Apache Solr — Обзор
Solr — это поисковая платформа с открытым исходным кодом, которая используется для создания поисковых приложений . Он был построен поверх Lucene (полнотекстовая поисковая система). Solr готов к работе, быстр и масштабируем. Приложения, созданные с использованием Solr, являются сложными и обеспечивают высокую производительность.
Именно Йоник Сили создал Solr в 2004 году, чтобы добавить возможности поиска на веб-сайт компании CNET Networks. В январе 2006 года был сделан проект с открытым исходным кодом в рамках Apache Software Foundation. Его последняя версия, Solr 6.0, была выпущена в 2016 году с поддержкой выполнения параллельных SQL-запросов.
Solr можно использовать вместе с Hadoop. Поскольку Hadoop обрабатывает большой объем данных, Solr помогает нам найти необходимую информацию из такого большого источника. Solr может использоваться не только для поиска, но и для хранения. Как и другие базы данных NoSQL, это нереляционная технология хранения и обработки данных .
Короче говоря, Solr — это масштабируемая, готовая к развертыванию система поиска и хранения, оптимизированная для поиска больших объемов тексто-ориентированных данных.
Особенности Apache Solr
Solr — это оболочка вокруг Java API от Lucene. Поэтому, используя Solr, вы можете использовать все возможности Lucene. Давайте посмотрим на некоторые из наиболее важных особенностей Solr —
-
Restful APIs — Чтобы общаться с Solr, не обязательно иметь навыки программирования на Java. Вместо этого вы можете использовать успокоительные услуги для общения с ним. Мы вводим документы в Solr в таких форматах, как XML, JSON и .CSV, и получаем результаты в тех же форматах.
-
Полнотекстовый поиск — Solr предоставляет все возможности, необходимые для полнотекстового поиска, такие как токены, фразы, проверка орфографии, подстановочные знаки и автозаполнение.
-
Готовность для предприятия — в зависимости от потребностей организации Solr может быть развернут в любых системах (больших или малых), таких как автономные, распределенные, облачные и т. Д.
-
Гибкость и расширяемость. Расширяя классы Java и настраивая их соответствующим образом, мы можем легко настраивать компоненты Solr.
-
База данных NoSQL — Solr также может использоваться в качестве базы данных NOSQL с большими объемами данных, где мы можем распределять задачи поиска по кластеру.
-
Интерфейс администратора — Solr предоставляет простой в использовании, удобный, функциональный пользовательский интерфейс, с помощью которого мы можем выполнять все возможные задачи, такие как управление журналами, добавление, удаление, обновление и поиск документов.
-
Высокая масштабируемость. Используя Solr с Hadoop, мы можем масштабировать его емкость, добавляя реплики.
-
Текст-ориентированный и отсортированный по релевантности — Solr в основном используется для поиска текстовых документов, а результаты предоставляются в соответствии с запросом пользователя по порядку.
Restful APIs — Чтобы общаться с Solr, не обязательно иметь навыки программирования на Java. Вместо этого вы можете использовать успокоительные услуги для общения с ним. Мы вводим документы в Solr в таких форматах, как XML, JSON и .CSV, и получаем результаты в тех же форматах.
Полнотекстовый поиск — Solr предоставляет все возможности, необходимые для полнотекстового поиска, такие как токены, фразы, проверка орфографии, подстановочные знаки и автозаполнение.
Готовность для предприятия — в зависимости от потребностей организации Solr может быть развернут в любых системах (больших или малых), таких как автономные, распределенные, облачные и т. Д.
Гибкость и расширяемость. Расширяя классы Java и настраивая их соответствующим образом, мы можем легко настраивать компоненты Solr.
База данных NoSQL — Solr также может использоваться в качестве базы данных NOSQL с большими объемами данных, где мы можем распределять задачи поиска по кластеру.
Интерфейс администратора — Solr предоставляет простой в использовании, удобный, функциональный пользовательский интерфейс, с помощью которого мы можем выполнять все возможные задачи, такие как управление журналами, добавление, удаление, обновление и поиск документов.
Высокая масштабируемость. Используя Solr с Hadoop, мы можем масштабировать его емкость, добавляя реплики.
Текст-ориентированный и отсортированный по релевантности — Solr в основном используется для поиска текстовых документов, а результаты предоставляются в соответствии с запросом пользователя по порядку.
В отличие от Lucene, вам не нужно иметь навыки программирования на Java при работе с Apache Solr. Он предоставляет замечательную готовую к развертыванию службу для создания окна поиска с автозаполнением, которое Lucene не предоставляет. Используя Solr, мы можем масштабировать, распространять и управлять индексами для крупномасштабных приложений (больших данных).
Lucene в поисковых приложениях
Lucene — это простая, но мощная библиотека поиска на основе Java. Его можно использовать в любом приложении для добавления возможностей поиска. Lucene — это масштабируемая и высокопроизводительная библиотека, используемая для индексации и поиска практически любого текста. Библиотека Lucene предоставляет основные операции, необходимые для любого поискового приложения, такие как индексирование и поиск .
Если у нас есть веб-портал с огромным объемом данных, то нам, скорее всего, потребуется поисковая система на нашем портале для извлечения соответствующей информации из огромного пула данных. Lucene работает как сердце любого поискового приложения и обеспечивает жизненно важные операции, связанные с индексацией и поиском.
Apache Solr — Основы поисковой системы
Поисковая система относится к огромной базе данных интернет-ресурсов, таких как веб-страницы, группы новостей, программы, изображения и т. Д. Она помогает находить информацию в World Wide Web.
Пользователи могут искать информацию, передавая запросы в поисковую систему в виде ключевых слов или фраз. Затем поисковая система выполняет поиск в своей базе данных и возвращает соответствующие ссылки пользователю.
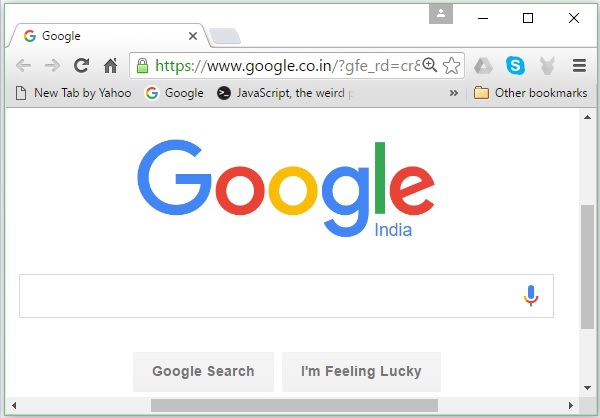
Компоненты поисковой системы
Как правило, есть три основных компонента поисковой системы, как указано ниже —
-
Web Crawler — веб-сканеры также известны как пауки или боты . Это программный компонент, который проходит через Интернет для сбора информации.
-
База данных — Вся информация в Интернете хранится в базах данных. Они содержат огромный объем веб-ресурсов.
-
Интерфейсы поиска — этот компонент является интерфейсом между пользователем и базой данных. Это помогает пользователю осуществлять поиск по базе данных.
Web Crawler — веб-сканеры также известны как пауки или боты . Это программный компонент, который проходит через Интернет для сбора информации.
База данных — Вся информация в Интернете хранится в базах данных. Они содержат огромный объем веб-ресурсов.
Интерфейсы поиска — этот компонент является интерфейсом между пользователем и базой данных. Это помогает пользователю осуществлять поиск по базе данных.
Как работают поисковые системы?
Любое приложение для поиска требуется для выполнения некоторых или всех следующих операций.
| шаг | заглавие | Описание |
|---|---|---|
|
1 |
Получить сырье |
Самым первым шагом любого поискового приложения является сбор целевого содержимого, по которому будет проводиться поиск. |
|
2 |
Построить документ |
Следующим шагом является создание документа (ов) из необработанного содержимого, которое поисковое приложение может легко понять и интерпретировать. |
|
3 |
Проанализируйте документ |
Прежде чем начать индексацию, документ должен быть проанализирован. |
|
4 |
Индексирование документа |
После того, как документы построены и проанализированы, следующим шагом является их индексация, чтобы этот документ можно было получить на основе определенных ключей, а не всего содержимого документа. Индексирование аналогично индексам, которые мы имеем в конце книги, где обычные слова показаны с номерами их страниц, так что эти слова можно быстро отслеживать, а не искать в полной книге. |
|
5 |
Пользовательский интерфейс для поиска |
Когда база данных индексов готова, приложение может выполнять поисковые операции. Чтобы помочь пользователю выполнить поиск, приложение должно предоставить пользовательский интерфейс, в котором пользователь может вводить текст и инициировать процесс поиска. |
|
6 |
Построить запрос |
Как только пользователь отправляет запрос на поиск текста, приложение должно подготовить объект запроса, используя этот текст, который затем можно использовать для запроса базы данных индекса для получения соответствующих сведений. |
|
7 |
Поисковый запрос |
Используя объект запроса, проверяется база данных индекса для получения соответствующих сведений и документов содержимого. |
|
8 |
Результаты рендеринга |
Как только требуемый результат получен, приложение должно решить, как отобразить результаты пользователю, используя его пользовательский интерфейс. |
1
Получить сырье
Самым первым шагом любого поискового приложения является сбор целевого содержимого, по которому будет проводиться поиск.
2
Построить документ
Следующим шагом является создание документа (ов) из необработанного содержимого, которое поисковое приложение может легко понять и интерпретировать.
3
Проанализируйте документ
Прежде чем начать индексацию, документ должен быть проанализирован.
4
Индексирование документа
После того, как документы построены и проанализированы, следующим шагом является их индексация, чтобы этот документ можно было получить на основе определенных ключей, а не всего содержимого документа.
Индексирование аналогично индексам, которые мы имеем в конце книги, где обычные слова показаны с номерами их страниц, так что эти слова можно быстро отслеживать, а не искать в полной книге.
5
Пользовательский интерфейс для поиска
Когда база данных индексов готова, приложение может выполнять поисковые операции. Чтобы помочь пользователю выполнить поиск, приложение должно предоставить пользовательский интерфейс, в котором пользователь может вводить текст и инициировать процесс поиска.
6
Построить запрос
Как только пользователь отправляет запрос на поиск текста, приложение должно подготовить объект запроса, используя этот текст, который затем можно использовать для запроса базы данных индекса для получения соответствующих сведений.
7
Поисковый запрос
Используя объект запроса, проверяется база данных индекса для получения соответствующих сведений и документов содержимого.
8
Результаты рендеринга
Как только требуемый результат получен, приложение должно решить, как отобразить результаты пользователю, используя его пользовательский интерфейс.
Посмотрите на следующую иллюстрацию. Это показывает общее представление о том, как работают поисковые системы.
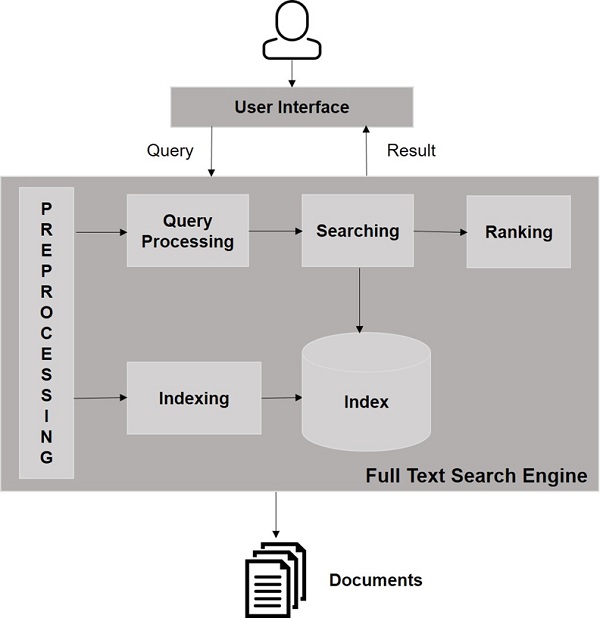
Помимо этих основных операций, поисковые приложения также могут предоставлять интерфейс администратора-пользователя, чтобы помочь администраторам контролировать уровень поиска на основе профилей пользователей. Аналитика результатов поиска — еще один важный и продвинутый аспект любого поискового приложения.
Apache Solr — в среде Windows
В этой главе мы обсудим, как настроить Solr в среде Windows. Чтобы установить Solr в вашей системе Windows, вам нужно выполнить следующие шаги:
-
Посетите домашнюю страницу Apache Solr и нажмите кнопку загрузки.
-
Выберите одно из зеркал, чтобы получить индекс Apache Solr. Оттуда скачайте файл с именем Solr-6.2.0.zip .
-
Переместите файл из папки загрузок в нужный каталог и разархивируйте его.
Посетите домашнюю страницу Apache Solr и нажмите кнопку загрузки.
Выберите одно из зеркал, чтобы получить индекс Apache Solr. Оттуда скачайте файл с именем Solr-6.2.0.zip .
Переместите файл из папки загрузок в нужный каталог и разархивируйте его.
