Solr можно использовать вместе с Hadoop. Поскольку Hadoop обрабатывает большой объем данных, Solr помогает нам найти необходимую информацию из такого большого источника. В этом разделе мы расскажем, как установить Hadoop в своей системе.
Загрузка Hadoop
Ниже приведены шаги, которые необходимо выполнить для загрузки Hadoop в вашу систему.
Шаг 1 — Перейдите на домашнюю страницу Hadoop. Вы можете использовать ссылку — www.hadoop.apache.org/ . Нажмите на ссылку Releases , как показано на следующем снимке экрана.
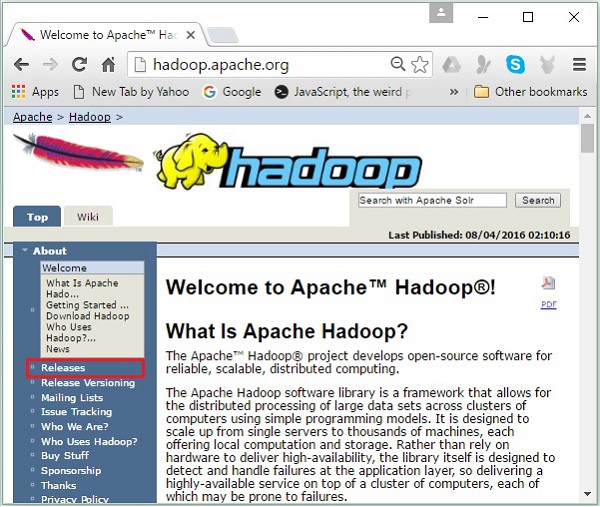
Он перенаправит вас на страницу Apache Hadoop Releases, которая содержит ссылки на зеркала исходных и двоичных файлов различных версий Hadoop следующим образом:
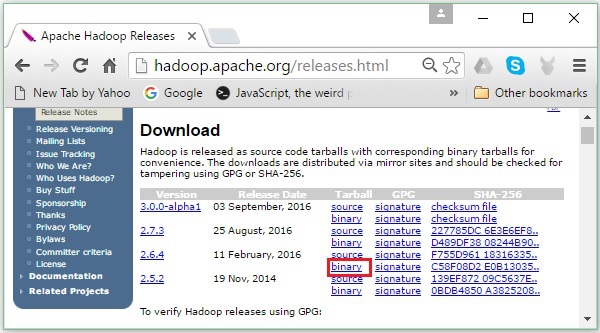
Шаг 2 — Выберите последнюю версию Hadoop (в нашем руководстве это 2.6.4) и щелкните по ее бинарной ссылке . Вы попадете на страницу, где доступны зеркала для двоичного кода Hadoop. Нажмите на одно из этих зеркал, чтобы загрузить Hadoop.
Загрузите Hadoop из командной строки
Откройте терминал Linux и войдите в систему как суперпользователь.
$ su password:
Перейдите в каталог, где вам нужно установить Hadoop, и сохраните файл там, используя ранее скопированную ссылку, как показано в следующем блоке кода.
# cd /usr/local # wget http://redrockdigimark.com/apachemirror/hadoop/common/hadoop- 2.6.4/hadoop-2.6.4.tar.gz
После загрузки Hadoop извлеките его с помощью следующих команд.
# tar zxvf hadoop-2.6.4.tar.gz # mkdir hadoop # mv hadoop-2.6.4/* to hadoop/ # exit
Установка Hadoop
Следуйте приведенным ниже инструкциям, чтобы установить Hadoop в псевдораспределенном режиме.
Шаг 1: Настройка Hadoop
Вы можете установить переменные среды Hadoop, добавив следующие команды в файл ~ / .bashrc .
export HADOOP_HOME = /usr/local/hadoop export HADOOP_MAPRED_HOME = $HADOOP_HOME export HADOOP_COMMON_HOME = $HADOOP_HOME export HADOOP_HDFS_HOME = $HADOOP_HOME export YARN_HOME = $HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR = $HADOOP_HOME/lib/native export PATH = $PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin export HADOOP_INSTALL = $HADOOP_HOME
Затем примените все изменения в текущей работающей системе.
