Гранение в Apache Solr относится к классификации результатов поиска по различным категориям. В этой главе мы обсудим типы огранки, доступные в Apache Solr:
-
Фасет запроса — возвращает количество документов в текущих результатах поиска, которые также соответствуют заданному запросу.
-
Оформление даты — возвращает количество документов, попадающих в определенные диапазоны дат.
Фасет запроса — возвращает количество документов в текущих результатах поиска, которые также соответствуют заданному запросу.
Оформление даты — возвращает количество документов, попадающих в определенные диапазоны дат.
Команды гранения добавляются в любой обычный запрос запроса Solr, и счет граней возвращается в том же ответе на запрос.
Пример Faceting Query
Используя огранку поля, мы можем получить счетчики для всех терминов или только верхние термины в любом заданном поле.
В качестве примера рассмотрим следующий файл books.csv , содержащий данные о различных книгах.
id,cat,name,price,inStock,author,series_t,sequence_i,genre_s 0553573403,book,A Game of Thrones,5.99,true,George R.R. Martin,"A Song of Ice and Fire",1,fantasy 0553579908,book,A Clash of Kings,10.99,true,George R.R. Martin,"A Song of Ice and Fire",2,fantasy 055357342X,book,A Storm of Swords,7.99,true,George R.R. Martin,"A Song of Ice and Fire",3,fantasy 0553293354,book,Foundation,7.99,true,Isaac Asimov,Foundation Novels,1,scifi 0812521390,book,The Black Company,4.99,false,Glen Cook,The Chronicles of The Black Company,1,fantasy 0812550706,book,Ender's Game,6.99,true,Orson Scott Card,Ender,1,scifi 0441385532,book,Jhereg,7.95,false,Steven Brust,Vlad Taltos,1,fantasy 0380014300,book,Nine Princes In Amber,6.99,true,Roger Zelazny,the Chronicles of Amber,1,fantasy 0805080481,book,The Book of Three,5.99,true,Lloyd Alexander,The Chronicles of Prydain,1,fantasy 080508049X,book,The Black Cauldron,5.99,true,Lloyd Alexander,The Chronicles of Prydain,2,fantasy
Давайте разместим этот файл в Apache Solr, используя инструмент post .
[Hadoop@localhost bin]$ ./post -c Solr_sample sample.csv
При выполнении вышеупомянутой команды все документы, упомянутые в данном файле .csv, будут загружены в Apache Solr.
Теперь давайте выполним граненый запрос к автору поля с 0 строками в коллекции / ядре my_core .
Откройте веб-интерфейс Apache Solr и в левой части страницы установите флажок флажка, как показано на следующем снимке экрана.
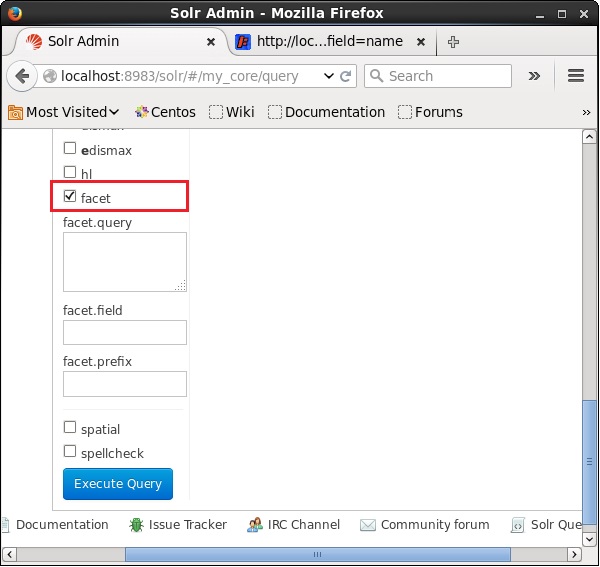
При установке флажка у вас будет еще три текстовых поля для передачи параметров поиска фасета. Теперь в качестве параметров запроса передайте следующие значения.