Предположим, вы загрузили Solr fie и распаковали его на диск C. В таком случае вы можете запустить Solr, как показано на следующем снимке экрана.
Чтобы проверить установку, используйте следующий URL в вашем браузере.
HTTP: // локальный: 8983 /
Если процесс установки прошел успешно, вы увидите панель управления пользовательского интерфейса Apache Solr, как показано ниже.
Настройка среды Java
Мы также можем общаться с Apache Solr, используя библиотеки Java; но прежде чем получить доступ к Solr с помощью Java API, вам нужно установить classpath для этих библиотек.
Установка пути к классам
Установите classpath для библиотек Solr в файле .bashrc . Откройте .bashrc в любом из редакторов, как показано ниже.
$ gedit ~/.bashrc
Установите classpath для библиотек Solr (папка lib в HBase), как показано ниже.
export CLASSPATH = $CLASSPATH://home/hadoop/Solr/lib/*
Это сделано для предотвращения исключения «класс не найден» при доступе к HBase с использованием Java API.
Apache Solr — на Hadoop
Solr можно использовать вместе с Hadoop. Поскольку Hadoop обрабатывает большой объем данных, Solr помогает нам найти необходимую информацию из такого большого источника. В этом разделе мы расскажем, как установить Hadoop в своей системе.
Загрузка Hadoop
Ниже приведены шаги, которые необходимо выполнить для загрузки Hadoop в вашу систему.
Шаг 1 — Перейдите на домашнюю страницу Hadoop. Вы можете использовать ссылку — www.hadoop.apache.org/ . Нажмите на ссылку Releases , как показано на следующем снимке экрана.
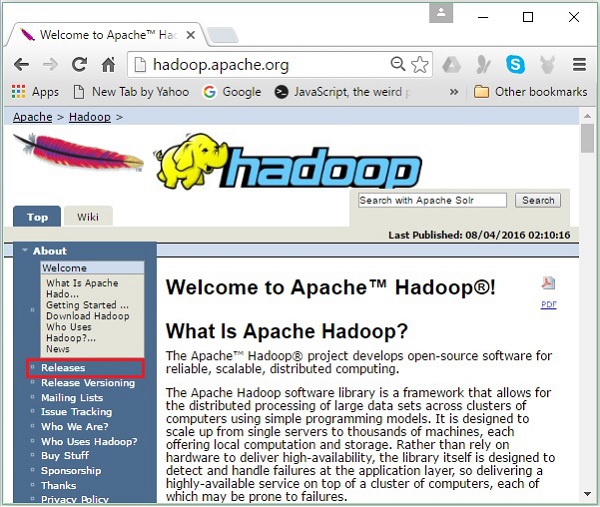
Он перенаправит вас на страницу Apache Hadoop Releases, которая содержит ссылки на зеркала исходных и двоичных файлов различных версий Hadoop следующим образом:
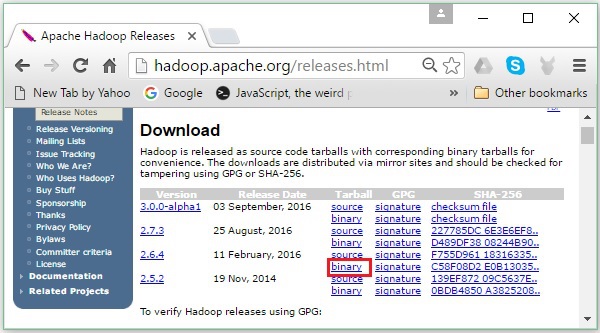
Шаг 2 — Выберите последнюю версию Hadoop (в нашем руководстве это 2.6.4) и щелкните по ее бинарной ссылке . Вы попадете на страницу, где доступны зеркала для двоичного кода Hadoop. Нажмите на одно из этих зеркал, чтобы загрузить Hadoop.
Загрузите Hadoop из командной строки
Откройте терминал Linux и войдите в систему как суперпользователь.
$ su password:
Перейдите в каталог, где вам нужно установить Hadoop, и сохраните файл там, используя ранее скопированную ссылку, как показано в следующем блоке кода.
# cd /usr/local # wget http://redrockdigimark.com/apachemirror/hadoop/common/hadoop- 2.6.4/hadoop-2.6.4.tar.gz
После загрузки Hadoop извлеките его с помощью следующих команд.
# tar zxvf hadoop-2.6.4.tar.gz # mkdir hadoop # mv hadoop-2.6.4/* to hadoop/ # exit
Установка Hadoop
Следуйте приведенным ниже инструкциям, чтобы установить Hadoop в псевдораспределенном режиме.
Шаг 1: Настройка Hadoop
Вы можете установить переменные среды Hadoop, добавив следующие команды в файл ~ / .bashrc .
export HADOOP_HOME = /usr/local/hadoop export HADOOP_MAPRED_HOME = $HADOOP_HOME export HADOOP_COMMON_HOME = $HADOOP_HOME export HADOOP_HDFS_HOME = $HADOOP_HOME export YARN_HOME = $HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR = $HADOOP_HOME/lib/native export PATH = $PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin export HADOOP_INSTALL = $HADOOP_HOME
Затем примените все изменения в текущей работающей системе.
$ source ~/.bashrc
Шаг 2: Конфигурация Hadoop
Вы можете найти все файлы конфигурации Hadoop в папке «$ HADOOP_HOME / etc / hadoop». Необходимо внести изменения в эти файлы конфигурации в соответствии с вашей инфраструктурой Hadoop.
$ cd $HADOOP_HOME/etc/hadoop
Для разработки программ Hadoop на Java вам необходимо сбросить переменные среды Java в файле hadoop-env.sh , заменив значение JAVA_HOME расположением Java в вашей системе.
export JAVA_HOME = /usr/local/jdk1.7.0_71
Ниже приведен список файлов, которые вы должны отредактировать для настройки Hadoop:
- ядро-site.xml
- HDFS-site.xml
- Пряжа-site.xml
- mapred-site.xml
ядро-site.xml
Файл core-site.xml содержит такую информацию, как номер порта, используемый для экземпляра Hadoop, память, выделенная для файловой системы, лимит памяти для хранения данных и размер буферов чтения / записи.
Откройте файл core-site.xml и добавьте следующие свойства в теги <configuration>, </ configuration>.
<configuration> <property> <name>fs.default.name</name> <value>hdfs://localhost:9000</value> </property> </configuration>
HDFS-site.xml
Файл hdfs-site.xml содержит такую информацию, как значение данных репликации, путь namenode и пути datanode вашей локальной файловой системы. Это место, где вы хотите хранить инфраструктуру Hadoop.
Допустим, следующие данные.
dfs.replication (data replication value) = 1 (In the below given path /hadoop/ is the user name. hadoopinfra/hdfs/namenode is the directory created by hdfs file system.) namenode path = //home/hadoop/hadoopinfra/hdfs/namenode (hadoopinfra/hdfs/datanode is the directory created by hdfs file system.) datanode path = //home/hadoop/hadoopinfra/hdfs/datanode
Откройте этот файл и добавьте следующие свойства в теги <configuration>, </ configuration>.
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.name.dir</name> <value>file:///home/hadoop/hadoopinfra/hdfs/namenode</value> </property> <property> <name>dfs.data.dir</name> <value>file:///home/hadoop/hadoopinfra/hdfs/datanode</value> </property> </configuration>
Примечание. В приведенном выше файле все значения свойств определяются пользователем, и вы можете вносить изменения в соответствии с инфраструктурой Hadoop.
Пряжа-site.xml
Этот файл используется для настройки пряжи в Hadoop. Откройте файл yarn-site.xml и добавьте следующие свойства между тегами <configuration>, </ configuration> в этом файле.
<configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration>
mapred-site.xml
Этот файл используется, чтобы указать, какую платформу MapReduce мы используем. По умолчанию Hadoop содержит шаблон yarn-site.xml. Прежде всего, необходимо скопировать файл из mapred-site, xml.template в файл mapred-site.xml, используя следующую команду.
$ cp mapred-site.xml.template mapred-site.xml
Откройте файл mapred-site.xml и добавьте следующие свойства в теги <configuration>, </ configuration>.
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
Проверка правильности установки Hadoop
Следующие шаги используются для проверки установки Hadoop.
Шаг 1: Настройка имени узла
Настройте namenode с помощью команды «hdfs namenode –format» следующим образом.
$ cd ~ $ hdfs namenode -format
Ожидаемый результат заключается в следующем.
10/24/14 21:30:55 INFO namenode.NameNode: STARTUP_MSG: /************************************************************ STARTUP_MSG: Starting NameNode STARTUP_MSG: host = localhost/192.168.1.11 STARTUP_MSG: args = [-format] STARTUP_MSG: version = 2.6.4 ... ... 10/24/14 21:30:56 INFO common.Storage: Storage directory /home/hadoop/hadoopinfra/hdfs/namenode has been successfully formatted. 10/24/14 21:30:56 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0 10/24/14 21:30:56 INFO util.ExitUtil: Exiting with status 0 10/24/14 21:30:56 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at localhost/192.168.1.11 ************************************************************/
Шаг 2: Проверка Hadoop dfs
Следующая команда используется для запуска Hadoop dfs. Выполнение этой команды запустит вашу файловую систему Hadoop.
$ start-dfs.sh
Ожидаемый результат следующий:
10/24/14 21:37:56 Starting namenodes on [localhost] localhost: starting namenode, logging to /home/hadoop/hadoop-2.6.4/logs/hadoop- hadoop-namenode-localhost.out localhost: starting datanode, logging to /home/hadoop/hadoop-2.6.4/logs/hadoop- hadoop-datanode-localhost.out Starting secondary namenodes [0.0.0.0]
Шаг 3: Проверка скрипта пряжи
Следующая команда используется для запуска скрипта Yarn. Выполнение этой команды запустит ваших демонов Пряжи.
$ start-yarn.sh
Ожидаемый результат следующим образом —
starting yarn daemons starting resourcemanager, logging to /home/hadoop/hadoop-2.6.4/logs/yarn- hadoop-resourcemanager-localhost.out localhost: starting nodemanager, logging to /home/hadoop/hadoop- 2.6.4/logs/yarn-hadoop-nodemanager-localhost.out
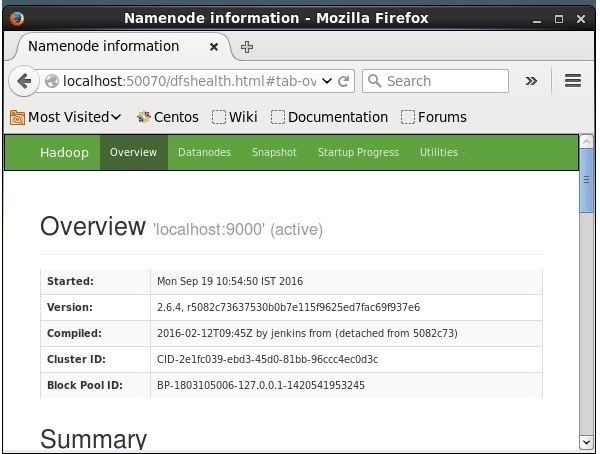
Шаг 4: Доступ к Hadoop в браузере
Номер порта по умолчанию для доступа к Hadoop — 50070. Используйте следующий URL-адрес, чтобы получить службы Hadoop в браузере.
HTTP: // локальный: 50070 /
Установка Solr на Hadoop
Следуйте инструкциям ниже, чтобы загрузить и установить Solr.
Шаг 1
Откройте домашнюю страницу Apache Solr, перейдя по следующей ссылке — https://lucene.apache.org/solr/
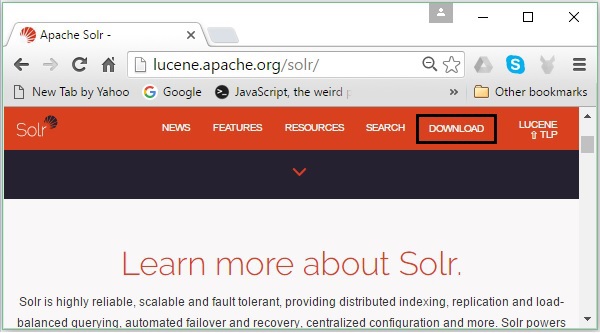
Шаг 2
Нажмите кнопку загрузки (выделено на скриншоте выше). При нажатии вы будете перенаправлены на страницу, где у вас есть различные зеркала Apache Solr. Выберите зеркало и нажмите на него, чтобы перенаправить вас на страницу, где вы можете загрузить исходные и двоичные файлы Apache Solr, как показано на следующем снимке экрана.
Шаг 3
При щелчке папка с именем Solr-6.2.0.tqz будет загружена в папку загрузок вашей системы. Извлеките содержимое загруженной папки.
Шаг 4
Создайте папку с именем Solr в домашнем каталоге Hadoop и переместите в нее содержимое извлеченной папки, как показано ниже.
