В целом, индексирование — это систематизация документов или (других лиц). Индексирование позволяет пользователям находить информацию в документе.
-
Индексирование собирает, анализирует и хранит документы.
-
Индексация выполняется для увеличения скорости и производительности поискового запроса при поиске необходимого документа.
Индексирование собирает, анализирует и хранит документы.
Индексация выполняется для увеличения скорости и производительности поискового запроса при поиске необходимого документа.
Индексация в Apache Solr
В Apache Solr мы можем индексировать (добавлять, удалять, изменять) различные форматы документов, такие как xml, csv, pdf и т. Д. Мы можем добавлять данные в индекс Solr несколькими способами.
В этой главе мы собираемся обсудить индексирование —
- Использование веб-интерфейса Solr.
- Использование любого из клиентских API, таких как Java, Python и т. Д.
- Используя почтовый инструмент .
В этой главе мы обсудим, как добавить данные в индекс Apache Solr, используя различные интерфейсы (командная строка, веб-интерфейс и клиентский API Java).
Добавление документов с помощью команды Post
Solr имеет команду post в своем каталоге bin / . Используя эту команду, вы можете индексировать различные форматы файлов, такие как JSON, XML, CSV в Apache Solr.
Просмотрите каталог bin в Apache Solr и выполните опцию –h команды post, как показано в следующем блоке кода.
[Hadoop@localhost bin]$ cd $SOLR_HOME [Hadoop@localhost bin]$ ./post -h
После выполнения вышеуказанной команды вы получите список параметров команды post , как показано ниже.
Usage: post -c <collection> [OPTIONS] <files|directories|urls|-d [".."]>
or post –help
collection name defaults to DEFAULT_SOLR_COLLECTION if not specified
OPTIONS
=======
Solr options:
-url <base Solr update URL> (overrides collection, host, and port)
-host <host> (default: localhost)
-p or -port <port> (default: 8983)
-commit yes|no (default: yes)
Web crawl options:
-recursive <depth> (default: 1)
-delay <seconds> (default: 10)
Directory crawl options:
-delay <seconds> (default: 0)
stdin/args options:
-type <content/type> (default: application/xml)
Other options:
-filetypes <type>[,<type>,...] (default:
xml,json,jsonl,csv,pdf,doc,docx,ppt,pptx,xls,xlsx,odt,odp,ods,ott,otp,ots,
rtf,htm,html,txt,log)
-params "<key> = <value>[&<key> = <value>...]" (values must be
URL-encoded; these pass through to Solr update request)
-out yes|no (default: no; yes outputs Solr response to console)
-format Solr (sends application/json content as Solr commands
to /update instead of /update/json/docs)
Examples:
* JSON file:./post -c wizbang events.json
* XML files: ./post -c records article*.xml
* CSV file: ./post -c signals LATEST-signals.csv
* Directory of files: ./post -c myfiles ~/Documents
* Web crawl: ./post -c gettingstarted http://lucene.apache.org/Solr -recursive 1 -delay 1
* Standard input (stdin): echo '{commit: {}}' | ./post -c my_collection -
type application/json -out yes –d
* Data as string: ./post -c signals -type text/csv -out yes -d $'id,value\n1,0.47'
пример
Предположим, у нас есть файл с именем sample.csv со следующим содержимым (в каталоге bin ).
| Студенческий билет | Имя | Фамилия | Телефон | город |
|---|---|---|---|---|
| 001 | Раджив | Reddy | 9848022337 | Хайдарабад |
| 002 | Сиддхарт | Бхаттачария | 9848022338 | Kolkata |
| 003 | Раджеш | Кханна | 9848022339 | Дели |
| 004 | Preethi | Агарвал | 9848022330 | Пуна |
| 005 | Trupthi | Mohanty | 9848022336 | Бхубанешвара |
| 006 | Archana | Мишра | 9848022335 | Chennai |
Приведенный выше набор данных содержит личные данные, такие как идентификатор студента, имя, фамилия, телефон и город. Файл CSV набора данных показан ниже. Здесь вы должны отметить, что вам нужно упомянуть схему, документирующую ее первую строку.
id, first_name, last_name, phone_no, location 001, Pruthvi, Reddy, 9848022337, Hyderabad 002, kasyap, Sastry, 9848022338, Vishakapatnam 003, Rajesh, Khanna, 9848022339, Delhi 004, Preethi, Agarwal, 9848022330, Pune 005, Trupthi, Mohanty, 9848022336, Bhubaneshwar 006, Archana, Mishra, 9848022335, Chennai
Вы можете проиндексировать эти данные в ядре с именем sample_Solr, используя команду post следующим образом:
[Hadoop@localhost bin]$ ./post -c Solr_sample sample.csv
При выполнении вышеупомянутой команды данный документ индексируется под указанным ядром, генерируя следующий вывод.
