Фрейм данных — это двумерная структура данных, т. Е. Данные выстраиваются в виде таблиц по строкам и столбцам.
Особенности DataFrame
- Потенциально столбцы бывают разных типов
- Размер — изменчивый
- Помеченные оси (строки и столбцы)
- Может выполнять арифметические операции над строками и столбцами
Состав
Давайте предположим, что мы создаем фрейм данных с данными ученика.
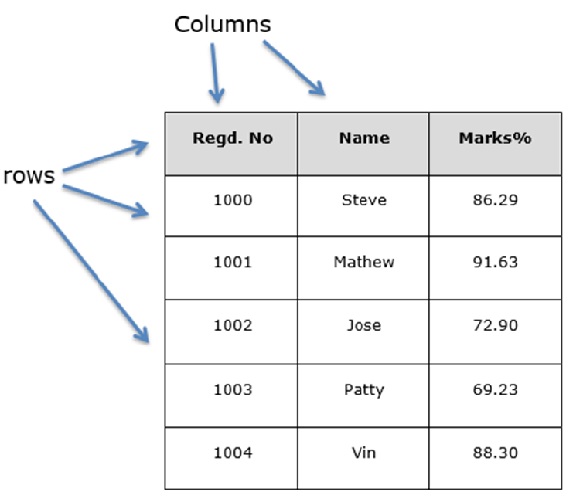
Вы можете думать об этом как о таблице SQL или представлении данных электронной таблицы.
pandas.DataFrame
DataFrame pandas может быть создан с помощью следующего конструктора —
pandas.DataFrame( data, index, columns, dtype, copy)
Параметры конструктора следующие:
| Sr.No | Параметр и описание |
|---|---|
| 1 |
данные Данные могут принимать различные формы, такие как ndarray, series, map, lists, dict, constants, а также другой DataFrame. |
| 2 |
индекс Для меток строк индекс, который будет использоваться для результирующего кадра, является необязательным значением по умолчанию np.arrange (n), если индекс не передан. |
| 3 |
столбцы Для меток столбцов необязательный синтаксис по умолчанию — np.arrange (n). Это верно только в том случае, если индекс не передан. |
| 4 |
DTYPE Тип данных каждого столбца. |
| 5 |
копия Эта команда (или что-то еще) используется для копирования данных, если по умолчанию установлено значение False. |
данные
Данные могут принимать различные формы, такие как ndarray, series, map, lists, dict, constants, а также другой DataFrame.
индекс
Для меток строк индекс, который будет использоваться для результирующего кадра, является необязательным значением по умолчанию np.arrange (n), если индекс не передан.
столбцы
Для меток столбцов необязательный синтаксис по умолчанию — np.arrange (n). Это верно только в том случае, если индекс не передан.
DTYPE
Тип данных каждого столбца.
копия
Эта команда (или что-то еще) используется для копирования данных, если по умолчанию установлено значение False.
Создать DataFrame
DataFrame Pandas может быть создан с использованием различных входных данных, таких как —
- Списки
- ДИКТ
- Серии
- Numpy ndarrays
- Другой DataFrame
В последующих разделах этой главы мы увидим, как создать DataFrame, используя эти входные данные.
Создать пустой фрейм данных
Основной DataFrame, который может быть создан, является Пустым DataFrame.
пример
#import the pandas library and aliasing as pd import pandas as pd df = pd.DataFrame() print df
Его вывод выглядит следующим образом —
Empty DataFrame Columns: [] Index: []
Создать DataFrame из списков
DataFrame может быть создан с использованием одного списка или списка списков.
Пример 1
import pandas as pd data = [1,2,3,4,5] df = pd.DataFrame(data) print df
Его вывод выглядит следующим образом —
0 0 1 1 2 2 3 3 4 4 5
Пример 2
import pandas as pd data = [['Alex',10],['Bob',12],['Clarke',13]] df = pd.DataFrame(data,columns=['Name','Age']) print df
Его вывод выглядит следующим образом —
Name Age 0 Alex 10 1 Bob 12 2 Clarke 13
Пример 3
import pandas as pd data = [['Alex',10],['Bob',12],['Clarke',13]] df = pd.DataFrame(data,columns=['Name','Age'],dtype=float) print df
Его вывод выглядит следующим образом —
Name Age 0 Alex 10.0 1 Bob 12.0 2 Clarke 13.0
Примечание. Обратите внимание, что параметр dtype изменяет тип столбца Age на число с плавающей запятой.