$ mkdir Solr $ cd Downloads $ mv Solr-6.2.0 /home/Hadoop/
верификация
Просмотрите папку bin в каталоге Solr Home и проверьте установку, используя опцию версии , как показано в следующем блоке кода.
$ cd bin/ $ ./Solr version 6.2.0
Настройка дома и пути
Откройте файл .bashrc, используя следующую команду —
[Hadoop@localhost ~]$ source ~/.bashrc
Теперь установите каталоги home и path для Apache Solr следующим образом:
export SOLR_HOME = /home/Hadoop/Solr export PATH = $PATH:/$SOLR_HOME/bin/
Откройте терминал и выполните следующую команду —
[Hadoop@localhost Solr]$ source ~/.bashrc
Теперь вы можете выполнять команды Solr из любого каталога.
Apache Solr — Архитектура
В этой главе мы обсудим архитектуру Apache Solr. На следующем рисунке показана блок-схема архитектуры Apache Solr.
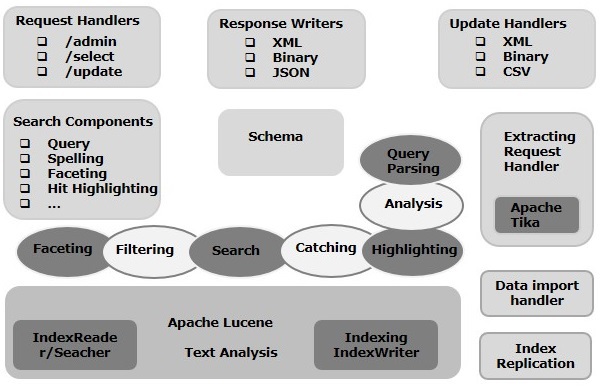
Solr Architecture ─ Строительные блоки
Ниже приведены основные строительные блоки (компоненты) Apache Solr —
-
Обработчик запросов — запросы, которые мы отправляем в Apache Solr, обрабатываются этими обработчиками запросов. Запросы могут быть запросами запроса или запросами на обновление индекса. Исходя из нашего требования, нам нужно выбрать обработчик запроса. Чтобы передать запрос в Solr, мы обычно сопоставляем обработчик с определенной конечной точкой URI, и указанный запрос будет обслуживаться им.
-
Компонент поиска — компонент поиска — это тип (функция) поиска, предоставляемый в Apache Solr. Это может быть проверка орфографии, запрос, огранка, выделение совпадений и т. Д. Эти компоненты поиска зарегистрированы как обработчики поиска . Несколько компонентов могут быть зарегистрированы в обработчике поиска.
-
Парсер запросов — Парсер запросов Apache Solr анализирует запросы, которые мы передаем Solr, и проверяет запросы на наличие синтаксических ошибок. После анализа запросов он переводит их в формат, понятный Lucene.
-
Средство записи ответов — Средство записи ответов в Apache Solr — это компонент, который генерирует форматированный вывод для пользовательских запросов. Solr поддерживает форматы ответов, такие как XML, JSON, CSV и т. Д. У нас есть разные средства записи ответов для каждого типа ответа.
-
Анализатор / токенизатор — Lucene распознает данные в виде токенов. Apache Solr анализирует содержимое, разделяет его на токены и передает эти токены в Lucene. Анализатор в Apache Solr анализирует текст полей и генерирует поток токенов. Токенизатор разбивает поток токенов, подготовленный анализатором, на токены.
-
Процессор запросов на обновление — всякий раз, когда мы отправляем запрос на обновление в Apache Solr, запрос выполняется через набор плагинов (подпись, ведение журнала, индексирование), которые в совокупности известны как процессор запросов на обновление . Этот процессор отвечает за изменения, такие как удаление поля, добавление поля и т. Д.
Обработчик запросов — запросы, которые мы отправляем в Apache Solr, обрабатываются этими обработчиками запросов. Запросы могут быть запросами запроса или запросами на обновление индекса. Исходя из нашего требования, нам нужно выбрать обработчик запроса. Чтобы передать запрос в Solr, мы обычно сопоставляем обработчик с определенной конечной точкой URI, и указанный запрос будет обслуживаться им.
Компонент поиска — компонент поиска — это тип (функция) поиска, предоставляемый в Apache Solr. Это может быть проверка орфографии, запрос, огранка, выделение совпадений и т. Д. Эти компоненты поиска зарегистрированы как обработчики поиска . Несколько компонентов могут быть зарегистрированы в обработчике поиска.
Парсер запросов — Парсер запросов Apache Solr анализирует запросы, которые мы передаем Solr, и проверяет запросы на наличие синтаксических ошибок. После анализа запросов он переводит их в формат, понятный Lucene.
Средство записи ответов — Средство записи ответов в Apache Solr — это компонент, который генерирует форматированный вывод для пользовательских запросов. Solr поддерживает форматы ответов, такие как XML, JSON, CSV и т. Д. У нас есть разные средства записи ответов для каждого типа ответа.
Анализатор / токенизатор — Lucene распознает данные в виде токенов. Apache Solr анализирует содержимое, разделяет его на токены и передает эти токены в Lucene. Анализатор в Apache Solr анализирует текст полей и генерирует поток токенов. Токенизатор разбивает поток токенов, подготовленный анализатором, на токены.
Процессор запросов на обновление — всякий раз, когда мы отправляем запрос на обновление в Apache Solr, запрос выполняется через набор плагинов (подпись, ведение журнала, индексирование), которые в совокупности известны как процессор запросов на обновление . Этот процессор отвечает за изменения, такие как удаление поля, добавление поля и т. Д.
Apache Solr — Терминология
В этой главе мы попытаемся понять реальное значение некоторых терминов, которые часто используются при работе с Solr.
Общая терминология
Ниже приведен список общих терминов, которые используются во всех типах установок Solr:
-
Экземпляр — Точно так же, как экземпляр Tomcat или Jetty , этот термин относится к серверу приложений, который работает внутри JVM. Домашний каталог Solr содержит ссылку на каждый из этих экземпляров Solr, в котором одно или несколько ядер могут быть настроены для работы в каждом экземпляре.
-
Ядро — при запуске нескольких индексов в вашем приложении вы можете иметь несколько ядер в каждом экземпляре, вместо нескольких экземпляров, каждое из которых имеет одно ядро.
-
Домашний — термин $ SOLR_HOME относится к домашнему каталогу, который содержит всю информацию, касающуюся ядер, их индексов, конфигураций и зависимостей.
-
Shard — в распределенных средах данные распределяются между несколькими экземплярами Solr, где каждый кусок данных можно назвать Shard . Он содержит подмножество всего индекса.
Экземпляр — Точно так же, как экземпляр Tomcat или Jetty , этот термин относится к серверу приложений, который работает внутри JVM. Домашний каталог Solr содержит ссылку на каждый из этих экземпляров Solr, в котором одно или несколько ядер могут быть настроены для работы в каждом экземпляре.
Ядро — при запуске нескольких индексов в вашем приложении вы можете иметь несколько ядер в каждом экземпляре, вместо нескольких экземпляров, каждое из которых имеет одно ядро.
Домашний — термин $ SOLR_HOME относится к домашнему каталогу, который содержит всю информацию, касающуюся ядер, их индексов, конфигураций и зависимостей.
Shard — в распределенных средах данные распределяются между несколькими экземплярами Solr, где каждый кусок данных можно назвать Shard . Он содержит подмножество всего индекса.
SolrCloud Терминология
В предыдущей главе мы обсуждали, как установить Apache Solr в автономном режиме. Обратите внимание, что мы также можем установить Solr в распределенном режиме (облачная среда), где Solr устанавливается в шаблоне главный-подчиненный. В распределенном режиме индекс создается на главном сервере и реплицируется на один или несколько подчиненных серверов.
Ключевые термины, связанные с Solr Cloud, следующие:
-
Узел — В облаке Solr каждый отдельный экземпляр Solr рассматривается как узел .
-
Кластер — все узлы среды, объединенные вместе, образуют кластер .
-
Коллекция . Кластер имеет логический индекс, который называется коллекцией .
-
Осколок — это часть коллекции, в которой есть одна или несколько копий индекса.
-
Реплика. В Solr Core копия осколка, которая работает в узле, называется репликой .
-
Лидер — это также точная копия осколка, которая распределяет запросы облака Solr по оставшимся репликам.
-
Zookeeper — это проект Apache, который Solr Cloud использует для централизованной настройки и координации, управления кластером и выбора лидера.
Узел — В облаке Solr каждый отдельный экземпляр Solr рассматривается как узел .
Кластер — все узлы среды, объединенные вместе, образуют кластер .
Коллекция . Кластер имеет логический индекс, который называется коллекцией .
Осколок — это часть коллекции, в которой есть одна или несколько копий индекса.
Реплика. В Solr Core копия осколка, которая работает в узле, называется репликой .
Лидер — это также точная копия осколка, которая распределяет запросы облака Solr по оставшимся репликам.
Zookeeper — это проект Apache, который Solr Cloud использует для централизованной настройки и координации, управления кластером и выбора лидера.
Конфигурационные файлы
Основные конфигурационные файлы в Apache Solr:
-
Solr.xml — это файл в каталоге $ SOLR_HOME, который содержит информацию, связанную с Solr Cloud. Для загрузки ядер Solr обращается к этому файлу, который помогает их идентифицировать.
-
Solrconfig.xml — этот файл содержит определения и специфичные для ядра конфигурации, связанные с обработкой запросов и форматированием ответов, а также с индексацией, настройкой, управлением памятью и выполнением коммитов.
-
Schema.xml — этот файл содержит всю схему вместе с полями и типами полей.
-
Core.properties — этот файл содержит конфигурации, специфичные для ядра. Он передается для обнаружения ядра , так как содержит имя ядра и путь к каталогу данных. Его можно использовать в любом каталоге, который затем будет рассматриваться как основной каталог .
Solr.xml — это файл в каталоге $ SOLR_HOME, который содержит информацию, связанную с Solr Cloud. Для загрузки ядер Solr обращается к этому файлу, который помогает их идентифицировать.
Solrconfig.xml — этот файл содержит определения и специфичные для ядра конфигурации, связанные с обработкой запросов и форматированием ответов, а также с индексацией, настройкой, управлением памятью и выполнением коммитов.
Schema.xml — этот файл содержит всю схему вместе с полями и типами полей.
Core.properties — этот файл содержит конфигурации, специфичные для ядра. Он передается для обнаружения ядра , так как содержит имя ядра и путь к каталогу данных. Его можно использовать в любом каталоге, который затем будет рассматриваться как основной каталог .
Apache Solr — Основные команды
Начиная Solr
После установки Solr перейдите в папку bin в домашнем каталоге Solr и запустите Solr, используя следующую команду.
[Hadoop@localhost ~]$ cd [Hadoop@localhost ~]$ cd Solr/ [Hadoop@localhost Solr]$ cd bin/ [Hadoop@localhost bin]$ ./Solr start
Эта команда запускает Solr в фоновом режиме, прослушивая порт 8983, отображая следующее сообщение.
Waiting up to 30 seconds to see Solr running on port 8983 [\] Started Solr server on port 8983 (pid = 6035). Happy searching!
Начиная Solr на переднем плане
Если вы запустите Solr с помощью команды запуска , Solr запустится в фоновом режиме. Вместо этого вы можете запустить Solr на переднем плане, используя опцию –f .
[Hadoop@localhost bin]$ ./Solr start –f 5823 INFO (coreLoadExecutor-6-thread-2) [ ] o.a.s.c.SolrResourceLoader Adding 'file:/home/Hadoop/Solr/contrib/extraction/lib/xmlbeans-2.6.0.jar' to classloader 5823 INFO (coreLoadExecutor-6-thread-2) [ ] o.a.s.c.SolrResourceLoader Adding 'file:/home/Hadoop/Solr/dist/Solr-cell-6.2.0.jar' to classloader 5823 INFO (coreLoadExecutor-6-thread-2) [ ] o.a.s.c.SolrResourceLoader Adding 'file:/home/Hadoop/Solr/contrib/clustering/lib/carrot2-guava-18.0.jar' to classloader 5823 INFO (coreLoadExecutor-6-thread-2) [ ] o.a.s.c.SolrResourceLoader Adding 'file:/home/Hadoop/Solr/contrib/clustering/lib/attributes-binder1.3.1.jar' to classloader 5823 INFO (coreLoadExecutor-6-thread-2) [ ] o.a.s.c.SolrResourceLoader Adding 'file:/home/Hadoop/Solr/contrib/clustering/lib/simple-xml-2.7.1.jar' to classloader …………………………………………………………………………………………………………………………………………………………………………………………………………… …………………………………………………………………………………………………………………………………………………………………………………………………. 12901 INFO (coreLoadExecutor-6-thread-1) [ x:Solr_sample] o.a.s.u.UpdateLog Took 24.0ms to seed version buckets with highest version 1546058939881226240 12902 INFO (coreLoadExecutor-6-thread-1) [ x:Solr_sample] o.a.s.c.CoreContainer registering core: Solr_sample 12904 INFO (coreLoadExecutor-6-thread-2) [ x:my_core] o.a.s.u.UpdateLog Took 16.0ms to seed version buckets with highest version 1546058939894857728 12904 INFO (coreLoadExecutor-6-thread-2) [ x:my_core] o.a.s.c.CoreContainer registering core: my_core
Запуск Solr на другом порту
Используя опцию –p команды start , мы можем запустить Solr на другом порту, как показано в следующем блоке кода.
