Вы можете создать исполняемый файл JAR и запустить приложение Spring Boot с помощью команд Maven или Gradle, как показано ниже —
Для Maven, вы можете использовать команду, приведенную ниже —
mvn clean install
После «BUILD SUCCESS» вы можете найти файл JAR в целевом каталоге.
Для Gradle вы можете использовать команду, как показано на рисунке —
gradle clean build
После «BUILD SUCCESSFUL» вы можете найти файл JAR в каталоге build / libs.
Запустите файл JAR, используя приведенную здесь команду —
java –jar <JARFILE>
Теперь приложение запущено на порт 8080 Tomcat, как показано на рисунке.

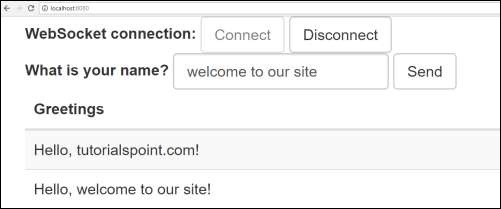
Теперь нажмите URL-адрес http: // localhost: 8080 / в своем веб-браузере, подключите веб-сокет, отправьте приветствие и получите сообщение.
Пакетная служба — это процесс для выполнения более одной команды в одной задаче. В этой главе вы узнаете, как создать пакетный сервис в приложении Spring Boot.
Давайте рассмотрим пример, в котором мы собираемся сохранить содержимое файла CSV в HSQLDB.
Чтобы создать программу Batch Service, нам нужно добавить зависимость Spring Boot Starter Batch и HSQLDB в наш файл конфигурации сборки.
Пользователи Maven могут добавить следующие зависимости в файл pom.xml.
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-batch</artifactId> </dependency> <dependency> <groupId>org.hsqldb</groupId> <artifactId>hsqldb</artifactId> </dependency>
Пользователи Gradle могут добавить следующие зависимости в файл build.gradle.
compile("org.springframework.boot:spring-boot-starter-batch")
compile("org.hsqldb:hsqldb")
Теперь добавьте простой файл данных CSV в ресурс classpath — src / main / resources и назовите файл как file.csv, как показано на рисунке —
William,John Mike, Sebastian Lawarance, Lime
Затем напишите сценарий SQL для HSQLDB — в каталоге ресурсов classpath — request_fail_hystrix_timeout
DROP TABLE USERS IF EXISTS; CREATE TABLE USERS ( user_id BIGINT IDENTITY NOT NULL PRIMARY KEY, first_name VARCHAR(20), last_name VARCHAR(20) );
Создайте класс POJO для модели USERS, как показано на рисунке —
package com.tutorialspoint.batchservicedemo;
public class User {
private String lastName;
private String firstName;
public User() {
}
public User(String firstName, String lastName) {
this.firstName = firstName;
this.lastName = lastName;
}
public void setFirstName(String firstName) {
this.firstName = firstName;
}
public String getFirstName() {
return firstName;
}
public String getLastName() {
return lastName;
}
public void setLastName(String lastName) {
this.lastName = lastName;
}
@Override
public String toString() {
return "firstName: " + firstName + ", lastName: " + lastName;
}
}
Теперь создайте промежуточный процессор для выполнения операций после чтения данных из файла CSV и перед записью данных в SQL.
package com.tutorialspoint.batchservicedemo;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.batch.item.ItemProcessor;
public class UserItemProcessor implements ItemProcessor<User, User> {
private static final Logger log = LoggerFactory.getLogger(UserItemProcessor.class);
@Override
public User process(final User user) throws Exception {
final String firstName = user.getFirstName().toUpperCase();
final String lastName = user.getLastName().toUpperCase();
final User transformedPerson = new User(firstName, lastName);
log.info("Converting (" + user + ") into (" + transformedPerson + ")");
return transformedPerson;
}
}
Давайте создадим файл конфигурации Batch, чтобы прочитать данные из CSV и записать в файл SQL, как показано ниже. Нам нужно добавить аннотацию @EnableBatchProcessing в файл класса конфигурации. Аннотация @EnableBatchProcessing используется для включения пакетных операций для приложения Spring Boot.