Создать DataFrame из Dict of ndarrays / Lists
Все ndarrays должны быть одинаковой длины. Если индекс передан, то длина индекса должна быть равна длине массивов.
Если индекс не передается, то по умолчанию индексом будет range (n), где n — длина массива.
Пример 1
import pandas as pd data = {'Name':['Tom', 'Jack', 'Steve', 'Ricky'],'Age':[28,34,29,42]} df = pd.DataFrame(data) print df
Его вывод выглядит следующим образом —
Age Name 0 28 Tom 1 34 Jack 2 29 Steve 3 42 Ricky
Примечание — Соблюдайте значения 0,1,2,3. Они являются индексом по умолчанию, назначаемым каждому с использованием диапазона функций (n).
Пример 2
Теперь давайте создадим индексированный DataFrame с использованием массивов.
import pandas as pd data = {'Name':['Tom', 'Jack', 'Steve', 'Ricky'],'Age':[28,34,29,42]} df = pd.DataFrame(data, index=['rank1','rank2','rank3','rank4']) print df
Его вывод выглядит следующим образом —
Age Name rank1 28 Tom rank2 34 Jack rank3 29 Steve rank4 42 Ricky
Примечание. Обратите внимание, что параметр index присваивает индекс каждой строке.
Создать DataFrame из списка Dicts
Список словарей может быть передан в качестве входных данных для создания DataFrame. Ключи словаря по умолчанию принимаются в качестве имен столбцов.
Пример 1
В следующем примере показано, как создать DataFrame, передав список словарей.
import pandas as pd data = [{'a': 1, 'b': 2},{'a': 5, 'b': 10, 'c': 20}] df = pd.DataFrame(data) print df
Его вывод выглядит следующим образом —
a b c 0 1 2 NaN 1 5 10 20.0
Примечание. Обратите внимание, что NaN (не число) добавляется в пропущенные области.
Пример 2
В следующем примере показано, как создать DataFrame, передав список словарей и индексы строк.
import pandas as pd data = [{'a': 1, 'b': 2},{'a': 5, 'b': 10, 'c': 20}] df = pd.DataFrame(data, index=['first', 'second']) print df
Его вывод выглядит следующим образом —
a b c first 1 2 NaN second 5 10 20.0
Пример 3
В следующем примере показано, как создать DataFrame со списком словарей, индексов строк и столбцов.
import pandas as pd data = [{'a': 1, 'b': 2},{'a': 5, 'b': 10, 'c': 20}] #With two column indices, values same as dictionary keys df1 = pd.DataFrame(data, index=['first', 'second'], columns=['a', 'b']) #With two column indices with one index with other name df2 = pd.DataFrame(data, index=['first', 'second'], columns=['a', 'b1']) print df1 print df2
Его вывод выглядит следующим образом —
#df1 output
a b
first 1 2
second 5 10
#df2 output
a b1
first 1 NaN
second 5 NaN
Примечание. Обратите внимание, что df2 DataFrame создается с индексом столбца, отличным от ключа словаря; таким образом, добавил NaN на месте. Принимая во внимание, что df1 создается с индексами столбцов, такими же, как ключи словаря, поэтому добавляется NaN.
Создать DataFrame из Dict of Series
Словарь серии может быть передан для формирования DataFrame. Результирующий индекс — это объединение всех переданных индексов серии.
пример
import pandas as pd d = {'one' : pd.Series([1, 2, 3], index=['a', 'b', 'c']), 'two' : pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])} df = pd.DataFrame(d) print df
Его вывод выглядит следующим образом —
one two a 1.0 1 b 2.0 2 c 3.0 3 d NaN 4
Примечание. Обратите внимание, что для первой серии нет пропущенной метки d , но в результате к метке d добавляется NaN с NaN.
Теперь давайте разберемся в выборе, добавлении и удалении столбцов с помощью примеров.
Выбор столбца
Мы поймем это, выбрав столбец в DataFrame.
пример
import pandas as pd d = {'one' : pd.Series([1, 2, 3], index=['a', 'b', 'c']), 'two' : pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])} df = pd.DataFrame(d) print df ['one']
Его вывод выглядит следующим образом —
a 1.0 b 2.0 c 3.0 d NaN Name: one, dtype: float64
Добавление столбца
Мы поймем это, добавив новый столбец в существующий фрейм данных.