[Hadoop@localhost bin]$ ./Solr start -p 8984 Waiting up to 30 seconds to see Solr running on port 8984 [-] Started Solr server on port 8984 (pid = 10137). Happy searching!
Остановка Solr
Вы можете остановить Solr используя команду stop .
$ ./Solr stop
Эта команда останавливает Solr, отображая сообщение, как показано ниже.
Sending stop command to Solr running on port 8983 ... waiting 5 seconds to allow Jetty process 6035 to stop gracefully.
Перезапуск Solr
Команда перезапуска Solr останавливает Solr на 5 секунд и запускает его снова. Вы можете перезапустить Solr, используя следующую команду —
./Solr restart
Эта команда перезапускает Solr, отображая следующее сообщение —
Sending stop command to Solr running on port 8983 ... waiting 5 seconds to allow Jetty process 6671 to stop gracefully. Waiting up to 30 seconds to see Solr running on port 8983 [|] [/] Started Solr server on port 8983 (pid = 6906). Happy searching!
Solr ─ команда помощи
Команда справки Solr может использоваться для проверки использования подсказки Solr и ее параметров.
[Hadoop@localhost bin]$ ./Solr -help Usage: Solr COMMAND OPTIONS where COMMAND is one of: start, stop, restart, status, healthcheck, create, create_core, create_collection, delete, version, zk Standalone server example (start Solr running in the background on port 8984): ./Solr start -p 8984 SolrCloud example (start Solr running in SolrCloud mode using localhost:2181 to connect to Zookeeper, with 1g max heap size and remote Java debug options enabled): ./Solr start -c -m 1g -z localhost:2181 -a "-Xdebug - Xrunjdwp:transport = dt_socket,server = y,suspend = n,address = 1044" Pass -help after any COMMAND to see command-specific usage information, such as: ./Solr start -help or ./Solr stop -help
Solr ─ статус команды
Эту команду состояния Solr можно использовать для поиска и обнаружения запущенных экземпляров Solr на вашем компьютере. Он может предоставить вам информацию об экземпляре Solr, такую как его версия, использование памяти и т. Д.
Вы можете проверить состояние экземпляра Solr, используя команду status следующим образом:
[Hadoop@localhost bin]$ ./Solr status
При выполнении вышеупомянутая команда отображает статус Solr следующим образом:
Found 1 Solr nodes:
Solr process 6906 running on port 8983 {
"Solr_home":"/home/Hadoop/Solr/server/Solr",
"version":"6.2.0 764d0f19151dbff6f5fcd9fc4b2682cf934590c5 -
mike - 2016-08-20 05:41:37",
"startTime":"2016-09-20T06:00:02.877Z",
"uptime":"0 days, 0 hours, 5 minutes, 14 seconds",
"memory":"30.6 MB (%6.2) of 490.7 MB"
}
Solr Admin
После запуска Apache Solr вы можете посетить домашнюю страницу веб-интерфейса Solr , используя следующий URL-адрес.
Localhost:8983/Solr/
Интерфейс Solr Admin выглядит следующим образом —
Apache Solr — Core
Solr Core — это работающий экземпляр индекса Lucene, который содержит все файлы конфигурации Solr, необходимые для его использования. Нам нужно создать Solr Core для выполнения таких операций, как индексация и анализ.
Приложение Solr может содержать одно или несколько ядер. При необходимости два ядра в приложении Solr могут связываться друг с другом.
Создание ядра
После установки и запуска Solr вы можете подключиться к клиенту (веб-интерфейсу) Solr.
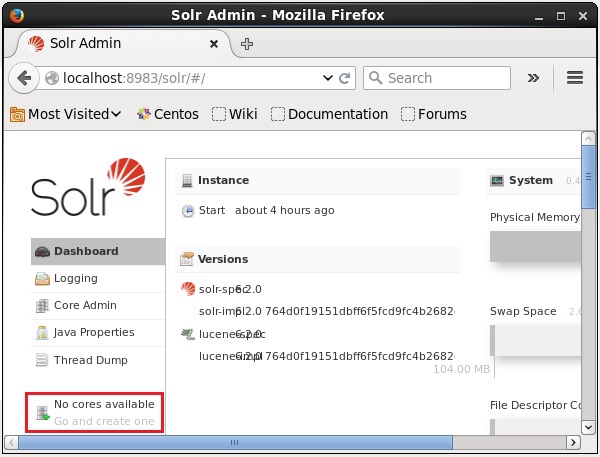
Как показано на следующем снимке экрана, изначально в Apache Solr нет ядер. Теперь посмотрим, как создать ядро в Solr.
Используя команду создания
Одним из способов создания ядра является создание ядра без схемы с помощью команды create , как показано ниже:
[Hadoop@localhost bin]$ ./Solr create -c Solr_sample
Здесь мы пытаемся создать ядро с именем Solr_sample в Apache Solr. Эта команда создает ядро, отображающее следующее сообщение.
Copying configuration to new core instance directory:
/home/Hadoop/Solr/server/Solr/Solr_sample
Creating new core 'Solr_sample' using command:
http://localhost:8983/Solr/admin/cores?action=CREATE&name=Solr_sample&instanceD
ir = Solr_sample {
"responseHeader":{
"status":0,
"QTime":11550
},
"core":"Solr_sample"
}
Вы можете создать несколько ядер в Solr. В левой части Solr Admin вы можете видеть селектор ядра, где вы можете выбрать только что созданное ядро, как показано на следующем скриншоте.
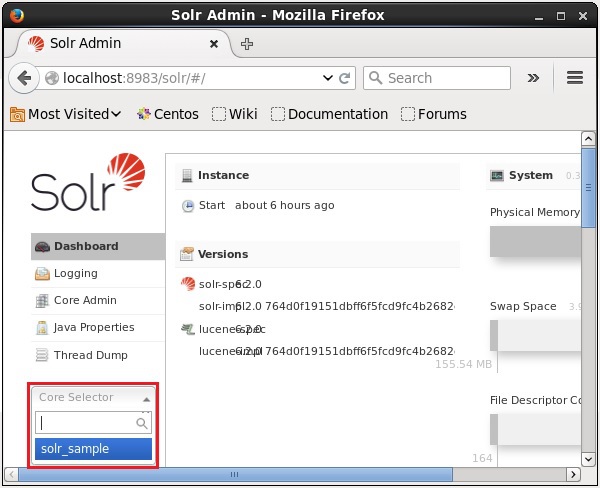
Использование команды create_core
Кроме того, вы можете создать ядро с помощью команды create_core . Эта команда имеет следующие параметры —
| –C core_name | Название ядра, которое вы хотели создать |
| -p имя_порта | Порт, на котором вы хотите создать ядро |
| -d conf_dir | Каталог конфигурации порта |
Давайте посмотрим, как вы можете использовать команду create_core . Здесь мы попытаемся создать ядро с именем my_core .
[Hadoop@localhost bin]$ ./Solr create_core -c my_core
При выполнении вышеуказанная команда создает ядро, отображающее следующее сообщение:
Copying configuration to new core instance directory:
/home/Hadoop/Solr/server/Solr/my_core
Creating new core 'my_core' using command:
http://localhost:8983/Solr/admin/cores?action=CREATE&name=my_core&instanceD
ir = my_core {
"responseHeader":{
"status":0,
"QTime":1346
},
"core":"my_core"
}
Удаление ядра
Вы можете удалить ядро, используя команду удаления Apache Solr. Предположим, у нас есть ядро с именем my_core в Solr, как показано на следующем снимке экрана.
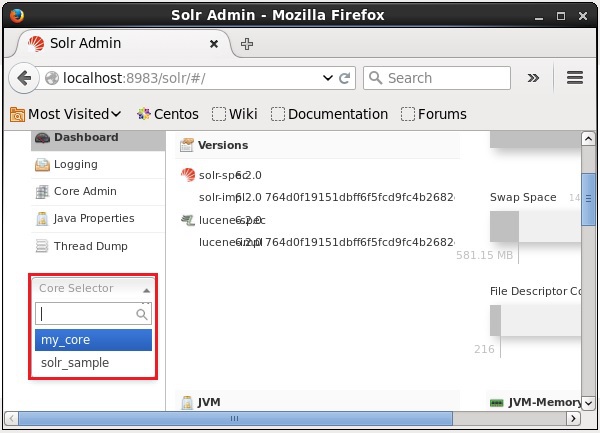
Вы можете удалить это ядро, используя команду delete , передав имя ядра этой команде следующим образом:
[Hadoop@localhost bin]$ ./Solr delete -c my_core
При выполнении вышеупомянутой команды указанное ядро будет удалено с отображением следующего сообщения.
Deleting core 'my_core' using command:
http://localhost:8983/Solr/admin/cores?action=UNLOAD&core = my_core&deleteIndex
= true&deleteDataDir = true&deleteInstanceDir = true {
"responseHeader" :{
"status":0,
"QTime":170
}
}
Вы можете открыть веб-интерфейс Solr, чтобы проверить, было ли удалено ядро или нет.
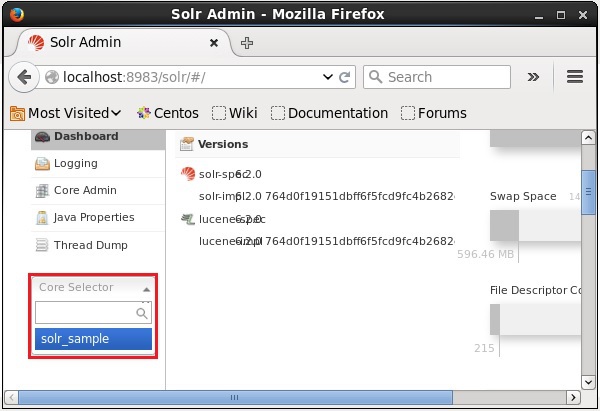
Apache Solr — индексирование данных
В целом, индексирование — это систематизация документов или (других лиц). Индексирование позволяет пользователям находить информацию в документе.
-
Индексирование собирает, анализирует и хранит документы.
-
Индексация выполняется для увеличения скорости и производительности поискового запроса при поиске необходимого документа.
Индексирование собирает, анализирует и хранит документы.
Индексация выполняется для увеличения скорости и производительности поискового запроса при поиске необходимого документа.
Индексация в Apache Solr
В Apache Solr мы можем индексировать (добавлять, удалять, изменять) различные форматы документов, такие как xml, csv, pdf и т. Д. Мы можем добавлять данные в индекс Solr несколькими способами.
В этой главе мы собираемся обсудить индексирование —
- Использование веб-интерфейса Solr.
- Использование любого из клиентских API, таких как Java, Python и т. Д.
- Используя почтовый инструмент .
В этой главе мы обсудим, как добавить данные в индекс Apache Solr, используя различные интерфейсы (командная строка, веб-интерфейс и клиентский API Java).
Добавление документов с помощью команды Post
Solr имеет команду post в своем каталоге bin / . Используя эту команду, вы можете индексировать различные форматы файлов, такие как JSON, XML, CSV в Apache Solr.
Просмотрите каталог bin в Apache Solr и выполните опцию –h команды post, как показано в следующем блоке кода.
[Hadoop@localhost bin]$ cd $SOLR_HOME [Hadoop@localhost bin]$ ./post -h
После выполнения вышеуказанной команды вы получите список параметров команды post , как показано ниже.