$ source ~/.bashrc
Шаг 2: Конфигурация Hadoop
Вы можете найти все файлы конфигурации Hadoop в папке «$ HADOOP_HOME / etc / hadoop». Необходимо внести изменения в эти файлы конфигурации в соответствии с вашей инфраструктурой Hadoop.
$ cd $HADOOP_HOME/etc/hadoop
Для разработки программ Hadoop на Java вам необходимо сбросить переменные среды Java в файле hadoop-env.sh , заменив значение JAVA_HOME расположением Java в вашей системе.
export JAVA_HOME = /usr/local/jdk1.7.0_71
Ниже приведен список файлов, которые вы должны отредактировать для настройки Hadoop:
- ядро-site.xml
- HDFS-site.xml
- Пряжа-site.xml
- mapred-site.xml
ядро-site.xml
Файл core-site.xml содержит такую информацию, как номер порта, используемый для экземпляра Hadoop, память, выделенная для файловой системы, лимит памяти для хранения данных и размер буферов чтения / записи.
Откройте файл core-site.xml и добавьте следующие свойства в теги <configuration>, </ configuration>.
<configuration> <property> <name>fs.default.name</name> <value>hdfs://localhost:9000</value> </property> </configuration>
HDFS-site.xml
Файл hdfs-site.xml содержит такую информацию, как значение данных репликации, путь namenode и пути datanode вашей локальной файловой системы. Это место, где вы хотите хранить инфраструктуру Hadoop.
Допустим, следующие данные.
dfs.replication (data replication value) = 1 (In the below given path /hadoop/ is the user name. hadoopinfra/hdfs/namenode is the directory created by hdfs file system.) namenode path = //home/hadoop/hadoopinfra/hdfs/namenode (hadoopinfra/hdfs/datanode is the directory created by hdfs file system.) datanode path = //home/hadoop/hadoopinfra/hdfs/datanode
Откройте этот файл и добавьте следующие свойства в теги <configuration>, </ configuration>.
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/datanode</value>
</property>
</configuration>
Примечание. В приведенном выше файле все значения свойств определяются пользователем, и вы можете вносить изменения в соответствии с инфраструктурой Hadoop.
Пряжа-site.xml
Этот файл используется для настройки пряжи в Hadoop. Откройте файл yarn-site.xml и добавьте следующие свойства между тегами <configuration>, </ configuration> в этом файле.
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
mapred-site.xml
Этот файл используется, чтобы указать, какую платформу MapReduce мы используем. По умолчанию Hadoop содержит шаблон yarn-site.xml. Прежде всего, необходимо скопировать файл из mapred-site, xml.template в файл mapred-site.xml, используя следующую команду.
$ cp mapred-site.xml.template mapred-site.xml
Откройте файл mapred-site.xml и добавьте следующие свойства в теги <configuration>, </ configuration>.
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
Проверка правильности установки Hadoop
Следующие шаги используются для проверки установки Hadoop.
Шаг 1: Настройка имени узла
Настройте namenode с помощью команды «hdfs namenode –format» следующим образом.
$ cd ~ $ hdfs namenode -format
Ожидаемый результат заключается в следующем.
10/24/14 21:30:55 INFO namenode.NameNode: STARTUP_MSG: /************************************************************ STARTUP_MSG: Starting NameNode STARTUP_MSG: host = localhost/192.168.1.11 STARTUP_MSG: args = [-format] STARTUP_MSG: version = 2.6.4 ... ... 10/24/14 21:30:56 INFO common.Storage: Storage directory /home/hadoop/hadoopinfra/hdfs/namenode has been successfully formatted. 10/24/14 21:30:56 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0 10/24/14 21:30:56 INFO util.ExitUtil: Exiting with status 0 10/24/14 21:30:56 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at localhost/192.168.1.11 ************************************************************/
Шаг 2: Проверка Hadoop dfs
Следующая команда используется для запуска Hadoop dfs. Выполнение этой команды запустит вашу файловую систему Hadoop.
$ start-dfs.sh
Ожидаемый результат следующий:
10/24/14 21:37:56 Starting namenodes on [localhost] localhost: starting namenode, logging to /home/hadoop/hadoop-2.6.4/logs/hadoop- hadoop-namenode-localhost.out localhost: starting datanode, logging to /home/hadoop/hadoop-2.6.4/logs/hadoop- hadoop-datanode-localhost.out Starting secondary namenodes [0.0.0.0]
Шаг 3: Проверка скрипта пряжи
Следующая команда используется для запуска скрипта Yarn. Выполнение этой команды запустит ваших демонов Пряжи.
