачи
Задача «Профилирование данных» выводит выбранные профили в формат XML, структурированный как схема DataProfile.xsd.
Вы можете сохранить локальную копию схемы и просмотреть локальную копию схемы в Microsoft Visual Studio или другом редакторе схемы, в редакторе XML или в текстовом редакторе, таком как Блокнот.
SAP HANA — SQL-скрипт
Набор операторов SQL для базы данных HANA, который позволяет разработчику передавать сложную логику в базу данных, называется SQL Script. SQL Script известен как набор расширений SQL. К таким расширениям относятся «Расширения данных», «Расширения функций» и «Расширение процедур».
SQL Script поддерживает хранимые функции и процедуры и позволяет передавать сложные части логики приложения в базу данных.
Основным преимуществом использования SQL Script является возможность выполнения сложных вычислений внутри базы данных SAP HANA. Использование сценариев SQL вместо одного запроса позволяет функциям возвращать несколько значений. Сложные функции SQL могут быть далее разложены на более мелкие функции. SQL Script предоставляет управляющую логику, которая недоступна ни в одном операторе SQL.
Сценарии SQL используются для оптимизации производительности в HANA путем выполнения сценариев на уровне БД —
-
Выполнение сценариев SQL на уровне базы данных устраняет необходимость переноса большого объема данных из базы данных в приложение.
-
Расчеты выполняются на уровне базы данных, чтобы получить преимущества базы данных HANA, такие как операции со столбцами, параллельная обработка запросов и т. Д.
Выполнение сценариев SQL на уровне базы данных устраняет необходимость переноса большого объема данных из базы данных в приложение.
Расчеты выполняются на уровне базы данных, чтобы получить преимущества базы данных HANA, такие как операции со столбцами, параллельная обработка запросов и т. Д.
Интеграция с Информационным Моделером
При использовании сценариев SQL в Information Modeler, нижеприведенное относится к процедурам —
- Входные параметры могут быть скалярного или табличного типа.
- Выходные параметры должны быть табличных типов.
- Типы таблиц, необходимые для подписи, генерируются автоматически.
Сценарии SQL с представлениями вычислений
Сценарий SQL используется для создания представлений расчета на основе сценария. Введите операторы SQL для существующих необработанных таблиц или хранилищ столбцов. Определите структуру вывода, активация представления создает тип таблицы согласно структуре.
Как создать представление расчета с помощью скрипта SQL?
Запуск студии SAP HANA . Разверните узел содержимого → Выберите пакет, в котором вы хотите создать новое представление вычисления. Щелкните правой кнопкой мыши → Новый вид расчета. Конец навигационного пути → Введите имя и описание.
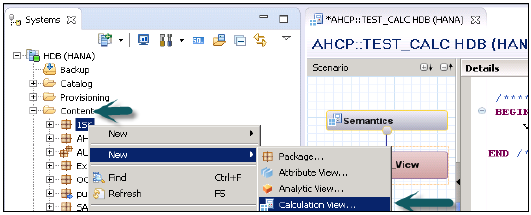
Выберите тип представления калькуляции → в раскрывающемся списке «Тип», выберите «Сценарий SQL» → «Задать чувствительный к регистру параметров» значение «Истина» или «Ложь» в зависимости от того, как требуется соглашение об именах для выходных параметров представления калькуляции → Выберите «Готово».
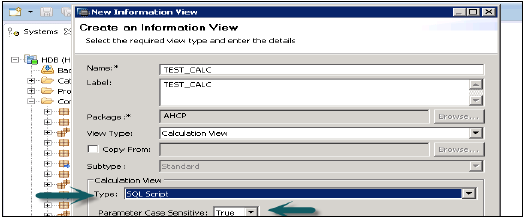
Выберите схему по умолчанию — выберите узел «Семантика» → выберите вкладку «Свойства представления» → в раскрывающемся списке «Схема по умолчанию» выберите схему по умолчанию.
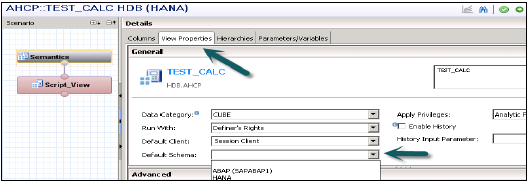
Выберите узел «Сценарий SQL» в узле «Семантика» → Определить структуру вывода. В области вывода выберите «Создать цель». Добавьте необходимые выходные параметры и укажите его длину и тип.
Чтобы добавить несколько столбцов, которые являются частью существующих информационных представлений, таблиц каталога или табличных функций, в структуру вывода представлений расчета на основе сценариев —
На панели «Вывод» выберите «Начало пути навигации» «Новый следующий шаг навигации» «Добавить столбцы с конца пути навигации» → «Имя объекта, содержащего столбцы, которые необходимо добавить к выводу» → «Выберите один или несколько объектов из раскрывающегося списка» → Выберите Далее.
На панели «Источник» выберите столбцы, которые вы хотите добавить в выходные данные → Чтобы добавить выборочные столбцы в выходные данные, затем выберите эти столбцы и нажмите «Добавить». Чтобы добавить все столбцы объекта в выходные данные, выберите объект и выберите «Добавить» → «Готово».
Активируйте представление расчета на основе сценариев — в перспективе SAP HANA Modeler — Сохранить и активировать — чтобы активировать текущее представление и повторно развернуть затронутые объекты, если существует активная версия затронутого объекта. В противном случае активируется только текущий вид.
Сохранить и активировать все — активировать текущий вид вместе с нужными и затронутыми объектами.
В перспективе Разработка SAP HANA — в представлении Project Explorer выберите нужный объект. В контекстном меню выберите Начало навигационного пути Команда Следующий шаг навигации Активируйте Конец навигационного пути.
Сценарии SQL в HANA Information Modeler используются для создания сложных представлений вычислений, которые невозможно создать с помощью параметра GUI.