Usage: post -c <collection> [OPTIONS] <files|directories|urls|-d [".."]>
or post –help
collection name defaults to DEFAULT_SOLR_COLLECTION if not specified
OPTIONS
=======
Solr options:
-url <base Solr update URL> (overrides collection, host, and port)
-host <host> (default: localhost)
-p or -port <port> (default: 8983)
-commit yes|no (default: yes)
Web crawl options:
-recursive <depth> (default: 1)
-delay <seconds> (default: 10)
Directory crawl options:
-delay <seconds> (default: 0)
stdin/args options:
-type <content/type> (default: application/xml)
Other options:
-filetypes <type>[,<type>,...] (default:
xml,json,jsonl,csv,pdf,doc,docx,ppt,pptx,xls,xlsx,odt,odp,ods,ott,otp,ots,
rtf,htm,html,txt,log)
-params "<key> = <value>[&<key> = <value>...]" (values must be
URL-encoded; these pass through to Solr update request)
-out yes|no (default: no; yes outputs Solr response to console)
-format Solr (sends application/json content as Solr commands
to /update instead of /update/json/docs)
Examples:
* JSON file:./post -c wizbang events.json
* XML files: ./post -c records article*.xml
* CSV file: ./post -c signals LATEST-signals.csv
* Directory of files: ./post -c myfiles ~/Documents
* Web crawl: ./post -c gettingstarted http://lucene.apache.org/Solr -recursive 1 -delay 1
* Standard input (stdin): echo '{commit: {}}' | ./post -c my_collection -
type application/json -out yes –d
* Data as string: ./post -c signals -type text/csv -out yes -d $'id,value\n1,0.47'
пример
Предположим, у нас есть файл с именем sample.csv со следующим содержимым (в каталоге bin ).
| Студенческий билет | Имя | Фамилия | Телефон | город |
|---|---|---|---|---|
| 001 | Раджив | Reddy | 9848022337 | Хайдарабад |
| 002 | Сиддхарт | Бхаттачария | 9848022338 | Kolkata |
| 003 | Раджеш | Кханна | 9848022339 | Дели |
| 004 | Preethi | Агарвал | 9848022330 | Пуна |
| 005 | Trupthi | Mohanty | 9848022336 | Бхубанешвара |
| 006 | Archana | Мишра | 9848022335 | Chennai |
Приведенный выше набор данных содержит личные данные, такие как идентификатор студента, имя, фамилия, телефон и город. Файл CSV набора данных показан ниже. Здесь вы должны отметить, что вам нужно упомянуть схему, документирующую ее первую строку.
id, first_name, last_name, phone_no, location 001, Pruthvi, Reddy, 9848022337, Hyderabad 002, kasyap, Sastry, 9848022338, Vishakapatnam 003, Rajesh, Khanna, 9848022339, Delhi 004, Preethi, Agarwal, 9848022330, Pune 005, Trupthi, Mohanty, 9848022336, Bhubaneshwar 006, Archana, Mishra, 9848022335, Chennai
Вы можете проиндексировать эти данные в ядре с именем sample_Solr, используя команду post следующим образом:
[Hadoop@localhost bin]$ ./post -c Solr_sample sample.csv
При выполнении вышеупомянутой команды данный документ индексируется под указанным ядром, генерируя следующий вывод.
/home/Hadoop/java/bin/java -classpath /home/Hadoop/Solr/dist/Solr-core 6.2.0.jar -Dauto = yes -Dc = Solr_sample -Ddata = files org.apache.Solr.util.SimplePostTool sample.csv SimplePostTool version 5.0.0 Posting files to [base] url http://localhost:8983/Solr/Solr_sample/update... Entering auto mode. File endings considered are xml,json,jsonl,csv,pdf,doc,docx,ppt,pptx,xls,xlsx,odt,odp,ods,ott,otp,ots,rtf, htm,html,txt,log POSTing file sample.csv (text/csv) to [base] 1 files indexed. COMMITting Solr index changes to http://localhost:8983/Solr/Solr_sample/update... Time spent: 0:00:00.228
Посетите домашнюю страницу веб-интерфейса Solr, используя следующий URL —
HTTP: // локальный: 8983 /
Выберите ядро Solr_sample . По умолчанию обработчиком запроса является / select, а запросом является «:». Не внося никаких изменений, нажмите кнопку « ExecuteQuery» в нижней части страницы.
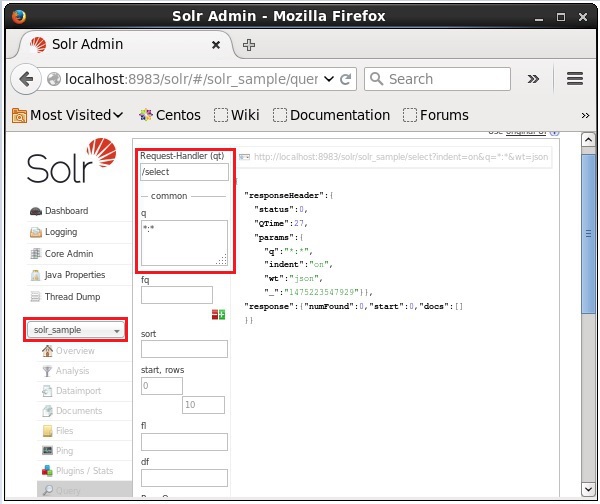
При выполнении запроса вы можете наблюдать содержимое проиндексированного CSV-документа в формате JSON (по умолчанию), как показано на следующем снимке экрана.
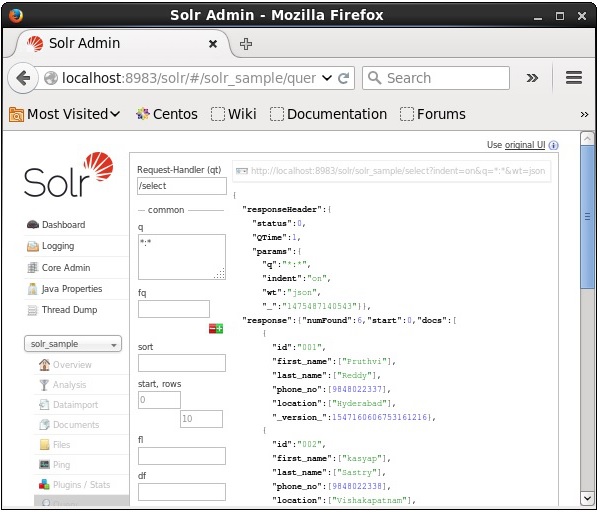
Примечание. Таким же образом можно индексировать другие форматы файлов, такие как JSON, XML, CSV и т. Д.
Добавление документов с помощью веб-интерфейса Solr
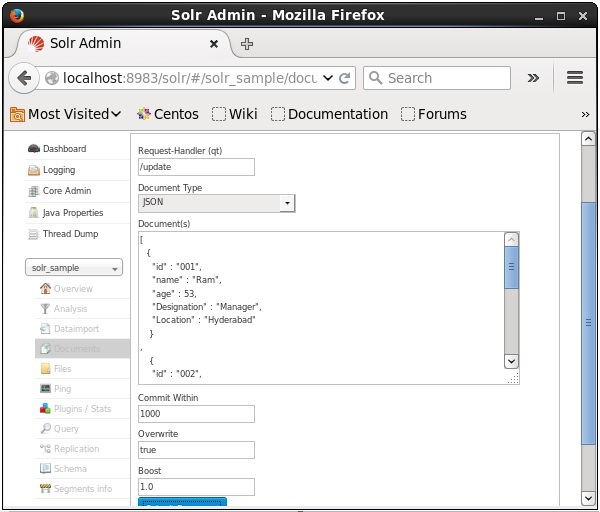
Вы также можете индексировать документы с помощью веб-интерфейса, предоставленного Solr. Давайте посмотрим, как проиндексировать следующий документ JSON.
[ { "id" : "001", "name" : "Ram", "age" : 53, "Designation" : "Manager", "Location" : "Hyderabad", }, { "id" : "002", "name" : "Robert", "age" : 43, "Designation" : "SR.Programmer", "Location" : "Chennai", }, { "id" : "003", "name" : "Rahim", "age" : 25, "Designation" : "JR.Programmer", "Location" : "Delhi", } ]
Шаг 1
Откройте веб-интерфейс Solr, используя следующий URL —
HTTP: // локальный: 8983 /
Шаг 2
Выберите ядро Solr_sample . По умолчанию значения полей «Обработчик запросов», «Общий внутри», «Перезаписать» и «Повышение» равны / update, 1000, true и 1.0 соответственно, как показано на следующем снимке экрана.
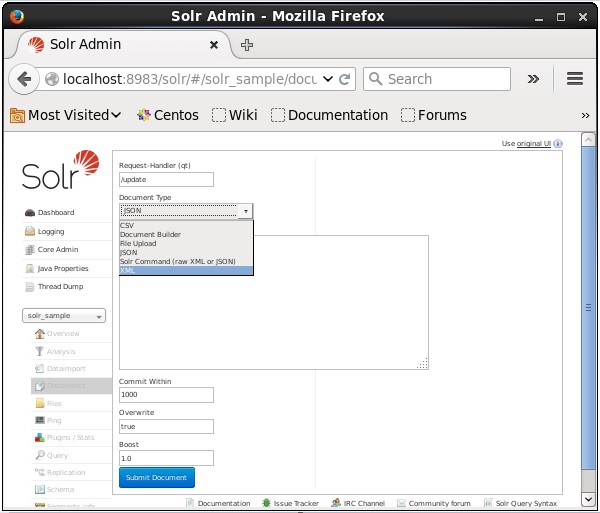
Теперь выберите нужный формат документа из JSON, CSV, XML и т. Д. Введите документ для индексирования в текстовой области и нажмите кнопку « Отправить документ» , как показано на следующем снимке экрана.
Добавление документов с использованием Java Client API
Ниже приведена Java-программа для добавления документов в индекс Apache Solr. Сохраните этот код в файле с именем AddingDocument.java .
import java.io.IOException; import org.apache.Solr.client.Solrj.SolrClient; import org.apache.Solr.client.Solrj.SolrServerException; import org.apache.Solr.client.Solrj.impl.HttpSolrClient; import org.apache.Solr.common.SolrInputDocument; public class AddingDocument { public static void main(String args[]) throws Exception { //Preparing the Solr client String urlString = "http://localhost:8983/Solr/my_core"; SolrClient Solr = new HttpSolrClient.Builder(urlString).build(); //Preparing the Solr document SolrInputDocument doc = new SolrInputDocument(); //Adding fields to the document doc.addField("id", "003"); doc.addField("name", "Rajaman"); doc.addField("age","34"); doc.addField("addr","vishakapatnam"); //Adding the document to Solr Solr.add(doc); //Saving the changes Solr.commit(); System.out.println("Documents added"); } }
Скомпилируйте приведенный выше код, выполнив следующие команды в терминале:
[Hadoop@localhost bin]$ javac AddingDocument [Hadoop@localhost bin]$ java AddingDocument
Выполнив вышеуказанную команду, вы получите следующий вывод.
Documents added
Apache Solr — Добавление документов (XML)
В предыдущей главе мы объяснили, как добавлять данные в Solr в форматах файлов JSON и .CSV. В этой главе мы покажем, как добавлять данные в индекс Apache Solr, используя формат документа XML.
Пример данных
Предположим, нам нужно добавить следующие данные в индекс Solr, используя формат файла XML.
| Студенческий билет | Имя | Фамилия | Телефон | город |
|---|---|---|---|---|
| 001 | Раджив | Reddy | 9848022337 | Хайдарабад |
| 002 | Сиддхарт | Бхаттачария | 9848022338 | Kolkata |
| 003 | Раджеш | Кханна | 9848022339 | Дели |
| 004 | Preethi | Агарвал | 9848022330 | Пуна |
| 005 | Trupthi | Mohanty | 9848022336 | Бхубанешвара |
| 006 | Archana | Мишра | 9848022335 | Chennai |
Добавление документов с использованием XML
Чтобы добавить вышеуказанные данные в индекс Solr, нам нужно подготовить документ XML, как показано ниже. Сохраните этот документ в файле с именем sample.xml .
<add> <doc> <field name = "id">001</field> <field name = "first name">Rajiv</field> <field name = "last name">Reddy</field> <field name = "phone">9848022337</field> <field name = "city">Hyderabad</field> </doc> <doc> <field name = "id">002</field> <field name = "first name">Siddarth</field> <field name = "last name">Battacharya</field> <field name = "phone">9848022338</field> <field name = "city">Kolkata</field> </doc> <doc> <field name = "id">003</field> <field name = "first name">Rajesh</field> <field name = "last name">Khanna</field> <field name = "phone">9848022339</field> <field name = "city">Delhi</field> </doc> <doc> <field name = "id">004</field> <field name = "first name">Preethi</field> <field name = "last name">Agarwal</field> <field name = "phone">9848022330</field> <field name = "city">Pune</field> </doc> <doc> <field name = "id">005</field> <field name = "first name">Trupthi</field> <field name = "last name">Mohanthy</field> <field name = "phone">9848022336</field> <field name = "city">Bhuwaeshwar</field> </doc> <doc> <field name = "id">006</field> <field name = "first name">Archana</field> <field name = "last name">Mishra</field> <field name = "phone">9848022335</field> <field name = "city">Chennai</field> </doc> </add>
Как вы можете заметить, XML-файл, написанный для добавления данных в индекс, содержит три важных тега, а именно: <add> </ add>, <doc> </ doc> и <field> </ field>.
-
add — это корневой тег для добавления документов в индекс. Он содержит один или несколько документов, которые необходимо добавить.
-
doc — документы, которые мы добавляем, должны быть заключены в теги <doc> </ doc>. Этот документ содержит данные в виде полей.
-
field — тег field содержит имя и значение полей документа.
add — это корневой тег для добавления документов в индекс. Он содержит один или несколько документов, которые необходимо добавить.
doc — документы, которые мы добавляем, должны быть заключены в теги <doc> </ doc>. Этот документ содержит данные в виде полей.
field — тег field содержит имя и значение полей документа.