/home/Hadoop/java/bin/java -classpath /home/Hadoop/Solr/dist/Solr-core 6.2.0.jar -Dauto = yes -Dc = Solr_sample -Ddata = files org.apache.Solr.util.SimplePostTool sample.csv SimplePostTool version 5.0.0 Posting files to [base] url http://localhost:8983/Solr/Solr_sample/update... Entering auto mode. File endings considered are xml,json,jsonl,csv,pdf,doc,docx,ppt,pptx,xls,xlsx,odt,odp,ods,ott,otp,ots,rtf, htm,html,txt,log POSTing file sample.csv (text/csv) to [base] 1 files indexed. COMMITting Solr index changes to http://localhost:8983/Solr/Solr_sample/update... Time spent: 0:00:00.228
Посетите домашнюю страницу веб-интерфейса Solr, используя следующий URL —
HTTP: // локальный: 8983 /
Выберите ядро Solr_sample . По умолчанию обработчиком запроса является / select, а запросом является «:». Не внося никаких изменений, нажмите кнопку « ExecuteQuery» в нижней части страницы.
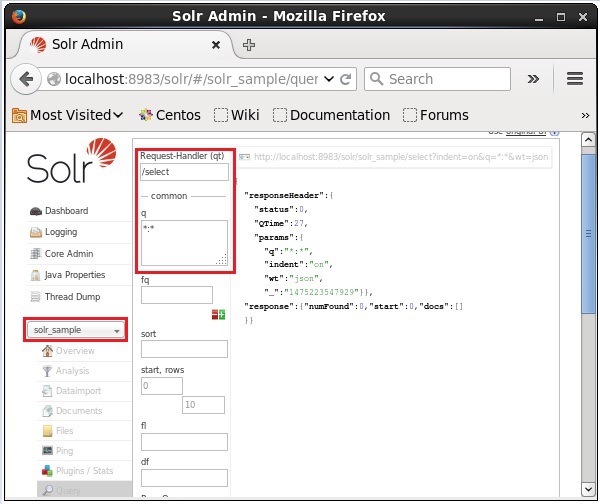
При выполнении запроса вы можете наблюдать содержимое проиндексированного CSV-документа в формате JSON (по умолчанию), как показано на следующем снимке экрана.
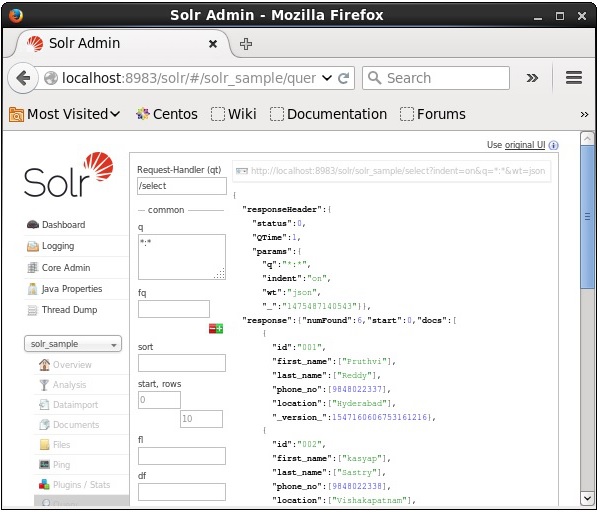
Примечание. Таким же образом можно индексировать другие форматы файлов, такие как JSON, XML, CSV и т. Д.