пример
import pandas as pd d = {'one' : pd.Series([1, 2, 3], index=['a', 'b', 'c']), 'two' : pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])} df = pd.DataFrame(d) # Adding a new column to an existing DataFrame object with column label by passing new series print ("Adding a new column by passing as Series:") df['three']=pd.Series([10,20,30],index=['a','b','c']) print df print ("Adding a new column using the existing columns in DataFrame:") df['four']=df['one']+df['three'] print df
Его вывод выглядит следующим образом —
Adding a new column by passing as Series:
one two three
a 1.0 1 10.0
b 2.0 2 20.0
c 3.0 3 30.0
d NaN 4 NaN
Adding a new column using the existing columns in DataFrame:
one two three four
a 1.0 1 10.0 11.0
b 2.0 2 20.0 22.0
c 3.0 3 30.0 33.0
d NaN 4 NaN NaN
Удаление столбца
Столбцы могут быть удалены или вытолкнуты; давайте возьмем пример, чтобы понять, как.
пример
# Using the previous DataFrame, we will delete a column # using del function import pandas as pd d = {'one' : pd.Series([1, 2, 3], index=['a', 'b', 'c']), 'two' : pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd']), 'three' : pd.Series([10,20,30], index=['a','b','c'])} df = pd.DataFrame(d) print ("Our dataframe is:") print df # using del function print ("Deleting the first column using DEL function:") del df['one'] print df # using pop function print ("Deleting another column using POP function:") df.pop('two') print df
Его вывод выглядит следующим образом —
Our dataframe is:
one three two
a 1.0 10.0 1
b 2.0 20.0 2
c 3.0 30.0 3
d NaN NaN 4
Deleting the first column using DEL function:
three two
a 10.0 1
b 20.0 2
c 30.0 3
d NaN 4
Deleting another column using POP function:
three
a 10.0
b 20.0
c 30.0
d NaN
Выбор, добавление и удаление строк
Теперь мы поймем выбор, добавление и удаление строк на примерах. Давайте начнем с концепции отбора.
Выбор по метке
Строки могут быть выбраны путем передачи метки строки в функцию loc .
import pandas as pd d = {'one' : pd.Series([1, 2, 3], index=['a', 'b', 'c']), 'two' : pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])} df = pd.DataFrame(d) print df.loc['b']
Его вывод выглядит следующим образом —
one 2.0 two 2.0 Name: b, dtype: float64
Результатом является серия с метками в качестве имен столбцов DataFrame. И, имя серии — это метка, с которой она извлекается.
Выбор по целому расположению
Строки можно выбирать, передавая целочисленное местоположение в функцию iloc .
import pandas as pd d = {'one' : pd.Series([1, 2, 3], index=['a', 'b', 'c']), 'two' : pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])} df = pd.DataFrame(d) print df.iloc[2]
Его вывод выглядит следующим образом —
one 3.0 two 3.0 Name: c, dtype: float64
Ломтик строк
Несколько строк могут быть выбраны с помощью оператора «:».
import pandas as pd d = {'one' : pd.Series([1, 2, 3], index=['a', 'b', 'c']), 'two' : pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])} df = pd.DataFrame(d) print df[2:4]
Его вывод выглядит следующим образом —
one two c 3.0 3 d NaN 4
Добавление строк
Добавьте новые строки в DataFrame, используя функцию добавления . Эта функция будет добавлять строки в конце.
import pandas as pd df = pd.DataFrame([[1, 2], [3, 4]], columns = ['a','b']) df2 = pd.DataFrame([[5, 6], [7, 8]], columns = ['a','b']) df = df.append(df2) print df
Его вывод выглядит следующим образом —
a b 0 1 2 1 3 4 0 5 6 1 7 8
Удаление строк
Используйте индексную метку для удаления или удаления строк из DataFrame. Если метка дублируется, то несколько строк будут отброшены.
Если вы наблюдаете, в приведенном выше примере метки дублируются. Давайте сбросим метку и увидим, сколько строк будет отброшено.
import pandas as pd df = pd.DataFrame([[1, 2], [3, 4]], columns = ['a','b']) df2 = pd.DataFrame([[5, 6], [7, 8]], columns = ['a','b']) df = df.append(df2) # Drop rows with label 0 df = df.drop(0) print df
Его вывод выглядит следующим образом —
a b 1 3 4 1 7 8
В приведенном выше примере две строки были отброшены, поскольку эти две строки содержат одинаковую метку 0.