После подготовки документа вы можете добавить этот документ в индекс, используя любое из средств, рассмотренных в предыдущей главе.
Предположим, что XML-файл существует в каталоге bin Solr и он должен быть проиндексирован в ядре с именем my_core , затем вы можете добавить его в индекс Solr с помощью инструмента post следующим образом:
[Hadoop@localhost bin]$ ./post -c my_core sample.xml
Выполнив вышеуказанную команду, вы получите следующий вывод.
/home/Hadoop/java/bin/java -classpath /home/Hadoop/Solr/dist/Solr- core6.2.0.jar -Dauto = yes -Dc = my_core -Ddata = files org.apache.Solr.util.SimplePostTool sample.xml SimplePostTool version 5.0.0 Posting files to [base] url http://localhost:8983/Solr/my_core/update... Entering auto mode. File endings considered are xml,json,jsonl,csv,pdf,doc,docx,ppt,pptx, xls,xlsx,odt,odp,ods,ott,otp,ots,rtf,htm,html,txt,log POSTing file sample.xml (application/xml) to [base] 1 files indexed. COMMITting Solr index changes to http://localhost:8983/Solr/my_core/update... Time spent: 0:00:00.201
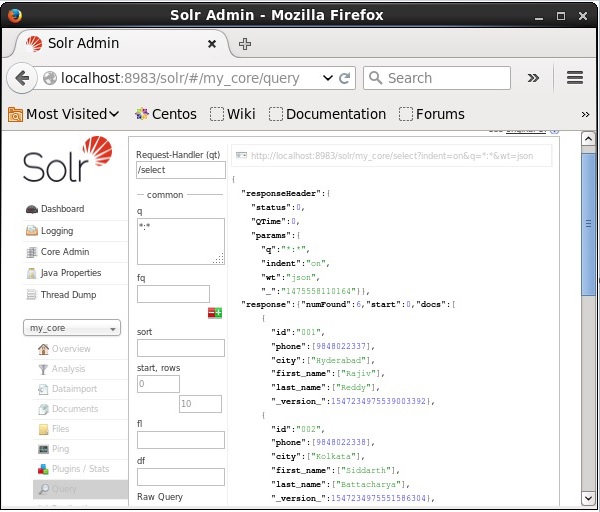
верификация
Посетите домашнюю страницу веб-интерфейса Apache Solr и выберите ядро my_core . Попробуйте получить все документы, введя запрос «:» в текстовой области q и выполните запрос. При выполнении вы можете заметить, что нужные данные добавляются в индекс Solr.
Apache Solr — Обновление данных
Обновление документа с использованием XML
Ниже приведен XML-файл, используемый для обновления поля в существующем документе. Сохраните это в файле с именем update.xml .
<add> <doc> <field name = "id">001</field> <field name = "first name" update = "set">Raj</field> <field name = "last name" update = "add">Malhotra</field> <field name = "phone" update = "add">9000000000</field> <field name = "city" update = "add">Delhi</field> </doc> </add>
Как вы можете заметить, XML-файл, написанный для обновления данных, похож на тот, который мы используем для добавления документов. Но единственное отличие состоит в том, что мы используем атрибут обновления поля.
В нашем примере мы будем использовать вышеуказанный документ и попробуем обновить поля документа с идентификатором 001 .
Предположим, что документ XML существует в каталоге bin Solr. Поскольку мы обновляем индекс, который существует в ядре с именем my_core , вы можете обновить его с помощью инструмента post следующим образом:
[Hadoop@localhost bin]$ ./post -c my_core update.xml
Выполнив вышеуказанную команду, вы получите следующий вывод.
/home/Hadoop/java/bin/java -classpath /home/Hadoop/Solr/dist/Solr-core 6.2.0.jar -Dauto = yes -Dc = my_core -Ddata = files org.apache.Solr.util.SimplePostTool update.xml SimplePostTool version 5.0.0 Posting files to [base] url http://localhost:8983/Solr/my_core/update... Entering auto mode. File endings considered are xml,json,jsonl,csv,pdf,doc,docx,ppt,pptx,xls,xlsx,odt,odp,ods,ott,otp,ots,rtf, htm,html,txt,log POSTing file update.xml (application/xml) to [base] 1 files indexed. COMMITting Solr index changes to http://localhost:8983/Solr/my_core/update... Time spent: 0:00:00.159
верификация
Посетите домашнюю страницу веб-интерфейса Apache Solr и выберите ядро как my_core . Попробуйте получить все документы, введя запрос «:» в текстовой области q и выполните запрос. При выполнении вы можете наблюдать, что документ обновляется.
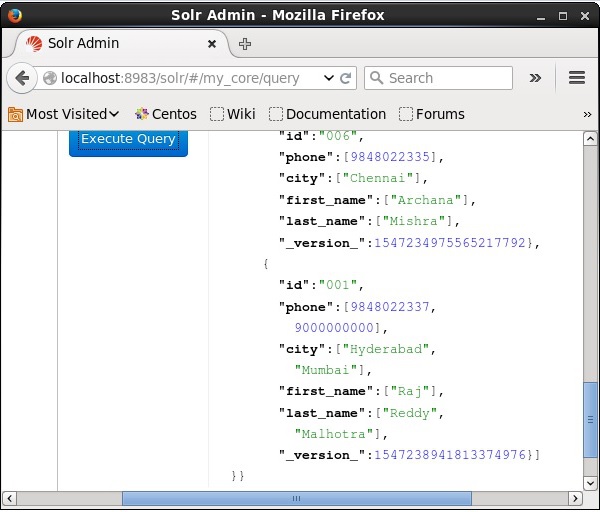
Обновление документа с помощью Java (клиентский API)
Ниже приведена Java-программа для добавления документов в индекс Apache Solr. Сохраните этот код в файле с именем UpdatingDocument.java .
import java.io.IOException; import org.apache.Solr.client.Solrj.SolrClient; import org.apache.Solr.client.Solrj.SolrServerException; import org.apache.Solr.client.Solrj.impl.HttpSolrClient; import org.apache.Solr.client.Solrj.request.UpdateRequest; import org.apache.Solr.client.Solrj.response.UpdateResponse; import org.apache.Solr.common.SolrInputDocument; public class UpdatingDocument { public static void main(String args[]) throws SolrServerException, IOException { //Preparing the Solr client String urlString = "http://localhost:8983/Solr/my_core"; SolrClient Solr = new HttpSolrClient.Builder(urlString).build(); //Preparing the Solr document SolrInputDocument doc = new SolrInputDocument(); UpdateRequest updateRequest = new UpdateRequest(); updateRequest.setAction( UpdateRequest.ACTION.COMMIT, false, false); SolrInputDocument myDocumentInstantlycommited = new SolrInputDocument(); myDocumentInstantlycommited.addField("id", "002"); myDocumentInstantlycommited.addField("name", "Rahman"); myDocumentInstantlycommited.addField("age","27"); myDocumentInstantlycommited.addField("addr","hyderabad"); updateRequest.add( myDocumentInstantlycommited); UpdateResponse rsp = updateRequest.process(Solr); System.out.println("Documents Updated"); } }
Скомпилируйте приведенный выше код, выполнив следующие команды в терминале:
[Hadoop@localhost bin]$ javac UpdatingDocument [Hadoop@localhost bin]$ java UpdatingDocument
Выполнив вышеуказанную команду, вы получите следующий вывод.
Documents updated
Apache Solr — Удаление документов
Удаление документа
Чтобы удалить документы из индекса Apache Solr, нам нужно указать идентификаторы документов, которые нужно удалить, между тегами <delete> </ delete>.
<delete> <id>003</id> <id>005</id> <id>004</id> <id>002</id> </delete>
Здесь этот код XML используется для удаления документов с идентификаторами 003 и 005 . Сохраните этот код в файле с именем delete.xml .
Если вы хотите удалить документы из индекса, который принадлежит ядру с именем my_core , вы можете опубликовать файл delete.xml с помощью инструмента post , как показано ниже.
[Hadoop@localhost bin]$ ./post -c my_core delete.xml
Выполнив вышеуказанную команду, вы получите следующий вывод.
/home/Hadoop/java/bin/java -classpath /home/Hadoop/Solr/dist/Solr-core 6.2.0.jar -Dauto = yes -Dc = my_core -Ddata = files org.apache.Solr.util.SimplePostTool delete.xml SimplePostTool version 5.0.0 Posting files to [base] url http://localhost:8983/Solr/my_core/update... Entering auto mode. File endings considered are xml,json,jsonl,csv,pdf,doc,docx,ppt,pptx,xls,xlsx,odt,odp,ods,ott,otp,ots, rtf,htm,html,txt,log POSTing file delete.xml (application/xml) to [base] 1 files indexed. COMMITting Solr index changes to http://localhost:8983/Solr/my_core/update... Time spent: 0:00:00.179
верификация
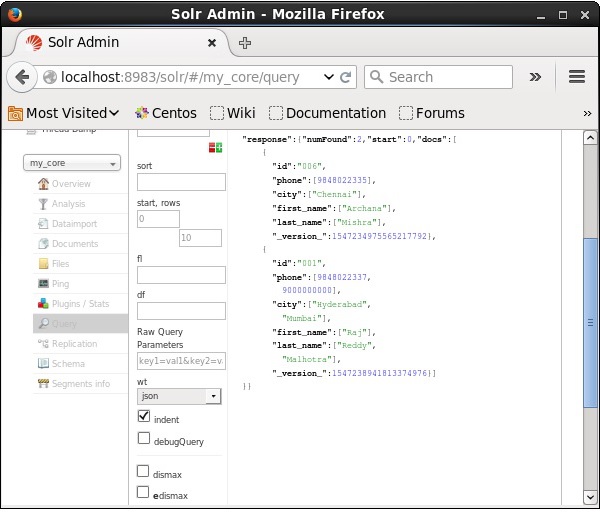
Посетите домашнюю страницу веб-интерфейса Apache Solr и выберите ядро my_core . Попробуйте получить все документы, введя запрос «:» в текстовой области q и выполните запрос. При выполнении вы можете заметить, что указанные документы удалены.
Удаление поля
Иногда нам нужно удалить документы на основе полей, отличных от ID. Например, нам, возможно, придется удалить документы, где город Ченнай.
В таких случаях вам необходимо указать имя и значение поля в паре тегов <query> </ query>.
<delete> <query>city:Chennai</query> </delete>
Сохраните его как delete_field.xml и выполните операцию удаления в ядре с именем my_core с помощью инструмента post Solr.
[Hadoop@localhost bin]$ ./post -c my_core delete_field.xml
При выполнении вышеупомянутой команды это производит следующий вывод.
/home/Hadoop/java/bin/java -classpath /home/Hadoop/Solr/dist/Solr-core 6.2.0.jar -Dauto = yes -Dc = my_core -Ddata = files org.apache.Solr.util.SimplePostTool delete_field.xml SimplePostTool version 5.0.0 Posting files to [base] url http://localhost:8983/Solr/my_core/update... Entering auto mode. File endings considered are xml,json,jsonl,csv,pdf,doc,docx,ppt,pptx,xls,xlsx,odt,odp,ods,ott,otp,ots, rtf,htm,html,txt,log POSTing file delete_field.xml (application/xml) to [base] 1 files indexed. COMMITting Solr index changes to http://localhost:8983/Solr/my_core/update... Time spent: 0:00:00.084
верификация
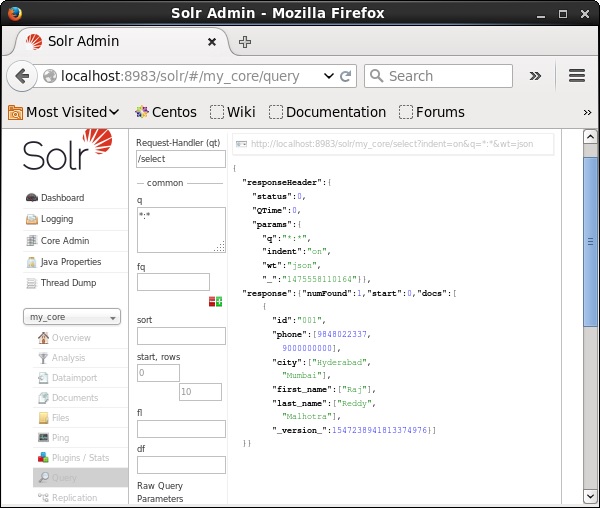
Посетите домашнюю страницу веб-интерфейса Apache Solr и выберите ядро my_core . Попробуйте получить все документы, введя запрос «:» в текстовой области q и выполните запрос. При выполнении вы можете заметить, что документы, содержащие указанную пару значений поля, удаляются.
Удаление всех документов
Как и при удалении определенного поля, если вы хотите удалить все документы из индекса, вам просто нужно вставить символ «:» между тегами <query> </ query>, как показано ниже.
<delete> <query>*:*</query> </delete>
Сохраните его как delete_all.xml и выполните операцию удаления в ядре с именем my_core с помощью инструмента post Solr.