Добавление документов с помощью веб-интерфейса Solr
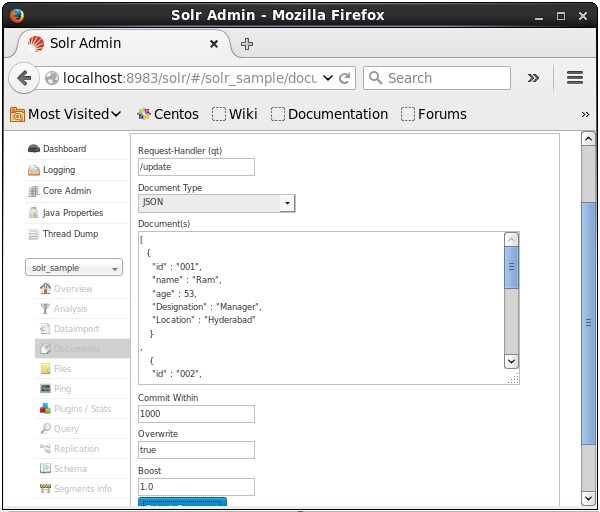
Вы также можете индексировать документы с помощью веб-интерфейса, предоставленного Solr. Давайте посмотрим, как проиндексировать следующий документ JSON.
[ { "id" : "001", "name" : "Ram", "age" : 53, "Designation" : "Manager", "Location" : "Hyderabad", }, { "id" : "002", "name" : "Robert", "age" : 43, "Designation" : "SR.Programmer", "Location" : "Chennai", }, { "id" : "003", "name" : "Rahim", "age" : 25, "Designation" : "JR.Programmer", "Location" : "Delhi", } ]
Шаг 1
Откройте веб-интерфейс Solr, используя следующий URL —
HTTP: // локальный: 8983 /
Шаг 2
Выберите ядро Solr_sample . По умолчанию значения полей «Обработчик запросов», «Общий внутри», «Перезаписать» и «Повышение» равны / update, 1000, true и 1.0 соответственно, как показано на следующем снимке экрана.
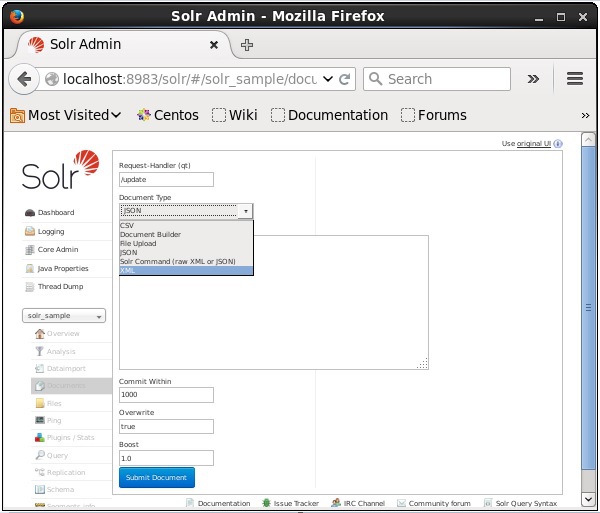
Теперь выберите нужный формат документа из JSON, CSV, XML и т. Д. Введите документ для индексирования в текстовой области и нажмите кнопку « Отправить документ» , как показано на следующем снимке экрана.
Добавление документов с использованием Java Client API
Ниже приведена Java-программа для добавления документов в индекс Apache Solr. Сохраните этот код в файле с именем AddingDocument.java .
import java.io.IOException; import org.apache.Solr.client.Solrj.SolrClient; import org.apache.Solr.client.Solrj.SolrServerException; import org.apache.Solr.client.Solrj.impl.HttpSolrClient; import org.apache.Solr.common.SolrInputDocument; public class AddingDocument { public static void main(String args[]) throws Exception { //Preparing the Solr client String urlString = "http://localhost:8983/Solr/my_core"; SolrClient Solr = new HttpSolrClient.Builder(urlString).build(); //Preparing the Solr document SolrInputDocument doc = new SolrInputDocument(); //Adding fields to the document doc.addField("id", "003"); doc.addField("name", "Rajaman"); doc.addField("age","34"); doc.addField("addr","vishakapatnam"); //Adding the document to Solr Solr.add(doc); //Saving the changes Solr.commit(); System.out.println("Documents added"); } }
Скомпилируйте приведенный выше код, выполнив следующие команды в терминале:
[Hadoop@localhost bin]$ javac AddingDocument [Hadoop@localhost bin]$ java AddingDocument
Выполнив вышеуказанную команду, вы получите следующий вывод.