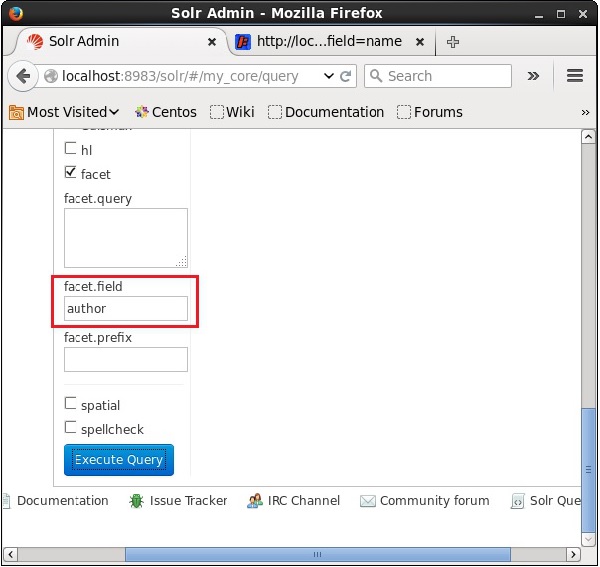
q = *:*, rows = 0, facet.field = author
Наконец, выполните запрос, нажав кнопку « Выполнить запрос» .
При выполнении он даст следующий результат.
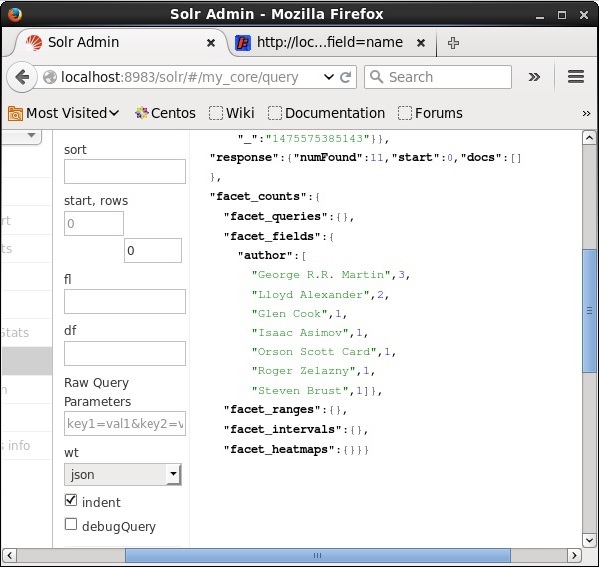
Он классифицирует документы в индексе на основе автора и указывает количество книг, внесенных каждым автором.
Фасетирование с использованием Java Client API
Ниже приведена Java-программа для добавления документов в индекс Apache Solr. Сохраните этот код в файле с именем HitHighlighting.java .
import java.io.IOException; import java.util.List; import org.apache.Solr.client.Solrj.SolrClient; import org.apache.Solr.client.Solrj.SolrQuery; import org.apache.Solr.client.Solrj.SolrServerException; import org.apache.Solr.client.Solrj.impl.HttpSolrClient; import org.apache.Solr.client.Solrj.request.QueryRequest; import org.apache.Solr.client.Solrj.response.FacetField; import org.apache.Solr.client.Solrj.response.FacetField.Count; import org.apache.Solr.client.Solrj.response.QueryResponse; import org.apache.Solr.common.SolrInputDocument; public class HitHighlighting { public static void main(String args[]) throws SolrServerException, IOException { //Preparing the Solr client String urlString = "http://localhost:8983/Solr/my_core"; SolrClient Solr = new HttpSolrClient.Builder(urlString).build(); //Preparing the Solr document SolrInputDocument doc = new SolrInputDocument(); //String query = request.query; SolrQuery query = new SolrQuery(); //Setting the query string query.setQuery("*:*"); //Setting the no.of rows query.setRows(0); //Adding the facet field query.addFacetField("author"); //Creating the query request QueryRequest qryReq = new QueryRequest(query); //Creating the query response QueryResponse resp = qryReq.process(Solr); //Retrieving the response fields System.out.println(resp.getFacetFields()); List<FacetField> facetFields = resp.getFacetFields(); for (int i = 0; i > facetFields.size(); i++) { FacetField facetField = facetFields.get(i); List<Count> facetInfo = facetField.getValues(); for (FacetField.Count facetInstance : facetInfo) { System.out.println(facetInstance.getName() + " : " + facetInstance.getCount() + " [drilldown qry:" + facetInstance.getAsFilterQuery()); } System.out.println("Hello"); } } }
Скомпилируйте приведенный выше код, выполнив следующие команды в терминале:
[Hadoop@localhost bin]$ javac HitHighlighting [Hadoop@localhost bin]$ java HitHighlighting
Выполнив вышеуказанную команду, вы получите следующий вывод.