[Hadoop@localhost bin]$ ./post -c my_core delete_all.xml
При выполнении вышеупомянутой команды это производит следующий вывод.
/home/Hadoop/java/bin/java -classpath /home/Hadoop/Solr/dist/Solr-core 6.2.0.jar -Dauto = yes -Dc = my_core -Ddata = files org.apache.Solr.util.SimplePostTool deleteAll.xml SimplePostTool version 5.0.0 Posting files to [base] url http://localhost:8983/Solr/my_core/update... Entering auto mode. File endings considered are xml,json,jsonl,csv,pdf,doc,docx,ppt,pptx,xls,xlsx,odt,odp,ods,ott,otp,ots,rtf, htm,html,txt,log POSTing file deleteAll.xml (application/xml) to [base] 1 files indexed. COMMITting Solr index changes to http://localhost:8983/Solr/my_core/update... Time spent: 0:00:00.138
верификация
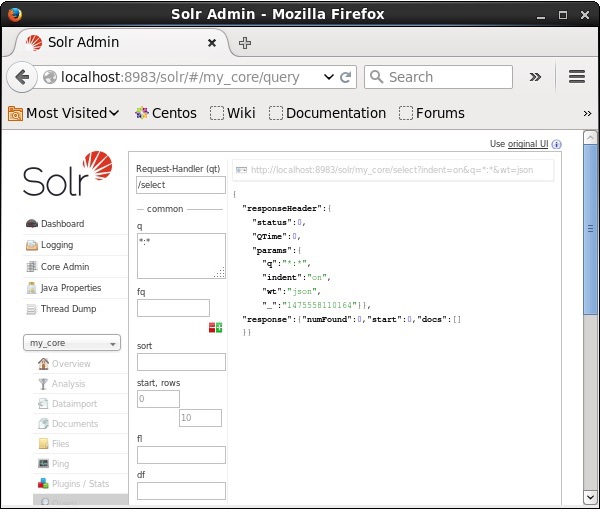
Посетите домашнюю страницу веб-интерфейса Apache Solr и выберите ядро как my_core . Попробуйте получить все документы, введя запрос «:» в текстовой области q и выполните запрос. При выполнении вы можете заметить, что документы, содержащие указанную пару значений поля, удаляются.
Удаление всех документов с использованием Java (Client API)
Ниже приведена Java-программа для добавления документов в индекс Apache Solr. Сохраните этот код в файле с именем UpdatingDocument.java .
import java.io.IOException; import org.apache.Solr.client.Solrj.SolrClient; import org.apache.Solr.client.Solrj.SolrServerException; import org.apache.Solr.client.Solrj.impl.HttpSolrClient; import org.apache.Solr.common.SolrInputDocument; public class DeletingAllDocuments { public static void main(String args[]) throws SolrServerException, IOException { //Preparing the Solr client String urlString = "http://localhost:8983/Solr/my_core"; SolrClient Solr = new HttpSolrClient.Builder(urlString).build(); //Preparing the Solr document SolrInputDocument doc = new SolrInputDocument(); //Deleting the documents from Solr Solr.deleteByQuery("*"); //Saving the document Solr.commit(); System.out.println("Documents deleted"); } }
Скомпилируйте приведенный выше код, выполнив следующие команды в терминале:
[Hadoop@localhost bin]$ javac DeletingAllDocuments [Hadoop@localhost bin]$ java DeletingAllDocuments
Выполнив вышеуказанную команду, вы получите следующий вывод.
Documents deleted
Apache Solr — получение данных
В этой главе мы обсудим, как получить данные с помощью Java Client API. Предположим, у нас есть документ .csv с именем sample.csv со следующим содержимым.
001,9848022337,Hyderabad,Rajiv,Reddy 002,9848022338,Kolkata,Siddarth,Battacharya 003,9848022339,Delhi,Rajesh,Khanna
Вы можете проиндексировать эти данные в ядре с именем sample_Solr, используя команду post .
[Hadoop@localhost bin]$ ./post -c Solr_sample sample.csv
Ниже приведена Java-программа для добавления документов в индекс Apache Solr. Сохраните этот код в файле с именем RetrievingData.java .
import java.io.IOException; import org.apache.Solr.client.Solrj.SolrClient; import org.apache.Solr.client.Solrj.SolrQuery; import org.apache.Solr.client.Solrj.SolrServerException; import org.apache.Solr.client.Solrj.impl.HttpSolrClient; import org.apache.Solr.client.Solrj.response.QueryResponse; import org.apache.Solr.common.SolrDocumentList; public class RetrievingData { public static void main(String args[]) throws SolrServerException, IOException { //Preparing the Solr client String urlString = "http://localhost:8983/Solr/my_core"; SolrClient Solr = new HttpSolrClient.Builder(urlString).build(); //Preparing Solr query SolrQuery query = new SolrQuery(); query.setQuery("*:*"); //Adding the field to be retrieved query.addField("*"); //Executing the query QueryResponse queryResponse = Solr.query(query); //Storing the results of the query SolrDocumentList docs = queryResponse.getResults(); System.out.println(docs); System.out.println(docs.get(0)); System.out.println(docs.get(1)); System.out.println(docs.get(2)); //Saving the operations Solr.commit(); } }
Скомпилируйте приведенный выше код, выполнив следующие команды в терминале:
[Hadoop@localhost bin]$ javac RetrievingData [Hadoop@localhost bin]$ java RetrievingData
Выполнив вышеуказанную команду, вы получите следующий вывод.
{numFound = 3,start = 0,docs = [SolrDocument{id=001, phone = [9848022337],
city = [Hyderabad], first_name = [Rajiv], last_name = [Reddy],
_version_ = 1547262806014820352}, SolrDocument{id = 002, phone = [9848022338],
city = [Kolkata], first_name = [Siddarth], last_name = [Battacharya],
_version_ = 1547262806026354688}, SolrDocument{id = 003, phone = [9848022339],
city = [Delhi], first_name = [Rajesh], last_name = [Khanna],
_version_ = 1547262806029500416}]}
SolrDocument{id = 001, phone = [9848022337], city = [Hyderabad], first_name = [Rajiv],
last_name = [Reddy], _version_ = 1547262806014820352}
SolrDocument{id = 002, phone = [9848022338], city = [Kolkata], first_name = [Siddarth],
last_name = [Battacharya], _version_ = 1547262806026354688}
SolrDocument{id = 003, phone = [9848022339], city = [Delhi], first_name = [Rajesh],
last_name = [Khanna], _version_ = 1547262806029500416}
Apache Solr — запрос данных
В дополнение к хранению данных, Apache Solr также предоставляет возможность запрашивать их обратно по мере необходимости. Solr предоставляет определенные параметры, с помощью которых мы можем запрашивать данные, хранящиеся в нем.
В следующей таблице мы перечислили различные параметры запроса, доступные в Apache Solr.
| параметр | Описание |
|---|---|
| Q | Это основной параметр запроса Apache Solr, документы оцениваются по сходству с терминами в этом параметре. |
| FQ | Этот параметр представляет запрос фильтра Apache Solr, ограничивая набор результатов документами, соответствующими этому фильтру. |
| Начните | Параметр start представляет начальные смещения для результатов страницы, значение этого параметра по умолчанию равно 0. |
| строки | Этот параметр представляет количество документов, которые должны быть получены на странице. Значение по умолчанию для этого параметра — 10. |
| Сортировать | Этот параметр указывает список полей, разделенных запятыми, по которым сортируются результаты запроса. |
| Флорида | Этот параметр указывает список полей, возвращаемых для каждого документа в наборе результатов. |
| вес | Этот параметр представляет тип автора ответа, который мы хотели просмотреть в результате. |
Вы можете видеть все эти параметры как опции для запроса Apache Solr. Посетите домашнюю страницу Apache Solr. В левой части страницы нажмите на опцию Запрос. Здесь вы можете увидеть поля для параметров запроса.
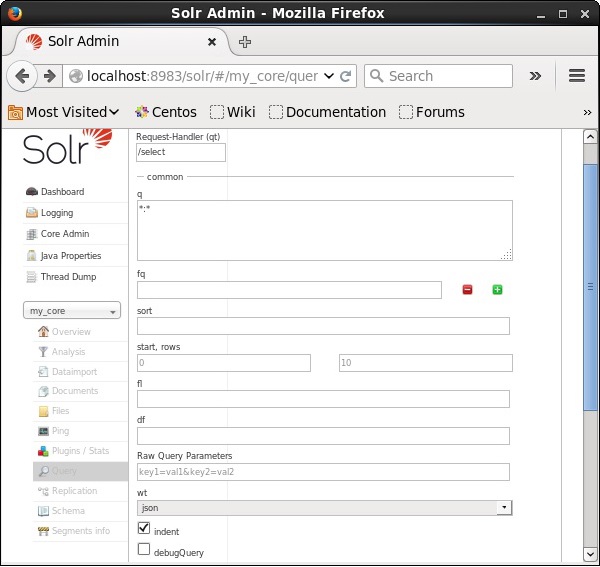
Извлечение записей
Предположим, у нас есть 3 записи в ядре с именем my_core . Чтобы извлечь конкретную запись из выбранного ядра, вам нужно передать пары имя и значение полей конкретного документа. Например, если вы хотите получить запись со значением поля id , вам нужно передать пару имя-значение поля как -Id: 001 в качестве значения для параметра q и выполнить запрос.
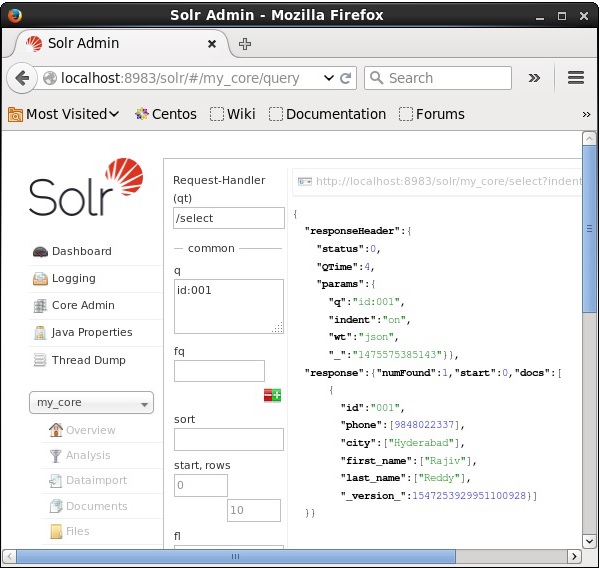
Таким же образом вы можете извлечь все записи из индекса, передав *: * в качестве значения параметра q , как показано на следующем снимке экрана.
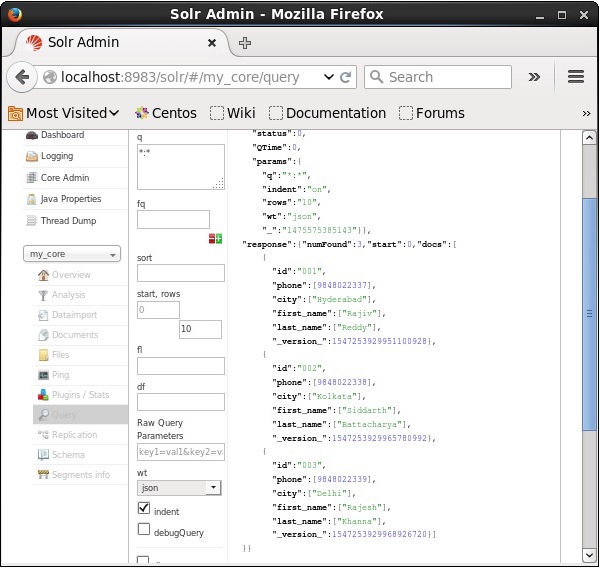
Извлечение из 2- й записи
Мы можем извлечь записи из второй записи, передав 2 в качестве значения для начала параметра, как показано на следующем снимке экрана.