package com.tutorialspoint.batchservicedemo;
import javax.sql.DataSource;
import org.springframework.batch.core.Job;
import org.springframework.batch.core.Step;
import org.springframework.batch.core.configuration.annotation.EnableBatchProcessing;
import org.springframework.batch.core.configuration.annotation.JobBuilderFactory;
import org.springframework.batch.core.configuration.annotation.StepBuilderFactory;
import org.springframework.batch.core.launch.support.RunIdIncrementer;
import org.springframework.batch.item.database.BeanPropertyItemSqlParameterSourceProvider;
import org.springframework.batch.item.database.JdbcBatchItemWriter;
import org.springframework.batch.item.file.FlatFileItemReader;
import org.springframework.batch.item.file.mapping.BeanWrapperFieldSetMapper;
import org.springframework.batch.item.file.mapping.DefaultLineMapper;
import org.springframework.batch.item.file.transform.DelimitedLineTokenizer;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.io.ClassPathResource;
@Configuration
@EnableBatchProcessing
public class BatchConfiguration {
@Autowired
public JobBuilderFactory jobBuilderFactory;
@Autowired
public StepBuilderFactory stepBuilderFactory;
@Autowired
public DataSource dataSource;
@Bean
public FlatFileItemReader<User> reader() {
FlatFileItemReader<User> reader = new FlatFileItemReader<User>();
reader.setResource(new ClassPathResource("file.csv"));
reader.setLineMapper(new DefaultLineMapper<User>() {
{
setLineTokenizer(new DelimitedLineTokenizer() {
{
setNames(new String[] { "firstName", "lastName" });
}
});
setFieldSetMapper(new BeanWrapperFieldSetMapper<User>() {
{
setTargetType(User.class);
}
});
}
});
return reader;
}
@Bean
public UserItemProcessor processor() {
return new UserItemProcessor();
}
@Bean
public JdbcBatchItemWriter<User> writer() {
JdbcBatchItemWriter<User> writer = new JdbcBatchItemWriter<User>();
writer.setItemSqlParameterSourceProvider(new BeanPropertyItemSqlParameterSourceProvider<User>());
writer.setSql("INSERT INTO USERS (first_name, last_name) VALUES (:firstName, :lastName)");
writer.setDataSource(dataSource);
return writer;
}
@Bean
public Job importUserJob(JobCompletionNotificationListener listener) {
return jobBuilderFactory.get("importUserJob").incrementer(
new RunIdIncrementer()).listener(listener).flow(step1()).end().build();
}
@Bean
public Step step1() {
return stepBuilderFactory.get("step1").<User, User>chunk(10).reader(reader()).processor(processor()).writer(writer()).build();
}
}
Метод reader () используется для чтения данных из файла CSV, а метод writer () — для записи данных в SQL.
Далее нам нужно написать класс слушателя уведомления о завершении задания, который используется для уведомления после завершения задания.
package com.tutorialspoint.batchservicedemo;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.util.List;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.batch.core.BatchStatus;
import org.springframework.batch.core.JobExecution;
import org.springframework.batch.core.listener.JobExecutionListenerSupport;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.jdbc.core.JdbcTemplate;
import org.springframework.jdbc.core.RowMapper;
import org.springframework.stereotype.Component;
@Component
public class JobCompletionNotificationListener extends JobExecutionListenerSupport {
private static final Logger log = LoggerFactory.getLogger(JobCompletionNotificationListener.class);
private final JdbcTemplate jdbcTemplate;
@Autowired
public JobCompletionNotificationListener(JdbcTemplate jdbcTemplate) {
this.jdbcTemplate = jdbcTemplate;
}
@Override
public void afterJob(JobExecution jobExecution) {
if (jobExecution.getStatus() == BatchStatus.COMPLETED) {
log.info("!!! JOB FINISHED !! It's time to verify the results!!");
List<User> results = jdbcTemplate.query(
"SELECT first_name, last_name FROM USERS", new RowMapper<User>() {
@Override
public User mapRow(ResultSet rs, int row) throws SQLException {
return new User(rs.getString(1), rs.getString(2));
}
});
for (User person : results) {
log.info("Found <" + person + "> in the database.");
}
}
}
}
Теперь создайте исполняемый файл JAR и запустите приложение Spring Boot, используя следующие команды Maven или Gradle.
Для Maven используйте команду как показано —
mvn clean install
После «BUILD SUCCESS» вы можете найти файл JAR в целевом каталоге.
Для Gradle вы можете использовать команду, как показано на рисунке —
gradle clean build
После «BUILD SUCCESSFUL» вы можете найти файл JAR в каталоге build / libs.
Запустите файл JAR, используя приведенную здесь команду —
java –jar <JARFILE>
Вы можете увидеть вывод в окне консоли, как показано на рисунке —