$ start-yarn.sh
Ожидаемый результат следующим образом —
starting yarn daemons starting resourcemanager, logging to /home/hadoop/hadoop-2.6.4/logs/yarn- hadoop-resourcemanager-localhost.out localhost: starting nodemanager, logging to /home/hadoop/hadoop- 2.6.4/logs/yarn-hadoop-nodemanager-localhost.out
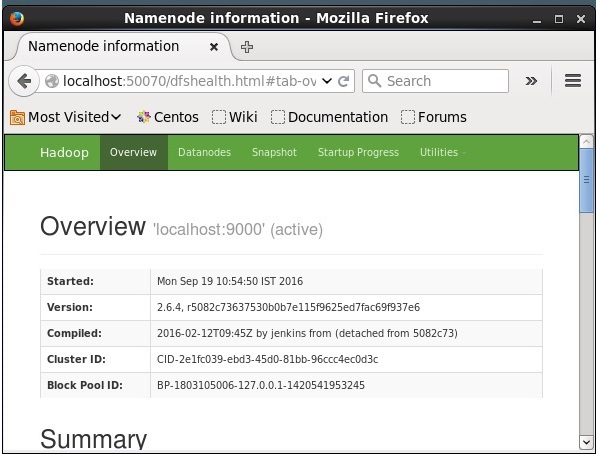
Шаг 4: Доступ к Hadoop в браузере
Номер порта по умолчанию для доступа к Hadoop — 50070. Используйте следующий URL-адрес, чтобы получить службы Hadoop в браузере.
HTTP: // локальный: 50070 /
Установка Solr на Hadoop
Следуйте инструкциям ниже, чтобы загрузить и установить Solr.
Шаг 1
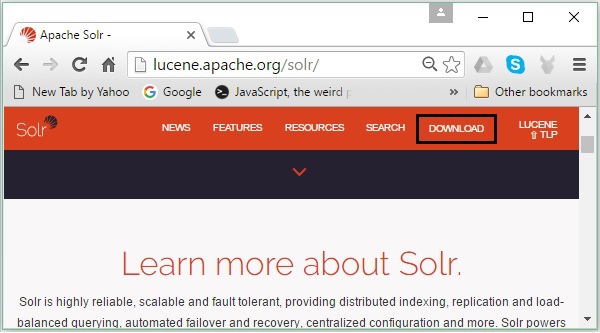
Откройте домашнюю страницу Apache Solr, перейдя по следующей ссылке — https://lucene.apache.org/solr/
Шаг 2
Нажмите кнопку загрузки (выделено на скриншоте выше). При нажатии вы будете перенаправлены на страницу, где у вас есть различные зеркала Apache Solr. Выберите зеркало и нажмите на него, чтобы перенаправить вас на страницу, где вы можете загрузить исходные и двоичные файлы Apache Solr, как показано на следующем снимке экрана.
Шаг 3
При щелчке папка с именем Solr-6.2.0.tqz будет загружена в папку загрузок вашей системы. Извлеките содержимое загруженной папки.
Шаг 4
Создайте папку с именем Solr в домашнем каталоге Hadoop и переместите в нее содержимое извлеченной папки, как показано ниже.
$ mkdir Solr $ cd Downloads $ mv Solr-6.2.0 /home/Hadoop/
верификация
Просмотрите папку bin в каталоге Solr Home и проверьте установку, используя опцию версии , как показано в следующем блоке кода.
$ cd bin/ $ ./Solr version 6.2.0
Настройка дома и пути
Откройте файл .bashrc, используя следующую команду —
[Hadoop@localhost ~]$ source ~/.bashrc
Теперь установите каталоги home и path для Apache Solr следующим образом:
export SOLR_HOME = /home/Hadoop/Solr export PATH = $PATH:/$SOLR_HOME/bin/
Откройте терминал и выполните следующую команду —
[Hadoop@localhost Solr]$ source ~/.bashrc
Теперь вы можете выполнять команды Solr из любого каталога.