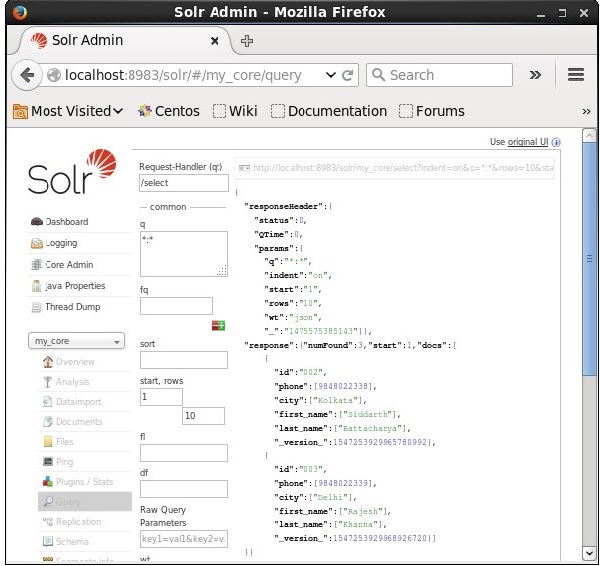
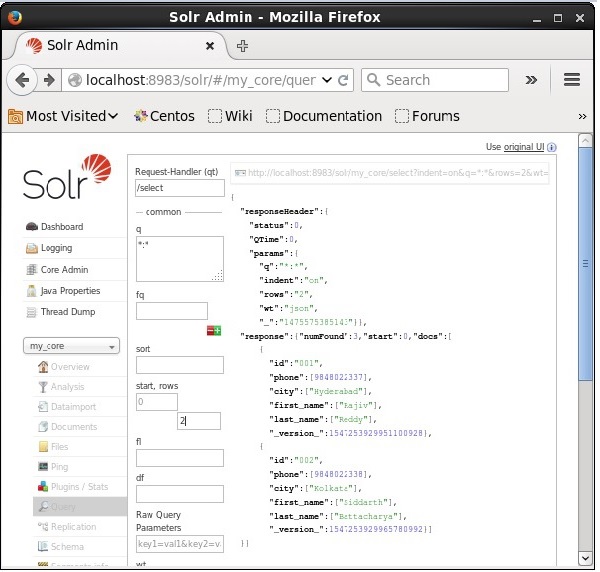
Ограничение количества записей
Вы можете ограничить количество записей, указав значение в параметре строк . Например, мы можем ограничить общее количество записей в результате запроса до 2, передав значение 2 в строки параметров, как показано на следующем снимке экрана.
Тип автора ответа
Вы можете получить ответ в требуемом типе документа, выбрав одно из предоставленных значений параметра wt .
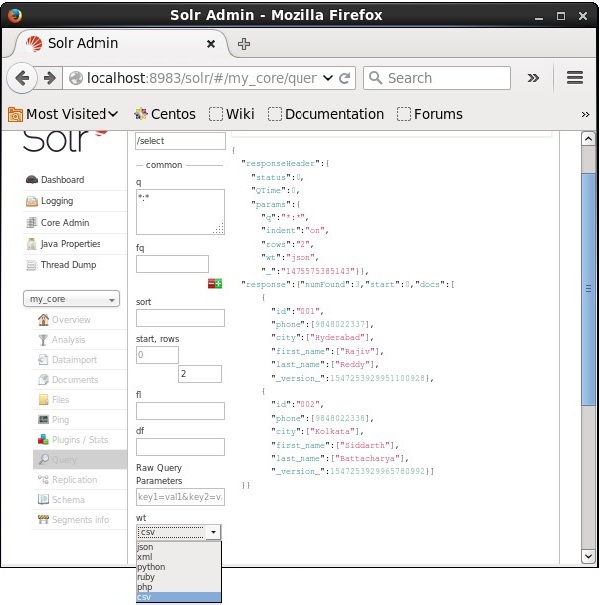
В приведенном выше примере мы выбрали формат .csv , чтобы получить ответ.
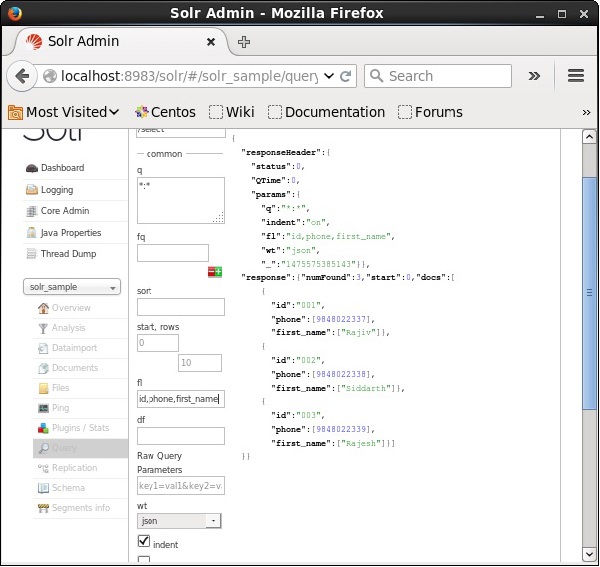
Список полей
Если мы хотим, чтобы в результирующих документах были определенные поля, нам нужно передать список обязательных полей, разделенных запятыми, в качестве значения свойства fl .
В следующем примере мы пытаемся получить поля — id, phone и first_name .
Apache Solr — огранка
Гранение в Apache Solr относится к классификации результатов поиска по различным категориям. В этой главе мы обсудим типы огранки, доступные в Apache Solr:
-
Фасет запроса — возвращает количество документов в текущих результатах поиска, которые также соответствуют заданному запросу.
-
Оформление даты — возвращает количество документов, попадающих в определенные диапазоны дат.
Фасет запроса — возвращает количество документов в текущих результатах поиска, которые также соответствуют заданному запросу.
Оформление даты — возвращает количество документов, попадающих в определенные диапазоны дат.
Команды гранения добавляются в любой обычный запрос запроса Solr, и счет граней возвращается в том же ответе на запрос.
Пример Faceting Query
Используя огранку поля, мы можем получить счетчики для всех терминов или только верхние термины в любом заданном поле.
В качестве примера рассмотрим следующий файл books.csv , содержащий данные о различных книгах.
id,cat,name,price,inStock,author,series_t,sequence_i,genre_s 0553573403,book,A Game of Thrones,5.99,true,George R.R. Martin,"A Song of Ice and Fire",1,fantasy 0553579908,book,A Clash of Kings,10.99,true,George R.R. Martin,"A Song of Ice and Fire",2,fantasy 055357342X,book,A Storm of Swords,7.99,true,George R.R. Martin,"A Song of Ice and Fire",3,fantasy 0553293354,book,Foundation,7.99,true,Isaac Asimov,Foundation Novels,1,scifi 0812521390,book,The Black Company,4.99,false,Glen Cook,The Chronicles of The Black Company,1,fantasy 0812550706,book,Ender's Game,6.99,true,Orson Scott Card,Ender,1,scifi 0441385532,book,Jhereg,7.95,false,Steven Brust,Vlad Taltos,1,fantasy 0380014300,book,Nine Princes In Amber,6.99,true,Roger Zelazny,the Chronicles of Amber,1,fantasy 0805080481,book,The Book of Three,5.99,true,Lloyd Alexander,The Chronicles of Prydain,1,fantasy 080508049X,book,The Black Cauldron,5.99,true,Lloyd Alexander,The Chronicles of Prydain,2,fantasy
Давайте разместим этот файл в Apache Solr, используя инструмент post .
[Hadoop@localhost bin]$ ./post -c Solr_sample sample.csv
При выполнении вышеупомянутой команды все документы, упомянутые в данном файле .csv, будут загружены в Apache Solr.
Теперь давайте выполним граненый запрос к автору поля с 0 строками в коллекции / ядре my_core .
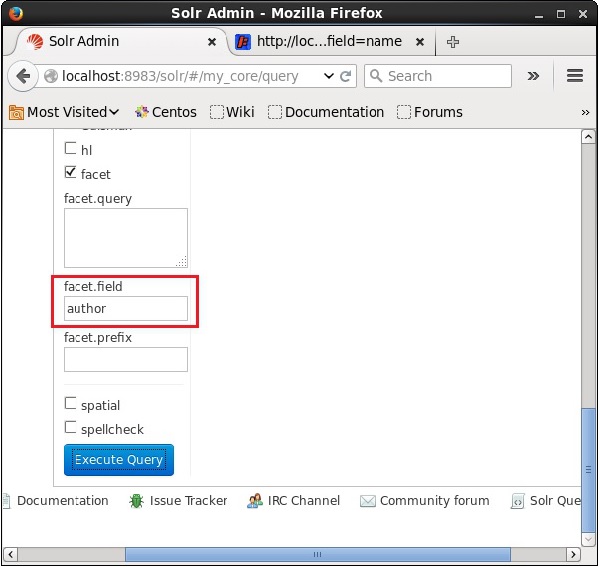
Откройте веб-интерфейс Apache Solr и в левой части страницы установите флажок флажка, как показано на следующем снимке экрана.
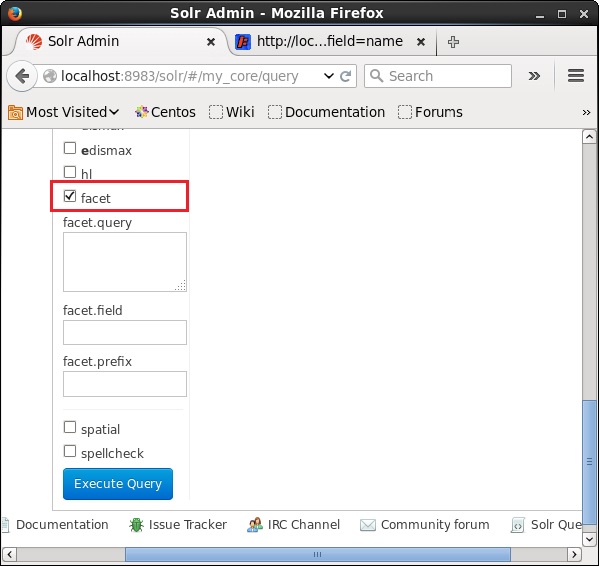
При установке флажка у вас будет еще три текстовых поля для передачи параметров поиска фасета. Теперь в качестве параметров запроса передайте следующие значения.
q = *:*, rows = 0, facet.field = author
Наконец, выполните запрос, нажав кнопку « Выполнить запрос» .
При выполнении он даст следующий результат.
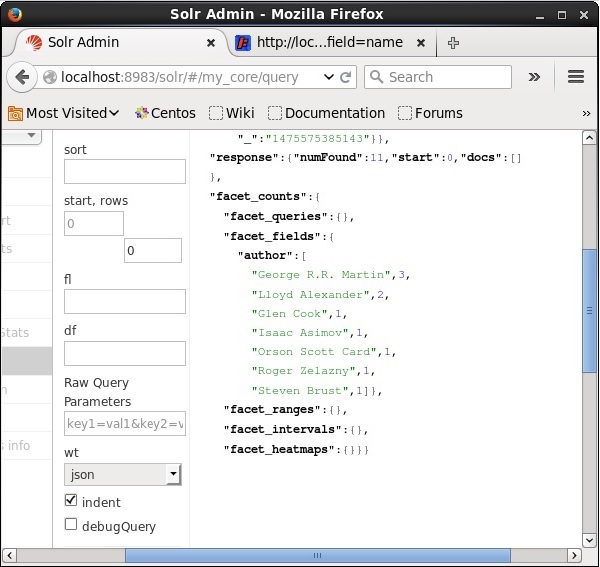
Он классифицирует документы в индексе на основе автора и указывает количество книг, внесенных каждым автором.
Фасетирование с использованием Java Client API
Ниже приведена Java-программа для добавления документов в индекс Apache Solr. Сохраните этот код в файле с именем HitHighlighting.java .
import java.io.IOException; import java.util.List; import org.apache.Solr.client.Solrj.SolrClient; import org.apache.Solr.client.Solrj.SolrQuery; import org.apache.Solr.client.Solrj.SolrServerException; import org.apache.Solr.client.Solrj.impl.HttpSolrClient; import org.apache.Solr.client.Solrj.request.QueryRequest; import org.apache.Solr.client.Solrj.response.FacetField; import org.apache.Solr.client.Solrj.response.FacetField.Count; import org.apache.Solr.client.Solrj.response.QueryResponse; import org.apache.Solr.common.SolrInputDocument; public class HitHighlighting { public static void main(String args[]) throws SolrServerException, IOException { //Preparing the Solr client String urlString = "http://localhost:8983/Solr/my_core"; SolrClient Solr = new HttpSolrClient.Builder(urlString).build(); //Preparing the Solr document SolrInputDocument doc = new SolrInputDocument(); //String query = request.query; SolrQuery query = new SolrQuery(); //Setting the query string query.setQuery("*:*"); //Setting the no.of rows query.setRows(0); //Adding the facet field query.addFacetField("author"); //Creating the query request QueryRequest qryReq = new QueryRequest(query); //Creating the query response QueryResponse resp = qryReq.process(Solr); //Retrieving the response fields System.out.println(resp.getFacetFields()); List<FacetField> facetFields = resp.getFacetFields(); for (int i = 0; i > facetFields.size(); i++) { FacetField facetField = facetFields.get(i); List<Count> facetInfo = facetField.getValues(); for (FacetField.Count facetInstance : facetInfo) { System.out.println(facetInstance.getName() + " : " + facetInstance.getCount() + " [drilldown qry:" + facetInstance.getAsFilterQuery()); } System.out.println("Hello"); } } }
Скомпилируйте приведенный выше код, выполнив следующие команды в терминале:
[Hadoop@localhost bin]$ javac HitHighlighting [Hadoop@localhost bin]$ java HitHighlighting
Выполнив вышеуказанную команду, вы получите следующий вывод.